Netty入门-ButeBuf
3.5、ByteBuf
3.5.1、创建
//结果:初始容量256,扩容到512
//PooledUnsafeDirectByteBuf(ridx: 0, widx: 0, cap: 256)
//PooledUnsafeDirectByteBuf(ridx: 0, widx: 300, cap: 512)
public class TestByteBuf {
public static void main(String[] args) {
//结果:初始容量256
//扩容:2倍。。。
ByteBuf buf = ByteBufAllocator.DEFAULT.buffer();//直接内存
//ByteBuf buf = ByteBufAllocator.DEFAULT.heapBuffer();//堆内存
//ByteBuf buf = ByteBufAllocator.DEFAULT.directBuffer();//直接内存
System.out.println(buf.getClass());//查看是否池化
System.out.println(buf);
StringBuilder builder = new StringBuilder();
for (int i = 0; i < 300; i++) {
builder.append("a");
}
buf.writeBytes(builder.toString().getBytes());
System.out.println(buf);
}
}
总结:
- 直接内存创建和销毁的代价昂贵,但读写性能高(少一次内存复制),适合配合池化功能一起用
- 直接内存对 GC 压力小,因为这部分内存不受 JVM 垃圾回收的管理,但也要注意及时主动释放
3.5.2、池化
池化的最大意义在于可以重用 ByteBuf,优点有
- 没有池化,则每次都得创建新的 ByteBuf 实例,这个操作对直接内存代价昂贵,就算是堆内存,也会增加 GC 压力
- 有了池化,则可以重用池中 ByteBuf 实例,并且采用了与 jemalloc 类似的内存分配算法提升分配效率
- 高并发时,池化功能更节约内存,减少内存溢出的可能
池化,非池化通过idea,vm options来配置
-Dio.netty.allocator.type=unpooled//非池化
-Dio.netty.allocator.type=pooled//池化
3.5.3、组成
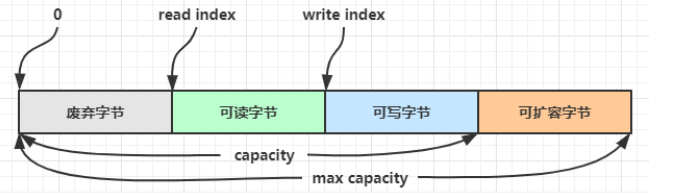
废弃部分,可读部分,可写部分,可扩容部分
3.5.4、扩容
- 如何写入后数据大小未超过 512,则选择下一个 16 的整数倍,例如写入后大小为 12 ,则扩容后 capacity 是 16
- 如果写入后数据大小超过 512,则选择下一个 2^n,例如写入后大小为 513,则扩容后 capacity 是 210=1024(29=512 已经不够了)
- 扩容不能超过 max capacity 会报错
3.5.5、读取
buf.readByte();//读一个字节,读过的就废弃了,可读指针移动
//重复度
//1.读之前,做标记
buffer.markReaderIndex();
//2.读取
buffer.readInt();
//3.重复度
buffer.resetReaderIndex();
或者用get通过下标读,不会改变指针
3.5.6、retain & release
由于 Netty 中有堆外内存的 ByteBuf 实现,堆外内存最好是手动来释放,而不是等 GC 垃圾回收。
- UnpooledHeapByteBuf 使用的是 JVM 内存,只需等 GC 回收内存即可
- UnpooledDirectByteBuf 使用的就是直接内存了,需要特殊的方法来回收内存
- PooledByteBuf 和它的子类使用了池化机制,需要更复杂的规则来回收内存
回收内存源码:protected abstract void deallocate()
回收算法:引用计数法,每个方法都实现了 ReferenceCounted 接口

谁来回收呢?一般会想到buf.release。但是,各个handler中间有buf在传递,有想到在tail和head回收,但是有可能buf在传递过程中已经变成了字符串了。
谁是最后使用者,谁负责 release
head和tail释放源码:TailContext类中channelRead()和HeadContext中channel(),释放逻辑:判断如果是Bybuf再release
3.5.7、slice
【零拷贝】的体现之一
小结:
- duplicate():直接拷贝整个buffer,包括readerIndex、capacity、writerIndex
- slice():拷贝buffer中已经写入数据的部分
- copy()方法会进行内存复制工作,效率很低。
对ByteBuf切片,切片后的ByteBuf并没有发生内存复制,而是和切片前ByteBuf共用内存,切片后的ByteBuf有自己独立的read,write指针
slice();//拷贝buffer中已经写入数据的部分
slice(index, length);//从index位置切片,切取length长度
slice后,新的buf和老buf共用内存,新的变了老的也变了。解决:
新buf.retain();引用计数+1 老buf.release();引用计数-1
public class TestSlice {
public static void main(String[] args) {
ByteBuf buf = ByteBufAllocator.DEFAULT.buffer();
buf.writeBytes("helloworld".getBytes());
ByteBuf buf1 = buf.slice(0, 5);
ByteBuf buf2 = buf.slice(5, 5);
buf1.retain();
buf.release();
System.out.println("buf1修改前,buf:" + buf.toString(Charset.defaultCharset()));
buf1.setByte(0, 'z');
System.out.println("buf1修改后,buf:" + buf.toString(Charset.defaultCharset()));
System.out.println("buf1修改后,buf1:" + buf1.toString(Charset.defaultCharset()));
System.out.println(buf2.toString(Charset.defaultCharset()));
}
}
3.5.7、duplicate
【零拷贝】的体现之一
直接拷贝整个buffer,包括readerIndex、capacity、writerIndex
3.5.8、copy
会将底层内存数据进行深拷贝,因此无论读写,都与原始 ByteBuf 无关
3.5.9、CompositeByteBuf
【零拷贝】的体现之一
多个 ByteBuf 合并为一个逻辑上的 ByteBuf,避免拷贝
3.5.10、Unpooled
Unpooled 是一个工具类,非池化的 ByteBuf 创建、组合、复制等操作
ByteBuf buf1 = ByteBufAllocator.DEFAULT.buffer(5);
buf1.writeBytes(new byte[]{1, 2, 3, 4, 5});
ByteBuf buf2 = ByteBufAllocator.DEFAULT.buffer(5);
buf2.writeBytes(new byte[]{6, 7, 8, 9, 10});
// 当包装 ByteBuf 个数超过一个时, 底层使用了 CompositeByteBuf
ByteBuf buf3 = Unpooled.wrappedBuffer(buf1, buf2);
System.out.println(ByteBufUtil.prettyHexDump(buf3));
3.6.1、ByteBuf 优势
- 池化 - 可以重用池中 ByteBuf 实例,更节约内存,减少内存溢出的可能
- 读写指针分离,不需要像 ByteBuffer 一样切换读写模式
- 可以自动扩容
- 支持链式调用,使用更流畅
- 很多地方体现零拷贝,例如 slice、duplicate、CompositeByteBuf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号