100天搞定机器学习|day39 Tensorflow Keras手写数字识别
提示:建议先看day36-38的内容
TensorFlow™ 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。它灵活的架构让你可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等。
TensorFlow 最初由Google大脑小组(隶属于Google机器智能研究机构)的研究员和工程师们开发出来,用于机器学习和深度神经网络方面的研究,但这个系统的通用性使其也可广泛用于其他计算领域。
1、安装库tensorflow
有些教程会推荐安装nightly,它适用于在一个全新的环境下进行TensorFlow的安装,默认会把需要依赖的库也一起装上。我使用的是anaconda,本文我们安装的是纯净版的tensorflow,非常简单,只需打开Prompt:
pip install tensorflow
安装成功
导入成功
#导入keras
from tensorflow import keras
#导入tensorflow
import tensorflow as tf
注:有些教程中导入Keras用的是import tensorflow.keras as keras会提示No module named 'tensorflow.keras'
2、导入mnist数据
在上篇文章中我们已经提到过 MNIST 了,用有趣的方式解释梯度下降算法
它是一个收录了许多 28 x 28 像素手写数字图片(以灰度值矩阵存储)及其对应的数字的数据集,可以把它理解成下图这个样子:
由于众所周知的原因,Keras自带minist数据集下载会报错,无法下载。博客园崔小秋同学给出了很好的解决方法:
1、找到本地keras目录下的mnist.py文件,通常在这个目录下。
2、下载mnist.npz文件到本地,下载链接如下。
https://pan.baidu.com/s/1C3c2Vn-_616GqeEn7hQQ2Q
3、修改mnist.py文件为以下内容,并保存
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from ..utils.data_utils import get_file
import numpy as np
def load_data(path='mnist.npz'):
"""Loads the MNIST dataset. # Arguments
path: path where to cache the dataset locally
(relative to ~/.keras/datasets).
# Returns
Tuple of Numpy arrays: `(x_train, y_train), (x_test, y_test)`.
"""
path = 'E:/Data/Mnist/mnist.npz' #此处的path为你刚刚存放mnist.py的目录。注意斜杠
f = np.load(path)
x_train, y_train = f['x_train'], f['y_train']
x_test, y_test = f['x_test'], f['y_test']
f.close()
return (x_train, y_train), (x_test, y_test)
看一下数据
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
print(x_train[0].shape)
(28, 28)
import matplotlib.pyplot as plt
plt.imshow(x_train[0],cmap=plt.cm.binary)
plt.show()
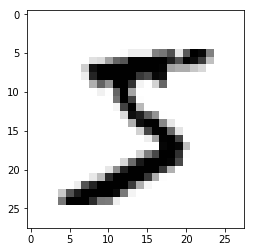
print(y_train[0])
5
对数据进行归一化处理
x_train = tf.keras.utils.normalize(x_train, axis=1)
x_test = tf.keras.utils.normalize(x_test, axis=1)
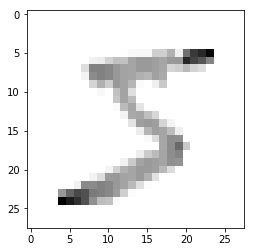
再看一下,图像的像素值被限定在了 [0,1]
plt.imshow(x_train[0],cmap=plt.cm.binary)
plt.show()
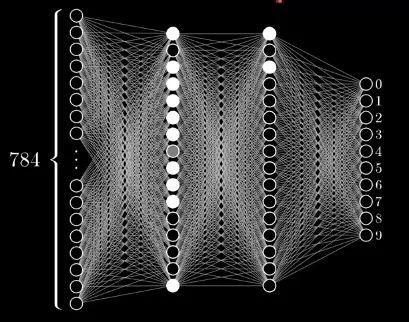
3 构建与训练模型我们使用 Keras 的 Sequential 模型(顺序模型),顺序模型是多个网络层的线性堆叠。本文旨在介绍TensorFlow 及Keras用法,不再展开,有兴趣的同学们学习其具体用法,可以参考Keras文档:
https://keras.io/zh/getting-started/sequential-model-guide/
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28,28)))
model.add(tf.keras.layers.Dense(128, activation=tf.nn.relu))
model.add(tf.keras.layers.Dense(128, activation=tf.nn.relu))
model.add(tf.keras.layers.Dense(10, activation=tf.nn.softmax))
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=3)
我们构建出的模型大概是这个样子的,区别是我们的隐藏层有128个单元
在训练的过程中,我们会发现损失值(loss)在降低,而准确度(accuracy)在提高,最后达到了一个令人满意的程度。
Epoch 1/3
60000/60000 - 8s 127us/step - loss: 0.2677 - acc: 0.9211Epoch 2/3
60000/60000 - 8s 130us/step - loss: 0.1106 - acc: 0.9655Epoch 3/3
60000/60000 - 8s 136us/step - loss: 0.0751 - acc: 0.9764
4 测试模型
val_loss, val_acc = model.evaluate(x_test, y_test)
print(val_loss)
print(val_acc)
10000/10000 - 0s 45us/step0.0916121033909265
0.9713
损失和准确度看起来还凑合,尝试识别训练集
predictions = model.predict(x_test)
print(predictions)
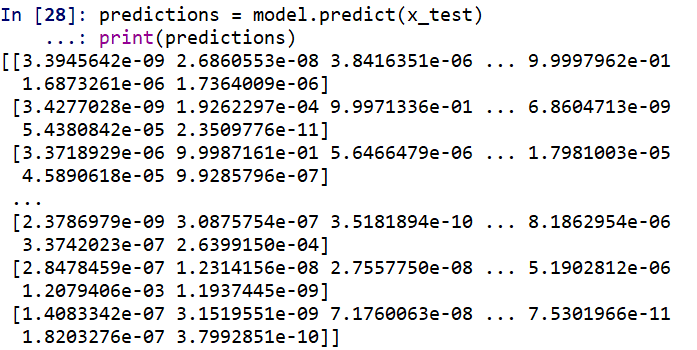
用 argmax 解析一下(就是找出最大数对应的索引,即为识别出的数字)
import numpy as np
print(np.argmax(predictions[0]))
7
plt.imshow(x_test[0],cmap=plt.cm.binary)
plt.show()
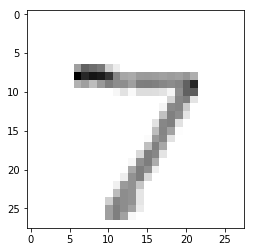
OK,模型可以识别数字了。
5、保存模型
主要用于模型的存储和恢复。
model.save('epic_num_reader.model')
# 加载保存的模型
new_model = tf.keras.models.load_model('epic_num_reader.model')
# 测试保存的模型
predictions = new_model.predict(x_test)print(np.argmax(predictions[0]))
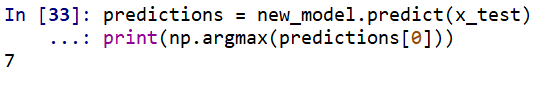
看到这里的都是真爱,另推荐一个Keras教程
Colab超火的Keras/TPU深度学习免费实战,有点Python基础就能看懂的快速课程
参考:
https://www.cnblogs.com/shinny/p/9283372.html
https://www.cnblogs.com/wj-1314/p/9579490.html
https://github.com/MLEveryday/100-Days-Of-ML-Code/blob/master/Code/Day 39.ipynb

 浙公网安备 33010602011771号
浙公网安备 33010602011771号