索引
概述
index是帮助MYSQL高效获取数据的数据结构,相当于书的目录。
缺点:
-
索引本身很大, 可以存放在内存/硬盘(通常为 硬盘)
-
索引不是所有情况均适用: a.少量数据 b.频繁更新的字段 c.很少使用的字段
-
索引会降低增删改的效率(增删改)
优点:
- 提高查询效率(降低IO使用率)
- 降低CPU使用率 (...order by age desc,因为 B树索引 本身就是一个 好排序的结构,因此在排序时 可以直接使用)
索引原则
- 索引不是越多越好
- 不要经常变动的数据加索引
- 小数据量的表不需加索引索引
- 一般加在需经常查询的字段上
索引数据结构
- Hash
- Btree:InnoDB默认 小的放左,大的放右
- B+树:Mysql默认
B树
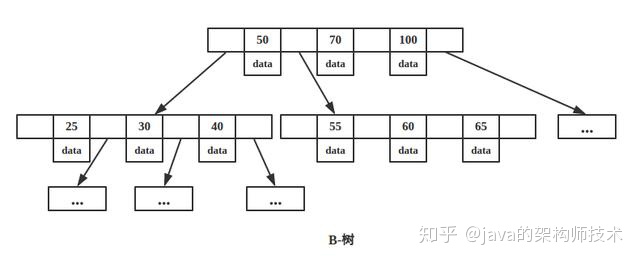
-
多路,非二叉树
-
每个节点既保存索引,又保存数据
-
搜索时相当于二分查找
B+树
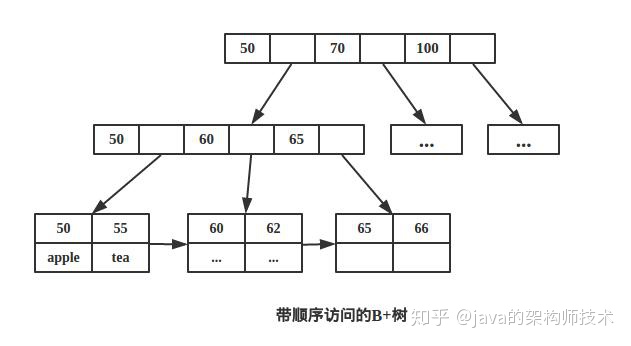
- 多路非二叉
- 只有叶子节点保存数据
- 搜索时相当于二分查找
- 增加了相邻接点的指向指针。
B树和B+树区别
-
B+树查询时间复杂度固定是logn,B树查询复杂度最好是 O(1)。
-
B+树相邻接点的指针可以大大增加区间访问性,可使用在范围查询等,而B-树每个节点 key 和 data 在一起,则无法区间查找。
-
B+树更适合外部存储,也就是磁盘存储。由于内节点无 data 域,每个节点能索引的范围更大更精确
-
注意这个区别相当重要,是基于(1)(2)(3)的,B树每个节点即保存数据又保存索引,所以磁盘IO的次数很少,B+树只有叶子节点保存,磁盘IO多,但是区间访问比较好。
索引分类
- 主键索引(primary key): 不能重复。id 不能是null,只能有一个
- 唯一索引(unique key) :可以有多个,可以是null** 主键创建后一定包含一个唯一性索引,唯一性索引并不一定就是主键
- 单值索引/常规索引(key/index) : 单列, age ;一个表可以多个单值索引,name。
- 复合索引:多个列构成的索引 (相当于 二级目录 : z: zhao) (name,age) (a,b,c,d,...,n)
- 全文索引(fulltext):char、varchar或text类型的列上创建,版本低的mysql,MyISAM才有
使用索引
添加
- 创建表时:create 索引类型 索引名 on 表名(字段)
- 创建表后:alter table 表名 索引类型 索引名(字段1,字段2)
删除
drop index 索引名 on 表名
查询
show index from 表名
索引优化
- 最佳做前缀,保持索引的定义和使用的顺序一致性
- 将含In的范围查询 放到where条件的最后,防止失效。
- 小表驱动大表 当编写 ..on t.cid=c.cid 时,将数据量小的表 放左边(假设此时t表数据量小)
- 主查询数据集大用in,否侧exist
- 不要写select *
- 分批查询
- 分表
索引失效
- 在索引上进行任何操作(计算、函数、类型转换)会索引失效
- 对于复合索引,如果左边失效,右侧全部失效
- like %开头,索引失效
- or语句前后没有同时使用索引
- 符合索引中,!= ,<>,between and
- is null, is not null
- 没有使用最佳左前缀
- 字符串不加单引号,索引失效
- in也可能索引失效

 浙公网安备 33010602011771号
浙公网安备 33010602011771号