
Presto知识点总结
Presto简介
是Facebook开源的,完全基于内存的并⾏计算,分布式SQL交互式查询引擎
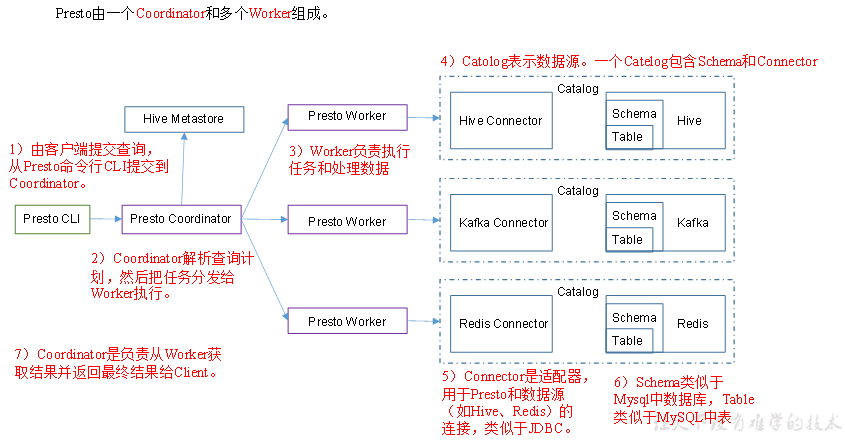
Presto架构
Presto优缺点
优点:
1)Presto基于内存运算,减少了磁盘IO,计算更快;
2)能够连接多个数据源,跨数据源连表查;
缺点:
Presto 能够处理PB级别的海量数据分析,但 Presto并不是把PB级数据都放在内存中计算的。而是根据场景,如 Count,AVG等聚合运算,是边读数据边计算,再清内存,再读数据再计算,这种耗的内存并不高。但是连表查,就可能产生大量的临时数据,因此速度会变慢
Presto使用
Presto Server部署
配置coordinator节点、worker节点
Presto命令行Client部署
启动:./prestocli --server hadoop102:8881 --catalog hive --schema default
注意:
对接Hive时,如果表使用了parquet存储+lzo压缩,需要手动添加lzo的jar包;
如果表是纯lzo压缩,需要修改hadoop-lzo源码后再手动添加lzo的jar包;
Presto可视化Client部署
Presto优化
数据存储优化
(1)合理设置分区
与Hive类似,Presto会根据元数据信息读取分区数据,合理的分区能减少Presto数据读取量,提升查询性能
(2)使用列式存储
Presto对ORC文件读取做了特定优化,因此在Hive中创建Presto使用的表时,建议采用ORC格式存储。相对于Parquet,Presto对ORC支持更好。
(3)使用压缩
数据压缩可以减少节点间数据传输对IO带宽压力,对于即席查询需要快速解压,建议采用Snappy压缩。
SQL查询优化
(1)只选择使用的字段
由于采用列式存储,选择需要的字段可加快字段的读取、减少数据量。避免采用*读取所有字段。
(2)过滤条件加上分区字段
对于有分区的表,where语句中优先使用分区字段进行过滤。
(3)Group By语句优化
合理安排Group by语句中字段顺序对性能有一定提升。将Group By语句中字段按照每个字段distinct数据多少进行降序排列。
(4)Order by时使用Limit
Order by需要扫描数据到单个worker节点进行排序,导致单个worker需要大量内存。如果是查询Top N或者Bottom N,使用limit可减少排序计算和内存压力。
(5)使用Join语句时将大表放在左边
Presto中join的默认算法是broadcast join,即将join左边的表分割到多个worker,然后将join右边的表数据整个复制一份发送到每个worker进行计算。如果右边的表数据量太大,则可能会报内存溢出错误。
注意事项
(1)字段名引用
避免和关键字冲突:MySQL对字段加反引号`、Presto对字段加双引号分割
(2)时间函数
对于Timestamp,需要进行比较的时候,需要添加Timestamp关键字,而MySQL中对Timestamp可以直接进行比较。
(3)不支持INSERT OVERWRITE语法
Presto中不支持insert overwrite语法,只能先delete,然后insert into。
(4)PARQUET格式
Presto目前支持Parquet格式,支持查询,但不支持insert。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号