生产者详解
消息发送
数据生成流程
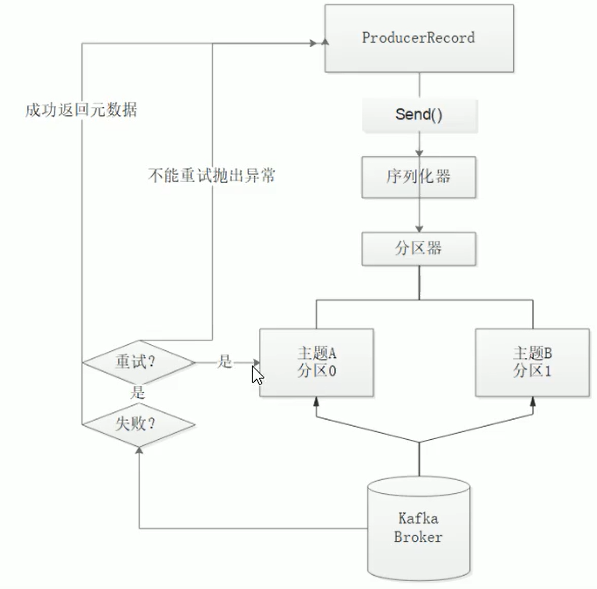
发送类型
发送即忘记
producer.send(record);
同步发送
send()发送消息后返回Future对象啊。调用get方法等待kafka响应
正常响应:返回RecordMetadata对象,它存储消息的偏移量等
发生错误:无法正常响应,抛出异常,我们就可以异常处理
try {
RecordMetadata recordMetadata = producer.send(record).get();
System.out.println(recordMetadata.topic());//返回topic
System.out.println(recordMetadata.partition());//返回分区
System.out.println(recordMetadata.offset());//返回偏移量
} catch (Exception e) {
e.printStackTrace();
}
异步发送
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e == null) {
System.out.println(recordMetadata.topic());//返回topic
System.out.println(recordMetadata.partition());//返回分区
System.out.println(recordMetadata.offset());//返回偏移量
}
}
});
序列化器
都实现了Serializer
默认
- 字符串:StringSerializer
- 整形:IntegerSerializer
- 字节数组:BytesSerializer
自定义序列化器
-
Student类
public class Student { private String name; private String sex; //下面get、set方法省略 } -
自定义Student序列化器
package com.moral.kafka.chapter1; import java.nio.ByteBuffer; import java.util.Map; import org.apache.kafka.common.serialization.Serializer; public class StudentSerializer implements Serializer<Student> { private final String encoder = "UTF-8"; @Override public void configure(Map configs, boolean isKey) { } @Override public byte[] serialize(String topic, Student student) { if (student == null) return null; byte[] name, sex; try { if (student.getName() != null) { name = student.getName().getBytes(encoder); } else { name = new byte[0]; } if (student.getSex() != null) { sex = student.getSex().getBytes(encoder); } else { sex = new byte[0]; } ByteBuffer buffer = ByteBuffer.allocate(4 + 4 + name.length + sex.length); buffer.putInt(name.length); buffer.put(name); buffer.putInt(sex.length); buffer.put(sex); return buffer.array(); } catch (Exception e) { e.printStackTrace(); } return new byte[0]; } @Override public void close() { } } -
使用自定义序列化器
package com.moral.kafka.chapter1; import java.util.Properties; import org.apache.kafka.clients.producer.Callback; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; import org.apache.kafka.common.serialization.StringSerializer; public class ProduceDefineSerializer { private static final String brokerList = "192.168.0.191:9092"; private static final String topic = "jpy"; public static void main(String[] args) { Properties properties = new Properties(); //1.设置key序列化器 properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); //设置重试次数 properties.put(ProducerConfig.RETRIES_CONFIG, 10); //设置值序列化器,用自定义序列化器 properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StudentSerializer.class.getName()); //设置集群地址 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList); KafkaProducer<String, Student> producer = new KafkaProducer<String, Student>(properties); Student student = new Student("张三", "男"); ProducerRecord<String, Student> record = new ProducerRecord<>(topic, student); try { producer.send(record); } catch (Exception e) { e.printStackTrace(); } finally { producer.close(); } } }
分区器
未指定,会使用默认的分区策略,DefaultPartitioners。根据消息key,hash(key)%numPartitions。key相同分配到同一分区
自定义分区器
需实现Partitioner
package com.moral.kafka.chapter1;
import java.util.List;
import java.util.Map;
import java.util.concurrent.atomic.AtomicInteger;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.utils.Utils;
public class DefinePartitioner implements Partitioner {
//AtomicInteger是一个提供原子操作的Integer类,通过线程安全的方式操作加减。适合高并发
private final AtomicInteger counter = new AtomicInteger(0);
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
//1.getAndIncrement()返回原值,相当于i++
//2.incrementAndGet()返回原值+1,相当于++i
//3.这里counter.getAndIncrement()=0,counter.incrementAndGet()=1
return counter.getAndIncrement() % numPartitions;
}
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
-
基本类型的原子操作类
//Integer原子操作测试 public class AtomicIntegerTest { public static void main(String[] args) { AtomicInteger atomicInteger = new AtomicInteger(0); System.out.println(atomicInteger.getAndIncrement());//0 System.out.println(atomicInteger);//1 System.out.println(atomicInteger.incrementAndGet());//2 } } -
自定义分区器使用
//自定义分区器使用 properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, DefinePartitioner.class.getName());
拦截器interceptor
- Producer端拦截器ProducerIntercetor,可以在消息发送前做一些准备工作
- Consumer端拦截器
使用场景
- 按照某个规则过滤掉不符合要求的信息
- 修改消息内容
- 统计类需求
定义拦截器
package com.moral.kafka.interceptor;
import java.util.Map;
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
//自定义拦截器,给消息加前缀prefix1
public class MyProducerInterceptor implements ProducerInterceptor<String, String> {
//发送成功的消息数
private volatile long sendSuccess = 0;
//发送失败的消息数
private volatile long sendFail = 0;
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
String modifiedValue = "prefix1" + record.value();
return new ProducerRecord<>(record.topic(), record.partition(), record.timestamp(), record.key(), modifiedValue, record.headers());
}
//在消息被应答之前或者消息发送失败时调用
//统计失败,成功消息数
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
if (exception == null) {
sendSuccess++;
} else {
sendFail++;
}
}
@Override
//当前拦截器关闭时,输出发送成功率
public void close() {
double successRatio = (double) sendSuccess / (sendSuccess + sendFail);
System.out.println("发送成功率==" + String.format("%f", successRatio * 100) + "%");
}
@Override
public void configure(Map<String, ?> configs) {
}
}
使用拦截器
properties.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, MyProducerInterceptor.class.getName());
发送原理剖析
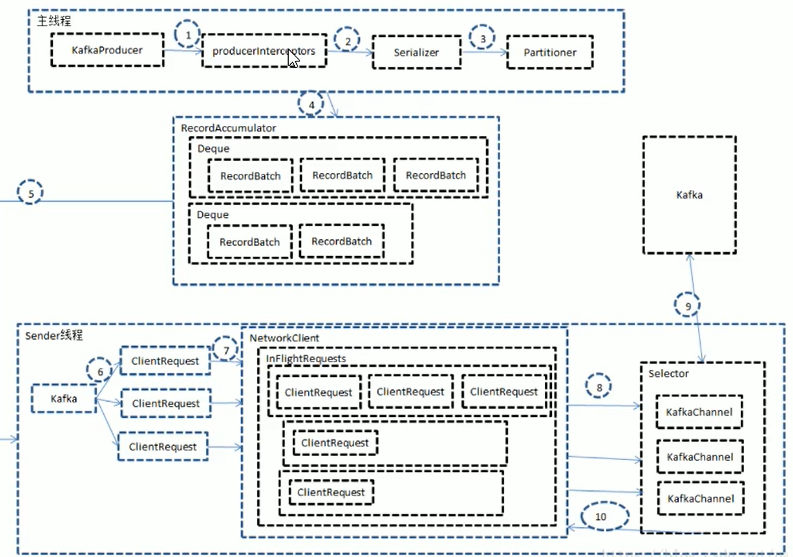
消息发送过程中,涉及到两个线程协同工作,主线程首先将业务数据封装成ProducerRecord对象,之后调用send()方法将消息放入到RecordAccumulator(消息收集器,也可以理解为主线程与Sender线程直接的缓冲区)中暂存,Sender线程负责将消息构成请求,并最终执行I/O的线程,它从RecordAccumulator中取出消息并批量发送出去,需要注意的是,Kafka是线程安全的,多个线程间可以共享一个KafkaProducer对象
其他生产者参数
ack
指定分区中比需有多少个副本收到这条消息,生产者才会认为这条消息写入成功,客户端中重要参数,它涉及到消息的可靠性和吞吐量之间的权衡
String类型
//配置ack properties.put(ProducerConfig.ACKS_CONFIG, "0");
- ack=0:生产者写入消息前不需等待服务器的响应,消息可能丢失,发送消息速度最大,吞吐量大
- ack=1(默认):集群Leader收到消息,生产者就会收到服务器的成功响应,如果消息无法到达Leader(Leader崩溃,新Leader还没选举出来),生产者会收到错误响应,为避免数据丢失,生产者会重发消息。但是还有可能导致数据丢失,如果收到写成功通知,Leader还没来得及同步到follower,Leader就崩溃,数据就丢失
- ack=-1:所有参与复制节点收到消息,生产者才收到成功响应,最安全,保证不止一个服务器收到消息
retries
重试次数。默认情况下每次重试间隔100ms,可通过retry.backoff.ms设置间隔
batch.size
多个消息发送到同一分区,生产者会把他们放在同一批次里。该参数指定一个批次可以使用的内存大小
max.request.size
控制生产者发送的请求大小,指定发送的单个消息的最大值,也可指定单个请求里所有消息的总大小
broker对可接收消息最大值也有自己的限制,message.max.size,两边最好匹配
发送消息到指定分区
- new ProducerRecord<>时用partiton参与构造
- 使用自定义分区器,重写partition方法自定义分区规则,返回

 浙公网安备 33010602011771号
浙公网安备 33010602011771号