【数据分析 R语言实战】学习笔记 第八章 方差分析与R实现
方差分析泛应用于商业、经济、医学、农业等诸多领域的数量分析研究中。例如商业广告宣传方面,广告效果可能会受广告式、地区规模、播放时段、播放频率等多个因素的影响,通过方差分析研究众多因素中,哪些是主要的以及如何产生影响等。而在经济管理中,方差分析常用于分析变量之间的关系,如人民币汇率对股票收益率的影响、存贷款利率对债券市场的影响,等等。
协方差是在方差分析的基础上,综合回归分析的方法,研究如何调节协变量对因变量的影响效应,从而更加有效地分析实验处理效应的一种统计技术。
8.1单因素方差分析及R实现
(1)正态性检验
对数据的正态性,利用Shapiro-Wilk正态检验方法(W检验),它通常用于样本容量n≤50时,检验样本是否符合正态分布。
R中,函数shapiro.test()提供了W统计量和相应P值,所以可以直接使用P值作为判断标准,其调用格式为shapiro.test(x),参数x即所要检验的数据集,它是长度在35000之间的向量。
例:
某银行规定VIP客户的月均账户余额要达到100万元,并以此作为比较各分行业绩的一项指标。这里分行即因子,账户余额是所要检验的指标,先从三个分行中,分别随机抽取7个VIP客户的账户。为了用单因素方差分析判断三个分行此项业绩指标是否相同,首先对二个分行的账户余额分别进行正态检验。

> x1=c(103,101,98,110,105,100,106) > x2=c(113,107,108,116,114,110,115) > x3=c(82,92,84,86,84,90,88) > shapiro.test(x1) Shapiro-Wilk normality test data: x1 W = 0.97777, p-value =0.948 > shapiro.test(x2) Shapiro-Wilk normality test data: x2 W = 0.91887, p-value =0.4607 > shapiro.test(x3) Shapiro-Wilk normality test data: x3 W = 0.95473, p-value =0.7724
P值均大于显著性水平a=0.05,因此不能拒绝原假设,说明数据在因子A的三个水平下都
是来自正态分布的。
(2)方差齐性检验
方差分析的另一个假设:方差齐性,需要检验不同水平卜的数据方差是否相等。R中最常用的Bartlett检验,bartlett.test()调用格式为
bartlett.test(x,g…)
其中,参数X是数据向量或列表(list) ; g是因子向量,如果X是列表则忽略g.当使用数据集时,也通过formula调用函数:
bartlett.test(formala, data, subset,na.action…)
formula是形如lhs一rhs的方差分析公式;data指明数据集:subset是可选项,可以用来指定观测值的一个子集用于分析:na.action表示遇到缺失值时应当采取的行为。
续上例:
> x=c(x1,x2,x3) > account=data.frame(x,A=factor(rep(1:3,each=7))) > bartlett.test(x~A,data=account) Bartlett test of homogeneity of variances data: x by A Bartlett's K-squared = 0.13625, df = 2, p-value = 0.9341
由于P值远远大于显著性水平a=0.05,因此不能拒绝原假设,我们认为不同水平下的数据是等方差的。
8.1.2单因素方差分析
R中的函数aov()用于方差分析的计算,其调用格式为:
aov(formula, data = NULL, projections =FALSE, qr = TRUE,contrasts = NULL, ...)
其中的参数formula表示方差分析的公式,在单因素方差分析中即为x~A ; data表示做方差分析的数据框:projections为逻辑值,表示是否返回预测结果:qr同样是逻辑值,表示是否返回QR分解结果,默认为TRUE; contrasts是公式中的一些因子的对比列表。通过函数summary()可列出方差分析表的详细结果。
上面的例子已经对数据的正态性和方差齐性做了检验,接F来就可以进行方差分析:
> a.aov=aov(x~A,data=account) > summary(a.aov) Df Sum Sq Mean Sq F value Pr(>F) A 2 2315 1158 82.68 8.46e-10 *** Residuals 18 252 14 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 > plot(account$x~account$A)
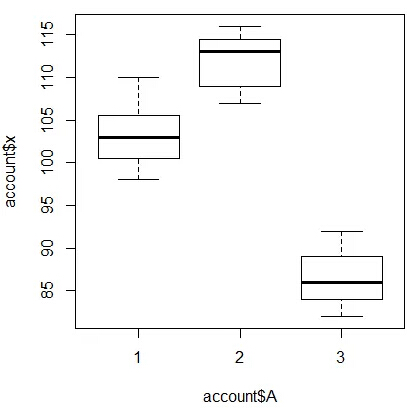
Levene检验
Levene检验,它既可以用于正态分布的数据,也可用于非正态分布的数据或分布不明的数据,具有比较稳健的特点,检验效果也比较理想。
R的程序包car中提供了Levene检验的函数levene.test()
> library(car) > levene.test(account$x,account$A) Levene's Test for Homogeneity of Variance (center = median) Df F value Pr(>F) group 2 0.0426 0.9584 18
由于p值大于a=0.05,不能拒绝原假设,我们认为不同水平下的数据是等方差的。
8.1.3多重t检验
单因素方差分析是从总体的角度上说明各效应的均值之间存在显著差异,但具体哪些水平下的均值存在较人差异无从得知,所以我们要对每一对样本均值进行一一比较,即要进行均值的多重比较。
> p.adjust.methods [1] "holm" "hochberg" "hommel" "bonferroni" "BH" [6] "BY" "fdr" "none" > attach(account) > pairwise.t.test(x,A,p.adjust.method="bonferroni") Pairwise comparisons using t tests with pooled SD data: x and A 1 2 2 0.0013 - 3 3.9e-07 6.5e-10 P value adjustment method: bonferroni
经过修正后的p值比原来会增大很多,这在一定程度上克服了多重t检验增加犯第一类错误的
概率的缺点。从检验结果来看,样本两两之问t检验的p值都很小,说明几个样本之间差异明显。
8.1.4Kruskal-Wallis秩和检验
R内置函数kruskal.test()可以完成Kruskal-Wallis秩和检验,使用如下:
kruskal.test(x, ...)
kruskal.test(x, g, ...)
kruskal.test(formula, data, subset,na.action, ...)
例:
某制造商雇用了来自三所本地大学的雇员作为管理人员。最近,公司的人事部门已经收集信息并考核了年度工作成绩。从三所大学来的雇员中随机地抽取了三个独立样本,样本量分别为7、6, 7,数据如表所示。制造商想知道来自这三所不同的大学的雇员在管理岗位上的表现是否有所不同,我们通过Kruskal-Wallis秩和检验来得到结论。

>data=data.frame(x=c(25,70,60,85,95,90,80,60,20,30,15,40,35,50,70,60,80,90,70,75),g=factor(rep(1:3,c(7,6,7)))) > kruskal.test(x~g, data=data) Kruskal-Wallis rank sum test data: x by g Kruskal-Wallis chi-squared = 8.9839, df = 2, p-value = 0.0112
检验的结果为P=0.0112<0.05,因此拒绝原假设,说明来自这三个不同的大学的雇员在管理岗位上的表现有比较显著的差异。
8.2双因素方差分析及R实现
8.2.1无交互作用的分析
例:
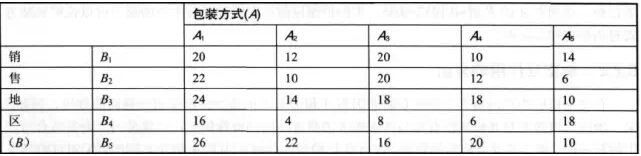
某商品在不同地区、不同包装的销售数据
首先为了建立数据集,引入生成因子水平的函数g1(),其调用格式为:
gl(n, k, length=n*k,labels=1:n,ordered=FALSE)
n是因子的水平个数;k表示每一水平上的重复次数;length=n*k表示总观测数;可通过参数labels对因子的不同水平添加标签;ordered为逻辑值,指示是否排序。
> x=c(20,12,20,10,14,22,10,20,12,6,24,14,18,18,10,16,4,8,6,18,26,22,16,20,10) > sales=data.frame(x,A=gl(5,5),B=gl(5,1,25)) > sales$B [1] 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 12 3 4 5 Levels: 1 2 3 4 5
分析前先对因素A和B作方差齐性检验,使用函数bartlett.test()
> bartlett.test(x~A,data=sales) Bartlett test of homogeneity of variances data: x by A Bartlett's K-squared =0.66533, df = 4, p-value = 0.9555 > bartlett.test(x~B,data=sales) Bartlett test of homogeneity of variances data: x by B Bartlett's K-squared =1.2046, df = 4, p-value = 0.8773
因素A和B的P值都远大于0.05的显著性水平,不能拒绝原假设,说明因素A, B的各水平是满足方差齐性的。这时再进行双因素方差分析,输入指令
> sales.aov=aov(x~A+B,data=sales) > summary(sales.aov) Df Sum Sq Mean Sq F valuePr(>F) A 4 199.4 49.84 2.303 0.1032 B 4 335.4 83.84 3.874 0.0219 * Residuals 16 346.2 21.64 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’1
检验的结论:因素B的P值=0.0219<0.05,拒绝原假设,说明销售地区对饮料的销售量有显著影响;而因素A的P值=0.1032>0.05,不能拒绝原假设,因此没有充分的理由可以说明包装方式对销售有明显影响。
8.2.2有交互作用的分析
R仍然用函数aov()作双因素方差分析,只需将formula改为x~A+B+A:B或x~A*B的形式即可。
例:
不同路段和不同时段的行车时间数据

首先构造数据集,对因素A和B作方差齐性检验,利用函数bartlett.test()
> time=c(25,24,27,25,25,19,20,23,22,21,29,28,31,28,30,20,17,22,21,17,18,17,13,16,12,22,18,24,21,22)
> traffic=data.frame(time,A=gl(2,15,30),B=gl(3,5,30,labels=c("I","II","III")))
> bartlett.test(time~A,data=traffic)
Bartlett test of homogeneity of variances
data: time by A
Bartlett's K-squared =0.053302, df = 1, p-value = 0.8174
> bartlett.test(time~B,data=traffic)
Bartlett test of homogeneity of variances
data: time by B
Bartlett's K-squared =0.57757, df = 2, p-value = 0.7492
检验结果的P值均远大于显著性水平0.05,说明两个因素下的各水平都满足方差齐性的要求,可以进一步做方差分析。画图来观察一下数据的特点,首先是箱线图。
> op=par(mfrow=c(1,2)) #分割图形区域 > plot(time~A+B,data=traffic) Hit <Return> tosee next plot:
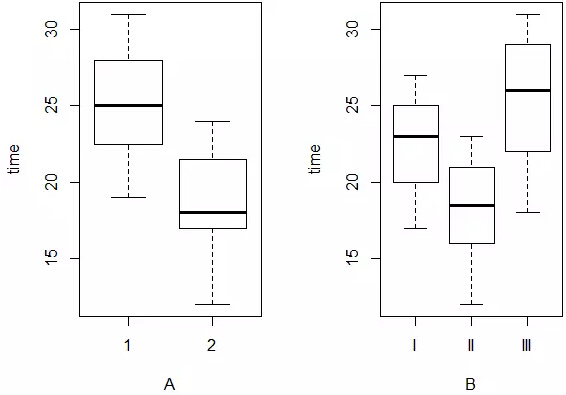
从图形上单独观察时段和路段对行车时间的影响,可以发现因素的不同水平还是有明显差别的。为了考察因素间的交互作用是否存在,利用函数interaction.plot()绘制交互效应图:
interaction.plot(x.factor, trace.factor,response, fun = mean,type = c("l","p", "b", "o", "c"), legend = TRUE,trace.label =deparse(substitute(trace.factor)),fixed = FALSE,xlab =deparse(substitute(x.factor)),ylab = ylabel,ylim = range(cells, na.rm =TRUE),lty = nc:1, col = 1, pch =c(1:9, 0, letters),xpd = NULL, leg.bg =par("bg"), leg.bty = "n",
xtick = FALSE, xaxt = par("xaxt"),axes = TRUE,...)
x.factor表示横轴的因子
trace.factor表示分类绘图的因子
response是数值向量,要输入响应变量
fun表示汇总数据的方式,默认为计算每个因子水平下的均值
type指定图形类型
legend是逻辑值,指示是否生成图例
trace.label给出图例中的标签。
> attach(traffic) > interaction.plot(A,B,time,legend=F) > interaction.plot(B,A,time,legend=F)
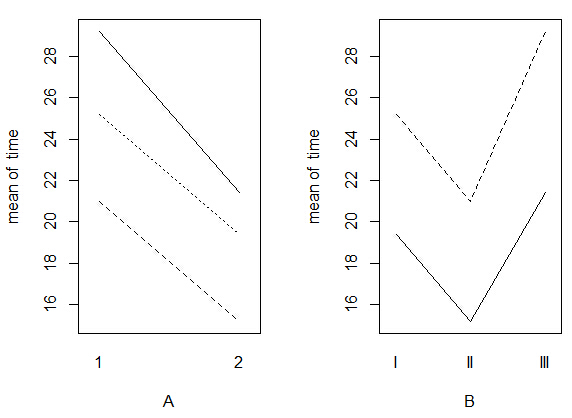
曲线均没有相交,所以可以初步判断两个因素之间应该没有交互作用。用方差分析进行确认:
> traf.aov=aov(time~A*B,data=traffic) > summary(traf.aov) Df Sum Sq Mean Sq F value Pr(>F) A 1 313.63 313.63 84.766 2.41e-09 *** B 2 261.60 130.80 35.351 7.02e-08 *** A:B 2 6.67 3.33 0.901 0.42 Residuals 24 88.80 3.70 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
根据检验结果的P值作判断:引素A时段和B路段对行车时间有显著影响;而交互作用A:B的P值=0.42>0.05 ,因此不能拒绝原假设H0,说明两个因素间没有明显的交互效应。
8.3协方差分析及R实现
为了提高试验的精确性和准确性,我们对除研究因素以外的一切条件都需要采取有效措施严加控制,使它们在因素的不同水平间尽量保持一致,这叫做试验控制。但当我们进行试验设计时,即使做出很大努力控制,也经常会碰到试验个体的初始条件不同的情况,如果不考虑这些因素有可能导致结果失真。如果考虑这些不可控的因素,这种方差分析就叫做协方差分析,其是将回归分析和方差分析结合在一起的方法。它的基本原理如下:将一些对响应变量Y有影响的变量X(未知或难以控制的因素)看作协变量,建立响应变量Y随X变化的线性回归分析,从Y的总的平方和中扣除X对Y的回归平方和,对残差平方和作进一步分解后再进行方差分析。
例:
施用3种肥料的苹果产量
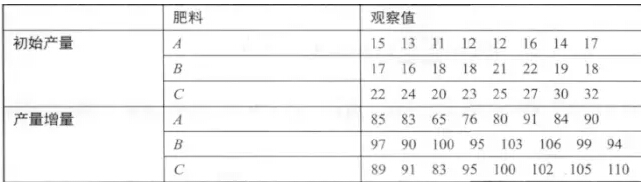
> Weight_Initial=c(15,13,11,12,12,16,14,17,17,16,18,18,21,22,19,18,22,24,20,23,25,27,30,32) > Weight_Increment=c(85,83,65,76,80,91,84,90,97,90,100,95,103,106,99,94,89,91,83,95,100,102,105,110) > feed=gl(3,8,24) > data_feed=data.frame(Weight_Initial,Weight_Increment,feed) > library(HH) > m=ancova(Weight_Increment~Weight_Initial+feed,data=data_feed) > summary(m) Df Sum Sq Mean Sq F value Pr(>F) Weight_Initial 1 1621.1 1621.1 142.44 1.50e-10 feed 2 707.2 353.6 31.07 7.32e-07 Residuals 20 227.6 11.4 Weight_Initial *** feed *** Residuals --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
协方差分析的P值非常小,说明结果非常显著,应该拒绝原假设,认为各因素在不同水平下的试验结果有显著差别,即三种肥料对苹果产量有很大的影响。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号