Prometheus笔记-告警规则配置
告警规则Demo
groups:
# 告警组名称
- name: host_memory
rules:
# 告警规则名称
- alert: HighMemroy
# 告警规则(例子:下面的告警规则是内存大于30%告警的PromQL查询语法)
expr: ((node_memory_MemTotal_bytes - node_memory_MemFree_bytes - node_memory_Buffers_bytes - node_memory_Cached_bytes) / (node_memory_MemTotal_bytes )) * 100 > 30
# for:等待时间,表示当触发条件持续一段时间后才会触发告警,在等待期间新产生的告警状态为pending
for: 1m
# 自定义标签,Prometheus本身有一部分标签,这里可以附加额外的标签到告警上
labels:
type: memory
# 用于指定一组附加信息,比如用于描述告警详细信息的文字等
annotations:
# 通过$labels.<labelname>变量可以访问当前告警实例中指定标签的值。$value则可以获取当前PromQL表达式计算的样本值。
# 这里是类似于标题的效果,简述下告警信息(比如是什么类型的告警)
summarg: "Instance {{$labels.instance}} Memory high"
# 这里相当于正文,主要描述告警的阈值,是哪台实例主机发生告警等详细信息
description: "{{$labels.instance}} memory usage above 30% (current value :{{$value}})"
Prometheus 配置文件-告警部分
# my global config
global:
scrape_interval: 15s
evaluation_interval: 15s # 告警计算周期,默认为1m
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
rule_files:
# 告警规则文件存放路径,文件后缀必须是rules,比如 cpu.rules
- "/usr/local/src/prometheus/prometheus-2.44.0-rc.2.linux-amd64/rules/*.rules"
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: "node_exporter"
static_configs:
- targets: ["localhost:9100"]
- job_name: "nginx_exporter"
static_configs:
- targets: ["localhost:9113"]
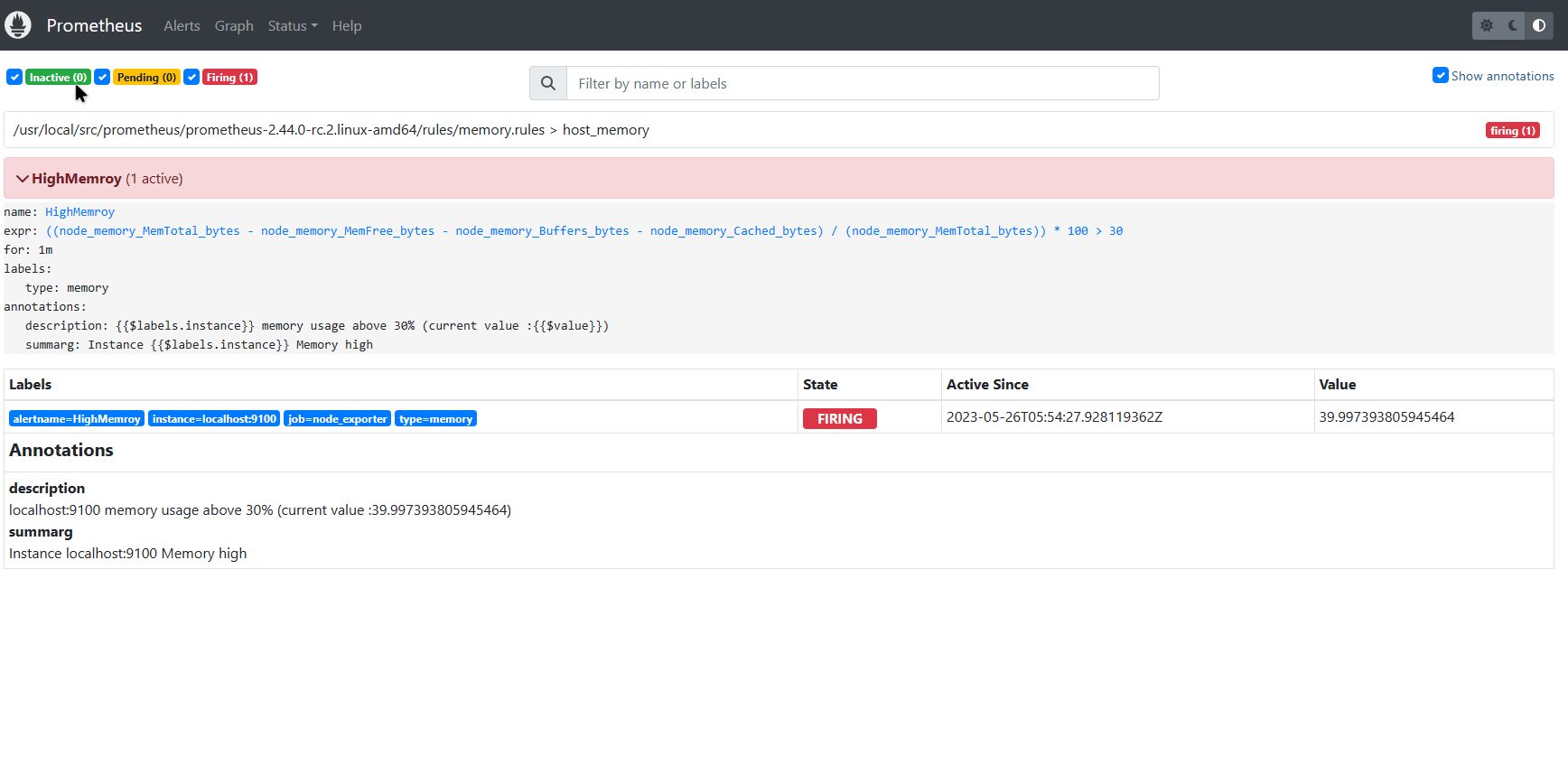
告警活动状态查询
ALERTS{alertname="<alert name>", alertstate="pending|firing", <additional alert labels>}
样本值为1表示当前告警处于活动状态(pending或者firing),当告警从活动状态转换为非活动状态时,样本值则为0。
展示效果
配置完成后重启Prometheus服务
本文来自博客园,作者:Jruing,转载请注明原文链接:https://www.cnblogs.com/jruing/p/17434858.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号