
Kylin知识点总结
Kylin简介
Apache Kylin是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据
Kylin架构
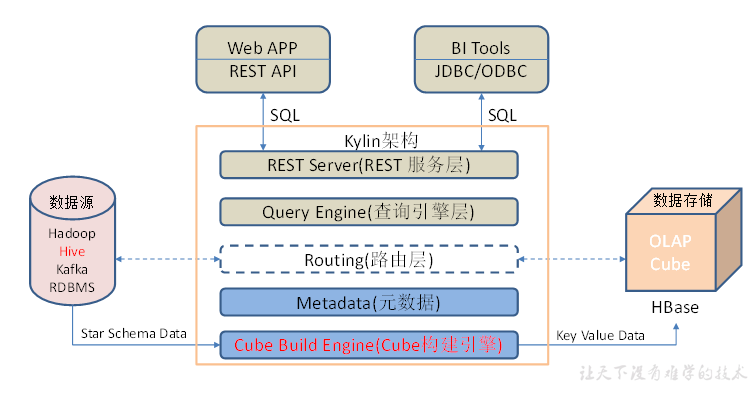
1)REST Server
REST Server是一套面向应用程序开发的入口点,旨在实现针对Kylin平台的应用开发工作。 此类应用程序可以提供查询、获取结果、触发cube构建任务、获取元数据以及获取用户权限等等。另外可以通过Restful接口实现SQL查询。
2)查询引擎(Query Engine)
当cube准备就绪后,查询引擎就能够获取并解析用户查询。它随后会与系统中的其它组件进行交互,从而向用户返回对应的结果。
3)路由器(Routing)
在最初设计时曾考虑过将Kylin不能执行的查询引导去Hive中继续执行,但在实践后发现Hive与Kylin的速度差异过大,导致用户无法对查询的速度有一致的期望,很可能大多数查询几秒内就返回结果了,而有些查询则要等几分钟到几十分钟,因此体验非常糟糕。最后这个路由功能在发行版中默认关闭。
4)元数据管理工具(Metadata)
Kylin是一款元数据驱动型应用程序。元数据管理工具是一大关键性组件,用于对保存在Kylin当中的所有元数据进行管理,其中包括最为重要的cube元数据。其它全部组件的正常运作都需以元数据管理工具为基础。 Kylin的元数据存储在hbase中。
5)任务引擎(Cube Build Engine)
这套引擎的设计目的在于处理所有离线任务,其中包括shell脚本、Java API以及Map Reduce任务等等。任务引擎对Kylin当中的全部任务加以管理与协调,从而确保每一项任务都能得到切实执行并解决其间出现的故障。
Kylin使用
1)创建工程
2)获取数据源
导入Hive表
注意:Kylin不能处理Hive表中的复杂数据类型(Array,Map,Struct),即便复杂类型的字段并未参与到计算之中。故在加载Hive数据源时,不能直接加载带有复杂数据类型字段的表。
解决方法:创建视图过滤复杂数据类型字段
3)创建model(星型/雪花模型)
(1)指定事实表
(2)选择维度表,并指定事实表和维度表的关联条件
(3)指定维度字段
(4)指定度量字段
(5)指定事实表分区字段
(6)过滤
4)构建cube
(1)选择cube所依赖的model
(2)选择预计算所需的维度(Derived优化)
(3)选择预计算所需度量值、聚合函数
(4)cube自动合并设置(为提高查询效率,需将每日的cube进行合并,此处可设置合并周期)
(5)Kylin高级配置 (聚合组优化、RowKey优化)
(6)构建Cube,选择要构建的时间区间(Kylin提供了Restful API,因次我们可以将构建cube的命令写到脚本中,将脚本交给调度工具,以实现定时调度的功能)
注意:每日全量维度表及拉链维度表重复Key报错
解决方法:创建视图,创建视图时对数据加以过滤,保证从视图中查出的数据是一份全量最新的数据
Kylin Cube构建优化
使用衍生维度(derived dimension)
衍生维度用于在有效维度内将维度表上的非主键维度排除掉,并使用维度表的主键(其实是事实表上相应的外键)来替代它们。Kylin会在底层记录维度表主键与维度表其他维度之间的映射关系,以便在查询时能够动态地将维度表的主键“翻译”成这些非主键维度,并进行实时聚合。
注意:如果从维度表主键到某个维度表维度所需要的聚合工作量非常大,则不建议使用衍生维度。
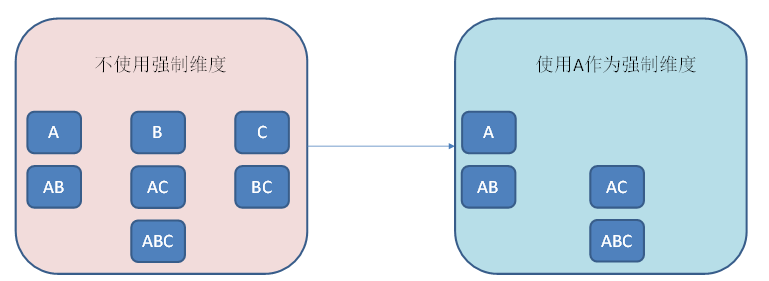
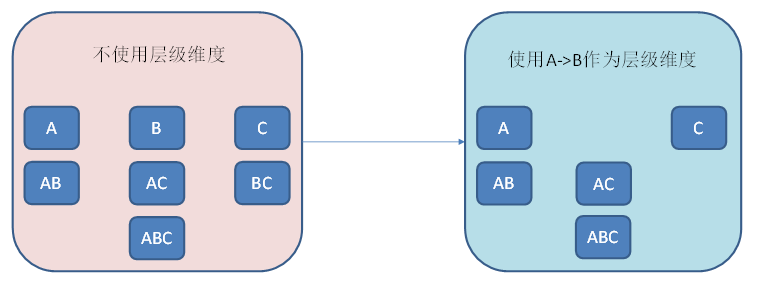
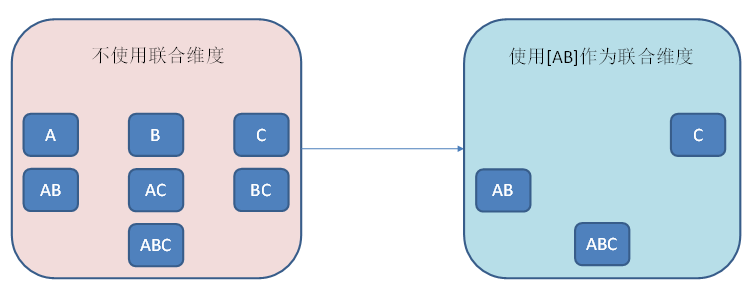
使用聚合组(Aggregation group)
聚合组是一种强大的剪枝工具,可以通过强制维度、层级维度、联合维度去掉不需要的维度组合。
Row Key优化
调整维度在rowkey中的次序,对查询性能有显著的影响。
1)优化查询:被用作过滤的维度放在前边。
2)优化计算:基数大的维度放在基数小的维度前边
Kylin Cube构建原理
Cube和Cuboid
对于每一种维度的组合,将度量值做聚合计算,然后将结果保存为一个物化视图,称为Cuboid。所有维度组合的Cuboid作为一个整体,称为Cube。
Cube构建算法
1)逐层构建算法(layer)
在逐层算法中,按维度数逐层减少来计算,每个层级的计算(除了第一层,它是从原始数据聚合而来),是基于它上一层级的结果来计算的。每一轮的计算都是一个MapReduce任务,且串行执行
总结:稳定但效率较低
2)快速构建算法(inmem)
每个Mapper将其所分配到的数据块,计算成一个完整的小Cube 段(在内存做预聚合,算出所有组合)。每个Mapper将计算完的Cube段输出给Reducer做合并,生成大Cube(只有一轮MapReduce)。
总结:效率较高但不稳定
Kylin Cube存储原理
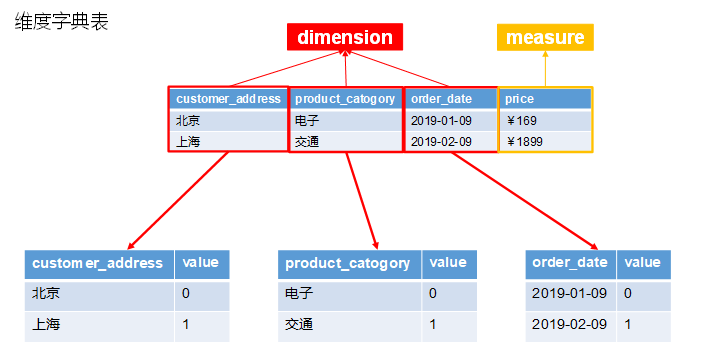
关注HBase表的RowKey设计(此处为简化后的RowKey)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号