编码表
一、编码表的由来
计算机只能识别二进制数据,早期由来是电信号。
为了方便应用计算机,让它可以识别各个国家的文字。
就将各个国家的文字用数字来表示,并一一对应,形成一张表。
这就是编码表。
二、常见的编码表
1.ASCII:美国标准信息交换码
用一个字节的7位可以表示
2.ISO8859-1:拉丁码表,欧洲码表
用一个字节的8位表示
3.GB2312:中国的中文编码表
4.GBK:中国的中文编码表升级,融合了更多的中文字符号
5.Unicode:国际标准码,融合了多种文字,
所有文字都用两个字节来表示,java语言使用的就是Unicode。
6.UTF-8:最多用三个字节来表示一个字符。
……
无非就是字符和二进制之间的转换。
public static void change() { String str="你好"; //编码 byte[] buf1=str.getBytes() //默认码表为GBK -60 -29 -70 -61 byte[] buf2=str.getBytes("utf-8") // -28 -67 -96 -27 -91 -67 //解码 String s1=new String(buf1); String S2=new String(buf2,"utf-8"); }
如果编码正确,但是解码不正确,怎么办?
public static void show() { string s="你好"; //编码 byte[] buf1=s.getBytes("gbk"); //解码 string s1=new String(buf1,"iso-8859-1"); //打印出s1=???? System.out.println("s1="+s1); //利用错码再编一次,得到正确的字节数组 byte[] buf2=s1.getBytes("iso-8859-1"); //利用正确的编码再解一次码,得到正确的字符 string s2=new String(buf2,"gbk"); //打印出“s2=你好” System.out.println("s2="+s2); }
原理如下图:
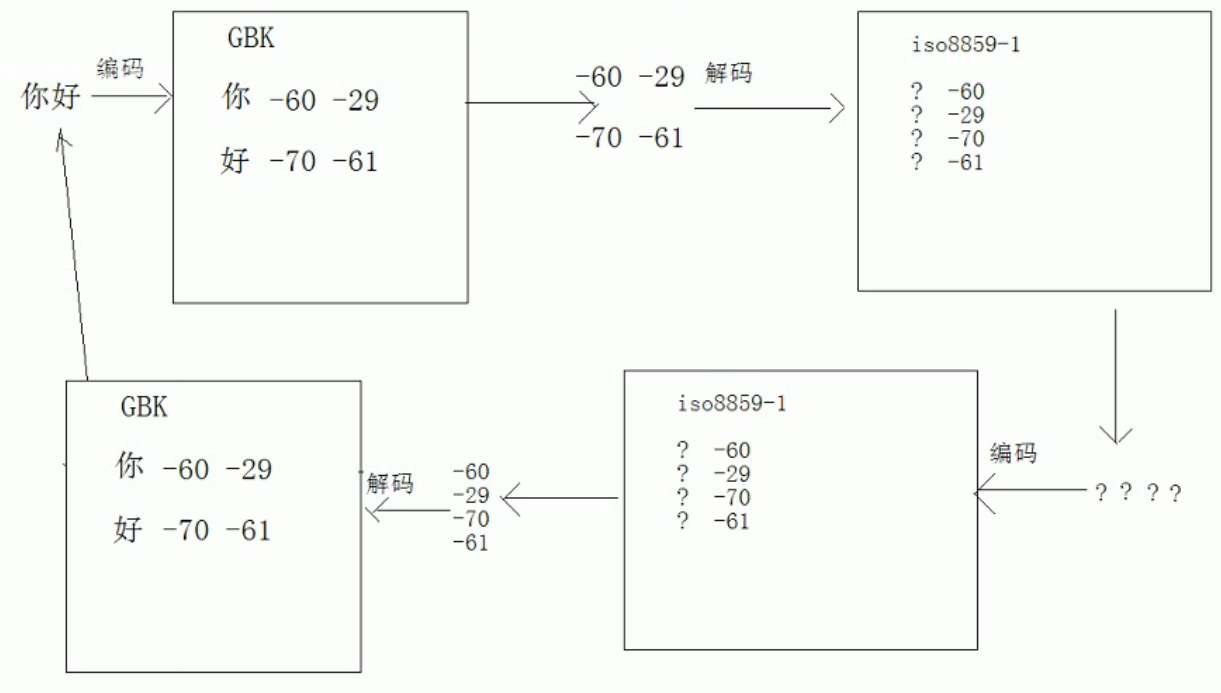
其实java开发中的Tomcat就是利用这个原理。Tomcat利用的是iso885901来进行编码和解码的,但是我们习惯于用gbk进行编码和解码,利用上述原理可以正确进行编码和解码。实现原理如下图:
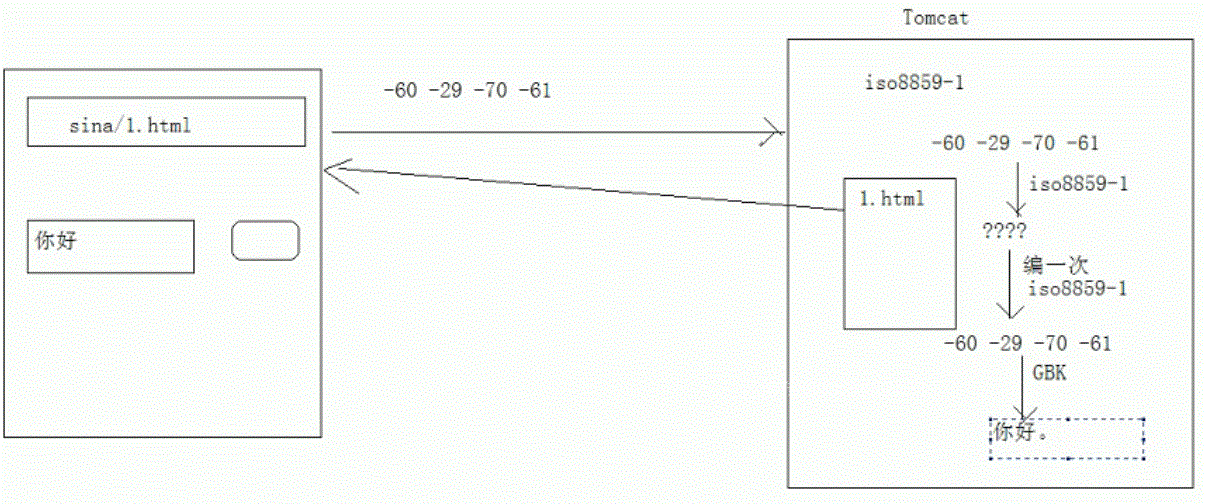
上述方法能成功,是因为iso8859-1是单字节编码,不影响原字节的长度。如果上例换成GBK和UTF-8两种编码表之间的转换,那么就不能实现了。首先因为UTF-8比较特殊,有可能一字节、二字节、三字节,如果找不到这种编码,就会给出-17 -65 -67三字节编码,改变了原编码字节长度,所以解码必须是错的。这一点要注意。
GB2312中两个字节都是是1开头,所以两个字节转整数都是负数,但是GBK中第一个字节是1开头,第2个字节有可能是0开头,如字“琲”。
在记事本中输入“移动”两个字,默认格式保存后再打开,是正常显示的。但是输入“联通”两个字,默认格式保存后再打开,显示不正常。因为联通两个字正好符合UTF-8规范,记事本认为这是一个UTF-8编码,所以打开文件时,采用UTF-8解码了,这就出现乱码了。
UTF-8规范:
一字节:0*******
二字节:11****** 10******
三字节:111***** 10****** 10******

 浙公网安备 33010602011771号
浙公网安备 33010602011771号