分布式机器学习框架
分布式机器学习框架
分布式机器学习解决的是研究的就是如何使用计算机集群来训练大规模机器学习模型。
一、基本流程
问题:计算量太大、训练数据太多、模型规模太大
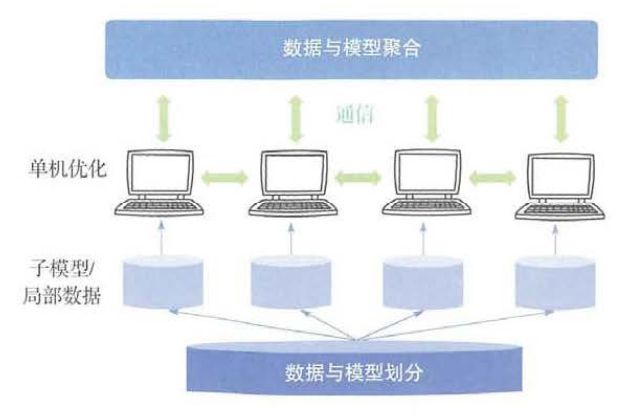
二、数据与模型划分模块
数据划分
对训练样本划分
- 随机采样(有放回)
- 置乱切分(无放回)
对样本的特征维度划分
需要与特定的优化方法(如坐标下降法)配合使用,否则通信代价很大。
模型划分
不同的子模型划分方法会影响到各个工作节点之间的依赖关系和通信强度,好的划分可以降低通信强度、提高并行计算的的加速比。
- 线性模型:针对不同的特征维度划分
- 深层神经网络:
- 逐层的横向划分:接口清晰,但并行度不高,一层的模型有可能仍太大
- 跨层的纵向划分:分成更多份,但依赖关系复杂,通信代价更高
- 随机划分:将骨架网络存储于每个工作节点。
三、单机优化模块
传统的机器学习发生的地方
四、通信模块
通信内容
子模型(可直接发送中间计算结果)、重要样本
通信拓扑结构
- 基于迭代式MapReduce/AllReduce的通信拓扑:可以利用现有的系统简单高效完成分布式机器学习任务。但只支持同步通信,运算节点和模型存储节点没有很好的逻辑隔离,且需要将单机优化算法进行比较大的改动。
- 基于参数服务器的通信拓扑:将工作节点之间的交互过程隔离开来,不需同步。且可以采用多个参数服务器来共同维护较大的模型。
- 基于数据流的通信拓扑:控制消息流和计算数据流
通信的步调
同步、异步(有锁、无锁)、半同步、混合同步
通信的频率
实现计算代价与通信代价的最优匹配
五、数据与模型聚合模块
聚合方法(以基于参数服务器为例)
- 对模型参数简单平均:适用于学习目标是凸函数
- 解一个一致性优化问题(ADMM、BMUF)
- 模型集成:“模型爆炸”,参数巨多。
是否所有的子模型都需要被聚合?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号