Hashtable,HashMap,TreeMap有什么区别?Vector,ArrayList,LinkedList有什么区别?int和Integer有什么区别?
接着上篇继续更新。
/*请尊重作者劳动成果,转载请标明原文链接:*/
/* https://www.cnblogs.com/jpcflyer/p/10759447.html* /
题目一:Hashtable,HashMap,TreeMap有什么区别?
一般回答:
Hashtable 是早期 Java 类库提供的一个哈希表实现,本身是同步的,不支持 null 键和值,由于同步导致的性能开销,所以已经很少被推荐使用。
HashMap 是应用更加广泛的哈希表实现,行为上大致上与 HashTable 一致,主要区别在于 HashMap 不是同步的,支持 null 键和值等。通常情况下,HashMap 进行 put 或者 get 操作,可以达到常数时间的性能,所以它是绝大部分利用键值对存取场景的首选,比如,实现一个用户 ID 和用户信息对应的运行时存储结构。
TreeMap 则是基于红黑树的一种提供顺序访问的 Map,和 HashMap 不同,它的 get、put、remove 之类操作都是 O(log(n))的时间复杂度,具体顺序可以由指定的 Comparator 来决定,或者根据键的自然顺序来判断。
扩展一下,看看JAVA集合的全集。
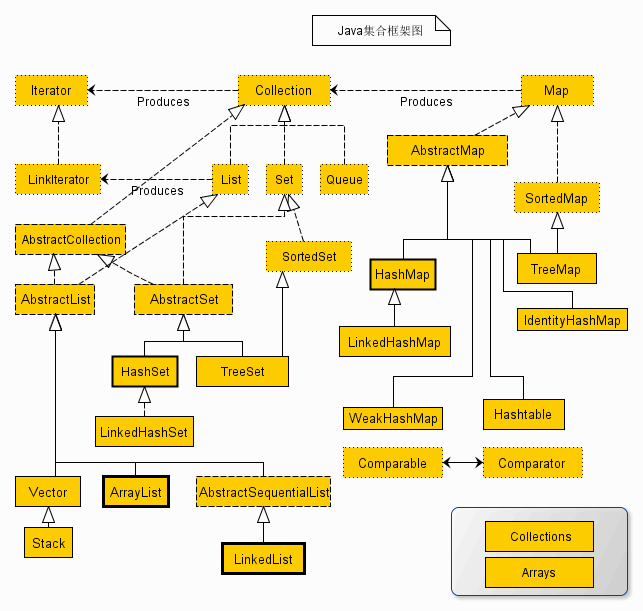
上述类图中,实线边框的是实现类,比如ArrayList,LinkedList,HashMap等,折线边框的是抽象类,比如AbstractCollection,AbstractList,AbstractMap等,而点线边框的是接口,比如Collection,Iterator,List等。
发现一个特点,上述所有的集合类,都实现了Iterator接口,这是一个用于遍历集合中元素的接口,主要包含hashNext(),next(),remove()三种方法。它的一个子接口LinkedIterator在它的基础上又添加了三种方法,分别是add(),previous(),hasPrevious()。也就是说如果是先Iterator接口,那么在遍历集合中元素的时候,只能往后遍历,被遍历后的元素不会在遍历到,通常无序集合实现的都是这个接口,比如HashSet,HashMap;而那些元素有序的集合,实现的一般都是LinkedIterator接口,实现这个接口的集合可以双向遍历,既可以通过next()访问下一个元素,又可以通过previous()访问前一个元素,比如ArrayList。
还有一个特点就是抽象类的使用。如果要自己实现一个集合类,去实现那些抽象的接口会非常麻烦,工作量很大。这个时候就可以使用抽象类,这些抽象类中给我们提供了许多现成的实现,我们只需要根据自己的需求重写一些方法或者添加一些方法就可以实现自己需要的集合类,工作流昂大大降低。
题目二:Vector,ArrayList,LinkedList有什么区别?
一般回答:
Vector 是 Java 早期提供的线程安全的动态数组,如果不需要线程安全,并不建议选择,毕竟同步是有额外开销的。Vector 内部是使用对象数组来保存数据,可以根据需要自动的增加容量,当数组已满时,会创建新的数组,并拷贝原有数组数据。
ArrayList 是应用更加广泛的动态数组实现,它本身不是线程安全的,所以性能要好很多。与 Vector 近似,ArrayList 也是可以根据需要调整容量,不过两者的调整逻辑有所区别,Vector 在扩容时会提高 1 倍,而 ArrayList 则是增加 50%。
LinkedList 顾名思义是 Java 提供的双向链表,所以它不需要像上面两种那样调整容量,它也不是线程安全的。
继续扩展一下,还是先看上题中的集合框架图。
我们可以看到 Java 的集合框架,Collection 接口是所有集合的根,然后扩展开提供了三大类集合,分别是:
List,也就是我们前面介绍最多的有序集合,它提供了方便的访问、插入、删除等操作。
Set,Set 是不允许重复元素的,这是和 List 最明显的区别,也就是不存在两个对象 equals 返回 true。我们在日常开发中有很多需要保证元素唯一性的场合。
Queue/Deque,则是 Java 提供的标准队列结构的实现,除了集合的基本功能,它还支持类似先入先出(FIFO, First-in-First-Out)或者后入先出(LIFO,Last-In-First-Out)等特定行为。这里不包括 BlockingQueue,因为通常是并发编程场合,所以被放置在并发包里。
每种集合的通用逻辑,都被抽象到相应的抽象类之中,比如 AbstractList 就集中了各种 List 操作的通用部分。这些集合不是完全孤立的,比如,LinkedList 本身,既是 List,也是 Deque 哦。
如果阅读过更多源码,你会发现,其实,TreeSet 代码里实际默认是利用 TreeMap 实现的,Java 类库创建了一个 Dummy 对象“PRESENT”作为 value,然后所有插入的元素其实是以键的形式放入了 TreeMap 里面;同理,HashSet 其实也是以 HashMap 为基础实现的,原来他们只是 Map 类的马甲!
题目三:int和Integer有什么区别?
一般回答:
int 是我们常说的整形数字,是 Java 的 8 个原始数据类型(Primitive Types,boolean、byte 、short、char、int、float、double、long)之一。 Java 语言虽然号称一切都是对象,但原始数据类型是例外。
Integer 是 int 对应的包装类,它有一个 int 类型的字段存储数据,并且提供了基本操作,比如数学运算、int 和字符串之间转换等。在 Java 5 中,引入了自动装箱和自动拆箱功能(boxing/unboxing),Java 可以根据上下文,自动进行转换,极大地简化了相关编程。
扩展:
这里很容易就想到装箱和拆箱。 装箱就是自动将基本数据类型转换为包装器类型;拆箱就是自动将包装器类型转换为基本数据类型。
这个过程是自动执行的,那么我们需要看看它的执行过程:
public class Main { public static void main(String[] args) { //自动装箱 Integer total = 99; //自定拆箱 int totalprim = total; } }
反编译class文件之后得到如下内容:
javap -c StringTest
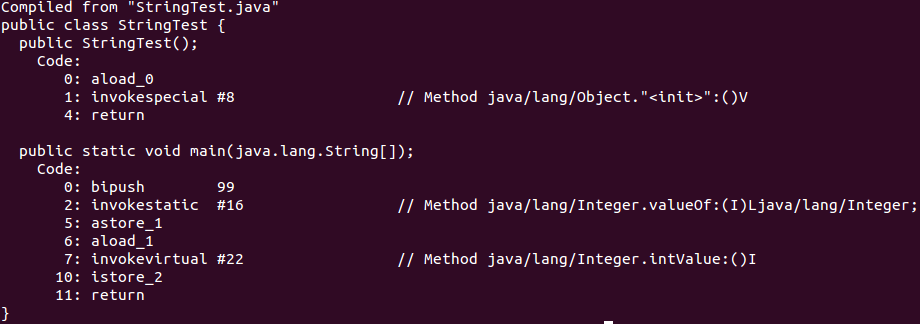
Integer total = 99;
执行上面那句代码的时候,系统为我们执行了:
Integer total = Integer.valueOf(99);
int totalprim = total;
执行上面那句代码的时候,系统为我们执行了:
int totalprim = total.intValue();
那么什么时候会进行封箱拆箱呢?
当一个基础数据类型与封装类进行==、+、-、*、/运算时,会将封装类进行拆箱,对基础数据类型进行运算。
需要注意的是:
1. 装箱操作会创建对象,频繁的装箱操作会消耗许多内存,影响性能,所以可以避免装箱的时候应该尽量避免。
2.自动拆箱实际是jvm 调用了 intValue 方法,所以性能上不会有影响。
3.除double 和float 两种类型以外,其他基本类型入Integer值 在 -128 ~ 127之间时不会新建一个Integer 对象而是从缓存中获取。所以在做 == 判断时 要注意值得大小,如果超过范围,则两个值 虽然一样但 == 比较的结果会是FALSE。
4.Integer 类型的比较最好用 compare 。
5.比较两者(int 与 Integer变量) 时,可以用拆箱 (用intValue方法),没影响的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号