100天搞定机器学习|day38 反向传播算法推导
往期回顾
100天搞定机器学习|Day37无公式理解反向传播算法之精髓
上集我们学习了反向传播算法的原理,今天我们深入讲解其中的微积分理论,展示在机器学习中,怎么理解链式法则。
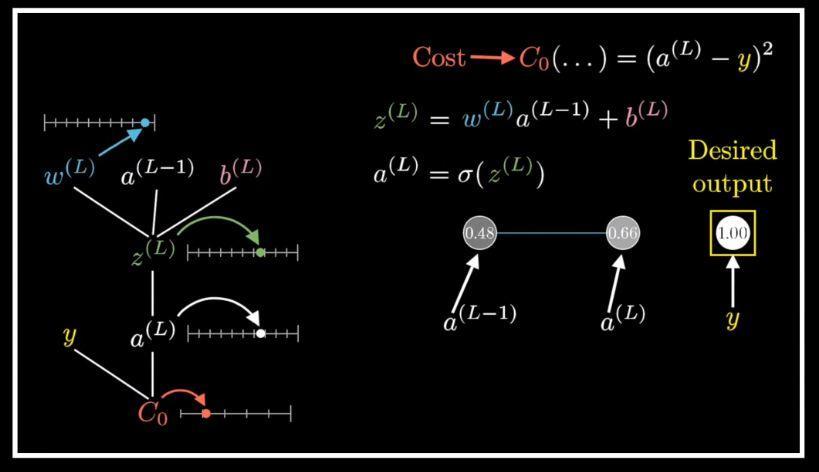
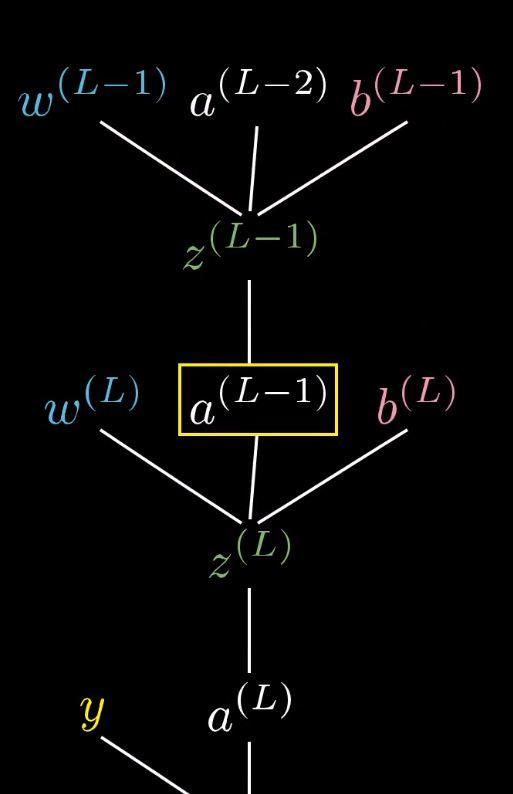
我们从一个最简单的网络讲起,每层只有一个神经元,图上这个网络就是由三个权重和三个偏置决定的,我们的目标是理解代价函数对这些变量有多敏感。这样我们就知道怎么调整这些变量,才能使代价函数下降的最快。

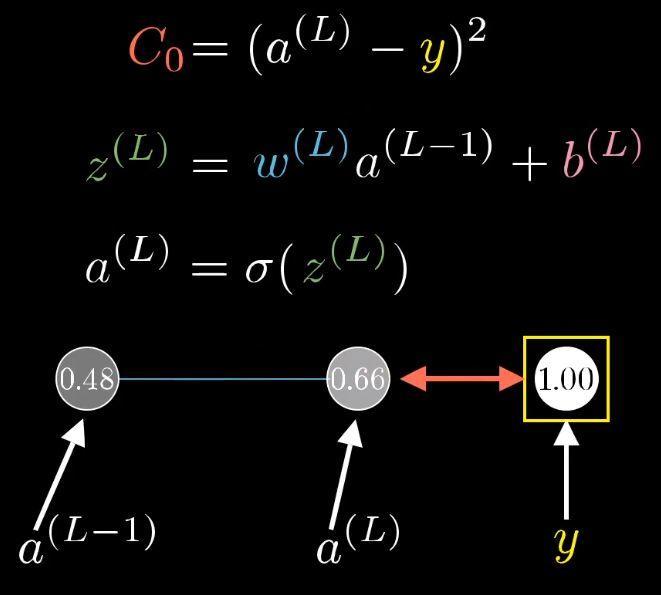
我们先来关注最后两个神经元,我们给最后一个神经元一个上标L,表示它处在第L层。给定一个训练样本,我们把这个最终层激活值要接近的目标叫做y,y的值为0/1。那么这个简易网络对于单个训练样本的代价就等于(a(L)−y)2。对于这个样本,我们把这个代价值标记为C0。

之前讲过,最终层的激活值公式:
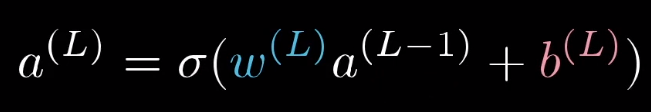
换个标记方法:
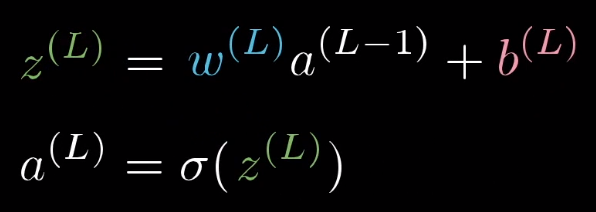
整个流程就是这样的:
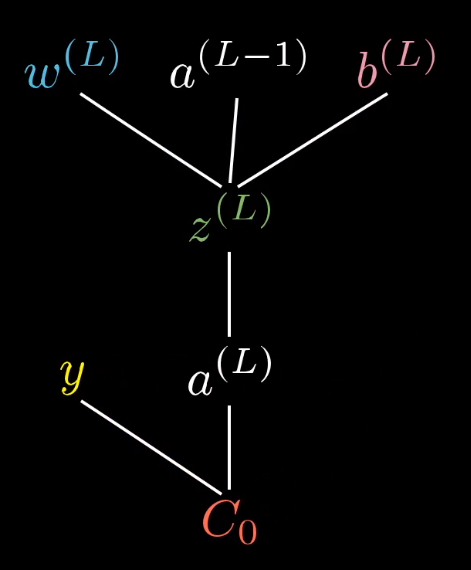
当然了,a(L−1)还可以再向上推一层,不过这不重要。
这些东西都是数字,我们可以想象,每个数字都对应数轴上的一个位置。我们第一个目标是来理解代价函数对权重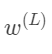
的微小变化有多敏感。换句话说,求C0对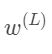
的导数。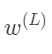 的微小变化导致
的微小变化导致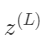 产生变化,然后导致
产生变化,然后导致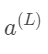 ,最终影响到cost。
,最终影响到cost。

我们把式子拆开,首先求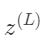 的变化量比
的变化量比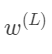 的变化量,即
的变化量,即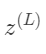 关于
关于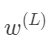 的导数;同力考虑
的导数;同力考虑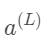 变化量比
变化量比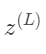 的变化量,以及最终的c的变化量比上直接改动
的变化量,以及最终的c的变化量比上直接改动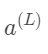 产生的变化量。
产生的变化量。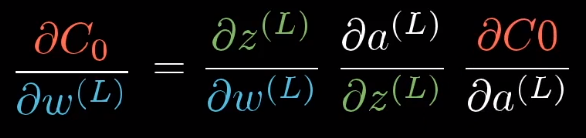
这就是链式法则
开始分别求导
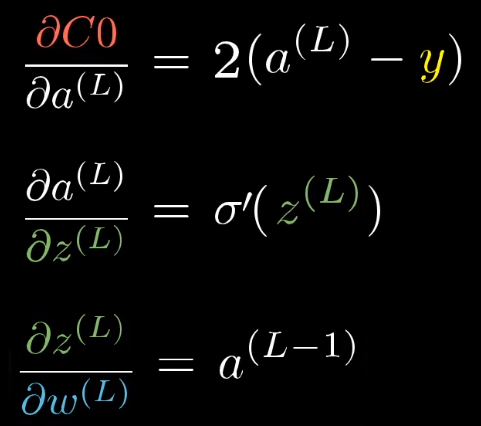
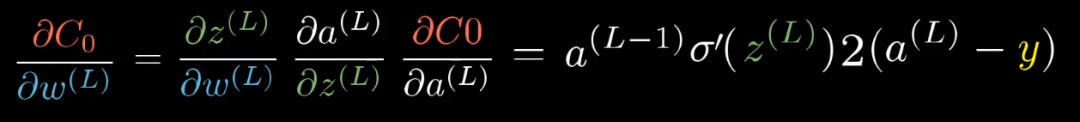
这只是包含一个训练样本的代价对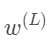 的导数,
的导数,
总的代价函数是所有训练样本代价的总平均,它对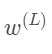 的导数就要求出这个表达式对每一个训练样本的平均,
的导数就要求出这个表达式对每一个训练样本的平均,

这只是梯度向量的一个分量,梯度由代价函数对每一个权重和偏置求导数构成。
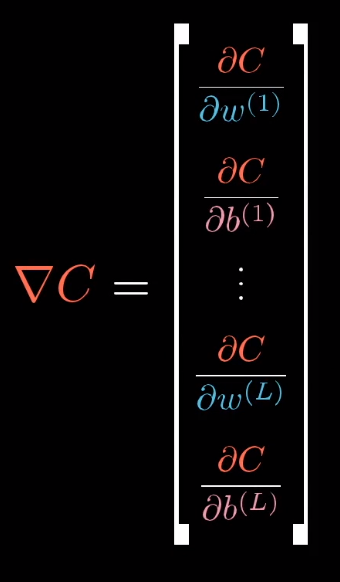
当然了,对偏置求导数也是同样的步骤。只要把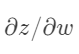 替换成
替换成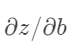
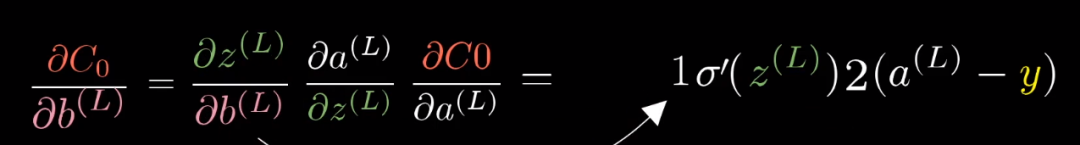
同样的,这里也有反向传播的思想
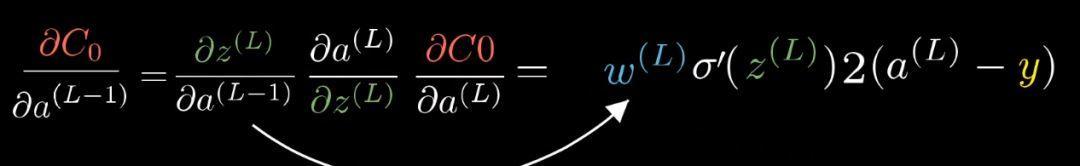
到此,我们可以方向应用链式法则,来计算代价函数对之前的权重和偏置的敏感程度

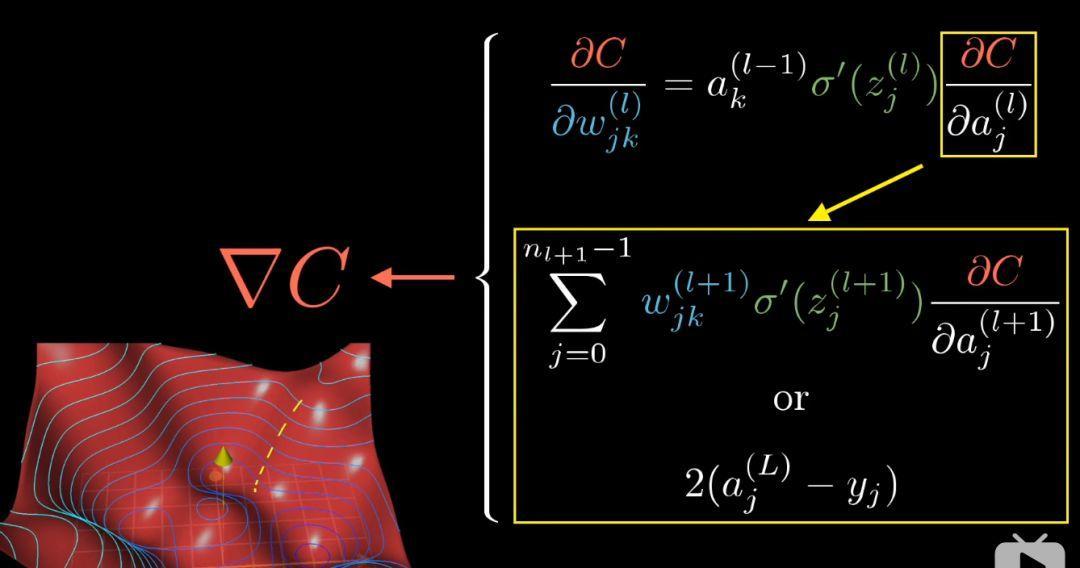
到这里,我们可以看每层不止一个神经元的情况了,其实并不复杂太多,只是多写一些下标罢了。
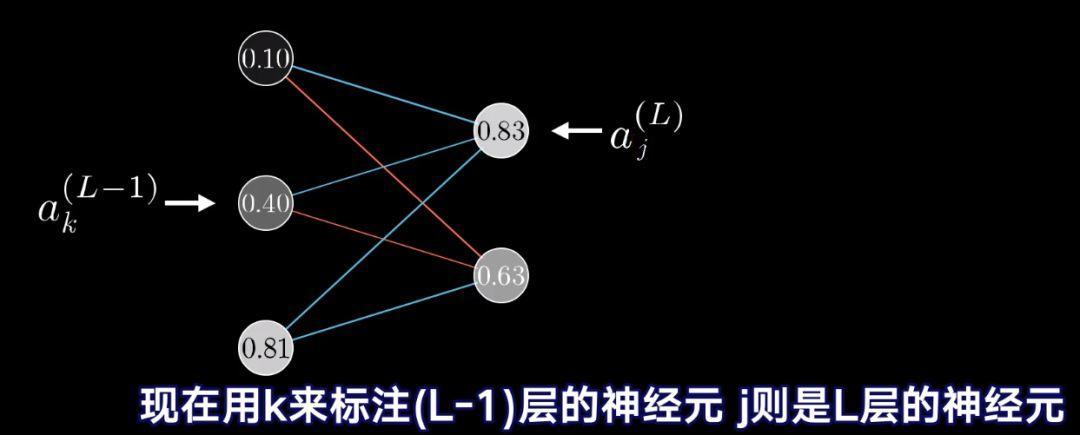
这些方程式和之前每层只有一个神经元的时候本质上一样的
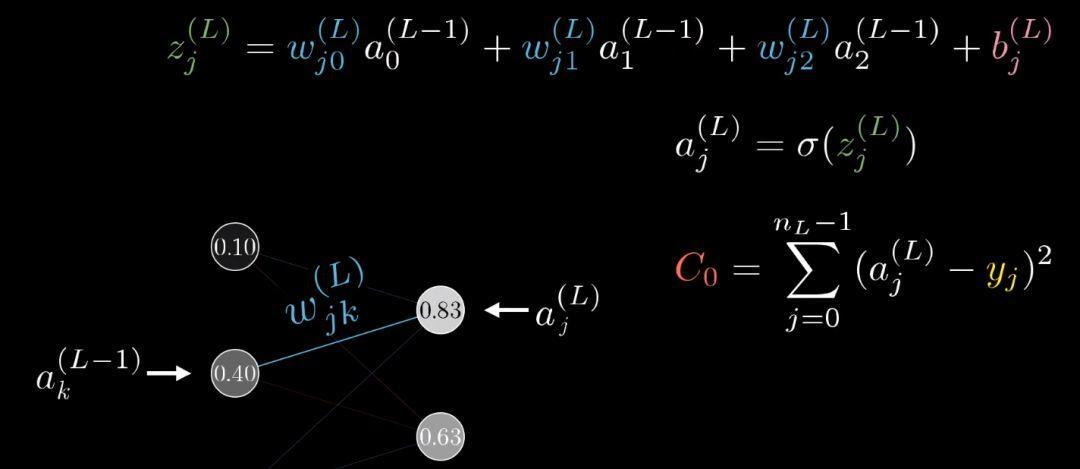
代价函数也类似
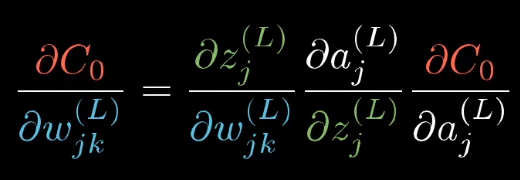
不同的是代价函数对(L-1)层激活值的导数
因为此时,激活值可以通过不同的途径影响cost function,
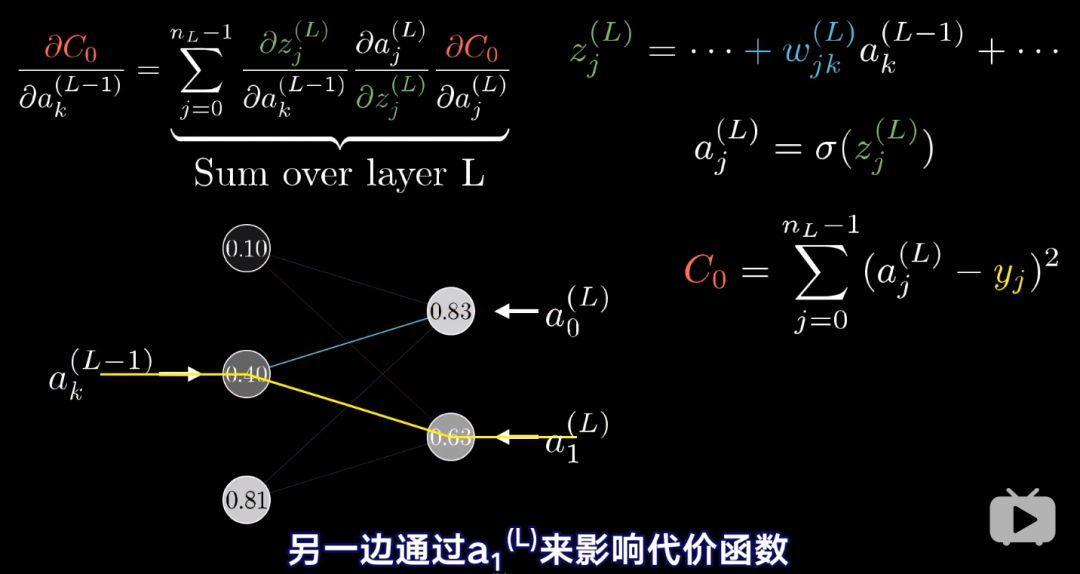
只要计算出倒数第二层代价函数对激活值的敏感度,接下来重复上述过程就行了。至此,反向传播介绍完毕。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号