
SparkStreaming实时数仓
总体架构
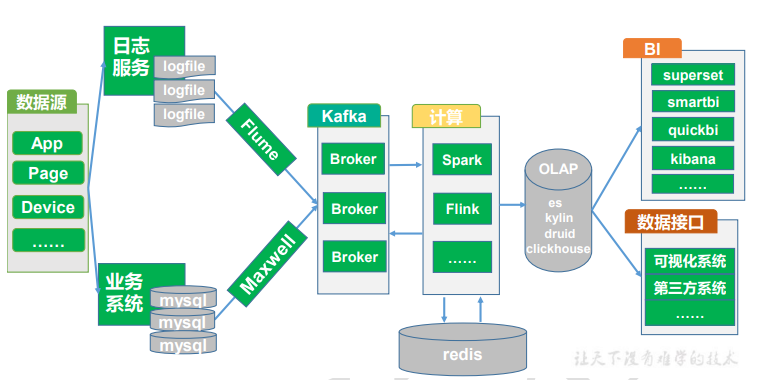
日志数据采集和分流
整体架构(ODS-DWD)
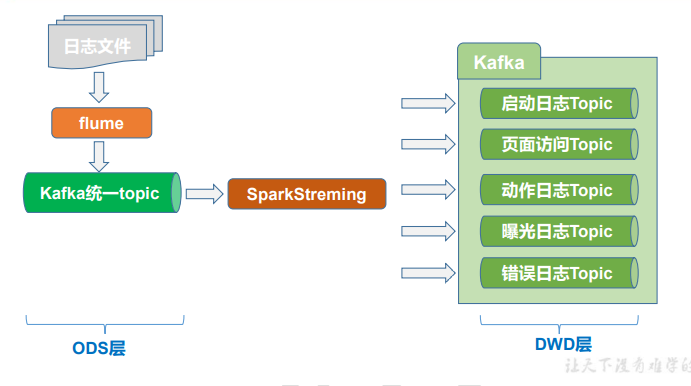
日志数据采集
HTTP模式
日志数据发往日志服务器,由Flume采集到Kafka
适用于离线数仓,采集后能进行数据清洗工作
Kafka模式
日志数据直接发往Kafka
适用于实时数仓,省去数据采集过程,低延迟
日志数据消费分流
1)准备实时处理环境
并行度与Kafka分区数保持一致
2)从Kafka消费数据
Kafka工具类编写:使用默认offset消费数据、使用默认分区策略生产数据
Properties工具类编写
3)数据结构转换
fastjson工具类的使用
String->JSONObject:JSON.parseObject(log)
String->Object:JSON.parseObject(value, classOf[PageLog])
Object->String:JSON.toJSONString(displayLog,new SerializeConfig(true))(不使用get/set方法,直接操作字段)
JSONObject提取:jsonObj.getJSONObject("obj")、jsonObj.getString("str")、jsonObj.getJSONArray("arr")、jsonObj.getLong("ts")
4)数据分流并发送到Kafka
if(错误!=null){ 发送 错误 } else{ 提取 公共 字段 if(页面!=null){ 发送 公共+页面 发送 公共+曝光 发送 公共+动作 }
if(启动!=null){ 发送 公共+启动 } }
优化 - 精确一次消费
相关语义
1)至少一次消费(at least once) 主要是保证数据不会丢失,但有可能存在数据重复问题。
2)最多一次消费 (at most once) 主要是保证数据不会重复,但有可能存在数据丢失问题。
3)精确一次消费(Exactly-once) 指消息一定会被处理且只会被处理一次。不多不少就一次处理。如果达不到精确一次消 费,可能会达到另外两种情况。
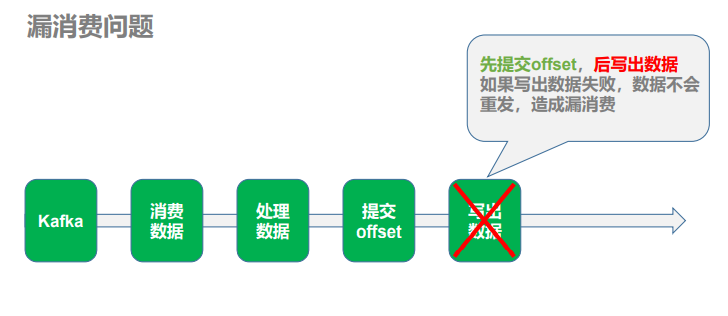
消费问题
1)漏消费
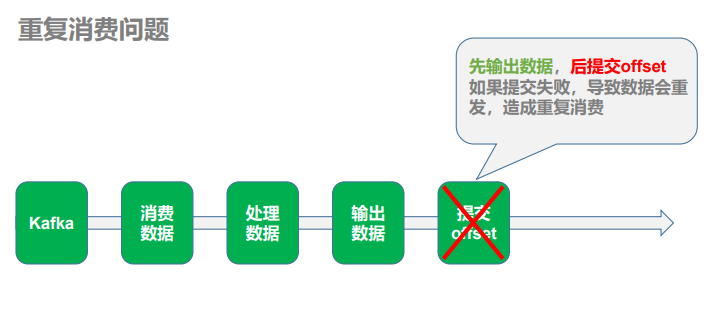
2)重复消费
问题解决-策略一
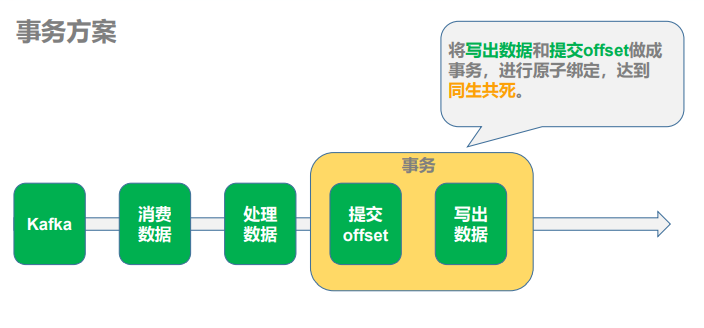
1)策略: 利用关系型数据库的事务进行处理
出现丢失或者重复的问题,核心就是偏移量的提交与数据的保存,不是原子性的。如果 能做成要么数据保存和偏移量都成功,要么两个失败,那么就不会出现丢失或者重复了。 这样的话可以把存数据和修改偏移量放到一个事务里。这样就做到前面的成功,如果后面做失败了,就回滚前面那么就达成了原子性,这种情况先存数据还是先修改偏移量没影响。
2)好处
事务方式能够保证精准一次性消费
3)问题与限制
(1)数据必须都要放在一个关系型数据库中,无法使用其他功能强大的 nosql 数据库
(2)事务本身性能不好
(3)如果保存的数据量较大一个数据库节点不够,多个节点的话,还要考虑分布式事务的问题。分布式事务会带来管理的复杂性,一般企业不选择使用,有的企业会把分布式事务变成本地事务,例如把 Executor 上的数据通过 rdd.collect 算子提取到 Driver 端,由 Driver 端统一写入数据库,这样会将分布式事务变成本地事务的单线程操作,降低了写入的吞吐量。
4)使用场景
数据足够少(通常经过聚合后的数据量都比较小,明细数据一般数据量都比较大),并且支持事务的数据库。
问题解决-策略二
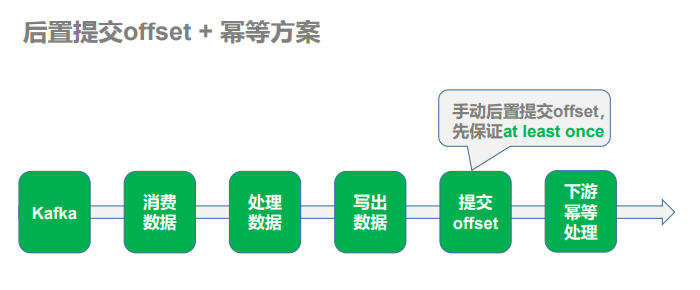
1)策略:手动提交偏移量 + 幂等性处理
首先解决数据丢失问题,办法就是要等数据保存成功后再提交偏移量,所以就必须手工 来控制偏移量的提交时机。
然后解决数据重复问题,把数据的保存做成幂等性保存。即同一批数据反复保存多次,数据不会翻倍,保存一次和保 存一百次的效果是一样的。如果能做到这个,就达到了幂等性保存,就不用担心数据会重复了。
2)难点
话虽如此,在实际的开发中手动提交偏移量其实不难,难的是幂等性的保存,有的时候 并不一定能保证,这个需要看使用的数据库,如果数据库本身不支持幂等性操作,那只能优 先保证的数据不丢失,数据重复难以避免,即只保证了至少一次消费的语义。 一般有主键的数据库都支持幂等性操作 upsert。
3)使用场景
处理数据较多,或者数据保存在不支持事务的数据库上。
手动提交偏移方案
1)使用KafkaDStream
xxDstream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
但是如果用这种方式管理偏移量,有一个限制就是在提交偏移量时,数据流的元素结构不能发生转变,即提交偏移量时数据流,必须是 InputDStream[ConsumerRecord[String, String]] 这种结构。但是在实际计算中,数据难免发生转变,或聚合,或关联,一旦发生转变,就无法在利用以下语句进行偏移量的提交。
因为 offset 的存储于 HasOffsetRanges,只有 kafkaRDD 继承了他,所以假如我们对 KafkaRDD 进行了转化之后,其它 RDD 没有继承 HasOffsetRanges,所以就无法再获取 offset 了。
2)使用工具管理offset
实际生产中通常会利用 ZooKeeper,Redis,Mysql 等工具手动对偏移量进行保存
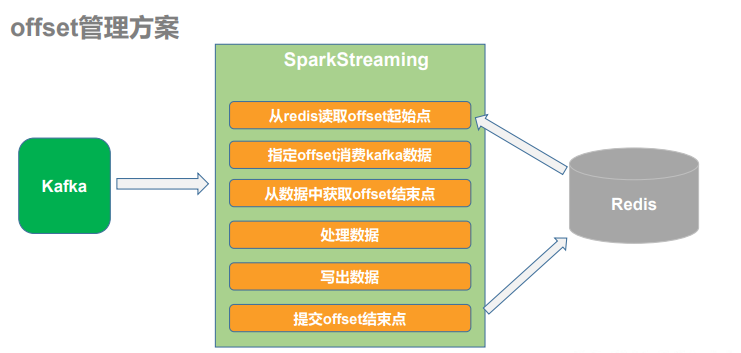
手动提交偏移实现
1)Redis工具类编写:用于从连接池中取Jedis对象
2)Offset工具类编写:用于往redis中存储和读取offset
Kafka中offset结构:key 是 group.id+topic+分区号,value 就是当前 offset 的值
存储在Redis的结构:hash,key 是 group.id+topic,value是 (分区号,offset)
需要的offset结构:Map[TopicPartition,Long]
知识点:redis中hash 写入hset 读取hget
3)Kafka工具类补充代码:可以使用指定的offset消费
4)主程序补充代码:
从Redis中读取offset,指定offset进行消费
val offsets: Map[TopicPartition, Long] = MyOffsetsUtils.readOffset(topicName, groupId) var kafkaDStream: InputDStream[ConsumerRecord[String, String]] = null if(offsets != null && offsets.nonEmpty){ kafkaDStream = MyKafkaUtils.getKafkaDStream(ssc, topicName, groupId,offsets) }else{ kafkaDStream = MyKafkaUtils.getKafkaDStream(ssc, topicName, groupId) }
提取offset(Driver)
var offsetRanges: Array[OffsetRange] = null
val offsetRangesDStream: DStream[ConsumerRecord[String, String]] = kafkaDStream.transform(
rdd => {
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}
)
注意:对rdd进行操作的就运行在worker节点,对DStream进行操作的就运行在driver节点,所以此处不需要对offsetRanges特殊处理
知识点:Transform 允许 DStream 上执行任意的 RDD-to-RDD 函数。
写出数据后提交offset(Driver)
MyOffsetsUtils.saveOffset(topicName, groupId, offsetRanges)
注意:提交offset的位置需要在jsonObjDStream.foreachRDD()里面,rdd.forech()外面。这样的话,提交操作在Driver端执行,且一批次数据提交一次
知识点:foreachRDD 是最通用的输出操作,即将函数 func 用于产生于 stream 的每一个 RDD。其中参数传入的函数 func 应该实现将每一个 RDD 中数据推送到外部系统,如将 RDD 存入文件或者通过网络将其写入数据库。
幂等性操作
目前处理完的数据写到了 kafka,如果程序出现宕机重试,kafka 是没有办法通过唯一性 标识实现幂等性识别,但是也没有关系,因为 kafka 中的数据只是用于中间存储,并不会进行 统计,所以只要保证不丢失即可,重复数据的幂等性处理可以交给下游处理,只要保证最终 统计结果是不会有重复即可。
优化 - kafka 消息发送问题
缓冲区问题
Kafka 消息的发送分为同步发送和异步发送。 Kafka 默认使用异步发送的方式。Kafka 的生产者将消息进行发送时,会先将消息发送到缓冲区中,待缓冲区写满或者到达指定的时间,才会真正的将缓冲区的数据写到 Broker。
假设消息发送到缓冲区中还未写到 Broker,我们认为数据已经成功写给了 Kafka,接下来会手动的提交 offset, 如果 offset 提交成功,但此刻 Kafka 集群突然出现故障。 缓冲区的 数据会丢失,最终导致的问题就是数据没有成功写到 Kafka ,而 offset 已经提交,此部分的数据就会被漏掉。
问题解决 – 策略一
将消息的发送修改为同步发送,保证每条数据都能发送到 Broker。 但带来的问题就是 消息是一条一条写给 Broker,会牺牲性能,一般不推荐。
问题解决 – 策略二
在手动提交 offset 之前,强制将缓冲区的数据 flush 到 broker
Kafka 的生产者对象提供了 flush 方法, 可以强制将缓冲区的数据刷到 Broker。
jsonObjDStream.foreachRDD( rdd=>{ rdd.foreachPartition( jsonObjIter=>{ for(jsonObj <- jsonObjIter){ 往Kafka发送数据 } //刷写 MyKafkaUtils.flush } ) //提交offset MyOffsetsUtils.saveOffset(topicName, groupId, offsetRanges) } )
注意:刷写的位置,即要保证在Executor端刷写,又要一批次地刷写。使用rdd.foreachPartition()代替rdd.foreach(),在foreachPartition中刷写
知识点:rdd.foreachPartition() 对每个分区单独处理
业务数据采集和分流
整体架构(ODS-DIM-DWD)
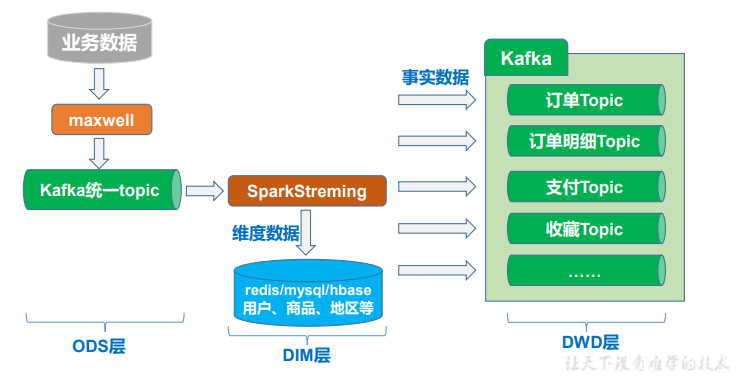
业务数据采集
使用Maxwall实时同步MySQL数据
Maxwall断点续传:在MySQL中创建Maxwell数据库存储 Maxwell 运行过程中的一些数据,包括 binlog 同步的断点位置等
业务数据消费分流
1)准备实时处理环境
2)从redis中读取偏移量
3)从kafka中消费数据
4)提取偏移量结束点
5)数据处理
6)刷写kafka缓冲区
7)提交offset
1)准备实时处理环境 2)从redis中读取偏移量 3)从kafka中消费数据 4)提取偏移量结束点 5)数据处理 val jsonObjDStream: DStream[JSONObject] = offsetRangesDStream.map(结构转换) //事实表清单 val factTables: Array[String] = Array[String](....) //维度表清单 val dimTables: Array[String] = Array[String](....) //分流 jsonObjDStream.foreachRDD( rdd => { rdd.foreachPartition( jsonObjIter => { for(jsonObj <- jsonObjIter){ 提取操作类型 if(opValue != null){ 提取表名 if(事实表) 写往kafka:DWD_tableName_opValue if(维度表) 连接redis,写往redis:string(DIM:tableName:id,data),关闭redis } } 6)刷写缓冲区 } ) 7)提交offset } )
注意1:
写往redis选择一条数据一个string
不选择一张表一个hash是因为 考虑到目前数据量大小、将来数据量增长、高频访问等问题
不选择一条数据一个hash是因为 处理麻烦,且没有相应的需求,比如拿某个字段
知识点:redis中string 写入set 读取get
注意2:
若维度表数据量太大,可以选择将维度数据存储在MySQL/HBase,并使用redis做缓存
优化 - 历史维度数据同步
1)使用maxwell-bootstrap 功能来进行历史数据的全量同步
2)增加操作类型,历史维度数据本身就属于维度数据,会分流到redis
val operType: String = jsonObj.getString("type")
val opValue: String = operType match {
case "bootstrap-insert" => "I"
case "insert" => "I"
case "update" => "U"
case "delete" => "D"
case _ => null
}
优化 - redis连接使用频繁
在foreachPartition里面,循环外面开关redis连接
说明:redis连接的开关和使用都在Executor端,且一批数据使用一个连接
rdd.foreachPartition( jsonObjIter => { 开启redis for(jsonObj <- jsonObjIter){分流} 关闭redis } )
优化 - 表清单动态维护
将表清单维护到redis中,实时任务动态的到redis获取
1)在foreachRDD里面,foreachPartition外面加载表清单
说明:一批次数据加载一次,但是注意表清单在Driver端加载,在Executor端使用,Driver会以task为单位传递表清单给Executor,并且传递的数据必须满足序列化
知识点:redis中set 写入sadd 读取smembers
jsonObjDStream.foreachRDD( rdd => { 连接redis,加载表清单,关闭连接 rdd.foreachPartition() } )
2)优化,使用广播变量,Driver会以Executor为单位传递表清单
val factTablesBC: Broadcast[util.Set[String]] = ssc.sparkContext.broadcast(factTables) val dimTablesBC: Broadcast[util.Set[String]] = ssc.sparkContext.broadcast(dimTables) //使用 if(factTablesBC.value.contains(tableName)){} if(dimTablesBC.value.contains(tableName)){}
优化 - 数据处理顺序性
在实时计算中,对业务数据的计算,要考虑到数据处理的顺序, 即能否依照数据改变的顺序进行处理。
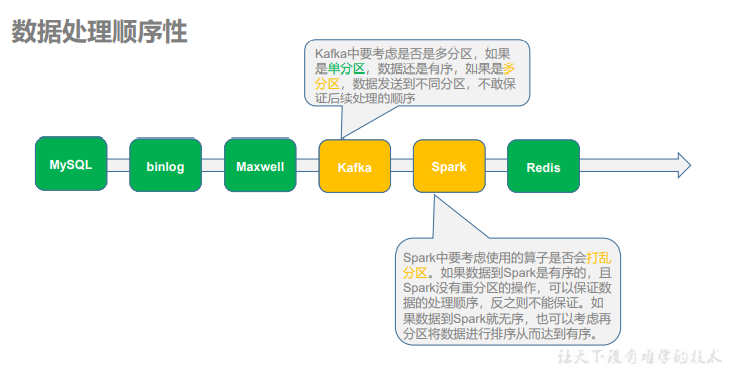
解决方法
通过分析,目前我们的计算过程中,只有可能在 Kafka 环节出现数据乱序,导致最终存储的结果不正确。如果想要保证数据处理的顺序性,我们可以将同一条数据的修改发往 topic 的同一个分区中。需要修改 maxwell 的配置文件,指定发送数据到 kafka 时要使用分区键key。
修改 config.properties 文件中的如下配置:
producer_partition_by=column producer_partition_columns=id producer_partition_by_fallback=table
DWD 到 DWS 层数据处理
整体架构(DWD-DWS)
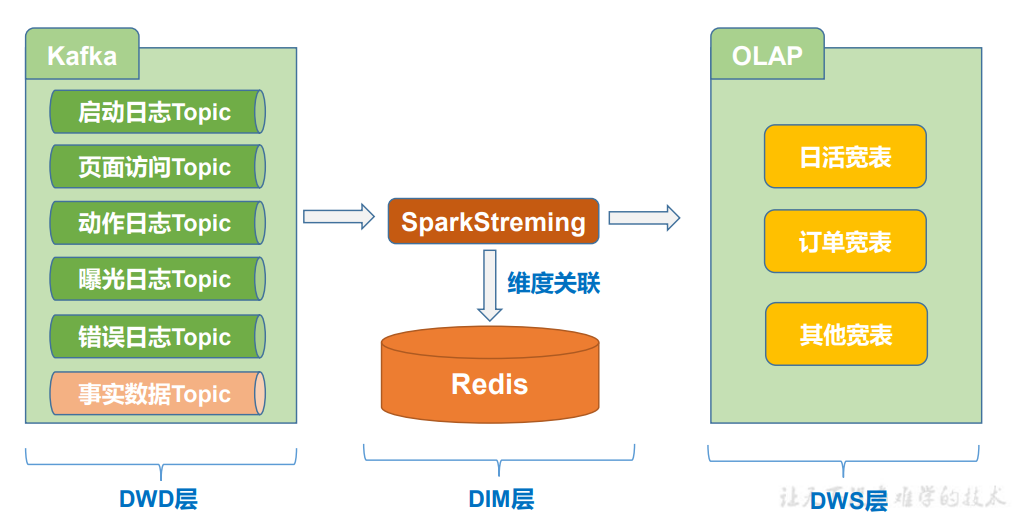
首先明确的是数据的聚合操作,一律交给 OLAP 来完成,因为 OLAP 数据库的特性都 是非常利于数据聚合统计的,可以说这也是 OLAP 的本职工作。
那么在此之前实时计算就要完成一些 OLAP 不是特别方便或者性能并不好的操作,比 如 JOIN 操作,比如分组去重(需要开窗)或者复杂的数据计算等等,实际情况还要看 OLAP 的选型。那这些工作可以交由实时计算完成。
从 ODS 到 DWD 层主要负责原始数据的整理拆分,形成一个一个的业务事实 topic。
从 DWD 层到 DWS 层主要负责把单个的业务事实 topic 变为面向统计的事实明细宽表, 然后保存到 OLAP 中
日活宽表
去重
日活的统计我们只需要考虑用户的首次访问行为,不同企业判断用户活跃的方式不同, 可以通过启动数据或者页面数据来分析,我们采用页面数据来统计日活,页面数据中包含用户所有的访问行为,而我们只需要首次访问行为,所以可以在每批次的数据中先将包含 有 last_page_id 的数据过滤掉, 剩下的数据再与第三方(redis)中所记录的今日访问用户 进行比对。
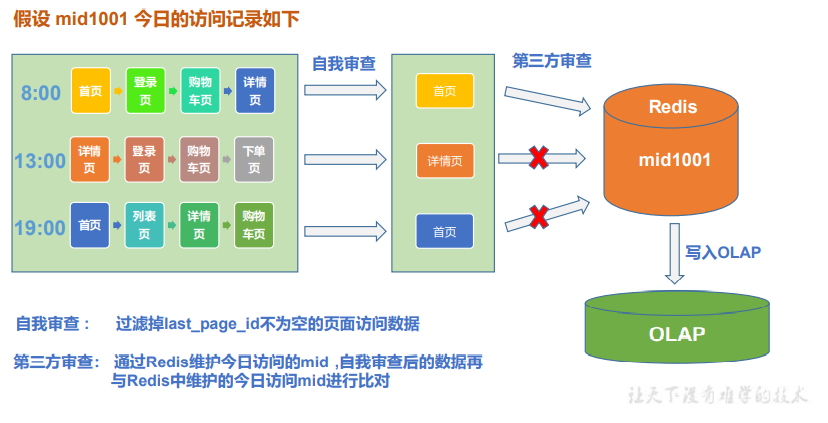
自我审查
val filterDStream: DStream[PageLog] = pageLogDStream.filter( pageLog => pageLog.last_page_id == null )
第三方审查
val redisFilterDStream: DStream[PageLog] = filterDStream.mapPartitions( pageLogIter => { val pageLogs: ListBuffer[PageLog] = ListBuffer[PageLog]() val jedis: Jedis = MyRedisUtils.getJedisFromPool() for (pageLog <- pageLogIter) { val mid: String = pageLog.mid val date:String = LocalDate.now().toString val redisDauKey: String = s"DAU:$date" val isNew: lang.Long = jedis.sadd(redisDauKey, mid) if (isNew == 1L) { pageLogs.append(pageLog) } } jedis.close() pageLogs.iterator } )
说明:使用mapPartitions可以以批为单位过滤,从而减少频繁地开关redis连接;使用set能很方便地进行去重;key中拼接日期已区分相同用户不同日期的活跃
维度关联
由于要针对各种对于不同角度的“日活”分析,而 OLAP 数据库中尽量减少 join 操作, 所以在实时计算中要考虑其会被分析的维度,补充相应的维度数据,形成宽表。
由于维度数据已经保存在固定容器中了,所以在实时计算中,维度与事实数据关联并不是通过 join 算子完成。而是在流中查询固定容器(redis/mysql/hbase)来实现维度补充。
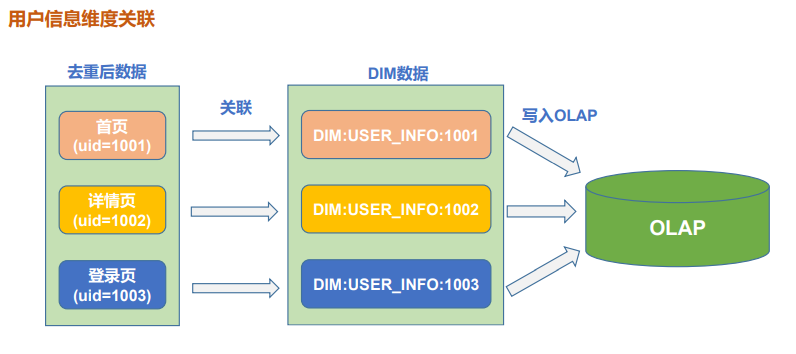
1)将 PageLog 的字段信息拷贝到 DauInfo 中
编写对象字段拷贝工具类进行拷贝
object MyBeanUtils { def copyProperties(srcObj: AnyRef, destObj: AnyRef): Unit = { if(srcObj == null || destObj == null) return val srcFields: Array[Field] = srcObj.getClass.getDeclaredFields for (srcField <- srcFields) { Breaks.breakable { var getMethodName: String = srcField.getName var setMethodName: String = srcField.getName + "_$eq" val getMethod: Method = srcObj.getClass.getDeclaredMethod(getMethodName) val setMethod: Method = try { destObj.getClass.getDeclaredMethod(setMethodName, srcField.getType) } catch{ case ex : Exception => Breaks.break() } val destField: Field = destObj.getClass.getDeclaredField(srcField.getName) if(destField.getModifiers.equals(Modifier.FINAL)){ Breaks.break() } setMethod.invoke(destObj, getMethod.invoke(srcObj)) } } } }
2)关联维度
redisFilterDStream.mapPartitions( pageLogIter => { val dauInfos: ListBuffer[DauInfo] = ListBuffer[DauInfo]() val jedis: Jedis = MyRedisUtils.getJedisFromPool() for(pagelog <- pageLogIter){ 1)PageLog中的字段拷贝到DauInfo 2)关联用户维度:DIM:USER_INFO$uid 3)关联地区维度:DIM:BASE_PROVINCE:$provinceID 4)处理日期字段 } jedis.close() dauInfos.iterator } )
订单业务宽表
需求分析
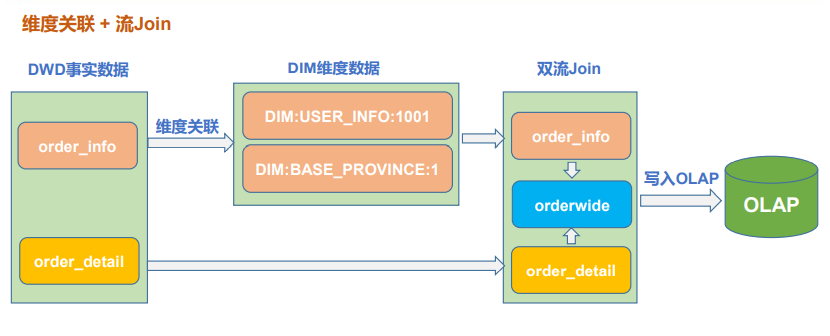
流与维度表之间的合并, 通常是事实表与维度表之间的关联。
流与流之间的合并,也可以叫双流 join,通常是几乎同时产生的事实表的关联。
维度关联
参考日活宽表维度关联
双流 join
初步实现:
val orderInfoKVDStream: DStream[(Long, OrderInfo)] = orderInfoDimDStream.map(orderInfo => (orderInfo.id, orderInfo)) val orderDetailKVDStream: DStream[(Long, OrderDetail)] = orderDetailDStream.map(orderDetail => (orderDetail.id, orderDetail)) val orderJoinDStream: DStream[(Long, (OrderInfo, OrderDetail))] = orderInfoKVDStream.join(orderDetailKVDStream)
存在问题:
由于两个流的数据是独立保存,独立消费,很有可能同一业务的数据,分布在不同的批次。因为 join 算子只 join 同一批次的数据。如果只用简单的 join 流方式,会丢失掉不同批次的数据。
解决策略:
(1)增大采集周期
(2)利用滑动窗口进行 join 然后再进行去重
(3)把数据存入缓存 ,关联时进行 join 后 ,再去查询缓存中的数据,来弥补不同批次的问题。
程序流程图(缓存策略)
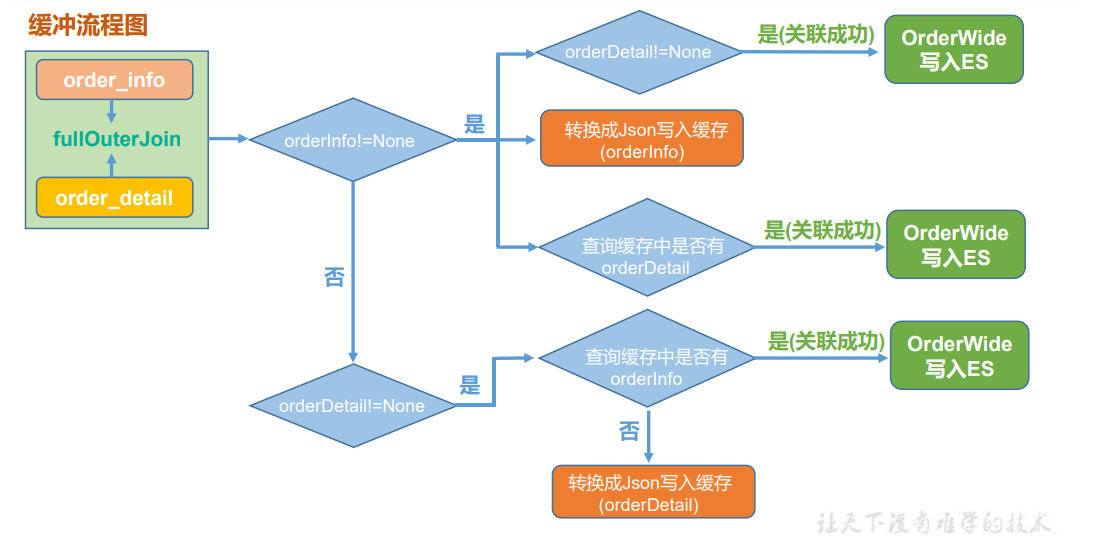
缓存策略实现
val orderJoinDStream: DStream[(Long, (Option[OrderInfo], Option[OrderDetail]))] = orderInfoKVDStream.fullOuterJoin(orderDetailKVDStream) val orderWideDStream: DStream[OrderWide] = orderJoinDStream.mapPartitions( orderJoinIter => { val jedis: Jedis = MyRedisUtils.getJedisFromPool() val orderWides: ListBuffer[OrderWide] = ListBuffer[OrderWide]() for ((key, (orderInfoOp, orderDetailOp)) <- orderJoinIter){ if(有orderInfo){ if(有orderDetail){ 关联 }
//不管orderDetail有没有都要写缓存读缓存,因为一个orderInfo对应多个orderDetail
//orderDetail可能来得晚,需要写缓存等orderDetail;orderDetail可能来得早,在缓存中等orderInfo 写缓存:ORDERJOIN:ORDER_INFO${orderInfo.id} 读缓存:ORDERJOIN:ORDER_DETAIL:${orderInfo.id} if(有orderDetail){
//可能多个orderDetail,循环关联 关联 } }else{
//没有orderInfo,有orderDetail,不可能两个都没有 读缓存:ORDERJOIN:ORDER_INFO:${orderDetail.order_id} if(有orderInfo){ 关联 }else{ 写缓存:ORDERJOIN:ORDER_DETAIL:${orderDetail.order_id} } } } jedis.close() orderWides.iterator } )
注意:redis中orderInfo为string,orderDetail为set
写入ES
编写ES工具类
object MyEsUtils{ val esClient: RestHighLevelClient = build() def build()={ val restClientBuilder: RestClientBuilder = RestClient.builder(new HttpHost(MyPropsUtils("es.host"), MyPropsUtils("es.port").toInt)) val client = new RestHighLevelClient(restClientBuilder) client } def close(): Unit ={ if(esClient != null) esClient.close() } def bulkSave(indexName: String, docs: List[(String, AnyRef)]): Unit = { val bulkRequest = new BulkRequest(indexName) for(doc <- docs){ val indexRequest = new IndexRequest() val dataJson: String = JSON.toJSONString(doc._2, new SerializeConfig(true)) indexRequest.source(dataJson,XContentType.JSON) indexRequest.id(doc._1) bulkRequest.add(indexRequest) } esClient.bulk(bulkRequest, RequestOptions.DEFAULT) } }
建立索引模板
不需要倒排索引text,使用keyword
写入ES
//写入ES dauInfoDStream.foreachRDD( rdd => { rdd.foreachPartition( dauInfoIter => { val docs: List[(String, DauInfo)] = dauInfoIter.map(dauInfo => (dauInfo.mid, dauInfo)).toList val date:String = LocalDate.now().toString val indexName: String = s"gmall_dau_info_$date" MyEsUtils.bulkSave(indexName, docs) } ) //提交offset MyOffsetsUtils.saveOffset(topicName, groupId, offsetRanges) } )
ES和Redis状态不一致问题
在日活宽表处理中,如果某个用户某天的首次访问数据写入 redis 后, 接下来 在写入到 es 的过程中,程序挂掉。此时,偏移量还未提交,重启后会触发数据的重试,但是因为 redis 中记录了相关的数据,所以该数据会被过滤掉。因此此数据,就再也无法进入 es,也就意味着丢失。
这个问题的本质就是,状态数据与最终数据库的数据以及偏移量,没有形成原子性事务造成的。
当然可以通过事务数据库的方式解决该问题,而我们的项目中没有选择使用支持事务 的数据库,例如 MySQL 等。在既有的环境下我们依然有很多破解方案,例如进行状态还原,在启动程序前,将 ES 中已有的数据的 mid 提取出来,覆盖到 Redis 中,这样就能保证 Redis 和 ES 数据的同步
解决方案
1)在 ES 工具类中添加方法
//查询指定的字段 def searchField(indexName: String, fieldName: String): List[String] = { //判断索引是否存在 val getIndexRequest = new GetIndexRequest(indexName) val isExists: Boolean = esClient.indices().exists(getIndexRequest, RequestOptions.DEFAULT) if(!isExists) return null; //索引存在,查出所有的mid val mids: ListBuffer[String] = ListBuffer[String]() val searchRequest: SearchRequest = new SearchRequest(indexName) val searchSourceBuilder = new SearchSourceBuilder() searchSourceBuilder.fetchSource(fieldName, null).size(100000) searchRequest.source(searchSourceBuilder) val searchResponse: SearchResponse = esClient.search(searchRequest, RequestOptions.DEFAULT) val hits: Array[SearchHit] = searchResponse.getHits.getHits for (hit <- hits) { val sourceAsMap: util.Map[String, AnyRef] = hit.getSourceAsMap val mid: String = sourceAsMap.get(fieldName).toString mids.append(mid) } mids.toList }
2)调整 ES 参数
PUT /_settings { "index.max_result_window" :"5000000" }
3)在主程序中添加状态还原方法
def revertState(): Unit ={ val date:String = LocalDate.now().toString val indexName = s"gmall_dau_info$date" val fieldName = "mid" val mids: List[String] = MyEsUtils.searchField(indexName, fieldName) //删除redis中的所有状态 val jedis: Jedis = MyRedisUtils.getJedisFromPool() val redisDauKey = s"DAU:$date" jedis.del(redisDauKey) //重新写入redis,与ES状态一致 if(mids != null && mids.size > 0){ val pipeline: Pipeline = jedis.pipelined() for (mid <- mids) { pipeline.sadd(redisDauKey, mid) } pipeline.sync() } jedis.close() }
4)修补主程序,在整个程序加载数据前进行状态还原
可视化
BI 搭建数据可视化
利用 kibana 进行可视化展示:
配置数据源 Index Patterns
配置可视化图形Visualize
配置仪表盘Dashboard
数据接口
日活实时监控
数据接口要求
http://bigdata.gmall.com/dauRealtime?td=2022-01-01
{ dauTotal:123, dauYd:{"12":90,"13":33,"17":166 }, dauTd:{"11":232,"15":45,"18":76} }
mapper实现
public Map<String, Object> searchDau(String td) { Map<String,Object> dauResults = new HashMap<>(); //日活总数 Long dauTotal = searchDauTotal(td); dauResults.put("dauTotal",dauTotal) ; //今日分时明细 Map<String, Long> dauTd = searchDauHr(td); dauResults.put("dauTd", dauTd); //昨日分时明细 //计算昨日 LocalDate tdLd = LocalDate.parse(td); LocalDate ydLd = tdLd.minusDays(1); Map<String, Long> dauYd = searchDauHr(ydLd.toString()); dauResults.put("dauYd", dauYd); return dauResults; } //分时明细 public Map<String,Long> searchDauHr(String td ){ HashMap<String, Long> dauHr = new HashMap<>(); String indexName = dauIndexNamePrefix + td ; SearchRequest searchRequest = new SearchRequest(indexName); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //不要明细 searchSourceBuilder.size(0); //聚合 TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.terms("groupbyhr").field("hr").size(24); searchSourceBuilder.aggregation(termsAggregationBuilder); searchRequest.source(searchSourceBuilder); try { SearchResponse searchResponse = esClient.search(searchRequest, RequestOptions.DEFAULT); Aggregations aggregations = searchResponse.getAggregations(); ParsedTerms parsedTerms = aggregations.get("groupbyhr"); List<? extends Terms.Bucket> buckets = parsedTerms.getBuckets(); for (Terms.Bucket bucket : buckets) { String hr = bucket.getKeyAsString(); long hrTotal = bucket.getDocCount(); dauHr.put(hr, hrTotal); } return dauHr ; } catch (ElasticsearchStatusException ese){ if(ese.status() == RestStatus.NOT_FOUND){ log.warn( indexName +" 不存在......"); } } catch (IOException e) { e.printStackTrace(); throw new RuntimeException("查询ES失败...."); } return dauHr ; } //日活总数 public Long searchDauTotal(String td ){ String indexName = dauIndexNamePrefix + td ; SearchRequest searchRequest = new SearchRequest(indexName); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //不要明细 searchSourceBuilder.size(0); searchRequest.source(searchSourceBuilder); try { SearchResponse searchResponse = esClient.search(searchRequest, RequestOptions.DEFAULT); long dauTotals = searchResponse.getHits().getTotalHits().value; return dauTotals ; }catch (ElasticsearchStatusException ese){ if(ese.status() == RestStatus.NOT_FOUND){ log.warn( indexName +" 不存在......"); } } catch (IOException e) { e.printStackTrace(); throw new RuntimeException("查询ES失败...."); } return 0L; }
灵活查询数据接口开发
数据接口要求
http://bigdata.gmall.com/statsByItem?itemName=小米手机&date=2021-02-02&t=gender [ { value: 1048, name: "男" }, { value: 735, name: "女" } ]
http://bigdata.gmall.com/statsByItem?itemName=小米手机&date=2021-02-02&t=age [ { value: 1048, name: "20 岁以下" }, { value: 735, name: "20 岁至 29 岁" } , { value: 34, name: "30 岁以上" } ]
http://bigdata.gmall.com/detailByItem?date=2021-02-02&itemName=小米手机&pageNo=1&pageSize=20 { "total":23, "detail":[{},{}......]
mapper实现
//根据field分组统计总额 public List<NameValue> searchStatsByItem(String itemName, String date, String field) { ArrayList<NameValue> results = new ArrayList<>(); String indexName = orderIndexNamePrefix + date ; SearchRequest searchRequest = new SearchRequest(indexName); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //不需要明细 searchSourceBuilder.size(0); //query MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("sku_name", itemName).operator(Operator.AND); searchSourceBuilder.query(matchQueryBuilder); //group TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.terms("groupby" + field).field(field).size(100); //sum SumAggregationBuilder sumAggregationBuilder = AggregationBuilders.sum("totalamount").field("split_total_amount"); termsAggregationBuilder.subAggregation(sumAggregationBuilder); searchSourceBuilder.aggregation(termsAggregationBuilder); searchRequest.source(searchSourceBuilder); try { SearchResponse searchResponse = esClient.search(searchRequest, RequestOptions.DEFAULT); Aggregations aggregations = searchResponse.getAggregations(); ParsedTerms parsedTerms = aggregations.get("groupby" + field); List<? extends Terms.Bucket> buckets = parsedTerms.getBuckets(); for (Terms.Bucket bucket : buckets) { String key = bucket.getKeyAsString(); Aggregations bucketAggregations = bucket.getAggregations(); ParsedSum parsedSum = bucketAggregations.get("totalamount"); double totalamount = parsedSum.getValue(); results.add(new NameValue(key ,totalamount)); } return results ; } catch (ElasticsearchStatusException ese){ if(ese.status() == RestStatus.NOT_FOUND){ log.warn( indexName +" 不存在......"); } } catch (IOException e) { e.printStackTrace(); throw new RuntimeException("查询ES失败...."); } return results; } //根据搜索关键词查询明细 public Map<String, Object> searchDetailByItem(String date, String itemName, Integer from, Integer pageSize) { HashMap<String, Object> results = new HashMap<>(); String indexName = orderIndexNamePrefix + date ; SearchRequest searchRequest = new SearchRequest(indexName); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //明细字段 searchSourceBuilder.fetchSource(new String[]{"create_time", "order_price", "province_name" , "sku_name", "sku_num", "total_amount","user_age","user_gender"}, null ); //query MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("sku_name", itemName).operator(Operator.AND); searchSourceBuilder.query(matchQueryBuilder); //form searchSourceBuilder.from(from); //size searchSourceBuilder.size(pageSize); //高亮 HighlightBuilder highlightBuilder = new HighlightBuilder(); highlightBuilder.field("sku_name"); searchSourceBuilder.highlighter(highlightBuilder); searchRequest.source(searchSourceBuilder); try { SearchResponse searchResponse = esClient.search(searchRequest, RequestOptions.DEFAULT); long total = searchResponse.getHits().getTotalHits().value; SearchHit[] searchHits = searchResponse.getHits().getHits(); ArrayList<Map<String, Object>> sourceMaps = new ArrayList<>(); for (SearchHit searchHit : searchHits) { //提取source Map<String, Object> sourceMap = searchHit.getSourceAsMap(); //提取高亮 Map<String, HighlightField> highlightFields = searchHit.getHighlightFields(); HighlightField highlightField = highlightFields.get("sku_name"); Text[] fragments = highlightField.getFragments(); String highLightSkuName = fragments[0].toString(); //使用高亮结果覆盖原结果 sourceMap.put("sku_name",highLightSkuName ) ; sourceMaps.add(sourceMap); } //最终结果 results.put("total",total ); results.put("detail", sourceMaps); return results ; } catch (ElasticsearchStatusException ese){ if(ese.status() == RestStatus.NOT_FOUND){ log.warn( indexName +" 不存在......"); } } catch (IOException e) { e.printStackTrace(); throw new RuntimeException("查询ES失败...."); } return results; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号