Hadoop中的块、片、区
块(Block)
文件上传HDFS的时候,HDFS客户端将文件切分成一个一个的块,然后进行上传。
块的默认大小在Hadoop2.x/3.x版本中是128M,1.x版本中是64M。
思考:为什么块的大小不能设置太小,也不能设置太大?
(1)HDFS的块设置太小,会增加寻址时间,程序一直在找块的开始位置;
(2)如果块设置的太大,从磁盘传输数据的时间会明显大于定位这个块开 始位置所需的时间。导致程序在处理这块数据时,会非常慢。
总结:HDFS块的大小设置主要取决于磁盘传输速率。
片(Split)
在提交Job时,Yarn客户端将文件切片,生成切片规划文件。(MapReduce前的准备阶段)
Block 是 HDFS 物理上把数据分成一块一块。数据块是 HDFS 存储数据单位。
Split只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。数据切片是 MapReduce 程序计算输入数据的单位,一个切片会对应启动一个 MapTask。
切片机制:
(1)简单地按照文件的内容长度进行切片
(2)切片大小,默认等于Block大小
(3)切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
思考:为什么切片大小默认设置与块大小一致?
使MapTask需要的切片在同一节点,减少I/O传输过程。
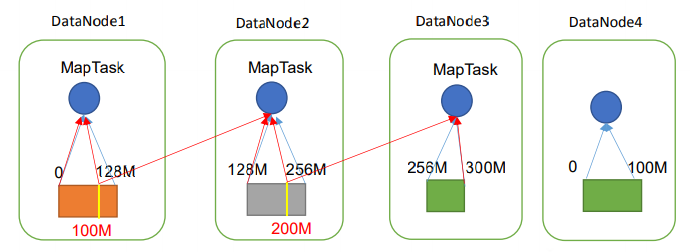
(图中蓝线按照块大小切片,不需要额外的I/O传输,红线自定义切片大小,需要额外的I/O传输)
区(Partition)
在MapReduce的Shuffle阶段,MapTask 收集我们的 map()方法输出的 kv 对,放到内存缓冲区中,此时会对每个kv进行分区。
默认分区是根据key的hashCode对ReduceTasks个数取模得到的。
一般情况下,一个分区对应一个ReduceTask。(ReduceTask的数量与分区数都可以自定义,二者也可以不相等)
思考:当ReduceTask的数量与分区数不相等时,会发生什么?
(1)如果ReduceTask的数量> getPartition的结果数,则会多产生几个空的输出文件part-r-000xx;
(2)如果1<ReduceTask的数量<getPartition的结果数,则有一部分分区数据无处安放,会Exception;
(3)如果ReduceTask的数量=1,则不管MapTask端输出多少个分区文件,最终结果都交给这一个ReduceTask,最终也就只会产生一个结果文件 part-r-00000;
思考:如果分区数不是1,但是ReduceTask为1,是否执行分区过程?
不执行分区过程。因为在MapTask的源码中,执行分区的前提是先判断ReduceNum个数是否大于1。不大于1肯定不执行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号