
NEO4J亿级数据导入导出以及数据更新
1、添加配置
apoc.export.file.enabled=true
apoc.import.file.enabled=true
dbms.directories.import=import
dbms.security.allow_csv_import_from_file_urls=true
2、导出操作
CALL apoc.export.csv.all('C:\\Users\\11416\\.Neo4jDesktop\\neo4jDatabases\\database-bcbe66f8-2f8f-4926-a1b8-bbdb0c4c6409\\installation-3.4.1\\data\\back\\db.csv',{stream:true,batchSize:2})
db.csv文件内容样例
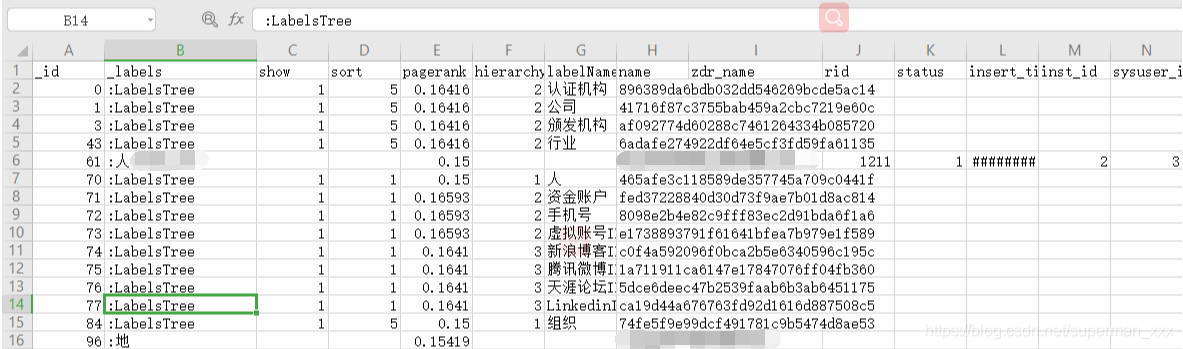
3、导入操作
// 导入大量数据不适用
CALL apoc.load.csv('C:\\Users\\11416\\.Neo4jDesktop\\neo4jDatabases\\database-bcbe66f8-2f8f-4926-a1b8-bbdb0c4c6409\\installation-3.4.1\\data\\back\\db.csv') yield lineNo, map, list
RETURN *
// 支持在开放事务中提交-使用之前需要先安装存储过程库
CALL apoc.periodic.iterate(
'CALL apoc.load.csv("file:/C:/Users/11416/.Neo4jDesktop/neo4jDatabases/database-06767a53-355b-44eb-b8a8-0156dff8f8e1/installation-3.4.1/import/test.csv") yield map as row return row',
'merge (n:Label {name:row.Linkin}) with * merge (m:Mark {name:row.学校}) with * merge (n)-[r:教育经历]->(m)'
,{batch:10000, iterateList:true, parallel:true})
// 不支持在开放事务中提交
using periodic commit 1000
load csv with headers from "file:///test.csv" as line with line
merge (n:Linkin {name:line.LinkedinID}) with *
merge (m:学校 {name:line.学校}) with *
merge (n)-[r:教育经历]->(m)
// CSV文件压缩为ZIP之后进行导入
using periodic commit 1000
load csv with headers from "file:///studentBatch.zip" as line with line
merge (n:Linkin {name:line.LinkedinID}) with *
merge (m:学校 {name:line.学校}) with *
merge (n)-[r:教育经历]->(m)
// Twitter公开数据导入测试(https://snap.stanford.edu/data/twitter-2010.txt.gz)
USING PERIODIC COMMIT 1000 LOAD CSV FROM "file:///twitter-2010.txt.gz" AS line FIELDTERMINATOR ' ' WITH toInt(line[0]) as id MERGE (n:Person {id:id}) ON CREATE SET n.name = toString(id), n.sex = ["男", "女"][(id % 2)],n.age = (id % 50) + 15,n.country = ["中国", "美国", "法国", "英国", "俄罗斯", "加拿大", "德国", "日本", "意大利"][(id % 9)];
4、批量更新还可以使用UNWIND子句
// 节点关系同时MERGE
UNWIND [{from:"Pamela May24173068",to:"United Nations Conference on Trade and Development (UNCTAD)9491230"},{from:"Carl Walsh33095175",to:"United Nations Conference on Trade and Development (UNCTAD)9491230"}] as row
MERGE (from:Linkin {name:row.from}) MERGE (to:认证机构 {name:row.to}) WITH from,to
CALL apoc.merge.relationship(from, '奖项', null, null, to) YIELD rel RETURN count(*) as count;
// 示例一:apoc.create.relationship的示例
UWNIND {batch} as row
MATCH (from) WHERE id(n) = row.from
MATCH (to:Label) where to.key = row.to
CALL apoc.create.relationship(from, row.type, row.properties, to) yield rel
RETURN count(*)
// 示例二:动态创建节点和关系(标签是一个String数组/属性就是一个Map):
// 1
UWNIND {batch} as row
CALL apoc.create.node(row.labels, row.properties) yield node
RETURN count(*)
// 2
UNWIND [{label:["label1","label2"],properties:{name:"Emil Eifrem",born:1978}}] as row
CALL apoc.create.node(row.labels, row.properties) yield node
RETURN count(*)
// 3
UNWIND [{labels:["Person"],properties:{name:"Emil Eifrem"}}] as row
CALL apoc.merge.node(row.labels, row.properties,null) yield node
RETURN node
// 示例三
UNWIND {batch} as row
UNWIND [{from:"alice@example.com",to:"bob@example.com",properties:{since:2012}},{from:"alice@example.com",to:"charlie@example.com",properties:{since:2016}}] as row
MATCH (from:Label {from:row.from})
MATCH (to:Label {to:row.to})
MERGE (from)-[rel:KNOWS]->(to)
ON CREATE SET rel.since = row.properties.since
5、亿级数据量更新操作
执行一
// 1、根据节点属性对已有节点添加新的标签(更新失败)-超时设置:dbms.transaction.timeout=180s
MATCH (n:Lable) WHERE n.userDefinedImageUrl IS NOT NULL SET n:头像
更新失败

执行二
// 2、根据节点属性对已有节点添加新的标签(更新成功)
CALL apoc.periodic.iterate('MATCH (n:LinkedinID) WHERE n.userDefinedImageUrl IS NOT NULL RETURN n','WITH {n} AS n SET n:头像',{batchSize:10,parallel:true});
原文地址:https://blog.csdn.net/superman_xxx/article/details/83589953更新成功


 浙公网安备 33010602011771号
浙公网安备 33010602011771号