使用雪花算法为分布式下全局ID、订单号等简单解决方案考虑到时钟回拨
1.snowflake简介
互联网快速发展的今天,分布式应用系统已经见怪不怪,在分布式系统中,我们需要各种各样的ID,既然是ID那么必然是要保证全局唯一,除此之外,不同当业务还需要不同的特性,比如像并发巨大的业务要求ID生成效率高,吞吐大;比如某些银行类业务,需要按每日日期制定交易流水号;又比如我们希望用户的ID是随机的,无序的,纯数字的,且位数长度是小于10位的。等等,不同的业务场景需要的ID特性各不一样,于是,衍生了各种ID生成器,但大多数利用数据库控制ID的生成,性能受数据库并发能力限制,那么有没有一款不需要依赖任何中间件(如数据库,分布式缓存服务等)的ID生成器呢?本着取之于开源,用之于开源的原则,今天,特此介绍Twitter开源的一款分布式自增ID算法snowflake,并附上算法原理推导和演算过程!
snowflake算法是一款本地生成的(ID生成过程不依赖任何中间件,无网络通信),保证ID全局唯一,并且ID总体有序递增,性能每秒生成300w+。
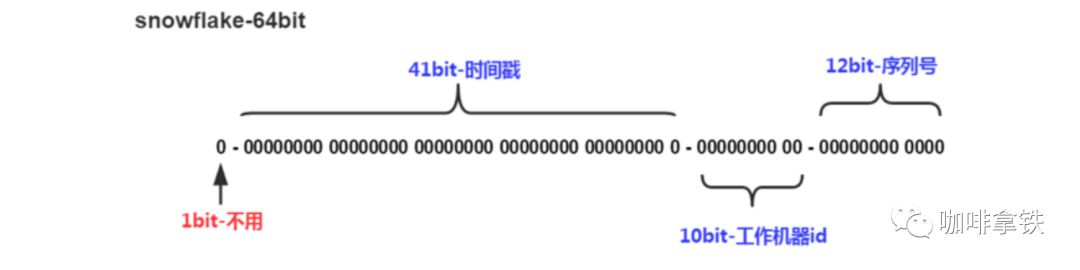
-
1bit:一般是符号位,不做处理
-
41bit:用来记录时间戳,这里可以记录69年,如果设置好起始时间比如今年是2018年,那么可以用到2089年,到时候怎么办?要是这个系统能用69年,我相信这个系统早都重构了好多次了。
-
10bit:10bit用来记录机器ID,总共可以记录1024台机器,一般用前5位代表数据中心ID,后面5位是某个数据中心的机器ID
-
12bit:循环位,用来对同一个毫秒之内产生不同的ID,12位可以最多记录4095个,也就是在同一个机器同一毫秒最多记录4095个,多余的需要进行等待下毫秒。
总体来说,在工作节点达到1024顶配的场景下,SnowFlake算法在同一毫秒内最多可以生成多少个全局唯一ID呢?这是一个简单的乘法:
同一毫秒的ID数量 = 1024 X 4096 = 4194304
400多万个ID,这个数字在绝大多数并发场景下都是够用的。
snowflake 算法中,第三个部分是工作机器ID,可以结合上一节的命名方法,并通过Zookeeper管理workId,免去手动频繁修改集群节点,去配置机器ID的麻烦。
上面只是一个将64bit划分的标准,当然也不一定这么做,可以根据不同业务的具体场景来划分,比如下面给出一个业务场景:
-
服务目前QPS10万,预计几年之内会发展到百万。
-
当前机器三地部署,上海,北京,深圳都有。
-
当前机器10台左右,预计未来会增加至百台。
这个时候我们根据上面的场景可以再次合理的划分62bit,QPS几年之内会发展到百万,那么每毫秒就是千级的请求,目前10台机器那么每台机器承担百级的请求,为了保证扩展,后面的循环位可以限制到1024,也就是2^10,那么循环位10位就足够了。
机器三地部署我们可以用3bit总共8来表示机房位置,当前的机器10台,为了保证扩展到百台那么可以用7bit 128来表示,时间位依然是41bit,那么还剩下64-10-3-7-41-1 = 2bit,还剩下2bit可以用来进行扩展。

适用场景:当我们需要无序不能被猜测的ID,并且需要一定高性能,且需要long型,那么就可以使用我们雪花算法。比如常见的订单ID,用雪花算法别人就发猜测你每天的订单量是多少。
上面定义了雪花算法的实现,在nextId中是我们生成雪花算法的关键。
2.防止时钟回拨
因为机器的原因会发生时间回拨,我们的雪花算法是强依赖我们的时间的,如果时间发生回拨,有可能会生成重复的ID,在我们上面的nextId中我们用当前时间和上一次的时间进行判断,如果当前时间小于上一次的时间那么肯定是发生了回拨,普通的算法会直接抛出异常,这里我们可以对其进行优化,一般分为两个情况:
-
如果时间回拨时间较短,比如配置5ms以内,那么可以直接等待一定的时间,让机器的时间追上来。
-
如果时间的回拨时间较长,我们不能接受这么长的阻塞等待,那么又有两个策略:
-
直接拒绝,抛出异常,打日志,通知RD时钟回滚。
-
利用扩展位,上面我们讨论过不同业务场景位数可能用不到那么多,那么我们可以把扩展位数利用起来了,比如当这个时间回拨比较长的时候,我们可以不需要等待,直接在扩展位加1。2位的扩展位允许我们有3次大的时钟回拨,一般来说就够了,如果其超过三次我们还是选择抛出异常,打日志。
通过上面的几种策略可以比较的防护我们的时钟回拨,防止出现回拨之后大量的异常出现。下面是修改之后的代码,这里修改了时钟回拨的逻辑:
最终代码如下:
-
- import org.apache.commons.lang3.RandomUtils;
- import org.apache.commons.lang3.StringUtils;
- import org.slf4j.Logger;
- import org.slf4j.LoggerFactory;
-
- import java.lang.management.ManagementFactory;
- import java.net.InetAddress;
- import java.net.NetworkInterface;
- import java.net.UnknownHostException;
- import java.text.SimpleDateFormat;
- import java.util.*;
- import java.util.concurrent.ConcurrentHashMap;
- import java.util.concurrent.CountDownLatch;
- import java.util.concurrent.TimeUnit;
- import java.util.concurrent.locks.LockSupport;
-
-
- /**
- * 分布式全局ID雪花算法解决方案
- *
- * 防止时钟回拨
- * 因为机器的原因会发生时间回拨,我们的雪花算法是强依赖我们的时间的,如果时间发生回拨,
- * 有可能会生成重复的ID,在我们上面的nextId中我们用当前时间和上一次的时间进行判断,
- * 如果当前时间小于上一次的时间那么肯定是发生了回拨,
- * 普通的算法会直接抛出异常,这里我们可以对其进行优化,一般分为两个情况:
- * 如果时间回拨时间较短,比如配置5ms以内,那么可以直接等待一定的时间,让机器的时间追上来。
- * 如果时间的回拨时间较长,我们不能接受这么长的阻塞等待,那么又有两个策略:
- * 直接拒绝,抛出异常,打日志,通知RD时钟回滚。
- * 利用扩展位,上面我们讨论过不同业务场景位数可能用不到那么多,那么我们可以把扩展位数利用起来了,
- * 比如当这个时间回拨比较长的时候,我们可以不需要等待,直接在扩展位加1。
- * 2位的扩展位允许我们有3次大的时钟回拨,一般来说就够了,如果其超过三次我们还是选择抛出异常,打日志。
- * 通过上面的几种策略可以比较的防护我们的时钟回拨,防止出现回拨之后大量的异常出现。下面是修改之后的代码,这里修改了时钟回拨的逻辑:
- */
- public class SnowflakeIdFactory {
-
- private static final Logger log = LoggerFactory.getLogger(SnowflakeIdFactory.class);
-
- /**
- * EPOCH是服务器第一次上线时间点, 设置后不允许修改
- * 2018/9/29日,从此时开始计算,可以用到2089年
- */
- private static long EPOCH = 1538211907857L;
-
- /**
- * 每台workerId服务器有3个备份workerId, 备份workerId数量越多, 可靠性越高, 但是可部署的sequence ID服务越少
- */
- private static final long BACKUP_COUNT = 3;
-
- /**
- * worker id 的bit数,最多支持8192个节点
- */
- private static final long workerIdBits = 5L;
- /**
- * 数据中心标识位数
- */
- private static final long dataCenterIdBits = 5L;
- /**
- * 序列号,支持单节点最高每毫秒的最大ID数4096
- * 毫秒内自增位
- */
- private static final long sequenceBits = 12L;
-
- /**
- * 机器ID偏左移12位
- */
- private static final long workerIdShift = sequenceBits;
-
- /**
- * 数据中心ID左移17位(12+5)
- */
- private static final long dataCenterIdShift = sequenceBits + workerIdBits;
-
- /**
- * 时间毫秒左移22位(5+5+12)
- */
- private static final long timestampLeftShift = sequenceBits + workerIdBits + dataCenterIdBits;
- /**
- * sequence掩码,确保sequnce不会超出上限
- * 最大的序列号,4096
- * -1 的补码(二进制全1)右移12位, 然后取反
- * 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095)
- */
- private static final long sequenceMask = -1L ^ (-1L << sequenceBits);
-
- //private final static long sequenceMask = ~(-1L << sequenceBits);
- /**
- * 实际的最大workerId的值 结果是31,8091
- * workerId原则上上限为1024, 但是需要为每台sequence服务预留BACKUP_AMOUNT个workerId,
- * (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数)
- */
- //private static final long maxWorkerId = (1L << workerIdBits) / (BACKUP_COUNT + 1);
-
- //原来代码 -1 的补码(二进制全1)右移13位, 然后取反
- private static final long maxWorkerId = -1L ^ (-1L << workerIdBits);
- //private final static long maxWorkerId = ~(-1L << workerIdBits);
-
- /**
- * 支持的最大数据标识id,结果是31
- */
- private static final long maxDataCenterId = -1L ^ (-1L << dataCenterIdBits);
- /**
- * long workerIdBits = 5L;
- * -1L 的二进制: 1111111111111111111111111111111111111111111111111111111111111111
- * -1L<<workerIdBits = -32 ,二进制: 1111111111111111111111111111111111111111111111111111111111100000
- * workerMask= -1L ^ -32 = 31, 二进制: 11111
- */
- private static long workerMask= -1L ^ (-1L << workerIdBits);
- //进程编码
- private long processId = 1L;
- private static long processMask=-1L ^ (-1L << dataCenterIdBits);
-
-
- /**
- * 工作机器ID(0~31)
- * snowflake算法给workerId预留了10位,即workId的取值范围为[0, 1023],
- * 事实上实际生产环境不大可能需要部署1024个分布式ID服务,
- * 所以:将workerId取值范围缩小为[0, 511],[512, 1023]
- * 这个范围的workerId当做备用workerId。workId为0的备用workerId是512,
- * workId为1的备用workerId是513,以此类推
- */
- private static long workerId;
-
- /**
- * 数据中心ID(0~31)
- */
- private long dataCenterId;
-
- /**
- * 当前毫秒生成的序列
- */
- private long sequence = 0L;
-
- /**
- * 上次生成ID的时间戳
- */
- private long lastTimestamp = -1L;
-
- private long extension = 0L;
- private long maxExtension = 0L;
-
- /**
- * 保留workerId和lastTimestamp, 以及备用workerId和其对应的lastTimestamp
- */
- private static Map<Long, Long> workerIdLastTimeMap = new ConcurrentHashMap<>();
-
- /**
- * 最大容忍时间, 单位毫秒, 即如果时钟只是回拨了该变量指定的时间, 那么等待相应的时间即可;
- * 考虑到sequence服务的高性能, 这个值不易过大
- */
- private static final long MAX_BACKWARD_MS = 3;
- private static SnowflakeIdFactory idWorker;
-
- static {
- idWorker = new SnowflakeIdFactory();
- }
-
-
-
- static {
- Calendar calendar = Calendar.getInstance();
- calendar.set(2018, Calendar.NOVEMBER, 1);
- calendar.set(Calendar.HOUR_OF_DAY, 0);
- calendar.set(Calendar.MINUTE, 0);
- calendar.set(Calendar.SECOND, 0);
- calendar.set(Calendar.MILLISECOND, 0);
- // EPOCH是服务器第一次上线时间点, 设置后不允许修改
- EPOCH = calendar.getTimeInMillis();
-
- // 初始化workerId和其所有备份workerId与lastTimestamp
- // 假设workerId为0且BACKUP_AMOUNT为4, 那么map的值为: {0:0L, 256:0L, 512:0L, 768:0L}
- // 假设workerId为2且BACKUP_AMOUNT为4, 那么map的值为: {2:0L, 258:0L, 514:0L, 770:0L}
- /* for (int i = 0; i<= BACKUP_COUNT; i++){
- workerIdLastTimeMap.put(workerId + (i * maxWorkerId), 0L);
- }*/
- }
-
- //成员类,IdGenUtils的实例对象的保存域
- private static class SnowflakeIdGenHolder {
- private static final SnowflakeIdFactory instance = new SnowflakeIdFactory();
- }
- //外部调用获取IdGenUtils的实例对象,确保不可变
- public static SnowflakeIdFactory getInstance(){
- return SnowflakeIdGenHolder.instance;
- }
-
- /**
- * 静态工具类
- *
- * @return
- */
- public static Long generateId(){
- long id = idWorker.nextId();
- return id;
- }
-
- //初始化构造,无参构造有参函数,默认节点都是0
- public SnowflakeIdFactory(){
- //this(0L, 0L);
- this.dataCenterId = getDataCenterId(maxDataCenterId);
- //获取机器编码
- this.workerId = getWorkerId(dataCenterId, maxWorkerId);
- }
-
- /**
- * 构造函数
- * @param workerId 工作ID (0~31)
- * @param dataCenterId 数据中心ID (0~31)
- */
- public SnowflakeIdFactory(long workerId, long dataCenterId) {
- if (workerId > maxWorkerId || workerId < 0) {
- throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
- }
- if (dataCenterId > maxDataCenterId || dataCenterId < 0) {
- throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDataCenterId));
- }
- this.workerId = workerId;
- this.dataCenterId = dataCenterId;
- }
-
- /**
- * 获取带自定义前缀的全局唯一编码
- */
- public String getStrCodingByPrefix(String prefix){
- Long ele = this.nextId();
- return prefix + ele.toString();
- }
-
- /**
- * 获得下一个ID (该方法是线程安全的)
- * 在单节点上获得下一个ID,使用Synchronized控制并发,而非CAS的方式,
- * 是因为CAS不适合并发量非常高的场景。
- *
- * 考虑时钟回拨
- * 缺陷: 如果连续两次时钟回拨, 可能还是会有问题, 但是这种概率极低极低
- * @return
- */
- public synchronized long nextId() {
- long currentTimestamp = timeGen();
- // 当发生时钟回拨时
- if (currentTimestamp < lastTimestamp){
- // 如果时钟回拨在可接受范围内, 等待即可
- long offset = lastTimestamp - currentTimestamp;
- if ( offset <= MAX_BACKWARD_MS){
- try {
- //睡(lastTimestamp - currentTimestamp)ms让其追上
- LockSupport.parkNanos(TimeUnit.MILLISECONDS.toNanos(offset));
- //时间偏差大小小于5ms,则等待两倍时间
- //wait(offset << 1);
- //Thread.sleep(waitTimestamp);
-
- currentTimestamp = timeGen();
- //如果时间还小于当前时间,那么利用扩展字段加1
- //或者是采用抛异常并上报
- if (currentTimestamp < lastTimestamp) {
- //扩展字段
- //extension += 1;
- //if (extension > maxExtension) {
- //服务器时钟被调整了,ID生成器停止服务.
- throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - currentTimestamp));
- //}
- }
- } catch (Exception e) {
- e.printStackTrace();
- }
- }else {
- //扩展字段
- /*extension += 1;
- if (extension > maxExtension) {
- //服务器时钟被调整了,ID生成器停止服务.
- throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - currentTimestamp));
- }*/
- tryGenerateKeyOnBackup(currentTimestamp);
- }
- }
- //对时钟回拨简单处理
- /* if (currentTimestamp < lastTimestamp) {
- //服务器时钟被调整了,ID生成器停止服务.
- throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - currentTimestamp));
- }*/
-
- // 如果和最后一次请求处于同一毫秒, 那么sequence+1
- if (lastTimestamp == currentTimestamp) {
- // 如果当前生成id的时间还是上次的时间,那么对sequence序列号进行+1
- sequence = (sequence + 1) & sequenceMask;
- if (sequence == 0) {
- //自旋等待到下一毫秒
- currentTimestamp = waitUntilNextTime(lastTimestamp);
- }
- //判断是否溢出,也就是每毫秒内超过4095,当为4096时,与sequenceMask相与,sequence就等于0
- /*if (sequence == sequenceMask) {
- // 当前毫秒生成的序列数已经大于最大值,那么阻塞到下一个毫秒再获取新的时间戳
- currentTimestamp = this.waitUntilNextTime(lastTimestamp);
- }*/
-
- } else {
- // 如果是一个更近的时间戳, 那么sequence归零
- sequence = 0L;
- }
- // 更新上次生成id的时间戳
- lastTimestamp = currentTimestamp;
-
- // 更新map中保存的workerId对应的lastTimestamp
- //workerIdLastTimeMap.put(this.workerId, lastTimestamp);
-
- if (log.isDebugEnabled()) {
- log.debug("{}-{}-{}", new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS").format(new Date(lastTimestamp)), workerId, sequence);
- }
-
- // 进行移位操作生成int64的唯一ID
- //时间戳右移动23位
- long timestamp = (currentTimestamp - EPOCH) << timestampLeftShift;
-
- //workerId 右移动10位
- long workerId = this.workerId << workerIdShift;
-
- //dataCenterId 右移动(sequenceBits + workerIdBits = 17位)
- long dataCenterId = this.dataCenterId << dataCenterIdShift;
- return timestamp | dataCenterId | workerId | sequence;
- }
-
- /**
- * 尝试在workerId的备份workerId上生成
- * 核心优化代码在方法tryGenerateKeyOnBackup()中,BACKUP_COUNT即备份workerId数越多,
- * sequence服务避免时钟回拨影响的能力越强,但是可部署的sequence服务越少,
- * 设置BACKUP_COUNT为3,最多可以部署1024/(3+1)即256个sequence服务,完全够用,
- * 抗时钟回拨影响的能力也得到非常大的保障。
- * @param currentMillis 当前时间
- */
- private long tryGenerateKeyOnBackup(long currentMillis){
- // 遍历所有workerId(包括备用workerId, 查看哪些workerId可用)
- for (Map.Entry<Long, Long> entry:workerIdLastTimeMap.entrySet()){
- this.workerId = entry.getKey();
- // 取得备用workerId的lastTime
- Long tempLastTime = entry.getValue();
- lastTimestamp = tempLastTime==null?0L:tempLastTime;
-
- // 如果找到了合适的workerId
- if (lastTimestamp<=currentMillis){
- return lastTimestamp;
- }
- }
-
- // 如果所有workerId以及备用workerId都处于时钟回拨, 那么抛出异常
- throw new IllegalStateException("Clock is moving backwards, current time is "
- +currentMillis+" milliseconds, workerId map = " + workerIdLastTimeMap);
- }
-
- /**
- * 阻塞到下一个毫秒,直到获得新的时间戳
- * @param lastTimestamp 上次生成ID的时间截
- * @return 当前时间戳
- */
- protected long waitUntilNextTime(long lastTimestamp) {
- long timestamp = timeGen();
- while (timestamp <= lastTimestamp) {
- timestamp = timeGen();
- }
- return timestamp;
- }
-
- protected long timeGen() {
- return System.currentTimeMillis();
- }
-
- /**
- * 获取WorkerId
- * @param dataCenterId
- * @param maxWorkerId
- * @return
- */
- protected static long getWorkerId(long dataCenterId, long maxWorkerId) {
- StringBuffer mpid = new StringBuffer();
- mpid.append(dataCenterId);
- String name = ManagementFactory.getRuntimeMXBean().getName();
- if (!name.isEmpty()) {
- // GET jvmPid
- mpid.append(name.split("@")[0]);
- }
- // MAC + PID 的 hashcode 获取16个低位
- return (mpid.toString().hashCode() & 0xffff) % (maxWorkerId + 1);
- }
-
- /**
- * 获取机器编码 用来做数据ID
- * 数据标识id部分 通常不建议采用下面的MAC地址方式,
- * 因为用户通过破解很容易拿到MAC进行破坏
- */
- protected static long getDataCenterId(long tempMaxDataCenterId) {
- if (tempMaxDataCenterId < 0L || tempMaxDataCenterId > maxDataCenterId) {
- tempMaxDataCenterId = maxDataCenterId;
- }
- long id = 0L;
- try {
- InetAddress ip = InetAddress.getLocalHost();
- NetworkInterface network = NetworkInterface.getByInetAddress(ip);
- if (network == null) {
- id = 1L;
- } else {
- byte[] mac = network.getHardwareAddress();
- id = ((0x000000FF & (long) mac[mac.length - 1])
- | (0x0000FF00 & (((long) mac[mac.length - 2]) << 8))) >> 6;
- id = id % (tempMaxDataCenterId + 1);
- }
- } catch (Exception e) {
- System.out.println(" getDatacenterId: " + e.getMessage());
- }
- return id;
- }
-
-
- public static void testProductIdByMoreThread(int dataCenterId, int workerId, int n) throws InterruptedException {
- List<Thread> tlist = new ArrayList<>();
- Set<Long> setAll = new HashSet<>();
- CountDownLatch cdLatch = new CountDownLatch(10);
- long start = System.currentTimeMillis();
- int threadNo = dataCenterId;
- Map<String,SnowflakeIdFactory> idFactories = new HashMap<>();
- for(int i=0;i<10;i++){
- //用线程名称做map key.
- idFactories.put("snowflake"+i,new SnowflakeIdFactory(workerId, threadNo++));
- }
- for(int i=0;i<10;i++){
- Thread temp =new Thread(new Runnable() {
- @Override
- public void run() {
- Set<Long> setId = new HashSet<>();
- SnowflakeIdFactory idWorker = idFactories.get(Thread.currentThread().getName());
- for(int j=0;j<n;j++){
- setId.add(idWorker.nextId());
- }
- synchronized (setAll){
- setAll.addAll(setId);
- log.info("{}生产了{}个id,并成功加入到setAll中.",Thread.currentThread().getName(),n);
- }
- cdLatch.countDown();
- }
- },"snowflake"+i);
- tlist.add(temp);
- }
- for(int j=0;j<10;j++){
- tlist.get(j).start();
- }
- cdLatch.await();
-
- long end1 = System.currentTimeMillis() - start;
-
- log.info("共耗时:{}毫秒,预期应该生产{}个id, 实际合并总计生成ID个数:{}",end1,10*n,setAll.size());
-
- }
-
- public static void testProductId(int dataCenterId, int workerId, int n){
- SnowflakeIdFactory idWorker = new SnowflakeIdFactory(workerId, dataCenterId);
- SnowflakeIdFactory idWorker2 = new SnowflakeIdFactory(workerId+1, dataCenterId);
- Set<Long> setOne = new HashSet<>();
- Set<Long> setTow = new HashSet<>();
- long start = System.currentTimeMillis();
- for (int i = 0; i < n; i++) {
- setOne.add(idWorker.nextId());//加入set
- }
- long end1 = System.currentTimeMillis() - start;
- log.info("第一批ID预计生成{}个,实际生成{}个<<<<*>>>>共耗时:{}",n,setOne.size(),end1);
-
- for (int i = 0; i < n; i++) {
- setTow.add(idWorker2.nextId());//加入set
- }
- long end2 = System.currentTimeMillis() - start;
- log.info("第二批ID预计生成{}个,实际生成{}个<<<<*>>>>共耗时:{}",n,setTow.size(),end2);
-
- setOne.addAll(setTow);
- log.info("合并总计生成ID个数:{}",setOne.size());
-
- }
-
- public static void testPerSecondProductIdNums(){
- SnowflakeIdFactory idWorker = new SnowflakeIdFactory(1, 2);
- long start = System.currentTimeMillis();
- int count = 0;
- for (int i = 0; System.currentTimeMillis()-start<1000; i++,count=i) {
- /** 测试方法一: 此用法纯粹的生产ID,每秒生产ID个数为300w+ */
- idWorker.nextId();
- /** 测试方法二: 在log中打印,同时获取ID,此用法生产ID的能力受限于log.error()的吞吐能力.
- * 每秒徘徊在10万左右. */
- //log.error("{}",idWorker.nextId());
- }
- long end = System.currentTimeMillis()-start;
- System.out.println(end);
- System.out.println(count);
- }
-
- public static void main(String[] args) {
- /** case1: 测试每秒生产id个数?
- * 结论: 每秒生产id个数300w+ */
- testPerSecondProductIdNums();
-
- /** case2: 单线程-测试多个生产者同时生产N个id,验证id是否有重复?
- * 结论: 验证通过,没有重复. */
- //testProductId(1,2,10000);//验证通过!
- //testProductId(1,2,20000);//验证通过!
-
- /** case3: 多线程-测试多个生产者同时生产N个id, 全部id在全局范围内是否会重复?
- * 结论: 验证通过,没有重复. */
- /* try {
- testProductIdByMoreThread(1,2,100000);//单机测试此场景,性能损失至少折半!
- } catch (InterruptedException e) {
- e.printStackTrace();
- }*/
-
- }
- }
本文链接:https://blog.csdn.net/ycb1689/article/details/89331634

 浙公网安备 33010602011771号
浙公网安备 33010602011771号