非洲 AI 不发达,看看这份PPT,受益匪浅
非洲 AI 不发达,看看这份PPT,受益匪浅
非洲有大量的工程+机器学习人才,他们渴望学习、努力工作和进步。
大家好,我是老章
看到我关注的一位博主在首届非洲 @LangChainAI 聚会上的一个演示PPT,主题是“使用 LangChain 构建生产就绪的 LLM 应用程序” 。
很好奇在非洲推广AI、LLM会讲些什么,但是没有找到视频,只有一份PPT。
这里就截取其中几张,稍微扩展看看都有哪些内容。

如果需要原版可以微信(mindszhang)找我要一下

这里介绍了多模态的重要性,因为大量信息包含在图像(视频也可以视作图像)和表格中。
PPT中有个来源链接:https://cloudedjudgement.substack.com/p/clouded-judgement-111023
这篇文章由Jamin Ball撰写,涵盖了关于OpenAI和Datadog近期发展的分析以及软件即服务(SaaS)公司的市场表现和估值,作者预测2024年将是AI应用的爆发之年
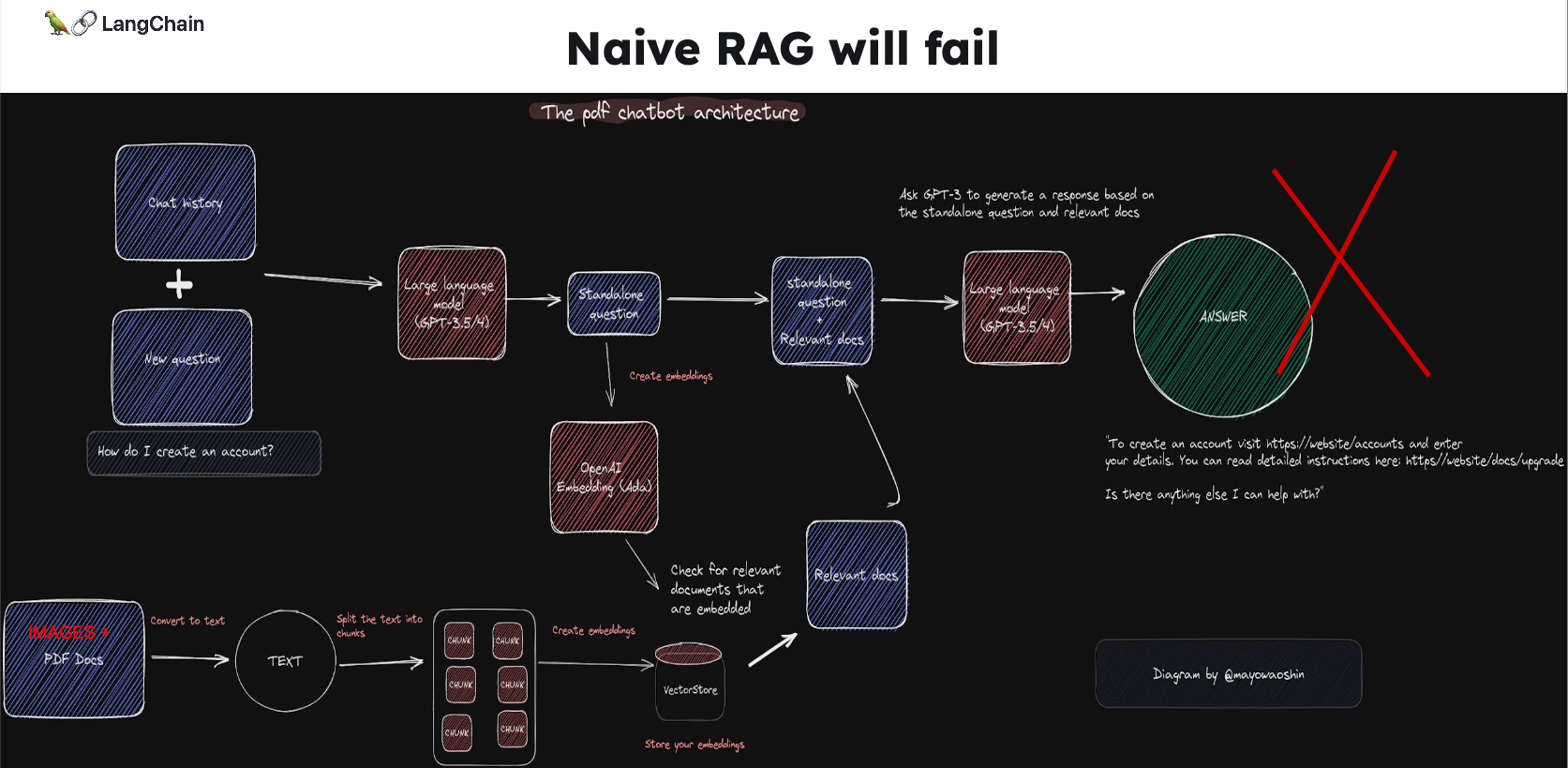
这张片子标题是“纯RAG会失败”,RAG(检索增强生成)这个前几天我在介绍吴恩达新课中有介绍。
配图是pdf chatbot 的架构图,这个项目是一个使用GPT-4和LangChain创建的聊天机器人,专门设计来处理和回应关于大型PDF文档的查询。用户可以通过这个聊天机器人提出问题,它会通过理解和检索PDF文档中的内容来回答这些问题。项目的技术栈包括LangChain、Pinecone、Typescript、OpenAI和Next.js。LangChain是一个框架,用于构建可扩展的AI/LLM应用程序和聊天机器人。Pinecone是一个向量存储系统,用于存储嵌入向量和文本形式的PDF文档,以便于后续检索相似文档。
项目地址:https://github.com/mayooear/gpt4-pdf-chatbot-langchain
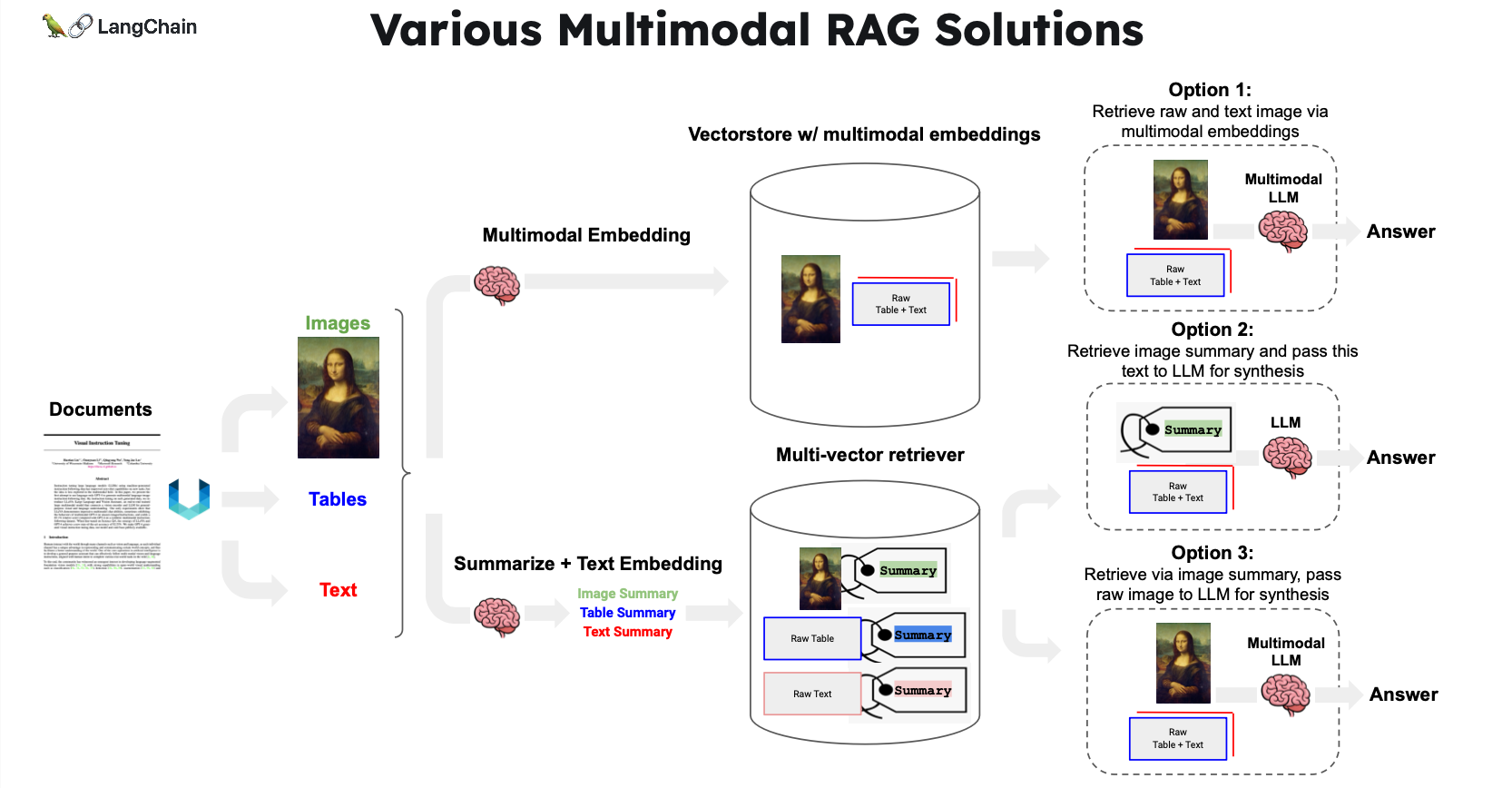
标题:各种多模态RAG解决方案
介绍了利用多向量检索器来达到这个效果的方法:
- Option 1:
使用多模态嵌入(如 CLIP)来嵌入图像和文本
利用相似性搜索检索图像和文本
将原始图像和文本块传递给多模态大语言模型以合成答案 - Option 2:
使用多模态大语言模型(如 GPT-4V、LLaVA 或 FUYU-8b)从图像中生成文本摘要
嵌入并检索文本
将文本块传递给大语言模型以合成答案 - Option 3:
使用多模态大语言模型(如 GPT-4V、LLaVA 或 FUYU-8b)从图像中生成文本摘要
将图像摘要嵌入并与原始图像的引用一起检索
将原始图像和文本块传递给多模态大语言模型以合成答案
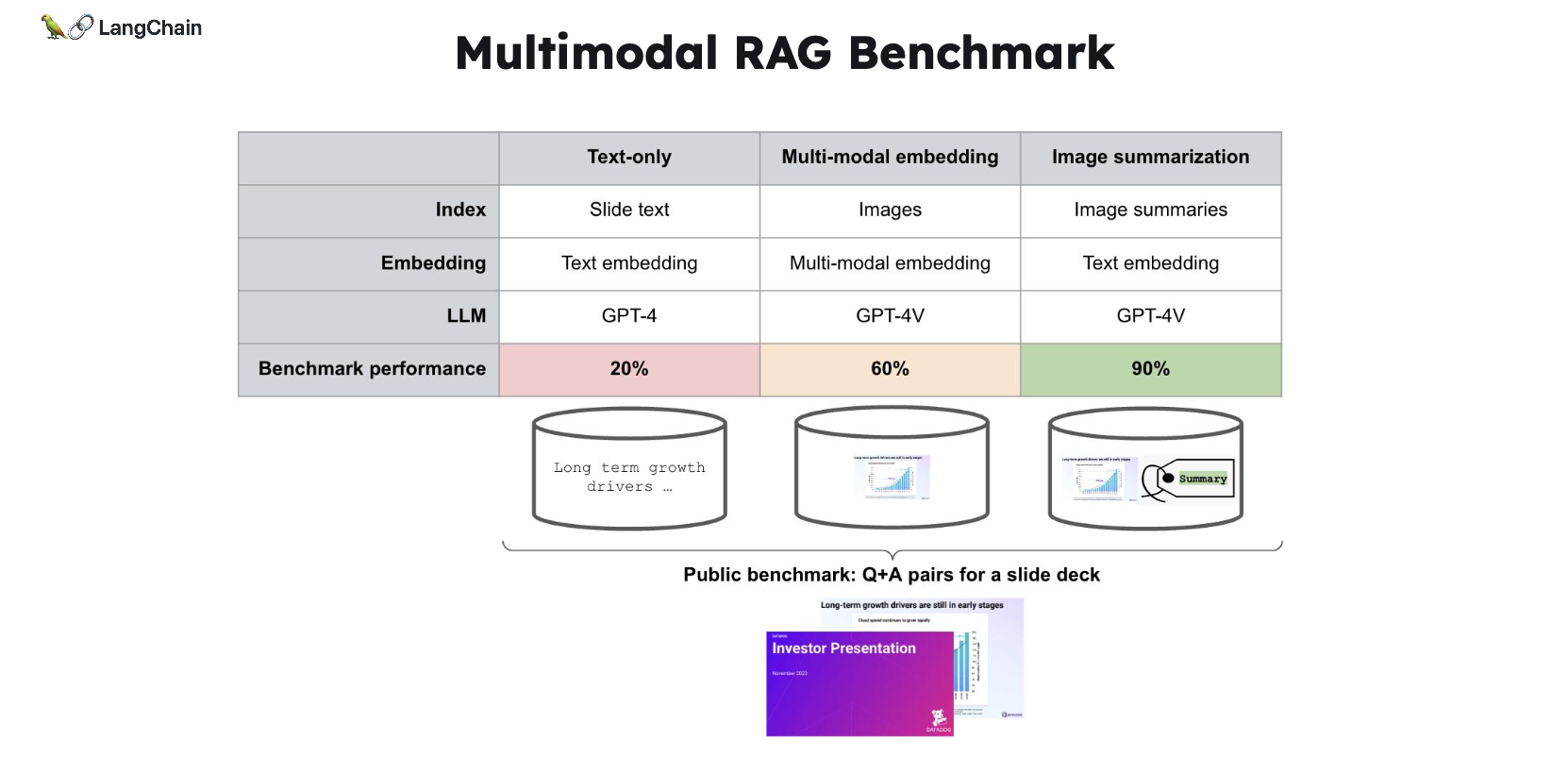
标题:多模态RAG基准测试,介绍三种方案基准测试的表现。
数据来源:https://smith.langchain.com/public/b738420f-3cd5-46c4-a0e1-894aff3cf37e/d
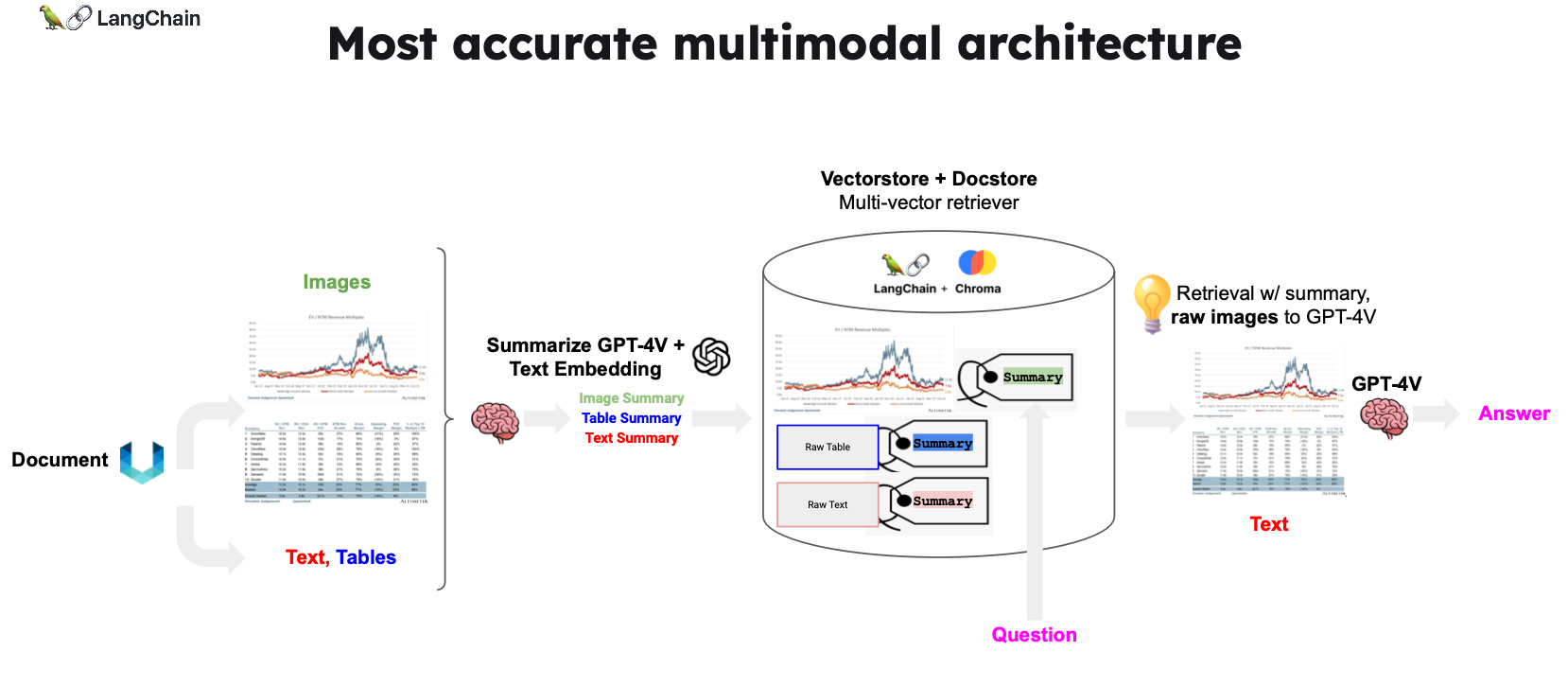
这页PPT重点介绍第三种方案并付了示例代码。
- 使用 Unstructured 来解析文档(PDFs)中的图像、文本和表格。
- 使用带有 Chroma 的多向量检索器来存储原始文本和图像以及它们的摘要以便检索。
- 使用 GPT-4V 进行图像摘要(用于检索)以及从图像和文本(或表格)的联合审查中合成最终答案。
示例代码:https://github.com/langchain-ai/langchain/blob/master/cookbook/Multi_modal_RAG.ipynb
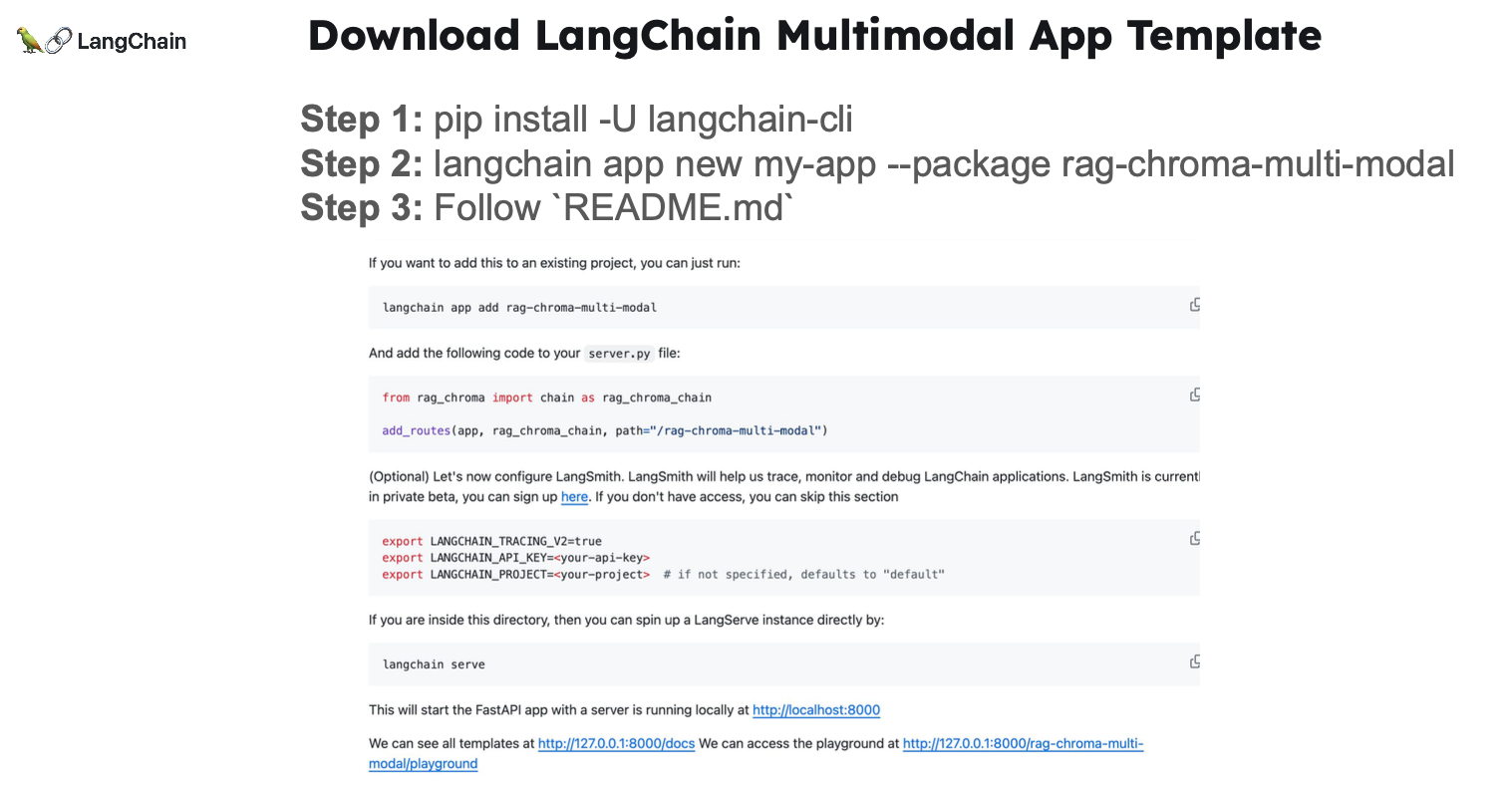
这里演示了利用 Chroma 实现了多模态 RAG,并且整合了多模态 OpenCLIP 的嵌入功能以及 OpenAI 的 GPT-4V 技术。
示例代码:https://github.com/langchain-ai/langchain/tree/master/templates/rag-chroma-multi-modal

后面几张PPT演示了示例代码的执行结果,使用自然语言检索相关图片。
怎么样?非洲AI真的不发达吗?


 浙公网安备 33010602011771号
浙公网安备 33010602011771号