
欠采样和过采样解决分类样本不平衡问题
什么是样本不平衡
对于二分类问题,如果两个类别的样本数目差距很大,那么训练模型的时候会出现很严重的问题。举个简单的例子,猫狗图片分类,其中猫有990张,狗有10张,这时候模型只需要把所有输入样本都预测成猫就可以获得99%的识别率,但这样的分类器没有任何价值,它无法预测出狗。
类别不平衡(class-imbalance)就是指分类任务中正负样本数目差距很大的情况。生活中有很多类别不平衡的例子,如工业产品次品检测,次品样本数目远小于正品样本;欺诈问题,欺诈类观测在样本集中也只占据少数。因此,有必要了解解决类别不平衡的常用方法。
解决方法
欠采样
-
什么是欠采样
顾名思义,欠采样就是从大数目类别样本选取和小数目类别样本数目相当的样本,然后和少数目类别样本组成新的数据集,在新的数据集中正负样本比例相当。 -
随机欠采样算法
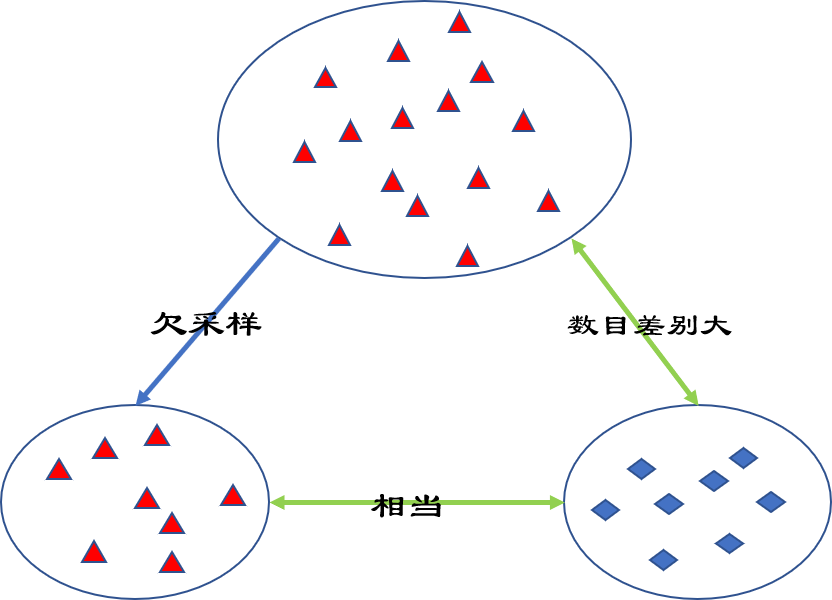
随机欠采样正如上图展示的,从大数目类别样本中随机选取和小数目类别样本数目相当的样本,然后和少数目类别样本组成新的数据集。
缺点:
随机欠采样后样本数目取决于原先小量类别样本数目,而当大类别样本和小类别样本数目差距很大而且小类别样本数目比较少时,这样很有可能会导致大类别样本损失一些重要信息。
为了克服这个问题,学者相继提出了EasyEnsemble和BalanceCascade算法。
- 欠采样代表性算法
-
EasyEnsemble
算法步骤
(1) 从多数类中有放回的随机采样n次,每次选取与少数类数目相近的样本个数,从而得到n个样本集合记作 \(\{S_{1maj}, S_{2maj},\cdots,S_{nmaj}\}\);
(2) 将(1)中得到的n个集合分别与少数类样本合并组成新的数据集去训练模型,可以得到n个模型;
(3) 将这些模型组成成集成学习系统,系统输出为n个模型的平均值。 -
BalanceCascade
BalanceCascade算法基于Adaboost,将Adaboost作为基分类器,核心思路如下:
(1) 在每一轮训练时都使用与少数类样本数目相当的多数类样本,训练出一个Adaboost基分类器;
(2) 然后使用该分类器对全体多数类进行预测,通过控制分类阈值来控制假正例率,将所有判断正确的样本删除。
(3) 最后,进入下一轮迭代中,继续降低多数类数量。
扩展阅读:
Liu X Y, Wu J, Zhou Z H. Exploratory undersampling for class-imbalance learning[J]
EasyEnsemble算法和BalanceCascade算法出自这篇论文。
过采样
- 什么是过采样方法
对训练集中少数类进行“过采样”(oversampling),简单来说就是少数类中一个样本抽取多次,从而使正负样本数目接近,再进行学习。 - 随机过采样
随机过采样是指从少数类 \(S_{min}\) 中随机选择一些样本,然后通过复制所选择的样本生成样本集 \(E\),把它们添加到 \(S_{min}\) 中来扩大少数类数据集。扩充后少数类数据集 \(S_{min}+E\) 应和多数类 \(S_{maj}\) 样本数目基本保持一致。
缺点:
少数类样本的扩充会导致模型训练复杂度加大;样本的直接复制会使得学习期学得的规则过于具体化,容易过拟合。
为解决过拟合问题,出现了过采样代表性算法:SMOTE和Borderline-SMOTE。
- 过采样代表性算法
- SMOTE
SMOTE全称是Synthetic Minority Oversampling即合成少数类过采样技术。随机过采样直接对少数类样本进行复制操作,容易导致过拟合,SMOTE算法针对复制操作进行改进,基本思想是:对每个少数类样本 \(x_i\),从它的最近邻(少数类)中随机选择一个样本 \(\hat x_i\) ,然后在 \(x_i\) 和 \(\hat x_i\)之间的连线上随机选择一点作为新合成的少数类样本。算法描述如下:
(1) 对于少数类样本中的每一个样本 \(x_i\), 计算它在 \(S_{min}\) 中的k个近邻;
(2) 根据类别不平衡比例设置一个采样比例以确定采样倍率N,从每个少数类样本 \(x_i\) 的k个近邻中挑选N个样本,对该少数类样本和其N个近邻分别进行随机线性插值生成N个新样本;
(3) 新样本与原多数类样本混合,产生新的数据集。
优缺点:
SMOTE算法摒弃了直接复制样本的做法,可以防止过拟合问题,实践证明可以提升分类器性能。但是SMOTE算法也存在下面两个缺点:
(1) 易发生样本重叠问题;
(2) 未考虑属性特征和临近样本分布特点,易过度泛化。
为克服上面两点的限制,多种自适应抽样方法相继被提出,其中具有代表性的方法包括Borderline-SMOTE算法。
- Borderline-SMOTE
Borderline-SMOTE采样过程将少数类样本分为3类:safe、danger和noise,然后仅使用danger少数类样本进行过采样。3类样本定义如下,
safe:样本k近邻(全体样本,含多数类)中一半以上均为少数类样本
danger:样本k近邻中一半以上均为多数类样本,这类样本视为边界点
noise:样本k近邻中均为多数类样本,视为异常值或噪声
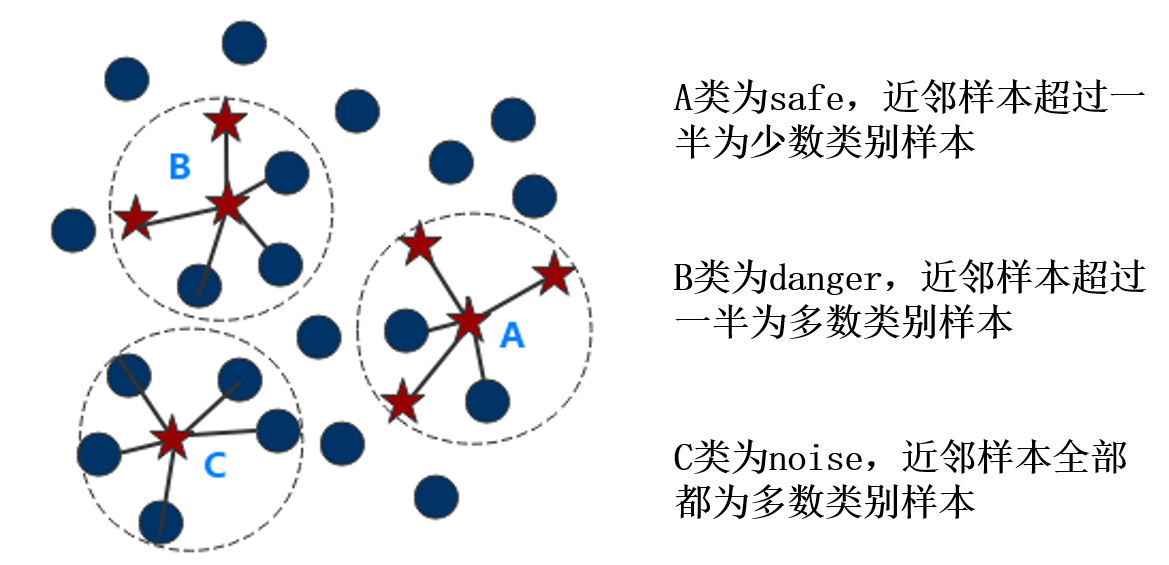
下图展示了Borderline-SMOTE算法采样的案例。
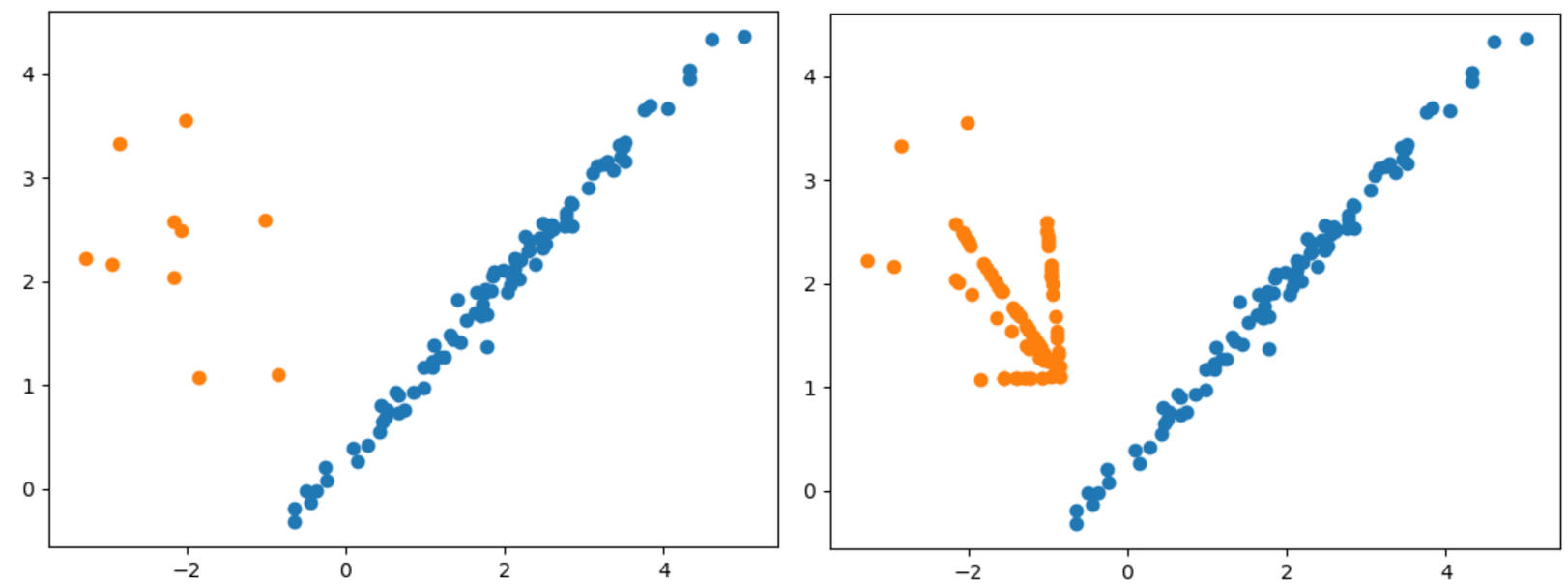
扩展阅读:
Han H, Wang W Y, Mao B H. Borderline-SMOTE: a new over-sampling method in imbalanced data sets learning[C], 2005.
Borderline-SMOTE算法出自上面这篇论文。
算法选取建议
- 在正负样本都非常少的情况下,应该采取数据合成的方式,如:SMOTE和Borderline-SMOTE算法。
- 在正负样本都足够充足且比例不是特别悬殊的情况下,应该考虑采样的方法或者是加权的方法。
References
[1] 分类中解决类别不平衡问题
[2] 不平衡数据处理之SMOTE、Borderline SMOTE和ADASYN详解及Python使用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号