
JavaSE知识点总结
HashMap
hash的查找效率:O(1)
链表的查找效率:O(n)
红黑树的查找效率:O(log n)
基本属性
// 默认容量16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认负载因子0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 链表节点转换红黑树节点的阈值, 9个节点转
//(通常情况下,并没有必要转为红黑树,所以就选择了概率非常小,小于千万分之一概率,也就是长度为8的概率,把长度 8 作为转化的默认阈值。)
static final int TREEIFY_THRESHOLD = 8;
// 红黑树节点转换链表节点的阈值, 6个节点转
static final int UNTREEIFY_THRESHOLD = 6;
// 转红黑树时, table的最小长度
static final int MIN_TREEIFY_CAPACITY = 64;
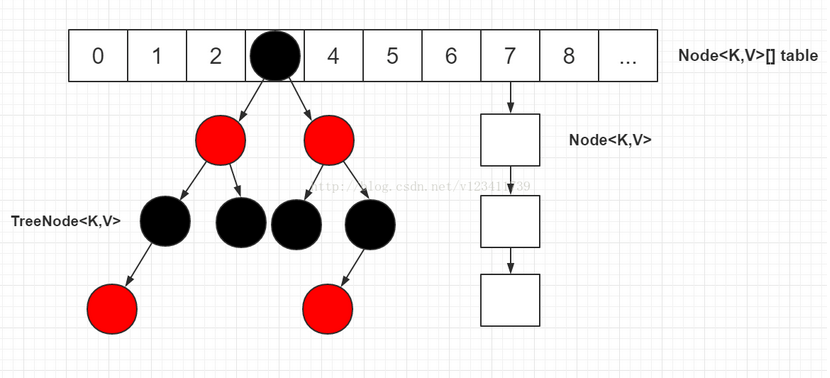
// 链表节点, 继承自Entry
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
// ... ...
}
// 红黑树节点
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
// ...
}
具体细节
https://blog.csdn.net/v123411739/article/details/78996181/
JDK1.7
数组+链表
头插法 ->多线程,循环链表
JDK1.8
数组+链表+红黑树
尾插法
总结
HashMap是我们在日常开发中几乎每天都要用到的集合类,它是以键值对的形式存储
在JDK1.7到JDK1.8之间,HashMap的实现略有区别,其中有两个比较重要的区别
一个是HashMap在JDK1.7之前采用的数据结构是数组+链表,但是在JDK1.8之后改成了数组+链表+红黑树
红黑树的引入是为了提高它的查询效率,因为链表的查询时间复杂度是O(n),而红黑树是O(log n )
还有一个是在JDK1.7之前,当我们遇到Hash碰撞,需要在链表上添加数据的时候采用的是头插法,而到了JDK1.8之后改用了尾插法
因为头插法在多线程的情况下会导致一些问题,比如说循环列表
当然,JDK1.7到JDK1.8之间还有其他许多优化的细节,比如Hash算法进行了简化等等
接下来,我就用JDK1.8来聊一聊基本的原理
首先,在创建HashMap的时候,阿里规约里面要求传入一个初始化容量,默认16,最好是一个2的次幂
当我们往HashMap中put第一个值的时候,数组才真正的被初始化
按照我们传入的容量,取大于大于这个容量的一个2的次幂,进行初始化数组
初始化之后,使用key的Hash值 与上 容量减一。因为容量都是2的次幂,减一后低位全是1,高位都是零,结果一定是一个在容量范围之内的下标
与运算结果与余运算相同,但是与运算在计算机中效率非常高
而在往其中添加数据时会产生两个问题,一个是扩容,一个是树化
关于扩容,HashMap有一个成员变量是加载因子默认是0.75,但节点数量大于等于容量乘以加载因子,就会进行扩容
在扩容之后,一个元素的新索引要么是在原位置,要么就是在原位置加上扩容前的容量
当我们链表上悬挂的节点足够多的时候还会进行树化,这两个但是很耗性能的操作,树化的前提是链表长度大于等于8,当然还有一个条件在HashMap的成员变量中,也就是最小数化容量为64
意思是数组容量达不到64会优先选择扩容,而不是树化
之前说的阿里规约里面要求传入一个初始化容量,根本目的就是在于减少扩容
而树化之后,随着数据的删除,红黑树节点减少为6时,又会变回到链表
HashMap和HashTable区别
1)线程安全性不同
HashMap是线程不安全的,HashTable是线程安全的,其中的方法是Synchronize的,在多线程并发的情况下,可以直接使用HashTabl,但是使用HashMap时必须自己增加同步处理。
2)是否提供contains方法
HashMap只有containsValue和containsKey方法;HashTable有contains、containsKey和containsValue三个方法,其中contains和containsValue方法功能相同。
3)key和value是否允许null值
Hashtable中,key和value都不允许出现null值。HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。
4)数组初始化和扩容机制
HashTable在不指定容量的情况下的默认容量为11,而HashMap为16,Hashtable不要求底层数组的容量一定要为2的整数次幂,而HashMap则要求一定为2的整数次幂。
Hashtable扩容时,将容量变为原来的2倍加1,而HashMap扩容时,将容量变为原来的2倍。
TreeSet和HashSet区别
HashSet是采用hash表来实现的。其中的元素没有按顺序排列,add()、remove()以及contains()等方法都是复杂度为O(1)的方法。
TreeSet是采用树结构实现(红黑树算法)。元素是按顺序进行排列,但是add()、remove()以及contains()等方法都是复杂度为O(log (n))的方法。它还提供了一些方法来处理排序的set,如first(),last(),headSet(),tailSet()等等。
String buffer和String build区别
1)StringBuffer与StringBuilder中的方法和功能完全是等价的。
2)只是StringBuffer中的方法大都采用了 synchronized 关键字进行修饰,因此是线程安全的,而StringBuilder没有这个修饰,可以被认为是线程不安全的。
3)在单线程程序下,StringBuilder效率更快,因为它不需要加锁,不具备多线程安全而StringBuffer则每次都需要判断锁,效率相对更低
Final、Finally、Finalize
final:修饰符(关键字)有三种用法:修饰类、变量和方法。修饰类时,意味着它不能再派生出新的子类,即不能被继承,因此它和abstract是反义词。修饰变量时,该变量使用中不被改变,必须在声明时给定初值,在引用中只能读取不可修改,即为常量。修饰方法时,也同样只能使用,不能在子类中被重写。
finally:通常放在try…catch的后面构造最终执行代码块,这就意味着程序无论正常执行还是发生异常,这里的代码只要JVM不关闭都能执行,可以将释放外部资源的代码写在finally块中。
finalize:Object类中定义的方法,Java中允许使用finalize() 方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。这个方法是由垃圾收集器在销毁对象时调用的,通过重写finalize() 方法可以整理系统资源或者执行其他清理工作。
==和Equals区别
== : 如果比较的是基本数据类型,那么比较的是变量的值
如果比较的是引用数据类型,那么比较的是地址值(两个对象是否指向同一块内存)
equals:如果没重写equals方法比较的是两个对象的地址值。
如果重写了equals方法后我们往往比较的是对象中的属性的内容
equals方法是从Object类中继承的,默认的实现就是使用==
Java自带哪几种线程池
1)newCachedThreadPool
创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。这种类型的线程池特点是:
工作线程的创建数量几乎没有限制(其实也有限制的,数目为Interger. MAX_VALUE), 这样可灵活的往线程池中添加线程。
如果长时间没有往线程池中提交任务,即如果工作线程空闲了指定的时间(默认为1分钟),则该工作线程将自动终止。终止后,如果你又提交了新的任务,则线程池重新创建一个工作线程。
在使用CachedThreadPool时,一定要注意控制任务的数量,否则,由于大量线程同时运行,很有会造成系统瘫痪。
2)newFixedThreadPool
创建一个指定工作线程数量的线程池。每当提交一个任务就创建一个工作线程,如果工作线程数量达到线程池初始的最大数,则将提交的任务存入到池队列中。FixedThreadPool是一个典型且优秀的线程池,它具有线程池提高程序效率和节省创建线程时所耗的开销的优点。但是,在线程池空闲时,即线程池中没有可运行任务时,它不会释放工作线程,还会占用一定的系统资源。
3)newSingleThreadExecutor
创建一个单线程化的Executor,即只创建唯一的工作者线程来执行任务,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。如果这个线程异常结束,会有另一个取代它,保证顺序执行。单工作线程最大的特点是可保证顺序地执行各个任务,并且在任意给定的时间不会有多个线程是活动的。
4)newScheduleThreadPool
创建一个定长的线程池,而且支持定时的以及周期性的任务执行,支持定时及周期性任务执行。延迟3秒执行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号