100天搞定机器学习|day43 几张GIF理解K-均值聚类原理
前文推荐
KMeans算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。
K个初始聚类中心点的选取对聚类结果具有较大的影响,因为在该算法第一步中是随机地选取任意k个对象作为初始聚类中心,初始地代表一个簇。该算法在每次迭代中对数据集中剩余的每个对象,根据其与各个簇中心的距离赋给最近的簇。当考查完所有数据对象后,一次迭代运算完成,新的聚类中心被计算出来。
算法过程如下:
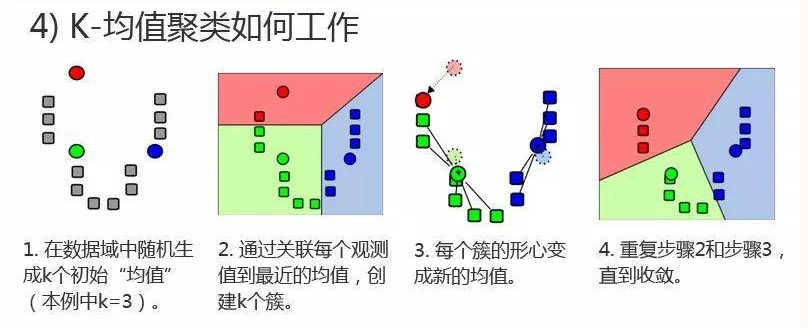
(1)从N个数据文档(样本)随机选取K个数据文档作为质心(聚类中心)。
本文在聚类中心初始化实现过程中采取在样本空间范围内随机生成K个聚类中心。
(2)对每个数据文档测量其到每个质心的距离,并把它归到最近的质心的类。
(3)重新计算已经得到的各个类的质心。
(4)迭代(2)~(3步直至新的质心与原质心相等或小于指定阈值,算法结束。
The data points.

Starting with 4 left-most points

Starting with 4 right-most points

Starting with 4 top points

Starting with 4 bottom points

Starting with 4 random points in one cluster

参考:
https://github.com/MLEveryday/100-Days-Of-ML-Code
https://www.cnblogs.com/eczhou/p/7860424.html
http://www.avikjain.me

 浙公网安备 33010602011771号
浙公网安备 33010602011771号