消费者详解
相关概念
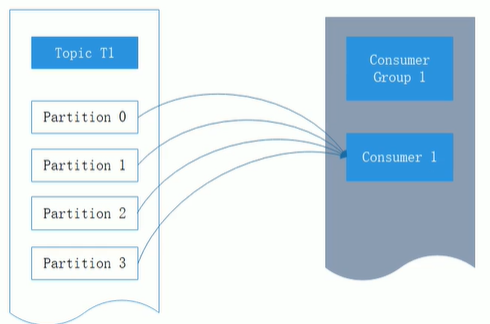
消费者和消费组
同一个消费组内的每个消费者会收到不同分区的消息,消费者和分区1对多
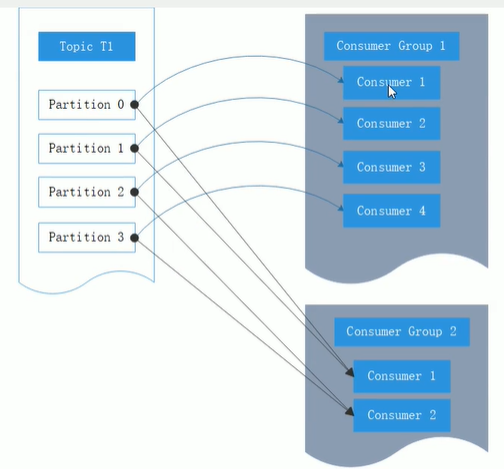
应用需要不同的消费组,每个应用可以读取到一个主题内所有分区的消息
消息接收
必要参数设置
- key,value的反序列化
- 集群清单,bootstrap.servers
- 消费组,group.id,默认为空,会抛出异常
- KafkaConsumer对应客户端ID,client.id,默认空,不设置就为空字符串
订阅主题和分区
订阅主题
//参数是topic列表
consumer.subscribe(Arrays.asList(topic));
//以为正则表达式匹配,订阅所有jpy开头的主题
consumer.subscribe(Pattern.compile("jpy.*"));
订阅分区
//订阅jpy主题中0分区的消息
consumer.assign(Arrays.asList(new TopicPartition("jpy", 0)));
反序列化
//key反序列化
//properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//value发序列化
//properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
位移提交
同一个分区中的每条消息都有唯一offset,表示消息在分区中的位置
重复消费
消费端自动提交offersets设置为true,已经消费了数据,但是offset没提交
消息丢失
消费端自动提交offersets设置为true,当消费者拉到消息之后,还没有处理完 commit interval 提交间隔就到了,提交了offerset。这时consummer又挂了,重启后,从下一个offersets开始消费,之前的消息丢失了。
自动提交
消费者来管理位移,消费者会在poll调用后每隔5秒(auto.commit.interval.ms指定)提交一次位移。和许多其他操作一样,自动提交也是由poll方法驱动。
调用poll时,消费者判断是否达到提交时间,如果是则提交上一次poll返回的最大位移。
可能导致消息重复消费。某个消费者poll消息后,应用正在处理消息,3秒后Kafka进行了重平衡。由于offset没提交,导致平衡后这部分消息重复消费
默认自动提交,true
//显示自动提交
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
// 设置自动每1s提交一次
props.put("auto.commit.interval.ms", "1000");
同步提交
-
抽取properties工具类
public class ConsumerClientUtil { private static final String brokerList = "192.168.0.191:9092"; private static final String topic = "jpy"; private static final String groupId = "group.demo"; public static Properties initConfig() { Properties properties = new Properties(); properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList); properties.put(ConsumerConfig.GROUP_ID_CONFIG, groupId); properties.put(ConsumerConfig.CLIENT_ID_CONFIG, "");//非必需,默认为空字符串 properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);//非必需,默认为true,自动提交 return properties; } public static String getTopic() { return topic; } }
适用场景:减少消息重复消费或者避免消息丢失 auto.commit.offset为false commitSync()
缺点:发起提交调用时应用会阻塞
public class ConsumerSyncFastStart {
public static void main(String[] args) {
Properties properties = ConsumerClientUtil.initConfig();
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
String topic = ConsumerClientUtil.getTopic();
//声明消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
//订阅topic中消息
//consumer.subscribe(Arrays.asList(topic));
//以为正则表达式匹配,订阅所有jpy开头的主题里的消息
//consumer.subscribe(Pattern.compile("jpy.*"));
//只订阅jpy主题分区0里的消息
TopicPartition topicPartition = new TopicPartition(topic, 0);
consumer.assign(Arrays.asList(topicPartition));
long lastConsumerOffset = -1;
//获得消息
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
if (records.isEmpty()) {
break;
}
List<ConsumerRecord<String, String>> partitionRecords = records.records(topicPartition);
lastConsumerOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
consumer.commitSync();//同步提交offset
}
//上次提交
System.out.println("consumed offset is " + lastConsumerOffset);
OffsetAndMetadata offsetAndMetadata = consumer.committed(topicPartition);
//当前提交的位移,即下次消费的位移
System.out.println("commited offset is " + offsetAndMetadata.offset());
//下次消费的位移
long position = consumer.position(topicPartition);
System.out.println("the offset of the next record is " + position);
}
}
异步提交
适用场景:消息多,允许重复消费
缺点:如果服务器返回提交失败,异步提交不会重试。因为,如果同时存在多个异步提交,进行重试可能会导致位移覆盖。
例:一个异步提交A,提交位移2000,随后有一个异步提交B,提交位移为3000。A提交失败B成功,此时A重试并成功了,
会将实际上已经提交的位移从3000回滚到2000,2000到3000的就会重复消费
public class ConsumerAsyncCommit {
public static void main(String[] args) {
Properties properties = ConsumerClientUtil.initConfig();
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
String topic = ConsumerClientUtil.getTopic();
//声明消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
//订阅topic中消息
consumer.subscribe(Arrays.asList(topic));
//consumer.subscribe(Pattern.compile("jpy.*"));
//获得消息
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
if (records.isEmpty()) {
break;
}
for (ConsumerRecord<String, String> record : records) {
//do local something
}
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
if (exception == null) {
System.out.println("offsets=" + offsets);
} else {
logger.error("fail to commit offset {}", offsets, exception);
}
}
});
}
}
}
指定位移消费
-
seek()方法可一追踪以前的消费或回溯消费
//分区的分配是在 poll() 方法的调用过程中实现的,也就是说,在执行 seek() 方法之前需要先执行一次 poll() 方法 consumer.poll(Duration.ofMillis(2000)); //获取分区set Set<TopicPartition> assignment = consumer.assignment(); for (TopicPartition topicPartition : assignment) { //从offset=10,开始消费(包括10) consumer.seek(topicPartition, 10); } while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(2000)); for (ConsumerRecord<String, String> record : records) { System.out.println("分区=" + record.partition() + "\t" + "offset=" + record.offset() + "\t" + "消息=" + record.value()); } } -
增加判断是否分配到了分区
//增加判断是否分配到了分区 Set<TopicPartition> assignment = new HashSet<>(); while (assignment.size() == 0) { consumer.poll(Duration.ofMillis(100)); assignment = consumer.assignment(); }
分区末尾消费
-
第一种方法:endOffsets
//offset:0-n,endOffset就是n+1 Map<TopicPartition, Long> endOffsets = consumer.endOffsets(assignment); for (TopicPartition topicPartition : assignment) { //分区末尾开始消费,就是从最大的offset+1开始消费,就是空消息,要想获得最后一天消息,endOffsets.get(topicPartition)-1 consumer.seek(topicPartition, endOffsets.get(topicPartition)); } -
第二种方法:seekToEnd
consumer.seekToEnd(assignment);
再均衡监听器
通过消费者subcirbe方法,传入ConsumerRebalanceListener再平衡监听器,触发再平衡时,为避免重复消费,需要把当前消息所消息到的位置做个记录,
加上1,放入map中,这样存的就是下次消费的开始offset
map中key为TopicPartition,value为OffsetAndMetadata()
分区的所属从一个消费者转移到另一个消费者。再均衡期间,消费者无法拉取消息.
以下会触发再均衡
- 消费组内新增或删除consumer
- topic发生变化
- topic新增了分区
public class ConsumerSyncCommitInRebalance {
private static transient Logger logger = LoggerFactory.getLogger(ConsumerSyncCommitInRebalance.class);
private static final AtomicBoolean flag = new AtomicBoolean(true);
public static void main(String[] args) {
Properties properties = ConsumerClientUtil.initConfig();
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
String topic = ConsumerClientUtil.getTopic();
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
//
Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<>();
consumer.subscribe(Arrays.asList(topic), new ConsumerRebalanceListener() {
@Override
//再均衡开始前和上一个消费者停止读取消息之后被调用,这里提交偏移量,下一个接管分区的消费者就知道该从哪里开始读取了
//提交的是最近处理过的偏移量,而不是批次中还在处理的最后一个偏移量。
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
//同步提交offset,尽量避免重复消费
consumer.commitSync(currentOffsets);
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
}
});
try {
while (flag.get()) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.offset() + "==" + record.value());
//异步提交消费位移,再发生再均衡动作之前可以通过再均衡监听器的onPartitionRevoked回调执行commitSync方法同步提交位移
currentOffsets.put(new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1));
}
consumer.commitAsync(currentOffsets, new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
if (exception != null) {
logger.error("fail to commit offset {}", offsets, exception);
}
}
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
consumer.close();
}
}
}
消费者拦截器
消费消息或提交位移时进行一些定制化操作
使用场景
对消息设置一个有效期的属性,如果某条消息在指定时间内无法到达,那就视为无效,不需要再被处理
自定义消费者拦截器
public class MyConsumerInterceptorTTL implements ConsumerInterceptor<String, String> {
//过期时间10秒,消费者只消费10秒内消息
private static final long EXPIRE_INTERVAL = 10 * 1000;
@Override
//返回新的ConsumerRecords<String, String>,丢弃过期消息
public ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String> records) {
long now = System.currentTimeMillis();
//存放过滤后的消息
Map<TopicPartition, List<ConsumerRecord<String, String>>> newRecords = new HashMap<>();
Set<TopicPartition> partitions = records.partitions();
for (TopicPartition partition : partitions) {
List<ConsumerRecord<String, String>> newTpRecords = new ArrayList<>();
List<ConsumerRecord<String, String>> tpRecords = records.records(partition);
for (ConsumerRecord<String, String> tpRecord : tpRecords) {
if (now - tpRecord.timestamp() < EXPIRE_INTERVAL) {
newTpRecords.add(tpRecord);
}
}
if (!newTpRecords.isEmpty()) {
newRecords.put(partition, newTpRecords);
}
}
return new ConsumerRecords<>(newRecords);
}
@Override
//poll()方法返回之前调用对消息进行定制化
public void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets) {
offsets.forEach((k,v) -> System.out.println("tp = "+ k +"\toffset = "+ v));
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
消费者使用拦截器
public class ConsumerInterceptorTest {
public static void main(String[] args) {
Properties properties = ConsumerClientUtil.initConfig();
properties.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG, MyConsumerInterceptorTTL.class.getName());
String topic = ConsumerClientUtil.getTopic();
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Arrays.asList(topic));
//consumer.assign(Arrays.asList(new TopicPartition(topic, 0)));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value() + "==" + record.timestamp());
}
}
}
}
生产者测试
Properties properties = new Properties();
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.0.191:9092");
properties.put(ProducerConfig.RETRIES_CONFIG, 10);
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
//拦截器会过滤掉此条消息,消费者不会收到
ProducerRecord<String, String> record = new ProducerRecord<String, String>("jpy", 0, System.currentTimeMillis() - 10 * 1000, "kafka_demo", "过期消息");
ProducerRecord<String, String> record1 = new ProducerRecord<String, String>("jpy", 0, "kafka_demo", "不过期消息");
try {
producer.send(record1);
producer.send(record);
} catch (Exception e) {
e.printStackTrace();
} finally {
producer.close();
}
消费者参数
-
fetch.min.bytes:消费者从broker读取消息时的最小数据量。如果消息小于这个阈值,broker会等待直到有足够的数据才发给消费者
写入量不高的topic,可以减少broker和消费者的压力,因为减少了往返时间。对于有大量消费者的topic,可以减轻broker的压力
-
fetch.max.wait.ms:消费者读取时最大等待时间。默认500ms
-
max.partition.fetch.bytes:每个分区返回的最多字节数。默认1M,也就是poll方法返回记录列表时,每个分区的记录字节数最多为1M
如果一个主题有20个分区,同时有5个消费者,那每个消费者需要4M空间来处理消息
-
max.poll.records:控制poll方法返回的记录数,用来控制应用在拉取循环中的处理数据量

 浙公网安备 33010602011771号
浙公网安备 33010602011771号