
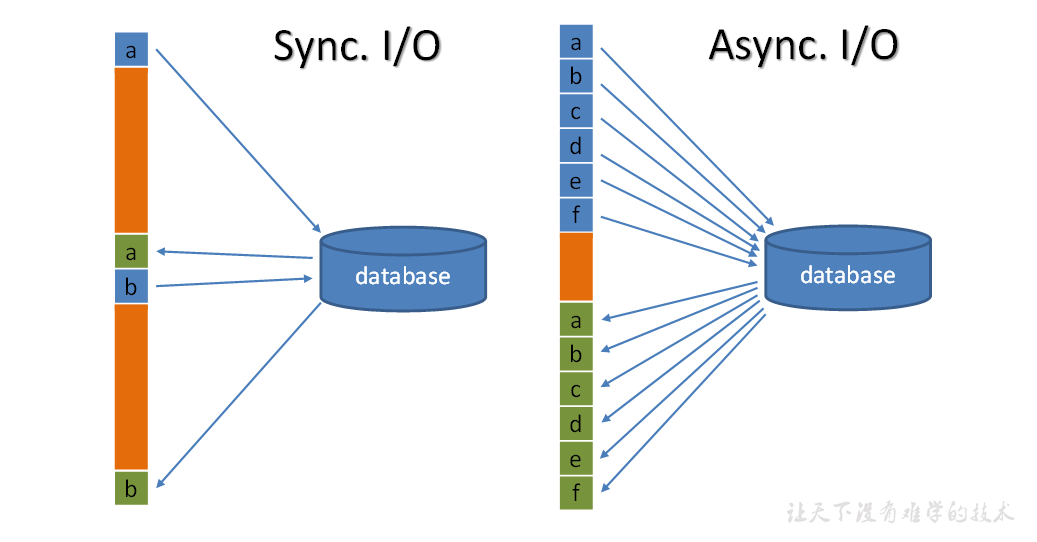
Flink实时数仓
总体架构
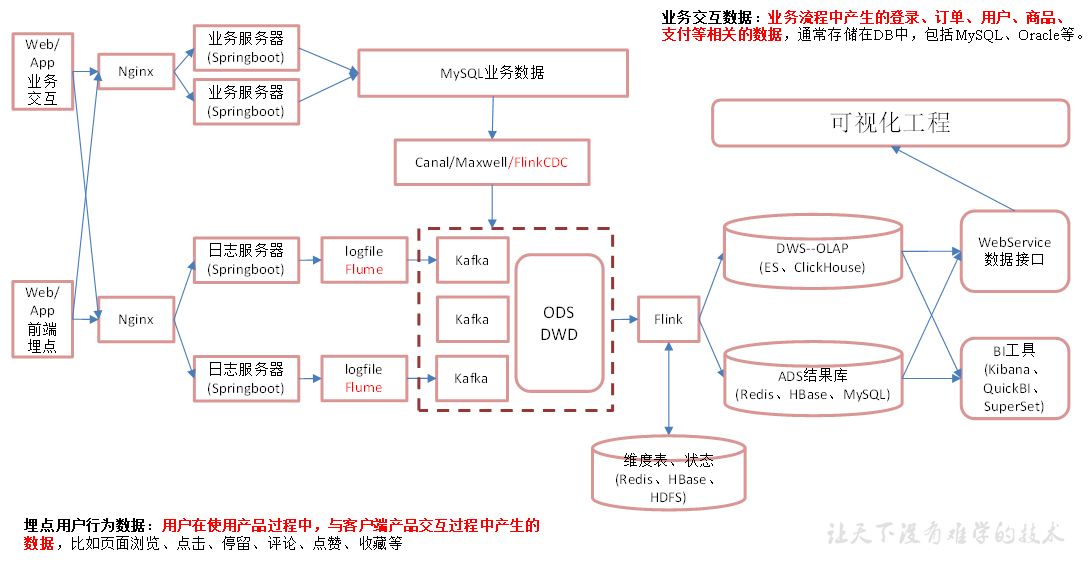
业务数据采集平台
不同点:
1)使用Maxwell同步所有表,不需要过滤
2)将所有表同步到一个Kafka Topic
注意:若离线数仓想要使用同一套采集平台,需要在Flume时间戳拦截器中补充表名,从而导入到不同的HDFS目录中
数据仓库
ODS
采集到 Kafka 的 topic_log 和 topic_db 主题的数据即为实时数仓的 ODS 层,这一层的作用是对数据做原样展示和备份。
DIM
DIM层设计要点
(1)DIM层的设计依据是维度建模理论,该层存储维度模型的维度表。
(2)DIM层的数据存储在 HBase 表中
DIM 层表是用于维度关联的,要通过主键去获取相关维度信息,这种场景下 K-V 类型数据库的效率较高。常见的 K-V 类型数据库有 Redis、HBase,而 Redis 的数据常驻内存,会给内存造成较大压力,因而选用 HBase 存储维度数据。
(3)DIM层表名的命名规范为dim_表名
DIM层主要任务
(1)接收Kafka数据,过滤空值数据
(2)动态拆分维度表功能
(3)把流中的数据保存到对应的维度表
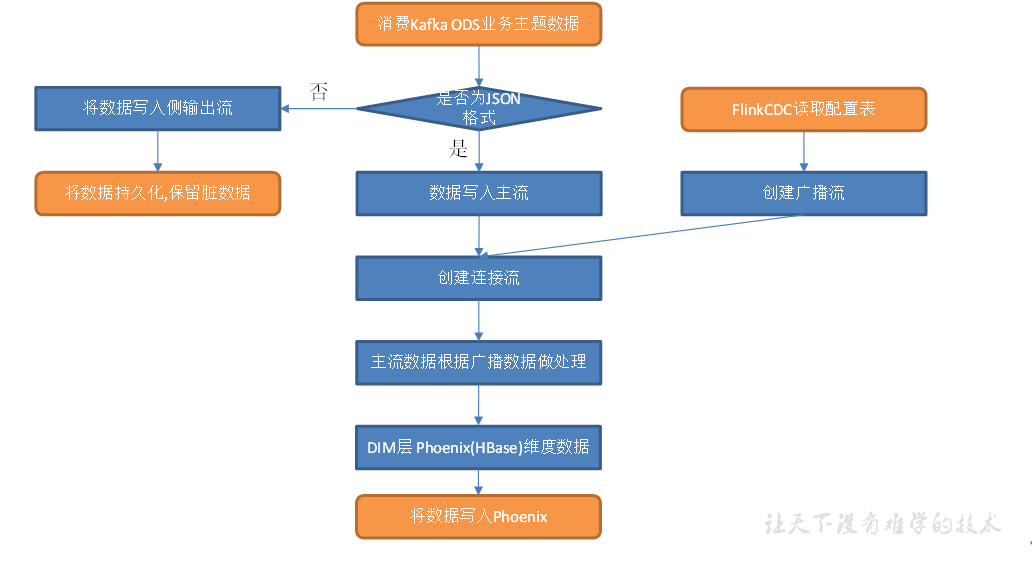
接收Kafka数据,过滤空值数据
对Maxwell抓取的数据进行ETL,有用的部分保留,没用的过滤掉。
(1)编写Kafka工具类
public class MyKafkaUtil { public static FlinkKafkaConsumer<String> getKafkaConsumer(String topic, String group_id){ Properties properties = new Properties(); properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092"); properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, group_id); return new FlinkKafkaConsumer<String>(topic, new KafkaDeserializationSchema<String>() { @Override public boolean isEndOfStream(String s) { return false; } @Override public String deserialize(ConsumerRecord<byte[], byte[]> record) throws Exception { if(record == null || record.value() == null){ return ""; }else{ return new String(record.value()); } } @Override public TypeInformation<String> getProducedType() { return BasicTypeInfo.STRING_TYPE_INFO; } }, properties); } }
注意:不使用new SimpleStringSchema(),因为遇到空数据会报错
(2)读取数据,转换为JSON数据流,脏数据写入到侧输出流
//TODO 获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1);//Kafka主题分区数 env.setStateBackend(new HashMapStateBackend());//状态后端设置 env.enableCheckpointing(5000L); env.getCheckpointConfig().setCheckpointTimeout(10000L); env.getCheckpointConfig().setCheckpointStorage("hdfs:hadoop102:8020//checkpoint"); //TODO 读取Kafka topic_db 主题创建流 DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtil.getKafkaConsumer("topic_db", "dim_app")); //TODO 过滤非JSON数据,写入侧输出流 OutputTag<String> dirtyDataTag = new OutputTag<String>("Dirty") {}; SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.process(new ProcessFunction<String, JSONObject>() { @Override public void processElement(String s, Context context, Collector<JSONObject> collector) throws Exception { try { JSONObject jsonObject = JSON.parseObject(s); collector.collect(jsonObject); } catch (Exception e) { context.output(dirtyDataTag, s); } } }); //取出脏数据 DataStream<String> sideOutput = jsonObjDS.getSideOutput(dirtyDataTag); sideOutput.print("Dirty>");
动态拆分维度表功能
动态配置方案:
MySQL + 定时任务 + JDBC
MySQL + FlinkCDC
File + Flume + Kafka + FlinkKafkaConsumer
Zookeeper + Watch
这里选择MySQL + FlinkCDC,主要是MySQL对于配置数据初始化和维护管理,使用FlinkCDC读取配置信息表,将配置流作为广播流与主流进行connect(也可以keyby+connect,但是存在数据倾斜问题)
(1)创建MySQL建配置表,创建对应实体类
@Data public class TableProcess { //来源表 String sourceTable; //输出表 String sinkTable; //输出字段 String sinkColumns; //主键字段 String sinkPk; //建表扩展 String sinkExtend; }
(2)FlinkCDC读取配置表,处理为广播流,连接主流与广播流
//TODO 使用FlinkCDC读取MySQL中的配置信息 MySqlSource<String> mySqlSource = MySqlSource.<String>builder() .hostname("hadoop102") .port(3306) .username("root") .password("000000") .databaseList("gmall-config") .tableList("gmall-config.table_process") .deserializer(new JsonDebeziumDeserializationSchema()) .startupOptions(StartupOptions.initial()) .build(); DataStreamSource<String> mysqlSourceDS = env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MysqlSource"); //TODO 将配置信息流处理成广播流 //而下游子任务收到广播出来的规则,会把它保存成一个状态,这就是所谓的“广播状态”(broadcast state) MapStateDescriptor<String, TableProcess> mapStateDescriptor = new MapStateDescriptor<>("map-state", String.class, TableProcess.class); BroadcastStream<String> broadcastStream = mysqlSourceDS.broadcast(mapStateDescriptor)
//TODO 连接主流与广播流
BroadcastConnectedStream<JSONObject, String> connectedStream = jsonObjDS.connect(broadcastStream);
(3)根据广播流处理主流
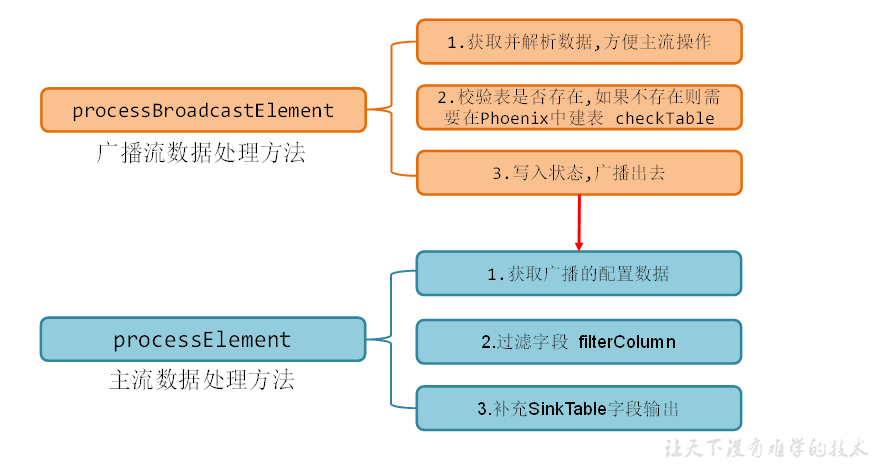
SingleOutputStreamOperator<JSONObject> hbaseDS = connectedStream.process(new TableProcessFunction(mapStateDescriptor));
自定义类TableProcessFunction
public class TableProcessFunction extends BroadcastProcessFunction<JSONObject, String, JSONObject> { private Connection connection; MapStateDescriptor<String, TableProcess> mapStateDescriptor; public TableProcessFunction(MapStateDescriptor<String, TableProcess> mapStateDescriptor) { this.mapStateDescriptor = mapStateDescriptor; } @Override public void open(Configuration parameters) throws Exception { connection = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER); } //处理广播流 @Override public void processBroadcastElement(String value, Context ctx, Collector<JSONObject> collector) throws Exception { //获取并解析数据为JavaBean对象 JSONObject jsonObject = JSON.parseObject(value); TableProcess tableProcess = JSON.parseObject(jsonObject.getString("after"), TableProcess.class); //校验表是否存在,不存在建表 checkTable( tableProcess.getSinkTable(), tableProcess.getSinkColumns(), tableProcess.getSinkPk(), tableProcess.getSinkExtend() ); //将数据写入状态 String key = tableProcess.getSourceTable(); BroadcastState<String, TableProcess> broadcastState = ctx.getBroadcastState(mapStateDescriptor); broadcastState.put(key,tableProcess); } //建表 private void checkTable(String sinkTable, String sinkColumns, String sinkPk, String sinkExtend) { PreparedStatement preparedStatement = null; try { if(sinkPk == null || sinkPk.equals("")){ sinkPk = "id"; } if(sinkExtend == null){ sinkExtend = ""; } StringBuilder sql = new StringBuilder("create table if not exists ") .append(GmallConfig.HBASE_SCHEMA) .append(".") .append(sinkTable) .append("("); String[] columns = sinkColumns.split(","); for (int i = 0; i < columns.length; i++) { String column = columns[i]; if (sinkPk.equals(column)){ sql.append(column).append(" varchar primary key"); }else { sql.append(column).append(" varchar"); } if(i < columns.length - 1){ sql.append(","); } } sql.append(")").append(sinkExtend); preparedStatement = connection.prepareStatement(sql.toString()); preparedStatement.execute(); }catch (SQLException e){ throw new RuntimeException("建表" + sinkTable + "失败"); }finally { if(preparedStatement != null){ try { preparedStatement.close(); } catch (SQLException e) { e.printStackTrace(); } } } } //处理主流 @Override public void processElement(JSONObject value, ReadOnlyContext ctx, Collector<JSONObject> out) throws Exception { //获取广播配置信息 ReadOnlyBroadcastState<String, TableProcess> broadcastState = ctx.getBroadcastState(mapStateDescriptor); TableProcess tableProcess = broadcastState.get(value.getString("table")); String type = value.getString("type"); if(tableProcess != null && ("bootstrap-insert".equals(type) || "insert".equals(type) || "update".equals(type))){ //根据配置信息过滤字段 filter(value.getJSONObject("data"), tableProcess.getSinkColumns()); //补充sinkTable字段写出 value.put("sinkTable", tableProcess.getSinkTable()); out.collect(value); }else{ System.out.println("过滤数据:" + value); } } //根据配置信息过滤字段 private void filter(JSONObject data, String sinkColumns) { String[] split = sinkColumns.split(","); List<String> columnsList = Arrays.asList(split); Iterator<Map.Entry<String, Object>> iterator = data.entrySet().iterator(); while (iterator.hasNext()){ Map.Entry<String, Object> next = iterator.next(); if(!columnsList.contains(next.getKey())){ iterator.remove(); } } } }
把流中的数据保存到对应的维度表
维度数据保存到HBase的表中
//TODO 将数据写出到Phoenix hbaseDS.addSink(new DimSinkFunction()); //TODO 启动任务 env.execute("DimApp");
自定义类DimSinkFunction
public class DimSinkFunction extends RichSinkFunction<JSONObject> { private Connection connection; @Override public void open(Configuration parameters) throws Exception { connection = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER); } @Override public void invoke(JSONObject value, Context context) throws Exception { PreparedStatement preparedStatement = null; try { String sql = genUpsertSql(value.getString("sinkTable"), value.getJSONObject("data")); preparedStatement = connection.prepareStatement(sql); preparedStatement.execute(); connection.commit(); } catch (SQLException e) { System.out.println("插入数据失败"); } finally { if(preparedStatement != null){ preparedStatement.close(); } } } private String genUpsertSql(String sinkTable, JSONObject data) { Set<String> columns = data.keySet(); Collection<Object> values = data.values(); return "upsert into " + GmallConfig.HBASE_SCHEMA + "." + sinkTable + "(" + StringUtils.join(columns,",") + ") values ('" + StringUtils.join(values,"','") + "')"; } }
DWD
DWD层设计要点
(1)DWD层的设计依据是维度建模理论,该层存储维度模型的事实表。
(2)DWD层表名的命名规范为dwd_数据域_表名
流量域未经加工的事务事实表
主要任务
1)数据清洗(ETL)
2)新老访客状态标记修复
3)分流
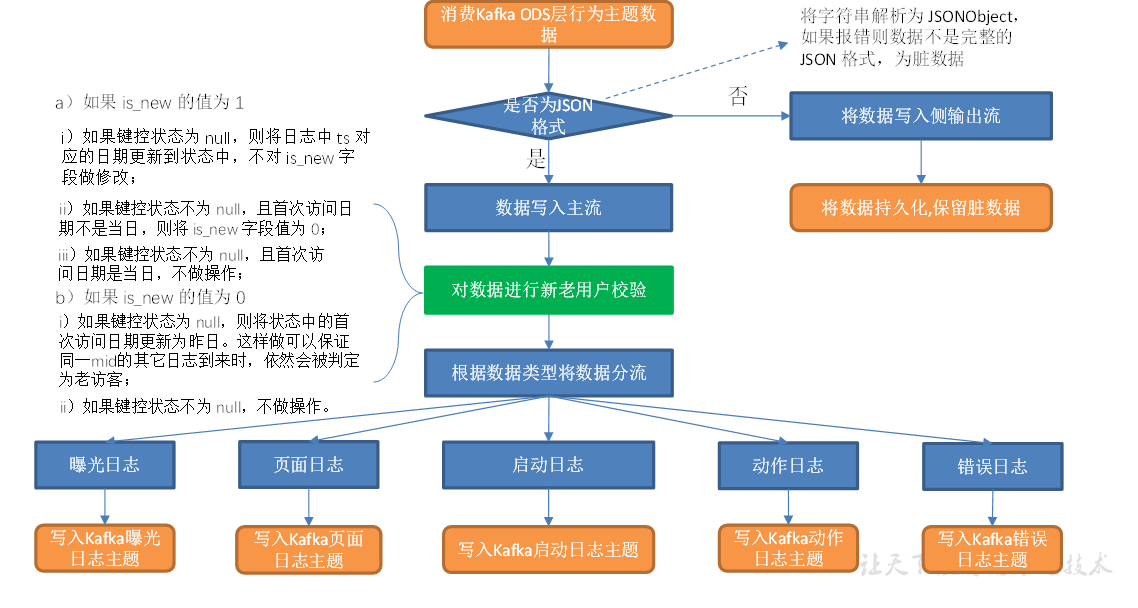
数据清洗
//TODO 获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1);//Kafka主题分区数 env.setStateBackend(new HashMapStateBackend()); env.enableCheckpointing(5000L); env.getCheckpointConfig().setCheckpointTimeout(10000L); env.getCheckpointConfig().setCheckpointStorage("hdfs:hadoop102:8020//checkpoint"); //TODO 读取kafka topic_log 主题数据创建流 DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtil.getKafkaConsumer("topic_log", "base_log_app")); //TODO 将数据转换为JSON格式,并过滤非JSON格式数据 OutputTag<String> dirtyTag = new OutputTag<String>("Dirty"){}; SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.process(new ProcessFunction<String, JSONObject>() { @Override public void processElement(String value, Context ctx, Collector<JSONObject> out) throws Exception { try { JSONObject jsonObject = JSON.parseObject(value); out.collect(jsonObject); } catch (Exception e) { ctx.output(dirtyTag, value); } } }); DataStream<String> dirtyDS = jsonObjDS.getSideOutput(dirtyTag); dirtyDS.print("Dirty>");
新老访客状态标记修复
1)日期格式化工具类
public class DateFormatUtil { private static final DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy-MM-dd"); private static final DateTimeFormatter dtfFull = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"); public static Long toTs(String dtStr, boolean isFull) { LocalDateTime localDateTime = null; if (!isFull) { dtStr = dtStr + " 00:00:00"; } localDateTime = LocalDateTime.parse(dtStr, dtfFull); return localDateTime.toInstant(ZoneOffset.of("+8")).toEpochMilli(); } public static Long toTs(String dtStr) { return toTs(dtStr, false); } public static String toDate(Long ts) { Date dt = new Date(ts); LocalDateTime localDateTime = LocalDateTime.ofInstant(dt.toInstant(), ZoneId.systemDefault()); return dtf.format(localDateTime); } public static String toYmdHms(Long ts) { Date dt = new Date(ts); LocalDateTime localDateTime = LocalDateTime.ofInstant(dt.toInstant(), ZoneId.systemDefault()); return dtfFull.format(localDateTime); } public static void main(String[] args) { System.out.println(toYmdHms(System.currentTimeMillis())); } }
注意:不用SimpleDateFormat是因为format()有线程安全问题
(2)处理状态编程做新老用户校验
//TODO 使用状态编程做新老用户校验 KeyedStream<JSONObject, String> keyedByMidStream = jsonObjDS.keyBy(jsonObject -> jsonObject.getJSONObject("common").getString("mid")); SingleOutputStreamOperator<JSONObject> jsonObjWithNewFlagDS = keyedByMidStream.map(new RichMapFunction<JSONObject, JSONObject>() { private ValueState<String> lastVisitDtState; @Override public void open(Configuration parameters) throws Exception { lastVisitDtState = getRuntimeContext().getState(new ValueStateDescriptor<String>("last-visit", String.class)); } @Override public JSONObject map(JSONObject value) throws Exception { String isNew = value.getJSONObject("common").getString("is_new"); String lastVisitDt = lastVisitDtState.value(); Long ts = value.getLong("ts"); if ("1".equals(isNew)) { String curDt = DateFormatUtil.toDate(ts); if (lastVisitDt == null) { lastVisitDtState.update(curDt); } else if (!lastVisitDt.equals(curDt)) { value.getJSONObject("common").put("is_new", "0"); } } else if (lastVisitDt == null) { String yesterday = DateFormatUtil.toDate(ts - 24 * 60 * 60 * 1000L); lastVisitDtState.update(yesterday); } return value; } });
注意:状态的访问需要获取运行时上下文,只能在富函数类(Rich Function)中获取到
分流
数据量大分流,数据量小直接过滤取数据
(1)使用侧输出流对数据进行分流
//TODO 使用侧输出流对数据进行分流
OutputTag<String> startTag = new OutputTag<String>("start"){}; OutputTag<String> displayTag = new OutputTag<String>("display"){}; OutputTag<String> actionTag = new OutputTag<String>("action"){}; OutputTag<String> errorTag = new OutputTag<String>("error"){}; SingleOutputStreamOperator<String> pageDS = jsonObjWithNewFlagDS.process(new ProcessFunction<JSONObject, String>() { @Override public void processElement(JSONObject value, Context ctx, Collector<String> out) throws Exception { String jsonString = value.toJSONString(); String error = value.getString("err"); if (error != null) { ctx.output(errorTag, jsonString); } String start = value.getString("start"); if (start != null) { ctx.output(startTag, jsonString); } else { String pageId = value.getJSONObject("page").getString("page_id"); Long ts = value.getLong("ts"); String common = value.getString("common"); JSONArray displays = value.getJSONArray("displays"); if (displays != null && displays.size() > 0) { for (int i = 0; i < displays.size(); i++) { JSONObject display = displays.getJSONObject(i); display.put("page_id", pageId); display.put("ts", ts); display.put("common", common); ctx.output(displayTag, display.toJSONString()); } } JSONArray actions = value.getJSONArray("actions"); if (actions != null && actions.size() > 0) { for (int i = 0; i < actions.size(); i++) { JSONObject action = actions.getJSONObject(i); action.put("page_id", pageId); action.put("ts", ts); action.put("common", common); ctx.output(actionTag, action.toJSONString()); } } value.remove("displays"); value.remove("action"); out.collect(value.toJSONString()); } } });
注意:为什么输出标签要加{}? 使用匿名实现类对象,防止泛型擦除
(2)修改Kafka工具类
public class MyKafkaUtil { private static Properties properties = new Properties(); static { properties.setProperty(CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092"); } public static FlinkKafkaConsumer<String> getKafkaConsumer(String topic, String group_id){ properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, group_id); return new FlinkKafkaConsumer<String>(topic, new KafkaDeserializationSchema<String>() { @Override public boolean isEndOfStream(String s) { return false; } @Override public String deserialize(ConsumerRecord<byte[], byte[]> record) throws Exception { if(record == null || record.value() == null){ return ""; }else{ return new String(record.value()); } } @Override public TypeInformation<String> getProducedType() { return BasicTypeInfo.STRING_TYPE_INFO; } }, properties); } public static FlinkKafkaProducer<String> getKafkaProducer(String topic){ return new FlinkKafkaProducer<String>(topic, new SimpleStringSchema(), properties ); } }
(3)提取各个流,写出Kafka
//TODO 提取各个流的数据 DataStream<String> startDS = pageDS.getSideOutput(startTag); DataStream<String> errorDS = pageDS.getSideOutput(errorTag); DataStream<String> displayDS = pageDS.getSideOutput(displayTag); DataStream<String> actionDS = pageDS.getSideOutput(actionTag); //TODO 写出到Kafka String page_topic = "dwd_traffic_page_log"; String start_topic = "dwd_traffic_start_log"; String display_topic = "dwd_traffic_display_log"; String action_topic = "dwd_traffic_action_log"; String error_topic = "dwd_traffic_error_log"; pageDS.addSink(MyKafkaUtil.getKafkaProducer(page_topic)); startDS.addSink(MyKafkaUtil.getKafkaProducer(start_topic)); errorDS.addSink(MyKafkaUtil.getKafkaProducer(error_topic)); displayDS.addSink(MyKafkaUtil.getKafkaProducer(display_topic)); actionDS.addSink(MyKafkaUtil.getKafkaProducer(action_topic)); //TODO 启动 env.execute("BaseLogApp");
流量域独立访客事务事实表
主要任务
1)过滤 last_page_id 不为 null 的数据
2)筛选独立访客记录
3)状态存活时间设置
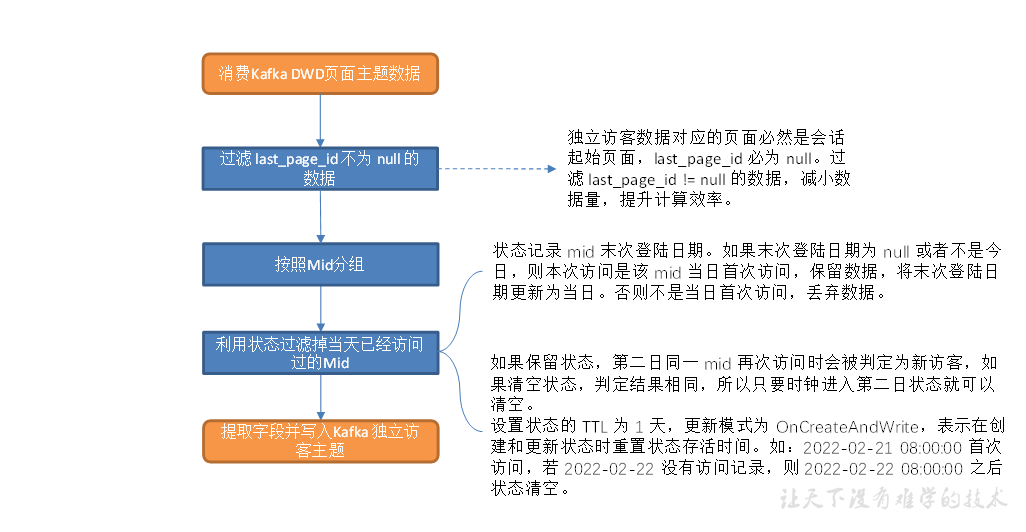
过滤 last_page_id 不为 null 的数据
独立访客数据对应的页面必然是会话起始页面,last_page_id 必为 null。过滤 last_page_id != null 的数据,减小数据量,提升计算效率。
//TODO 获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1);//Kafka主题分区数 env.setStateBackend(new HashMapStateBackend()); env.enableCheckpointing(5000L); env.getCheckpointConfig().setCheckpointTimeout(10000L); env.getCheckpointConfig().setCheckpointStorage("hdfs:hadoop102:8020//checkpoint"); //TODO 读取 Kafka dwd_traffic_page_log 主题数据创建流 String sourceTopic = "dwd_traffic_page_log"; String groupId = "dwd_traffic_unique_visitor_detail"; DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtil.getKafkaConsumer(sourceTopic, groupId)); //TODO 将每行数据转换为JSON对象 SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.map(line -> JSON.parseObject(line)); //TODO 过滤掉上一跳页面id不等于null的数据 SingleOutputStreamOperator<JSONObject> filterDS = jsonObjDS.filter(new FilterFunction<JSONObject>() { @Override public boolean filter(JSONObject value) throws Exception { return value.getJSONObject("page").getString("last_page_id") == null; } });
筛选独立访客记录
如果末次登录日期为 null 或者不是今日,则本次访问是该 mid 当日首次访问,保留数据,将末次登录日期更新为当日。否则不是当日首次访问,丢弃数据。
//TODO 按照mid分组 KeyedStream<JSONObject, String> keyedByMidStream = filterDS.keyBy(json -> json.getJSONObject("common").getString("mid")); //TODO 使用状态编程进行每日登录数据去重 SingleOutputStreamOperator<JSONObject> uvDetailDS = keyedByMidStream.filter(new RichFilterFunction<JSONObject>() { private ValueState<String> visitDtState; @Override public void open(Configuration parameters) throws Exception { ValueStateDescriptor<String> stringValueStateDescriptor = new ValueStateDescriptor<>("visit-dt", String.class); visitDtState = getRuntimeContext().getState(stringValueStateDescriptor); } @Override public boolean filter(JSONObject value) throws Exception { String dt = visitDtState.value(); String curDt = DateFormatUtil.toDate(value.getLong("ts")); if (dt == null || !dt.equals(curDt)) { visitDtState.update(curDt); return true; } else { return false; } } }); //TODO 将数据写出到Kafka String targetTopic = "dwd_traffic_unique_visitor_detail"; FlinkKafkaProducer<String> kafkaProducer = MyKafkaUtil.getKafkaProducer(targetTopic); uvDetailDS.map(JSONAware::toJSONString).addSink(kafkaProducer); //TODO 启动任务 env.execute("DwdTrafficUniqueVisitorDetail");
状态存活时间设置
当天状态只对当天数据起到去重作用,第二天应该及时清理掉
方案一:定时器零点清理,需要使用process
方案二:设置状态的 TTL 为 1 天,存在问题:4-1 9:00来了一条数据保留,4-2 8:00来了一条数据保留,4-2 9:00清空状态,4-2 10:00来了一条数据保留
方案三:设置状态的 TTL 为 1 天,更新模式为 OnCreateAndWrite,表示在创建和更新状态时重置状态存活时间。
@Override public void open(Configuration parameters) throws Exception { ValueStateDescriptor<String> stringValueStateDescriptor = new ValueStateDescriptor<>("visit-dt", String.class); StateTtlConfig stateTtlConfig = new StateTtlConfig.Builder(Time.days(1)) .setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite) .build(); stringValueStateDescriptor.enableTimeToLive(stateTtlConfig); visitDtState = getRuntimeContext().getState(stringValueStateDescriptor); }
流量域用户跳出事务事实表
跳出是指会话中只有一个页面的访问行为,如果能获取会话的所有页面,只要筛选页面数为 1 的会话即可获取跳出明细数据。
(1)离线数仓中我们可以获取一整天的数据,结合访问时间、page_id 和 last_page_id 字段对整体数据集做处理可以按照会话对页面日志进行划分,从而获得每个会话的页面数,只要筛选页面数为 1 的会话即可提取跳出明细数据;
(2)实时计算中无法考虑整体数据集,很难按照会话对页面访问记录进行划分。而本项目模拟生成的日志数据中没有 session_id(会话id)字段,也无法通过按照 session_id 分组的方式计算每个会话的页面数。
解决方案:
(1)会话窗口:短时间连续跳出,存在误差
(2)状态编程 + 定时器:乱序数据,存在误差
(3)状态编程 + 会话开窗:实现复杂,可以直接使用FlinkCEP代替
(4)FlinkCEP
主要任务
(1)消费数据按照mid分组
(2)形成规则流
(3)提取两条流,合并输出
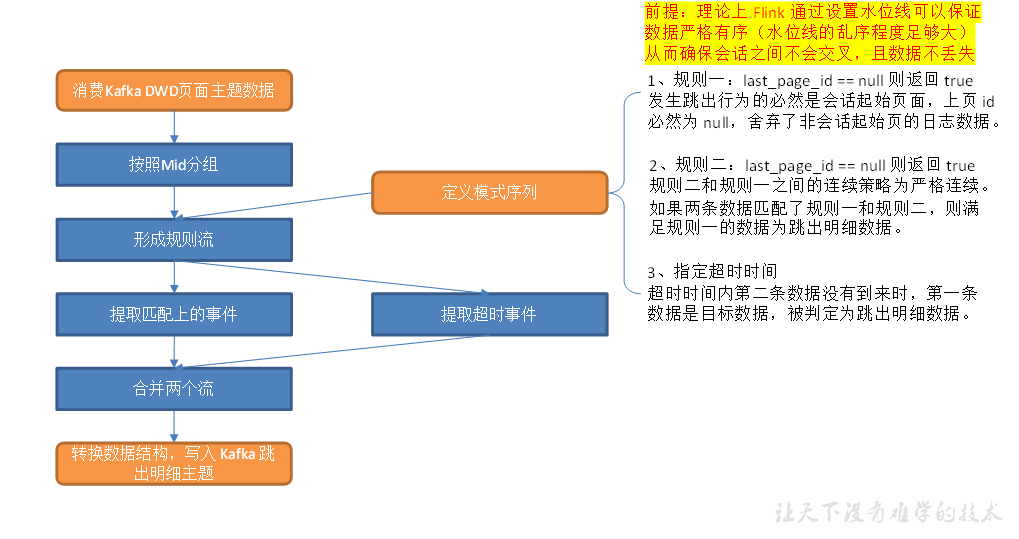
消费数据按照mid分组
//TODO 获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1);//Kafka主题分区数 env.setStateBackend(new HashMapStateBackend()); env.enableCheckpointing(5000L); env.getCheckpointConfig().setCheckpointTimeout(10000L); env.getCheckpointConfig().setCheckpointStorage("hdfs:hadoop102:8020//checkpoint"); //TODO 读取 Kafka dwd_traffic_page_log 主题数据创建流 String sourceTopic = "dwd_traffic_page_log"; String groupId = "dwd_traffic_user_jump_detail"; DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtil.getKafkaConsumer(sourceTopic, groupId)); //TODO 将数据转换为JSON对象 SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.map(JSON::parseObject); //TODO 提取事件时间生成WaterMark SingleOutputStreamOperator<JSONObject> jsonObjWithWmDS = jsonObjDS.assignTimestampsAndWatermarks(WatermarkStrategy.<JSONObject>forBoundedOutOfOrderness(Duration.ofSeconds(2)) .withTimestampAssigner(new SerializableTimestampAssigner<JSONObject>() { @Override public long extractTimestamp(JSONObject element, long l) { return element.getLong("ts"); } })); //TODO 按照mid分组 KeyedStream<JSONObject, String> keyedByMidStream = jsonObjWithWmDS.keyBy(json -> json.getJSONObject("common").getString("mid"));
形成规则流
//TODO 定义模式序列 Pattern<JSONObject, JSONObject> pattern = Pattern.<JSONObject>begin("first").where(new SimpleCondition<JSONObject>() { @Override public boolean filter(JSONObject value) throws Exception { return value.getJSONObject("page").getString("last_page_id") == null; } }).next("second").where(new SimpleCondition<JSONObject>() { @Override public boolean filter(JSONObject value) throws Exception { return value.getJSONObject("page").getString("last_page_id") == null; } }).within(Time.seconds(10)); //TODO 将模式序列作用到流上 PatternStream<JSONObject> patternStream = CEP.pattern(keyedByMidStream, pattern);
提取两条流,合并输出
//TODO 提取匹配事件以及超时事件 OutputTag<JSONObject> timeOutTag = new OutputTag<JSONObject>("time-out"){}; SingleOutputStreamOperator<JSONObject> selectDS = patternStream.select(timeOutTag, new PatternTimeoutFunction<JSONObject, JSONObject>() { @Override public JSONObject timeout(Map<String, List<JSONObject>> map, long l) throws Exception { return map.get("first").get(0); } }, new PatternSelectFunction<JSONObject, JSONObject>() { @Override public JSONObject select(Map<String, List<JSONObject>> map) throws Exception { return map.get("first").get(0); } }); DataStream<JSONObject> timeoutDS = selectDS.getSideOutput(timeOutTag); //TODO 合并两个流 DataStream<JSONObject> unionDS = selectDS.union(timeoutDS); //TODO 将数据写出到Kafka String targetTopic = "dwd_traffic_user_jump_detail"; unionDS.map(JSONAware::toJSONString) .addSink(MyKafkaUtil.getKafkaProducer(targetTopic)); //TODO 启动 env.execute("DwdTrafficUserJumpDetail");
交易域加购事务事实表
提取加购操作生成加购表,并将字典表中的相关维度退化到加购表中,写出到 Kafka 对应主题。
主要任务
(1)读取购物车表数据
(2)建立 Mysql-LookUp 字典表
(3)关联购物车表和字典表,维度退化
(4)将数据写回到Kafka
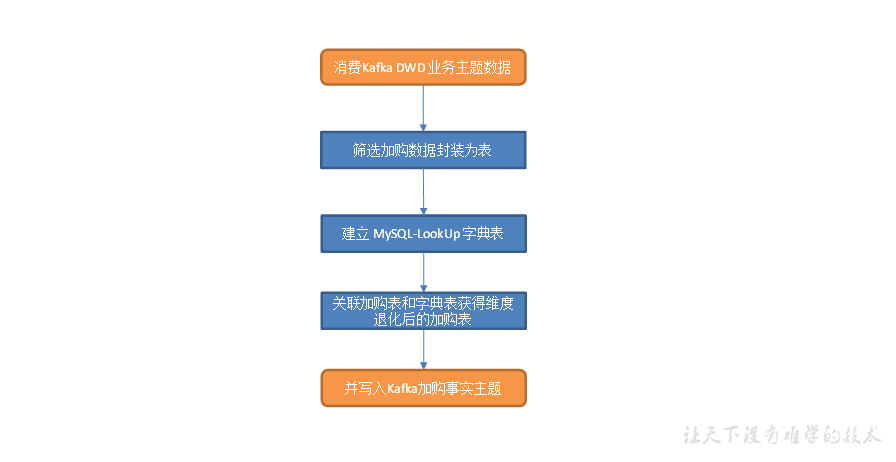
读取购物车表数据
(1)补充Kafka工具类
/** * Kafka-Source DDL 语句 * * @param topic 数据源主题 * @param groupId 消费者组 * @return 拼接好的 Kafka 数据源 DDL 语句 */ public static String getKafkaDDL(String topic, String groupId) { return " with ('connector' = 'kafka', " + " 'topic' = '" + topic + "'," + " 'properties.bootstrap.servers' = '" + BOOTSTRAP_SERVERS + "', " + " 'properties.group.id' = '" + groupId + "', " + " 'format' = 'json', " + " 'scan.startup.mode' = 'latest-offsets')"; } public static String getTopicDbDDL(String groupId){ return "create table topic_db( " + " `database` string, " + " `table` string, " + " `type` string, " + " `data` map<string, string>, " + " `old` map<string, string>, " + " `ts` string, " + " `proc_time` as PROCTIME() " + ")" + MyKafkaUtil.getKafkaDDL("topic_db", groupId); }
(2)使用DDL方式读取Kafka topic_db 主题数据
//TODO 获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); env.setStateBackend(new HashMapStateBackend()); env.enableCheckpointing(5000L); env.getCheckpointConfig().setCheckpointTimeout(10000L); env.getCheckpointConfig().setCheckpointStorage("hdfs:hadoop102:8020//checkpoint"); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); tableEnv.getConfig().setIdleStateRetention(Duration.ofSeconds(5)); //TODO 使用DDL方式读取Kafka topic_db 主题数据 tableEnv.executeSql(MyKafkaUtil.getTopicDbDDL("dwd_trade_cart_add"));
(3)过滤出加购数据
//TODO 过滤出加购数据 Table cartAdd = tableEnv.sqlQuery("" + "select " + " data['id'] id, " + " data['user_id'] user_id, " + " data['sku_id'] sku_id, " + " data['source_id'] source_id, " + " data['source_type'] source_type, " + " if(`type` = 'insert', " + " data['sku_num'],cast((cast(data['sku_num'] as int) - cast(`old`['sku_num'] as int)) as string)) sku_num, " + " ts, " + " proc_time " + "from `topic_db` " + "where `table` = 'cart_info' " + " and (`type` = 'insert' " + " or (`type` = 'update' " + " and `old`['sku_num'] is not null " + " and cast(data['sku_num'] as int) > cast(`old`['sku_num'] as int)))"); tableEnv.createTemporaryView("cart_add", cartAdd);
注意:关键字加飘号,比如`table`
建立 Mysql-LookUp 字典表
为什么使用 Mysql-LookUp? 维表数据不能过期;维表数据更新只能关联更新的这条数据。
(1)编写SQL工具类
public class MysqlUtil { public static String getBaseDicLookUpDDL() { return "create table `base_dic`( " + "`dic_code` string, " + "`dic_name` string, " + "`parent_code` string, " + "`create_time` timestamp, " + "`operate_time` timestamp, " + "primary key(`dic_code`) not enforced " + ")" + MysqlUtil.mysqlLookUpTableDDL("base_dic"); } public static String mysqlLookUpTableDDL(String tableName) { return "WITH ( " + "'connector' = 'jdbc', " + "'url' = 'jdbc:mysql://hadoop102:3306/gmall', " + "'table-name' = '" + tableName + "', " + "'lookup.cache.max-rows' = '10', " + "'lookup.cache.ttl' = '1 hour', " + "'username' = 'root', " + "'password' = '000000', " + "'driver' = 'com.mysql.cj.jdbc.Driver' " + ")"; } }
注意:使用lookup缓存,可以提供吞吐量,但修改数据可能会造成数据不一致。而这里不会修改base_dic表,只会新增,故不会产生影响。
(2)读取MySQL中的base_dic表构建维表
//TODO 读取MySQL中的base_dic表构建维表 tableEnv.executeSql(MysqlUtil.getBaseDicLookUpDDL());
关联购物车表和字典表,维度退化
//TODO 关联两张表(维度退化) Table resultTable = tableEnv.sqlQuery("" + "select " + " cadd.id, " + " user_id, " + " sku_id, " + " source_id, " + " source_type, " + " dic_name source_type_name, " + " sku_num, " + " ts " + "from cart_add cadd " + " left join base_dic for system_time as of cadd.proc_time as dic " + " on cadd.source_type=dic.dic_code"); tableEnv.createTemporaryView("result_table", resultTable);
注意:主表关联lookup表需要处理时间 proc_time 字段,保证维表更新后,存在多条数据,关联合适的数据
将数据写回到Kafka
//TODO 将数据写回到Kafka String sinkTopic = "dwd_trade_cart_add"; tableEnv.executeSql("" + "create table dwd_trade_cart_add( " + " id string, " + " user_id string, " + " sku_id string, " + " source_id string, " + " source_type_code string, " + " source_type_name string, " + " sku_num string, " + " ts string, " + " primary key(id) not enforced " + ")" + MyKafkaUtil.getKafkaDDL(sinkTopic, "")); tableEnv.executeSql("insert into dwd_trade_cart_add select * from result_table");
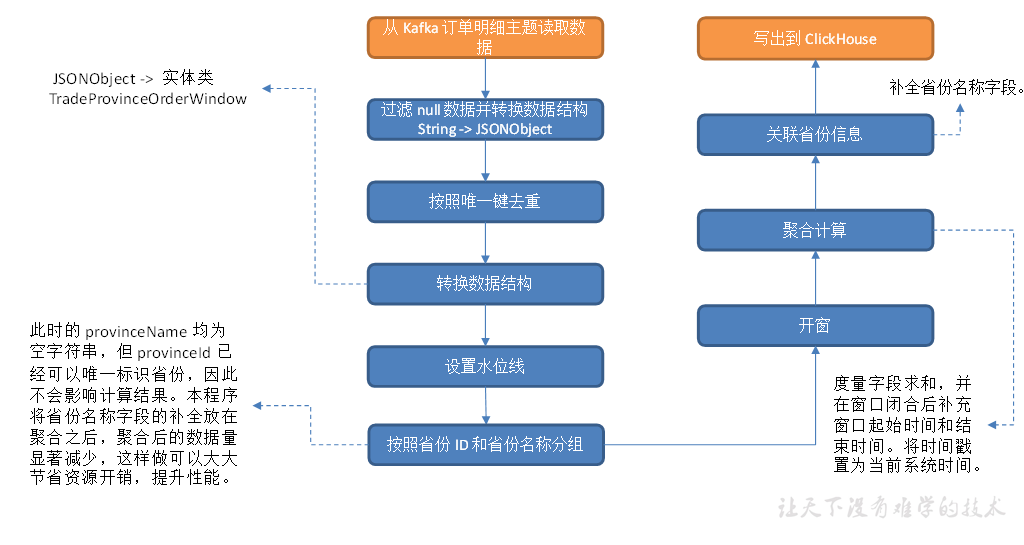
交易域订单预处理表
关联订单明细表、订单表、订单明细活动关联表、订单明细优惠券关联表四张事实业务表和字典表(维度业务表)形成订单预处理表,写入 Kafka 对应主题。
主要任务
(1)从 Kafka topic_db 主题读取业务数据;
(2)筛选订单明细表数据;
(3)筛选订单表数据;
(4)筛选订单明细活动关联表数据;
(5)筛选订单明细优惠券关联表数据;
(6)建立 MySQL-Lookup 字典表;
(7)关联上述五张表获得订单宽表,写入 Kafka 主题
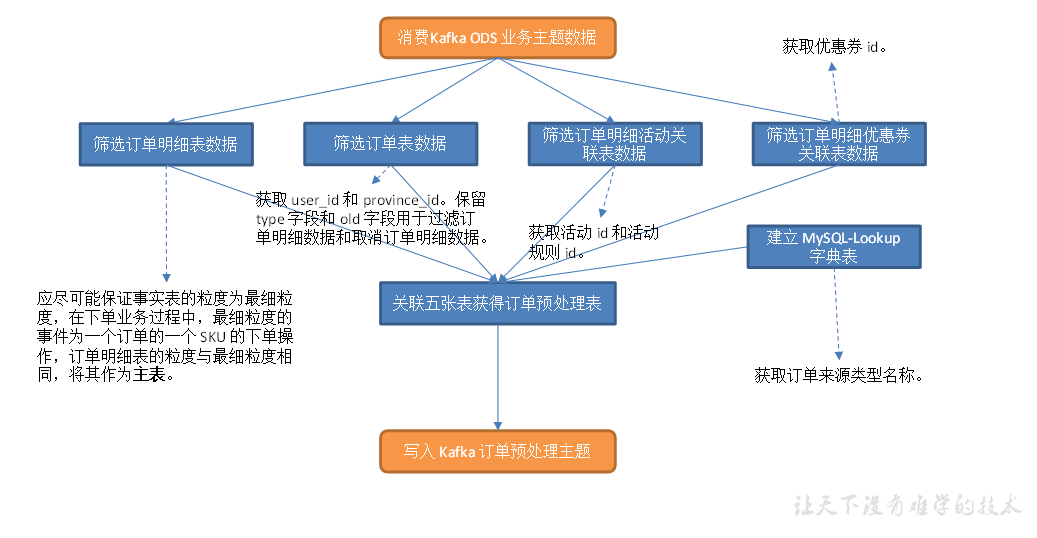
从 Kafka topic_db 主题读取业务数据
//TODO 获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); env.setStateBackend(new HashMapStateBackend()); env.enableCheckpointing(5000L); env.getCheckpointConfig().setCheckpointTimeout(10000L); env.getCheckpointConfig().setCheckpointStorage("hdfs:hadoop102:8020//checkpoint"); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); tableEnv.getConfig().setIdleStateRetention(Duration.ofDays(3)); //TODO 使用DDL方式读取 Kafka topic_db 主题的数据 tableEnv.executeSql(MyKafkaUtil.getTopicDbDDL("dwd_trade_cart_add"));
筛选订单明细表数据
//TODO 过滤出订单明细数据 Table orderDetail = tableEnv.sqlQuery("" + "select " + " data['id'] id, " + " data['order_id'] order_id, " + " data['sku_id'] sku_id, " + " data['sku_name'] sku_name, " + " data['create_time'] create_time, " + " data['source_id'] source_id, " + " data['source_type'] source_type, " + " data['sku_num'] sku_num, " + " cast(cast(data['sku_num'] as decimal(16,2)) * " + " cast(data['order_price'] as decimal(16,2)) as String) split_original_amount, " + " data['split_total_amount'] split_total_amount, " + " data['split_activity_amount'] split_activity_amount, " + " data['split_coupon_amount'] split_coupon_amount, " + " ts od_ts, " + " proc_time " + "from `topic_db` where `table` = 'order_detail' " + "and `type` = 'insert' "); tableEnv.createTemporaryView("order_detail", orderDetail);
筛选订单表数据
//TODO 过滤出订单数据 Table orderInfo = tableEnv.sqlQuery("" + "select " + " data['id'] id, " + " data['user_id'] user_id, " + " data['province_id'] province_id, " + " data['operate_time'] operate_time, " + " data['order_status'] order_status, " + " `type`, " + " `old`, " + " ts oi_ts " + "from `topic_db` " + "where `table` = 'order_info' " + "and (`type` = 'insert' or `type` = 'update')"); tableEnv.createTemporaryView("order_info", orderInfo);
筛选订单明细活动关联表数据
//TODO 过滤出订单明细活动数据 Table orderDetailActivity = tableEnv.sqlQuery("" + "select " + " data['order_detail_id'] order_detail_id, " + " data['activity_id'] activity_id, " + " data['activity_rule_id'] activity_rule_id " + "from `topic_db` " + "where `table` = 'order_detail_activity' " + "and `type` = 'insert' "); tableEnv.createTemporaryView("order_detail_activity", orderDetailActivity);
筛选订单明细优惠券关联表数据
//TODO 过滤出订单明细购物券数据 Table orderDetailCoupon = tableEnv.sqlQuery("" + "select " + " data['order_detail_id'] order_detail_id, " + " data['coupon_id'] coupon_id " + "from `topic_db` " + "where `table` = 'order_detail_coupon' " + "and `type` = 'insert' "); tableEnv.createTemporaryView("order_detail_coupon", orderDetailCoupon);
建立 MySQL-Lookup 字典表
//TODO 构建MySQL-Lookup表 base_dic tableEnv.executeSql(MysqlUtil.getBaseDicLookUpDDL());
关联上述五张表获得订单宽表,写入 Kafka 主题
(1)关联5张表//TODO 关联5张表 Table resultTable = tableEnv.sqlQuery("" + "select " + " od.id, " + " od.order_id, " + " oi.user_id, " + " oi.order_status, " + " od.sku_id, " + " od.sku_name, " + " oi.province_id, " + " act.activity_id, " + " act.activity_rule_id, " + " cou.coupon_id, " + " date_format(od.create_time, 'yyyy-MM-dd') date_id, " + " od.create_time, " + " date_format(oi.operate_time, 'yyyy-MM-dd') operate_date_id, " + " oi.operate_time, " + " od.source_id, " + " od.source_type, " + " dic.dic_name source_type_name, " + " od.sku_num, " + " od.split_original_amount, " + " od.split_activity_amount, " + " od.split_coupon_amount, " + " od.split_total_amount, " + " oi.`type`, " + " oi.`old`, " + " od.od_ts, " + " oi.oi_ts, " + " current_row_timestamp() row_op_ts " + "from order_detail od " + "join order_info oi " + " on od.order_id = oi.id " + "left join order_detail_activity act " + " on od.id = act.order_detail_id " + "left join order_detail_coupon cou " + " on od.id = cou.order_detail_id " + "left join `base_dic` for system_time as of od.proc_time as dic " + " on od.source_type = dic.dic_code"); tableEnv.createTemporaryView("result_table", resultTable);
(2)补充Kafka工具类
/**
* Kafka-Sink DDL 语句
*
* @param topic 输出到 Kafka 的目标主题
* @return 拼接好的 Kafka-Sink DDL 语句
*/
public static String getUpsertKafkaDDL(String topic) {
return "WITH ( " +
" 'connector' = 'upsert-kafka', " +
" 'topic' = '" + topic + "', " +
" 'properties.bootstrap.servers' = '" + BOOTSTRAP_SERVERS + "', " +
" 'key.format' = 'json', " +
" 'value.format' = 'json' " +
")";
}
注意:因为left join输出为撤回流(lookup join 不会输出撤回流),所以需要upsert-kafka。使用upsert-kafka必须定义主键,撤回数据在kafka中为null
(3)写出数据
//TODO 创建 upsert-kafka表 tableEnv.executeSql("" + "create table dwd_trade_order_pre_process( " + " id string, " + " order_id string, " + " user_id string, " + " order_status string, " + " sku_id string, " + " sku_name string, " + " province_id string, " + " activity_id string, " + " activity_rule_id string, " + " coupon_id string, " + " date_id string, " + " create_time string, " + " operate_date_id string, " + " operate_time string, " + " source_id string, " + " source_type string, " + " source_type_name string, " + " sku_num string, " + " split_original_amount string, " + " split_activity_amount string, " + " split_coupon_amount string, " + " split_total_amount string, " + " `type` string, " + " `old` map<string,string>, " + " od_ts string, " + " oi_ts string, " + " row_op_ts timestamp_ltz(3), " + "primary key(id) not enforced " + ")" + MyKafkaUtil.getUpsertKafkaDDL("dwd_trade_order_pre_process")); //TODO 将数据写出 tableEnv.executeSql("" + "insert into dwd_trade_order_pre_process \n" + "select * from result_table");
交易域下单事务事实表
从 Kafka 读取订单预处理表数据,筛选订单明细数据,写入 Kafka 对应主题。
主要任务
(1)从 Kafka dwd_trade_order_pre_process 主题读取订单预处理数据;
(2)筛选订单明细数据:新增数据,即订单表操作类型为 insert 的数据即为订单明细数据;
(3)写入 Kafka 订单明细主题。
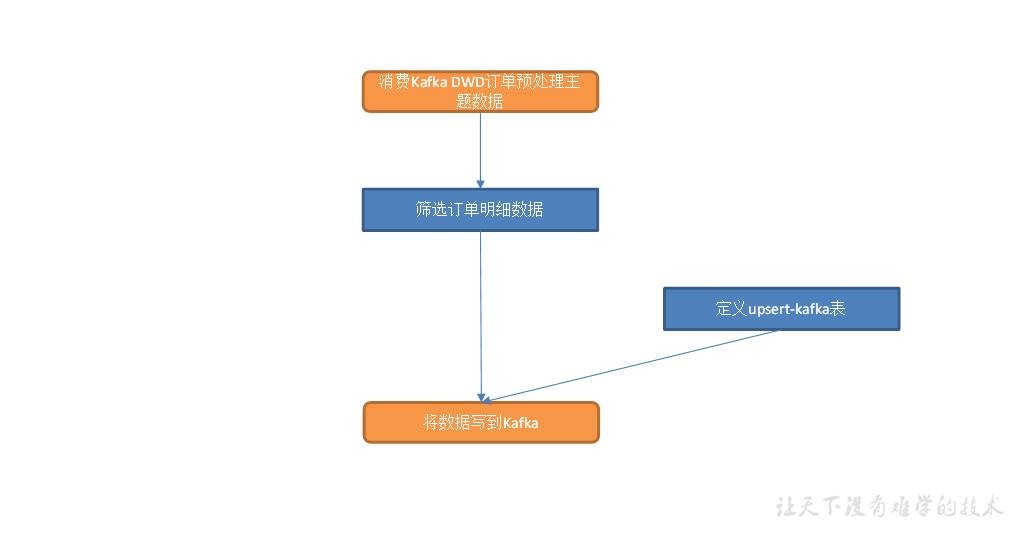
交易域取消订单事务事实表
从 Kafka 读取订单预处理表数据,筛选取消订单明细数据,写入 Kafka 对应主题。
主要任务
(1)从 Kafka dwd_trade_order_pre_process 主题读取订单预处理数据;
(2)筛选取消订单明细数据:保留修改了 order_status 字段且修改后该字段值为 "1003" 的数据;
(3)写入 Kafka 取消订单主题。
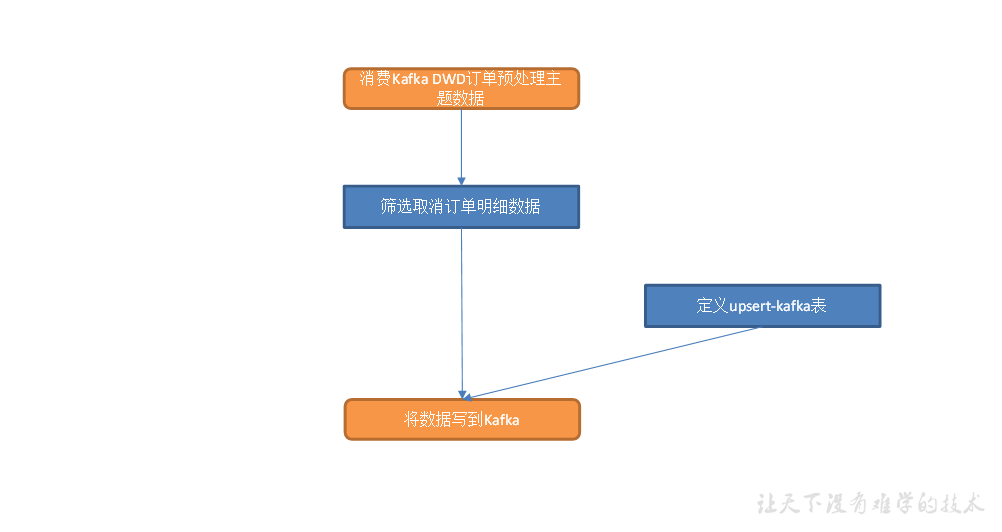
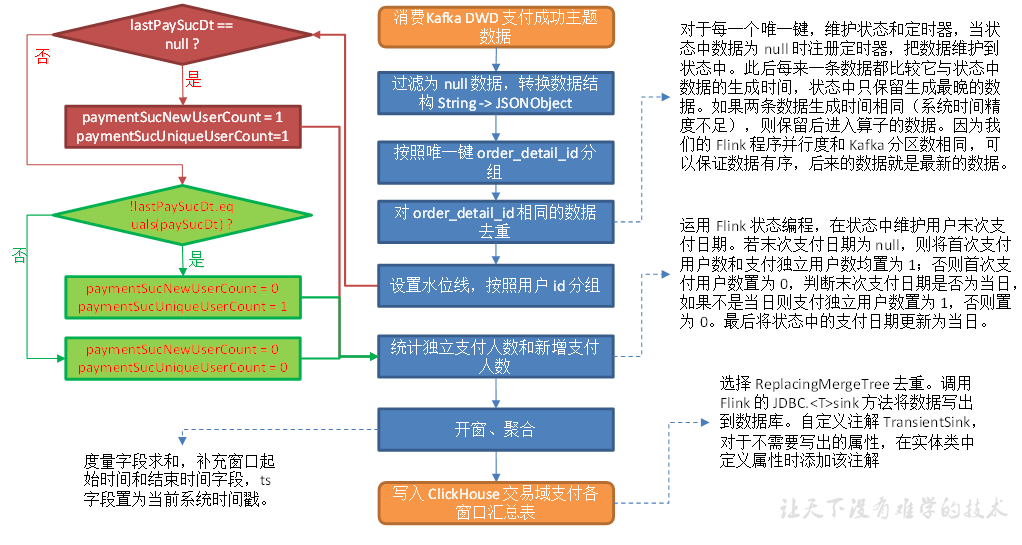
交易域支付成功事务事实表
从 Kafka topic_db主题筛选支付成功数据、从dwd_trade_order_detail主题中读取订单事实数据、MySQL-LookUp字典表,关联三张表形成支付成功宽表,写入 Kafka 支付成功主题。
主要任务
1)获取订单明细数据
2)筛选支付表数据
3)构建 MySQL-LookUp 字典表
4)关联上述三张表形成支付成功宽表,写入 Kafka 支付成功主题
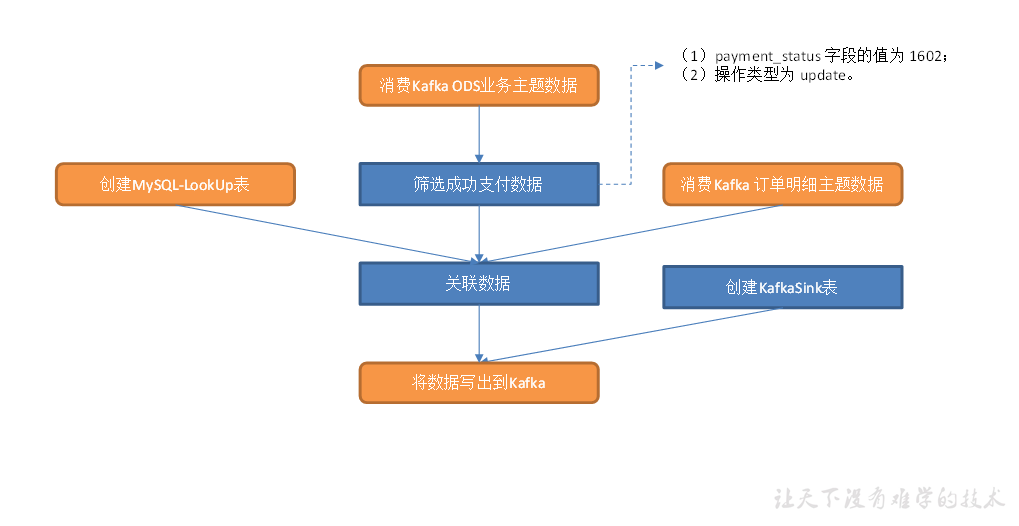
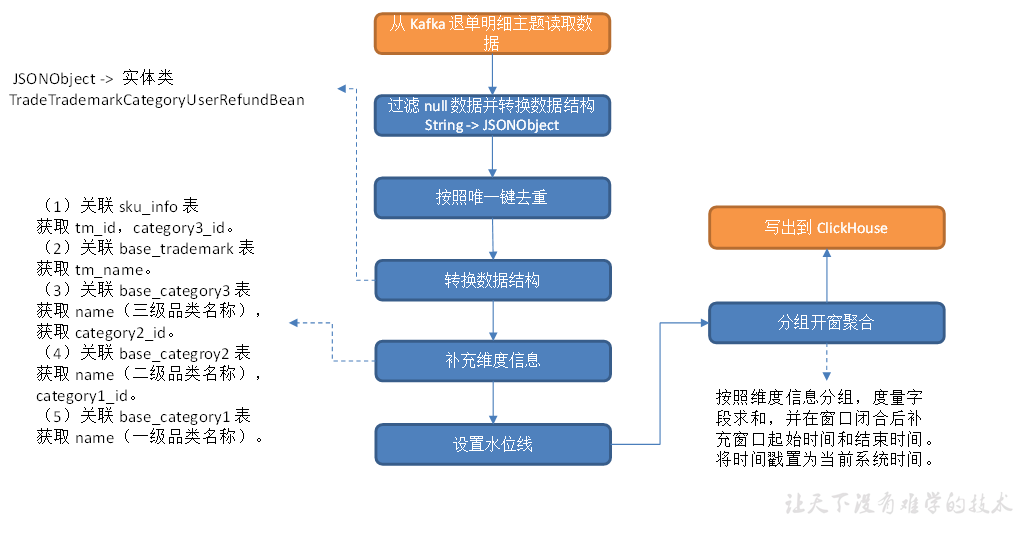
交易域退单事务事实表
从 Kafka 读取业务数据,筛选退单表数据,筛选满足条件的订单表数据,建立 MySQL-Lookup 字典表,关联三张表获得退单明细宽表。
主要任务
1)筛选退单表数据
2)筛选订单表数据
3)建立 MySQL-Lookup 字典表
4)关联这几张表获得退单明细宽表,写入 Kafka 退单明细主题
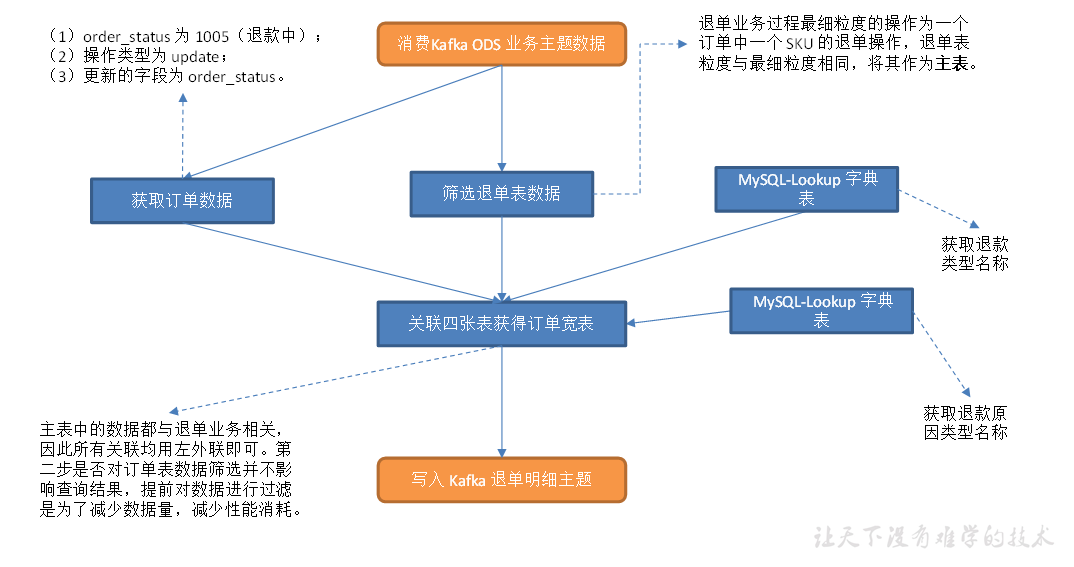
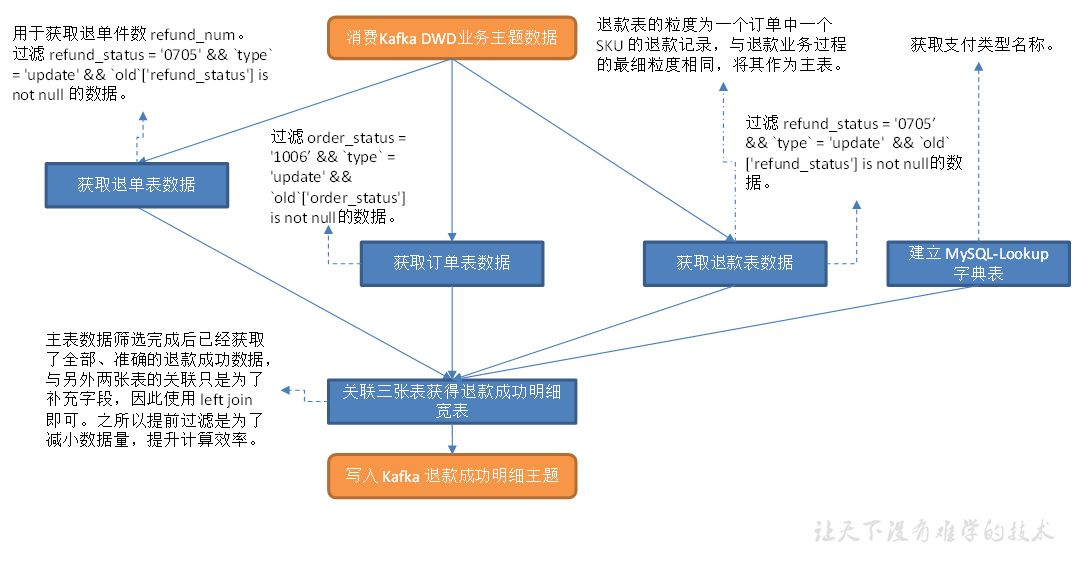
交易域退款成功事务事实表
主要任务
1)从退款表中提取退款成功数据
2)从订单表中提取退款成功订单数据
3)从退单表中提取退款成功的明细数据
4)建立 MySQL-Lookup 字典表
5)关联这几张表获得退款明细宽表,写入 Kafka 退款明细主题
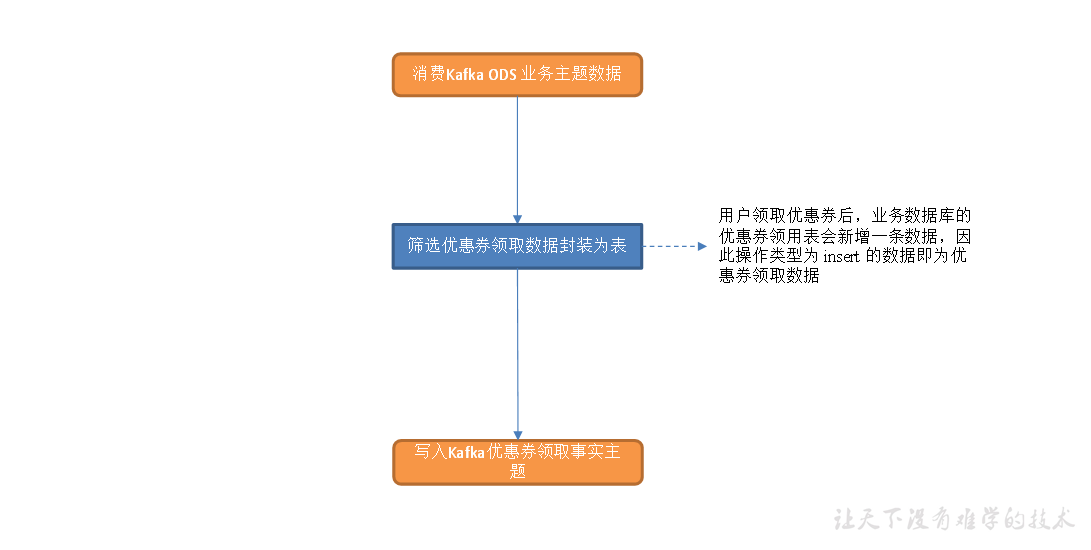
工具域优惠券领取事务事实表
主要任务
1)筛选优惠券领用表中领取数据
2)写入 Kafka 优惠券领取主题
工具域优惠券使用(下单)事务事实表
主要任务
1)筛选优惠券领用表数据,封装为流
2)过滤满足条件的优惠券下单数据,封装为表
3)写入 Kafka 优惠券下单主题
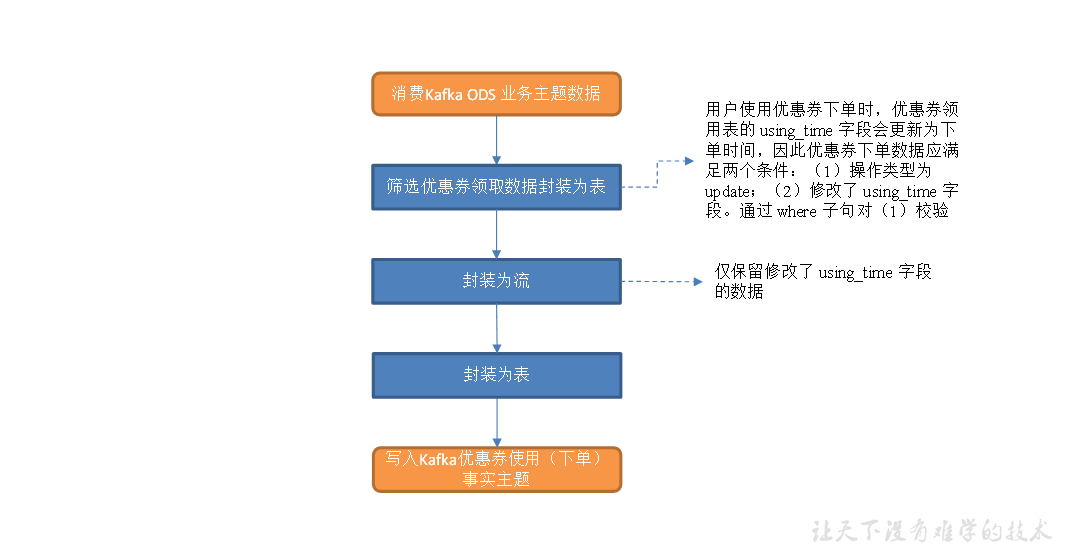
注意:这里需要的是old中有using_time字段,如果使用SQL(`old`['using_time'] is not null)需要的数据会被过滤掉,所以先转换为流处理后再转换回表。
//读取优惠券领用表数据,封装为流 Table couponUseOrder = tableEnv.sqlQuery("select " + "data['id'] id, " + "data['coupon_id'] coupon_id, " + "data['user_id'] user_id, " + "data['order_id'] order_id, " + "date_format(data['using_time'],'yyyy-MM-dd') date_id, " + "data['using_time'] using_time, " + "`old`, " + "ts " + "from topic_db " + "where `table` = 'coupon_use' " + "and `type` = 'update' "); DataStream<CouponUseOrderBean> couponUseOrderDS = tableEnv.toAppendStream(couponUseOrder, CouponUseOrderBean.class); // 过滤满足条件的优惠券下单数据,封装为表 SingleOutputStreamOperator<CouponUseOrderBean> filteredDS = couponUseOrderDS.filter( couponUseOrderBean -> { String old = couponUseOrderBean.getOld(); if(old != null) { Map oldMap = JSON.parseObject(old, Map.class); Set changeKeys = oldMap.keySet(); return changeKeys.contains("using_time"); } return false; } ); Table resultTable = tableEnv.fromDataStream(filteredDS); tableEnv.createTemporaryView("result_table", resultTable);
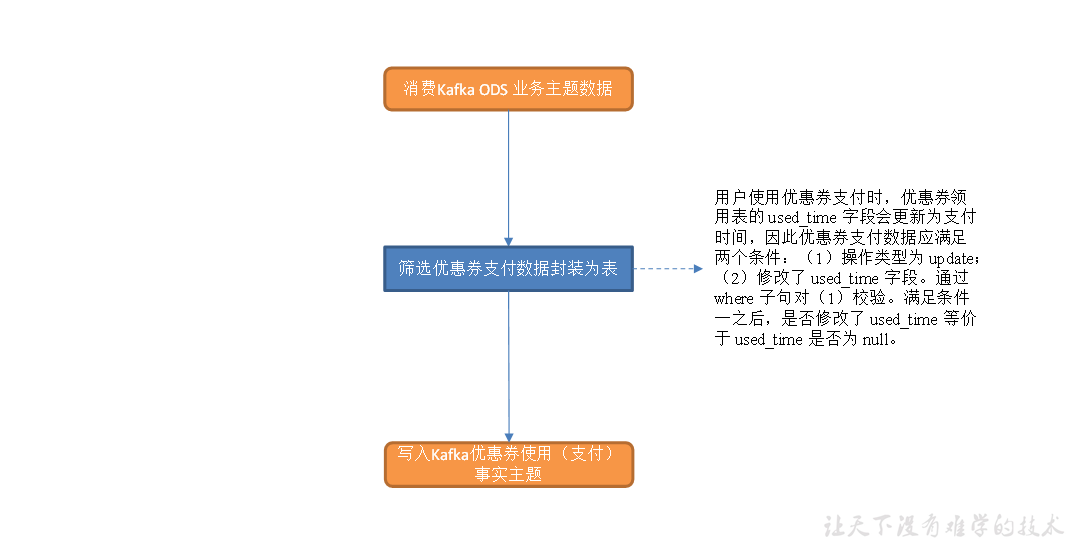
工具域优惠券使用(支付)事务事实表
主要任务
1)筛选优惠券领用表中支付数据
2)写入 Kafka 优惠券支付主题
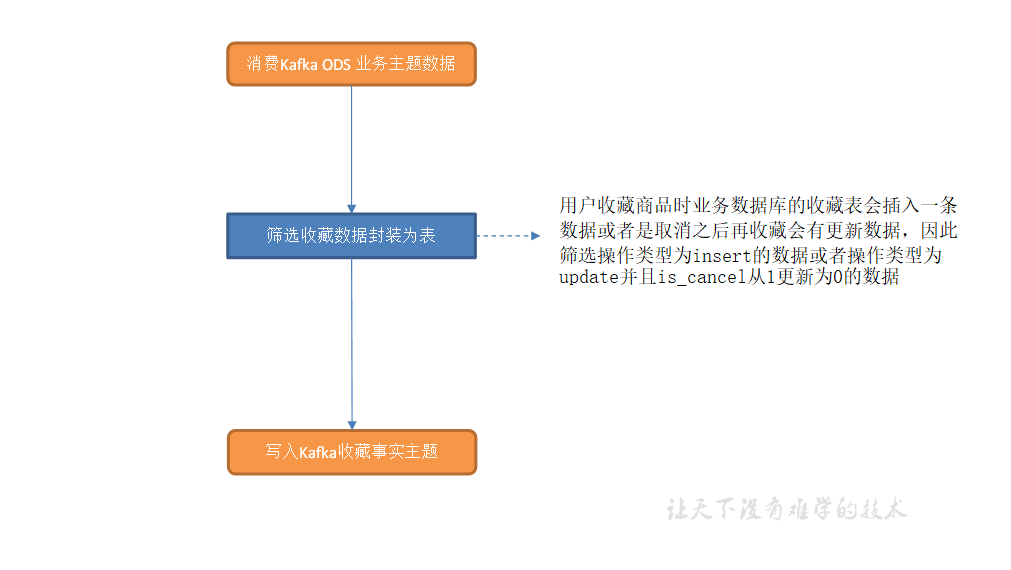
互动域收藏商品事务事实表
主要任务
1)筛选收藏数据
2)写入 Kafka 收藏主题
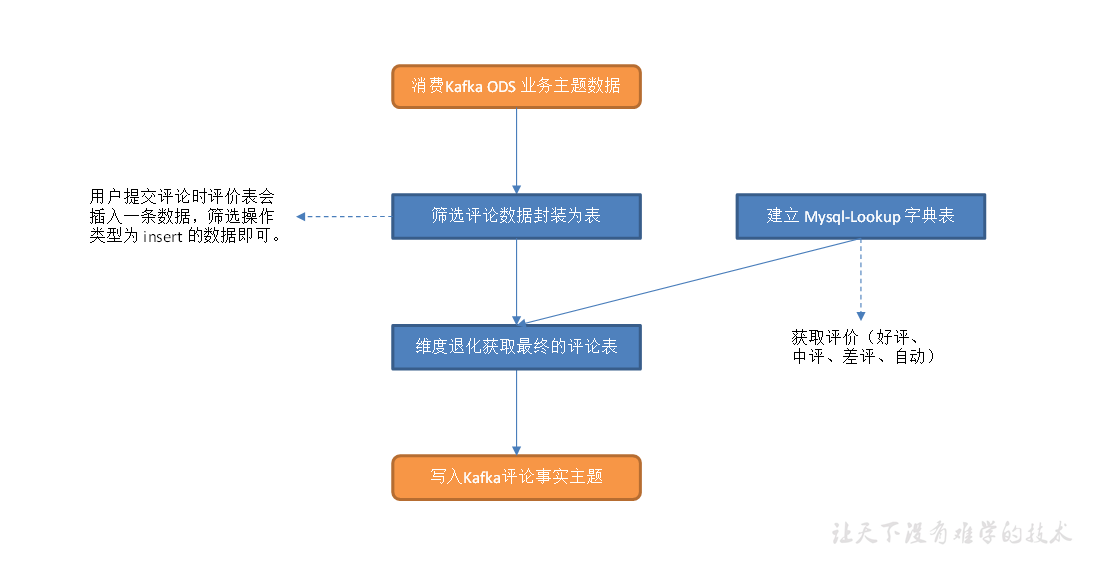
互动域评价事务事实表
主要任务
1)筛选评价数据
2)建立 MySQL-Lookup 字典表
3)关联这两张表,写入 Kafka 评价主题
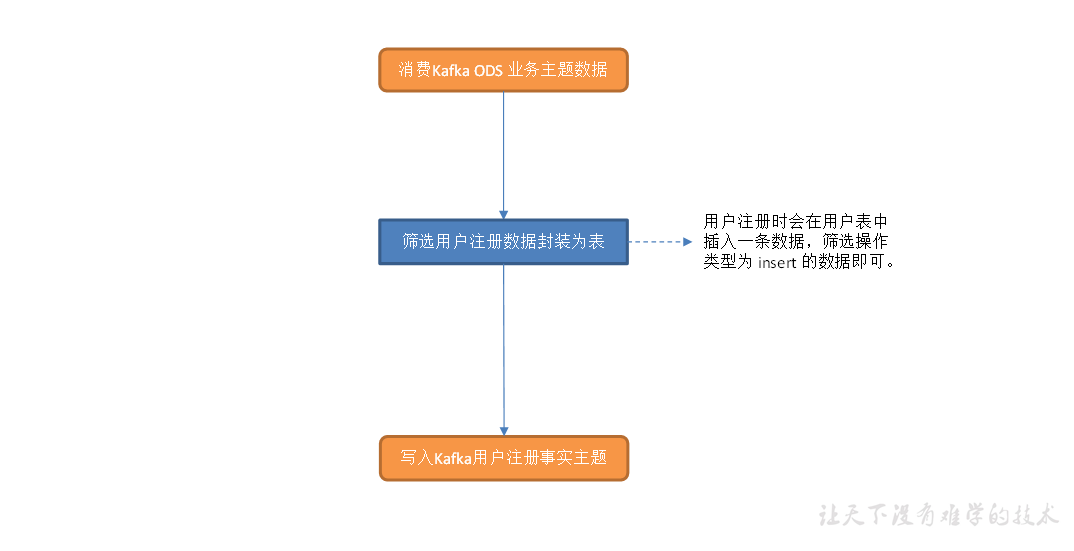
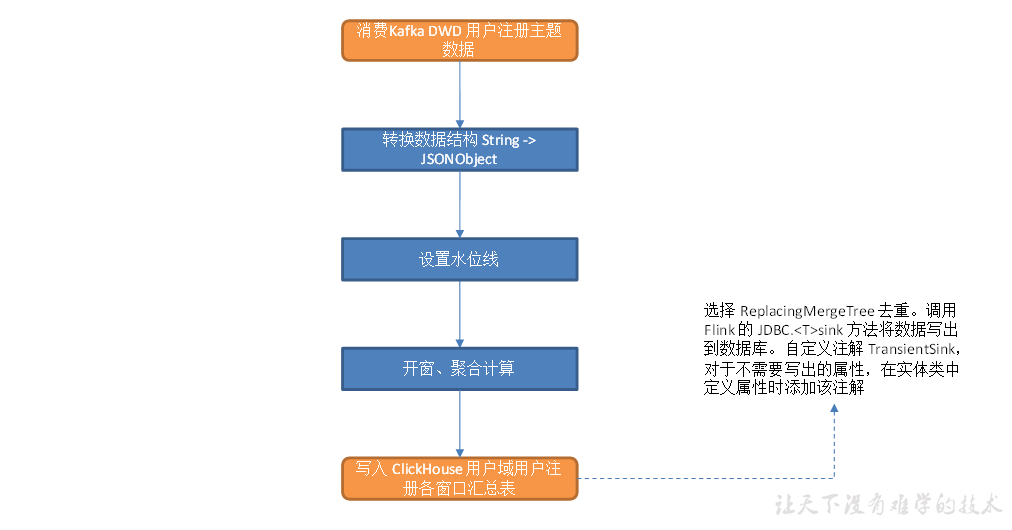
用户域用户注册事务事实表
主要任务
1)筛选用户注册数据
2)写入 Kafka 用户注册主题
DWS
DWS层设计要点
(1)DWS层的设计参考指标体系。
(2)DWS层表名的命名规范为dws_数据域_统计粒度_业务过程_统计周期(window)
注:window 表示窗口对应的时间范围
流量域来源关键词粒度页面浏览各窗口汇总表
从 Kafka 页面浏览明细主题读取数据,过滤搜索行为,使用自定义 UDTF(一进多出)函数对搜索内容分词。统计各窗口各关键词出现频次,写入 ClickHouse。
主要任务
1)消费数据并设置水位线
2)过滤搜索行为
3)分词
4)分组开窗聚合
5)将数据转换为流并写入ClickHouse
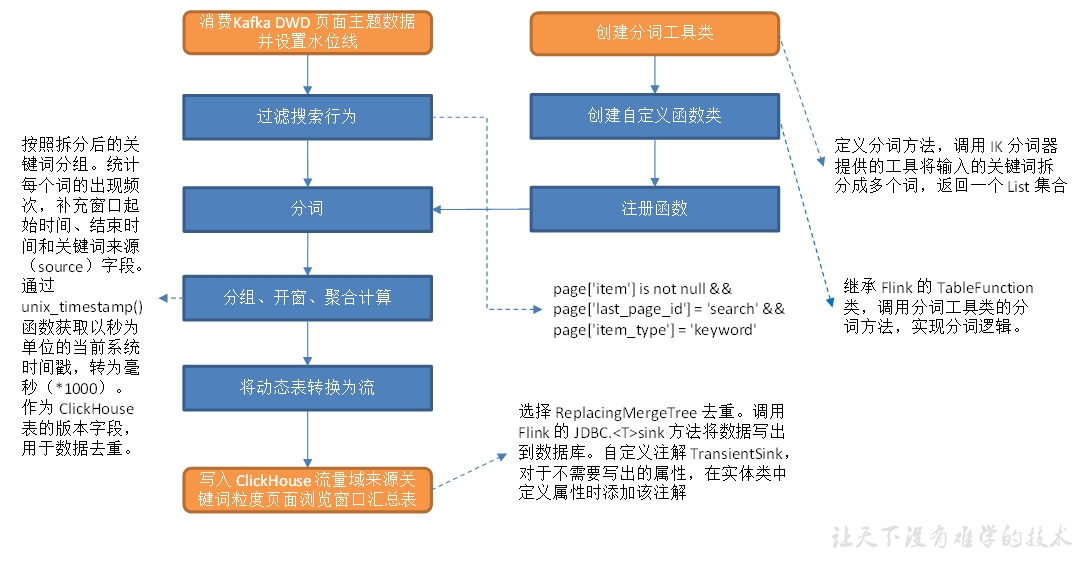
消费数据并设置水位线
//TODO 获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(4); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); env.enableCheckpointing(3000L, CheckpointingMode.EXACTLY_ONCE); env.getCheckpointConfig().setCheckpointTimeout(60 * 1000L); env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000L); env.getCheckpointConfig().enableExternalizedCheckpoints( CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION ); env.setRestartStrategy(RestartStrategies.failureRateRestart( 3, Time.days(1), Time.minutes(1) )); env.setStateBackend(new HashMapStateBackend()); env.getCheckpointConfig().setCheckpointStorage( "hdfs://hadoop102:8020/ck" ); System.setProperty("HADOOP_USER_NAME", "atguigu"); //TODO 使用DDL方式读取 DWD层页面浏览日志 创建表,同时获取事件时间生成Watermark String topic = "dwd_traffic_page_log"; String groupId = "dws_traffic_source_keyword_page_view_window"; tableEnv.executeSql("" + "create table page_log( " + " `page` map<string, string>, " + " `ts` bigint, " + " row_time AS TO_TIMESTAMP(FROM_UNIXTIME(ts/1000, 'yyyy-MM-dd HH:mm:ss')), " + "WATERMARK FOR row_time AS row_time - INTERVAL '3' SECOND " + ")" + MyKafkaUtil.getKafkaDDL(topic, groupId));
过滤搜索行为
//TODO 过滤出搜索数据 Table searchTable = tableEnv.sqlQuery("" + "select " + " page['item'] full_word, " + " row_time " + "from page_log " + "where page['item'] is not null " + "and page['last_page_id'] = 'search' " + "and page['item_type'] = 'keyword'"); tableEnv.createTemporaryView("search_table", searchTable);
分词
(1)编写关键词分词工具类
public class KeywordUtil { public static List<String> splitKeyWord(String keyword) throws IOException { ArrayList<String> result = new ArrayList<>(); //创建分词器对象 StringReader reader = new StringReader(keyword); IKSegmenter ikSegmenter = new IKSegmenter(reader, false); //提取分词 Lexeme next = ikSegmenter.next(); while (next != null){ String word = next.getLexemeText(); result.add(word); next = ikSegmenter.next(); } return result; } }
(2)编写分词函数
@FunctionHint(output = @DataTypeHint("Row<word STRING>"))
public class SplitFunction extends TableFunction<Row> {
public void eval(String keyword){
List<String> list;
try {
list = KeywordUtil.splitKeyWord(keyword);
for (String word : list) {
collect(Row.of(word));
}
} catch (IOException e) {
collect(Row.of(keyword));
}
}
}
(3)使用分词函数
//TODO 使用自定义函数分词处理 tableEnv.createTemporaryFunction("SplitFunction", SplitFunction.class); Table splitTable = tableEnv.sqlQuery("" + "select " + " keyword, " + " row_time " + "from search_table, " + "lateral table(SplitFunction(full_word)) " + "as t(keyword)"); tableEnv.createTemporaryView("split_table", splitTable);
分组开窗聚合
//TODO 分组开窗聚合 Table KeywordBeanSearch = tableEnv.sqlQuery("" + "select " + " DATE_FORMAT(TUMBLE_START(row_time, INTERVAL '10' SECOND),'yyyy-MM-dd HH:mm:ss') stt, " + " DATE_FORMAT(TUMBLE_END(row_time, INTERVAL '10' SECOND),'yyyy-MM-dd HH:mm:ss') edt, " + " 'search' source, " + " keyword, " + " count(*) keyword_count, " + " UNIX_TIMESTAMP()*1000 ts " + "from split_table " + "GROUP BY TUMBLE(row_time, INTERVAL '10' SECOND),keyword");
注意:ts作为后续幂等写入ReplacingMergeTree表的版本,不写版本默认按照插入顺序保留。
将数据转换为流并写入ClickHouse
(1)编写ClickHouse工具类
public class MyClickHouseUtil { public static <T> SinkFunction<T> getClickHouseSink(String sql){ return JdbcSink.<T>sink(sql, new JdbcStatementBuilder<T>() { @SneakyThrows @Override public void accept(PreparedStatement preparedStatement, T t) throws SQLException { //使用反射的方式提取字段 Class<?> clz = t.getClass(); Field[] fields = clz.getDeclaredFields(); int offset = 0; for (int i = 0; i < fields.length; i++) { Field field = fields[i]; field.setAccessible(true); TransientSink transientSink = field.getAnnotation(TransientSink.class); if(transientSink != null){ offset++; continue; } //获取数据并给占位符赋值 Object value = field.get(t); preparedStatement.setObject(i + 1 - offset, value); } } }, new JdbcExecutionOptions.Builder() .withBatchSize(5) .withBatchIntervalMs(1000L) .build(), new JdbcConnectionOptions.JdbcConnectionOptionsBuilder() .withDriverName(GmallConfig.CLICKHOUSE_DRIVER) .withUrl(GmallConfig.CLICKHOUSE_URL) .build() ); } }
(2)转换为流
//TODO 将数据转换为流 DataStream<KeywordBean> keywordBeanDS = tableEnv.toAppendStream(KeywordBeanSearch, KeywordBean.class);
注意:这里开窗聚合,追加流即可
(3)建表
drop table if exists dws_traffic_source_keyword_page_view_window; create table if not exists dws_traffic_source_keyword_page_view_window ( stt DateTime, edt DateTime, source String, keyword String, keyword_count UInt64, ts UInt64 ) engine = ReplacingMergeTree(ts) partition by toYYYYMMDD(stt) order by (stt, edt, source, keyword);
(4)写入ClickHouse
//TODO 写出到ClickHouse keywordBeanDS.addSink(MyClickHouseUtil.getClickHouseSink("" + "insert into dws_traffic_source_keyword_page_view_window values(?,?,?,?,?,?))")); //TODO 启动任务 env.execute("DwsTrafficSourceKeywordPageViewWindow");
流量域版本-渠道-地区-访客类别粒度页面浏览各窗口汇总表
DWS 层是为 ADS 层服务的,通过对指标体系的分析,本节汇总表中需要有会话数、页面浏览数、浏览总时长、独立访客数、跳出会话数五个度量字段。本节的任务是统计这五个指标,并将维度和度量数据写入 ClickHouse 汇总表。
主要任务
1)读取3个主题的数据创建3各流
2)统一数据格式并合并
3)分组开窗聚合
4)写到ClickHouse
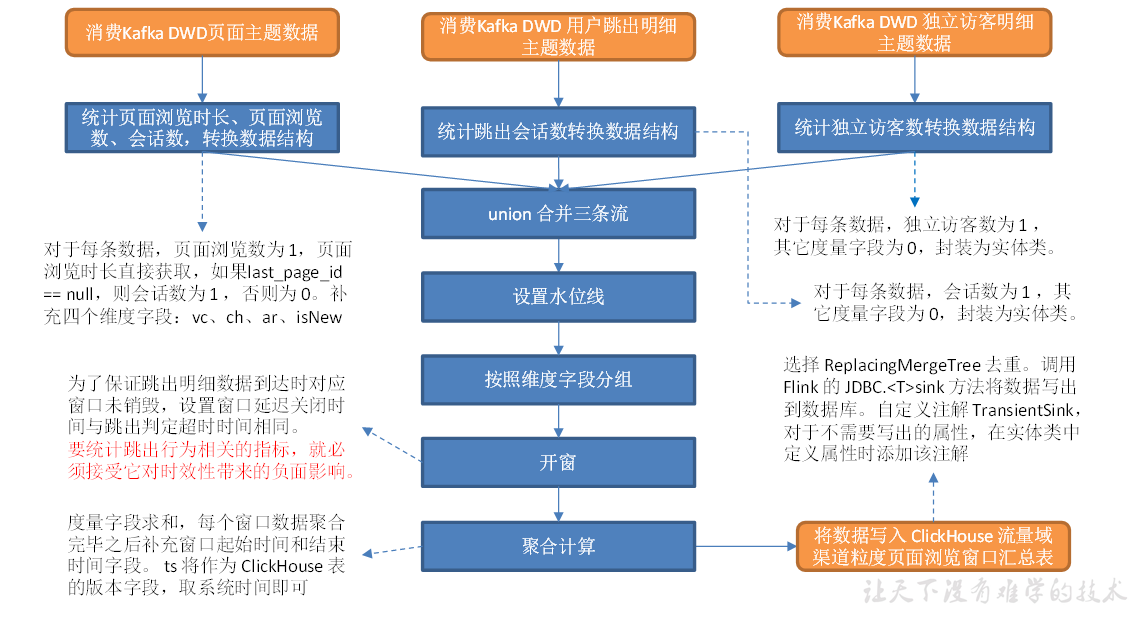
读取3个主题的数据创建3各流
//TODO 读取3个主题的数据创建三个流 String page_topic = "dwd_traffic_page_log"; String uv_topic = "dwd_traffic_unique_visitor_detail"; String uj_topic = "dwd_traffic_user_jump_detail"; String groupId = "dws_traffic_vc_ch_ar_isnew_pageview_window"; DataStreamSource<String> pageStringDS = env.addSource(MyKafkaUtil.getKafkaConsumer(page_topic, groupId)); DataStreamSource<String> uvStringDS = env.addSource(MyKafkaUtil.getKafkaConsumer(uv_topic, groupId)); DataStreamSource<String> ujStringDS = env.addSource(MyKafkaUtil.getKafkaConsumer(uj_topic, groupId));
统一数据格式并合并
//TODO 3个流统一数据格式 SingleOutputStreamOperator<TrafficPageViewBean> trafficPageViewWithUvDS = uvStringDS.map(line -> { JSONObject jsonObject = JSON.parseObject(line); JSONObject common = jsonObject.getJSONObject("common"); return new TrafficPageViewBean("", "", common.getString("vc"), common.getString("ch"), common.getString("ar"), common.getString("is_new"), 1L, 0L, 0L, 0L, 0L, jsonObject.getLong("ts") ); }); SingleOutputStreamOperator<TrafficPageViewBean> trafficPageViewWithUjDS = ujStringDS.map(line -> { JSONObject jsonObject = JSON.parseObject(line); JSONObject common = jsonObject.getJSONObject("common"); return new TrafficPageViewBean("", "", common.getString("vc"), common.getString("ch"), common.getString("ar"), common.getString("is_new"), 0L, 0L, 0L, 0L, 1L, jsonObject.getLong("ts") ); }); SingleOutputStreamOperator<TrafficPageViewBean> trafficPageViewWithPvDS = pageStringDS.map(line -> { JSONObject jsonObject = JSON.parseObject(line); JSONObject common = jsonObject.getJSONObject("common"); JSONObject page = jsonObject.getJSONObject("page"); String lastPageId = page.getString("last_page_id"); long sv = 0L; if(lastPageId == null){ sv = 1; } return new TrafficPageViewBean("", "", common.getString("vc"), common.getString("ch"), common.getString("ar"), common.getString("is_new"), 0L, sv, 1L, jsonObject.getJSONObject("page").getLong("during_time"), 0L, jsonObject.getLong("ts") ); }); //TODO 合并3个流并提取事件时间生成Watermark SingleOutputStreamOperator<TrafficPageViewBean> unionDS = trafficPageViewWithPvDS.union( trafficPageViewWithUjDS, trafficPageViewWithUvDS ).assignTimestampsAndWatermarks(WatermarkStrategy.<TrafficPageViewBean>forBoundedOutOfOrderness(Duration.ofSeconds(2)) .withTimestampAssigner(new SerializableTimestampAssigner<TrafficPageViewBean>() { @Override public long extractTimestamp(TrafficPageViewBean element, long l) { return element.getTs(); } }));
分组开窗聚合
//TODO 分组开窗聚合 KeyedStream<TrafficPageViewBean, Tuple4<String, String, String, String>> keyedStream = unionDS.keyBy(new KeySelector<TrafficPageViewBean, Tuple4<String, String, String, String>>() { @Override public Tuple4<String, String, String, String> getKey(TrafficPageViewBean value) throws Exception { return new Tuple4<>(value.getAr(), value.getCh(), value.getIsNew(), value.getVc()); } }); WindowedStream<TrafficPageViewBean, Tuple4<String, String, String, String>, TimeWindow> windowedStream = keyedStream.window(TumblingEventTimeWindows.of(Time.seconds(10))); SingleOutputStreamOperator<TrafficPageViewBean> reduceDS = windowedStream.reduce(new ReduceFunction<TrafficPageViewBean>() { @Override public TrafficPageViewBean reduce(TrafficPageViewBean value1, TrafficPageViewBean value2) throws Exception { value1.setUvCt(value1.getUvCt() + value2.getUvCt()); value1.setSvCt(value1.getSvCt() + value2.getSvCt()); value1.setPvCt(value1.getPvCt() + value2.getPvCt()); value1.setDurSum(value1.getDurSum() + value2.getDurSum()); value1.setUjCt(value1.getUjCt() + value2.getUjCt()); return value1; } }, new WindowFunction<TrafficPageViewBean, TrafficPageViewBean, Tuple4<String, String, String, String>, TimeWindow>() { @Override public void apply(Tuple4<String, String, String, String> key, TimeWindow window, Iterable<TrafficPageViewBean> input, Collector<TrafficPageViewBean> out) throws Exception { //获取数据 TrafficPageViewBean trafficPageViewBean = input.iterator().next(); //获取窗口信息 long start = window.getStart(); long end = window.getEnd(); //补充窗口信息 trafficPageViewBean.setStt(DateFormatUtil.toDate(start)); trafficPageViewBean.setEdt(DateFormatUtil.toDate(end)); //输出数据 out.collect(trafficPageViewBean); } });
写到ClickHouse
(1)建表
drop table if exists dws_traffic_vc_ch_ar_is_new_page_view_window; create table if not exists dws_traffic_vc_ch_ar_is_new_page_view_window ( stt DateTime, edt DateTime, vc String, ch String, ar String, is_new String, uv_ct UInt64, sv_ct UInt64, pv_ct UInt64, dur_sum UInt64, uj_ct UInt64, ts UInt64 ) engine = ReplacingMergeTree(ts) partition by toYYYYMMDD(stt) order by (stt, edt, vc, ch, ar, is_new);
(2)写入ClickHouse
//TODO 写出到ClickHouse reduceDS.addSink(MyClickHouseUtil.getClickHouseSink("" + "insert into dws_traffic_vc_ch_ar_is_new_page_view_window values(?,?,?,?,?,?,?,?,?,?,?,?)"));
存在问题
uj数据有两次开窗,当uj数据来到第二次开窗时,由于第一次开窗的延迟,第二个窗口已经关闭了,最终无法输出。
解决方案:一是增大第二次开窗水位线延迟;二是uj数据单独统计
流量域页面浏览各窗口汇总表
从 Kafka 页面日志主题读取数据,统计当日的首页和商品详情页独立访客数。
主要任务
1)过滤出主页和商品详情页数据
2)使用状态编程计算主页及商品详情页的独立访客
3)开窗聚合并输出
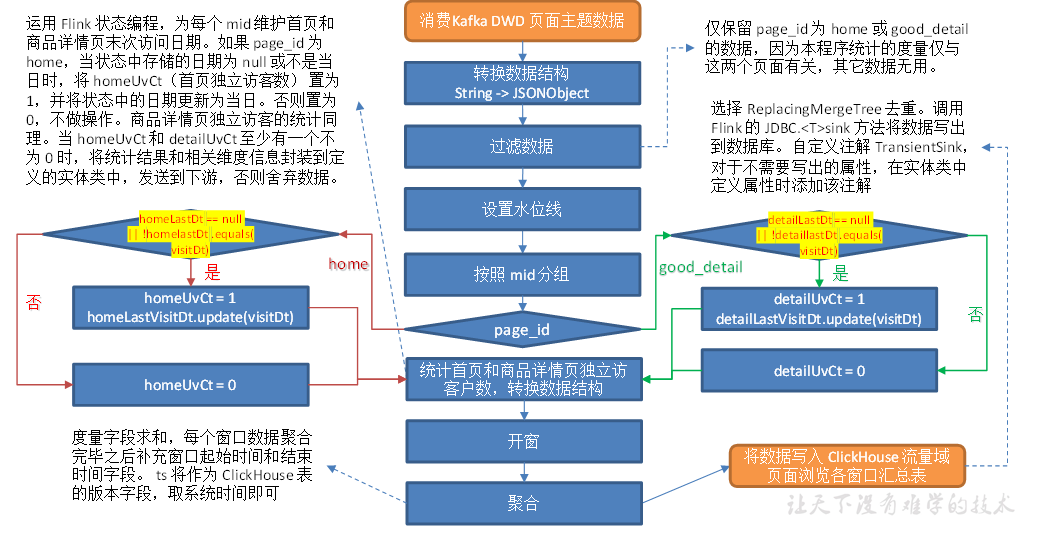
过滤出主页和商品详情页数据
//TODO 读取Kafka 页面日志主题 数据创建流 String page_topic = "dwd_traffic_page_log"; String groupId = "dws_traffic_page_view_window"; DataStreamSource<String> pageStringDS = env.addSource(MyKafkaUtil.getKafkaConsumer(page_topic, groupId)); //TODO 将数据转换为JSON对象 SingleOutputStreamOperator<JSONObject> jsonObjDS = pageStringDS.map(JSON::parseObject); //TODO 过滤数据,只需要访问主页跟商品详情页的数据 SingleOutputStreamOperator<JSONObject> homeAndDetailPageDS = jsonObjDS.filter(new FilterFunction<JSONObject>() { @Override public boolean filter(JSONObject value) throws Exception { String pageId = value.getJSONObject("page").getString("page_id"); return "good_detail".equals(pageId) || "home".equals(pageId); } }); //TODO 提取事件时间生成Watermark SingleOutputStreamOperator<JSONObject> homeAndDetailPageWithWmDS = homeAndDetailPageDS.assignTimestampsAndWatermarks( WatermarkStrategy.<JSONObject>forBoundedOutOfOrderness(Duration.ofSeconds(2)) .withTimestampAssigner(new SerializableTimestampAssigner<JSONObject>() { @Override public long extractTimestamp(JSONObject element, long l) { return element.getLong("ts"); } }));
使用状态编程计算主页及商品详情页的独立访客
//TODO 按照Mid分组 KeyedStream<JSONObject, String> keyedStream = homeAndDetailPageWithWmDS.keyBy(jsonObject -> jsonObject.getJSONObject("common").getString("mid")); //TODO 使用状态编程计算主页及商品详情页的独立访客 SingleOutputStreamOperator<TrafficHomeDetailPageViewBean> trafficHomeDetailDS = keyedStream.flatMap(new RichFlatMapFunction<JSONObject, TrafficHomeDetailPageViewBean>() { private ValueState<String> homeLastVisitDt; private ValueState<String> detailLastVisitDt; @Override public void open(Configuration parameters) throws Exception { //状态TTL StateTtlConfig stateTtlConfig = new StateTtlConfig.Builder(Time.days(1)).setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite).build(); ValueStateDescriptor<String> homeDtDescriptor = new ValueStateDescriptor<>("home-dt", String.class); homeDtDescriptor.enableTimeToLive(stateTtlConfig); homeLastVisitDt = getRuntimeContext().getState(homeDtDescriptor); ValueStateDescriptor<String> detailDtDescriptor = new ValueStateDescriptor<>("detail-dt", String.class); detailDtDescriptor.enableTimeToLive(stateTtlConfig); detailLastVisitDt = getRuntimeContext().getState(detailDtDescriptor); } @Override public void flatMap(JSONObject value, Collector<TrafficHomeDetailPageViewBean> out) throws Exception { //取出当前页面信息及时间 String pageId = value.getJSONObject("page").getString("page_id"); Long ts = value.getLong("ts"); String curDt = DateFormatUtil.toDate(ts); //过滤 long homeUvCt = 0L; long detailUvCt = 0L; if ("home".equals(pageId)) { String homeLastDt = homeLastVisitDt.value(); if (homeLastDt == null || !homeLastDt.equals(curDt)) { homeUvCt = 1L; homeLastVisitDt.update(curDt); } } else { String detailLastDt = detailLastVisitDt.value(); if (detailLastDt == null || !detailLastDt.equals(curDt)) { detailUvCt = 1L; detailLastVisitDt.update(curDt); } } if (homeUvCt != 0L || detailUvCt != 0L) { out.collect(new TrafficHomeDetailPageViewBean("", "", homeUvCt, detailUvCt, System.currentTimeMillis())); } } });
开窗聚合并输出
(1)开窗聚合
//TODO 开窗聚合 SingleOutputStreamOperator<TrafficHomeDetailPageViewBean> reduceDS = trafficHomeDetailDS.windowAll(TumblingEventTimeWindows.of(org.apache.flink.streaming.api.windowing.time.Time.seconds(10))) .reduce(new ReduceFunction<TrafficHomeDetailPageViewBean>() { @Override public TrafficHomeDetailPageViewBean reduce(TrafficHomeDetailPageViewBean value1, TrafficHomeDetailPageViewBean value2) throws Exception { value1.setHomeUvCt(value1.getHomeUvCt() + value2.getHomeUvCt()); value1.setGoodDetailUvCt(value1.getGoodDetailUvCt() + value2.getGoodDetailUvCt()); return value1; } }, new AllWindowFunction<TrafficHomeDetailPageViewBean, TrafficHomeDetailPageViewBean, TimeWindow>() { @Override public void apply(TimeWindow window, Iterable<TrafficHomeDetailPageViewBean> values, Collector<TrafficHomeDetailPageViewBean> out) throws Exception { TrafficHomeDetailPageViewBean pageViewBean = values.iterator().next(); pageViewBean.setStt(DateFormatUtil.toYmdHms(window.getStart())); pageViewBean.setEdt(DateFormatUtil.toYmdHms(window.getEnd())); out.collect(pageViewBean); } });
(2)建表
drop table if exists dws_traffic_page_view_window; create table if not exists dws_traffic_page_view_window ( stt DateTime, edt DateTime, home_uv_ct UInt64, good_detail_uv_ct UInt64, ts UInt64 ) engine = ReplacingMergeTree(ts) partition by toYYYYMMDD(stt) order by (stt, edt);
(3)输出
//TODO 将数据输出到ClickHouse reduceDS.addSink(MyClickHouseUtil.getClickHouseSink("insert into dws_traffic_page_view_window values(?,?,?,?,?)"));
用户域用户登陆各窗口汇总表
从 Kafka 页面日志主题读取数据,统计七日回流用户和当日独立用户数。
主要任务
1)过滤得到用户登录数据
2)提取回流用户数和独立用户数
3)开窗聚合,写入ClickHouse
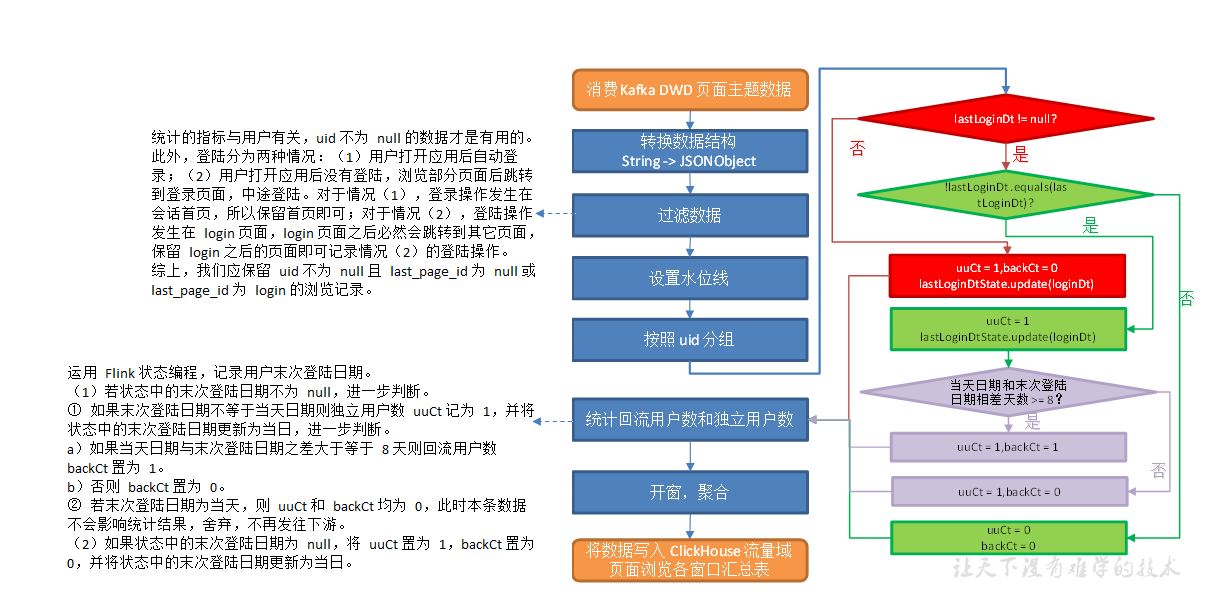
过滤得到用户登录数据
//TODO 读取Kafka 页面日志主题 数据创建流 String page_topic = "dwd_traffic_page_log"; String groupId = "dws_user_user_login_window"; DataStreamSource<String> pageStringDS = env.addSource(MyKafkaUtil.getKafkaConsumer(page_topic, groupId)); //TODO 将数据转换为JSON对象 SingleOutputStreamOperator<JSONObject> jsonObjDS = pageStringDS.map(JSON::parseObject); //TODO 过滤数据,只保留用户 id 不为 null 且 (last_page_id 为 null 或为 login 的数据) SingleOutputStreamOperator<JSONObject> filterDS = jsonObjDS.filter( new FilterFunction<JSONObject>() { @Override public boolean filter(JSONObject value) throws Exception { JSONObject common = value.getJSONObject("common"); JSONObject page = value.getJSONObject("page"); return common.getString("uid") != null && (page.getString("last_page_id") == null || page.getString("last_page_id").equals("login")); } } ); //TODO 提取事件时间生成Watermark SingleOutputStreamOperator<JSONObject> filterWithWmDS = filterDS.assignTimestampsAndWatermarks( WatermarkStrategy.<JSONObject>forBoundedOutOfOrderness(Duration.ofSeconds(2)) .withTimestampAssigner(new SerializableTimestampAssigner<JSONObject>() { @Override public long extractTimestamp(JSONObject element, long l) { return element.getLong("ts"); } }));
提取回流用户数和独立用户数
//TODO 按照uid分组 KeyedStream<JSONObject, String> keyedStream = filterWithWmDS.keyBy(jsonObject -> jsonObject.getJSONObject("common").getString("uid")); //TODO 使用状态编程实现 回流及独立用户的提取 SingleOutputStreamOperator<UserLoginBean> uvDS = keyedStream.process(new KeyedProcessFunction<String, JSONObject, UserLoginBean>() { private ValueState<String> lastVisitDt; @Override public void open(Configuration parameters) throws Exception { lastVisitDt = getRuntimeContext().getState(new ValueStateDescriptor<String>("last-dt", String.class)); } @Override public void processElement(JSONObject value, Context ctx, Collector<UserLoginBean> out) throws Exception { //取出状态 String lastDt = lastVisitDt.value(); //获取数据日期 Long ts = value.getLong("ts"); String curDt = DateFormatUtil.toDate(ts); long uuCt = 0; long backCt = 0; if (lastDt == null) { uuCt = 1L; lastVisitDt.update(curDt); } else { if (!lastDt.equals(curDt)) { uuCt = 1L; lastVisitDt.update(curDt); Long lastTs = DateFormatUtil.toTs(lastDt); long days = (ts - lastTs) / (1000L * 60 * 60 * 24); if (days >= 8L) { backCt = 1; } } } if (uuCt == 1L) { out.collect(new UserLoginBean("", "", backCt, uuCt, System.currentTimeMillis())); } } });
开窗聚合,写入ClickHouse
(1)开窗聚合
//TODO 开窗聚合 SingleOutputStreamOperator<UserLoginBean> resultDS = uvDS.windowAll(TumblingEventTimeWindows.of(org.apache.flink.streaming.api.windowing.time.Time.seconds(10))) .reduce(new ReduceFunction<UserLoginBean>() { @Override public UserLoginBean reduce(UserLoginBean value1, UserLoginBean value2) throws Exception { value1.setUuCt(value1.getUuCt() + value2.getUuCt()); value1.setBackCt(value1.getBackCt() + value2.getBackCt()); return value1; } }, new AllWindowFunction<UserLoginBean, UserLoginBean, TimeWindow>() { @Override public void apply(TimeWindow window, Iterable<UserLoginBean> values, Collector<UserLoginBean> out) throws Exception { UserLoginBean userLoginBean = values.iterator().next(); userLoginBean.setStt(DateFormatUtil.toYmdHms(window.getStart())); userLoginBean.setEdt(DateFormatUtil.toYmdHms(window.getEnd())); out.collect(userLoginBean); } });
(2)建表
drop table if exists dws_user_user_login_window; create table if not exists dws_user_user_login_window ( stt DateTime, edt DateTime, back_ct UInt64, uu_ct UInt64, ts UInt64 ) engine = ReplacingMergeTree(ts) partition by toYYYYMMDD(stt) order by (stt, edt);
(3)写入ClickHouse
//TODO 写入ClickHouse resultDS.addSink(MyClickHouseUtil.getClickHouseSink("insert into dws_user_user_login_window values(?,?,?,?,?)"));
用户域用户注册各窗口汇总表
从 DWD 层用户注册表中读取数据,统计各窗口注册用户数,写入 ClickHouse。
主要任务
开窗聚合
交易域加购各窗口汇总表
从 Kafka 读取用户加购明细数据,统计各窗口加购独立用户数,写入 ClickHouse
主要任务
使用状态编程过滤独立用户数据
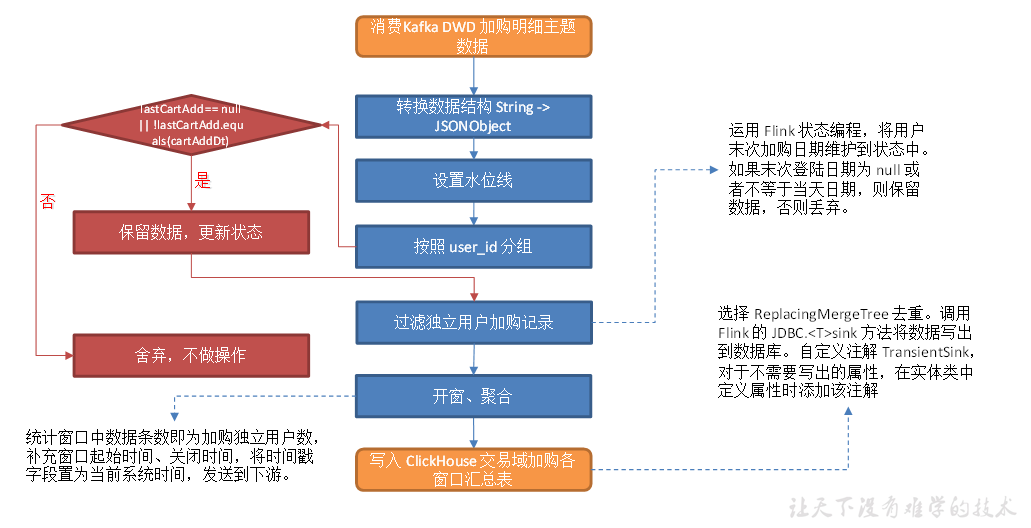
注意:提取水位线时,有operate_tiem要使用operate_tiem,没有则使用create_time。
交易域下单各窗口汇总表
从 Kafka 订单明细主题读取数据,过滤 null 数据并去重,统计当日下单独立用户数和新增下单用户数,封装为实体类,写入 ClickHouse。
注意:null数据和重复数据都是由于使用了left join和upsert-kafka产生的
主要任务
1)过滤 null 数据并去重
2)统计当日下单独立用户数和新增下单用户数
3)写入 ClickHouse
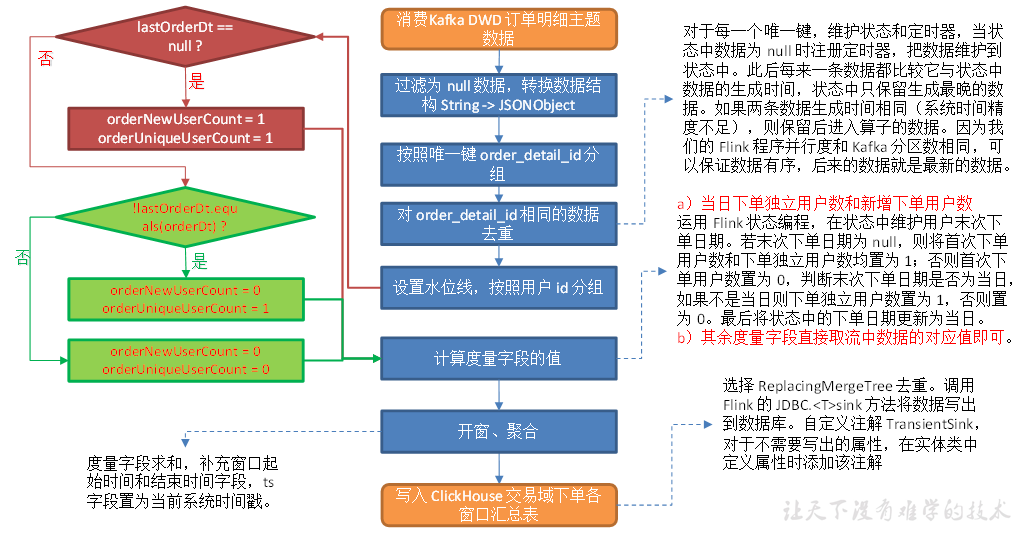
过滤 null 数据并去重
(1)过滤null数据
//TODO 读取Kafka DWD 订单明细 主题数据 String topic = "dwd_trade_order_detail"; String groupId = "dws_trade_order_window"; DataStreamSource<String> orderDetailStrDS = env.addSource(MyKafkaUtil.getKafkaConsumer(topic, groupId)); //TODO 过滤数据 转换数据为JSON格式 SingleOutputStreamOperator<JSONObject> JSONObjDS = orderDetailStrDS.flatMap(new FlatMapFunction<String, JSONObject>() { @Override public void flatMap(String value, Collector<JSONObject> out) throws Exception { if (!"".equals(value)) { JSONObject jsonObject = JSON.parseObject(value); out.collect(jsonObject); } } });
(2)时间戳比较工具类
public class TimestampLtz3CompareUtil { public static int compare(String timestamp1, String timestamp2) { // 数据格式 2022-04-01 10:20:47.302Z // 1. 去除末尾的时区标志,'Z' 表示 0 时区 String cleanedTime1 = timestamp1.substring(0, timestamp1.length() - 1); String cleanedTime2 = timestamp2.substring(0, timestamp2.length() - 1); // 2. 提取小于 1秒的部分 String[] timeArr1 = cleanedTime1.split("\\."); String[] timeArr2 = cleanedTime2.split("\\."); String milliseconds1 = new StringBuilder(timeArr1[timeArr1.length - 1]) .append("000").toString().substring(0, 3); String milliseconds2 = new StringBuilder(timeArr2[timeArr2.length - 1]) .append("000").toString().substring(0, 3); int milli1 = Integer.parseInt(milliseconds1); int milli2 = Integer.parseInt(milliseconds2); // 3. 提取 yyyy-MM-dd HH:mm:ss 的部分 String date1 = timeArr1[0]; String date2 = timeArr2[0]; Long ts1 = DateFormatUtil.toTs(date1, true); Long ts2 = DateFormatUtil.toTs(date2, true); // 4. 获得精确到毫秒的时间戳 long milliTs1 = ts1 + milli1; long milliTs2 = ts2 + milli2; long divTs = milliTs1 - milliTs2; return divTs < 0 ? -1 : divTs == 0 ? 0 : 1; } }
(3)去重
//TODO 按照order_detail_id分组 KeyedStream<JSONObject, String> keyedStream = JSONObjDS.keyBy(jsonObject -> jsonObject.getString("order_detail_id")); //TODO 去重 SingleOutputStreamOperator<JSONObject> orderDetailJSONObjDS = keyedStream.process(new KeyedProcessFunction<String, JSONObject, JSONObject>() { private ValueState<JSONObject> orderDetailState; @Override public void open(Configuration parameters) throws Exception { orderDetailState = getRuntimeContext().getState(new ValueStateDescriptor<JSONObject>("order-detail", JSONObject.class)); } @Override public void processElement(JSONObject value, Context ctx, Collector<JSONObject> out) throws Exception { JSONObject orderDetail = orderDetailState.value(); if (orderDetail == null) { orderDetailState.update(value); ctx.timerService().registerProcessingTimeTimer(ctx.timerService().currentProcessingTime() + 2000L); } else { String stateTs = orderDetail.getString("row_op_ts"); String curTs = value.getString("row_op_ts"); int compare = TimestampLtz3CompareUtil.compare(stateTs, curTs); if (compare != 1) { orderDetailState.update(value); } } } @Override public void onTimer(long timestamp, OnTimerContext ctx, Collector<JSONObject> out) throws Exception { JSONObject orderDetail = orderDetailState.value(); out.collect(orderDetail); } });
注意:row_op_ts为上游 通过current_row_timestamp()产生,代表订单详情关联其他表的时间
统计当日下单独立用户数和新增下单用户数
(1)提取下单独立用户并转换为JavaBean对象
//TODO 按照user_id分组 KeyedStream<JSONObject, String> keyedByUidStream = jsonObjWithWmDS.keyBy(jsonObject -> jsonObject.getString("user_id")); //TODO 提取下单独立用户并转换为JavaBean对象 SingleOutputStreamOperator<TradeOrderBean> tradeOrderDS = keyedByUidStream.flatMap(new RichFlatMapFunction<JSONObject, TradeOrderBean>() { private ValueState<String> lastOrderDt; @Override public void open(Configuration parameters) throws Exception { lastOrderDt = getRuntimeContext().getState(new ValueStateDescriptor<String>("last-order", String.class)); } @Override public void flatMap(JSONObject value, Collector<TradeOrderBean> out) throws Exception { String lastOrder = lastOrderDt.value(); String curDt = value.getString("create_time").split(" ")[0]; long orderUniqueUserCount = 0L; long orderNewUserCount = 0L; if (lastOrder == null) { orderUniqueUserCount = 1L; orderNewUserCount = 1L; } else { if (!lastOrder.equals(curDt)) { orderUniqueUserCount = 1L; } } lastOrderDt.update(curDt); Double splitActivityAmount = value.getDouble("split_activity_amount"); if (splitActivityAmount == null) splitActivityAmount = 0.0D; Double splitCouponAmount = value.getDouble("split_coupon_amount"); if (splitCouponAmount == null) splitCouponAmount = 0.0D; Double splitOriginalAmount = value.getDouble("split_original_amount"); out.collect(new TradeOrderBean( "", "", orderUniqueUserCount, orderNewUserCount, splitActivityAmount, splitCouponAmount, splitOriginalAmount, 0L )); } });
(2)开窗聚合
//TODO 开窗聚合 AllWindowedStream<TradeOrderBean, TimeWindow> windowedStream = tradeOrderDS.windowAll(TumblingEventTimeWindows.of(org.apache.flink.streaming.api.windowing.time.Time.seconds(10))); SingleOutputStreamOperator<Object> resultDS = windowedStream.reduce(new ReduceFunction<TradeOrderBean>() { @Override public TradeOrderBean reduce(TradeOrderBean value1, TradeOrderBean value2) throws Exception { value1.setOrderUniqueUserCount(value1.getOrderUniqueUserCount() + value2.getOrderUniqueUserCount()); value1.setOrderNewUserCount(value1.getOrderNewUserCount() + value2.getOrderNewUserCount()); value1.setOrderActivityReduceAmount(value1.getOrderActivityReduceAmount() + value2.getOrderActivityReduceAmount()); value1.setOrderCouponReduceAmount(value1.getOrderCouponReduceAmount() + value2.getOrderCouponReduceAmount()); value1.setOrderOriginalTotalAmount(value1.getOrderOriginalTotalAmount() + value2.getOrderOriginalTotalAmount()); return value1; } }, new AllWindowFunction<TradeOrderBean, Object, TimeWindow>() { @Override public void apply(TimeWindow window, Iterable<TradeOrderBean> values, Collector<Object> out) throws Exception { TradeOrderBean orderBean = values.iterator().next(); orderBean.setStt(DateFormatUtil.toYmdHms(window.getStart())); orderBean.setEdt(DateFormatUtil.toYmdHms(window.getEnd())); orderBean.setTs(System.currentTimeMillis()); out.collect(orderBean); } });
写入 ClickHouse
(1)建表
drop table if exists dws_trade_order_window; create table if not exists dws_trade_order_window ( stt DateTime, edt DateTime, order_unique_user_count UInt64, order_new_user_count UInt64, order_activity_reduce_amount Decimal(38, 20), order_coupon_reduce_amount Decimal(38, 20), order_origin_total_amount Decimal(38, 20), ts UInt64 ) engine = ReplacingMergeTree(ts) partition by toYYYYMMDD(stt) order by (stt, edt);
(2)写入ClickHouse
//TODO 写入ClickHouse resultDS.addSink(MyClickHouseUtil.getClickHouseSink("insert into dws_trade_order_window values(?,?,?,?,?,?,?,?)"));
交易域品牌-品类-用户-SPU粒度下单各窗口汇总表
从 Kafka 订单明细主题读取数据,过滤 null 数据并按照唯一键对数据去重,关联维度信息,按照维度分组,统计各维度各窗口的订单数和订单金额,将数据写入 ClickHouse 交易域品牌-品类-用户-SPU粒度下单各窗口汇总表。
主要任务
1)获取过滤后的OrderDetail表
2)转换数据结构
3)编写DIM工具类
4)优化-旁路缓存
5)关联维表-异步IO
6)分组开窗聚合
7)写入ClickHouse
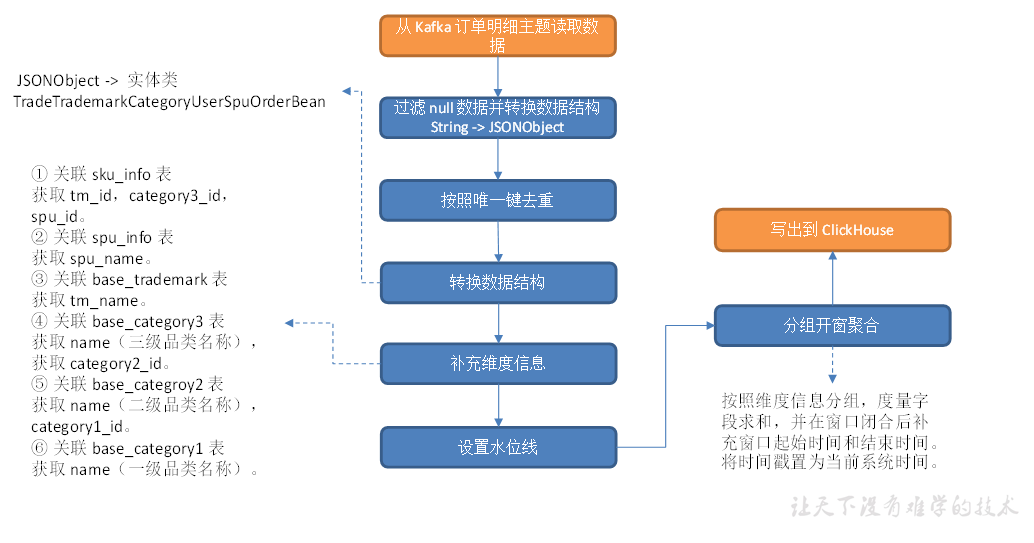
获取过滤后的OrderDetail表
(1)提取公共方法
public class OrderDetailFilterFunction { public static SingleOutputStreamOperator<JSONObject> getDwdOrderDetail(StreamExecutionEnvironment env, String groupId){ //TODO 读取Kafka DWD 订单明细 主题数据 String topic = "dwd_trade_order_detail"; DataStreamSource<String> orderDetailStrDS = env.addSource(MyKafkaUtil.getKafkaConsumer(topic, groupId)); //TODO 过滤数据 转换数据为JSON格式 SingleOutputStreamOperator<JSONObject> JSONObjDS = orderDetailStrDS.flatMap(new FlatMapFunction<String, JSONObject>() { @Override public void flatMap(String value, Collector<JSONObject> out) throws Exception { if (!"".equals(value)) { JSONObject jsonObject = JSON.parseObject(value); out.collect(jsonObject); } } }); //TODO 按照order_detail_id分组 KeyedStream<JSONObject, String> keyedStream = JSONObjDS.keyBy(jsonObject -> jsonObject.getString("order_detail_id")); //TODO 去重 SingleOutputStreamOperator<JSONObject> orderDetailJSONObjDS = keyedStream.process(new KeyedProcessFunction<String, JSONObject, JSONObject>() { private ValueState<JSONObject> orderDetailState; @Override public void open(Configuration parameters) throws Exception { orderDetailState = getRuntimeContext().getState(new ValueStateDescriptor<JSONObject>("order-detail", JSONObject.class)); } @Override public void processElement(JSONObject value, Context ctx, Collector<JSONObject> out) throws Exception { JSONObject orderDetail = orderDetailState.value(); if (orderDetail == null) { orderDetailState.update(value); ctx.timerService().registerProcessingTimeTimer(ctx.timerService().currentProcessingTime() + 2000L); } else { String stateTs = orderDetail.getString("row_op_ts"); String curTs = value.getString("row_op_ts"); int compare = TimestampLtz3CompareUtil.compare(stateTs, curTs); if (compare != 1) { orderDetailState.update(value); } } } @Override public void onTimer(long timestamp, OnTimerContext ctx, Collector<JSONObject> out) throws Exception { JSONObject orderDetail = orderDetailState.value(); out.collect(orderDetail); } }); return orderDetailJSONObjDS; } }
(2)调用这个公共方法过滤
//TODO 获取过滤后的OrderDetail表 String groupId = "sku_user_order_window"; SingleOutputStreamOperator<JSONObject> orderDetailJSONObjDS = OrderDetailFilterFunction.getDwdOrderDetail(env, groupId);
转换数据结构
(1)自定义JavaBean
@Data @AllArgsConstructor @Builder public class TradeTrademarkCategoryUserSpuOrderBean { // 窗口起始时间 String stt; // 窗口结束时间 String edt; // 品牌 ID String trademarkId; // 品牌名称 String trademarkName; // 一级品类 ID String category1Id; // 一级品类名称 String category1Name; // 二级品类 ID String category2Id; // 二级品类名称 String category2Name; // 三级品类 ID String category3Id; // 三级品类名称 String category3Name; // sku_id @TransientSink String skuId;
//order_id去重 @TransientSink Set<String> orderIdSet; // 用户 ID String userId; // spu_id String spuId; // spu 名称 String spuName; // 下单次数 Long orderCount; // 下单金额 Double orderAmount; // 时间戳 Long ts; public static void main(String[] args) { TradeTrademarkCategoryUserSpuOrderBean build = builder().build(); System.out.println(build); } }
注意:使用@TransientSink,在写入ClickHouse时屏蔽该字段;使用构造者设计模式,方便创建只有部分属性的对象
(2)转换数据结构
//TODO 转换数据为JavaBean SingleOutputStreamOperator<TradeTrademarkCategoryUserSpuOrderBean> skuUserOrderDS = orderDetailJSONObjDS.map(json -> TradeTrademarkCategoryUserSpuOrderBean.builder() .skuId(json.getString("sku_id")) .userId(json.getString("user_id")) .orderCount(1L) .orderAmount(json.getDouble("split_total_amount")) .ts(DateFormatUtil.toTs(json.getString("create_time"), true)) .build());
注意:orderCount直接置为1会有重复数据,可以使用set辅助,后续聚合时去重
//TODO 转换数据为JavaBean SingleOutputStreamOperator<TradeTrademarkCategoryUserSpuOrderBean> skuUserOrderDS = orderDetailJSONObjDS.map(json->{ HashSet<String> orderIds = new HashSet<String>(); orderIds.add(json.getString("order_id")); return TradeTrademarkCategoryUserSpuOrderBean.builder() .skuId(json.getString("sku_id")) .userId(json.getString("user_id")) .orderIdSet(orderIds) .orderAmount(json.getDouble("split_total_amount")) .ts(DateFormatUtil.toTs(json.getString("create_time"), true)) .build(); });
编写DIM工具类
(1)编写JDBC工具类
public class JdbcUtil { public static <T> List<T> queryList(Connection connection, String querySql, Class<T> clz, boolean underScoreToCamel) throws Exception{ ArrayList<T> list = new ArrayList<>(); //预编译SQL PreparedStatement preparedStatement = connection.prepareStatement(querySql); //查询 ResultSet resultSet = preparedStatement.executeQuery(); //处理结果集 ResultSetMetaData metaData = resultSet.getMetaData(); int columnCount = metaData.getColumnCount(); while (resultSet.next()){ //行遍历 T t = clz.newInstance(); for (int i = 0; i < columnCount; i++) {//列遍历 //列名 String columnName = metaData.getColumnName(i + 1); //列值 Object value = resultSet.getObject(columnName); //转换列名 if(underScoreToCamel){ columnName = CaseFormat.LOWER_UNDERSCORE.to(CaseFormat.LOWER_CAMEL, columnName.toLowerCase()); } //对象赋值 BeanUtils.setProperty(t, columnName, value); } list.add(t); } //释放资源 resultSet.close(); preparedStatement.close(); return list; } }
(2)编写DIM工具类
public class DimUtil { public static JSONObject getDimInfo(Connection connection, String tableName, String id) throws Exception { String querySql = "select * from " + GmallConfig.HBASE_SCHEMA + "." + tableName + " where id = '" + id + "'"; List<JSONObject> list = JdbcUtil.queryList(connection, querySql, JSONObject.class, false); return list.get(0); } }
优化-旁路缓存
(1)修改DIM工具类
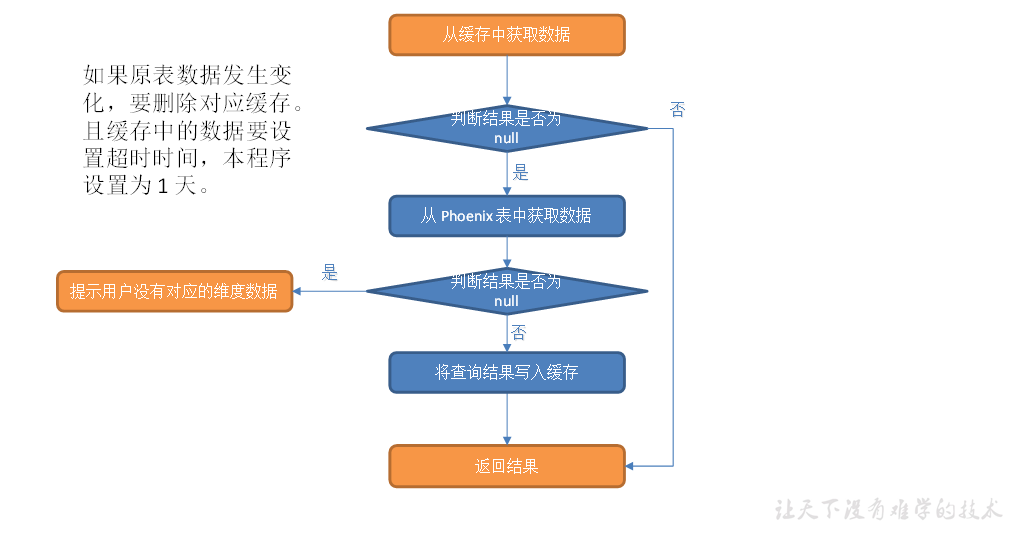
public class DimUtil { public static JSONObject getDimInfo(Connection connection, String tableName, String id) throws Exception { //查询redis Jedis jedis = JedisUtil.getJedis(); String redisKey = "DIM:" + tableName + ":" + id; String dimInfoStr = jedis.get(redisKey); if(dimInfoStr != null){ jedis.expire(redisKey, 24 * 60 * 60); jedis.close(); return JSON.parseObject(dimInfoStr); } //查询Phoenix String querySql = "select * from " + GmallConfig.HBASE_SCHEMA + "." + tableName + " where id = '" + id + "'"; List<JSONObject> list = JdbcUtil.queryList(connection, querySql, JSONObject.class, false); JSONObject dimInfo = list.get(0); //写入redis jedis.set(redisKey, dimInfo.toJSONString()); jedis.expire(redisKey, 24 * 60 * 60); jedis.close(); //返回结果 return dimInfo; } public static void delDimInfo(String tableName, String id){ Jedis jedis = JedisUtil.getJedis(); String redisKey = "DIM:" + tableName + ":" + id; jedis.del(redisKey); jedis.close(); } }
注意:缓存要设置过期时间;要考虑维度数据变化;
(2)修改DimSinkFunction,更新时删除缓存
public class DimSinkFunction extends RichSinkFunction<JSONObject> { private Connection connection; @Override public void open(Configuration parameters) throws Exception { connection = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER); } @Override public void invoke(JSONObject value, Context context) throws Exception { PreparedStatement preparedStatement = null; try { String sinkTable = value.getString("sinkTable"); JSONObject data = value.getJSONObject("data"); String sql = genUpsertSql(sinkTable, data); preparedStatement = connection.prepareStatement(sql); //如果当前为更新数据,则需要删除redis缓存 if("update".equals(value.getString("type"))){ DimUtil.delDimInfo(sinkTable.toUpperCase(), data.getString("id")); } preparedStatement.execute(); connection.commit(); } catch (SQLException e) { System.out.println("插入数据失败"); } finally { if(preparedStatement != null){ preparedStatement.close(); } } } private String genUpsertSql(String sinkTable, JSONObject data) { Set<String> columns = data.keySet(); Collection<Object> values = data.values(); return "upsert into " + GmallConfig.HBASE_SCHEMA + "." + sinkTable + "(" + StringUtils.join(columns,",") + ") values ('" + StringUtils.join(values,"','") + "')"; } }
关联维表-异步IO
当与外部系统交互时,需要注意与外部系统的通信延迟。简单地访问外部数据库中的数据,例如MapFunction中的数据,通常意味着同步交互:向数据库发送请求,MapFunction等待直到收到响应。在许多情况下,这种等待占据了函数的绝大多数时间。
而异步IO意味着单个并行函数实例可以同时处理多个请求并同时接收响应。这样,等待时间可以与发送其他请求和接收响应重叠。至少,等待时间是在多个请求中摊销的。这在大多数情况下会导致更高的流吞吐量。
实现异步I/O需要数据库的客户端支持异步请求。
如果没有,可以通过创建多个客户机并使用线程池处理同步调用,尝试将同步客户机转变为有限的并发客户机。然而,这种方法的效率通常低于适当的异步客户机。
(1)编写线程池工具类
public class ThreadPoolUtil { private static ThreadPoolExecutor threadPoolExecutor = null; private ThreadPoolUtil() { } public static ThreadPoolExecutor getThreadPoolExecutor() { //双重校验 if (threadPoolExecutor == null) { synchronized (ThreadPoolUtil.class){ if (threadPoolExecutor == null) { threadPoolExecutor = new ThreadPoolExecutor( 4,//核心线程数 20,//等待队列满了才会创建 60,//空闲线程回收时间 TimeUnit.SECONDS, new LinkedBlockingDeque<>()//线程不够,等待队列 ); } } } return threadPoolExecutor; } }
(2)编写维度关联异步方法
public abstract class DimAsyncFunction<T> extends RichAsyncFunction<T, T> implements DimJoinFunction<T>{ private Connection connection; private ThreadPoolExecutor threadPoolExecutor; private String tableName; public DimAsyncFunction(String tableName) { this.tableName = tableName; } @Override public void open(Configuration parameters) throws Exception { connection = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER); threadPoolExecutor = ThreadPoolUtil.getThreadPoolExecutor(); } @Override public void asyncInvoke(T input, ResultFuture<T> resultFuture) throws Exception { threadPoolExecutor.execute(new Runnable() { @SneakyThrows @Override public void run() { //查询维表数据 JSONObject dimInfo = DimUtil.getDimInfo(connection, tableName, getKey(input)); //补充JavaBean join(input, dimInfo); //输出 resultFuture.complete(Collections.singletonList(input)); } }); } @Override public void timeout(T input, ResultFuture<T> resultFuture) throws Exception { //再次查询补充信息 System.out.println("timeout:" + input); } }
注意:这里使用了泛型、抽象类、接口,使得在调用时,利用确定的信息补充方法
public interface DimJoinFunction<T> { public String getKey(T input); public void join(T input, JSONObject dimInfo); }
(3)关联维度
//TODO 关联维表-异步IO //关联DIM_SKU_INFO SingleOutputStreamOperator<TradeTrademarkCategoryUserSpuOrderBean> withSkuDS = AsyncDataStream.unorderedWait( skuUserOrderDS, new DimAsyncFunction<TradeTrademarkCategoryUserSpuOrderBean>("DIM_SKU_INFO") { @Override public String getKey(TradeTrademarkCategoryUserSpuOrderBean input) { return input.getSkuId(); } @Override public void join(TradeTrademarkCategoryUserSpuOrderBean input, JSONObject dimInfo) { if (dimInfo != null) { input.setSpuId(dimInfo.getString("SPU_ID")); input.setTrademarkId(dimInfo.getString("TM_ID")); input.setCategory3Id(dimInfo.getString("CATEGORY4_ID")); } } }, 60, TimeUnit.SECONDS ); //关联DIM_SPU_INFO //关联DIM_BASE_TRADEMARK //关联DIM_BASE_CATEGORY3 //关联DIM_BASE_CATEGORY2 //关联DIM_BASE_CATEGORY1
分组开窗聚合
//TODO 提取时间戳生成Watermark SingleOutputStreamOperator<TradeTrademarkCategoryUserSpuOrderBean> tradeTrademarkCategoryUserSpuOrderWithWmDS = withCategory1DS.assignTimestampsAndWatermarks( WatermarkStrategy.<TradeTrademarkCategoryUserSpuOrderBean>forBoundedOutOfOrderness(Duration.ofSeconds(2)) .withTimestampAssigner(new SerializableTimestampAssigner<TradeTrademarkCategoryUserSpuOrderBean>() { @Override public long extractTimestamp(TradeTrademarkCategoryUserSpuOrderBean element, long l) { return element.getTs(); } })); //TODO 分组开窗聚合 KeyedStream<TradeTrademarkCategoryUserSpuOrderBean, String> keyedStream = tradeTrademarkCategoryUserSpuOrderWithWmDS.keyBy(new KeySelector<TradeTrademarkCategoryUserSpuOrderBean, String>() { @Override public String getKey(TradeTrademarkCategoryUserSpuOrderBean value) throws Exception { return value.getUserId() + "-" + value.getCategory1Id() + "-" + value.getCategory1Name() + "-" + value.getCategory2Id() + "-" + value.getCategory2Name() + "-" + value.getCategory3Id() + "-" + value.getCategory3Name() + "-" + value.getSpuId() + "-" + value.getSpuName() + "-" + value.getTrademarkId() + "-" + value.getTrademarkName(); } }); WindowedStream<TradeTrademarkCategoryUserSpuOrderBean, String, TimeWindow> windowedStream = keyedStream.window(TumblingEventTimeWindows.of(org.apache.flink.streaming.api.windowing.time.Time.seconds(10))); SingleOutputStreamOperator<TradeTrademarkCategoryUserSpuOrderBean> resultDS = windowedStream.reduce(new ReduceFunction<TradeTrademarkCategoryUserSpuOrderBean>() { @Override public TradeTrademarkCategoryUserSpuOrderBean reduce(TradeTrademarkCategoryUserSpuOrderBean value1, TradeTrademarkCategoryUserSpuOrderBean value2) throws Exception { value1.setOrderCount(value1.getOrderCount() + value2.getOrderCount()); value1.setOrderAmount(value1.getOrderAmount() + value2.getOrderAmount());
//去重
value1.getOrderIdSet().addAll(value2.getOrderIdSet()); return value1; } }, new WindowFunction<TradeTrademarkCategoryUserSpuOrderBean, TradeTrademarkCategoryUserSpuOrderBean, String, TimeWindow>() { @Override public void apply(String s, TimeWindow window, Iterable<TradeTrademarkCategoryUserSpuOrderBean> input, Collector<TradeTrademarkCategoryUserSpuOrderBean> out) throws Exception { TradeTrademarkCategoryUserSpuOrderBean orderBean = input.iterator().next(); orderBean.setStt(DateFormatUtil.toYmdHms(window.getStart())); orderBean.setEdt(DateFormatUtil.toYmdHms(window.getEnd())); orderBean.setTs(System.currentTimeMillis());
orderBean.setOrderCount((long)orderBean.getOrderIdSet().size()); out.collect(orderBean); } });
写入ClickHouse
(1)建表
drop table if exists dws_trade_trademark_category_user_spu_order_window; create table if not exists dws_trade_trademark_category_user_spu_order_window ( stt DateTime, edt DateTime, trademark_id String, trademark_name String, category1_id String, category1_name String, category2_id String, category2_name String, category3_id String, category3_name String, user_id String, spu_id String, spu_name String, order_count UInt64, order_amount Decimal(38, 20), ts UInt64 ) engine = ReplacingMergeTree(ts) partition by toYYYYMMDD(stt) order by (stt, edt, trademark_id, trademark_name, category1_id, category1_name, category2_id, category2_name, category3_id, category3_name, user_id);
(2)写入ClickHouse
//TODO 写出到ClickHouse resultDS.addSink(MyClickHouseUtil.getClickHouseSink("insert into dws_trade_trademark_category_user_spu_order_window values(?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)"));
交易域省份粒度下单各窗口汇总表
从 Kafka 读取订单明细数据,过滤 null 数据并按照唯一键对数据去重,统计各省份各窗口订单数和订单金额,将数据写入 ClickHouse 交易域省份粒度下单各窗口汇总表。
主要任务
1)获取过滤后的OrderDetail表
2)转换数据结构
3)分组开窗聚合
4)关联维表
5)写入ClickHouse
注意:这里可以先分组开窗聚合,再关联维表,减少数据量
交易域支付各窗口汇总表
从 Kafka 读取交易域支付成功主题数据,统计支付成功独立用户数和首次支付成功用户数。
主要任务
1)过滤 null 数据并去重
2)统计支付成功独立用户数和首次支付成功用户数
3)写入 ClickHouse
注意:去重可以不用定时器,直接状态编程取第一条。因为后续需求中不需要上游关联的属性。
//TODO 按照唯一键分组 KeyedStream<JSONObject, String> keyedByDetailIdStream = jsonObjDS.keyBy(json -> json.getString("order_detail_id")); //TODO 状态编程去重 SingleOutputStreamOperator<JSONObject> filterDS = keyedByDetailIdStream.filter(new RichFilterFunction<JSONObject>() { private ValueState<String> valueState; @Override public void open(Configuration parameters) throws Exception { ValueStateDescriptor<String> descriptor = new ValueStateDescriptor<>("value", String.class); StateTtlConfig stateTtlConfig = new StateTtlConfig.Builder(Time.seconds(5)) .setUpdateType(StateTtlConfig.UpdateType.OnReadAndWrite) .build();
//设置状态TTL,因为上游重复数据是紧挨着的,可以设置一个小的TTL descriptor.enableTimeToLive(stateTtlConfig); valueState = getRuntimeContext().getState(descriptor); } @Override public boolean filter(JSONObject value) throws Exception { String state = valueState.value(); if (state == null) { valueState.update("1"); return true; } else { return false; } } });
交易域品牌-品类-用户粒度退单各窗口汇总表
从 Kafka 读取退单明细数据,过滤 null 数据并按照唯一键对数据去重,关联维度信息,按照维度分组,统计各维度各窗口的退单数,将数据写入 ClickHouse 交易域品牌-品类-用户粒度退单各窗口汇总表。
主要任务
1)过滤 null 数据并按照唯一键对数据去重
2)转换数据结构
3)关联维表
4)分组开窗聚合
5)写入ClickHouse
ADS
流量主题
各渠道流量统计
|
统计周期 |
统计粒度 |
指标 |
说明 |
|
当日 |
渠道 |
独立访客数 |
统计访问人数 |
|
当日 |
渠道 |
会话总数 |
统计会话总数 |
|
当日 |
渠道 |
会话平均浏览页面数 |
统计每个会话平均浏览页面数 |
|
当日 |
渠道 |
会话平均停留时长 |
统计每个会话平均停留时长 |
|
当日 |
渠道 |
跳出率 |
只有一个页面的会话的比例 |
select toYYYYMMDD(stt) dt, ch, sum(uv_ct) uv_ct, sum(sv_ct) sv_ct, sum(pv_ct) / sv_ct pv_per_session, sum(dur_sum) / sv_ct dur_per_session, sum(uj_ct) / sv_ct uj_rate from dws_traffic_channel_page_view_window where toYYYYMMDD(stt) = toYYYYMMDD(cast('2022-02-21 12:00:00' as DateTime)) group by toYYYYMMDD(stt), ch;
关键词统计
|
统计周期 |
统计粒度 |
指标 |
说明 |
|
当日 |
关键词 |
关键词评分 |
根据不同来源和频次计算得分 |
select toYYYYMMDD(stt) dt, keyword, sum(keyword_count * multiIf( source = 'SEARCH', 10, source = 'ORDER', 5, source = 'CART', 2, source = 'CLICK', 1, 0 )) keyword_count from dws_traffic_source_keyword_page_view_window where toYYYYMMDD(stt) = toYYYYMMDD(cast('2022-06-14 12:00:00' as DateTime)) group by toYYYYMMDD(stt), keyword;
用户主题
用户变动统计
|
统计周期 |
指标 |
说明 |
|
当日 |
回流用户数 |
之前的活跃用户,一段时间未活跃(流失),今日又活跃了,就称为回流用户。此处要求统计回流用户总数。 |
select toYYYYMMDD(stt) dt, sum(back_ct) back_ct from dws_user_user_login_window where toYYYYMMDD(stt) = toYYYYMMDD(cast('2022-06-14 12:00:00' as DateTime)) group by toYYYYMMDD(stt);
用户新增活跃统计
|
统计周期 |
指标 |
指标说明 |
|
当日 |
新增用户数 |
略 |
|
当日 |
活跃用户数 |
略 |
select t1.dt, uu_ct, register_ct from (select toYYYYMMDD(stt) dt, sum(uu_ct) uu_ct from dws_user_user_login_window where toYYYYMMDD(stt) = toYYYYMMDD(cast('2022-06-14 12:00:00' as DateTime)) group by toYYYYMMDD(stt)) t1 full outer join ( select toYYYYMMDD(stt) dt, sum(register_ct) register_ct from dws_user_user_register_window where toYYYYMMDD(stt) = toYYYYMMDD(cast('2022-02-21 12:00:00' as DateTime)) group by toYYYYMMDD(stt)) t2 on t1.dt = t2.dt;
用户行为漏斗分析
|
统计周期 |
指标 |
说明 |
|
当日 |
首页浏览人数 |
略 |
|
当日 |
商品详情页浏览人数 |
略 |
|
当日 |
加购人数 |
略 |
|
当日 |
下单人数 |
略 |
|
当日 |
支付人数 |
支付成功人数 |
(1)当日首页浏览人数及当日商品详情页浏览人数
select toYYYYMMDD(stt) dt, sum(home_uv_ct) home_uv_count, sum(good_detail_uv_ct) good_detail_uv_ct from dws_traffic_page_view_window where toYYYYMMDD(stt) = toYYYYMMDD(cast('2022-06-14 12:00:00' as DateTime)) group by toYYYYMMDD(stt);
(2)当日加购人数
select toYYYYMMDD(stt) dt, sum(cart_add_uu_ct) cart_add_uu_ct from dws_trade_cart_add_uu_window where toYYYYMMDD(stt) = toYYYYMMDD(cast('2022-06-14 12:00:00' as DateTime)) group by toYYYYMMDD(stt);
(3)当日下单人数
select toYYYYMMDD(stt) dt, sum(order_unique_user_count) order_uu_count from dws_trade_order_window where toYYYYMMDD(stt) = toYYYYMMDD(cast('2022-02-21 12:00:00' as DateTime)) group by toYYYYMMDD(stt);
(4)当日支付人数
select toYYYYMMDD(stt) dt, sum(payment_suc_unique_user_count) payment_suc_uu_count from dws_trade_payment_suc_window where toYYYYMMDD(stt) = toYYYYMMDD(cast('2022-02-21 12:00:00' as DateTime)) group by toYYYYMMDD(stt);
新增交易用户统计
|
统计周期 |
指标 |
说明 |
|
当日 |
新增下单人数 |
略 |
|
当日 |
新增支付人数 |
略 |
select dt, order_new_user_count, pay_suc_new_user_count from (select toYYYYMMDD(stt) dt, sum(order_new_user_count) order_new_user_count from dws_trade_order_window where toYYYYMMDD(stt) = toYYYYMMDD(cast('2022-02-21 12:00:00' as DateTime)) group by toYYYYMMDD(stt)) oct full outer join (select toYYYYMMDD(stt) dt, sum(payment_new_user_count) pay_suc_new_user_count from dws_trade_payment_suc_window where toYYYYMMDD(stt) = toYYYYMMDD(cast('2022-02-21 12:00:00' as DateTime)) group by toYYYYMMDD(stt)) pay_suc on oct.dt = pay_suc.dt;
商品主题
各品牌商品交易统计
|
统计周期 |
统计粒度 |
指标 |
说明 |
|
当日 |
品牌 |
订单数 |
略 |
|
当日 |
品牌 |
订单人数 |
略 |
|
当日 |
品牌 |
退单数 |
略 |
|
当日 |
品牌 |
退单人数 |
略 |
select dt, trademark_id, trademark_name, order_count, uu_count, order_amount, refund_count, refund_uu_count from (select toYYYYMMDD(stt) dt, trademark_id, trademark_name, sum(order_count) order_count, count(distinct user_id) uu_count, sum(order_amount) order_amount from dws_trade_trademark_category_user_spu_order_window where toYYYYMMDD(stt) = toYYYYMMDD(cast('2022-02-21 12:00:00' as DateTime)) group by toYYYYMMDD(stt), trademark_id, trademark_name) oct full outer join (select toYYYYMMDD(stt) dt, trademark_id, trademark_name, sum(refund_count) refund_count, count(distinct user_id) refund_uu_count from dws_trade_trademark_category_user_refund_window where toYYYYMMDD(stt) = toYYYYMMDD(cast('2022-02-21 12:00:00' as DateTime)) group by toYYYYMMDD(stt), trademark_id, trademark_name) rct on oct.dt = rct.dt and oct.trademark_id = rct.trademark_id;
各品类商品交易统计
|
统计周期 |
统计粒度 |
指标 |
说明 |
|
当日 |
品类 |
订单数 |
略 |
|
当日 |
品类 |
订单人数 |
略 |
|
当日 |
品类 |
订单金额 |
略 |
|
当日 |
品类 |
退单数 |
略 |
|
当日 |
品类 |
退单人数 |
略 |
select dt, category1_id, category1_name, category2_id, category2_name, category3_id, category3_name, order_count, uu_count, order_amount, refund_count, refund_uu_count from (select toYYYYMMDD(stt) dt, category1_id, category1_name, category2_id, category2_name, category3_id, category3_name, sum(order_count) order_count, count(distinct user_id) uu_count, sum(order_amount) order_amount from dws_trade_trademark_category_user_spu_order_window where toYYYYMMDD(stt) = toYYYYMMDD(cast('2022-02-21 12:00:00' as DateTime)) group by toYYYYMMDD(stt), category1_id, category1_name, category2_id, category2_name, category3_id, category3_name) oct full outer join (select toYYYYMMDD(stt) dt, category1_id, category1_name, category2_id, category2_name, category3_id, category3_name, sum(refund_count) refund_count, count(distinct user_id) refund_uu_count from dws_trade_trademark_category_user_refund_window where toYYYYMMDD(stt) = toYYYYMMDD(cast('2022-02-21 12:00:00' as DateTime)) group by toYYYYMMDD(stt), category1_id, category1_name, category2_id, category2_name, category3_id, category3_name) rct on oct.dt = rct.dt and oct.category1_id = rct.category1_id and oct.category2_id = rct.category2_id and oct.category3_id = rct.category3_id;
各 SPU 商品交易统计
select toYYYYMMDD(stt) dt, spu_id, spu_name, sum(order_count) order_count, count(distinct user_id) uu_count, sum(order_amount) order_amount from dws_trade_trademark_category_user_spu_order_window where toYYYYMMDD(stt) = toYYYYMMDD(cast('2022-02-21 12:00:00' as DateTime)) group by toYYYYMMDD(stt), spu_id, spu_name;
交易主题
交易综合统计
|
统计周期 |
指标 |
说明 |
|
当日 |
订单总额 |
订单最终金额 |
|
当日 |
订单数 |
略 |
|
当日 |
订单人数 |
略 |
|
当日 |
退单数 |
略 |
|
当日 |
退单人数 |
略 |
(1)当日订单总额
select toYYYYMMDD(stt) dt, sum(order_amount) order_total_amount from dws_trade_province_order_window where toYYYYMMDD(stt) = toYYYYMMDD(cast('2022-02-21 12:00:00' as DateTime)) group by toYYYYMMDD(stt);
(2)当日订单数与当日订单人数
select toYYYYMMDD(stt) dt, sum(order_count) order_count, count(distinct user_id) order_uu_count from dws_trade_trademark_category_user_spu_order_window where toYYYYMMDD(stt) = toYYYYMMDD(cast('2022-02-21 12:00:00' as DateTime)) group by toYYYYMMDD(stt);
(3)当日退单数与当日退单人数
select toYYYYMMDD(stt) dt, sum(refund_count) refund_count, count(distinct user_id) refund_uu_count from dws_trade_trademark_category_user_refund_window where toYYYYMMDD(stt) = toYYYYMMDD(cast('2022-02-21 12:00:00' as DateTime)) group by toYYYYMMDD(stt);
各省份交易统计
|
统计周期 |
统计粒度 |
指标 |
说明 |
|
当日 |
省份 |
订单数 |
略 |
|
当日 |
省份 |
订单金额 |
略 |
select toYYYYMMDD(stt) dt, province_id, province_name, sum(order_count) order_count, sum(order_amount) order_amount from dws_trade_province_order_window where toYYYYMMDD(stt) = toYYYYMMDD(cast('2022-02-21 12:00:00' as DateTime)) group by toYYYYMMDD(stt), province_id, province_name;
优惠券主题
当日优惠券补贴率
|
统计周期 |
统计粒度 |
指标 |
说明 |
|
当日 |
优惠券 |
补贴率 |
用券的订单明细优惠券减免金额总和/原始金额总和 |
select toYYYYMMDD(stt) dt, sum(order_coupon_reduce_amount) coupon_reduce_amount, sum(order_origin_total_amount) origin_total_amount, round(round(toFloat64(coupon_reduce_amount), 5) / round(toFloat64(origin_total_amount), 5), 20) coupon_subsidy_rate from dws_trade_order_window where toYYYYMMDD(stt) = toYYYYMMDD(cast('2022-02-21 12:00:00' as DateTime)) group by toYYYYMMDD(stt);
活动主题
当日活动补贴率
|
统计周期 |
统计粒度 |
指标 |
说明 |
|
当日 |
活动 |
补贴率 |
参与促销活动的订单明细活动减免金额总和/原始金额总和 |
select toYYYYMMDD(stt) dt, sum(order_activity_reduce_amount) activity_reduce_amount, sum(order_origin_total_amount) origin_total_amount, round(round(toFloat64(activity_reduce_amount), 5) / round(toFloat64(origin_total_amount), 5), 20) subsidyRate from dws_trade_order_window where toYYYYMMDD(stt) = toYYYYMMDD(cast('2022-02-21 12:00:00' as DateTime)) group by toYYYYMMDD(stt);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号