
记一次线程池任务执行异常
记一次线程池任务执行异常
一个名为 fetch- 线程池负责从Redis中读取文本数据,将读取到的文本数据提交给另一个线程池 tw-,将 tw- 线程池将任务通过HTTP请求的形式上报给过滤服务。如下图所示:
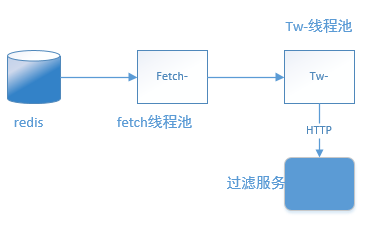
一开始采用默认线程池配置方式:
private final BlockingQueue<Runnable> taskQueue = new LinkedBlockingQueue<>(1000 * 20);
private final ThreadFactory threadFactory = new ThreadFactoryBuilder().setNameFormat("fetch-%d").build();
private final ThreadPoolExecutor executorService = new ThreadPoolExecutor(3, nThreads, 1, TimeUnit.HOURS,
taskQueue, threadFactory, new ThreadPoolExecutor.CallerRunsPolicy());然后只提交三个任务startService(),startService() 是个while(true)以 pipeline 形式不停地从redis上读取文本数据。程序运行一段时间之后,就卡死了。
//nThreads 是 3
for(int i = 0; i < nThreads; i++) {
executorService.execute(()->{
startService();
});
}
}看CPU、内存以及程序的GC日志,都是正常的。sudo jstack -l pid发现:
"fetch-26" #109 prio=5 os_prio=0 tid=0x00007fbfe00db000 nid=0xea76 waiting on condition [0x00007fc127bfc000]
"fetch-25" #108 prio=5 os_prio=0 tid=0x00007fbfec03c000 nid=0xea75 waiting on condition [0x00007fc1257dc000]
"fetch-24" #107 prio=5 os_prio=0 tid=0x00007fbf6c001000 nid=0xea74 waiting on condition [0x00007fc127cfd000]
执行从redis中读取文本任务的fetch- 线程池中的所有线程都阻塞了。由于提交的是Runnable任务,引用《Java并发编程实战》第七章中一段话:
导致线程提前死亡的最主要的原因是RuntimeException。由于这些异常表示出现了某种错误或者其他不可修复的错误,因此它们通常不会被捕获。它们不会在调用栈中逐层传递,而是默认地在控制台中输出栈追踪信息,并终止线程
When a thread exits due to an uncaught exception, the JVM reports this event to our UncaughtExceptionHandler, otherwise the default handler just prints the stack trace to standard error.
因此,我就自定义一个UncaughtExceptionHandler看看到底出现了什么错误:
public class FetchTextExceptionHandler implements Thread.UncaughtExceptionHandler {
private static final Logger logger = LoggerFactory.getLogger(FetchTextExceptionHandler.class);
@Override
public void uncaughtException(Thread t, Throwable e) {
logger.error("fetch redis text exception,thread name:{},msg:{}", t.getName(), e.getMessage());
}
}
UncaughtExceptionHandler只是简单地记录日志,先找到出错原因再说。重新发版,上线一段时间后发现出现程序卡死了,这次有了异常日志:
2018-11-23 23:10:25.681 ERROR 29818 --- [fetch-0] c.y.t.a.s.FetchTextExceptionHandler : fetch redis text exception,thread name:fetch-0,msg:I/O error on POST request for "xxx": Read timed out; nested exception is java.net.SocketTimeoutException: Read timed out
2018-11-23 23:10:25.686 ERROR 29818 --- [fetch-2] c.y.t.a.s.FetchTextExceptionHandler : fetch redis text exception,thread name:fetch-2,msg:I/O error on POST request for "xxx": Read timed out; nested exception is java.net.SocketTimeoutException: Read timed out
2018-11-23 23:10:27.429 ERROR 29818 --- [fetch-1] c.y.t.a.s.FetchTextExceptionHandler : fetch redis text exception,thread name:fetch-1,msg:I/O error on POST request for "xxx": Read timed out; nested exception is java.net.SocketTimeoutException: Read timed out
一看这个日志有点奇怪,fetch线程只是读取redis上的文本数据,并将文本数据封装到一个Runnable任务里面提交给 Tw- 线程池,Tw-线程 才是发送HTTP POST 请求将数据提交给过滤服务。
于是去检查创建Tw-线程池创建代码:发现了Tw-线程池采用的是CallerRunsPolicy延迟策略。
private final ThreadFactory threadFactory = new ThreadFactoryBuilder()
.setUncaughtExceptionHandler(exceptionHandler).setNameFormat("tw-%d").build();
private final ThreadPoolExecutor executorService = new ThreadPoolExecutor(20, maximumPoolSize, 1, TimeUnit.HOURS,
taskQueue, threadFactory, new ThreadPoolExecutor.CallerRunsPolicy());也就是说:当Fecth-线程提交任务过快时,Tw-线程池的taskQueue满了,CallerRunsPolicy让任务回退到调用者,任务由fetch-线程来执行了。因此,上面的日志打印出来的是线程名字是fetch:thread name:fetch-0,msg.....
再引用一段话:
调用者运行策略(Caller-Runs)实现了一种调节机制,该策略不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者,从而降低新任务的流量。它不会在线程池(这里的线程池是 tw-线程池)的某个线程中执行新提交的任务,而是在一个调用了execute的线程(fetch 线程)中执行该任务【fetch 线程执行execute 向 tw-线程池提交任务】
知道了异常出现的原因,于是我就把 tw-线程的 饱和策略从原来的CallerRunsPolicy修改成AbortPolicy,再重新运行程序,一段时间后,发现 tw-线程池中的30个线程全部阻塞,fetch-线程池中的三个线程也全部阻塞。如下图:
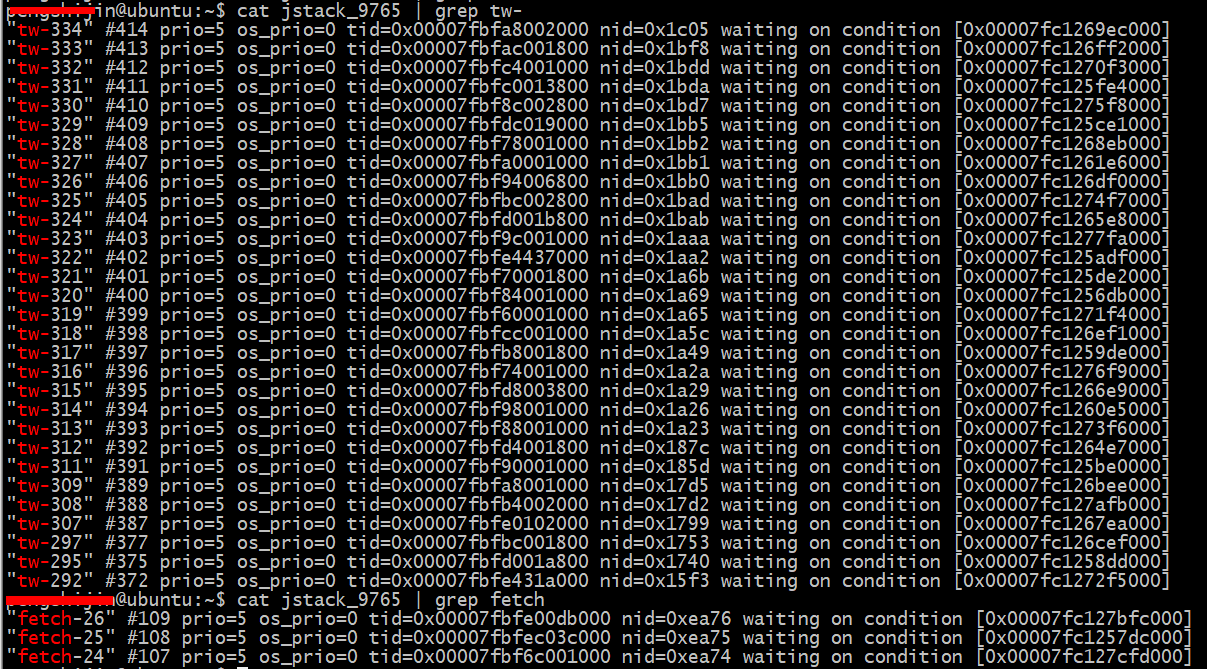
在程序中每个tw-线程隔20ms发送一次HTTP POST请求,将文本上报给过滤服务,30个tw-线程,并发量大约是1500次每秒,每次提交的数据不超过30KB吧。
看程序输出的log日志:30个tw- 线程 都是一样的异常SocketTimeoutException,Read timed out。
2018-11-24 09:16:47.885 ERROR 9765 --- [tw-310] c.y.t.a.s.ReportTwExceptionHandler : http request report tw exception,thread name:tw-310,cause:java.net.SocketTimeoutException: Read timed out,msg:I/O error on POST request for "xxx": Read timed out; nested exception is java.net.SocketTimeoutException: Read timed out
而3个 fetch-线程的异常日志是:rejected from java.util.concurrent.ThreadPoolExecutor
2018-11-24 09:04:36.758 ERROR 9765 --- [fetch-2] c.y.t.a.s.FetchTextExceptionHandler : fetch redis text exception,thread name:fetch-2,msg:Task ReportTwAuditService$$Lambda$75/259476123@7376559c rejected from java.util.concurrent.ThreadPoolExecutor@75fa1939[Running, pool size = 30, active threads = 30, queu
ed tasks = 50000, completed tasks = 20170]
这是因为 fetch-线程向 tw-线程池提交任务,而tw-线程池上面的饱和策略已经改成了AbortPolicy,当tw-线程池任务队列满了时,tw-线程就把 fetch-线程 提交过来的任务给拒绝了,并向fetch-线程抛出RejectedExecutionException 异常。
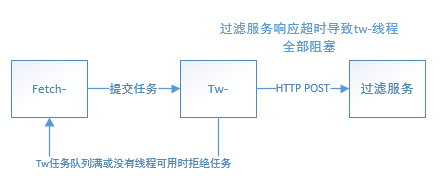
总结一下就是:30个tw-线程因为发送HTTP POST请求给过滤服务出现 SocketTimeoutException,Read timed out全部阻塞,而tw-线程池的饱和策略是AbortPolicy,即:丢弃任务并抛出RejectedExecutionException 异常,导致 fetch 线程阻塞,且提交给tw-线程池的任务被 abort,这就是上面那张图中所有线程都全部阻塞的原因。
再引用一段话:
工作线程在执行一个任务时被阻塞,如果等待用户的输入数据,但是用户一直不输入数据,导致这个线程一直被阻塞。这样的工作线程名存实亡,它实际上不执行任何任务了。如果线程池中的所有线程都处于这样的状态,那么线程池就无法加入新的任务了。各种类型的线程池中一个严重的风险是线程泄漏,当从线程池中除去一个线程以执行一项任务,而在任务完成后该线程却没有返回池时,会发生这种情况。发生线程泄漏的一种情形出现在任务抛出一个 RuntimeException 或一个 Error 时。如果池类没有捕捉到它们,那么线程只会退出而线程池的大小将会永久减少一个。当这种情况发生的次数足够多时,线程池最终就为空,而且系统将停止,因为没有可用的线程来处理任务。
既然tw-线程发送HTTP请求出现了 SocketTImeoutException,那么来看看HTTP连接池的配置:
import org.apache.http.client.HttpClient;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.impl.client.DefaultConnectionKeepAliveStrategy;
import org.apache.http.impl.client.HttpClientBuilder;
import org.apache.http.impl.conn.PoolingHttpClientConnectionManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.http.client.ClientHttpRequestFactory;
import org.springframework.http.client.HttpComponentsClientHttpRequestFactory;
import org.springframework.http.converter.HttpMessageConverter;
import org.springframework.http.converter.StringHttpMessageConverter;
import org.springframework.web.client.RestTemplate;
import java.util.concurrent.TimeUnit;
/**
-
Created by Administrator on 2018/7/4.
配置 RestTemplate 连接池
*/
public class RestTemplateConfig {/**
- https://stackoverflow.com/questions/44762794/java-spring-resttemplate-sets-unwanted-headers
- set http header explicitly: "Accept-Charset": "utf-8"
*/
public RestTemplate restTemplate() {
RestTemplate restTemplate = new RestTemplate(httpRequestFactory());
for (HttpMessageConverter converter : restTemplate.getMessageConverters()) {
if (converter instanceof StringHttpMessageConverter) {
((StringHttpMessageConverter)converter).setWriteAcceptCharset(false);
}
}
return restTemplate;
}
public ClientHttpRequestFactory httpRequestFactory() {
return new HttpComponentsClientHttpRequestFactory(httpClient());
}
public HttpClient httpClient() {
//配置http长连接
PoolingHttpClientConnectionManager connectionManager = new PoolingHttpClientConnectionManager(30, TimeUnit.SECONDS);
connectionManager.setMaxTotal(1000);
connectionManager.setDefaultMaxPerRoute(20);
RequestConfig requestConfig = RequestConfig.custom()
//服务器返回数据(response)的时间,超过该时间抛出read timeout
.setSocketTimeout(5000)
//连接上服务器(握手成功)的时间,超出该时间抛出connect timeout
.setConnectTimeout(5000)
//从连接池中获取连接的超时时间,超过该时间未拿到可用连接抛出异常
.setConnectionRequestTimeout(1000).build();return HttpClientBuilder.create().setDefaultRequestConfig(requestConfig).
setConnectionManager(connectionManager).
setConnectionManagerShared(true)
//keep alive
.setKeepAliveStrategy(DefaultConnectionKeepAliveStrategy.INSTANCE)
.build();
}
}
到这里就大概知道解决方案了:
让弱鸡的过滤服务牛B一点,这有点不太可能的。你懂的……
控制HTTP 请求速度,并添加线程抛出异常时处理方法(自定义ThreadPoolExecutor,重写afterExecute方法)而不仅仅是实现UncaughtExceptionHandler,简单地打印出异常日志。
fetch-线程 阻塞的原因是因为:向tw-线程池提交任务,而tw-线程池采用的饱和策略是
AbortPolicy,如果把它改成:DiscardPolicy直接丢弃任务而不抛出异常。这样fetch-线程就不会收到RejectedExecutionException 异常而阻塞了。当然了,采用DiscardPolicy饱和策略的话,fetch-线程提交任务出现异常就无法感知了,这时我们还可以自定义饱和策略。如下:可以简单地打印出一个日志:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.concurrent.RejectedExecutionHandler;
import java.util.concurrent.ThreadPoolExecutor;
/**
- @author xxx
@date 2018/11/24
*/
public class ReportTwRejectExceptionHandler implements RejectedExecutionHandler {
private static final Logger logger = LoggerFactory.getLogger(ReportTwRejectExceptionHandler.class);
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
logger.error("fetch thread submit task rejected. {}",executor.toString());
}
}
再修改一下 tw-线程池的配置参数:
//使用我们自定义的饱和策略 RejectedExecutionHandler,当有线程提交任务给tw-线程池时,若出现错误会打印日志
private RejectedExecutionHandler rejectedExecutionHandler = new ReportTwRejectExceptionHandler();
private ReportTwExceptionHandler exceptionHandler = new ReportTwExceptionHandler();
private final ThreadFactory threadFactory = new ThreadFactoryBuilder()
.setUncaughtExceptionHandler(exceptionHandler).setNameFormat("tw-%d").build();
//队列长度为50000
private final BlockingQueue<Runnable> taskQueue = new LinkedBlockingQueue<>(1000 * 10 * 5);
//maximumPoolSize=30
private final ThreadPoolExecutor executorService = new ThreadPoolExecutor(20, maximumPoolSize, 1, TimeUnit.HOURS,
taskQueue, threadFactory, rejectedExecutionHandler);
这样,如果fetch线程向 tw-线程池提交任务出错,就会收到如下日志了:
2018-11-24 17:05:45.511 ERROR 38161 --- [fetch-0] c.y.t.a.e.ReportTwRejectExceptionHandler : fetch thread submit task rejected.java.util.concurrent.ThreadPoolExecutor@41a28fcd[Running, pool size = 30, active threads = 30, queued tasks = 50000, completed tasks = 110438]
其他一些:
private static final int nThreads = Runtime.getRuntime().availableProcessors();//24返回的是逻辑cpu的个数。
~$ cat /proc/cpuinfo| grep "processor"| wc -l
24
在一台机器上开多少个线程合适?有个公式
W是等待时间、C是使用CPU的计算时间。因此,需要估计任务的类型,是计算密集型,还是IO密集型?另外:一台物理机上不仅仅是你写的程序在上面跑,还有其他人写的程序也在上面跑,因此,在使用这个公式计算线程数目时也要注意到这一点。
如果任务之间是异构的且独立的,两种不同类型的任务,那么可以使用2个线程池来执行这些任务。比如一个线程池执行CPU密集型任务,另一个线程池执行IO密集型任务。
为什么要自定义线程池?
个人认为我们在写代码的时候对要处理的任务是有一定的了解的,比如并发量多大?数据量多大?根据这些信息就大概能知道任务队列定义多长合适,而不是采用默认的无界阻塞队列。
同时,对任务的特征也有所了解,比如是否要调用远程HTTP服务?是否写磁盘有IO阻塞?还是只是转换数据、处理数据,另外所部署的服务器的硬件性能咋样?这些都能作为定义线程个数的一些参考。
最后,采用自定义线程池,在任务执行出错了,可能更灵活地控制处理错误,比如记录错误日志、执行任务前以及执行任务后的清理操作……
参考资料
原文:https://www.cnblogs.com/hapjin/p/10012435.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号