
主流图数据库Neo4J、ArangoDB、OrientDB综合对比:架构分析
1: 本地存储方式
2: 内置查询语言分析
3: 性能分析
4: 图算法支持
本地存储方式
Neo4J
neo4j数据库支持最大多少个节点?最大支持多少条边?
- 目前累积统计它有34.4亿个节点,344亿的关系,和6870亿条属性。
在数据库中,读/写性能跟节点/边的数量有关吗?
- 这个问题意味着两个不同的问题。单次读/写操作不依赖数据库的大小。不管数据库是有10个节点还是有1千万个都一样。 — 然而,有一个事实是如果数据库太大,你的内存可能无法完全缓存住它,因此,你需要频繁的读写磁盘。虽然很多用户没有这样大尺寸的数据库,但有的人却有。如果不巧你的数据库达到了这个尺寸,你可以扩展到多台机器上以减轻缓存压力。
是否有备份恢复机制?
- Neo4j 企业版提供了一个在线备份(完整备份和增量备份)功能。
写数据库是线程安全的吗?
- 不管在单服务模式还是HA模式,数据库在更新之前都通过锁定节点和关系来保证线程安全。
文件存储结构
node,relationship,property存储都是固定大小的。 如下图:
- 固定大小可以快速查找,基于此,可以直接计算一个节点的位置,时间复杂度$O(1)$,比查询的$O(log n)$快。
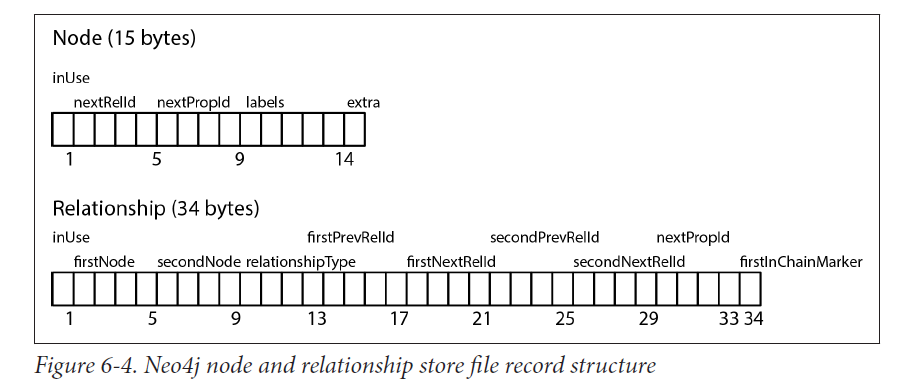
节点
存储文件neostore.nodestore.db,
- 第一个字节,是否被使用的Flag
- 下4个字节,代表第一个关系的ID,连接到这个节点上的 :ID
- 紧接着的4个字符,代表第一个属性ID,连接到这个节点上的
- 紧接着的5个字符是代表当前结点的Label,指向Label存储的。 :LABEL
- 最后一个字符是标志字符,用来标志紧密相邻的点,或者留备后用。 这就是Neo4J索引实现的方案。Index-Free Adjacency
这些指向的ID都是链式ID中的第一个,比如关系ID是关系链中的第一个。
关系
存储文件neostore.relationshipstore.db
- 1:同上
- 1-5:第一个节点
- 5-9:第二个节点
- 9-13:关系类型 :TYPE
- 13-21:前一个关系的前后节点 ID
- 21-29:后一个关系的前后节点 ID
- 29-33:属性ID
- 34:是都是关系链中的第一个的标志
关系是双向链表,属性是单向链表
属性文件
存储文件neostore.propertystore.db
- 每个属性文件包含4个属性块,一个指向下个属性的ID,在属性链中
- 属性包括属性类型,指向属性索引文件
neostore.propertystore.db.index的指针- 属性是键值对存储的,数据类型可以使用JVM的所有私有属性,加上字符串和数组类型;
- 属性值也可以使用动态存储,就是大文件,类型如下:字符串&数组
查找时文件调用模型

- 节点包含指向关系链和属性链的第一个指针。
- 指向Label的指针,可能多个。
- 属性读取从单向链表的第一个开始
- 关系读取直接在双向链表中查找,直到找到想要的关系。
Index-Free Adjacency
查询时,算法复杂度,$O(n)$,$n$是节点数,其他常规索引的复杂度都是$O(n log n)$
删除修改一个有很多很多边的节点时会有点麻烦,因为没有常规索引,只能从关系链中开始删除。
- 为了去除所有的事件边,你必须访问每个相邻的顶点,并且为每个相邻的顶点执行一个潜在的昂贵的移除操作。
ArangoDB
文档在ArangoDB中的存储格式非常类似JSON,叫做VelocyPack格式的二进制格式存储。
- 文档被组织在集合中。
- 有两种集合:文档(V),边集合(E)
- 边集合也是以文档形式存储,但包含两个特殊的属性
_from和_to,这两个属性被用来创建在文档和文档之间创建关系
存储空间占用下:采用了元数据模式存储数据
- 可通过内存提速,CPU占有率低。
索引
索引类型
-
Primary Index,默认索引,建立字段是_key或_id上,一个哈希索引 -
Edge Index,默认索引,建立在_from、_to上,哈希索引;不能用于范围查询、排序,弱于OrientDB -
Hash Index,自建 -
Skiplist Index,有序索引,- 用于快速查找具有特定属性值的文档,范围查询以及按索引排序顺序返回文档。
- 用于查找,范围查询和排序。补全范围查询的缺点。
Primary Index和Edge Index,是内存索引,文档加载速度很慢,推测是在重建索引。没有见到ArangoDB说有内存索引持久化。
-
Persistent Index,RocksDB的索引。- 持久性索引是具有持久性的排序索引。当存储或更新文档时,索引条目将写入磁盘。
- 使用持久性索引可能会减少集合加载时间。
-
Geo Index,用户可以在集合中的一个或多个属性上创建其他地理索引。地理索引用于快速找到地球表面的地方。 -
Fulltext Index,全文索引
Hash查询很快,几乎为$O(1)$。
Novel Hybrid Index
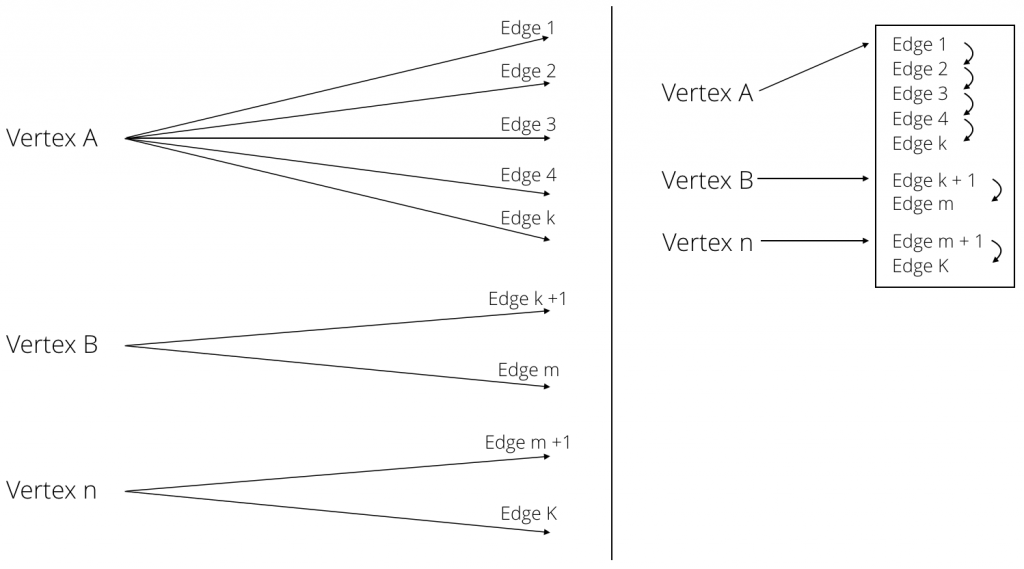
把所有的边都存储在一个大哈希表中,把每个顶点V都放到一个双链表中。
- 将节点放入链表中,遍历所有节点的复杂度时$O(k)$,k是节点总数。
- 节点邻接点是通过边集确定的,边集的起始点和结束点都是默认Hash索引的,所以查找一个节点的时间复杂度是$O(1)$。
- 遍历边的复杂度是$O(log E) + O(k)$,E是边的数量。
- 边的遍历是通过遍历节点开始的。
- 删除和修改边的时候,是通过节点的
key查找的,确认边是不是节点的链表中的第一个,不是就通过链表继续找。 - 边索引不仅是边集的索引,也是顶点的邻接点的索引。
存储引擎
在ArangoDB 3.0 这个版本,arangodb切换了自己的存储引擎,RocksDB。
Persistent indexes via RocksDB is the first step of ArangoDB to persist indexes in general.
在docker下这个版本的ArangoDB的接口没有做好,挂在存储卷时会导致RocksDB IO异常。
架构变动很频繁。3.2版本还会引入pregel框架。
- 数据库的Bug不但存在于本身还存在于其它引用的架构处。
OrientDB
索引类型
- SB-Tree Index:从其他索引类型中获得的特性的良好组合,默认索引
- Hash Index:
- Auto Sharding Index:提供一个DHT实现;不支持范围查询
- Lucene Spatial Index:持久化,支持事物,范围查询
在 Java中,如果哈希函数不合理,返回值过于集中,会导致大字典更慢。Java 由于存在链表和红黑树互换机制,搜索时间呈对数级增长,而非线性增长。在理想的哈希函数下,无论字典多大,搜索速度都是一样快。
SB-Tree Index
- UNIQUE:这些索引不允许重复的键。对于复合索引,这指的是组合键的惟一性。
- NOTUNIQUE:这些索引允许重复的键。
- FULLTEXT:这些索引是基于任何单个文本的。可以通过
CONTAINSTEXT操作符在查询中使用它们。 - DICTIONARY:这些索引类似于使用惟一的索引,但是在重复键的情况下,它们用新的记录替换现有的记录。
Lucene Engine
- FULLTEXT:这些索引使用Lucene引擎来索引字符串内容。可以在LUCENE操作符的查询中使用它们。
- SPATIAL:这些索引使用Lucene引擎来索引地理空间坐标。
SB索引
SB索引,B树上优化了数据插入和范围查询,时间复杂度$O(log(N))$,其底数大约500。
- 磁盘消耗大。
使用类似继承的方式去实现包含特殊属性的顶点集和边集。
OrientDB本地存储原则
OrientDB本地存储原则:使用包含由固定大小部分(页面)分割的磁盘数据并写入日志记录方法的磁盘缓存(当页面中的更改首先记录在所谓的持久存储器中时),我们可以实现以下特性:OrientDB 2.2.x——PLocal Engine
- Operations on single page are atomic.
- Changes applied to the page can be restored after server crash even if they were not flushed to the disk.
保护数据
集群实现就是通过Class的类似继承机制实现的分表。Clusters
内置查询语言分析
AQL
arangod与arangosh是用CPP写的。
- 网络/磁盘IO处理也是通过CPP写的
- AQL执行器:CPP
- AQL函数大部分是通过CPP写的,少部分是通过JS写的。
- AQL调用的用户函数全是JS函数
但,arangod与arangosh依赖V8 JS引擎
- 所有的JS命令行进入
arangosh都会被V8执行。 -
arangodJS孤岛,--javascript.v8-contexts,在多线程中用JS,但是JS本身还是单线程的。
类SQL语言,与ES6无缝连接,可以使用ES6语法。
- JS的引入功能类似存储过程,提供Foxx框架
- 以V8作为语句执行引擎,性能有问题,而且导致很多坑;
- V8和Neo4J与OrientDB的JVM相比差距有点大,执行的性能感觉和Node.JS差不错,适合事物密集型而不适合计算密集型的程序。
- 个人认为,
arangosh使用V8的目的是通过异步回掉调用本地cpp代码提供计算性能,而不是使用V8去直接计算,所以在用各图数据库实现图算法的时候如果使用JS去实现的话,性能会不是那么的友善,对于ArangoDB值得期待的就是pregel将会在3.2版本面世。
Cypher
语义清晰,Neo4J唯一支持的语言
OrientDB SQL
类SQL,语法和SQL基本类似,冗长。
性能分析
少量数据分析
省
亿级数据分析
ArangoDB
arangoimp插入效率感人,推测原因:
- 导入方式是边插入边建立索引的,可能性不高,因为同一数据集在多台主机上严重了其卡住的位置是不同的
- 其hash函数设置不好,导致不停的哈希冲突,hash索引是arangodb的默认索引,可能性也不高;
- 官网上有模糊的说明,arangodb的索引是存储在内存中的,官网特意说明
Persistent Index这个索引是存储在磁盘上的,其他索引是需要在文档加载时候重新建立索引的。
arangoimp在默认情况下到达1300万数据之后导入性能很差。
在都没有支持复杂图算法的情况下,十万级数据ArangoDB的图计算效率比较低,因为是单线程JS在V8上运行的。
arangodb对于边的插入不支持批量插入:
- 在
arangosh中已经验证,其只能一条边一条边的插入,后面的数据会被无视掉。
arangoimp上存在无效参数:
- 比如创建边集选项,无论是否选择是true,都不会创建,Github上官方解释必须在数据库中先创建边集才可以,也就是说这个命令中的创建边集的参数是一个无效参数。
Neo4J
neo4j-import导入数据很快。
root@ubuntu:/var/lib/neo4j/data/databases# neo4j-import --into njaq --nodes /home/dawn/csv/perosnInfo.csv --relationships /home/dawn/csv/know.csv --skip-bad-relationships true --skip-bad-entries-logging true --bad-tolerance true
WARNING: neo4j-import is deprecated and support for it will be removed in a future
version of Neo4j; please use neo4j-admin import instead.
Neo4j version: 3.2.1
Importing the contents of these files into njaq:
Nodes:
/home/dawn/csv/perosnInfo.csv
Relationships:
/home/dawn/csv/know.csv
Available resources:
Total machine memory: 3.84 GB
Free machine memory: 1.61 GB
Max heap memory : 875.00 MB
Processors: 4
Configured max memory: 700.35 MB
Nodes, started 2017-06-08 05:35:30.741+0000
[>:18.87 MB|NODE:152.59 MB----|PROPERTIES(3)============|LABEL SCAN--|v:37.14 MB/s-----------]20.0M ∆21.8K
Done in 51s 548ms
Prepare node index, started 2017-06-08 05:36:22.495+0000
[DETECT:419.62 MB----------------------------------------------------------------------------]20.0M ∆-6500000
Done in 9s 126ms
Relationships, started 2017-06-08 05:36:31.678+0000
[>:7|T|PREPARE(4)=========================================================|RE|CALCULATE-|P|v:]79.9M ∆10.9K
Done in 4m 17s 742ms
Relationship --> Relationship 1/1, started 2017-06-08 05:40:49.548+0000
[>-----------------------------------------------------------------------|LINK------------|v:]79.9M ∆ 405K
Done in 2m 5s 784ms
RelationshipGroup 1/1, started 2017-06-08 05:42:55.404+0000
[>:??----------------------------------------------------------------------------------------] 0 ∆ 0
Done in 11ms
Node --> Relationship, started 2017-06-08 05:42:55.439+0000
[>:13|>-------------------------------------------------|LIN|v:26.00 MB/s--------------------]19.9M ∆2.18M
Done in 11s 833ms
Relationship <-- Relationship 1/1, started 2017-06-08 05:43:07.308+0000
[>-------------------------------------------------------------------------------|LINK----|v:]79.9M ∆ 168K
Done in 11m 29s 787ms
Count groups, started 2017-06-08 05:54:37.570+0000
[>:??----------------------------------------------------------------------------------------] 0 ∆ 0
Done in 1ms
Gather, started 2017-06-08 05:54:38.061+0000
[>:??----------------------------------------------------------------------------------------] 0 ∆ 0
Done in 4ms
Write, started 2017-06-08 05:54:38.156+0000
[>:??----------------------------------------------------------------------------------------] 0 ∆ 0
Done in 15ms
Node --> Group, started 2017-06-08 05:54:38.213+0000
[>:??----------------------------------------------------------------------------------------] 0 ∆ 0
Done in
Node counts, started 2017-06-08 05:54:38.264+0000
[>(4)==============================|COU]20.0M ∆80.0K
Done in 1m 26s 338ms
Relationship counts, started 2017-06-08 05:56:04.625+0000
[*>(4)|COUNT----------------------------]80.0M ∆1.81M
Done in 2m 47s 277ms
IMPORT DONE in 23m 22s 420ms.
Imported:
20000000 nodes
79994052 relationships
80000000 properties
Peak memory usage: 899.62 MB
Neo4J使用导入方法之后会建立索引,否则基本没有性能,建立索引很快。
图算法支持
ArangoDB图算法支持
- AQL
- 遍历:从指定开始点,通过一定算法、边类型、图类型、深度获取与指定开始点相关连通的点。
- 数据源:图、边集合
- 边方向:出边、入边、全部
- 遍历方式:BFS Or DFS
- 最短路径:两点最短路径,选项基本和上面类型
- 遍历:从指定开始点,通过一定算法、边类型、图类型、深度获取与指定开始点相关连通的点。
- Pregel
-
@arangodb/pregel文件夹下,很多分布式的图算法 - PageRank
- CC 强弱连通算法
- 单源最短路径算法
-
JS扩展
- 通过JS可以完成对内置算法的扩展,但是自定义方法是单线程JS函数,如果用来做算法,性能堪忧,最佳选择就是选择内置的方法去实现图算法。
- 通过JS可以实现很多算法,但是在ArangoSH下代码单线程运作,虽然arangod的JS是在多线程中运行的,但是arangosh是在单线程中运行的,且JS本身并不擅长处理计算型代码,相比之下通过内置的数据库语言而不是这种内置语言与JS混杂方式的代码会快很多;比如Neo4J,OrientDB的查询语言。
Neo4J
对于普通的遍历最短路径算法支持和ArangoDB一样都支持,但Neo4J的图的遍历深度的阈值设置比较难,且深度超过6算法会效率比较低。
相比之下,ArangoDB的算法参数设置全部依赖于Key-Value实现,算法在编码层次灵活性很高。
对于PageRank,CC等算法的实现,Neo4J提供两种方式:
- 编写Jar包,GitHub上有个未被官方承认的Jar包
- Cypher直接实现
OrientDB
同上,图算法也支持Jar包导入。
内置图算法
最短路径
Cypher:
match (p1:person{no:'%s'}),(p2:person{no:'%s'}) match p=shortestPath((p1)-[*..3]->(p2)) return p
OrientDB SQL:
select dijkstra((select @RID from persons where no='%s'),(select @RID from persons where no='%s'),'E')
AQL:
for v,e in outbound shortest_path '%s' to '%s' graph 'graphPersons' return [v._key,e._key]
邻接点
Cypher:
MATCH (js:person)-[:know]-(surfer) WHERE js.no = '%s' return surfer
OrientDB SQL:
select from E where out = (select @RID from persons where no='%s
AQL:
traversal_results = graphPersons.traverse(
start_vertex='persons/'+getSingleInfo(id).no,
strategy='bfs',
direction='outbound',
edge_uniqueness='global',
vertex_uniqueness='global',
max_depth=1
)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号