
kafka存储,高吞吐分析
存储结构
概述
-
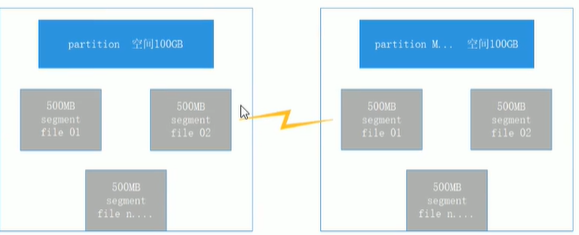
每一个partition(文件夹)相当于一个巨型文件被平均分配到多个大小相等的segment数据文件里
但每一个segment file消息数量不一定相等,这样的特性方便old segment file告诉被删除(默认每一个文件大小1G,可以在server.properties 中log.segment.bytes=107370设置)
-
每一个partition仅仅需支持顺序读写即可。segment文件生命周期由服务端配置参数决定
存储结构
每一个segment file由 2大部分组成。index file和data file。2个文件一一对应,成对出现。.index和.log表示。
segmeng文件命名规则:partition全局第一个segment从0开始,后面每个segment文件名称为上一个segment文件最后一条消息的offset值。
00000000000000368769.index的消息量起始偏移量为368770 = 368769 + 1
数值最大为64位long大小,19位数字字符长度。没有数字用0填充
logs下主题文件夹里
-rw-r--r--. 1 root root 10485760 Feb 19 23:55 00000000000000000000.index
-rw-r--r--. 1 root root 0 Feb 18 21:51 00000000000000000000.log
-rw-r--r--. 1 root root 10485756 Feb 19 23:55 00000000000000000000.timeindex
-rw-r--r--. 1 root root 8 Feb 19 23:56 leader-epoch-checkpoint
日志索引
数据文件的分段
将数据文件分段,每段放在一个单独的数据文件里,数据文件以该段中最小的offset命名,这样查找指定offset的message,二分查找定位
偏移量索引
索引文件和日志文件内容关系如下
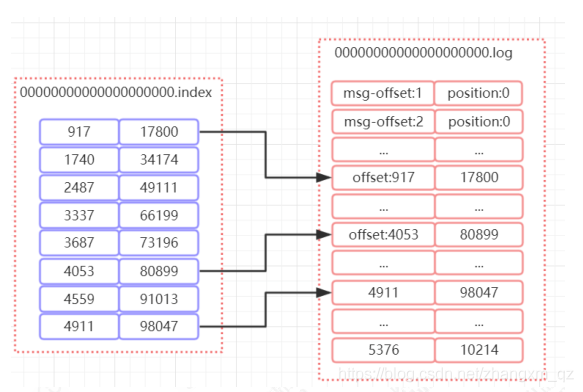
如上图所示,index 文件中存储了索引以及物理偏移量。 log 文件存储了消息的内容。索引文件中保存了部分offset和偏移量position的对应关系。比如 index文件中 [4053,80899],表示在 log 文件中,对应的是第 4053 条记录,物理偏移量(position)为 80899.
查找 message过程
-
根据offset,查找 segment 段中的 index 索引文件。由于索引文件命名是以上一个文件的最后一个offset 进行命名的,所以,使用二分查找算法能够根据offset 快速定位到指定的索引文件
-
找到索引文件后,根据 offset 进行定位,找到索引文件中的匹配范围的偏移量position。(kafka 采用稀疏索引的方式来提高查找性能)
(找到offset<=指定offset的索引条目,根据这个索引条目offset确定偏移量position)
-
得到 position 以后,再到对应的 log 文件中,从 position处开始查找 offset 对应的消息,将每条消息的 offset 与目标 offset 进行比较,直到找到消息
如说,我们要查找 offset=2490 这条消息,那么先找到00000000000000000000.index, 然后找到[2487,49111]这个索引,再到 log 文件中,根据 49111 这个 position 开始查找,比较每条消息的 offset 是否大于等于 2490。最后查找到对应的消息以后返回
这套机制是建立在offset是有序的。索引文件被映射到内存中,所以查找速度很快
总结:kafka的message存储采用了分区(partition),分段(segment)和稀疏索引来达到高效
日志清理
日志删除
#启用删除策略
log.cleanup.policy=delete(server.properties中配置)
#过期删除
log.retention.hours=128(server.properties中配置)
#超过大小删除
log.retention.bytes=1073741824(server.properties中配置)
-
根据消息的保留时间,当消息在 kafka 中保存的时间超过了指定的时间,就会触发清理过程
通过log.retention.hours,默认7天
-
根据 topic 存储的数据大小,当 topic 所占的日志文件大小大于一定的阀值,则可以开始删除最旧的消息。
通过 log.retention.bytes =字节数来设置,默认1G
都配置的话,当其中任意一个达到要求,都会执行删除
日志压缩
只保留每个key最后一个版本的数据。
概述及配置
配置方法:server.properties中
- broker配置中设置log.cleaner.enable=true,启用claner,默认关闭
- topic配置中设置log.cleanup.policy=compact启用压缩策略
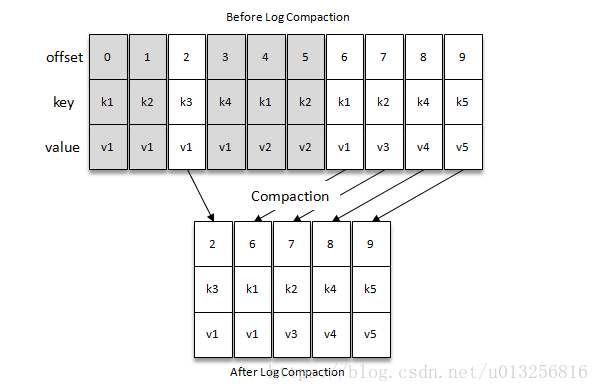
压缩后的offset是不连续的。当从这些offset 消费消息时,将会拿到比这个offset大的offset对应的消息。比如想获取offset=5的消息,实际上会拿到offset=6的消息,并从这个位置开始消费
适用场景
消息的key是用户ID,消息体是用户资料,通过压缩策略,整个消息集里就保存了所有用户的最新资料。
压缩策略支持删除,当某个key的最新消息没有内容时,此key将被删除。
kafka高吞吐分析
客户端优化
新版生产者客户端摒弃了以往的单线程,而采用了双线程:主线程和Sender线程。
主线程负责将消息置入客户端缓存,Sender线程负责从缓存中发送消息,而这个缓存会聚合多个消息为一个批次。有些消息中间件会把消息直接扔到broker。
分区,分段,索引
topic中数据分为多个partition分区存储到不同broker上。每个partition分为多个segment进行分段存储,所以每次操作都是对一小部分操作
每个segment由.index索引文件和.log数据文件构成,以offset命名
顺序读写
kafka采用了文件追加的方式来写入消息,只能在文件尾部追加新消息,不允许修改已经写入的消息
页缓存(PageCache)
操作系统在内存中给磁盘上的文件建立的缓存。
kafka利用了操作系统本身的Page Cache,就是利用操作系统自身的内存而不是JVM空间内存。
磁盘文件数据复制到页缓存中,将数据直接从页缓存发送到网络中(发送给不同订阅者,可以使用同一个页缓存)
零拷贝(zero-copy)
避免 CPU 将数据从一块存储拷贝到另外一块存储的技术。
linux操作系统 “零拷贝” 机制使用了sendfile方法, 允许操作系统将数据从Page Cache 直接发送到网络,只需要最后一步的copy操作将数据复制到 NIC 缓冲区, 这样避免重新复制数据 。示意图如下:
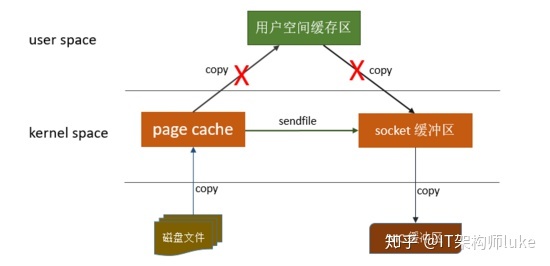
通过这种 “零拷贝” 的机制,Page Cache 结合 sendfile 方法,Kafka消费端的性能也大幅提升。这也是为什么有时候消费端在不断消费数据时,我们并没有看到磁盘io比较高,此刻正是操作系统缓存在提供数据。
批量处理
producer和consumer中,消息都是以批为单位进行传递的。消息达到固定条数或规定时间
消息压缩
批量压缩和批量处理一起使用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号