专题:性能调优之工具---perf
1. Linux Perf简介
1.1 Perf是什么
Perf 是内置于Linux 内核源码树中的性能剖析(profiling)工具。它基于事件采样原理,以性能事件为基础,支持针对处理器相关性能指标与操作系统相关性能指标的性能剖析。可用于性能瓶颈的查找与热点代码的定位。linux2.6及后续版本都自带该工具,几乎能够处理所有与性能相关的事件。
1.2 性能事件
性能事件指在处理器或者操作系统中发生,可能影响到程序性能的硬件事件或者软件事件。
1.3 主要作用
Perf工具可用来对软件进行优化,包括算法优化(空间复杂度、时间复杂度)和代码优化(提高执行速度、减少内存占用)。还可以评估程序对硬件资源的使用情况,例如各级cache的访问次数,各级cache的丢失次数、流水线停顿周期、前端总线访问次数等。也可以评估程序对操作系统资源的使用情况,系统调用次数、上下文切换次数、任务迁移次数等。
1.4 perf 安装
1.4.1 利用源码安装
下载一份2.6版本以后的linux源码,网址(https://www.kernel.org/)
在linux/tools/perf目录中执行命令,make--->make install,在usr1/用户名/bin下会有个perf命令。
1.4.2 利用软件包安装
……,网上的各种安装方法感觉都不好使,还是用源码来的方便快捷。
以上为linux下的perf的基本原理和工作流程
2.Perf基本原理
Perf主要基于性能事件的采集和分析,有两种采集方法:
基于硬件的采集方法,此种方法需要采用CPU中的PMU(performance monitoring unit)部件,在特定的条件下探测性能事件是否发生以及发生的次数。
基于软件的采集方法,需要将代码内置于kernel,分布在各个功能模块中,统计和操作系统相关性能事件。
那么perf 是怎么做到的呢?首先,perf 会通过系统调用sys_perf_event_open在内核中注册一个监测“cycles”事件的性能计数器。内核根据perf 提供的信息在PMU 上初始化一个硬件性能计数器(PMC: Performance Monitoring Counter)。PMC随着CPU 周期的增加而自动累加。在PMC溢出时,PMU 触发一个PMI(Performance Monitoring Interrupt)中断。内核在PMI 中断的处理函数中保存PMC的计数值,触发中断时的指令地址(Register IP:Instruction Pointer),当前时间戳以及当前进程的PID,TID,comm 等信息。我们把这些信息统称为一个采样(sample)。内核会将收集到的sample 放入用于跟用户空间通信的Ring Buffer。
用户空间里的perf 分析程序采用mmap 机制从ring buffer 中读入采样,并对其解析。perf 根据pid,comm 等信息可以找到对应的进程。根据IP 与ELF 文件中的符号表可以查到触发PMI 中断的指令所在的函数。为了能够使perf 读到函数名,我们的目标程序必须具备符号表。如果读者在perf 的分析结果中只看到一串地址,而没有对应的函数名时,通常是由于在编译时利用strip 删除了ELF 文件中的符号表。建议读者在性能分析阶段,保留程序中的symbol table,debug info等信息。【1】
2.1 Perf硬件采样原理
Perf硬件采样主要利用了CPU中的PMU部件。接下来为大家介绍PMU部件的操作方法。
下面为翻译的arm官方文档DDI0464E_cortex_a7_mpcore_r0p4_trm.pdf,这篇文档主要针对cortex_a7来讲的,详细的讲述了PMU部件。【2】
2.1.1 关于PMU
基于PMUv2架构,A7处理器在运行时可以收集关于处理器和内存的各种统计信息。对于处理器来说这些统计信息中的事件非常有用,你可以利用它们来调试或者剖析代码。
处理器PMU部件提供了4个计数器。每个计数器都可以对处理器的任何事件(可用的)计数。
2.1.2 PMU功能描述
主要包含三部分,eventinterface,CP15 and APB interface,Counters
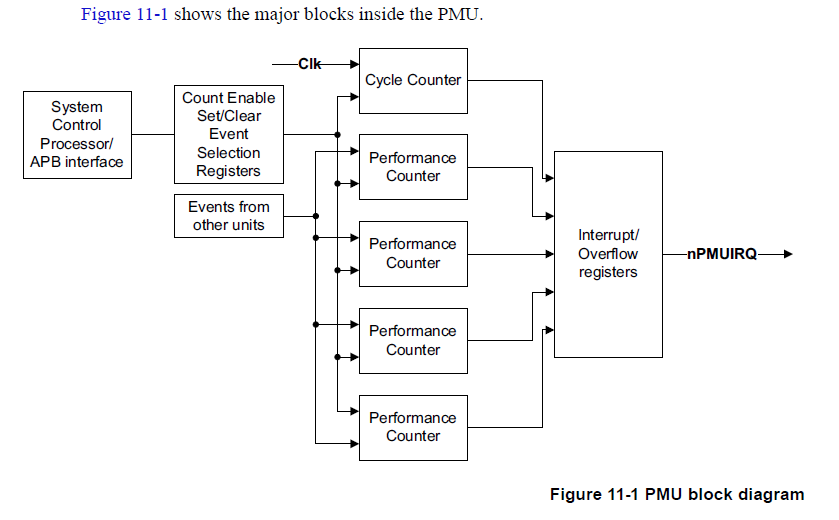
上图为PMU部件的组成,主要是那5个计数器。
Eventinterface
Eventsfrom all other units from across the design are provided to the PMU.
提供给PMU部件的所有事件,这些事件全部来自其他的部件。
CP15and APB interface
The PMUregisters can be programmed using the CP15 system control coprocessor orexternal APB interface.
PMU寄存器可以通过CP15 协处理器和外部APB接口来编程。
Counters计数器
PMU含有4个随事件增加32位计数器。
PMU含有1个随处理器时钟周期增加的循环计数器。
2.1.3 PMU寄存器汇总
访问方式:PMU计数器和PMU控制寄存器可以通过CP15协处理器和APB接口来访问。
下表为Cortex-A7MPCore PMU 寄存器,只列出了一部分,详细查看请看本篇文章底部。
| number | Offset | CRn | Op1 | CRm | Op2 | Name | Type | Description |
| 0 | 0x000 | c9 | 0 | c13 | 2 | PMXEVCNTR0 | RW | 事件计数寄存器, 参见 the ARM Architecture Reference Manual 手册 |
| 1 | 0x004 | c9 | 0 | c13 | 2 | PMXEVCNTR1 | RW | |
| 2 | 0x008 | c9 | 0 | c13 | 2 | PMXEVCNTR2 | RW | |
| 3 | 0x00C | c9 | 0 | c13 | 2 | PMXEVCNTR3 | RW | |
| 4--30 | 0x010-0x78 | - | - | - | - | - | Reserved | |
| 31 | 0x07C | c9 | 0 | c13 | 0 | PMCCNTR | RW | 循环计数寄存器, 参见 the ARM Architecture Reference Manual 手册 |
| 32-255 | 0x080-0x3FC - | - | - | - | - | Reserved | ||
| 256 | 0x400 | c9 | 0 | c13 | 1 | PMXEVTYPER0 | RW | 事件类型选择寄存器, 参见 the ARM Architecture Reference Manual手册 |
操作PMU部件需要通过mrc和mcr指令来操作cp15协处理器。
2.2 Perf 软件采样原理
2.3 Perf采样精度
如果需要采用高精度的采样,需要在制定性能事情时,在事件后添加后缀“:p”或者“:pp”。Perf 在采样精度上定义了4 个级别,如表2 所示。
表2. 性能事件的精度级别
0 无精度保证
1 采样指令与触发性能事件的指令之间的偏差为常数(:p)
2 需要尽量保证采样指令与触发性能事件的指令之间的偏差为0(:pp)
3 保证采样指令与触发性能事件的指令之间的偏差必须为0(:ppp)
3.Perf使用
3.1 使用方法
3.2 Perf常用命令
1、 perf list
2、 perf stat
3、 perf top
4、 perf record/report
参考:
【1】 Linux的系统级性能剖析工具---- 承刚
【2】 DDI0464E_cortex_a7_mpcore_r0p4_trm.pdf---- arm官网
【3】 Perf -- Linux下的系统性能调优工具,第1 部分
https://www.ibm.com/developerworks/cn/linux/l-cn-perf1/
【4】 Perf -- Linux下的系统性能调优工具,第 2 部分
http://www.ibm.com/developerworks/cn/linux/l-cn-perf2/
【5】Linux kernel profiling with perf
https://perf.wiki.kernel.org/index.php/Tutorial
原文地址:https://blog.csdn.net/chichi123137/article/details/80139237

 浙公网安备 33010602011771号
浙公网安备 33010602011771号