
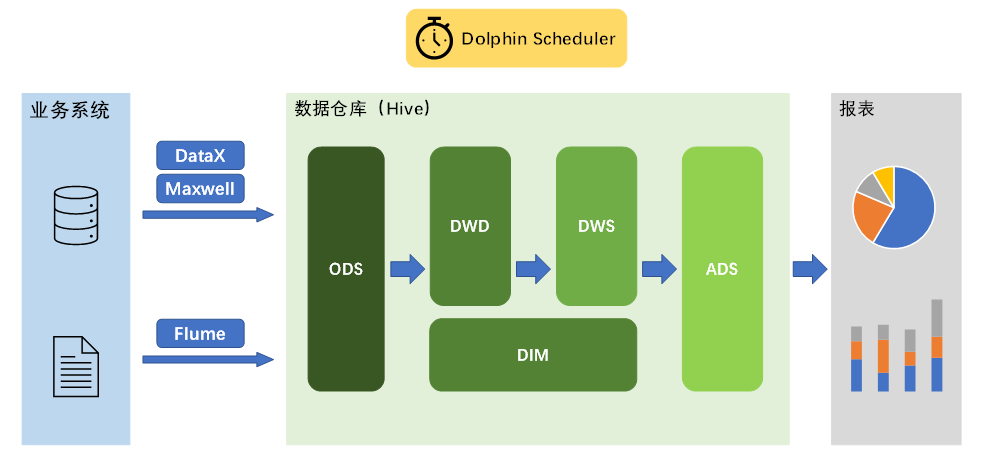
Hive离线数仓
总体架构
尚硅谷离线数仓5.0总体架构图
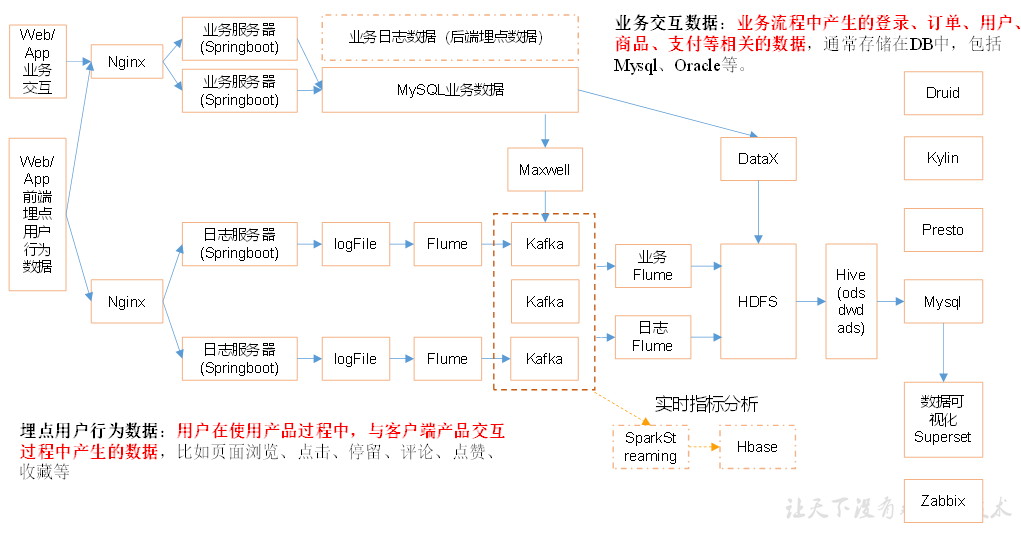
本项目收集和分析的用户行为信息主要有页面浏览记录、动作记录、曝光记录、启动记录和错误记录。
核心
本地磁盘 -> 采集Flume + Kafka + 消费Flume-> HDFS
采集Flume
TailDir Source
优点:断点续传(通过保存文件实现)、多目录多文件、实时监控文件变化
缺点:文件更名数据重复(解决方法:使用不更名打印日志框架logback/修改源码只看inode)
注意:零点漂移问题
Kafka Channel
优点:存储在磁盘中,可靠性高;省去Sink,效率高;
注意:parseAsFlumeEvent=false 使用String格式存储到Kafka (该属性为true时会转成Flume Event,结果时把Flume的headers中的信息混合着内容一起写入kafka的消息中,无论headers是否为空时都出现了奇怪的特殊字符)
ETL拦截器
对非法数据进行过滤(使用fastjson工具判断是否是Json格式)
Kafka消息队列
offset重置:没有消费记录(新的消费者组)或offset不存在
消费全部数据:新的消费者组GroupID + 重置策略为earliest
消费最新数据:重置策略为latest(默认)
断点续传:同一个消费者组会自动断点续传,断点续传的数据(是否丢失或重复)和Consumer提交Offset策略有关
消费Flume
KafkaSource
FileChannel(为什么不选择KafkaChannel&no Source?因为这里需要自定义拦截器解决零点漂移问题)
HDFS Sink
注意:控制生成的小文件(时间、大小滚动)、gzip压缩(与DataX统一使用gzip)
时间戳拦截器
将真正时间写入header头,从而正确按时间存储文件,解决零点漂移问题
Flume脚本
启动:nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf/ -f /opt/module/flume/job/file_to_kafka.conf >/dev/null 2>&1 &
停止:ps -ef | grep file_to_kafka.conf | grep -v grep |awk '{print \$2}' | xargs -n1 kill -9
业务数据采集平台
电商业务表
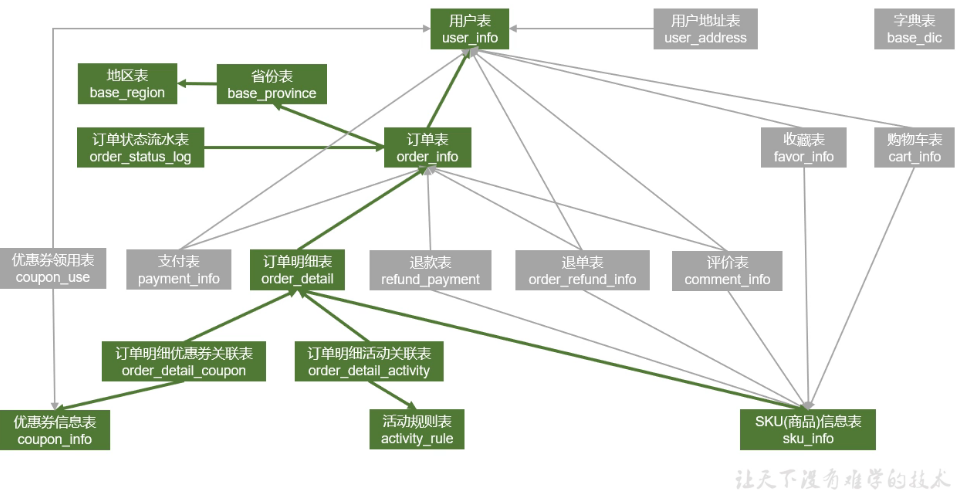
收藏商品:用户表<-收藏表->SKU信息表
加购物车:用户表<-购物车表->SKU信息表
领优惠券:用户表<-优惠券领用表->优惠券信息表
下单:如图
支付:支付表->用户表
->订单表
退单:退单表->用户表
->订单表
->SKU信息表
退款:退款表->订单表
->SKU信息表
评价:评价表->用户表
->订单表
->SKU信息表
后台管理系统表
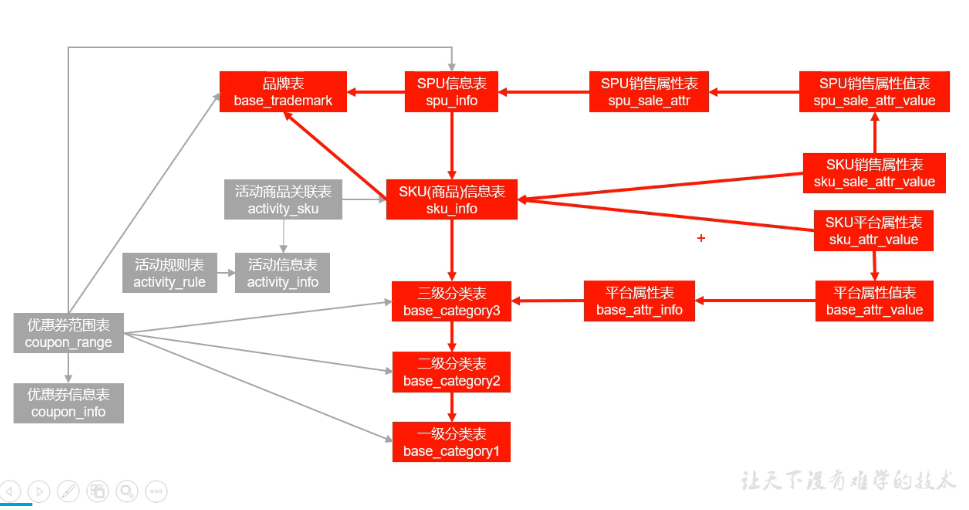
商品:如图
活动:活动规则表->活动信息表<-活动商品关联表->SKU信息表
优惠券:优惠券范围表->优惠券信息表
->三级分类表
->二级分类表
->一级分类表
->SPU信息表
->品牌表
业务数据采集平台 - 4.0核心
MySQL -> Sqoop -> HDFS
| 遇到的问题 | 解决方法 |
| Sqoop导入Null存储一致性问题 |
Hive中的Null在底层是以“\N”来存储,而MySQL中的Null在底层就是Null,为了保证数据两端的一致性。 在导出数据时采用--input-null-string和--input-null-non-string两个参数。 导入数据时采用--null-string和--null-non-string。 |
| Sqoop在导入数据的时候数据倾斜 |
通过ROWNUM()生成一个严格均匀分布的字段,然后split-by指定为分割字段 |
Sqoop优点:可以选择lzo压缩并加索引
业务数据采集平台 - 5.0核心
MySQL -> DataX + Maxwall -> HDFS
为什么使用DataX + Maxwall代替sqoop?
1)整体速度更快;
2)DataX有更多的功能,比如数据监控、速度控制等;
3)Maxwell实时同步记录了每一次业务数据操作,而sqoop只有最终结果;
4)Maxwell实时同步的数据可以提供给实时数仓做数据源;
但是也有缺点:ods需要处理多种“结构”的数据;整体架构更复杂;需使用gzip压缩,其压缩比高,但压缩数率较低,不支持切片。
为什么不单独使用Maxwall?
Maxwall进行全量同步需要使用maxwall-bootstrap,其底层为select * from table order by id,并且其没有进行其他特别的优化,效率极低。
而DataX全量同步进行了优化,比如任务切分,效率较高。
同步策略
全量同步,就是每天都将业务数据库中的全部数据同步一份到数据仓库,这是保证两侧数据同步的最简单的方式
增量同步,就是每天只将业务数据中的新增及变化数据同步到数据仓库。采用每日增量同步的表,通常需要在首日先进行一次全量同步。
总结:若业务表数据量比较大,且每天数据变化的比例比较低,这时应采用增量同步,否则可采用全量同步。
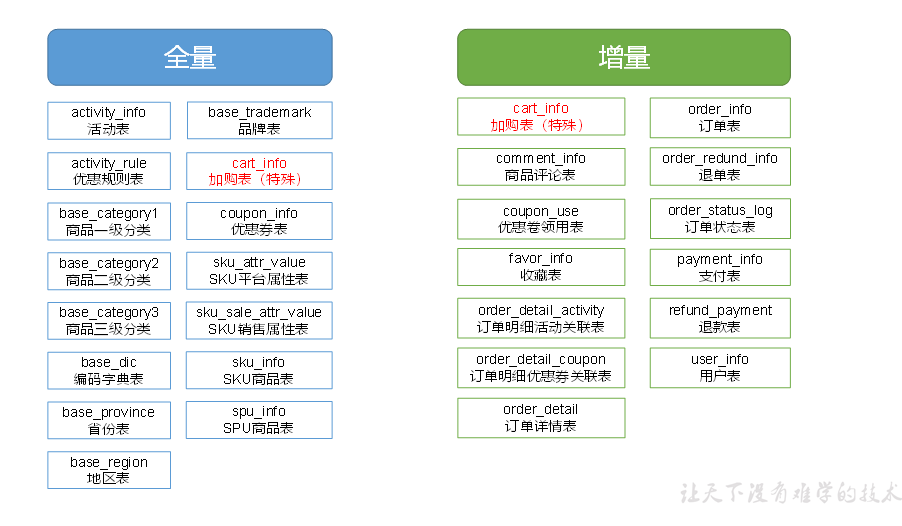
本项目中,全量同步采用DataX,增量同步采用Maxwell
全量表数据同步
全量表数据由DataX从MySQL业务数据库直接同步到HDFS
| 遇到的问题 | 解决方法 |
|
HFDS Writer并未提供nullFormat参数:也就是用户并不能自定义null值写到HFDS文件中的存储格式。 默认情况下,HFDS Writer会将null值存储为空字符串(''),而Hive默认的null值存储格式为\N 所以后期将DataX同步的文件导入Hive表就会出现问题 |
一是修改DataX HDFS Writer的源码,增加自定义null值存储格式的逻辑 二是在Hive中建表时指定null值存储格式为空字符串('') |
| HDFS Writer 中text文件压缩只支持gzip、bzip | 选择gzip压缩格式 |
| DataX每个表需要一个配置文件,需要编写十几个配置文件 | 编写DataX配置文件批量生成py脚本 |
| HDFS目标目录不存在会报错,且每个表的每个日期都需要创建目录 | 在全量表数据同步脚本中 同步数据之前创建目录 |
| 全量表数据同步脚本重复执行失败后,重复执行会有重复数据 |
在全量表数据同步脚本中 同步数据之前判断目录是否存在 不存在创建,存在则清空数据 |
DataX优化方向:编写多个数据同步脚本,同时启动多个DataX任务,使其并行执行
增量表数据同步
增量表数据由Maxwell从MySQL业务数据库同步到Kafka,再由Flume从Kafka同步到HDFS。
默认情况下,Maxwell会同步binlog中的所有表的数据变更记录,因此我们需要对Maxwell进行配置,另其只同步这特定的13张表。
另外,为方便下游使用数据,还需对Maxwell进行配置,另其将不同表的数据发往不同的Kafka Topic。
| 遇到的问题 | 解决方法 |
| binlog相关 | MySQL开启binlog,并设置为行格式 |
| Kafka主题不存在 | 配置文件中使用动态主题和过滤器后会自动创建Topic |
| 零点漂移问题 | 同样使用Flume时间戳拦截器 |
除了每日同步脚本,还需要使用Maxwell的maxwell-bootstrap功能编写首日同步脚本
需要注意的是,KafkaSource需订阅Kafka中的13个topic,HDFSSink需要将不同topic的数据写到不同的路径,并且路径中应当包含一层日期,用于区分每天的数据。
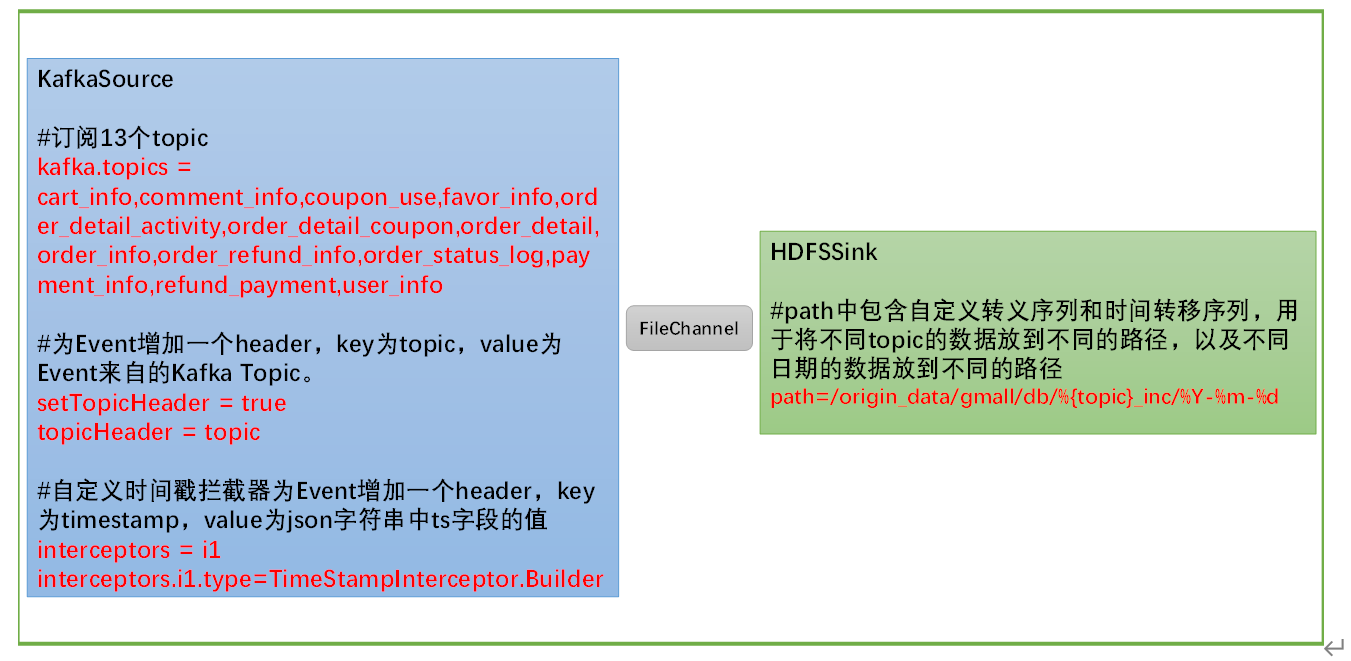
数仓仓库构建流程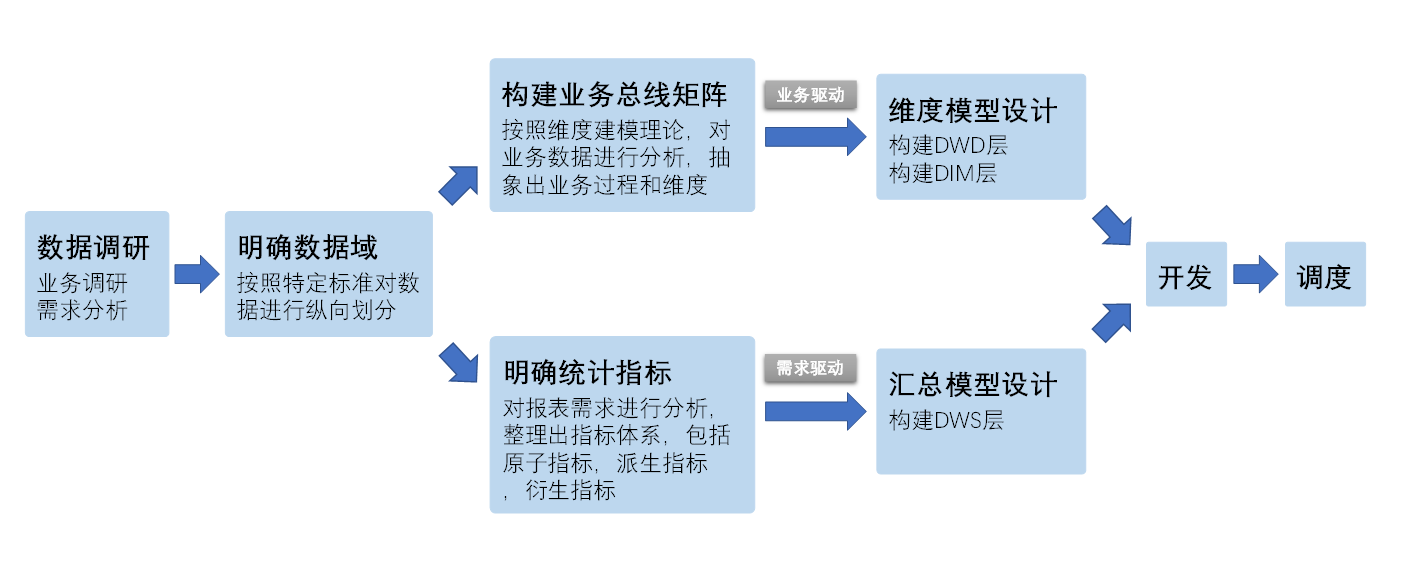
数据调研
1)业务调研
业务调研的主要目标是熟悉业务流程、熟悉业务数据。
2)需求分析
分析需求时,需要明确需求所需的业务过程及维度。
3)总结
做完业务分析和需求分析之后,要保证每个需求都能找到与之对应的业务过程及维度。
明确数据域
划分数据域的意义是便于数据的管理和应用。
通常可以根据业务过程或者部门进行划分,本项目根据业务过程进行划分,需要注意的是一个业务过程只能属于一个数据域。
|
数据域 |
业务过程 |
|
交易域 |
加购、下单、取消订单、支付成功、退单、退款成功 |
|
流量域 |
页面浏览、启动应用、动作、曝光、错误 |
|
用户域 |
注册、登录 |
|
互动域 |
收藏、评价 |
|
工具域 |
优惠券领取、优惠券使用(下单)、优惠券使用(支付) |
构建业务总线矩阵
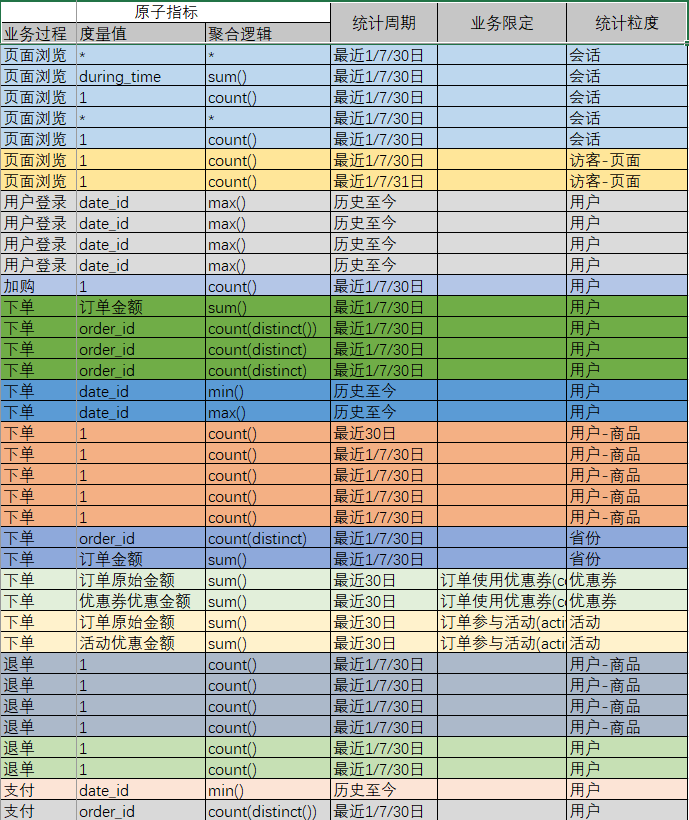
业务总线矩阵中包含维度模型所需的所有事实(业务过程)以及维度,以及各业务过程与各维度的关系。矩阵的行是一个个业务过程,矩阵的列是一个个的维度,行列的交点表示业务过程与维度的关系。
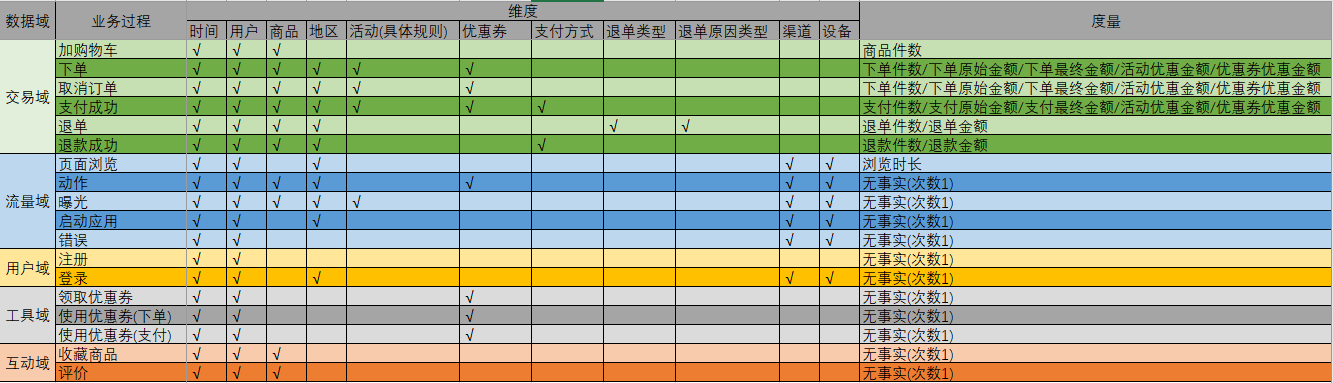
一个业务过程对应维度模型中一张事务型事实表,一个维度则对应维度模型中的一张维度表。所以构建业务总线矩阵的过程就是设计维度模型的过程。但是需要注意的是,总线矩阵中通常只包含事务型事实表,另外两种类型的事实表需单独设计。
明确统计指标
明确统计指标具体的工作是,深入分析需求,构建指标体系。构建指标体系的主要意义就是指标定义标准化。所有指标的定义,都必须遵循同一套标准,这样能有效的避免指标定义存在歧义,指标定义重复等问题。
(1)原子指标
原子指标基于某一业务过程的度量值,是业务定义中不可再拆解的指标,原子指标的核心功能就是对指标的聚合逻辑进行了定义。
例如订单总额就是一个典型的原子指标,其中的业务过程为用户下单、度量值为订单金额,聚合逻辑为sum()求和。需要注意的是原子指标只是用来辅助定义指标一个概念,通常不会对应有实际统计需求与之对应。
(2)派生指标
派生指标基于原子指标,其与原子指标的关系如下图所示。
与原子指标不同,派生指标通常会对应实际的统计需求。
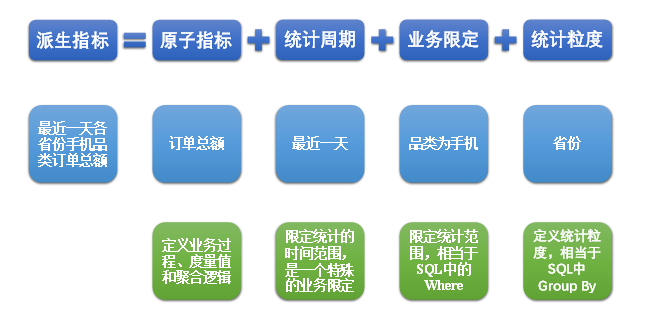
(3)衍生指标
衍生指标是在一个或多个派生指标的基础上,通过各种逻辑运算复合而成的。例如比率、比例等类型的指标。衍生指标也会对应实际的统计需求。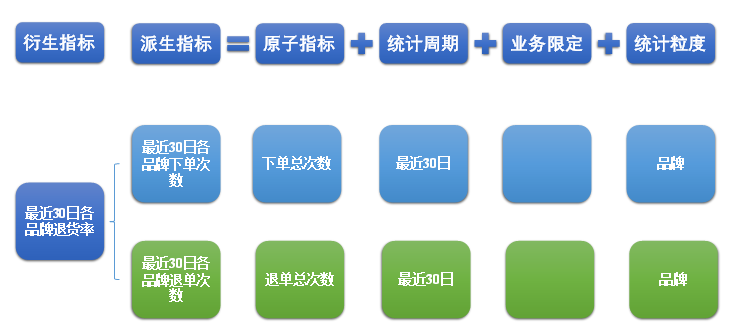
(4)指标体系对于数仓建模的意义
通过上述两个具体的案例可以看出,绝大多数的统计需求,都可以使用原子指标、派生指标以及衍生指标这套标准去定义。同时能够发现这些统计需求都直接的或间接的对应一个或者是多个派生指标。
当统计需求足够多时,必然会出现部分统计需求对应的派生指标相同的情况。这种情况下,我们就可以考虑将这些公共的派生指标保存下来,这样做的主要目的就是减少重复计算,提高数据的复用性。
这些公共的派生指标统一保存在数据仓库的DWS层。因此DWS层设计,就可以参考我们根据现有的统计需求整理出的派生指标。
维度模型设计
维度模型的设计参照上述得到的业务总线矩阵。事实表存储在DWD层,维度表存储在DIM层。
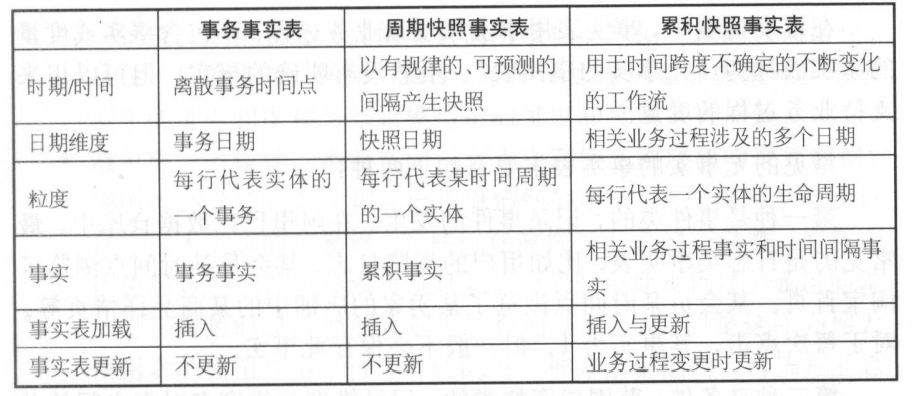
设计事实表
选择业务过程(及确认事实表类型) -> 声明粒度 -> 确认维度 -> 确认事实 -> 冗余维度
确认事实表类型:
关心每一步操作选择事务型事实表
关心周期型结果(存量型指标、连续状态型指标)选择周期型快照事实表
关心一个流程里多个过程(多事务关联统计,比如“用户下单到支付的时间间隔的平均值”)选择累积型快照事实表
设计维度表
选择维度或新建维度 -> 确认主维度表 -> 确认相关维表 -> 确认维度属性 -> 处理缓慢变化维
确认维度属性:
尽可能生成丰富的维度属性
尽量不使用编码,而使用明确的文字说明,一般可以编码和文字共存(JOIN字典表)
尽量沉淀出通用的维度属性 (拼接字段)
需要注意多值属性问题->将多值属性放到一个字段
处理缓慢变化维:
缓慢变化维在Kimball理论中有三种处理方式,重写、添加行、添加列,并且必须使用代理键作为维表主键。
而在《大数据之路:阿里巴巴大数据实践》书中写到阿里巴巴数据仓库建设并没有使用代理键
因为 代理键 对每一条记录生成稳定的全局唯一的代理键难度很大;使用代理键会大大增加ETL的复杂性,对ETL任务的开发和维护成本很高
对于缓慢变化维选择的处理方式是全量快照表
全量快照表 优点:简单而有效,开发和维护成本低,且方便理解和使用;缺点:浪费存储空间(现在存储成本远低于CPU、内存成本)
但对于数据量大变化比例小的特殊维度使用拉链表
拉链表 优点:节约存储空间;缺点:对下游会存在较高的解释成本;对于变化比例大的数据没有意义,但同样对下游产生影响
汇总模型设计
汇总模型的设计参考上述整理出的指标体系(主要是派生指标)。
汇总表与派生指标的对应关系是,一张汇总表通常包含业务过程相同、统计周期相同、统计粒度相同的多个派生指标。
设计完成
设计完成后,回过头来选择业务数据同步策略
同步策略不仅仅由数据量以及数据变化比例决定,还需要根据具体需求决定(以下表格中 不包含流量域/用户域事实表)
| 维度表/事实表划分 | 维度表/事实表 | 说明 | 同步策略 | 与维度表/事实表相关的业务表 |
|
全量快照表 |
商品/优惠券/活动/地区/日期维度表 | 对缓慢变化维的一般处理 | 全量同步 |
商品:SKU商品表(主)、SPU商品表、商品一/二/三级分类表、品牌表、 SKU平台属性表、SKU销售属性表; 优惠券:优惠券表(主)、编码字典表; 活动:活动表、优惠规则表(主)、编码字典表; 地区:地区表、省份表(主); 日期:日期数据一般不在业务表中; |
|
拉链表 |
用户维度表 |
对缓慢变化维的特殊处理: 数据量大,数据变化比例小 |
增量同步 | 用户表(主) |
| 事务型事实表 |
加购/下单/取消订单/支付成功/退单/ 退款成功/优惠券领取/优惠券使用(下单)/ 优惠券使用(支付)/收藏/评价事务事实表 |
关心每一次操作 | 增量同步 |
加购:加购表(增量)、编码字典表; 下单:订单详情表、订单表、订单明细活动关联表、订单明细优惠券关联表、编码字典表; 取消订单:订单详情表、订单表、订单明细活动关联表、订单明细优惠券关联表、编码字典表; 支付成功:支付表、订单详情表、订单表、订单明细活动关联表、订单明细优惠券关联表、编码字典表; 退单:退单表、订单表、编码字典表;退款成功:退款表、退单表、订单表、编码字典表; 优惠券领取/优惠券使用(下单)/优惠券使用(支付):优惠券领用表; 收藏:收藏表;评价:商品评论表、编码字典表; |
| 周期型快照事实表 | 购物车周期快照事实表 | 关心周期型结果 | 全量同步 | 加购表(全量) |
| 累积型快照事实表 | 没有多事务关联统计需求 | 关心阶段型变化 | 增量同步 | 无 |
数据仓库实现
核心架构
Hive on Spark
数仓分层

数仓分层有什么好处?
-
分层能使结构更加清晰:每一层都有它的作用和职责,我们在使用表的时候能更快速地定位和理解。
-
分层能使血缘关系更加清晰:高层依赖低层,不允许跨层依赖(例如:不允许明细层表依赖应用层的表)这样我们的血缘关系会更加清晰,使用也比较方便。
-
方便维护数据的准确性:如果有一张表出了问题,我们能够根据层级快速定位影响,通过字段血缘,快速识别影响范围。当数据出现问题之后,可以不用修复所有的数据,只需要修复问题表回刷下游影响表即可。
-
减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少一些重复计算,可以节省计算资源。
-
把复杂问题简单化:将一个复杂的任务分解成多个步骤来完成,每一层有不同定位,比较简单和容易理解。
-
屏蔽业务变动影响,屏蔽原始数据的异常:即使原始数据变动,在明细层兼容处理,不会影响模型和下游业务。
-
权限控制:对不同人员,选择性开放对应的层,可以粗粒度的管理权限。
ODS
ODS层设计要点
1)ODS层的表结构设计依托于从业务系统同步过来的数据结构。
2)ODS层要保存全部历史数据(text文件),故其压缩格式应选择压缩比较高的,此处选择gzip。
3)ODS层表名的命名规范为:ods_表名_单分区增量全量标识(inc/full)。
用户行为日志与业务增量同步数据
用户行为日志原本就是JSON数据,而业务增量同步数据是Maxwell转换MySQL中的binlog日志得到的JSON数据
表结构:根据JSON字符串格式设计
外部表:CREATE EXTERNAL TABLE
分区表:PARTITIONED BY (`dt` STRING)
行格式:ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
压缩格式:不需要设置,Hive能自动识别gzip压缩格式
注意:业务增量同步数据分为首日全量同步和每日增量同步,他们每一行数据表示的含义不同
业务全量同步数据
表结构:与MySQL表一致
外部表:CREATE EXTERNAL TABLE
分区表:PARTITIONED BY (`dt` STRING)
行格式:ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
压缩格式:不需要设置,Hive能自动识别gzip压缩格式
注意:NULL DEFINED AS '' 解决DataX中的问题
数据装载
hdfs_to_ods_log.sh:直接load并指定分区
hdfs_to_ods_db.sh:load前需要判断源数据路径是否存在,因为增量同步可能会没有数据
DIM
DIM层设计要点
1)DIM层的设计依据是维度建模理论,该层存储维度模型的维度表。
2)DIM层的数据存储格式为orc列式存储+snappy压缩。(STORED AS ORC + TBLPROPERTIES ('orc.compress' = 'snappy'))
orc查询速度快:查询的时候不需要扫描全部的数据,而只需要读取每次查询涉及的列,这样可以将I/O消耗降低N倍,另外可以保存每一列的统计信息(min、max、sum等),实现部分的谓词下推
snappy压缩速度快
3)DIM层表名的命名规范为dim_表名_全量表或者拉链表标识(full/zip)
全量快照表
数据装载:
WITH 主维表别名 AS (SELECT 维度属性 FROM 主维表 WHERE dt=‘日期’), 相关维表别名 AS (SELECT 维度属性 FROM 相关维表 WHERE dt=‘日期’), 相关维表别名 AS (SELECT 维度属性 FROM 相关维度表 WHERE dt=‘日期’) INSERT OVERWRITE TABLE 维度表 partition(dt=‘日期’)
SELECT 维度属性
FROM 主维表别名
LEFT JOIN 相关维表别名 ON 关联ID相等
LEFT JOIN 相关维表别名 ON 关联ID相等
商品维度表:平台属性和销售属性是结构体数组,需要使用collect_set(named_struct(...))构建
优惠券维度表:购物券类型名称和优惠范围类型名称需要JOIN字典表获取,优惠规则需要使用case判断类型,然后concat拼接字段(满元*减*元 / 满*件打*折')
活动维度表:活动类型名称需要JOIN字典表获取,活动规则需要使用case判断类型,然后concat拼接字段(满元*减*元 / 满*件打*折')
地区维度表:可以只导入一次
日期维度表:通常情况下,时间维度表的数据并不是来自于业务系统,而是手动写入,并且由于时间维度表数据的可预见性,无须每日导入,一般可一次性导入一年的数据。
数据装载时需要建立临时表,上传文件到临时表目录(不是分区表可以直接上传),再查询临时表添加到维度表(维度表为orc存储格式,解析不了文本文件)
拉链表
用户维度表
分区规划与数据流向
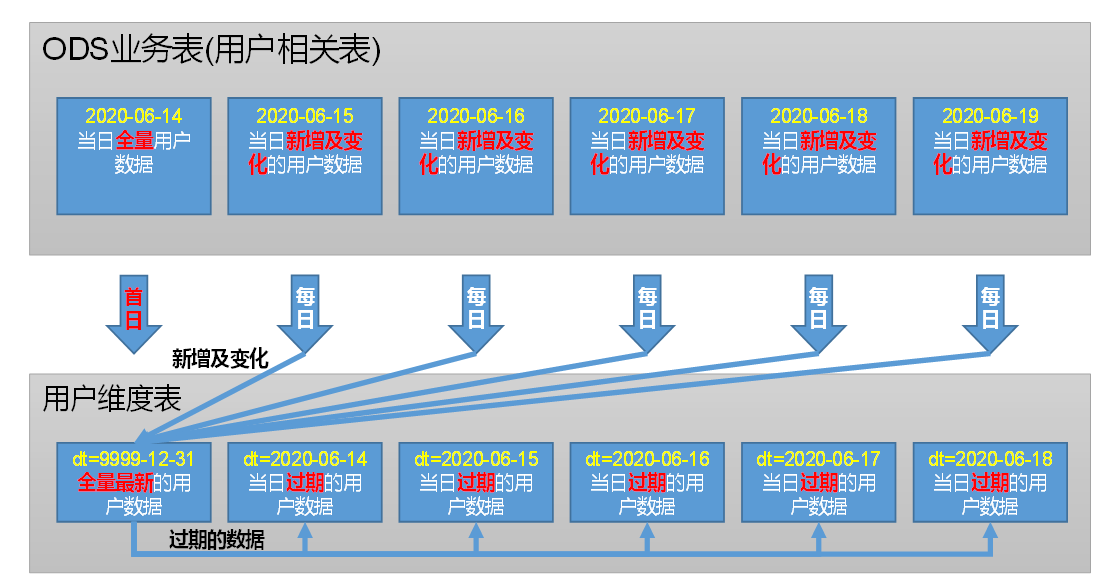
首日装载:
insert overwrite table dim_user_zip partition (dt='9999-12-31') select data.id, data.login_name, data.nick_name, md5(data.name), //脱敏 md5(data.phone_num), //脱敏 md5(data.email), //脱敏 data.user_level, data.birthday, data.gender, data.create_time, data.operate_time, '2020-06-14' start_date, '9999-12-31' end_date from ods_user_info_inc where dt='2020-06-14' and type='bootstrap-insert';//过滤bootstrap-start和bootstrap-end
每日装载:
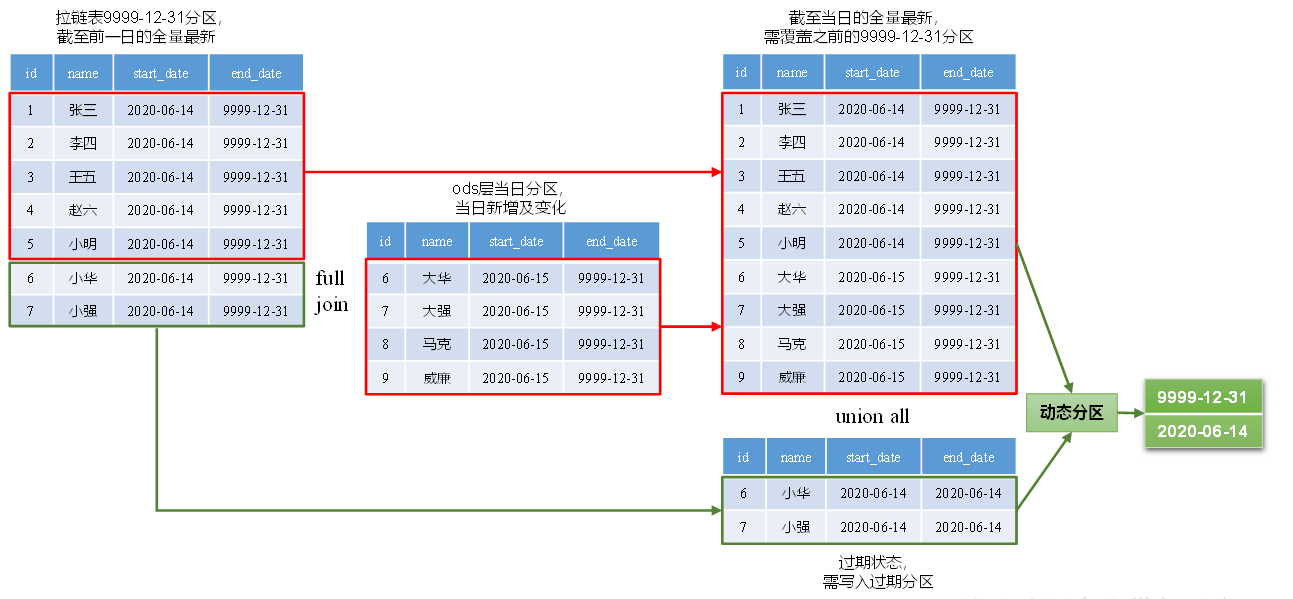
set hive.exec.dynamic.partition.mode=nonstrict;//设置非严格模式
with tmp as ( select old.字段名 old_字段名 new.字段名 new_字段名 from ( select 维度属性 from dim_user_zip where dt='9999-12-31' )old //前一天全量最新数据 full join ( select 字段名, 字段名(脱敏), '2020-06-15' start_date, '9999-12-31' end_date from ( select data.字段名, rank() over(partition by data.id order by ts desc) rk from ods_user_info_inc where dt='2020-06-15' )t1 where rk=1 )new //当天新增及变化数据 on old.id=new.id ) insert overwrite table dim_user_zip partition(dt) select //当日全量最新 if(new_字段名 is null, old_字段名, new_字段名) '9999-12-31' //分区字段 from tmp union all select //过期数据 old_字段名, cast(data_sub('2020-06-15', -1) as string) old_end_date,//类型强转,union需要数据类型一致 cast(data_sub('2020-06-15', -1) as string) dt //分区字段 from tmp where old_id is not null and new_id is not null;
DWD
DWD层设计要点
1)DWD层的设计依据是维度建模理论,该层存储维度模型的事实表。
2)DWD层的数据存储格式为orc列式存储+snappy压缩。
3)DWD层表名的命名规范为dwd_数据域_表名_单分区增量全量标识(inc/full)
交易域
加购事务事实表
分区规划与数据流向
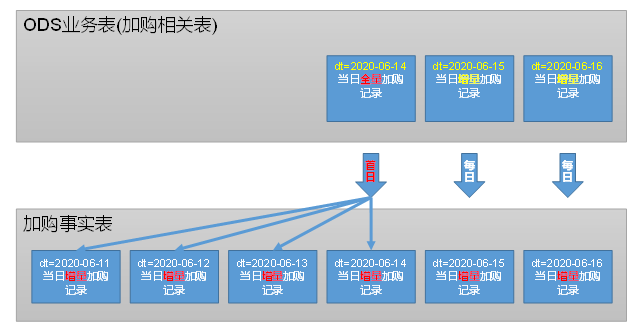
首日装载:格式化创建时间得到date_id、选择create_time作为加购时间、动态分区
from ods_cart_info_inc 的条件
where dt = '2020-06-14' and type = 'bootstrap-insert'
每日装载:格式化创建时间得到date_id、选择ts转化为日期作为加购时间、加购数量为insert操作的sku_num或者update操作的新旧data的sku_num的差值
from ods_cart_info_inc 的条件(当天的插入数据 或者 sku_num变大的更新数据)
where dt='2020-06-15' and (type='insert' or(type='update' and old['sku_num'] is not null and data.sku_num>cast(old['sku_num'] as int)))
知识点:格式化时间date_format(时间字符串,格式)、时间戳转时间字符串from_utc_timestamp(时间戳ms,时区)
下单事务事实表
首日装载:关联相关表、计算商品总价格(sku_num*order_price)、动态分区
每日装载:关联相关表insert数据、计算商品总价格(sku_num*order_price)
取消订单事务事实表
首日装载:订单表取消订单状态的数据与订单详情表的数据inner join,其他表left join、动态分区
每日装载:订单表取消订单状态的update数据(判断更改的是否是订单状态 array_contains(map_keys(old),'order_status'))与订单详情表的数据inner join,其他表left join
from ods_order_detail_inc、ods_order_detail_activity_inc、ods_order_detail_coupon_inc 的条件(当天的数据或者前天的数据 并且是 插入的数据或者首日全量的数据,因为下单的时间可能会比退单早一天)
where (dt='2020-06-15' or dt=date_add('2020-06-15',-1)) and (type = 'insert' or type= 'bootstrap-insert')
知识点:判断数组是否包含某个值 array_contains(数组, 某个值)、返回map集合中所有key组成的数组 map_keys(map集合)
支付成功事务事实表
首日装载:支付表支付成功状态的数据与订单详情表的数据inner join,其他表left join、动态分区
每日装载:支付表支付成功状态的update数据(判断更改的是否是支付状态)与订单详情表的数据inner join,其他表left join
from ods_order_detail_inc、ods_order_detail_activity_inc、ods_order_detail_coupon_inc 的条件 与取消订单事务事实表相同
from ods_order_info_inc 的条件 支付成功状态的update数据(判断更改的是否是订单状态 array_contains(map_keys(old),'order_status'))
退单事务事实表
首日装载:退单表首日全部数据、动态分区
每日装载:退单表每日insert数据、订单表的条件是退单中状态的update数据(判断更改的是否是订单状态)
退款成功事务事实表
首日装载:退款表中支付成功状态的数据left join订单表、退单表(关联条件为订单id和商品id相同)、字典表、动态分区
每日装载:退款表中支付成功状态的update数据 left join订单表、退单表(关联条件为订单id和商品id相同)、字典表。
其中订单表(退款完成状态)、退单表(退单完成状态)都是update数据并且判断更新的是否是各自的状态
购物车周期快照事实表
首日装载与每日装载:过滤已下单的数据
工具域
优惠券领取事务事实表
首日装载:取首日全量全部数据,按领取时间动态分区
每日装载:取增量insert数据
优惠券使用(下单)事务事实表
首日装载:取首日全量使用时间不为空的数据,按使用时间动态分区
每日装载:取增量update数据且更新的是使用时间
优惠券使用(支付)事务事实表
首日装载:取首日全量支付时间不为空的数据,按支付时间动态分区
每日装载:取增量update数据且更新的是支付时间
互动域
收藏商品事务事实表
首日装载:取首日全量全部数据、按创建时间动态分区
每日装载:取增量insert数据
评价事务事实表
首日装载:取首日全量全部数据、关联字典表、按创建时间动态分区
每日装载:取增量insert数据、关联字典表
流量域
页面浏览事务事实表
首日装载与每日装载:page结构体不为空、关联地区表获取省份id、划分会话、时间戳转化为日期和浏览时间
划分会话方法一
if(page.last_page_id is null,ts,null) session_start_point concat(mid_id,'-',last_value(session_start_point,true) over (partition by mid_id order by ts)) session_id
划分会话方法二
if(page.last_page_id is null,1,0) session_start_point concat(mid_id,'-',sum(session_start_point) over (partition by mid_id order by ts)) session_id
注意:Struct is not null过滤失效BUG,解决方法是使用结构体中一个字段过滤或者关闭CBO优化(set hive.cbo.enable=false;)
知识点:last_value(某字段,true) 窗口中某字段最后一个值,为空则跳取下一个值(往上)
启动事务事实表
首日装载与每日装载:start结构体不为空、关联地区表获取省份id、时间戳转化为日期和启动时间
注意:start关键字报错,使用`start`,shell脚本中要用 \`start\`
动作事务事实表
首日装载与每日装载:action数组不为空、关联地区表获取省份id、时间戳转化为日期和动作时间、拆分动作数组
from ods_log_inc lateral view explode(actions) tmp as action
知识点:explode(arr)将 hive 一列中复杂的 Array 或者 Map 结构拆分成多行;
table LATERAL VIEW udtf(expression) tableAlias AS columnAlias
生成侧写表,lateral view首先为原始表的每行调用UDTF,UTDF会把一行拆分成一或者多行,再将多行中的每一行与原来行关联,产生一个新的表取代原表,其中tableAlias并不是整张表,而是只有炸裂字段的虚拟表。
曝光事务事实表
首日装载与每日装载:display数组不为空、关联地区表获取省份id、时间戳转化为日期和曝光时间、拆分曝光数组
错误事务事实表
首日装载与每日装载:err结构体不为空、关联地区表获取省份id、时间戳转化为日期和错误时间
注意:运行后报错,到hadoop103:8088查看正在运行的job找到报错信息(Hive on Spark有BUG)改为mr引擎:set hive.execution.engine=mr
用户域
用户注册事务事实表
首日装载:用户表left join日志表中注册页面并且用户id不为空的数据、关联地区表获取省份id、时间字符串转换
每日装载:用户表insert数据left join日志表中注册页面并且用户id不为空的数据、关联地区表获取省份id、时间字符串转换
用户登录事务事实表
首日装载和每日装载:page结构体不为空、划分会话、找到每个会话里第一个用户id不为空的记录(过滤用户id为空的数据、排名取top1)、时间戳转化为日期和登录时间、关联地区表获取省份id
where user_id is not null row_number() over (partition by session_id order by ts) rn where rn=1
DWS
DWS层设计要点
1)DWS层的设计参考指标体系。
2)DWS层的数据存储格式为orc列式存储+snappy压缩。
3)DWS层表名的命名规范为dws_数据域_统计粒度_业务过程_统计周期(1d/nd/td)
注:1d表示最近1日,nd表示最近n日,td表示历史至今。
设计过程
需求:[最近1、7、30日] [各品牌] [订单数、下单人数]
需求分析:找到派生指标
最近1、7、30日 各品牌 订单数 本身就是一个派生指标 ,定义如下
原子指标:业务过程为下单,度量为1,聚合逻辑为count()
统计周期:最近1、7、30日
业务限定:无
统计粒度:品牌
计算逻辑:直接由事实表聚合而来
需求分析:
最近1、7、30日 各品牌 订单人数 本身就是一个派生指标 ,定义如下
原子指标:业务过程为下单,度量为user_id,聚合逻辑为count(distinct())
统计周期:最近1、7、30日
业务限定:无
统计粒度:品牌
计算逻辑:直接由事实表聚合而来
设计表:一张汇总表通常包含业务过程相同、统计周期相同、统计粒度相同的多个派生指标
交易域品牌粒度订单最近1天汇总表 dws_trade_tm_order_1d:
属性:品牌id、下单次数、下单人数 (展示数据不方便)
属性:品牌id、品牌名称、下单次数、下单人数(可能会有其他需求,从事实表度量值推断)
属性:品牌id、品牌名称、下单次数、下单人数、下单件数、下单金额
数据装载:事实表分组聚合
下单事实表取最近一天分区关联sku商品表,按品牌分组,进行聚合
下单次数:count(*)
下单人数:count(distinct(user_id))
下单件数:sum(sku_num)
下单金额:sum(split_total_amount)
设计表:
交易域品牌粒度订单最近n天汇总表 dws_trade_tm_order_nd:
属性:品牌id、品牌名称、最近7日下单次数、最近7日下单人数、最近7日下单件数、最近7日下单金额、最近30日下单次数、最近30日下单人数、最近30日下单件数、最近30日下单金额
数据装载:
品牌粒度订单最近1天汇总表最近30天分区,按品牌分组,进行聚合
最近7日下单次数:sum(if(dt>=date_sub('2020-06-14',6),order_count,0))
最近7日下单人数:sum(if(dt>=date_sub('2020-06-14',6),order_user_count,0)) (人数没有去重)
最近7日下单件数:sum(if(dt>=date_sub('2020-06-14',6),order_num,0))
最近7日下单金额:sum(if(dt>=date_sub('2020-06-14',6),order_total_amount,0))
最近30日下单次数:sum(order_count)
最近30日下单人数:sum(order_user_count)(人数没有去重)
最近30日下单件数:sum(order_num)
最近30日下单金额:sum(order_total_amount)
注意:此时下单人数会出现重复,且因为没有用户id无法去重
解决方法:降低汇总表粒度
交易域品牌粒度订单最近1天汇总表 dws_trade_tm_order_1d --》交易域用户品牌粒度订单最近1天汇总表 dws_trade_user_tm_order_1d
属性:用户id、品牌id、品牌名称、下单次数、下单件数、下单金额
交易域品牌粒度订单最近1天汇总表 dws_trade_tm_order_nd --》交易域用户品牌粒度订单最近n天汇总表 dws_trade_user_tm_order_nd
属性:用户id、品牌id、品牌名称、最近7日下单次数、最近7日下单件数、最近7日下单金额、最近30日下单次数、最近30日下单件数、最近30日下单金额
数据装载:
下单事实表取最近一天分区关联sku商品表,按用户、品牌分组,进行聚合
下单次数:count(*)
下单件数:sum(sku_num)
下单金额:sum(split_total_amount)
品牌粒度订单最近1天汇总表最近30天分区,按品牌分组,进行聚合
最近7日下单次数:sum(if(dt>=date_sub('2020-06-14',6),order_count,0))
最近7日下单件数:sum(if(dt>=date_sub('2020-06-14',6),order_num,0))
最近7日下单金额:sum(if(dt>=date_sub('2020-06-14',6),order_total_amount,0))
最近30日下单次数:sum(order_count)
最近30日下单件数:sum(order_num)
最近30日下单金额:sum(order_total_amount)
需求实现:
[最近1日] [各品牌] [订单数、订单人数]
select tm_id, tm_name, sum(order_count), count(distinct(user_id)) from dws_trade_user_tm_order_1d where dt='2020-06-14' group by tm_id,tm_name
[最近n日] [各品牌] [订单数、订单人数]
select tm_id, tm_name, sum(order_count_7d), count(distinct(if(order_count_7d>0,user_id,null))) sum(order_count_30d), count(distinct(user_id)) from dws_trade_user_tm_order_nd where dt='2020-06-14' group by tm_id,tm_name
需求分析修改:
最近1、7、30日 各品牌 订单数 依赖的一个派生指标 ,定义如下
原子指标:业务过程为下单,度量为1,聚合逻辑为count()
统计周期:最近1、7、30日
业务限定:无
统计粒度:用户-品牌
计算逻辑:由其依赖的一个派生指标计算而来
最近1、7、30日 各品牌 下单人数 依赖的一个派生指标 ,定义如下
原子指标:业务过程为下单,不依赖其中的度量
统计周期:最近1、7、30日
业务限定:无
统计粒度:用户-品牌
计算逻辑:由其依赖的一个派生指标计算而来
新的需求:[最近1、7、30日] [各品类] [订单数、下单人数]
设计:与品牌粒度汇总表基本一致(此时发现需要重复相同的聚合)
优化:用户-品牌 表、用户-品类 表 --》 用户-商品 表 (节省整体聚合工作量,设计一个更通用的汇总表)
结论:设计过程中汇总表的粒度不断变化,直到成为一张比较通用的汇总表
新的需求:[最近1、7、30日] [新增下单人数、新增支付人数]
需求分析:需要一个用户粒度订单历史至今汇总表
设计表:
交易域用户粒度订单历史至今汇总表
属性:用户id、首次下单日期、末次下单日期、下单次数、下单件数、下单金额
数据装载:
首日:
没有1d汇总表,下单事实表按用户id分组
首次下单日期:min(date_id)
末次下单日期:max(date_id)
下单次数:count(distinct(order_id))
下单件数:sum(sku_num)
下单金额:sum(split_toatl_amount)
每日:避免重复计算
昨天的用户粒度订单历史至今汇总表 + 今天的下单事实表按用户id分组聚合
使用full outer join相加:
nvl(new.uesr_id,old.user_id)
首次下单日期:if(old.user_id is null,'2020-06-15',old.order_date_first)
末次下单日期:if(new.user_id is null,old.order_date_last,'2020-06-15')
下单次数:nvl(old.order_count_td,0)+nvl(new.order_count_1d,0)(注意null)
下单件数:nvl(old.order_num_td,0)+nvl(new.order_num_1d,0)(注意null)
下单金额:nvl(old.order_total_amount_td,0)+nvl(new.order_total_amount_1d,0)(注意null)
使用union all相加:
字段数量不一致,用'2020-06-15'补齐首次下单日期和末次下单日期
union后按照用户id分组
首次下单日期:min(order_date_first)
末次下单日期:max(order_date_last)
下单次数:sum(order_count_td)
下单件数:sum(order_num_td)
下单金额:sum(order_total_amount_td)
细节补充:
最近1日汇总表:
首日装载(除了流量域)需要进行历史数据初始化,按照粒度id与dt分组聚合,进行动态分区;注意数值判空问题
最近n日汇总表:
不进行历史数据初始化,没必要
历史至今汇总表:
可以从已有的1d汇总表取数据
ADS
流量主题
[最近1/7/30日][各渠道]流量统计:
insert overwrite table ads_traffic_stats_by_channel select * from ads_traffic_stats_by_channel union select '2020-06-14' dt, //统计日期 recent_days, //最近天数 channel, //渠道 cast(count(distinct(mid_id)) as bigint) uv_count, //访客数 cast(avg(during_time_1d)/1000 as bigint) avg_duration_sec, //会话平均停留时长
cast(avg(page_count_1d) as bigint) avg_page_count, //会话平均浏览页面数 cast(count(*) as bigint) sv_count, //会话总数 cast(sum(if(page_count_1d=1,1,0))/count(*) as decimal(16,2)) bounce_rate //跳出率 from dws_traffic_session_page_view_1d lateral view explode(array(1,7,30)) tmp as recent_days where dt>=date_add('2020-06-14',-recent_days+1) //匹配不同的行 group by recent_days,channel;
说明:
没有分区,避免小文件;
只使用insert overwrite会丢失历史数据,使用insert into会出现重复数据且会产生小文件,所以使用insert overwrite 旧数据 union 新的数据,不重复,也没有小文件
路径分析
用户访问路径的可视化通常使用桑基图。
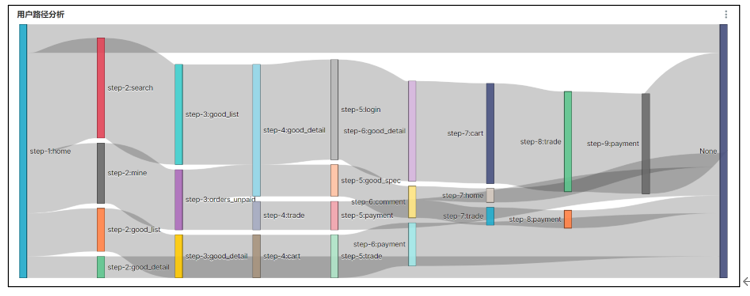
桑基图需要我们提供每种页面跳转的次数,每个跳转由source/target表示,source指跳转起始页面,target表示跳转终到页面。
insert overwrite table ads_page_path select * from ads_page_path union select '2020-06-14' dt, //统计日期 recent_days, //最近天数 source, //跳转起始页面ID nvl(target,'null'), //跳转终到页面ID count(*) path_count //跳转次数 from ( select recent_days, concat('step-',rn,':',page_id) source, concat('step-',rn+1,':',next_page_id) target from ( select recent_days, page_id, lead(page_id,1,null) over(partition by session_id,recent_days order by view_time) next_page_id, row_number() over (partition by session_id,recent_days order by view_time) rn from dwd_traffic_page_view_inc lateral view explode(array(1,7,30)) tmp as recent_days where dt>=date_add('2020-06-14',-recent_days+1) )t1 )t2 group by recent_days,source,target;
说明:
桑基图source不能为空:page_id作为source,下一个page_id作为target
桑基图不能存在环:加上前缀 'step-n:'
用户主题
用户变动统计
insert overwrite table ads_user_change select * from ads_user_change union select churn.dt, //统计日期 user_churn_count, //流失用户数:统计7日前当天活跃,但最近7日未活跃的用户总数。 user_back_count //回流用户数:之前的活跃用户,一段时间未活跃(流失),今日又活跃了 from ( //流失用户数 select '2020-06-14' dt, count(*) user_churn_count from dws_user_user_login_td where dt='2020-06-14' and login_date_last=date_add('2020-06-14',-7) )churn join ( //回流用户数 select '2020-06-14' dt, count(*) user_back_count from ( //今天活跃的用户 select user_id, login_date_last from dws_user_user_login_td where dt='2020-06-14'
and login_date_last='2020-06-14' )t1 join ( //上次活跃日期 select user_id, login_date_last login_date_previous from dws_user_user_login_td where dt=date_add('2020-06-14',-1) )t2 on t1.user_id=t2.user_id where datediff(login_date_last,login_date_previous)>=8 )back on churn.dt=back.dt;
说明:
流失用户:末次活动日期为7天前
回流用户:末次活动日期为今天,上次活动日期至少在8天前
上次活动日期:今天活跃用户 昨天的末次活动日期
用户留存率
留存分析一般包含新增留存和活跃留存分析。
新增留存分析是分析某天的新增用户中,有多少人有后续的活跃行为。活跃留存分析是分析某天的活跃用户中,有多少人有后续的活跃行为。
新增留存率具体是指留存用户数与新增用户数的比值
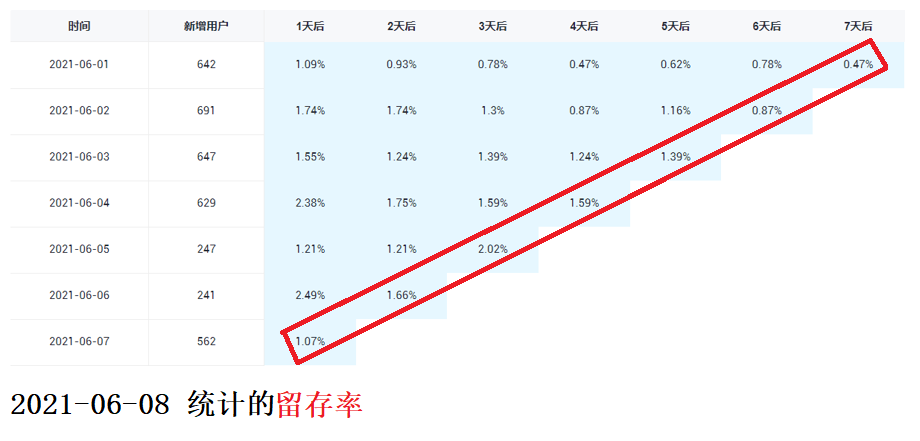
insert overwrite table ads_user_retention select * from ads_user_retention union select '2020-06-14' dt, //统计日期 login_date_first create_date, //用户新增日期 datediff('2020-06-14',login_date_first) retention_day, //截至当前日期留存天数 sum(if(login_date_last='2020-06-14',1,0)) retention_count, //留存用户数量 count(*) new_user_count, //新增用户数量 cast(sum(if(login_date_last='2020-06-14',1,0))/count(*)*100 as decimal(16,2)) retention_rate //留存率 from ( //2020-06-07 ~ 2020-06-13 每天新增用户 select user_id, date_id login_date_first from dwd_user_register_inc where dt>=date_add('2020-06-14',-7) and dt<'2020-06-14' )t1 join ( //2020-06-14 活跃用户 select user_id, login_date_last from dws_user_user_login_td where dt='2020-06-14' )t2 on t1.user_id=t2.user_id group by login_date_first;
用户新增活跃统计([最近1、7、30日][新增用户数、活跃用户数])
insert overwrite table ads_user_stats select * from ads_user_stats union select '2020-06-14' dt, //统计日期 t1.recent_days, //最近n天 new_user_count, // 新增用户数 active_user_count //活跃用户数 from ( select recent_days, sum(if(login_date_last>=date_add('2020-06-14',-recent_days+1),1,0)) new_user_count from dws_user_user_login_td lateral view explode(array(1,7,30)) tmp as recent_days where dt='2020-06-14' group by recent_days )t1 join ( select recent_days, sum(if(date_id>=date_add('2020-06-14',-recent_days+1),1,0)) active_user_count from dwd_user_register_inc lateral view explode(array(1,7,30)) tmp as recent_days group by recent_days )t2 on t1.recent_days=t2.recent_days;
用户行为漏斗分析
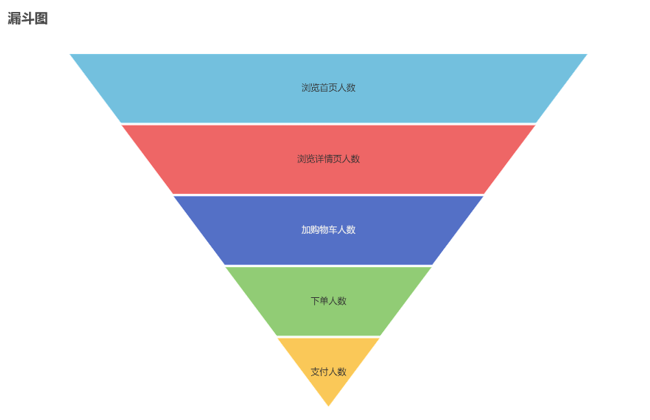
具体需求:[最近1、7、30日] [首页浏览人数、商品详情页浏览人数、加购人数、下单人数、支付人数]
insert overwrite table ads_user_action select * from ads_user_action union select '2020-06-14' dt, //统计日期 page.recent_days, //最近天数 home_count, //浏览首页人数 good_detail_count, //浏览商品详情页人数 cart_count, //加入购物车人数 order_count, //下单人数 payment_count //支付人数 from ( //浏览首页人数、浏览商品详情页人数 select 1 recent_days, sum(if(page_id='home',1,0)) home_count, sum(if(page_id='good_detail',1,0)) good_detail_count from dws_traffic_page_visitor_page_view_1d where dt='2020-06-14' and page_id in ('home','good_detail') union all select recent_days, sum(if(page_id='home' and view_count>0,1,0)), //不能直接count(*),因为可能会有最近7天没浏览,但最近30天浏览的人 sum(if(page_id='good_detail' and view_count>0,1,0)) from ( select recent_days, page_id, case recent_days //匹配不同的列 when 7 then view_count_7d when 30 then view_count_30d end view_count from dws_traffic_page_visitor_page_view_nd lateral view explode(array(7,30)) tmp as recent_days where dt='2020-06-14' and page_id in ('home','good_detail') )t1 group by recent_days )page join ( //加入购物车人数 select 1 recent_days, count(*) cart_count from dws_trade_user_cart_add_1d where dt='2020-06-14' union all select recent_days, sum(if(cart_count>0,1,0)) from ( select recent_days, case recent_days when 7 then cart_add_count_7d when 30 then cart_add_count_30d end cart_count from dws_trade_user_cart_add_nd lateral view explode(array(7,30)) tmp as recent_days where dt='2020-06-14' )t1 group by recent_days )cart on page.recent_days=cart.recent_days join ( //下单人数 select 1 recent_days, count(*) order_count from dws_trade_user_order_1d where dt='2020-06-14' union all select recent_days, sum(if(order_count>0,1,0)) from ( select recent_days, case recent_days when 7 then order_count_7d when 30 then order_count_30d end order_count from dws_trade_user_order_nd lateral view explode(array(7,30)) tmp as recent_days where dt='2020-06-14' )t1 group by recent_days )ord on page.recent_days=ord.recent_days join ( //支付人数 select 1 recent_days, count(*) payment_count from dws_trade_user_payment_1d where dt='2020-06-14' union all select recent_days, sum(if(order_count>0,1,0)) from ( select recent_days, case recent_days when 7 then payment_count_7d when 30 then payment_count_30d end order_count from dws_trade_user_payment_nd lateral view explode(array(7,30)) tmp as recent_days where dt='2020-06-14' )t1 group by recent_days )pay on page.recent_days=pay.recent_days;
新增交易用户统计([最近1、7、30日][新增下单数、新增支付数])
insert overwrite table ads_new_buyer_stats select * from ads_new_buyer_stats union select '2020-06-14', //统计日期 odr.recent_days, //最近天数 new_order_user_count, //新增下单数 new_payment_user_count //新增支付数 from ( select recent_days, sum(if(order_date_first>=date_add('2020-06-14',-recent_days+1),1,0)) new_order_user_count from dws_trade_user_order_td lateral view explode(array(1,7,30)) tmp as recent_days where dt='2020-06-14' group by recent_days )odr join ( select recent_days, sum(if(payment_date_first>=date_add('2020-06-14',-recent_days+1),1,0)) new_payment_user_count from dws_trade_user_payment_td lateral view explode(array(1,7,30)) tmp as recent_days where dt='2020-06-14' group by recent_days )pay on odr.recent_days=pay.recent_days;
商品主题
[最近7、30日] [各品牌] [复购率] (重复购买人数占购买人数比例)
insert overwrite table ads_repeat_purchase_by_tm select * from ads_repeat_purchase_by_tm union select '2020-06-14' dt, //统计日期 recent_days, //最近天数 tm_id, //品牌ID tm_name, //品牌名称 cast(sum(if(order_count>=2,1,0))/sum(if(order_count>=1,1,0)) as decimal(16,2)) //复购率 from ( select '2020-06-14' dt, recent_days, user_id, tm_id, tm_name, sum(order_count) order_count from ( select recent_days, user_id, tm_id, tm_name, case recent_days when 7 then order_count_7d when 30 then order_count_30d end order_count from dws_trade_user_sku_order_nd lateral view explode(array(7,30)) tmp as recent_days where dt='2020-06-14' )t1 group by recent_days,user_id,tm_id,tm_name )t2 group by recent_days,tm_id,tm_name;
各品牌商品交易统计([最近1、7、30日] [各品牌] [订单数、订单人数、退单数、退单人数])
insert overwrite table ads_trade_stats_by_tm select * from ads_trade_stats_by_tm union select '2020-06-14' dt, //统计日期 nvl(odr.recent_days,refund.recent_days), //最近天数 nvl(odr.tm_id,refund.tm_id), //品牌ID nvl(odr.tm_name,refund.tm_name), //品牌名称 nvl(order_count,0), //订单数 nvl(order_user_count,0), //订单人数 nvl(order_refund_count,0), //退单数 nvl(order_refund_user_count,0) //退单人数 from ( select 1 recent_days, tm_id, tm_name, sum(order_count_1d) order_count, count(distinct(user_id)) order_user_count from dws_trade_user_sku_order_1d where dt='2020-06-14' group by tm_id,tm_name union all select recent_days, tm_id, tm_name, sum(order_count), count(distinct(if(order_count>0,user_id,null))) from ( select recent_days, user_id, tm_id, tm_name, case recent_days when 7 then order_count_7d when 30 then order_count_30d end order_count from dws_trade_user_sku_order_nd lateral view explode(array(7,30)) tmp as recent_days where dt='2020-06-14' )t1 group by recent_days,tm_id,tm_name )odr full outer join //避免丢失数据 ( select 1 recent_days, tm_id, tm_name, sum(order_refund_count_1d) order_refund_count, count(distinct(user_id)) order_refund_user_count from dws_trade_user_sku_order_refund_1d where dt='2020-06-14' group by tm_id,tm_name union all select recent_days, tm_id, tm_name, sum(order_refund_count), count(if(order_refund_count>0,user_id,null)) from ( select recent_days, user_id, tm_id, tm_name, case recent_days when 7 then order_refund_count_7d when 30 then order_refund_count_30d end order_refund_count from dws_trade_user_sku_order_refund_nd lateral view explode(array(7,30)) tmp as recent_days where dt='2020-06-14' )t1 group by recent_days,tm_id,tm_name )refund on odr.recent_days=refund.recent_days and odr.tm_id=refund.tm_id and odr.tm_name=refund.tm_name;
知识点:多表全外联时,关联条件可以使用coalesce()取第一个不为空的关联id
各品类商品交易统计([最近1、7、30日] [各品类] [订单数、订单人数、退单数、退单人数])
insert overwrite table ads_trade_stats_by_cate select * from ads_trade_stats_by_cate union select '2020-06-14' dt, //统计日期 nvl(odr.recent_days,refund.recent_days), //最近天数 nvl(odr.category1_id,refund.category1_id), //一级分类id nvl(odr.category1_name,refund.category1_name), //一级分类名称 nvl(odr.category2_id,refund.category2_id), //二级分类id nvl(odr.category2_name,refund.category2_name), //二级分类名称 nvl(odr.category3_id,refund.category3_id), //三级分类id nvl(odr.category3_name,refund.category3_name), //三级分类名称 nvl(order_count,0), //订单数 nvl(order_user_count,0), //订单人数 nvl(order_refund_count,0), //退单数 nvl(order_refund_user_count,0) //退单人数 from ( select 1 recent_days, category1_id, category1_name, category2_id, category2_name, category3_id, category3_name, sum(order_count_1d) order_count, count(distinct(user_id)) order_user_count from dws_trade_user_sku_order_1d where dt='2020-06-14' group by category1_id,category1_name,category2_id,category2_name,category3_id,category3_name union all select recent_days, category1_id, category1_name, category2_id, category2_name, category3_id, category3_name, sum(order_count), count(distinct(if(order_count>0,user_id,null))) from ( select recent_days, user_id, category1_id, category1_name, category2_id, category2_name, category3_id, category3_name, case recent_days when 7 then order_count_7d when 30 then order_count_30d end order_count from dws_trade_user_sku_order_nd lateral view explode(array(7,30)) tmp as recent_days where dt='2020-06-14' )t1 group by recent_days,category1_id,category1_name,category2_id,category2_name,category3_id,category3_name )odr full outer join ( select 1 recent_days, category1_id, category1_name, category2_id, category2_name, category3_id, category3_name, sum(order_refund_count_1d) order_refund_count, count(distinct(user_id)) order_refund_user_count from dws_trade_user_sku_order_refund_1d where dt='2020-06-14' group by category1_id,category1_name,category2_id,category2_name,category3_id,category3_name union all select recent_days, category1_id, category1_name, category2_id, category2_name, category3_id, category3_name, sum(order_refund_count), count(distinct(if(order_refund_count>0,user_id,null))) from ( select recent_days, user_id, category1_id, category1_name, category2_id, category2_name, category3_id, category3_name, case recent_days when 7 then order_refund_count_7d when 30 then order_refund_count_30d end order_refund_count from dws_trade_user_sku_order_refund_nd lateral view explode(array(7,30)) tmp as recent_days where dt='2020-06-14' )t1 group by recent_days,category1_id,category1_name,category2_id,category2_name,category3_id,category3_name )refund on odr.recent_days=refund.recent_days and odr.category1_id=refund.category1_id and odr.category1_name=refund.category1_name and odr.category2_id=refund.category2_id and odr.category2_name=refund.category2_name and odr.category3_id=refund.category3_id and odr.category3_name=refund.category3_name;
各分类商品购物车存量Top3
insert overwrite table ads_sku_cart_num_top3_by_cate select * from ads_sku_cart_num_top3_by_cate union select '2020-06-14' dt, //统计日期 category1_id, //一级分类ID category1_name, //一级分类名称 category2_id, //二级分类ID category2_name, //二级分类名称 category3_id, //三级分类ID category3_name, //三级分类名称 sku_id, //商品id sku_name, //商品名称 cart_num, //购物车中商品数量 rk //排名 from ( select sku_id, sku_name, category1_id, category1_name, category2_id, category2_name, category3_id, category3_name, cart_num, rank() over (partition by category1_id,category2_id,category3_id order by cart_num desc) rk from ( //商品购物车存量 select sku_id, sum(sku_num) cart_num from dwd_trade_cart_full where dt='2020-06-14' group by sku_id )cart left join ( //维度信息 select id, sku_name, category1_id, category1_name, category2_id, category2_name, category3_id, category3_name from dim_sku_full where dt='2020-06-14' )sku on cart.sku_id=sku.id )t1 where rk<=3;
交易主题
交易综合统计([最近1、7、30日] [订单总额、订单数、订单人数、退单数、退单人数])
insert overwrite table ads_trade_stats select * from ads_trade_stats union select '2020-06-14', //统计日期 odr.recent_days, //最近天数 order_total_amount, //订单总额,GMV order_count, //订单数 order_user_count, //下单人数 order_refund_count, //退单数 order_refund_user_count //退单人数 from ( select 1 recent_days, sum(order_total_amount_1d) order_total_amount, sum(order_count_1d) order_count, count(*) order_user_count from dws_trade_user_order_1d where dt='2020-06-14' union all select recent_days, sum(order_total_amount), sum(order_count), sum(if(order_count>0,1,0)) from ( select recent_days, case recent_days when 7 then order_total_amount_7d when 30 then order_total_amount_30d end order_total_amount, case recent_days when 7 then order_count_7d when 30 then order_count_30d end order_count from dws_trade_user_order_nd lateral view explode(array(7,30)) tmp as recent_days where dt='2020-06-14' )t1 group by recent_days )odr join ( select 1 recent_days, sum(order_refund_count_1d) order_refund_count, count(*) order_refund_user_count from dws_trade_user_order_refund_1d where dt='2020-06-14' union all select recent_days, sum(order_refund_count), sum(if(order_refund_count>0,1,0)) from ( select recent_days, case recent_days when 7 then order_refund_count_7d when 30 then order_refund_count_30d end order_refund_count from dws_trade_user_order_refund_nd lateral view explode(array(7,30)) tmp as recent_days where dt='2020-06-14' )t1 group by recent_days )refund on odr.recent_days=refund.recent_days;
各省份交易统计([最近1、7、30日] [各省份] [订单数、订单金额])
insert overwrite table ads_order_by_province select * from ads_order_by_province union select '2020-06-14' dt, //统计日期 1 recent_days, //最近天数 province_id, //省份ID province_name, //省份名称 area_code, //地区编码 iso_code, //国际标准地区编码 iso_3166_2, //国际标准地区编码 order_count_1d, //订单数 order_total_amount_1d //订单金额 from dws_trade_province_order_1d where dt='2020-06-14' union //去重 select '2020-06-14' dt, recent_days, province_id, province_name, area_code, iso_code, iso_3166_2, sum(order_count), sum(order_total_amount) from ( select recent_days, province_id, province_name, area_code, iso_code, iso_3166_2, case recent_days when 7 then order_count_7d when 30 then order_count_30d end order_count, case recent_days when 7 then order_total_amount_7d when 30 then order_total_amount_30d end order_total_amount from dws_trade_province_order_nd lateral view explode(array(7,30)) tmp as recent_days where dt='2020-06-14' )t1 group by recent_days,province_id,province_name,area_code,iso_code,iso_3166_2;
优惠券主题
最近30天发布的优惠券的补贴率
insert overwrite table ads_coupon_stats select * from ads_coupon_stats union select '2020-06-14' dt, coupon_id, coupon_name, start_date, coupon_rule, cast(coupon_reduce_amount_30d/original_amount_30d as decimal(16,2)) from dws_trade_coupon_order_nd where dt='2020-06-14';
活动主题
最近30天发布的活动的补贴率
insert overwrite table ads_activity_stats select * from ads_activity_stats union select '2020-06-14' dt, activity_id, activity_name, start_date, cast(activity_reduce_amount_30d/original_amount_30d as decimal(16,2)) from dws_trade_activity_order_nd where dt='2020-06-14';
报表数据导出
将ads各指标的统计结果导出到MySQL数据库中
注意:要不要导出到mysql需要根据具体情况决定,比如下游数据需要供java组使用(开发可视化系统、第三方系统等等)则需要导出到mysql;
数据导出工具选用DataX,选用HDFSReader和MySQLWriter。
创建MySQL库和表
注意:创建MySQL表必须有主键,配合replace writeMode避免数据重复问题;主键的选择需要能唯一代表一行数据
编写DataX配置文件生成脚本
编写DataX配置文件批量生成脚本
编写每日导出脚本
DataX导出路径不允许存在空文件,需要清理空文件
任务调度
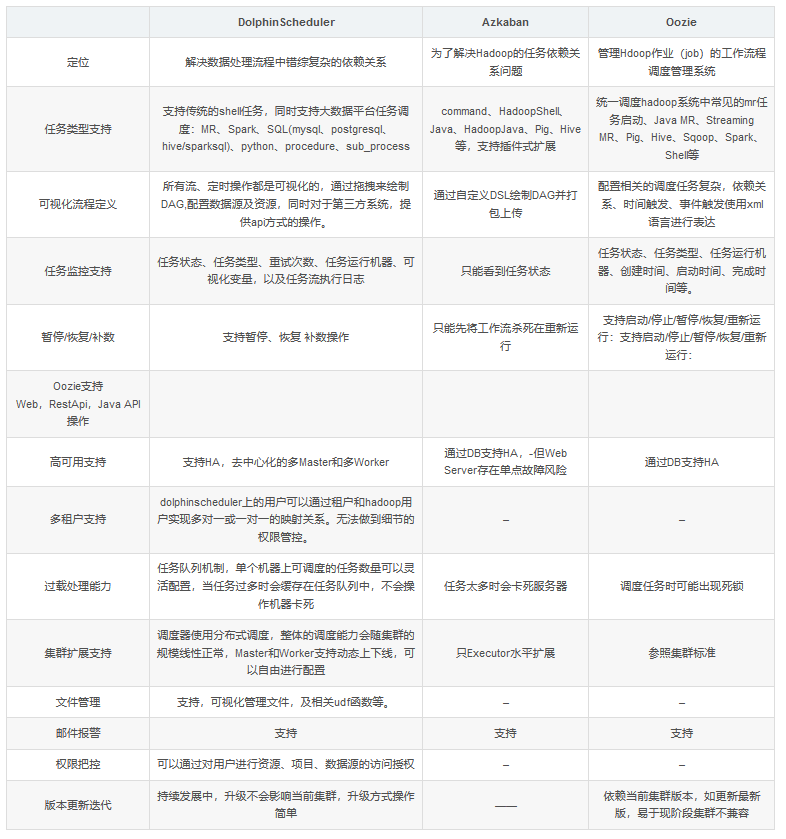
任务调度 - 核心
4.0核心:Azkaban
5.0核心:DolpinScheduler为什么使用DolpinScheduler代替Azkaban?
工作流程
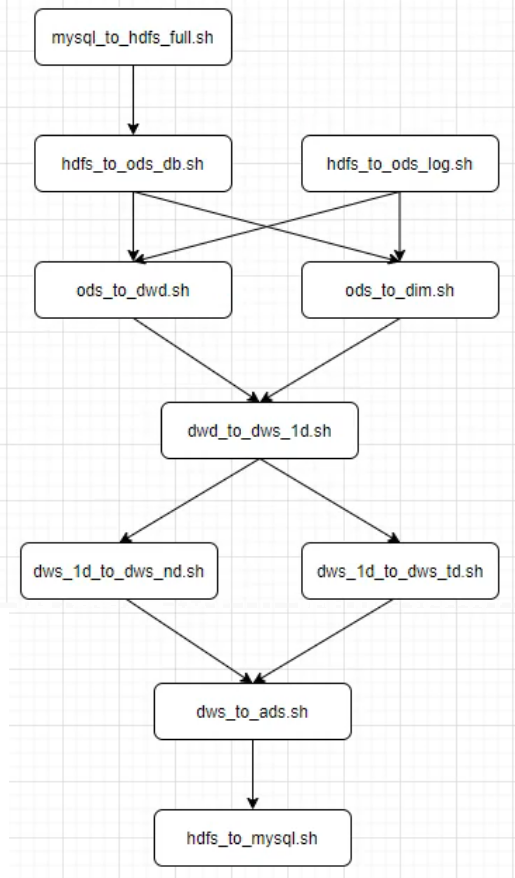
注意:上图所示工作流程 并行度不高、一个重试单位为多张表组成的一个工作单元,重试代价高
解决方法:一张表组成一个工作单元
数据仓库周边工作
可视化、即席查询、集群监控、用户认证、权限管理、元数据管理、数据质量管理
Hive on Spark调优
集群资源配置
Yarn配置说明
(1)yarn.nodemanager.resource.memory-mb
该参数的含义是,一个NodeManager节点分配给Container使用的内存。该参数的配置,取决于NodeManager所在节点的总内存容量和该节点运行的其他服务的数量。
(2)yarn.nodemanager.resource.cpu-vcores
该参数的含义是,一个NodeManager节点分配给Container使用的CPU核数。该参数的配置,同样取决于NodeManager所在节点的总CPU核数和该节点运行的其他服务。
(3)yarn.scheduler.maximum-allocation-mb
该参数的含义是,单个Container能够使用的最大内存。由于Spark的yarn模式下,Driver和Executor都运行在Container中,故该参数不能小于Driver和Executor的内存配置
(4)yarn.scheduler.minimum-allocation-mb
该参数的含义是,单个Container能够使用的最小内存
Spark配置
Executor配置说明
1)Executor CPU核数配置
单个Executor的CPU核数,由spark.executor.cores参数决定,建议配置为4-6,具体配置为多少,视具体情况而定,原则是尽量充分利用资源。
2)Executor内存配置
Executor相关的参数有:spark.executor.memory和spark.executor.memoryOverhead。spark.executor.memory用于指定Executor进程的堆内存大小,这部分内存用于任务的计算和存储;spark.executor.memoryOverhead用于指定Executor进程的堆外内存,这部分内存用于JVM的额外开销,操作系统开销等。两者的和才算一个Executor进程所需的总内存大小。默认情况下spark.executor.memoryOverhead的值等于spark.executor.memory*0.1。
以上两个参数的推荐配置思路是,先按照单个NodeManager的核数和单个Executor的核数,计算出每个NodeManager最多能运行多少个Executor。在将NodeManager的总内存平均分配给每个Executor,最后再将单个Executor的内存按照大约10:1的比例分配到spark.executor.memory和spark.executor.memoryOverhead。
2)Executor个数配置
一个Spark应用的Executor个数的指定方式有两种,静态分配和动态分配。
(1)静态分配
可通过spark.executor.instances指定一个Spark应用启动的Executor个数。这种方式需要自行估计每个Spark应用所需的资源,并为每个应用单独配置Executor个数。
(2)动态分配
动态分配可根据一个Spark应用的工作负载,动态的调整其所占用的资源(Executor个数)。这意味着一个Spark应用程序可以在运行的过程中,需要时,申请更多的资源(启动更多的Executor),不用时,便将其释放。
在生产集群中,推荐使用动态分配。动态分配相关参数如下:
#启动动态分配
spark.dynamicAllocation.enabled true
#启用Spark shuffle服务
spark.shuffle.service.enabled true
#Executor个数初始值
spark.dynamicAllocation.initialExecutors 1
#Executor个数最小值
spark.dynamicAllocation.minExecutors 1
#Executor个数最大值
spark.dynamicAllocation.maxExecutors 12
#Executor空闲时长,若某Executor空闲时间超过此值,则会被关闭
spark.dynamicAllocation.executorIdleTimeout 60s
#积压任务等待时长,若有Task等待时间超过此值,则申请启动新的Executor
spark.dynamicAllocation.schedulerBacklogTimeout 1s
#解决3.0版本兼容问题
spark.shuffle.useOldFetchProtocol true
说明:Spark shuffle服务的作用是管理Executor中的各Task的输出文件,主要是shuffle过程map端的输出文件。由于启用资源动态分配后,Spark会在一个应用未结束前,将已经完成任务,处于空闲状态的Executor关闭。Executor关闭后,其输出的文件,也就无法供其他Executor使用了。需要启用Spark shuffle服务,来管理各Executor输出的文件,这样就能关闭空闲的Executor,而不影响后续的计算任务了。
Driver配置说明
Driver主要配置内存即可,相关的参数有spark.driver.memory和spark.driver.memoryOverhead。
spark.driver.memory用于指定Driver进程的堆内存大小,spark.driver.memoryOverhead用于指定Driver进程的堆外内存大小。默认情况下,两者的关系如下:spark.driver.memoryOverhead=spark.driver.memory*0.1。两者的和才算一个Driver进程所需的总内存大小。
一般情况下,按照如下经验进行调整即可:假定yarn.nodemanager.resource.memory-mb设置为X,
若X>50G,则Driver可设置为12G,
若12G<X<50G,则Driver可设置为4G。
若1G<X<12G,则Driver可设置为1G。
此处yarn.nodemanager.resource.memory-mb为64G,则Driver的总内存可分配12G,所以上述两个参数可配置为
spark.driver.memory 10G
spark.yarn.driver.memoryOverhead 2G
SQL优化
Hive SQL执行计划
Hive SQL的执行计划,可由Explain查看。
Explain呈现的执行计划,由一系列Stage组成,这个Stage具有依赖关系,每个Stage对应一个MapReduce Job或者Spark Job,或者一个文件系统操作等。
每个Stage由一系列的Operator组成,一个Operator代表一个逻辑操作,例如TableScan Operator,Select Operator,Join Operator等。
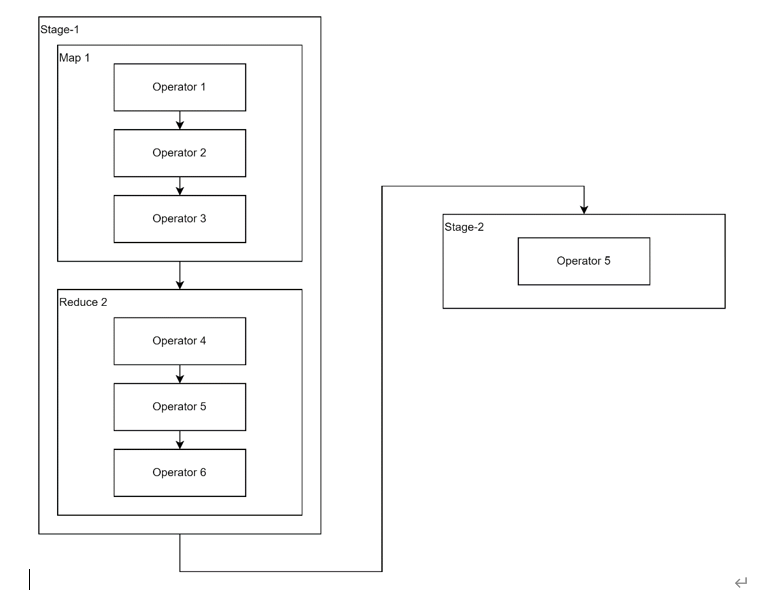
统计信息
--查看该表的结构化数据 desc formatted dim_province_full partiyion(dt='2022-06-16'); --表的状态信息统计 analyze table dim_province_full partition(dt='2022-06-16') compute statistics;
分组聚合优化
hive> select coupon_id, count(*) from dwd_trade_order_detail_inc where dt='2020-06-16' group by coupon_id;
优化思路
优化思路为map-side聚合。所谓map-side聚合,就是在map端维护一个hash table,利用其完成分区内的、部分的聚合,然后将部分聚合的结果,发送至reduce端,完成最终的聚合。map-side聚合能有效减少shuffle的数据量,提高分组聚合运算的效率。
--启用map-side聚合(默认true) set hive.map.aggr=true; --hash map占用map端内存的最大比例 set hive.map.aggr.hash.percentmemory=0.5;
Join优化
Hive Join算法概述
Hive拥有多种join算法,包括common join,map join,bucket map join等。下面对每种join算法做简要说明:
1)common join
Map端负责读取参与join的表的数据,并按照关联字段进行分区,将其发送到Reduce端,Reduce端完成最终的关联操作。
2)map join
若参与join的表中,有n-1张表足够小,Map端就会缓存小表全部数据,然后扫描另外一张大表,在Map端完成关联操作。
3)bucket map join
若参与join的表均为分桶表,且关联字段为分桶字段,且大表的分桶数量是小表分桶数量的整数倍。此时,就可以以分桶为单位,为每个Map分配任务了,Map端就无需再缓存小表的全表数据了,而只需缓存其所需的分桶。
Map Join优化
hive> select * from ( select * from dwd_trade_order_detail_inc where dt='2020-06-16' )fact left join ( select * from dim_sku_full where dt='2020-06-16' )dim on fact.sku_id=dim.id;
优化思路
上述参与join的两表一大一小,可考虑map join优化。
Map Join相关参数如下:
--启用map join自动转换(默认true) set hive.auto.convert.join=true; --common join转map join小表阈值 set hive.auto.convert.join.noconditionaltask.size
数据倾斜优化
数据倾斜说明
数据倾斜问题,通常是指参与计算的数据分布不均,即某个key或者某些key的数据量远超其他key,导致在shuffle阶段,大量相同key的数据被发往一个Reduce,进而导致该Reduce所需的时间远超其他Reduce,成为整个任务的瓶颈。
Hive中的数据倾斜常出现在分组聚合和join操作的场景中,下面分别介绍在上述两种场景下的优化思路。
分组聚合导致的数据倾斜
hive> select province_id, count(*) from dwd_trade_order_detail_inc where dt='2020-06-16' group by province_id;
优化思路
由分组聚合导致的数据倾斜问题主要有以下两种优化思路:
1)启用map-side聚合
2)启用skew groupby优化
其原理是启动两个MR任务,第一个MR按照随机数分区,将数据分散发送到Reduce,完成部分聚合,第二个MR按照分组字段分区,完成最终聚合。
--启用分组聚合数据倾斜优化(默认false) set hive.groupby.skewindata=true;
join导致的数据倾斜
hive> select * from ( select * from dwd_trade_order_detail_inc where dt='2020-06-16' )fact join ( select * from dim_province_full where dt='2020-06-16' )dim on fact.province_id=dim.id;
优化思路
由join导致的数据倾斜问题主要有以下两种优化思路:
1)使用map join
2)启用skew join优化
在common Join 过程中 Hive 会将计数超过阈值 hive.skewjoin.key 的 倾斜 key 对应的行临时写进文件中,然后再启动另一个 job 做 map join 生成结果。
--启用skew join优化(默认false) set hive.optimize.skewjoin=true; --触发skew join的阈值,若某个key的行数超过该参数值,则触发 set hive.skewjoin.key=100000;
任务并行度优化
优化说明
对于一个分布式的计算任务而言,设置一个合适的并行度十分重要。在Hive中,无论其计算引擎是什么,所有的计算任务都可分为Map阶段和Reduce阶段。所以并行度的调整,也可从上述两个方面进行调整。
Map阶段并行度
Map端的并行度,也就是Map的个数。是由输入文件的切片数决定的。一般情况下,Map端的并行度无需手动调整。Map端的并行度相关参数如下:
--可将多个小文件切片,合并为一个切片,进而由一个map任务处理 set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; --一个切片的最大值 set mapreduce.input.fileinputformat.split.maxsize=256000000;
Reduce阶段并行度
Reduce端的并行度,相对来说,更需要关注。默认情况下,Hive会根据Reduce端输入数据的大小,估算一个Reduce并行度。但是在某些情况下,其估计值不一定是最合适的,故需要人为调整其并行度。
Reduce并行度相关参数如下:
--指定Reduce端并行度,默认值为-1,表示用户未指定 set mapreduce.job.reduces; --Reduce端并行度最大值(1009) set hive.exec.reducers.max; --单个Reduce Task计算的数据量,用于估算Reduce并行度(256000000) set hive.exec.reducers.bytes.per.reducer;
Reduce端并行度的确定逻辑为,若指定参数mapreduce.job.reduces的值为一个非负整数,则Reduce并行度为指定值。否则,Hive会自行估算Reduce并行度,估算逻辑如下:
假设Reduce端输入的数据量大小为totalInputBytes
参数hive.exec.reducers.bytes.per.reducer的值为bytesPerReducer
参数hive.exec.reducers.max的值为maxReducers
则Reduce端的并行度(简化版)为:
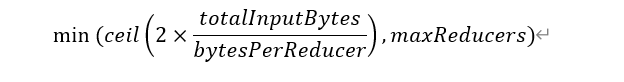
其中,Reduce端输入的数据量大小,是从Reduce上游的Operator的Statistics(统计信息)中获取的。为保证Hive能获得准确的统计信息,需配置如下参数:
--执行DML语句时,收集表级别的统计信息 set hive.stats.autogather=true; --执行DML语句时,收集字段级别的统计信息 set hive.stats.column.autogather=true; --计算Reduce并行度时,从上游Operator统计信息获得输入数据量 set hive.spark.use.op.stats=true; --计算Reduce并行度时,使用列级别的统计信息估算输入数据量 set hive.stats.fetch.column.stats=true;
小文件合并优化
优化说明
小文件合并优化,分为两个方面,分别是Map端输入的小文件合并,和Reduce端输出的小文件合并。
Map端输入文件合并
合并Map端输入的小文件,是指将多个小文件划分到一个切片中,进而由一个Map Task去处理。目的是防止为单个小文件启动一个Map Task,浪费计算资源。
--可将多个小文件切片,合并为一个切片,进而由一个map任务处理 set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
Reduce输出文件合并
合并Reduce端输出的小文件,是指将多个小文件合并成大文件。目的是减少HDFS小文件数量。
--开启合并Hive on Spark任务输出的小文件 set hive.merge.sparkfiles=true;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号