kfaka概述及linux下使用
定义
分布式的基于发布订阅模式的消息队列,主要用于大数据实时处理
- 点对点模式:一对一,消费者主动拉取数据,消息收到后消息删除
- 发布订阅:一对多
- 消费者拉取数据,缺点:队列中没有消息,也会拉取,长轮询
- 队列推送数据,缺点:各个消费者消费速度不一样, 有的消费能力不足崩了,有的资源浪费
特性
- 高吞吐量,低延迟:每秒几十万,延迟几毫秒,每个主题多个分区,消费者对分区进行消费
- 可扩展性:kafaka支持热扩展
- 持久性,可靠性:消息持久化到磁盘,支持数据备份防止数据丢失
- 容错性:允许集群中节点失败
- 高并发:支持数千客户端同时读写
使用场景
- 日志收集
- 消息系统
- 用户活动跟踪
- 运营指标
- 流式处理
技术优势
- 可伸缩性
- 容错性和可靠性
- 吞吐量
基础架构,概念
-
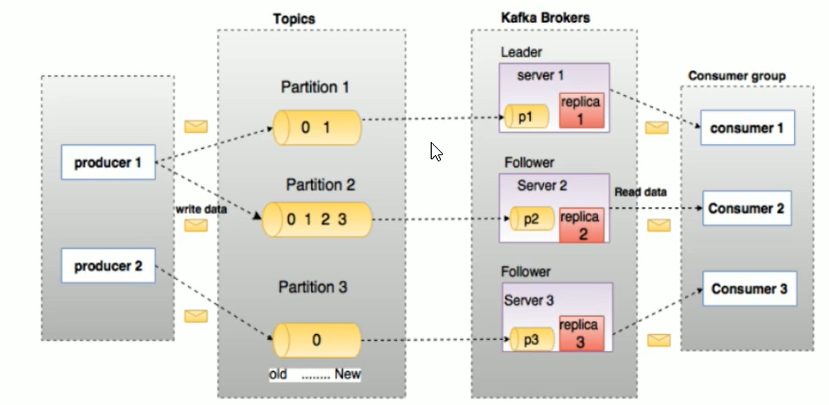
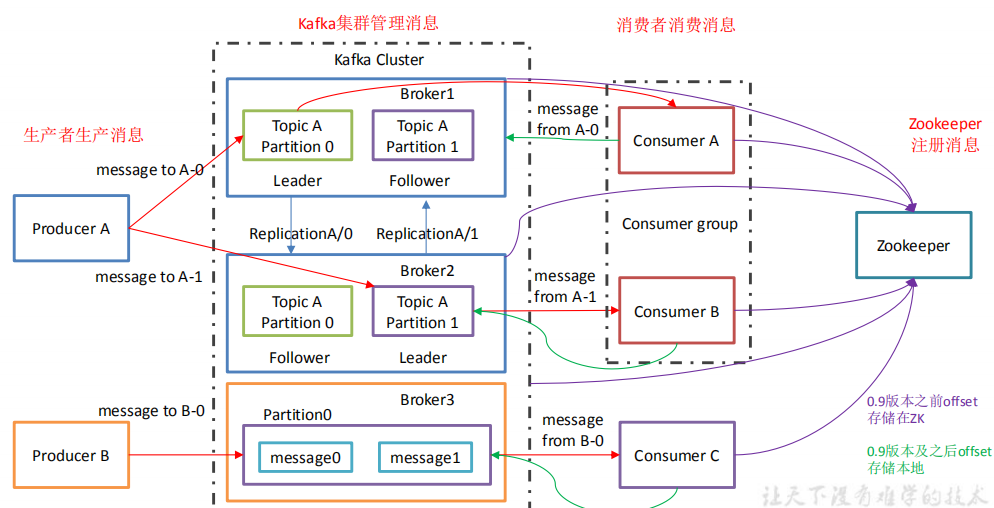
**Producer **:消息生产者,就是向 kafka broker 发消息的客户端
-
Consumer :消息消费者,向 kafka broker 取消息的客户端
-
Consumer group:消费者组:
- 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费
- 消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者
-
Topic :可以理解为一个队列,生产者和消费者面向的都是一个 topic
-
Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic可分为多个partition,每个 partition 是一个有序的队列
-
Replica:副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失, 且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower
-
leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 leader。
-
follower:每个分区多个副本中的“从”,实时从 leader 中同步数据,保持和 leader 数据的同步。leader 发生故障时,某个 follower 会成为新的 follower。
一个topic多个partition(分区),每个partition有多个replica(副本),这些副本中包含一个leader和一个follower
AR(Assigned Replicas):分区中所有replica
ISR(In-Sync-Replicas):所有与leader副本同步的副本组成ISR
OSR(Out-of-Sync-Replicas):与leader副本不同步的副本组成OSR
HW(High Watermark):高水位,标识了一个特定的offset,消费者只能拉取到这个offset之前的消息
LEO(Log End Offset):如果LEO=10,表示该副本中保存了10条消息,位移值范围是[0,9]
安装与配置
jdk安装
-
oralce下载对应tar.gz文件,放到opt/java中 jdk-8u281-linux-x64.tar.gz
-
解压:tar -zxvf jdk-8u281-linux-aarch64.tar.gz
-
配置环境变量:修改etc/profile
export JAVA_HOME=/opt/java/jdk1.8.0_281
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.😒{JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH -
java -version 查看是否安装成功
Zookeeper安装
-
下载:apache-zookeeper-3.6.1-bin.tar.gz
-
解压:tar -zxcf apache-zookeeper-3.6.1-bin.tar.gz
-
cd opt/zookeeper/apache-zookeeper-3.6.1/conf
-
修改配置文件:mv zoo_sample.cfg zoo.cfg
-
vim zoo.cfg更改dataDir=/opt/zookeeper/apache-zookeeper-3.6.1/data
tickTime=2000 zk服务器的心跳时间
initLimit=10 投票 选举新leader的初始化时间
dataDir:数据目录
-
进入 bin ./zkServer.sh start 启动
停止:stop
重启:restart
查看状态:status
- 查看状态:./zkServer.sh status
- 查看进程:ps -ef | grep zookeeper
kafka安装
-
安装
-
tar -zxvf 解压
-
配置文件:conf/server.properties,把listeners注释打开,logs文件要新建
broker.id:broker编号,集群中多个broker,每个都要不同
listeners:broker对外提供服务的入口地址
log.dirs=/opt/kafka/kafka_2.13-2.7.0/logs:消息日志文件地址
zookeeper.connect:当前kfaka连接的zookeeper的服务地址
-
启动:bin下的./kafka-server-start.sh ../config/server.properties
在后台启动,新建start.sh,777权限,编辑
cd /opt/kafka/kafka_2.13-2.7.0/bin
sh kafka-server-start.sh -daemon ../config/server.properties
直接启动start.sh -
查看:重新打开一个终端 ps -ef | grep kafka或者jps -l
kafka测试 消息生成与消费
-
创建主题
-
bin目录:./kafka-topics.sh --zookeeper localhost:2181 --create --topic jpy --partitions 2 --replication-factor 1
连接本地zookeeper,创建名为jpy的主题,有两个分区, 当前分区1个副本
-
-
展示所有主题
- ./kafka-topics.sh --zookeeper localhost:2181 --list
-
查看主题详情
- ./kafka-topics.sh --zookeeper localhost:2181 --describe --topic jpy
-
启动消费端接收消息
-
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic jpy
kafka集群地址,要接收的topic
-
-
生产端发送消息
-
./kafka-console-producer.sh --broker-list localhost:9092 --topic jpy
向本地9092端口服务器jpy主题发消息
-
注意
在windows上向linux的kafka上发消息,conf/server.properties里
添加host.name=linux服务器地址,
修改listeners=PLAINTEXT://linux服务器地址:9092

 浙公网安备 33010602011771号
浙公网安备 33010602011771号