Flume知识点总结
什么是Flume
Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume 基于流式架构,灵活简单。
Flume 基础架构
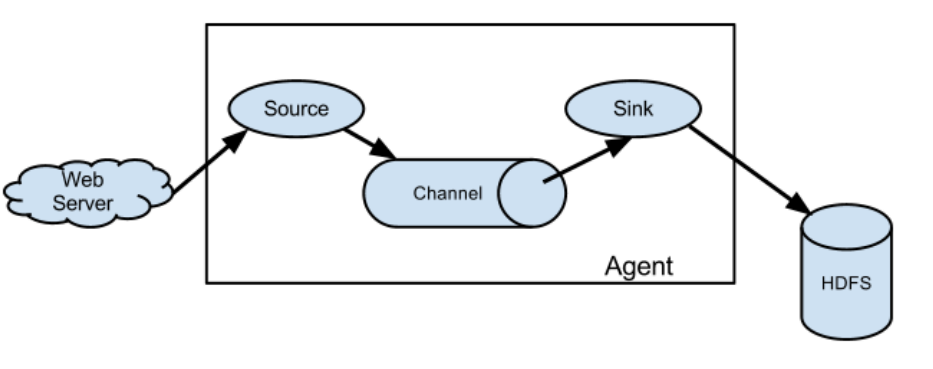
Agent
Agent 是一个 JVM 进程,它以事件的形式将数据从源头送至目的。 Agent 主要有 3 个部分组成,Source、Channel、Sink。
Source
Source 是负责接收数据到 Flume Agent 的组件。Source 组件可以处理各种类型、各种 格式的日志数据,包括 avro、thrift、exec、jms、spooling directory、netcat、taildir、 sequence generator、syslog、http、legacy。
Sink
Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储 或索引系统、或者被发送到另一个 Flume Agent。 Sink 组件目的地包括 hdfs、logger、avro、thrift、ipc、file、HBase、solr、自定 义。
Channel
Channel 是位于 Source 和 Sink 之间的缓冲区。因此,Channel 允许 Source 和 Sink 运 作在不同的速率上。Channel 是线程安全的,可以同时处理几个 Source 的写入操作和几个 Sink 的读取操作。 Flume 自带两种 Channel:Memory Channel 和 File Channel。 Memory Channel 是内存中的队列。Memory Channel 在不需要关心数据丢失的情景下适 用。如果需要关心数据丢失,那么 Memory Channel 就不应该使用,因为程序死亡、机器宕 机或者重启都会导致数据丢失。 File Channel 将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
Event
传输单元,Flume 数据传输的基本单元,以 Event 的形式将数据从源头送至目的地。 Event 由 Header 和 Body 两部分组成,Header 用来存放该 event 的一些属性,为 K-V 结构, Body 用来存放该条数据,形式为字节数组。
Flume 事务
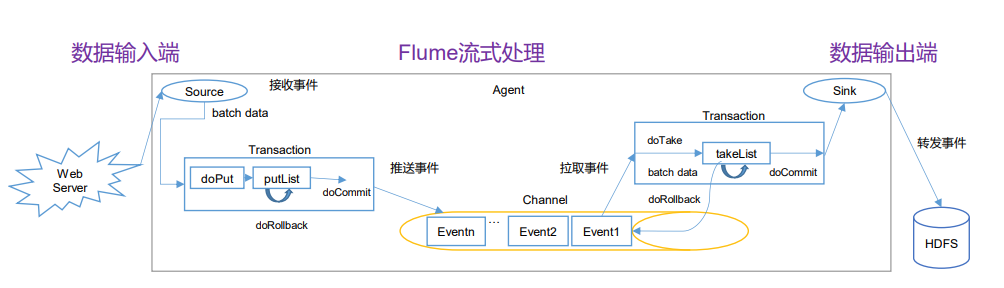
Put事务
•doPut:将批数据先写入临时缓冲区putList
•doCommit:检查channel内存队列是否足够合并。
•doRollback:channel内存队列空间不足,回滚数据(直接清除putList中的数据)
Put事务流程:事务开始的时候会调用一个doPut方法,doPut方法将一批数据(多个event)batch data 放在putList中,而这批数据“批”的大小取决于配置的 batch size 的参数的值。而putList的大小取决于配置channel的参数transaction capacity的大小,这个参数的大小就体现在putList上了。(tips:channel的另一个参数 capacity 指的是channel的容量)。
现在这批数据顺利的放到putList之后,接下来可以调用 doCommit方法,把putList中所有的event放到channel中,成功放完之后就清空putList。
以上是顺利的情况下,那如果事务进行的过程中出问题了怎么解决呢?
第一种问题:数据传输到channel过程出问题
在doCommit提交之后,事务在向channel放的过程中,事务容易出问题。比如:sink那边取数据慢,而source这边放数据速度快,就容易造成channel中的数据的积压,这个时候就会造成putList中的数据放不进去。那现在事务出问题了,如何解决呢?
通过调用doRollback方法,doRollback方法会进行两项操作:1、将putList清空;
2、抛出channelException异常。这个时候source就会捕捉到doRollback抛出的异常,然后source就会把刚才的一批数据重新采集一下(不一定采集得到),采集完之后重新走事务的流程。这就是事务的回滚。
(putList的数据在向channel发送之前先检查一下channel的容量能否放得下,如果放不下,就一个都不放。)
第二种问题:数据采集过程出问题
有这么种场景,source采集数据时候采用的是tailDir source,而我们因为某种原因将监控的目录文件删除,这个时候就会出现问题,同样地,出现问题的解决方式是调用doRollback方法来对事务进行回滚。
Take事务
•doTake:将数据取到临时缓冲区takeList,并将数据发送到HDFS
•doCommit:如果数据全部发送成功,则清除临时缓冲区takeList
•doRollback:数据发送过程中如果出现异常,rollback将临时缓冲区takeList中的数据归还给channel内存队列。
Take事务同样也有takeList,HDFS sink配置也有一个 batch size,这个参数决定sink从channel取数据的时候一次取多少个,所以这batch size 得小于takeList的大小,而takeList的大小取决于transaction capacity的大小,同样是channel 中的参数。
Take事务流程:事务开始后,doTake方法会将channel中的event剪切到takeList中,当然,后面接的是HDFS Sink的话,在把channel中的event剪切到takeList中的同时也往写入HDFS的IO缓冲流中放一份event(数据写入HDFS是先写入IO缓冲流然后flush到HDFS)。
当takeList中存放了batch size 数量的event之后,就会调用doCommit方法,doCommit方法会做两个操作:1、针对HDFS Sink,手动调用IO流的flush方法,将IO流缓冲区的数据写入到HDFS磁盘中;2、然后直接清空takeList中的数据。
以上是顺利的情况下,那如果事务进行的过程中出问题了怎么解决呢?
什么时候最容易出问题呢?——flush到HDFS的时候组容易出问题
如:flush到HDFS的时候,可能由于网络原因超时导致数据传输失败,这个时候同样地调用doRollback方法来进行回滚,回滚的时候,由于takeList中还有备份数据,所以将takeList中的数据原封不动地还给channel,这时候就完成了事务的回滚。
但是,如果flush到HDFS的时候,数据flush了一半之后出问题了,这意味着已经有一半的数据已经发送到HDFS上面了,现在出了问题,同样需要调用doRollback方法来进行回滚,回滚并没有“一半”之说,它只会把整个takeList中的数据返回给channel,然后继续进行数据的读写。这样开启下一个事务的时候就容易造成数据重复的问题。
所以,在某种程度上,flume对数据进行采集传输的时候,它有可能会造成数据的重复,但是其数据不丢失。
Flume Agent 内部原理
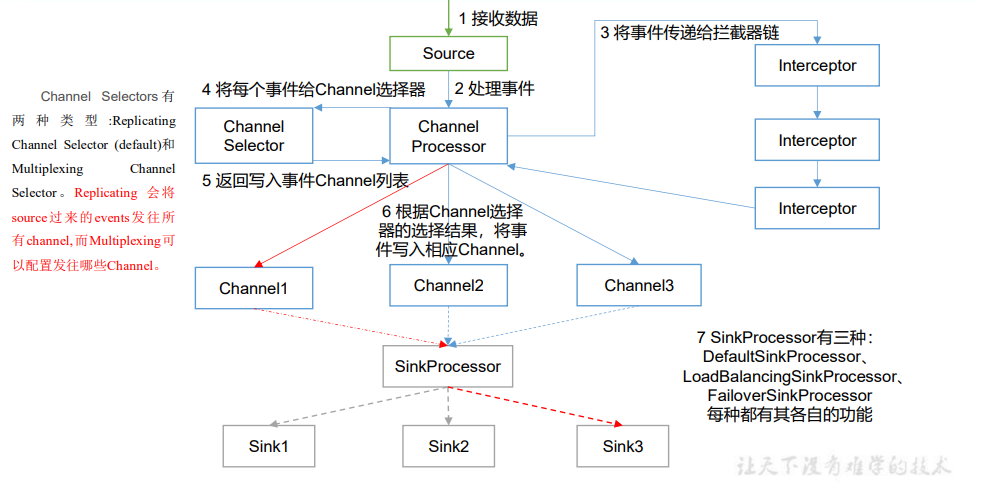
1)ChannelSelector
ChannelSelector 的作用就是选出 Event 将要被发往哪个 Channel。其共有两种类型, 分别是 Replicating(复制)和 Multiplexing(多路复用)。
ReplicatingSelector 会将同一个 Event 发往所有的 Channel,Multiplexing 会根据相 应的原则,将不同的 Event 发往不同的 Channel。
2)SinkProcessor
SinkProcessor 共 有 三 种 类 型 , 分 别 是 DefaultSinkProcessor 、 LoadBalancingSinkProcessor 和 FailoverSinkProcessor
DefaultSinkProcessor 对应的是单个的Sink,LoadBalancingSinkProcessor 和 FailoverSinkProcessor 对应的是 Sink Group,LoadBalancingSinkProcessor 可以实现负载均衡的功能,FailoverSinkProcessor 可以错误恢复的功能。
Flume传输是否会丢失或重复数据
这个问题需要分情况来看,需要结合具体使用的source、channel和sink来分析。
source:exec source 后面接tail -f,数据有可能丢;TailDir source 可以保证数据不丢失。
sink:数据有可能重复,但是不会丢失。
channel: 要想数据不丢失的话,还是要用 File channel,而memory channel 在flume挂掉的时候还是有可能造成数据的丢失的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号