

Hadoop与Hadoop集群介绍
1、什么是Hadoop
狭义上Hadoop指的是Apache软件基金会的一款开源软件。用java语言实现,开源。允许用户使用简单的编程模型实现跨机器集群对海量数据进行分布式计算处理
![]()
![]()
广义上Hadoop指的是围绕Hadoop打造的大数据生态圈。
2、Hadoop核心组件
Hadoop HDFS(分布式文件存储系统):解决海量数据存储
Hadoop YARN(集群资源管理和任务调度框架):解决资源任务调度
Hadoop MapReduce(分布式计算框架):解决海量数据计算
3、Hadoop现状
HDFS作为分布式文件存储系统,处在生态圈的底层与核心地位;
YARN作为分布式通用的集群资源管理系统和任务调度平台,支撑各种计算引擎运行,保证了Hadoop地位;
MapReduce作为大数据生态圈第一代分布式计算引擎,由于自身设计的模型所产生的弊端,导致企业一线几乎不再直接使用MapReduce进行编程处理,但是很多软件的底层依然在使用MapReduce引擎来处理数据。
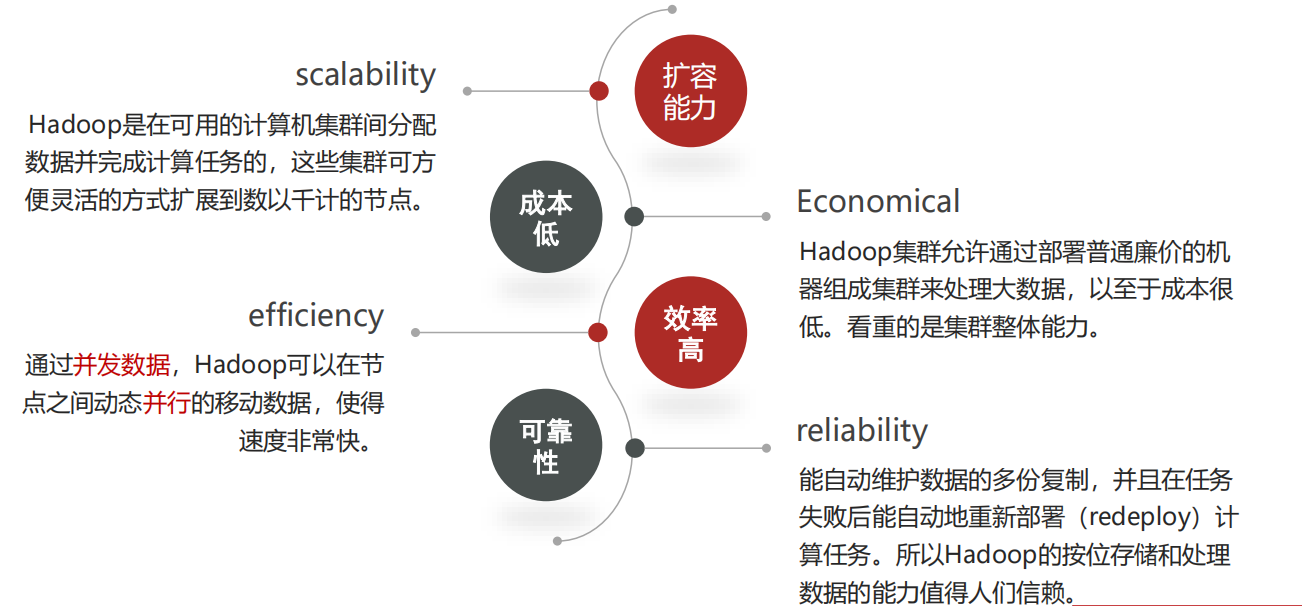
4、Hadoop特性优点
5、Hadoop架构变迁
Hadoop 1.0
HDFS(分布式文件存储)
MapReduce(资源管理和分布式数据处理)
Hadoop 2.0
HDFS(分布式文件存储)
MapReduce(分布式数据处理)
YARN(集群资源管理、任务调度)
Hadoop 3.0
架构组件和Hadoop 2.0类似,3.0着重于性能优化
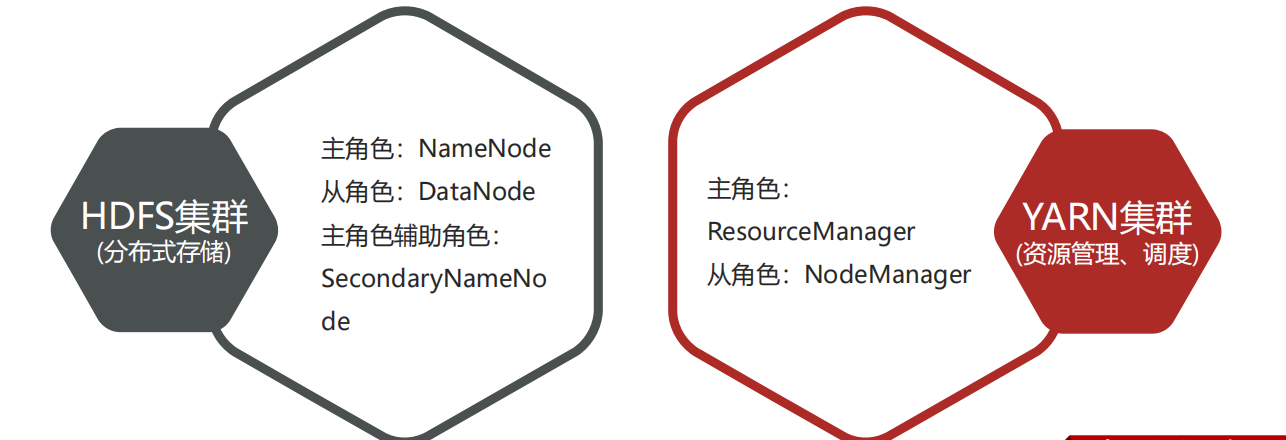
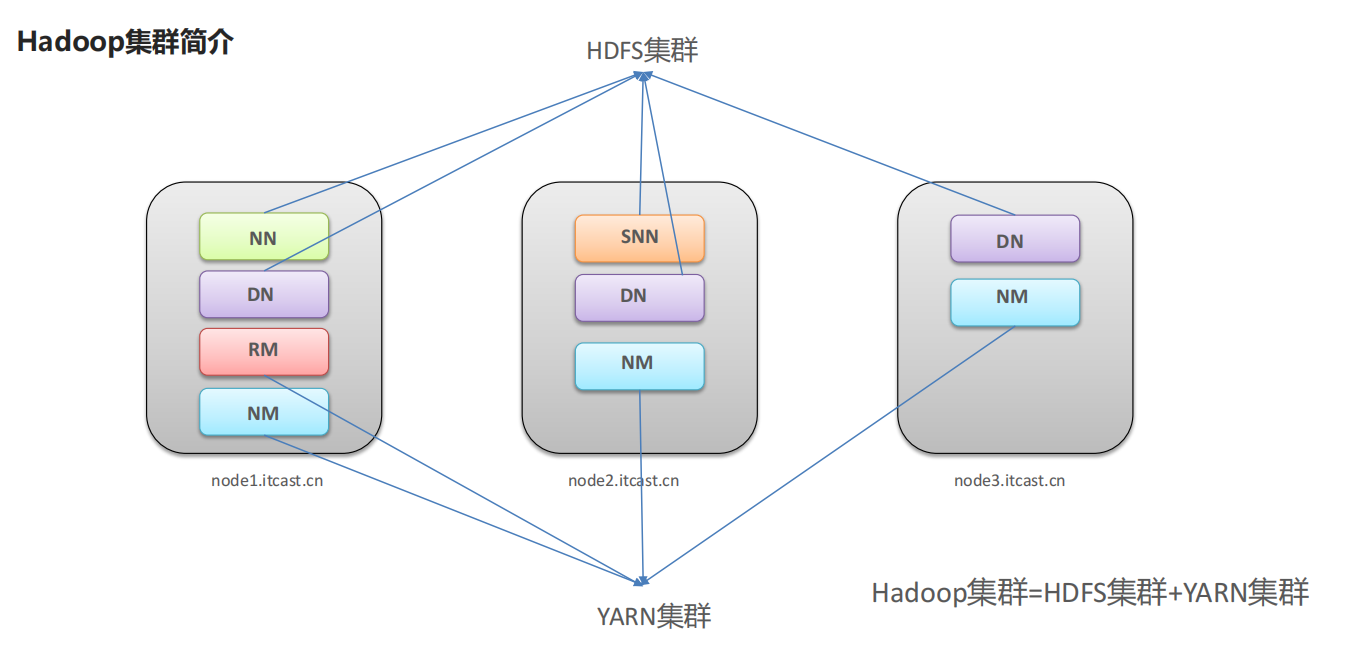
6、Hadoop集群整体概述
Hadoop集群包括两个集群:HDFS集群、YARN集群。而MapReduce是计算框架、代码层面的组件 没有集群之说
两个集群逻辑上分离、通常物理上在一起。逻辑上分离是指两个集群互相之间没有依赖、互不影响;物理上在一起是指某些角色进程往往部署在同一台物理服务器上
两个集群都是标准的主从架构集群
学习没有一蹴而就,放下急躁,一步一步扎实前进

 浙公网安备 33010602011771号
浙公网安备 33010602011771号