
stm32-屏幕-中英文显示原理
显示中英文
1、显示原理
字符实际上是一个个独特的图形,计算机必须把字符编码转化成对应的字符图形人类才能正常识别,因此我们要给计算机提供字符的图形数据,这些数据就是字模,多个字模数据组成的文件也被称为字库。计算机显示字符时,根据字符编码与字模数据的映射关系找到它相应的字模数据,液晶屏根据字模数据显示该字符。
- 使用字符软件生成一个宽、高为16x16的像素点阵组成的汉字图形。计算机要表示这样的图形,只需使用16x16个二进制数据位,每个数据位记录一个像素点的状态,把黑色像素点以“1”表示,无色像素点以“0”表示即可。这样的一个汉字图形,使用16x16/8=32个字节来就可以记录下来。
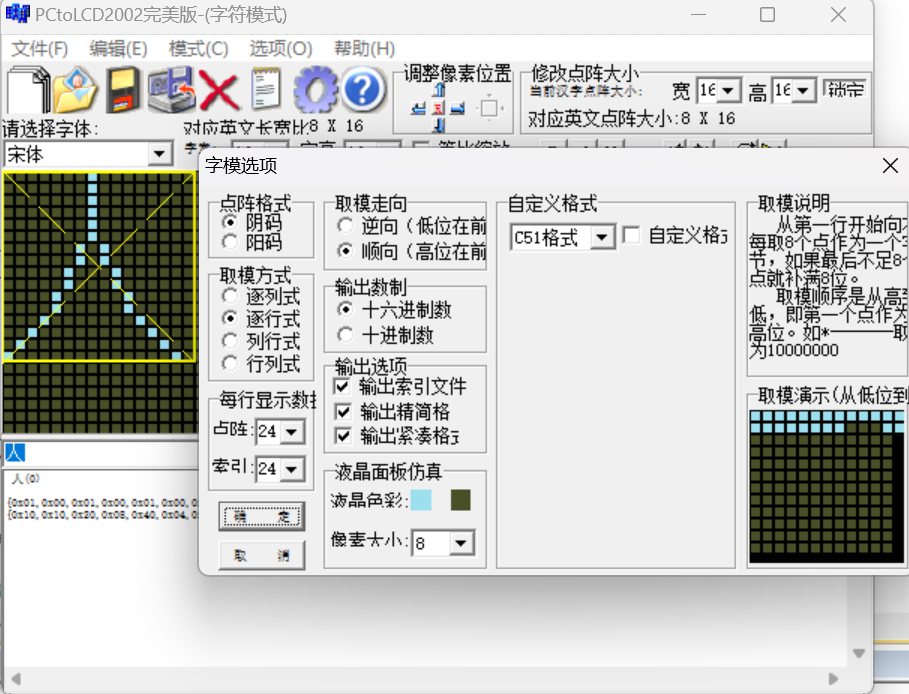
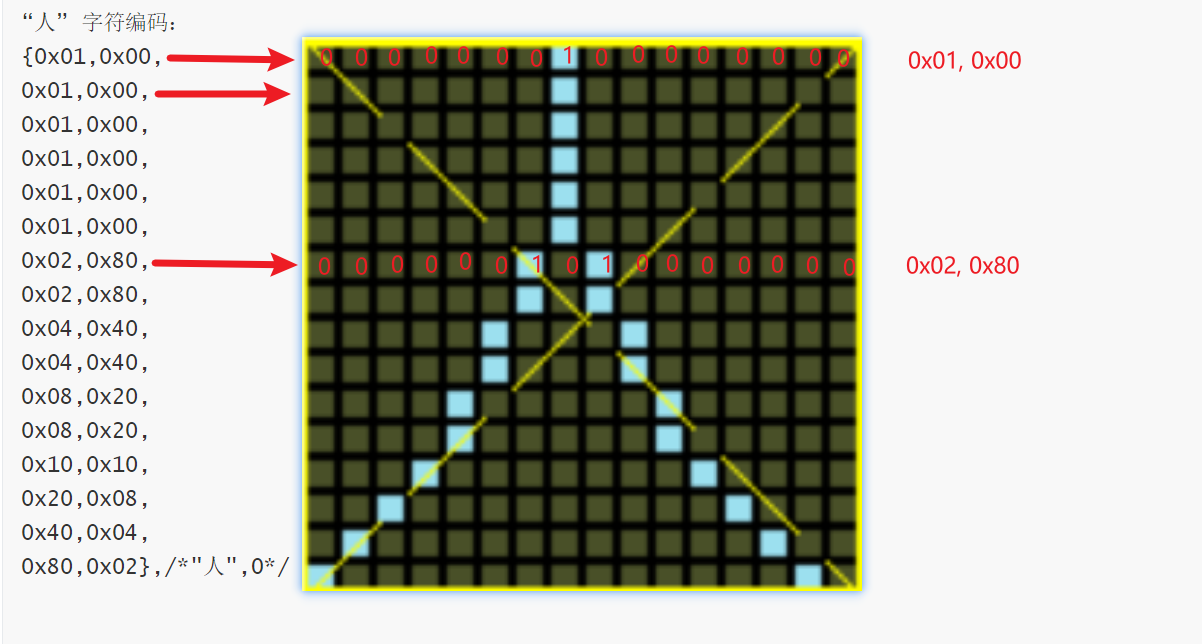
- 代码模拟打印字符
unsigned char font_module[] =
{0x01,0x00,
0x01,0x00,
0x01,0x00,
0x01,0x00,
0x01,0x00,
0x01,0x00,
0x02,0x80,
0x02,0x80,
0x04,0x40,
0x04,0x40,
0x08,0x20,
0x08,0x20,
0x10,0x10,
0x20,0x08,
0x40,0x04,
0x80,0x02};
int main(int argc, char const *argv[])
{
unsigned char row_num; // 行数,16 行
unsigned char byte_num; // 一行有 2 个字节
unsigned char column_num; // 列数,16 列(2个字节也是16位)
// 扫描 16 行
for(row_num = 0; row_num < 16; row_num++)
{
printf("\n");
// 一行 2 个字节
for(byte_num = 0; byte_num < 2; byte_num++)
{
// 一个字节 8 位,循环2次,16位(列)
for(column_num = 0; column_num < 8; column_num++)
{
// 用每一行的第 1 个字节和第 2 个字节和 0x80 偏移值“与”运算,判断哪一位为 1
if(font_module[row_num * 2 + byte_num] & (0x80 >> column_num))
{
printf("*");
}else{
printf(" ");
}
}
}
}
return 0;
}

2、液晶屏打印英文
2.1 准备一个字模库文件
(以ASCII为例,每个字符的大小为 8*16(宽高))
// 字模库的一部分
const unsigned char ASCII8x16_Table [] = { //@conslons字体,阴码点阵格式,逐行顺向取摸
0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, // ' '空格
0x00,0x00,0x00,0x18,0x18,0x18,0x18,0x18,0x18,0x08,0x00,0x08,0x18,0x00,0x00,0x00, // '!'
0x00,0x00,0x00,0x34,0x24,0x24,0x24,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, // '"'
0x00,0x00,0x00,0x00,0x16,0x24,0x7f,0x24,0x24,0x24,0x7e,0x24,0x24,0x00,0x00,0x00, // '#'
0x00,0x00,0x00,0x08,0x3e,0x68,0x48,0x68,0x1c,0x16,0x12,0x12,0x7c,0x10,0x10,0x00, // '$'
0x00,0x00,0x00,0x61,0xd2,0x96,0x74,0x08,0x10,0x16,0x29,0x49,0xc6,0x00,0x00,0x00, // '%'
0x00,0x00,0x00,0x00,0x3c,0x64,0x64,0x38,0x72,0x4a,0xce,0x46,0x7f,0x00,0x00,0x00, // '&'
0x00,0x00,0x00,0x18,0x18,0x18,0x18,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, // ','
0x00,0x00,0x00,0x04,0x08,0x18,0x10,0x30,0x30,0x30,0x30,0x10,0x10,0x18,0x0c,0x04, // '('
0x00,0x00,0x00,0x20,0x10,0x08,0x08,0x0c,0x04,0x04,0x04,0x0c,0x08,0x18,0x10,0x20, // ')'
………………
0x00,0x00,0x00,0x00,0x00,0x00,0x7e,0x06,0x0c,0x18,0x10,0x20,0x7e,0x00,0x00,0x00, // 'z'
0x00,0x00,0x00,0x0e,0x18,0x10,0x10,0x10,0x30,0x70,0x10,0x10,0x10,0x10,0x18,0x0e, // '{'
0x00,0x00,0x08,0x08,0x08,0x08,0x08,0x08,0x08,0x08,0x08,0x08,0x08,0x08,0x08,0x08, // '|'
0x00,0x00,0x00,0x30,0x18,0x08,0x08,0x08,0x0c,0x0e,0x08,0x08,0x08,0x08,0x18,0x30, // '}'
0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x71,0x4b,0x06,0x00,0x00,0x00,0x00,0x00, // '`'
}
2.2 字模寻址公式
-
一个字符
8*16=128个像素点,一个像素点1位,就是128bit,也就是128 / 8 = 16个字节 -
在ASCII中字符空格
' '的ASCII值十进制数是32以此递增,!是33,"是34,#是35,…………
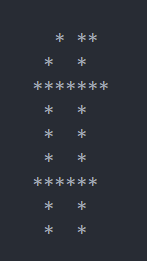
int main(int argc, char const *argv[])
{
printf("空格 ASCII值 ===> %d\r\n", ' ');
printf("! ASCII值 ===> %d\r\n", '!');
printf("'\"'ASCII值 ===> %d\r\n", '\"');
printf("'#'ASCII值 ===> %d\r\n", '#');
return 0;
}
输出:
空格 ASCII值 ===> 32
! ASCII值 ===> 33
'"'ASCII值 ===> 34
'#'ASCII值 ===> 35
- 获取任意字符的编码,以
#为例
// 获取偏移值
offset_val = '#' - ' ' = 35 - 32 = 3
// 一个字符的字节数,以8*16为例
byte_num = 8 * 16 / 8 = 16 个字节
// 获取指定字符的地址
addr = 16 * 3 = 48
ASCII8x16_Table[48]
// 打印
unsigned char *Pfont = (unsigned char*)&ASCII8x16_Table[48];
// 扫描 16 行
for(row_num = 0; row_num < 16; row_num++)
{
printf("\n");
// 一行 2 个字节
for(byte_num = 0; byte_num < 1; byte_num++)
{
// 一个字节 8 位,循环2次,16位(列)
for(column_num = 0; column_num < 8; column_num++)
{
// 用每一行的第 1 个字节和第 2 个字节和 0x80 偏移值“与”运算,判断哪一位为 1
if(Pfont[row_num * 1 + byte_num] & (0x80 >> column_num))
{
printf("*");
}else{
printf(" ");
}
}
}
}

3、液晶屏打印中文
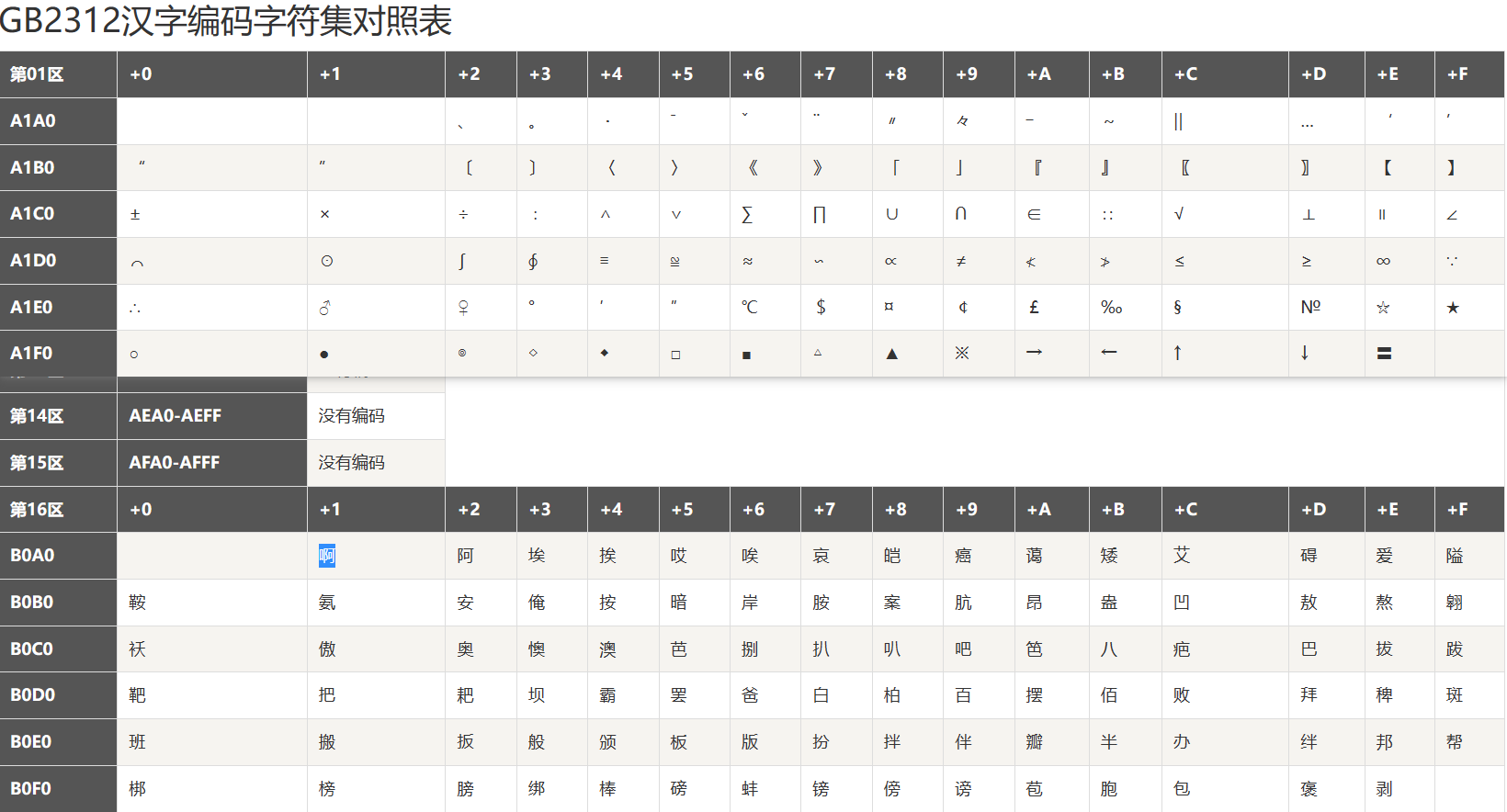
以GB2312为例(部分如下):
- GB2312,又称为GB0,由中国国家标准总局发布,1981年5月1日实施
- GB2312标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个
- GB2312是一种区位码。分为94个区(01-94),每区94个字符(01-94)
- 01-09区为特殊符号
- 10-15区没有编码
- 16-55区为一级汉字,按拼音排序,共3755个
- 56-87区为二级汉字,按部首/笔画排序,共3008个
- 88-94区没有编码
- GB2312只是编码表,在计算机中通常都是用"EUC-CN"表示法,即在每个区位加上0xA0来表示。区和位分别占用一个字节。
3.1 字模库
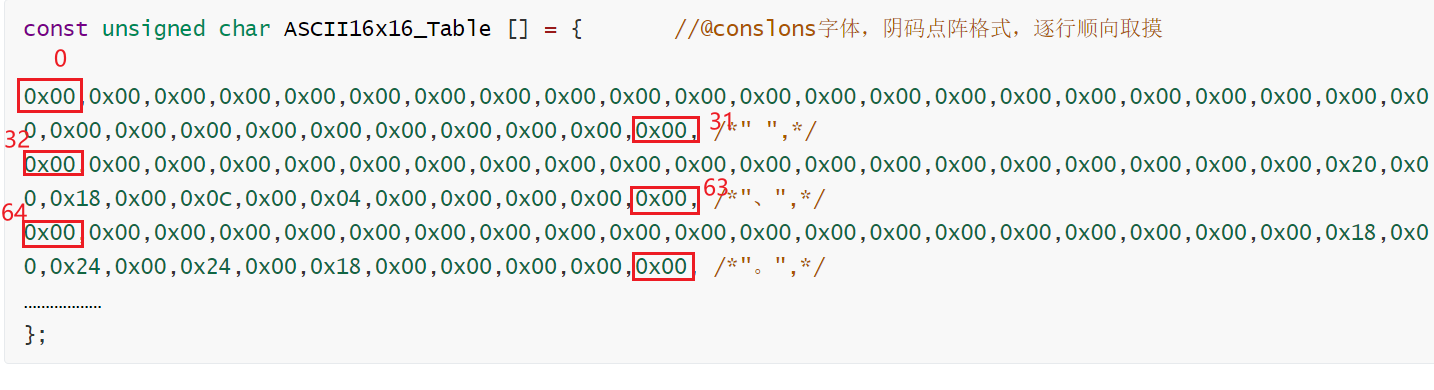
const unsigned char ASCII16x16_Table [] = { //@conslons字体,阴码点阵格式,逐行顺向取摸
0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, /*" ",*/
0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x20,0x00,0x18,0x00,0x0C,0x00,0x04,0x00,0x00,0x00,0x00,0x00, /*"、",*/
0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x18,0x00,0x24,0x00,0x24,0x00,0x18,0x00,0x00,0x00,0x00,0x00, /*"。",*/
………………
};
3.2 字模寻址
- 汉字一个字符以16*16的大小为例,所以一个字符需要
16 * 16 / 8 = 32个字节 - 按GB2312的汉字编码表,第一个字符”空格“的位置是
A1A1,
int main(int argc, char const *argv[])
{
unsigned short usChar = '、';
unsigned short jChar = '。';
unsigned short aChar = '啊';
printf("usChar ==> %X\r\n", usChar); // 结果:usChar ==> A1A2
printf("jChar ==> %X\r\n", jChar); // 结果:jChar ==> A1A3
printf("啊 ==> %X\r\n", aChar); // 结果:啊 ==> B0A1
return 0;
}
- 获取任意字符的编码,以中文的句号
。为例
// 获取字符的高八位和低八位
unsigned char high8bit, low8bit;
unsigned short jChar = '。';
high8bit = jChar >> 8;
low8bit = jChar & 0x00ff;
printf("jChar ==> %X\r\n", jChar); // jChar ==> A1A3
printf("high8bit ==> %X\r\n", high8bit); // high8bit ==> A1
printf("low8bit ==> %X\r\n", low8bit); // low8bit ==> A3
// 高八位减去0xA1是当前字符所在区和A1所在区的偏差,一个区有94个字符(所以乘以94),"。"的区偏差为0,在同一个区内
(high8bit - 0xA1) * 94
// 低八位减去0xA1,在当前区(同一个区)内,字符所在位置和第一个字符所产生的偏差,"。"的位置偏差为2,
(low8bit - 0xA1)
// 计算在ASCII16x16_Table数组中的偏差,"。"数组中的 (0 + 2) * 32 = 64
[(high8bit - 0xA1) * 94 + (low8bit - 0xA1)] * 32
// 最后得到所在索引

 浙公网安备 33010602011771号
浙公网安备 33010602011771号