分布式系统唯一ID的生成方案讨论
分布式系统唯一ID的生成方案讨论
</h2>
<div class="content" id="articleContent">
<div class="ad-wrap">
<p style="margin:0 0 10px 0;"><a data-traceid="blog_detail_above_text_link_1" data-tracepid="blog_detail_above_text_link" style="color:#A00;font-weight:bold;" href="https://gio.ren/w/GPnE1LRY" target="_blank">撸了今年阿里、头条和美团的面试,我有一个重要发现.......>>> </a> <img src="https://www.oschina.net/img/hot3.png" align="absmiddle" style="max-height: 32px; max-width: 32px;"></p>
</div>
<p>在分布式系统下唯一id问题,就是id咋生成?比如分表分库,因为要是一个表分成多个表之后,每个表的id都是从1开始累加自增长,那是不对的。举个例子,一个表拆分为了2张表,每个表的id都从1开始累加,这个肯定有问题了!你的系统就没办法根据表主键来查询了,比如id = 10这个记录,在两个表里都有!所以此时就需要分布式架构下的全局唯一id生成的方案了,保证每个表内的某个id,全局唯一。全局唯一id主要有以下几种方案。</p>
</h2>
<div class="content" id="articleContent">
<div class="ad-wrap">
<p style="margin:0 0 10px 0;"><a data-traceid="blog_detail_above_text_link_1" data-tracepid="blog_detail_above_text_link" style="color:#A00;font-weight:bold;" href="https://gio.ren/w/GPnE1LRY" target="_blank">撸了今年阿里、头条和美团的面试,我有一个重要发现.......>>> </a> <img src="https://www.oschina.net/img/hot3.png" align="absmiddle" style="max-height: 32px; max-width: 32px;"></p>
</div>
<p>在分布式系统下唯一id问题,就是id咋生成?比如分表分库,因为要是一个表分成多个表之后,每个表的id都是从1开始累加自增长,那是不对的。举个例子,一个表拆分为了2张表,每个表的id都从1开始累加,这个肯定有问题了!你的系统就没办法根据表主键来查询了,比如id = 10这个记录,在两个表里都有!所以此时就需要分布式架构下的全局唯一id生成的方案了,保证每个表内的某个id,全局唯一。全局唯一id主要有以下几种方案。</p>
分布式ID的生成方案
1. UUID
算法的核心思想是结合机器的网卡、当地时间、一个随记数来生成UUID。
- 优点:本地生成,生成简单,性能好,没有高可用风险
- 缺点:长度过长,存储冗余,且无序不可读,查询效率低(在数据库里不利于索引树的构建,不适合用作主键)
2. 数据库自增ID
使用数据库的id自增策略,如 MySQL 的 auto_increment。并且可以使用两台数据库分别设置不同步长,生成不重复ID的策略来实现高可用。
- 优点:数据库生成的ID绝对有序,高可用实现方式简单
- 缺点:需要独立部署数据库实例,成本高,有性能瓶颈
3. 批量生成ID
一次按需批量生成多个ID,每次生成都需要访问数据库,将数据库修改为最大的ID值,并在内存中记录当前值及最大值。
- 优点:避免了每次生成ID都要访问数据库并带来压力,提高性能
- 缺点:属于本地生成策略,存在单点故障,服务重启造成ID不连续
4. Redis生成ID
Redis的所有命令操作都是单线程的,本身提供像 incr 和 increby 这样的自增原子命令,所以能保证生成的 ID 肯定是唯一有序的。
-
优点:不依赖于数据库,灵活方便,且性能优于数据库;数字ID天然排序,对分页或者需要排序的结果很有帮助。
-
缺点:如果系统中没有Redis,还需要引入新的组件,增加系统复杂度;需要编码和配置的工作量比较大。
考虑到单节点的性能瓶颈,可以使用 Redis 集群来获取更高的吞吐量。假如一个集群中有5台 Redis。可以初始化每台 Redis 的值分别是1, 2, 3, 4, 5,然后步长都是 5。各个 Redis 生成的 ID 为:
A:1, 6, 11, 16, 21
B:2, 7, 12, 17, 22
C:3, 8, 13, 18, 23
D:4, 9, 14, 19, 24
E:5, 10, 15, 20, 25随便负载到哪个机确定好,未来很难做修改。步长和初始值一定需要事先确定。使用 Redis 集群也可以方式单点故障的问题。
另外,比较适合使用 Redis 来生成每天从0开始的流水号。比如订单号 = 日期 + 当日自增长号。可以每天在 Redis 中生成一个 Key ,使用 INCR 进行累加。
5. Twitter的snowflake算法
Twitter 利用 zookeeper 实现了一个全局ID生成的服务 Snowflake:https://github.com/twitter-archive/snowflake
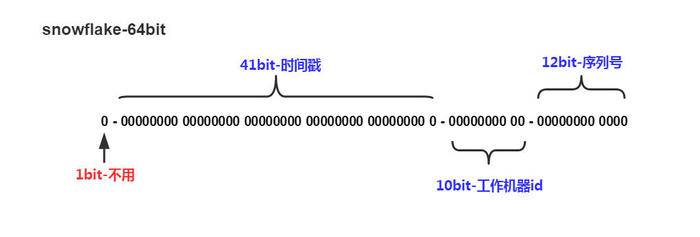
如上图的所示,Twitter 的 Snowflake 算法由下面几部分组成:
- 1位符号位:
由于 long 类型在 java 中带符号的,最高位为符号位,正数为 0,负数为 1,且实际系统中所使用的ID一般都是正数,所以最高位为 0。
- 41位时间戳(毫秒级):
需要注意的是此处的 41 位时间戳并非存储当前时间的时间戳,而是存储时间戳的差值(当前时间戳 - 起始时间戳),这里的起始时间戳一般是ID生成器开始使用的时间戳,由程序来指定,所以41位毫秒时间戳最多可以使用 (1 << 41) / (1000x60x60x24x365) = 69年。
- 10位数据机器位:
包括5位数据标识位和5位机器标识位,这10位决定了分布式系统中最多可以部署 1 << 10 = 1024 s个节点。超过这个数量,生成的ID就有可能会冲突。
- 12位毫秒内的序列:
这 12 位计数支持每个节点每毫秒(同一台机器,同一时刻)最多生成 1 << 12 = 4096个ID
加起来刚好64位,为一个Long型。
- 优点:高性能,低延迟,按时间有序,一般不会造成ID碰撞
- 缺点:需要独立的开发和部署,依赖于机器的时钟
代码实现:
public class IdWorker {
/**
* 起始时间戳 2017-04-01
*/
private final long epoch = 1491004800000L;
/**
* 机器ID所占的位数
*/
private final long workerIdBits = 5L;
/**
* 数据标识ID所占的位数
*/
private final long dataCenterIdBits = 5L;
/**
* 支持的最大机器ID,结果是31
*/
private final long maxWorkerId = ~(-1L << workerIdBits);
/**
* 支持的最大数据标识ID,结果是31
*/
private final long maxDataCenterId = ~(-1 << dataCenterIdBits);
/**
* 毫秒内序列在id中所占的位数
*/
private final long sequenceBits = 12L;
/**
* 机器ID向左移12位
*/
private final long workerIdShift = sequenceBits;
/**
* 数据标识ID向左移17(12+5)位
*/
private final long dataCenterIdShift = sequenceBits + workerIdBits;
/**
* 时间戳向左移22(12+5+5)位
*/
private final long timestampShift = sequenceBits + workerIdBits + dataCenterIdBits;
/**
* 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095)
*/
private final long sequenceMask = ~(-1L << sequenceBits);
/**
* 数据标识ID(0~31)
*/
private long dataCenterId;
/**
* 机器ID(0~31)
*/
private long workerId;
/**
* 毫秒内序列(0~4095)
*/
private long sequence;
/**
* 上次生成ID的时间戳
*/
private long lastTimestamp = -1L;
<span class="hljs-function"><span class="hljs-keyword"><span class="hljs-function"><span class="hljs-keyword">public</span></span></span><span class="hljs-function"> </span><span class="hljs-title"><span class="hljs-function"><span class="hljs-title">IdWorker</span></span></span><span class="hljs-params"><span class="hljs-function"><span class="hljs-params">(</span></span><span class="hljs-keyword"><span class="hljs-function"><span class="hljs-params"><span class="hljs-keyword">long</span></span></span></span><span class="hljs-function"><span class="hljs-params"> dataCenterId, </span></span><span class="hljs-keyword"><span class="hljs-function"><span class="hljs-params"><span class="hljs-keyword">long</span></span></span></span><span class="hljs-function"><span class="hljs-params"> workerId)</span></span></span><span class="hljs-function"> </span></span>{
<span class="hljs-keyword"><span class="hljs-keyword">if</span></span> (dataCenterId > maxDataCenterId || dataCenterId < <span class="hljs-number"><span class="hljs-number">0</span></span>) {
<span class="hljs-keyword"><span class="hljs-keyword">throw</span></span> <span class="hljs-keyword"><span class="hljs-keyword">new</span></span> IllegalArgumentException(String.format(<span class="hljs-string"><span class="hljs-string">"dataCenterId can't be greater than %d or less than 0"</span></span>, maxDataCenterId));
}
<span class="hljs-keyword"><span class="hljs-keyword">if</span></span> (workerId > maxWorkerId || workerId < <span class="hljs-number"><span class="hljs-number">0</span></span>) {
<span class="hljs-keyword"><span class="hljs-keyword">throw</span></span> <span class="hljs-keyword"><span class="hljs-keyword">new</span></span> IllegalArgumentException(String.format(<span class="hljs-string"><span class="hljs-string">"worker Id can't be greater than %d or less than 0"</span></span>, maxWorkerId));
}
<span class="hljs-keyword"><span class="hljs-keyword">this</span></span>.dataCenterId = dataCenterId;
<span class="hljs-keyword"><span class="hljs-keyword">this</span></span>.workerId = workerId;
}
<span class="hljs-comment"><span class="hljs-comment">/**
* 获得下一个ID (该方法是线程安全的)
* </span><span class="hljs-doctag"><span class="hljs-comment"><span class="hljs-doctag">@return</span></span></span><span class="hljs-comment"> snowflakeId
*/</span></span>
<span class="hljs-function"><span class="hljs-keyword"><span class="hljs-function"><span class="hljs-keyword">public</span></span></span><span class="hljs-function"> </span><span class="hljs-keyword"><span class="hljs-function"><span class="hljs-keyword">synchronized</span></span></span><span class="hljs-function"> </span><span class="hljs-keyword"><span class="hljs-function"><span class="hljs-keyword">long</span></span></span><span class="hljs-function"> </span><span class="hljs-title"><span class="hljs-function"><span class="hljs-title">nextId</span></span></span><span class="hljs-params"><span class="hljs-function"><span class="hljs-params">()</span></span></span><span class="hljs-function"> </span></span>{
<span class="hljs-keyword"><span class="hljs-keyword">long</span></span> timestamp = timeGen();
<span class="hljs-comment"><span class="hljs-comment">//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过,这个时候应当抛出异常</span></span>
<span class="hljs-keyword"><span class="hljs-keyword">if</span></span> (timestamp < lastTimestamp) {
<span class="hljs-keyword"><span class="hljs-keyword">throw</span></span> <span class="hljs-keyword"><span class="hljs-keyword">new</span></span> RuntimeException(String.format(<span class="hljs-string"><span class="hljs-string">"Clock moved backwards. Refusing to generate id for %d milliseconds"</span></span>, lastTimestamp - timestamp));
}
<span class="hljs-comment"><span class="hljs-comment">//如果是同一时间生成的,则进行毫秒内序列</span></span>
<span class="hljs-keyword"><span class="hljs-keyword">if</span></span> (timestamp == lastTimestamp) {
sequence = (sequence + <span class="hljs-number"><span class="hljs-number">1</span></span>) & sequenceMask;
<span class="hljs-comment"><span class="hljs-comment">//毫秒内序列溢出</span></span>
<span class="hljs-keyword"><span class="hljs-keyword">if</span></span> (sequence == <span class="hljs-number"><span class="hljs-number">0</span></span>) {
<span class="hljs-comment"><span class="hljs-comment">//阻塞到下一个毫秒,获得新的时间戳</span></span>
timestamp = nextMillis(lastTimestamp);
}
} <span class="hljs-keyword"><span class="hljs-keyword">else</span></span> {<span class="hljs-comment"><span class="hljs-comment">//时间戳改变,毫秒内序列重置</span></span>
sequence = <span class="hljs-number"><span class="hljs-number">0L</span></span>;
}
lastTimestamp = timestamp;
<span class="hljs-comment"><span class="hljs-comment">//移位并通过按位或运算拼到一起组成64位的ID</span></span>
<span class="hljs-keyword"><span class="hljs-keyword">return</span></span> ((timestamp - epoch) << timestampShift) |
(dataCenterId << dataCenterIdShift) |
(workerId << workerIdShift) |
sequence;
}
<span class="hljs-comment"><span class="hljs-comment">/**
* 返回以毫秒为单位的当前时间
* </span><span class="hljs-doctag"><span class="hljs-comment"><span class="hljs-doctag">@return</span></span></span><span class="hljs-comment"> 当前时间(毫秒)
*/</span></span>
<span class="hljs-function"><span class="hljs-keyword"><span class="hljs-function"><span class="hljs-keyword">protected</span></span></span><span class="hljs-function"> </span><span class="hljs-keyword"><span class="hljs-function"><span class="hljs-keyword">long</span></span></span><span class="hljs-function"> </span><span class="hljs-title"><span class="hljs-function"><span class="hljs-title">timeGen</span></span></span><span class="hljs-params"><span class="hljs-function"><span class="hljs-params">()</span></span></span><span class="hljs-function"> </span></span>{
<span class="hljs-keyword"><span class="hljs-keyword">return</span></span> System.currentTimeMillis();
}
<span class="hljs-comment"><span class="hljs-comment">/**
* 阻塞到下一个毫秒,直到获得新的时间戳
* </span><span class="hljs-doctag"><span class="hljs-comment"><span class="hljs-doctag">@param</span></span></span><span class="hljs-comment"> lastTimestamp 上次生成ID的时间截
* </span><span class="hljs-doctag"><span class="hljs-comment"><span class="hljs-doctag">@return</span></span></span><span class="hljs-comment"> 当前时间戳
*/</span></span>
<span class="hljs-function"><span class="hljs-keyword"><span class="hljs-function"><span class="hljs-keyword">protected</span></span></span><span class="hljs-function"> </span><span class="hljs-keyword"><span class="hljs-function"><span class="hljs-keyword">long</span></span></span><span class="hljs-function"> </span><span class="hljs-title"><span class="hljs-function"><span class="hljs-title">nextMillis</span></span></span><span class="hljs-params"><span class="hljs-function"><span class="hljs-params">(</span></span><span class="hljs-keyword"><span class="hljs-function"><span class="hljs-params"><span class="hljs-keyword">long</span></span></span></span><span class="hljs-function"><span class="hljs-params"> lastTimestamp)</span></span></span><span class="hljs-function"> </span></span>{
<span class="hljs-keyword"><span class="hljs-keyword">long</span></span> timestamp = timeGen();
<span class="hljs-keyword"><span class="hljs-keyword">while</span></span> (timestamp <= lastTimestamp) {
timestamp = lastTimestamp;
}
<span class="hljs-keyword"><span class="hljs-keyword">return</span></span> timestamp;
}
}
6. 美团Leaf
Leaf 是美团开源的分布式ID生成器,能保证全局唯一性、趋势递增、单调递增、信息安全,里面也提到了几种分布式方案的对比,但也需要依赖关系数据库、Zookeeper等中间件。官网链接:https://tech.meituan.com/2017/04/21/mt-leaf.html
</div>
</div>
<div class="ui hidden divider"></div>
<p style="text-align:center;">
© 著作权归作者所有
</p>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号