常用的17个运维监控系统(必备知识)
1. Zabbix

Zabbix 作为企业级的网络监控工具,通过从服务器,虚拟机和网络设备收集的数据提供实时监控,自动发现,映射和可扩展等功能。
Zabbix的企业级监控软件为用户提供内置的Java应用服务器监控,硬件监控,VMware监控和CPU,内存,网络,磁盘空间性能监控。
该企业级网络监控工具能够每分钟进行 3,000,000 次检查,具有更高的安全性和数据中心监控功能。
2. Nagios
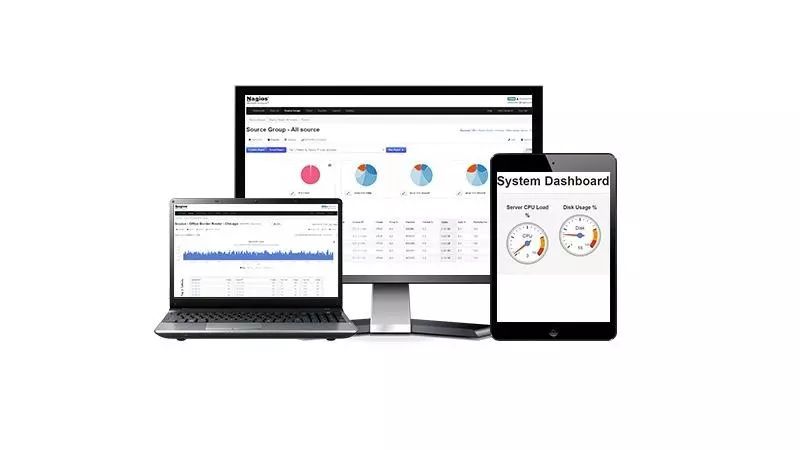
Nagios 是一款用于监控IT基础架构和查看当前状态、历史日志和基本报告的开源软件工具。 Nagios 用户可以监控系统指标,网络协议,应用程序,服务器,网络基础架构和接收故障警报。
Nagios提供三种类型的网络管理工具,Nagios XL,Nagios日志服务器和Nagios网络分析器。其中 Nagios XL 最适合网络监控(尽管其他两种也提供网络监控服务)。
Nagios XL提供企业级网络监控,为用户提供带宽报告,网络心跳监控,自定义URL,电子邮件报告和远程机器监控。 升级的企业版提供基于Web的服务器控制台访问,业务流程监控,记录审核和自动化删除功能。
3. Cacti

最初发布于2001年, Cacti 是一款开源的基于Web的网络监控和专为数据记录而设计的图形化工具。它可以用于实时显示网络数据,如CPU负载或带宽利用率。
Cacti是RRDtool的前端应用程序,RRDtool是一种用于存储实时变化数据的开源数据库工具,其使用SNMP作为其默认收集算法,但如果你喜欢本地Perl的PHP脚本,那么你也可以使用它们。
其最新版本0.8.8h于2016年5月发布,主要功能包括无限图形项目、图形自动填充支持、图形数据处理、自定义数据采集脚本、内置SNMP支持、图形模板、数据源模板、主机模板和基于用户的管理。
4. GroundWork Monitor Core

GroundWork Monitor Core 是监控网络、应用和云计算使用情况的平台。开源版本包含最多可监控50个设备和基于社区的支持的许可证,该软件还有其对应的商业版本。
在其网络管理功能方面,GroundWork提供网络和设备的自发现和维护、拓扑、报警控制、通过API/SNMP/IPMI的数据收集和对OpenDaylight SDN的支持等功能。
GroundWork还提供了存储管理,支持大规模的企业级供应商,如NetApp和EMC,以及从磁盘、块或对象存储的数据收集和存储缓冲以及中断可视化。
由于GroundWork的一站式网络管理方法,这种套件可能更适合那些寻找成熟品牌的大型商业和企业,而不是以开发人员为重点的工具,如Big Brother或Big Sister。
5. Hyperic

VMware的Hyperic工具用于在物理、虚拟或云环境下监控Web应用程序及其性能。 它适用于应用程序服务器,web服务器,数据库,操作系统,虚拟机管理程序,消息传递服务和目录服务器。
Hyperic提供基础架构和操作系统监控,详细的报告,应用程序和中间件监控,警报和修复工作流程以及通用可扩展的API。
该网络监控工具提供了企业版本,可以提高网络警报功能,并且能更好地创建基准。
6. Observium
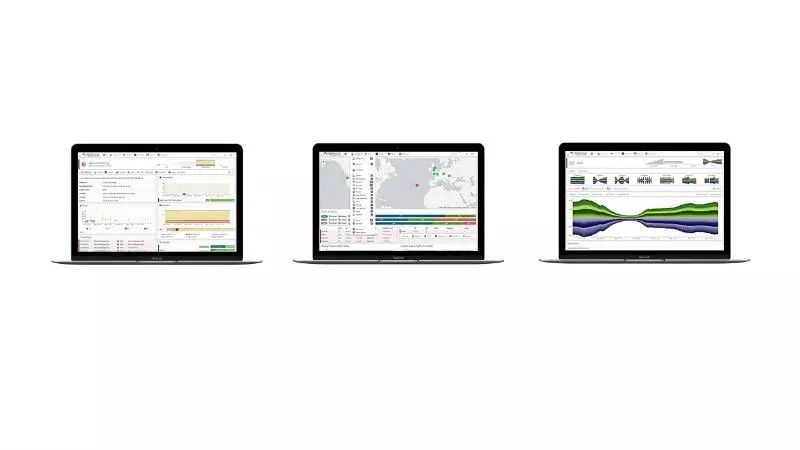
基于Linux的Observium是一个自动监测的网络监控工具。 据该网站介绍,“该工具是由一批经验丰富的专业网络工程师和系统管理员开发和维护的,Observium是一个由用户自己设计和构建的平台。”
Observium提供社区版本和专业版,使用RRDTool进行缓冲存储和图形化功能,并具有易于使用的用户界面和报告功能。 但是,它没有报告导出功能,这可能对商务应用来讲会是一个问题。
社区版本将为用户提供对所有支持设备或指标的完整自动监测功能,通过自动发现协议进行网络映射,自动识别数百种设备,并且每六个月发布一个新版本。
而专业版用户将获得所有社区版本的功能并且还将获得实时软件更新和修复功能,基于规则的自动分组功能,网络阈值和状态警报系统以及流量统计系统。
7. NetXMS
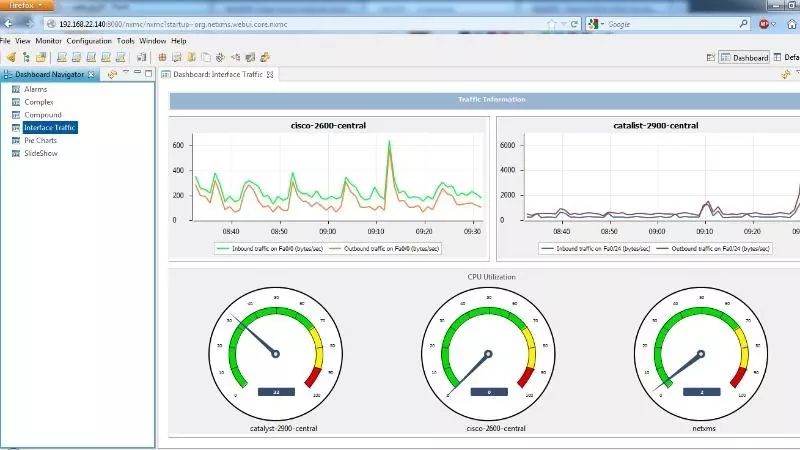
NetXMS 提供了企业级开源网络管理和监控程序,它在Windows和Linux上有一个简单的用户界面。
NetXMS通过相对简单的安装过程为IT基础架构的所有层提供了分布式网络监控、自动化网络发现和详细报告。
此外,服务器设备和代理对于这样一个全面的产品来说是相当轻量级的。
8. Pandora FMS

定位于企业级, Pandora FMS 提供了一个时尚且整洁的用户体验,提供了易于阅读的快速洞察工具以及重要的网络统计信息,例如网络状态、已上报的告警、已部署的代理数量和其他最近执行任务的列表。
Pandora FMS可以在无需外部访问的情况下执行网络诊断,这意味着用户可以更快地响应任何网络问题。事实上,FMS声称,在代理模式下的器监控系统响应速度约为10秒。
9. NetDisco

NetDisco专为类 Unix 操作系统而设计,通过NSMP提供基于网络的自动发现网络设备的功能,从而生成网络拓扑图。它是专为中型到大型网络而设计的。
该网络管理工具可用于定位设备,创建设备目录并报告IP地址和交换机端口使用情况。
NetDisco用户可以通过MAC或IP在网络上定位机器,关闭交换机端口,或更改端口的VLAN或PoE状态,按照型号,供应商,软件和操作系统对网络硬件进行清点,并给你的网络创建一个详细的拓扑图。
10.OpenNMS
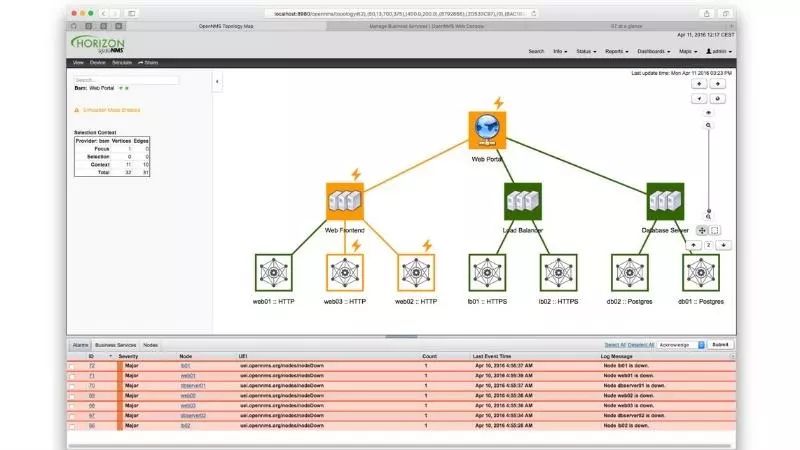
OpenNMS是在1999年发布的,旨在为大型企业级用户提供事件管理,服务监控和性能测量。
使企业用户受益的主要特点包括外部脚本、向通话系统工程师发送警报、扩展Java本机通知策略API、请求跟踪(RT)集成、高级警报、IPv4和IPv6网络可达性超过ICMP、测试状态和节点库存信息。
企业服务或是“风格”网络提供预置事件,通知,数据收集,工作流和附加报告等功能。
11. RANCID
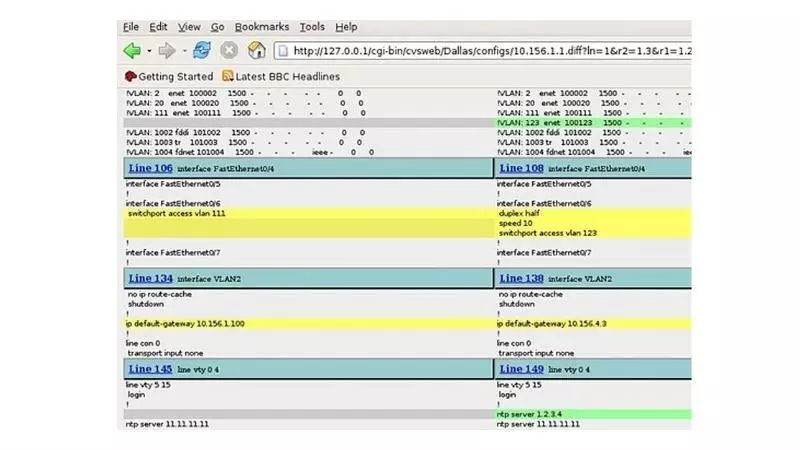
RANCID 听起来像一个消极的名字,除非你学会Really Awesome New Cisco的配置。这一点意味着它能监视路由器或其他设备的配置,并维护任何更改过的历史记录。RANCID 支持很多供应商设备,包括 Juniper路由,HP交换机,Redback的NAS 和 很多对Observium有扩展设备的支持。
RANCID支持许多供应商的设备,包括Juniper路由器,HP交换机,Redback NAS和许多其他设备,以及对Observium的扩展支持。
RANCID提供多种网络管理功能,包括登录到路由器表(router.db)中的每个设备,运行各种命令以获取将被保存的信息,将之前收集的信息中的任何变化发送到邮件列表,并提交这些更改到版本控制系统。
12. Xymon
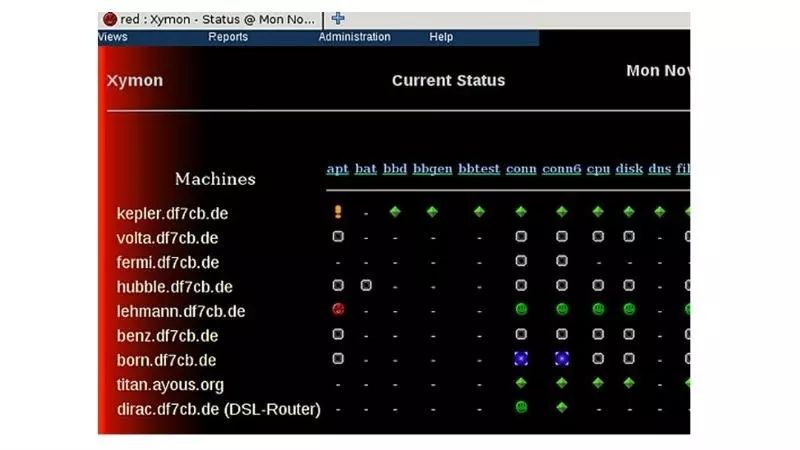
另一个需要提及的网络监控工具是Xymon(以前称为Hobbit)。 Xymon监控服务器,应用程序和网络,通过网页提供有关所有这些网络组件运行状况的信息。
其网站上表示Xymon的开发受到Big Brother的启发,同Big Sister一样,它试图解决Big Brother BTF的缺点,如性能方面。 同时,Xymon更容易部署并且是免费的。
13. Big Brother BTF
Big Brother创建于20世纪90年代中期,用于监控网络系统,后来被Quest Software收购,而其又被戴尔在2012年收购。
许多其他网络监控工具都是模仿Big Brother的,所以它有一个大型的、详细的论坛和有帮助的开发人员社区,是初学者的好选择。
除了可用于学生和非商业用途的开源版本之外,其还提供了名为Big Brother Professional Edition的商业版本。
14. Big Sister
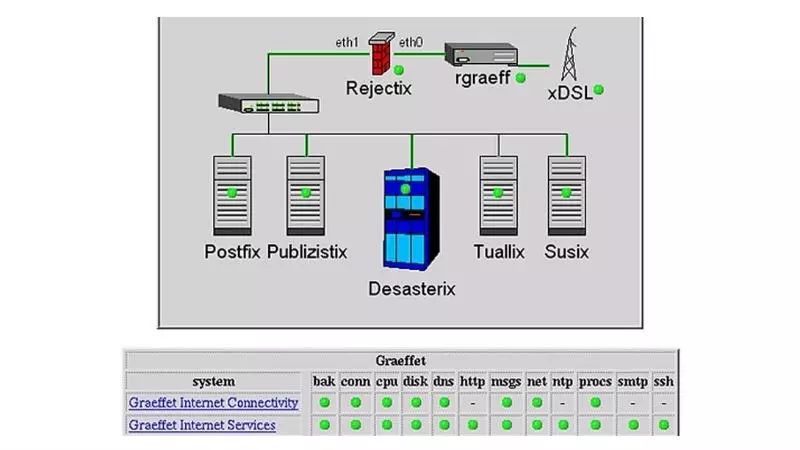
Big Sister创始人托马斯·艾比(Thomas Aeby)表示,他对Big Brother的网络监控印象深刻,但希望提高其性能,减少坏事件发生时的警报数量,并进行其他改进。
Big Sister提供网络监控,节点管理,doxygen过滤器和Web应用程序框架,作为Unix衍生产品和Microsoft Windows操作系统的一部分。
Big Sister对监控网络系统的IT管理员有所帮助。当系统故障时,它会通知管理员,生成状态变化历史记录日志并显示各种系统性能数据。
15. Open Falcon

Open Falcon 是由小米开源的运维监控系统。小米从互联网公司的一些需求出发,从各位SRE、SA、DEVS的使用经验和反馈出发,结合业界的一些大的互联网公司做监控,用监控的一些思考出发,设计开发了小米的监控系统:open-falcon。open-falcon的目标是做最开放、最好用的互联网企业级监控产品。
其特点是:
- 强大灵活的数据采集:自动发现,支持falcon-agent、snmp、支持用户主动push、用户自定义插件支持、opentsdb data model like(timestamp、endpoint、metric、key-value tags)
- 水平扩展能力:支持每个周期上亿次的数据采集、告警判定、历史数据存储和查询
- 高效率的告警策略管理:高效的portal、支持策略模板、模板继承和覆盖、多种告警方式、支持callback调用
- 人性化的告警设置:最大告警次数、告警级别、告警恢复通知、告警暂停、不同时段不同阈值、支持维护周期
- 高效率的graph组件:单机支撑200万metric的上报、归档、存储(周期为1分钟)
- 高效的历史数据query组件:采用rrdtool的数据归档策略,秒级返回上百个metric一年的历史数据
- dashboard:多维度的数据展示,用户自定义Screen
- 高可用:整个系统无核心单点,易运维,易部署,可水平扩展
- 开发语言: 整个系统的后端,全部golang编写,portal和dashboard使用python编写。
16. Icinga

Icinga 起初是 Nagios 的一个分支。Icinga 2 则是做减法得来的,它还能提供分布式监控和多线程框架,这是 Nagios 或 Icinga 1 所不具备的。你可以从 Nagios 迁移到 Icinga 1,然后再迁移到 Icinga 2。
与 Nagios 一样,Icinga 几乎也能通吃所有设备,搭配 SNMP、定制插件和扩展使用效果更佳。
Icinga 提供全局监控和警告框架,只是在 Web UI 上与 Nagios 有所不同。
Icinga 有多款 Web UI,它与 Nagios 的不同主要是配置,用户通过 Web UI 就能搞定,省去了麻烦的配置文档。对于那些在命令行之外管理配置的人来说,这是个重大利好。
Icinga 融入了多款绘图和监控套件(如 PNP4Nagios、inGraph 和 Graphite),可视化性能绝对可靠。此外,Icinga 还拥有扩展报告功能。
17. Ntop
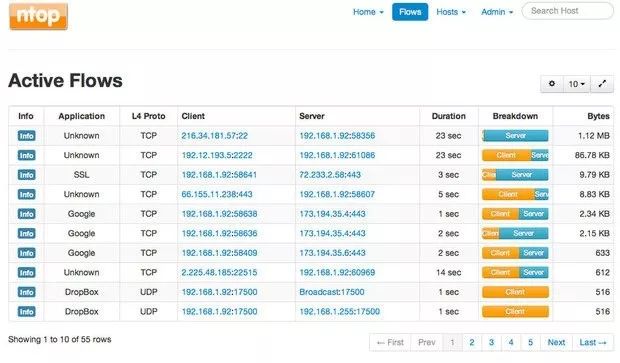
Ntop 计划,也就是传说中的 Ntopng,已经陆陆续续开发了十年。它是一款顶尖的网络流量监控工具,Web 图形用户界面简洁且顺滑。它使用 C 语言编写且完全独立,你只需要运行配置,就能监控某个特定网络接口的单一进程,就这么简单。
Ntop 提供了简单易懂的图形和表格来显示当前和过去的网络流量,包括协议、源、目的地以及特定交易的历史,甚至两端的主机。此外,你还会发现广泛的网络利用率图表、实时地图和趋势,以及针对各种附加件(例如NetFlow和sFlow)的插件框架。这里甚至还有专门嵌入到 Ntop 的硬件监控器 Nbox。
Ntop 甚至用上了轻量级 Lua API 框架,通过脚本语言就能支持扩展。Ntop 还可以将主机数据存储在 RRD 文件中,以支持持久的数据采集。
Ntop 最便捷的用途就是现场流量检查。当你发现自己的某个 Cacti PHP Weathermap 突然显示红色的网络链接集时,就意味着这些链接的利用率超过了 85%,但原因却不得而知。只要切换到 Ntopng 程序来监控该网络段,就可以查看最高流量消耗者每分钟的报表,并立即获知到底哪个主机在占用流量。
这种可视性算得上是无价之宝了,而且唾手可得。从本质上来讲,你可以在被配置成交换机级别的任何端口运行 Ntopng,以便监控任何端口或者 VLAN。
原文地址:https://blog.csdn.net/t8116189520/article/details/81737694
 浙公网安备 33010602011771号
浙公网安备 33010602011771号