
Neo4j基础入门
图数据库基础知识
图数据库以图这种数据结构为基础,可以保存任意种类的数据,以下图为基础,简单介绍Neo4j中的几个简单概念:
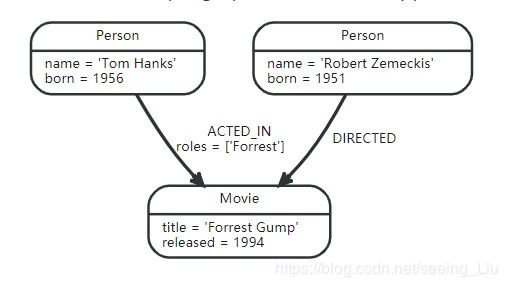
1.节点(Nodes)
表示图数据库的实体(entities),代表图数据库中的数据记录。上图中的圆角矩形即代表图数据库中的一个节点。
2.关系(Relationships)
描述节点之间的关系,关系总是有方向并且有一个类型的,一个节点也可以和自己有关系。上图中的箭头便代表关系,ACTED_IN和DIRECTED表示关系的类型。
3.属性(Properties)
用来保存数据,表示方法为name/value对,属性值可以有多种数据类型,比如数字、字符串和布尔值。节点和关系都可以有自己的属性,比如name='Tom Hanks’是一个节点的属性,roles=[‘Forrest’]是一个关系的属性。
4.标签(Labels)
用来关联一系列相关的节点,表示一组相关节点的域,没有属性。比如表示人的节点可以使用标签:Person,表示关系的类型为出演也使用标签:ACTED_IN。在执行图数据库操作时可以在限定的标签域上进行。
5.模式(Schema)
Neo4j中的模式指的是索引(indexes)和约束(constraints)。不过Neo4j中的模式是可选的,即创建索引和约束不是必须的。索引可以提高性能,约束可以确保数据遵守领域规则。
6.Neo4j命名规则
Neo4j官方给出了推荐的命名规则,注意Neo4j中的命名是大小写敏感的:
- 节点标签(Node label):推荐首字母大写的驼峰命名,如VehicleOwner
- 关系类型(Relationshio type):大写字母结合下划线,如OWNS_VEHICLE
- 属性(Property):首字母小写的驼峰命名,如firstName
Neo4j Browser
Neo4j Browser是一个命令驱动的客户机,适合运行即时的图查询语句。下载Neo4j Desktop之后,启动工程后,在浏览器输入http://localhost:7474/browser/ 便可以使用。在Neo4j Browser中:
- 开发人员只需要注重使用Cypher编写和运行图查询语句
- 任何查询结果可以导出为表格
- 查询结果可以使用包含节点和关系的可视化图形展示
- Cypher语句编辑框在浏览器上部,起始符为$。若想多行输入,以< shift+enter > 换行,使用< ctrl+enter >运行查询。
Neo4j Browser中也有指导教程,在编辑框输入:play start便可以开始探索Neo4j Browser了。
Neo4j基础语法
1.节点语法(Node Syntax)
Neo4j中使用
()代表一个节点
() # 一个匿名无特征地节点
(matrix) # 拥有变量名matrix的节点,其他地方可以通过变量名使用
(:Movie) # 声明节点标签为Movie,限制了匹配的模式
(matrix:Movie) # 既赋变量名又声明标签的节点
# {}表示节点属性,用来存储信息或限制模式
(matrix:Movie{title:"the matrix"})
(matrix:Movie{title:"the matrix",released:1997})
2.关系语法(Relationship Syntax)
Neo4j中使用一对虚线
--表示无向关系,有向关系在尾部会有箭头,比如<--和-->。中括号表达式[...]用来为关系添加详细信息,比如变量名、类型和属性。
-->
-[role]-> #定义关系的变量名为role,其他地方可以使用
-[:ACTED_IN]-> # 定义关系的类型为ACTED_IN
-[role:ACTED_IN]-> # 同时定义关系的变量名和类型
-[role:ACTED_IN {roles:["Neo"]}]-> # 定义关系的属性
3.模式语法(Pattern Syntax)
结合节点语法和关系语法可以表示模式。
# 以下是一个模式的实例
(keanu:Person {name:"Keanu Reeves"})
-[role:ACTED_IN {roles:["Neo"]}]->
(matrix:Movie {title:"The Matrix"})
# 表示指定姓名的人在指定电影中担当指定角色的模式
图数据库Neo4j的查询语言——Cypher
Cypher是一种声明式的查询语言,使用它可以描述需要查找的东西。
1.CREATE (create a node)
CREATE (ee:Person {name:"Emil",from:"Sweden"})
# CREATE从句可以用来生成数据
# CREATE ()表示生成一个node
# ee:Person表示变量ee和标签Person,ee可以指示此节点
# {}中的键值对是节点内的属性
CREATE (js:Person{name:"John",from:"Sweden"}),
(ir:Person{name:"Ian",from:"England"}),
(js)-[:KNOWS{since:2001}]->(ir)
# 若想同时生成多个数据需要使用','分隔
# ()-[]->()格式用来生成关系,()中写的是节点变量名,[]中的:后为关系的标签名,关系也可以使用{}生成关系的属性
2.MATCH (find nodes)
MATCH (ee:Person) WHERE ee.name="Emil" RETURN ee
# MATCH从句用来指定节点和关系的模式
# (ee:Person)表示标签为Person的节点,并将这类节点的变量命名为ee
# WHERE从句用来约束结果
# ee.name="Emil"比较了name属性值与"Emil"的相等关系
# RETURN从句用于返回特定的结果
# 比如上句的含义为返回所有属于Person的节点中name属性值为"Emil"的所有节点
MATCH (ee:Person)-[:KNOWS]->(friends) WHERE ee.name="Emil" RETURN ee,friends
# MATCH从句描述了从已知节点到待寻找节点的模式
# -[:KNOWS]->匹配了可以是任意方向的关系KNOWS
# 上句的含义是查找Emil的朋友(假设存在KNOWS关系即为朋友)
3.MERGE(complete patterns)
无论何时,我们从外部系统获取数据时,都无法确定某些信息是否在图中已经存在。这时可以使用MERGE语句,它的工作方式类似于MATCH和CREATE的结合。MERGE语句在增加数据时会首先检查数据是否存在,如果存在则进行匹配,否则便会创建新的数据。MERGE子句后可以显式指定ON CREATE或ON MATCH子句,通过MERGE子句可以指定图形中必须存在一个节点且必须具有特定的标签和属性等,如果不存在则会创建相应的节点。但是MERGE语句会增加执行时间,因为其需要首先检查存在性,所以在确定不会新增重复数据时,建议使用CREATE。
# 若我们不知道电影是否存在,且需要为它添加新属性,则可以使用MERGE
# 如果需要创建节点,则执行ON CREATE子句,更新节点数据
# 如果节点已存在,则执行ON MATCH子句,修改节点数据
MERGE (m:Movie {title:"Cloud Atlas"})
ON CREATE SET m.released=2012
ON MATCH SET n.counter = coalesce(n.counter,0)+1
RETURN m
# 在两个节点之间查找或新建一个关系
MATCH (a:Person {name:"Jack"}),(b:Person {name"Rose"})
MERGE (a)-[:LOVES]->(b)
# 如果只传入一个节点,MERGE会查找匹配该模式的另一节点或增加一个节点
CREATE (y:Year {year:2014})
MERGE (y)<-[:IN_YEAR]-(m10:Month {month:10})
MERGE (y)<-[:IN_YEAR]-(m11:Month {month:11})
RETURN y,m10,m11
4.PROFILE (use the visual query plan)
Neo4j Browser中使用PROFILE从句可以查看查询的具体流程计划。
PROFILE MATCH (ee:Person) WHERE ee.name="Emil" RETURN ee
# 运行这句话之后,在Neo4j浏览器中便可以看到该语句具体的执行流程
- 1
- 2
5.WHERE (filterin results)
如果想要过滤结果并返回我们感兴趣的数据,可以使用WHERE子句,WHERE子句中可以使用布尔表达式、谓词以及AND,OR,XOR,NOT的结合,WHERE子句也可以使用数值比较、正则匹配和存在性检查。
# 使用等号过滤
MATCH (m:Movie) WHERE m.ttle="The Matrix" RETURN m
# 上述语句等价于在模式中指定条件:
MATCH (m:Movie {title:"The Matrix"}) RETURN m
6.RETURN (return results)
RETURN子句可以返回任意数量的表达式,最简单的表达式可以是数字、字符串、数组(arrays)和映射(maps)。节点和关系的属性值都可以使用
.来获取,比如n.name。数组中的值或切片可以通过下标来索引,比如names[0]和movies[1..-1]。表达式也可以是一些函数,比如length(array),toInteger("12"),substring("2014-07-01",0,4)和coalesce(p.nickname,"n/a")。
# 默认表达式使用标签作为列名,可以使用expression AS alias对列名重命名
MATCH (p:Person)
RETURN p,p.name AS name,toUpper(p.name),coalesce(p.nickname,"n/a") AS nickname,
{name:p.name,label:head(labels(p))} AS person
# 若希望展示不重复的结果,可以在RETURN子句中使用DISTINCT关键字
MATCH (n) RETURN DISTINCT labels(n) AS labels
7.Aggregating Information
在Cypher中,信息聚合主要出现在RETURN子句中,支持许多常见的聚合函数,比如
count,sum,avg,min,max等。信息聚合的过程中会跳过NULL值,若只想聚合唯一信息,可以使用DISTINCT,比如count(DISTNICT role)。
# 统计数据库中的总人数
MATCH (:Person) RETURN count(*) AS people
# 统计演员和导演的合作次数
MATCH (actor:Person)-[:ACTED_IN]->(movie:Movie)<-[:DIRECTED]-(director:Person)
RETURN actor,director,count(*) AS collaborations
8.WITH
在Cypher中可以将语句片段链接在一起,在子查询语句中可以获得在
WITH中声明的列。WITH子句用于组合各个部分,并声明哪些数据从一个部分流向另一个部分。在WITH子句中要注意所有的列名都要重命名。
# 选择演过电影的演员,然后过滤只演过一部电影的演员
MATCH (person:Person)-[:ACTED_IN]->(m:Movie)
WITH person,count(*) AS appearances,collect(m.title) AS movies
WHERE appearances > 1
RETURN person.name, appearances,movies
9.LOAD CSV(import data)
# 使用LOAD CSV可以从外部导入CSV文件,支持FTP,HTTP等
LOAD CSV WITH HEADERS FROM "http://data.neo4j.com/northwind/products.csv" AS row
CREATE (n:Product)
SET n = row,
n.unitPrice = toFloat(row.unitPrice),
n.unitsInStock = toInteger(row.unitsInStock),
n.unitsOnOrder = toInteger(row.unitsOnOrder),
n.reorderLevel = toInteger(row.reorderLevel),
n.discontinued = (row.discontinued <> "0")
本文链接:https://blog.csdn.net/seeing_Liu/article/details/89040389Neo4j官方文档 :https://neo4j.com/docs/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号