
基于NEO4J的高级检索功能
一、需求
基于NEO4J实现类似万方的高级检索功能 万方链接
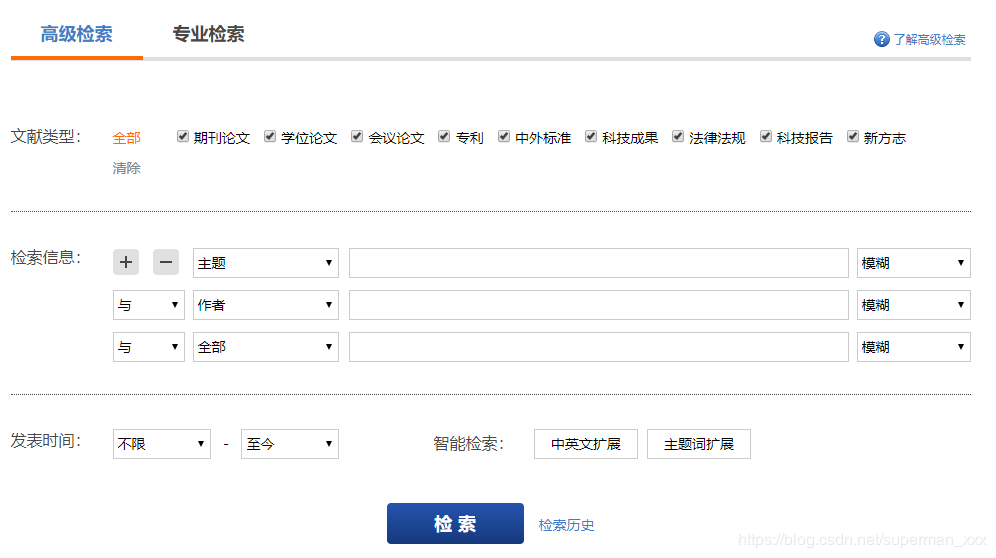
二、创建索引
1、索引自动更新配置
// neo4j.conf设置此项会影响性能 开启自动更新索引(测试时数值类型字段在全文检索时无法索引)
apoc.autoIndex.enabled=true
2、执行带有索引自动更新配置的过程
CALL apoc.index.addAllNodes('FacebookID', {FacebookID:["CurrentCity","PoliticalViews","Gender"]},{autoUpdate:true});
三、查询索引
1、LUCENE查询语法
1、基础的查询语法,关键词查询:
域名+“:”+搜索的关键字
例如:content:java
2、范围查询
域名+“:”+[最小值 TO 最大值]
例如:size:[1 TO 1000]
范围查询在lucene中支持数值类型,不支持字符串类型。在solr中支持字符串类型。
3、组合条件查询
1)+条件1 +条件2:两个条件之间是并且的关系and
例如:+filename:apache +content:apache
2)+条件1 条件2:必须满足第一个条件,应该满足第二个条件
例如:+filename:apache content:apache
3)条件1 条件2:两个条件满足其一即可。
例如:filename:apache content:apache
4)-条件1 条件2:必须不满足条件1,要满足条件2
例如:-filename:apache content:apache
4、组合条件查询
条件1 AND 条件2 / 条件1 OR 条件2 / 条件1 NOT 条件2
5、模糊搜索* 相似搜索~
6、表达式分组
表示必须为男性,且括号中条件必须满足一个
例: +(FacebookID.locality:BeiJing FacebookID.ReligiousViews:Methodist) +FacebookID.Gender:男
| Occur.MUST 查询条件必须满足,相当于and | +(加号) |
|---|---|
| Occur.SHOULD 查询条件可选,相当于or | 空(不用符号) |
| Occur.MUST_NOT 查询条件不能满足,相当于not非 | -(减号) |
2、实现高级检索的核心:LUCENE QUERY语句拼接
// 必须为男性,括号内属性任意一个满足或者不满足都可以
CALL apoc.index.search("nodesProperties", "(FacebookID.CurrentCity:香港 FacebookID.PoliticalViews:XX党) +FacebookID.Gender:男 ",20) YIELD node RETURN node
// 必须不是男性,括号内属性任意有一个满足即可
CALL apoc.index.search("nodesProperties", "+(FacebookID.CurrentCity:香港 FacebookID.PoliticalViews:XX党) -FacebookID.Gender:男 ",20) YIELD node RETURN node
// 可以是男性,括号内属性没有一个满足
CALL apoc.index.search("nodesProperties", "-(FacebookID.CurrentCity:香港 FacebookID.PoliticalViews:XX党) FacebookID.Gender:男 ",20) YIELD node RETURN node
四、总结
原文地址:https://blog.csdn.net/superman_xxx/article/details/893765411、多标签或者不指定标签检索,可以实现自定义过程将图库的属性字段直接建立索引而不指定标签,这样简化跨类型检索的查询。
2、为了支持中文分词全文索引,可以单独编写扩展插件以支持中文分词索引。这里是我实现的基于中文分词的全文索引过程(不包含索引自动更新)。NEO4J插件开发

 浙公网安备 33010602011771号
浙公网安备 33010602011771号