
Zookeeper知识点总结
什么是Zookeeper
Zookeeper从设计模式角度来理解,是一个基于观察者模式设计的分布式服务管理框架,它负责存储和 管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生了变化,Zookeeper就负责 通知已经在Zookeeper上注册的那些观察者做出相应的反应。
Zookeeper选举机制
第一次启动
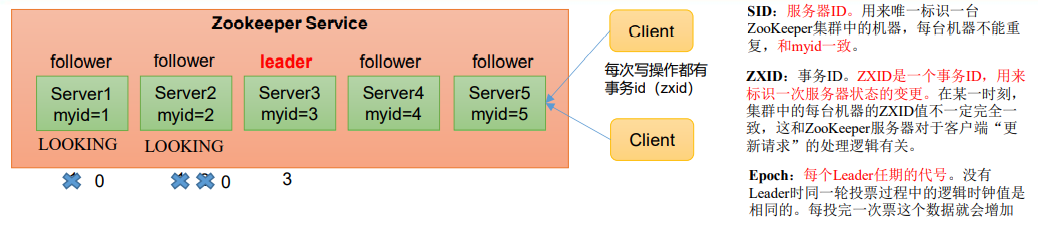
(1)服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为 LOOKING;
(2)服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的myid比自己目前投票推举的(服务器1) 大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING
(3)服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服 务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING; LOOKING LOOKING 1 0 1 2 0 3
(4)服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为 1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING;
(5)服务器5启动,同4一样当小弟。
第二次启动
(1)当ZooKeeper集群中的一台服务器出现以下两种情况之一时,就会开始进入Leader选举:
• 服务器初始化启动。
• 服务器运行期间无法和Leader保持连接。
(2)而当一台机器进入Leader选举流程时,当前集群也可能会处于以下两种状态:
• 集群中本来就已经存在一个Leader。 对于第一种已经存在Leader的情况,机器试图去选举Leader时,会被告知当前服务器的Leader信息,对于该机器来说,仅仅需要和Leader机器建立连 接,并进行状态同步即可。
• 集群中确实不存在Leader。 选举Leader规则: ①EPOCH大的直接胜出 ②EPOCH相同,事务id大的胜出 ③事务id相同,服务器id大的胜出

 浙公网安备 33010602011771号
浙公网安备 33010602011771号