[K8s]Kubernetes-服务、负载均衡、联网(下)
Ingress
FEATURE STATE: Kubernetes v1.19 [stable]
Ingress 是对集群中服务的外部访问进行管理的 API 对象,典型的访问方式是 HTTP。
Ingress 可以提供负载均衡、SSL终结和基于名称的虚拟托管。
术语
为了表达更加清晰,本指南定义了以下术语:
- 节点(Node): Kubernetes 集群中其中一台工作机器,是集群的一部分。
- 集群(Cluster): 一组运行由 Kubernetes 管理的容器化应用程序的节点。在此示例和在大多数常见的 Kubernetes 部署环境中,集群中的节点都不在公共网络中。
- 边缘路由器(Edge router): 在集群中强制执行防火墙策略的路由器(router)。可以是由云提供商管理的网关,也可以是物理硬件。
- 集群网络(Cluster network): 一组逻辑的或物理的连接,根据 Kubernetes 网络模型在集群内实现通信。
- 服务(Service):Kubernetes 服务使用标签选择算符(selectors)标识的一组 Pod。除非另有说明,否则假定服务只具有在集群网络中可路由的虚拟 IP。
Ingress 是什么?
Ingress 公开了从集群外部到集群内服务的 HTTP 和 HTTPS 路由。流量路由由 Ingress 资源上定义的规则控制。
下面是一个将所有流量都发送到同一 Service 的简单 Ingress 示例:
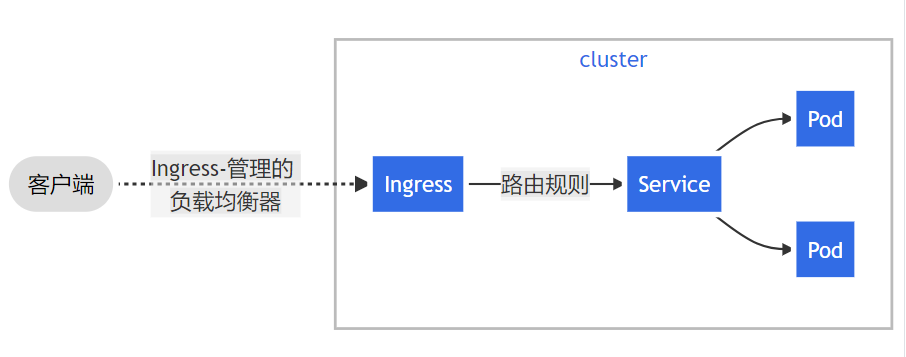
可以将 Ingress 配置为服务提供外部可访问的 URL、负载均衡流量、终止 SSL/TLS,以及提供基于名称的虚拟主机等能力。Ingress 控制器通常负责通过负载均衡器来实现 Ingress,尽管它也可以配置边缘路由器或其他前端来帮助处理流量。
Ingress 不会公开任意端口或协议。将 HTTP 和 HTTPS 以外的服务公开到 Internet 时,通常使用 Service.Type=NodePort 或 Service.Type=LoadBalancer 类型的服务。
环境准备
你必须具有 Ingress 控制器才能满足 Ingress 的要求。仅创建 Ingress 资源本身没有任何效果。
你可能需要部署 Ingress 控制器,例如 ingress-nginx。你可以从许多 Ingress 控制器中进行选择。
理想情况下,所有 Ingress 控制器都应符合参考规范。但实际上,不同的 Ingress 控制器操作略有不同。
说明: 确保你查看了 Ingress 控制器的文档,以了解选择它的注意事项。
Ingress 资源
一个最小的 Ingress 资源示例:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: minimal-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- http:
paths:
- path: /testpath
pathType: Prefix
backend:
service:
name: test
port:
number: 80
与所有其他 Kubernetes 资源一样,Ingress 需要使用 apiVersion、kind 和 metadata 字段。Ingress 对象的命名必须是合法的 DNS 子域名名称。有关使用配置文件的一般信息,请参见部署应用、配置容器、管理资源。Ingress 经常使用注解(annotations)来配置一些选项,具体取决于 Ingress 控制器,例如重写目标注解。不同的 Ingress 控制器支持不同的注解。查看文档以供你选择 Ingress 控制器,以了解支持哪些注解。
Ingress 规约提供了配置负载均衡器或者代理服务器所需的所有信息。最重要的是,其中包含与所有传入请求匹配的规则列表。Ingress 资源仅支持用于转发 HTTP 流量的规则。
Ingress 规则
每个 HTTP 规则都包含以下信息:
- 可选的 host。在此示例中,未指定 host,因此该规则适用于通过指定 IP 地址的所有入站 HTTP 通信。如果提供了 host(例如 foo.bar.com),则 rules 适用于该 host。
- 路径列表 paths(例如,/testpath),每个路径都有一个由 serviceName 和 servicePort 定义的关联后端。在负载均衡器将流量定向到引用的服务之前,主机和路径都必须匹配传入请求的内容。
- backend(后端)是 Service 文档中所述的服务和端口名称的组合。与规则的 host 和 path 匹配的对 Ingress 的 HTTP(和 HTTPS )请求将发送到列出的 backend。
通常在 Ingress 控制器中会配置 defaultBackend(默认后端),以服务于任何不符合规约中 path 的请求。
DefaultBackend
没有 rules 的 Ingress 将所有流量发送到同一个默认后端。defaultBackend 通常是 Ingress 控制器的配置选项,而非在 Ingress 资源中指定。
如果 hosts 或 paths 都没有与 Ingress 对象中的 HTTP 请求匹配,则流量将路由到默认后端。
资源后端
Resource 后端是一个 ObjectRef,指向同一名字空间中的另一个 Kubernetes,将其作为 Ingress 对象。Resource 与 Service 配置是互斥的,在二者均被设置时会无法通过合法性检查。Resource 后端的一种常见用法是将所有入站数据导向带有静态资产的对象存储后端。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-resource-backend
spec:
defaultBackend:
resource:
apiGroup: k8s.example.com
kind: StorageBucket
name: static-assets
rules:
- http:
paths:
- path: /icons
pathType: ImplementationSpecific
backend:
resource:
apiGroup: k8s.example.com
kind: StorageBucket
name: icon-assets
创建了如上的 Ingress 之后,你可以使用下面的命令查看它:
kubectl describe ingress ingress-resource-backend
Name: ingress-resource-backend
Namespace: default
Address:
Default backend: APIGroup: k8s.example.com, Kind: StorageBucket, Name: static-assets
Rules:
Host Path Backends
---- ---- --------
*
/icons APIGroup: k8s.example.com, Kind: StorageBucket, Name: icon-assets
Annotations: <none>
Events: <none>
路径类型
Ingress 中的每个路径都需要有对应的路径类型(Path Type)。未明确设置 pathType 的路径无法通过合法性检查。当前支持的路径类型有三种:
-
ImplementationSpecific:对于这种路径类型,匹配方法取决于 IngressClass。具体实现可以将其作为单独的 pathType 处理或者与 Prefix 或 Exact 类型作相同处理。
-
Exact:精确匹配 URL 路径,且区分大小写。
-
Prefix:基于以 / 分隔的 URL 路径前缀匹配。匹配区分大小写,并且对路径中的元素逐个完成。路径元素指的是由 / 分隔符分隔的路径中的标签列表。如果每个 p 都是请求路径 p 的元素前缀,则请求与路径 p 匹配。
说明: 如果路径的最后一个元素是请求路径中最后一个元素的子字符串,则不会匹配(例如:/foo/bar 匹配 /foo/bar/baz,但不匹配 /foo/barbaz)。
示例
|
类型
|
路径
|
请求路径
|
匹配与否?
|
|
Prefix
|
/
|
(所有路径)
|
是
|
|
Exact
|
/foo
|
/foo
|
是
|
|
Exact
|
/foo
|
/bar
|
否
|
|
Exact
|
/foo
|
/foo/
|
否
|
|
Exact
|
/foo/
|
/foo
|
否
|
|
Prefix
|
/foo
|
/foo, /foo/
|
是
|
|
Prefix
|
/foo/
|
/foo, /foo/
|
是
|
|
Prefix
|
/aaa/bb
|
/aaa/bbb
|
否
|
|
Prefix
|
/aaa/bbb
|
/aaa/bbb
|
是
|
|
Prefix
|
/aaa/bbb/
|
/aaa/bbb
|
是,忽略尾部斜线
|
|
Prefix
|
/aaa/bbb
|
/aaa/bbb/
|
是,匹配尾部斜线
|
|
Prefix
|
/aaa/bbb
|
/aaa/bbb/ccc
|
是,匹配子路径
|
|
Prefix
|
/aaa/bbb
|
/aaa/bbbxyz
|
否,字符串前缀不匹配
|
|
Prefix
|
/, /aaa
|
/aaa/ccc
|
是,匹配 /aaa 前缀
|
|
Prefix
|
/, /aaa, /aaa/bbb
|
/aaa/bbb
|
是,匹配 /aaa/bbb 前缀
|
|
Prefix
|
/, /aaa, /aaa/bbb
|
/ccc
|
是,匹配 / 前缀
|
|
Prefix
|
/aaa
|
/ccc
|
否,使用默认后端
|
|
混合
|
/foo (Prefix), /foo (Exact)
|
/foo
|
是,优选 Exact 类型
|
多重匹配
在某些情况下,Ingress 中的多条路径会匹配同一个请求。这种情况下最长的匹配路径优先。如果仍然有两条同等的匹配路径,则精确路径类型优先于前缀路径类型。
主机名通配符
主机名可以是精确匹配(例如“foo.bar.com”)或者使用通配符来匹配 (例如“*.foo.com”)。精确匹配要求 HTTP host 头部字段与 host 字段值完全匹配。通配符匹配则要求 HTTP host 头部字段与通配符规则中的后缀部分相同。
|
主机
|
host 头部
|
匹配与否?
|
|
*.foo.com
|
基于相同的后缀匹配
|
|
|
*.foo.com
|
不匹配,通配符仅覆盖了一个 DNS 标签
|
|
|
*.foo.com
|
不匹配,通配符仅覆盖了一个 DNS 标签
|
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-wildcard-host
spec:
rules:
- host: "foo.bar.com"
http:
paths:
- pathType: Prefix
path: "/bar"
backend:
service:
name: service1
port:
number: 80
- host: "*.foo.com"
http:
paths:
- pathType: Prefix
path: "/foo"
backend:
service:
name: service2
port:
number: 80
Ingress 类
Ingress 可以由不同的控制器实现,通常使用不同的配置。每个 Ingress 应当指定一个类,也就是一个对 IngressClass 资源的引用。IngressClass 资源包含额外的配置,其中包括应当实现该类的控制器名称。
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: external-lb
spec:
controller: example.com/ingress-controller
parameters:
apiGroup: k8s.example.com
kind: IngressParameters
name: external-lb
IngressClass 资源包含一个可选的 parameters 字段,可用于为该类引用额外的、特定于具体实现的配置。
名字空间域的参数
FEATURE STATE: Kubernetes v1.22 [beta]
parameters 字段有一个 scope 和 namespace 字段,可用来引用特定于名字空间的资源,对 Ingress 类进行配置。scope 字段默认为 Cluster,表示默认是集群作用域的资源。将 scope 设置为 Namespace 并设置 namespace 字段就可以引用某特定名字空间中的参数资源。
有了名字空间域的参数,就不再需要为一个参数资源配置集群范围的 CustomResourceDefinition。除此之外,之前对访问集群范围的资源进行授权,需要用到 RBAC 相关的资源,现在也不再需要了。
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: external-lb
spec:
controller: example.com/ingress-controller
parameters:
apiGroup: k8s.example.com
kind: IngressParameters
name: external-lb
namespace: external-configuration
scope: Namespace
废弃的注解
在 Kubernetes 1.18 版本引入 IngressClass 资源和 ingressClassName 字段之前,Ingress 类是通过 Ingress 中的一个 kubernetes.io/ingress.class 注解来指定的。这个注解从未被正式定义过,但是得到了 Ingress 控制器的广泛支持。
Ingress 中新的 ingressClassName 字段是该注解的替代品,但并非完全等价。该注解通常用于引用实现该 Ingress 的控制器的名称,而这个新的字段则是对一个包含额外 Ingress 配置的 IngressClass 资源的引用,包括 Ingress 控制器的名称。
默认 Ingress 类
你可以将一个特定的 IngressClass 标记为集群默认 Ingress 类。将一个 IngressClass 资源的 ingressclass.kubernetes.io/is-default-class 注解设置为 true 将确保新的未指定 ingressClassName 字段的 Ingress 能够分配为这个默认的 IngressClass.
注意: 如果集群中有多个 IngressClass 被标记为默认,准入控制器将阻止创建新的未指定 ingressClassName 的 Ingress 对象。解决这个问题只需确保集群中最多只能有一个 IngressClass 被标记为默认。
Ingress 类型
由单个 Service 来完成的 Ingress
现有的 Kubernetes 概念允许你暴露单个 Service (参见替代方案)。你也可以通过指定无规则的默认后端来对 Ingress 进行此操作。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: test-ingress
spec:
defaultBackend:
service:
name: test
port:
number: 80
如果使用 kubectl apply -f 创建此 Ingress,则应该能够查看刚刚添加的 Ingress 的状态:
kubectl get ingress test-ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
test-ingress external-lb * 203.0.113.123 80 59s
其中 203.0.113.123 是由 Ingress 控制器分配以满足该 Ingress 的 IP。
说明: 入口控制器和负载平衡器可能需要一两分钟才能分配 IP 地址。在此之前,你通常会看到地址字段的值被设定为
<pending>。
简单扇出
一个扇出(fanout)配置根据请求的 HTTP URI 将来自同一 IP 地址的流量路由到多个 Service。Ingress 允许你将负载均衡器的数量降至最低。例如,这样的设置:
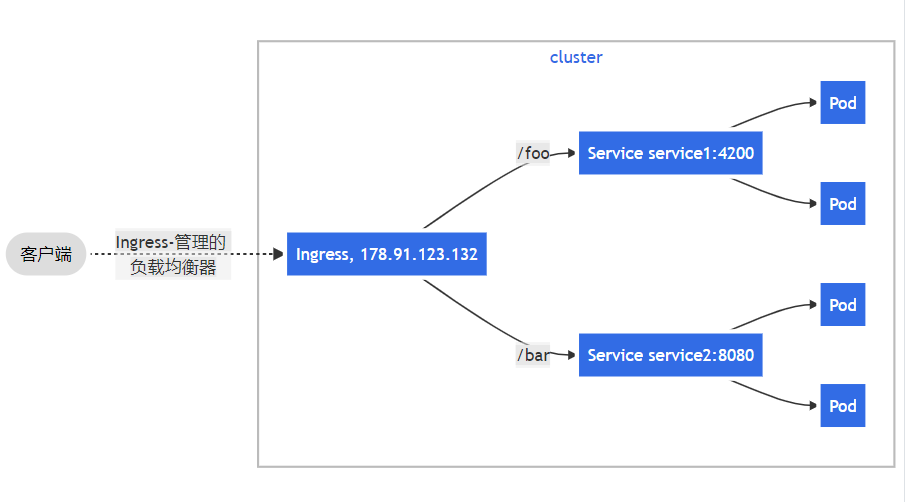
将需要一个如下所示的 Ingress:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: simple-fanout-example
spec:
rules:
- host: foo.bar.com
http:
paths:
- path: /foo
pathType: Prefix
backend:
service:
name: service1
port:
number: 4200
- path: /bar
pathType: Prefix
backend:
service:
name: service2
port:
number: 8080
当你使用 kubectl apply -f 创建 Ingress 时:
kubectl describe ingress simple-fanout-example
Name: simple-fanout-example
Namespace: default
Address: 178.91.123.132
Default backend: default-http-backend:80 (10.8.2.3:8080)
Rules:
Host Path Backends
---- ---- --------
foo.bar.com
/foo service1:4200 (10.8.0.90:4200)
/bar service2:8080 (10.8.0.91:8080)
Annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ADD 22s loadbalancer-controller default/test
Ingress 控制器将提供实现特定的负载均衡器来满足 Ingress,只要 Service (service1,service2) 存在。当它这样做时,你会在 Address 字段看到负载均衡器的地址。
说明: 取决于你所使用的 Ingress 控制器,你可能需要创建默认 HTTP 后端服务。
基于名称的虚拟托管
基于名称的虚拟主机支持将针对多个主机名的 HTTP 流量路由到同一 IP 地址上。
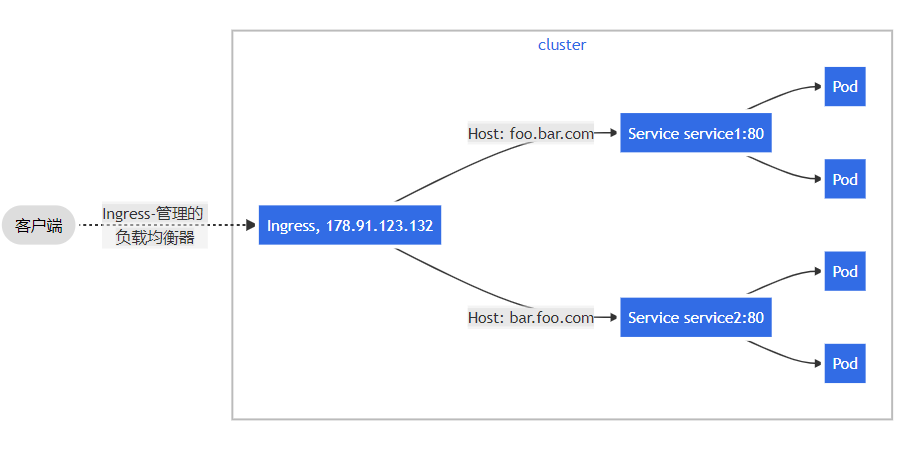
以下 Ingress 让后台负载均衡器基于host 头部字段来路由请求。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: name-virtual-host-ingress
spec:
rules:
- host: foo.bar.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service1
port:
number: 80
- host: bar.foo.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service2
port:
number: 80
如果你创建的 Ingress 资源没有在 rules 中定义的任何 hosts,则可以匹配指向 Ingress 控制器 IP 地址的任何网络流量,而无需基于名称的虚拟主机。
例如,以下 Ingress 会将针对 first.bar.com 的请求流量路由到 service1,将针对 second.bar.com 的请求流量路由到 service2,而针对该 IP 地址的、没有在请求中定义主机名的请求流量会被路由(即,不提供请求标头)到 service3。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: name-virtual-host-ingress-no-third-host
spec:
rules:
- host: first.bar.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service1
port:
number: 80
- host: second.bar.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service2
port:
number: 80
- http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service3
port:
number: 80
TLS
你可以通过设定包含 TLS 私钥和证书的 Secret 来保护 Ingress。Ingress 只支持单个 TLS 端口 443,并假定 TLS 连接终止于 Ingress 节点(与 Service 及其 Pod 之间的流量都以明文传输)。如果 Ingress 中的 TLS 配置部分指定了不同的主机,那么它们将根据通过 SNI TLS 扩展指定的主机名(如果 Ingress 控制器支持 SNI)在同一端口上进行复用。TLS Secret 必须包含名为 tls.crt 和 tls.key 的键名。这些数据包含用于 TLS 的证书和私钥。例如:
apiVersion: v1
kind: Secret
metadata:
name: testsecret-tls
namespace: default
data:
tls.crt: base64 编码的 cert
tls.key: base64 编码的 key
type: kubernetes.io/tls
在 Ingress 中引用此 Secret 将会告诉 Ingress 控制器使用 TLS 加密从客户端到负载均衡器的通道。你需要确保创建的 TLS Secret 创建自包含 https-example.foo.com 的公用名称(CN)的证书。这里的公共名称也被称为全限定域名(FQDN)。
说明:
注意,默认规则上无法使用 TLS,因为需要为所有可能的子域名发放证书。因此,tls 节区的 hosts 的取值需要域 rules 节区的 host 完全匹配。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: tls-example-ingress
spec:
tls:
- hosts:
- https-example.foo.com
secretName: testsecret-tls
rules:
- host: https-example.foo.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: service1
port:
number: 80
说明: 各种 Ingress 控制器所支持的 TLS 功能之间存在差异。请参阅有关 nginx、 GCE 或者任何其他平台特定的 Ingress 控制器的文档,以了解 TLS 如何在你的环境中工作。
负载均衡
Ingress 控制器启动引导时使用一些适用于所有 Ingress 的负载均衡策略设置,例如负载均衡算法、后端权重方案和其他等。更高级的负载均衡概念(例如持久会话、动态权重)尚未通过 Ingress 公开。你可以通过用于服务的负载均衡器来获取这些功能。
值得注意的是,尽管健康检查不是通过 Ingress 直接暴露的,在 Kubernetes 中存在并行的概念,比如就绪检查,允许你实现相同的目的。请检查特定控制器的说明文档( nginx, GCE)以了解它们是怎样处理健康检查的。
更新 Ingress
要更新现有的 Ingress 以添加新的 Host,可以通过编辑资源来对其进行更新:
kubectl describe ingress test
Name: test
Namespace: default
Address: 178.91.123.132
Default backend: default-http-backend:80 (10.8.2.3:8080)
Rules:
Host Path Backends
---- ---- --------
foo.bar.com
/foo service1:80 (10.8.0.90:80)
Annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ADD 35s loadbalancer-controller default/test
kubectl edit ingress test
这一命令将打开编辑器,允许你以 YAML 格式编辑现有配置。修改它来增加新的主机:
spec:
rules:
- host: foo.bar.com
http:
paths:
- backend:
serviceName: service1
servicePort: 80
path: /foo
pathType: Prefix
- host: bar.baz.com
http:
paths:
- backend:
serviceName: service2
servicePort: 80
path: /foo
pathType: Prefix
..
保存更改后,kubectl 将更新 API 服务器中的资源,该资源将告诉 Ingress 控制器重新配置负载均衡器。
验证:
kubectl describe ingress test
Name: test
Namespace: default
Address: 178.91.123.132
Default backend: default-http-backend:80 (10.8.2.3:8080)
Rules:
Host Path Backends
---- ---- --------
foo.bar.com
/foo service1:80 (10.8.0.90:80)
bar.baz.com
/foo service2:80 (10.8.0.91:80)
Annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ADD 45s loadbalancer-controller default/test
你也可以通过 kubectl replace -f 命令调用修改后的 Ingress yaml 文件来获得同样的结果。
跨可用区失败
不同的云厂商使用不同的技术来实现跨故障域的流量分布。详情请查阅相关 Ingress 控制器的文档。请查看相关 Ingress 控制器的文档以了解详细信息。
替代方案
不直接使用 Ingress 资源,也有多种方法暴露 Service:
- 使用 Service.Type=LoadBalancer
- 使用 Service.Type=NodePort
Ingress 控制器
为了让 Ingress 资源工作,集群必须有一个正在运行的 Ingress 控制器。
与作为 kube-controller-manager 可执行文件的一部分运行的其他类型的控制器不同,Ingress 控制器不是随集群自动启动的。基于此页面,你可选择最适合你的集群的 ingress 控制器实现。
Kubernetes 作为一个项目,目前支持和维护 AWS, GCE 和 nginx Ingress 控制器。
其他控制器
说明: 本部分链接到提供 Kubernetes 所需功能的第三方项目。Kubernetes 项目作者不负责这些项目。此页面遵循CNCF 网站指南,按字母顺序列出项目。要将项目添加到此列表中,请在提交更改之前阅读内容指南。
- AKS 应用程序网关 Ingress 控制器是一个配置 Azure 应用程序网关的 Ingress 控制器。
- Ambassador API 网关是一个基于 Envoy 的 Ingress 控制器。
- Apache APISIX Ingress 控制器是一个基于 Apache APISIX 网关的 Ingress 控制器。
- Avi Kubernetes Operator 使用 VMware NSX Advanced Load Balancer 提供第 4 到第 7 层的负载均衡。
- BFE Ingress 控制器 是一个基于 BFE 的 Ingress 控制器。
- Citrix Ingress 控制器 可以用来与 Citrix Application Delivery Controller 一起使用。
- Contour 是一个基于 Envoy 的 Ingress 控制器。
- EnRoute 是一个基于 Envoy API 网关, 可以作为 Ingress 控制器来执行。
- Easegress IngressController 是一个基于 Easegress API 网关,可以作为 Ingress 控制器来执行。
- F5 BIG-IP 的 用于 Kubernetes 的容器 Ingress 服务 让你能够使用 Ingress 来配置 F5 BIG-IP 虚拟服务器。
- Gloo 是一个开源的、基于 Envoy 的 Ingress 控制器,能够提供 API 网关功能,
- HAProxy Ingress 针对 HAProxy 的 Ingress 控制器。
- 用于 Kubernetes 的 HAProxy Ingress 控制器 也是一个针对 HAProxy 的 Ingress 控制器。
- Istio Ingress 是一个基于 Istio 的 Ingress 控制器。
- 用于 Kubernetes 的 Kong Ingress 控制器 是一个用来驱动 Kong Gateway 的 Ingress 控制器。
- 用于 Kubernetes 的 NGINX Ingress 控制器 能够与 NGINX Web 服务器(作为代理) 一起使用。
- Skipper HTTP 路由器和反向代理可用于服务组装,支持包括 Kubernetes Ingress 这类使用场景, 设计用来作为构造你自己的定制代理的库。
- Traefik Kubernetes Ingress 提供程序 是一个用于 Traefik 代理的 Ingress 控制器。
- Tyk Operator 使用自定义资源扩展 Ingress,为之带来 API 管理能力。Tyk Operator 使用开源的 Tyk Gateway & Tyk Cloud 控制面。
- Voyager 是一个针对 HAProxy 的 Ingress 控制器。
使用多个 Ingress 控制器
你可以在集群中部署任意数量的 ingress 控制器。创建 ingress 时,应该使用适当的 ingress.class 注解每个 Ingress 以表明在集群中如果有多个 Ingress 控制器时,应该使用哪个 Ingress 控制器。
如果不定义 ingress.class,云提供商可能使用默认的 Ingress 控制器。
理想情况下,所有 Ingress 控制器都应满足此规范,但各种 Ingress 控制器的操作略有不同。
说明: 确保你查看了 ingress 控制器的文档,以了解选择它的注意事项。
拓扑感知提示
FEATURE STATE: Kubernetes v1.21 [alpha]
拓扑感知提示包含客户怎么使用服务端点的建议,从而实现了拓扑感知的路由功能。这种方法添加了元数据,以启用 EndpointSlice 和/或 Endpoints 对象的调用者,这样,访问这些网络端点的请求流量就可以在它的发起点附近就近路由。
例如,你可以在一个地域内路由流量,以降低通信成本,或提高网络性能。
动机
Kubernetes 集群越来越多的部署到多区域环境中。拓扑感知提示提供了一种把流量限制在它的发起区域之内的机制。这个概念一般被称之为 “拓扑感知路由”。在计算服务(Service)的端点时,EndpointSlice 控制器会评估每一个端点的拓扑(地域和区域),填充提示字段,并将其分配到某个区域。集群组件,例如kube-proxy 就可以使用这些提示信息,并用他们来影响流量的路由(倾向于拓扑上相邻的端点)。
使用拓扑感知提示
如果你已经启用了整个特性,就可以通过把注解 service.kubernetes.io/topology-aware-hints 的值设置为 auto,来激活服务的拓扑感知提示功能。这告诉 EndpointSlice 控制器在它认为安全的时候来设置拓扑提示。重要的是,这并不能保证总会设置提示(hints)。
工作原理
此特性启用的功能分为两个组件:EndpointSlice 控制器和 kube-proxy。本节概述每个组件如何实现此特性。
EndpointSlice 控制器
此特性开启后,EndpointSlice 控制器负责在 EndpointSlice 上设置提示信息。控制器按比例给每个区域分配一定比例数量的端点。这个比例来源于此区域中运行节点的可分配 CPU 核心数。例如,如果一个区域拥有 2 CPU 核心,而另一个区域只有 1 CPU 核心,那控制器将给那个有 2 CPU 的区域分配两倍数量的端点。
以下示例展示了提供提示信息后 EndpointSlice 的样子:
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: example-hints
labels:
kubernetes.io/service-name: example-svc
addressType: IPv4
ports:
- name: http
protocol: TCP
port: 80
endpoints:
- addresses:
- "10.1.2.3"
conditions:
ready: true
hostname: pod-1
zone: zone-a
hints:
forZones:
- name: "zone-a"
kube-proxy
kube-proxy 组件依据 EndpointSlice 控制器设置的提示,过滤由它负责路由的端点。在大多数场合,这意味着 kube-proxy 可以把流量路由到同一个区域的端点。有时,控制器从某个不同的区域分配端点,以确保在多个区域之间更平均的分配端点。这会导致部分流量被路由到其他区域。
保护措施
Kubernetes 控制平面和每个节点上的 kube-proxy,在使用拓扑感知提示功能前,会应用一些保护措施规则。如果没有检出,kube-proxy 将无视区域限制,从集群中的任意节点上选择端点。
- 端点数量不足:如果一个集群中,端点数量少于区域数量,控制器不创建任何提示。
- 不可能实现均衡分配:在一些场合中,不可能实现端点在区域中的平衡分配。例如,假设 zone-a 比 zone-b 大两倍,但只有 2 个端点,那分配到 zone-a 的端点可能收到比 zone-b多两倍的流量。如果控制器不能确定此“期望的过载”值低于每一个区域可接受的阈值,控制器将不指派提示信息。重要的是,这不是基于实时反馈。所以对于单独的端点仍有可能超载。
- 一个或多个节点信息不足:如果任一节点没有设置标签 topology.kubernetes.io/zone,或没有上报可分配的 CPU 数据,控制平面将不会设置任何拓扑感知提示,继而 kube-proxy 也就不能通过区域过滤端点。
- 一个或多个端点没有设置区域提示:当这类事情发生时,kube-proxy 会假设这是正在执行一个从/到拓扑感知提示的转移。在这种场合下过滤Service 的端点是有风险的,所以 kube-proxy 回撤为使用所有的端点。
- 不在提示中的区域:如果 kube-proxy 不能根据一个指示在它所在的区域中发现一个端点,它回撤为使用所有节点的端点。当你的集群新增一个新的区域时,这种情况发生概率很高。
限制
- 当 Service 的 externalTrafficPolicy 或 internalTrafficPolicy 设置值为 Local 时, 拓扑感知提示功能不可用。你可以在一个集群的不同服务中使用这两个特性,但不能在同一个服务中这么做。
- 这种方法不适用于大部分流量来自于一部分区域的服务。相反的,这里假设入站流量将根据每个区域中节点的服务能力按比例的分配。
- EndpointSlice 控制器在计算每一个区域的容量比例时,会忽略未就绪的节点。在大量节点未就绪的场景下,这样做会带来非预期的结果。
- EndpointSlice 控制器在计算每一个区域的部署比例时,并不会考虑容忍度。如果服务后台的 Pod 被限制只能运行在集群节点的一个子集上,这些信息并不会被使用。
- 这种方法和自动扩展机制之间不能很好的协同工作。例如,如果大量流量来源于一个区域,那只有分配到该区域的端点才可用来处理流量。这会导致 Pod 自动水平扩展要么不能拾取此事件,要么新增 Pod 被启动到其他区域。
服务内部流量策略
FEATURE STATE: Kubernetes v1.21 [alpha]
服务内部流量策略开启了内部流量限制,只路由内部流量到和发起方处于相同节点的服务端点。这里的”内部“流量指当前集群中的 Pod 所发起的流量。这种机制有助于节省开销,提升效率。
使用服务内部流量策略
一旦你启用了 ServiceInternalTrafficPolicy 这个特性门控,你就可以通过将 Services 的 .spec.internalTrafficPolicy 项设置为 Local,来为它指定一个内部专用的流量策略。此设置就相当于告诉 kube-proxy 对于集群内部流量只能使用本地的服务端口。
说明: 如果某节点上的 Pod 均不提供指定 Service 的服务端点,即使该 Service 在其他节点上有可用的服务端点,Service 的行为看起来也像是它只有 0 个服务端点(只针对此节点上的 Pod)。
以下示例展示了把 Service 的 .spec.internalTrafficPolicy 项设为 Local 时,Service 的样子:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
internalTrafficPolicy: Local
工作原理
kube-proxy 基于 spec.internalTrafficPolicy 的设置来过滤路由的目标服务端点。当它的值设为 Local 时,只选择节点本地的服务端点。当它的值设为 Cluster 或缺省时,则选择所有的服务端点。启用特性门控 ServiceInternalTrafficPolicy 后,spec.internalTrafficPolicy 的值默认设为 Cluster。
限制
在一个Service上,当 externalTrafficPolicy 已设置为 Local时,服务内部流量策略无法使用。换句话说,在一个集群的不同 Service 上可以同时使用这两个特性,但在一个 Service 上不行。
端点切片(Endpoint Slices)
FEATURE STATE: Kubernetes v1.21 [stable]
端点切片(EndpointSlices)提供了一种简单的方法来跟踪 Kubernetes 集群中的网络端点 (network endpoints)。它们为 Endpoints 提供了一种可伸缩和可拓展的替代方案。
动机
Endpoints API 提供了在 Kubernetes 跟踪网络端点的一种简单而直接的方法。不幸的是,随着 Kubernetes 集群和服务逐渐开始为更多的后端 Pods 处理和发送请求,原来的 API 的局限性变得越来越明显。最重要的是那些因为要处理大量网络端点而带来的挑战。
由于任一服务的所有网络端点都保存在同一个 Endpoints 资源中,这类资源可能变得非常巨大,而这一变化会影响到 Kubernetes 组件(比如主控组件)的性能,并在 Endpoints 变化时产生大量的网络流量和额外的处理。EndpointSlice 能够帮助你缓解这一问题,还能为一些诸如拓扑路由这类的额外功能提供一个可扩展的平台。
Endpoint Slice 资源
在 Kubernetes 中,EndpointSlice 包含对一组网络端点的引用。指定选择器后控制面会自动为设置了选择算符的 Kubernetes 服务创建 EndpointSlice。这些 EndpointSlice 将包含对与服务选择算符匹配的所有 Pod 的引用。EndpointSlice 通过唯一的协议、端口号和服务名称将网络端点组织在一起。EndpointSlice 的名称必须是合法的 DNS 子域名。
例如,下面是 Kubernetes 服务 example 的 EndpointSlice 资源示例。
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: example-abc
labels:
kubernetes.io/service-name: example
addressType: IPv4
ports:
- name: http
protocol: TCP
port: 80
endpoints:
- addresses:
- "10.1.2.3"
conditions:
ready: true
hostname: pod-1
nodeName: node-1
zone: us-west2-a
默认情况下,控制面创建和管理的 EndpointSlice 将包含不超过 100 个端点。你可以使用 kube-controller-manager 的 --max-endpoints-per-slice 标志设置此值,最大值为 1000。
当涉及如何路由内部流量时,EndpointSlice 可以充当 kube-proxy 的决策依据。启用该功能后,在服务的端点数量庞大时会有可观的性能提升。
地址类型
EndpointSlice 支持三种地址类型:
- IPv4
- IPv6
- FQDN (完全合格的域名)
状况
EndpointSlice API 存储了可能对使用者有用的、有关端点的状况。这三个状况分别是 ready、serving 和 terminating。
Ready(就绪)
ready 状况是映射 Pod 的 Ready 状况的。处于运行中的 Pod,它的 Ready 状况被设置为 True,应该将此 EndpointSlice 状况也设置为 true。出于兼容性原因,当 Pod 处于终止过程中,ready 永远不会为 true。消费者应参考 serving 状况来检查处于终止中的 Pod 的就绪情况。该规则的唯一例外是将 spec.publishNotReadyAddresses 设置为 true 的服务。这些服务(Service)的端点将始终将 ready 状况设置为 true。
Serving(服务中)
FEATURE STATE: Kubernetes v1.20 [alpha]
serving 状况与 ready 状况相同,不同之处在于它不考虑终止状态。如果 EndpointSlice API 的使用者关心 Pod 终止时的就绪情况,就应检查此状况。
说明:
尽管 serving 与 ready 几乎相同,但是它是为防止破坏 ready 的现有含义而增加的。如果对于处于终止中的端点,ready 可能是 true,那么对于现有的客户端来说可能是有些意外的,因为从始至终,Endpoints 或 EndpointSlice API 从未包含处于终止中的端点。出于这个原因,ready 对于处于终止中的端点总是 false,并且在 v1.20 中添加了新的状况 serving,以便客户端可以独立于 ready 的现有语义来跟踪处于终止中的 Pod 的就绪情况。
Terminating(终止中)
FEATURE STATE: Kubernetes v1.20 [alpha]
Terminating 是表示端点是否处于终止中的状况。对于 Pod 来说,这是设置了删除时间戳的 Pod。
拓扑信息
EndpointSlice 中的每个端点都可以包含一定的拓扑信息。拓扑信息包括端点的位置,对应节点、可用区的信息。这些信息体现为 EndpointSlices 的如下端点字段:
- nodeName - 端点所在的 Node 名称;
- zone - 端点所处的可用区。
说明:
在 v1 API 中,逐个端点设置的 topology 实际上被去除,以鼓励使用专用的字段 nodeName 和 zone。
对 EndpointSlice 对象的 endpoint 字段设置任意的拓扑结构信息这一操作已被废弃,不再被 v1 API 所支持。取而代之的是 v1 API 所支持的 nodeName 和 zone 这些独立的字段。这些字段可以在不同的 API 版本之间自动完成转译。例如,v1beta1 API 中 topology 字段的 topology.kubernetes.io/zone 取值可以在 v1 API 中通过 zone 字段访问。
管理
通常,控制面(尤其是端点切片的控制器)会创建和管理 EndpointSlice 对象。EndpointSlice 对象还有一些其他使用场景,例如作为服务网格(Service Mesh)的实现。这些场景都会导致有其他实体或者控制器负责管理额外的 EndpointSlice 集合。
为了确保多个实体可以管理 EndpointSlice 而且不会相互产生干扰,Kubernetes 定义了标签 endpointslice.kubernetes.io/managed-by,用来标明哪个实体在管理某个 EndpointSlice。端点切片控制器会在自己所管理的所有 EndpointSlice 上将该标签值设置为 endpointslice-controller.k8s.io。管理 EndpointSlice 的其他实体也应该为此标签设置一个唯一值。
属主关系
在大多数场合下,EndpointSlice 都由某个 Service 所有,(因为)该端点切片正是为该服务跟踪记录其端点。这一属主关系是通过为每个 EndpointSlice 设置一个属主(owner)引用,同时设置 kubernetes.io/service-name 标签来标明的,目的是方便查找隶属于某服务的所有 EndpointSlice。
EndpointSlice 镜像
在某些场合,应用会创建定制的 Endpoints 资源。为了保证这些应用不需要并发的更改 Endpoints 和 EndpointSlice 资源,集群的控制面将大多数 Endpoints 映射到对应的 EndpointSlice 之上。
控制面对 Endpoints 资源进行映射的例外情况有:
- Endpoints 资源上标签 endpointslice.kubernetes.io/skip-mirror 值为 true。
- Endpoints 资源包含标签 control-plane.alpha.kubernetes.io/leader。
- 对应的 Service 资源不存在。
- 对应的 Service 的选择算符不为空。
每个 Endpoints 资源可能会被翻译到多个 EndpointSlices 中去。当 Endpoints 资源中包含多个子网或者包含多个 IP 地址族(IPv4 和 IPv6)的端点时,就有可能发生这种状况。每个子网最多有 1000 个地址会被镜像到 EndpointSlice 中。
EndpointSlices 的分布问题
每个 EndpointSlice 都有一组端口值,适用于资源内的所有端点。当为服务使用命名端口时,Pod 可能会就同一命名端口获得不同的端口号,因而需要不同的 EndpointSlice。这有点像 Endpoints 用来对子网进行分组的逻辑。
控制面尝试尽量将 EndpointSlice 填满,不过不会主动地在若干 EndpointSlice 之间执行再平衡操作。这里的逻辑也是相对直接的:
- 列举所有现有的 EndpointSlices,移除那些不再需要的端点并更新那些已经变化的端点。
- 列举所有在第一步中被更改过的 EndpointSlices,用新增加的端点将其填满。
- 如果还有新的端点未被添加进去,尝试将这些端点添加到之前未更改的切片中,或者创建新切片。
这里比较重要的是,与在 EndpointSlice 之间完成最佳的分布相比,第三步中更看重限制 EndpointSlice 更新的操作次数。例如,如果有 10 个端点待添加,有两个 EndpointSlice 中各有 5 个空位,上述方法会创建一个新的 EndpointSlice 而不是将现有的两个 EndpointSlice 都填满。换言之,与执行多个 EndpointSlice 更新操作相比较,方法会优先考虑执行一个 EndpointSlice 创建操作。
由于 kube-proxy 在每个节点上运行并监视 EndpointSlice 状态,EndpointSlice 的每次变更都变得相对代价较高,因为这些状态变化要传递到集群中每个节点上。这一方法尝试限制要发送到所有节点上的变更消息个数,即使这样做可能会导致有多个 EndpointSlice 没有被填满。
在实践中,上面这种并非最理想的分布是很少出现的。大多数被 EndpointSlice 控制器处理的变更都是足够小的,可以添加到某已有 EndpointSlice 中去的。并且,假使无法添加到已有的切片中,不管怎样都会快就会需要一个新的 EndpointSlice 对象。Deployment 的滚动更新为重新为 EndpointSlice 打包提供了一个自然的机会,所有 Pod 及其对应的端点在这一期间都会被替换掉。
重复的端点
由于 EndpointSlice 变化的自身特点,端点可能会同时出现在不止一个 EndpointSlice 中。鉴于不同的 EndpointSlice 对象在不同时刻到达 Kubernetes 的监视/缓存中,这种情况的出现是很自然的。使用 EndpointSlice 的实现必须能够处理端点出现在多个切片中的状况。关于如何执行端点去重(deduplication)的参考实现,你可以在 kube-proxy 的 EndpointSlice 实现中找到。
网络策略
如果你希望在 IP 地址或端口层面(OSI 第 3 层或第 4 层)控制网络流量,则你可以考虑为集群中特定应用使用 Kubernetes 网络策略(NetworkPolicy)。NetworkPolicy 是一种以应用为中心的结构,允许你设置如何允许 Pod 与网络上的各类网络“实体” (我们这里使用实体以避免过度使用诸如“端点”和“服务”这类常用术语,这些术语在 Kubernetes 中有特定含义)通信。
Pod 可以通信的 Pod 是通过如下三个标识符的组合来辩识的:
- 其他被允许的 Pods(例外:Pod 无法阻塞对自身的访问)
- 被允许的名字空间
- IP 组块(例外:与 Pod 运行所在的节点的通信总是被允许的,无论 Pod 或节点的 IP 地址)
在定义基于 Pod 或名字空间的 NetworkPolicy 时,你会使用选择算符来设定哪些流量可以进入或离开与该算符匹配的 Pod。
同时,当基于 IP 的 NetworkPolicy 被创建时,我们基于 IP 组块(CIDR 范围)来定义策略。
前置条件
网络策略通过网络插件来实现。要使用网络策略,你必须使用支持 NetworkPolicy 的网络解决方案。创建一个 NetworkPolicy 资源对象而没有控制器来使它生效的话,是没有任何作用的。
隔离和非隔离的 Pod
默认情况下,Pod 是非隔离的,它们接受任何来源的流量。
Pod 在被某 NetworkPolicy 选中时进入被隔离状态。一旦名字空间中有 NetworkPolicy 选择了特定的 Pod,该 Pod 会拒绝该 NetworkPolicy 所不允许的连接。(名字空间下其他未被 NetworkPolicy 所选择的 Pod 会继续接受所有的流量)
网络策略不会冲突,它们是累积的。如果任何一个或多个策略选择了一个 Pod, 则该 Pod 受限于这些策略的入站(Ingress)/出站(Egress)规则的并集。因此评估的顺序并不会影响策略的结果。
为了允许两个 Pods 之间的网络数据流,源端 Pod 上的出站(Egress)规则和目标端 Pod 上的入站(Ingress)规则都需要允许该流量。如果源端的出站(Egress)规则或目标端的入站(Ingress)规则拒绝该流量,则流量将被拒绝。
NetworkPolicy 资源
参阅 NetworkPolicy 来了解资源的完整定义。
下面是一个 NetworkPolicy 的示例:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
role: db
policyTypes:
- Ingress
- Egress
ingress:
- from:
- ipBlock:
cidr: 172.17.0.0/16
except:
- 172.17.1.0/24
- namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 5978
说明: 除非选择支持网络策略的网络解决方案,否则将上述示例发送到API服务器没有任何效果。
必需字段: 与所有其他的 Kubernetes 配置一样,NetworkPolicy 需要 apiVersion、kind 和metadata 字段。关于配置文件操作的一般信息,请参考使用 ConfigMap 配置容器,和对象管理。
spec: NetworkPolicy 规约中包含了在一个名字空间中定义特定网络策略所需的所有信息。
podSelector: 每个 NetworkPolicy 都包括一个 podSelector,它对该策略所适用的一组 Pod 进行选择。示例中的策略选择带有 "role=db" 标签的 Pod。空的 podSelector 选择名字空间下的所有 Pod。
policyTypes: 每个 NetworkPolicy 都包含一个 policyTypes 列表,其中包含 Ingress 或 Egress 或两者兼具。policyTypes 字段表示给定的策略是应用于进入所选 Pod 的入站流量还是来自所选 Pod 的出站流量,或两者兼有。如果 NetworkPolicy 未指定 policyTypes 则默认情况下始终设置 Ingress;如果 NetworkPolicy 有任何出口规则的话则设置 Egress。
ingress: 每个 NetworkPolicy 可包含一个 ingress 规则的白名单列表。每个规则都允许同时匹配 from 和 ports 部分的流量。示例策略中包含一条简单的规则:它匹配某个特定端口,来自三个来源中的一个,第一个通过 ipBlock 指定,第二个通过 namespaceSelector 指定,第三个通过 podSelector 指定。
egress: 每个 NetworkPolicy 可包含一个 egress 规则的白名单列表。每个规则都允许匹配 to 和 port 部分的流量。该示例策略包含一条规则,该规则将指定端口上的流量匹配到 10.0.0.0/24 中的任何目的地。
所以,该网络策略示例:
-
隔离 "default" 名字空间下 "role=db" 的 Pod(如果它们不是已经被隔离的话)。
-
(Ingress 规则)允许以下 Pod 连接到 "default" 名字空间下的带有 "role=db" 标签的所有 Pod 的 6379 TCP 端口:
- "default" 名字空间下带有 "role=frontend" 标签的所有 Pod
- 带有 "project=myproject" 标签的所有名字空间中的 Pod
- IP 地址范围为 172.17.0.0–172.17.0.255 和 172.17.2.0–172.17.255.255 (即,除了 172.17.1.0/24 之外的所有 172.17.0.0/16)
-
(Egress 规则)允许从带有 "role=db" 标签的名字空间下的任何 Pod 到 CIDR 10.0.0.0/24 下 5978 TCP 端口的连接。
选择器 to 和 from 的行为
可以在 ingress 的 from 部分或 egress 的 to 部分中指定四种选择器:
podSelector: 此选择器将在与 NetworkPolicy 相同的名字空间中选择特定的 Pod,应将其允许作为入站流量来源或出站流量目的地。
namespaceSelector: 此选择器将选择特定的名字空间,应将所有 Pod 用作其入站流量来源或出站流量目的地。
namespaceSelector 和 podSelector: 一个指定 namespaceSelector 和 podSelector 的 to/from 条目选择特定名字空间中的特定 Pod。注意使用正确的 YAML 语法;下面的策略:
...
ingress:
- from:
- namespaceSelector:
matchLabels:
user: alice
podSelector:
matchLabels:
role: client
...
在 from 数组中仅包含一个元素,只允许来自标有 role=client 的 Pod 且 该 Pod 所在的名字空间中标有 user=alice 的连接。但是这项策略:
...
ingress:
- from:
- namespaceSelector:
matchLabels:
user: alice
- podSelector:
matchLabels:
role: client
...
在 from 数组中包含两个元素,允许来自本地名字空间中标有 role=client 的 Pod 的连接,或来自任何名字空间中标有 user=alice 的任何 Pod 的连接。
如有疑问,请使用 kubectl describe 查看 Kubernetes 如何解释该策略。
ipBlock: 此选择器将选择特定的 IP CIDR 范围以用作入站流量来源或出站流量目的地。这些应该是集群外部 IP,因为 Pod IP 存在时间短暂的且随机产生。
集群的入站和出站机制通常需要重写数据包的源 IP 或目标 IP。在发生这种情况时,不确定在 NetworkPolicy 处理之前还是之后发生,并且对于网络插件、云提供商、Service 实现等的不同组合,其行为可能会有所不同。
对入站流量而言,这意味着在某些情况下,你可以根据实际的原始源 IP 过滤传入的数据包,而在其他情况下,NetworkPolicy 所作用的源IP 则可能是 LoadBalancer 或 Pod 的节点等。
对于出站流量而言,这意味着从 Pod 到被重写为集群外部 IP 的 Service IP 的连接可能会或可能不会受到基于 ipBlock 的策略的约束。
默认策略
默认情况下,如果名字空间中不存在任何策略,则所有进出该名字空间中 Pod 的流量都被允许。以下示例使你可以更改该名字空间中的默认行为。
默认拒绝所有入站流量
你可以通过创建选择所有容器但不允许任何进入这些容器的入站流量的 NetworkPolicy 来为名字空间创建 "default" 隔离策略。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress
spec:
podSelector: {}
policyTypes:
- Ingress
这样可以确保即使容器没有选择其他任何 NetworkPolicy,也仍然可以被隔离。此策略不会更改默认的出口隔离行为。
默认允许所有入站流量
如果要允许所有流量进入某个名字空间中的所有 Pod(即使添加了导致某些 Pod 被视为 “隔离”的策略),则可以创建一个策略来明确允许该名字空间中的所有流量。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-ingress
spec:
podSelector: {}
ingress:
- {}
policyTypes:
- Ingress
默认拒绝所有出站流量
你可以通过创建选择所有容器但不允许来自这些容器的任何出站流量的 NetworkPolicy 来为名字空间创建 "default" egress 隔离策略。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-egress
spec:
podSelector: {}
policyTypes:
- Egress
此策略可以确保即使没有被其他任何 NetworkPolicy 选择的 Pod 也不会被允许流出流量。此策略不会更改默认的入站流量隔离行为。
默认允许所有出站流量
如果要允许来自名字空间中所有 Pod 的所有流量(即使添加了导致某些 Pod 被视为“隔离”的策略), 则可以创建一个策略,该策略明确允许该名字空间中的所有出站流量。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-egress
spec:
podSelector: {}
egress:
- {}
policyTypes:
- Egress
默认拒绝所有入口和所有出站流量
你可以为名字空间创建“默认”策略,以通过在该名字空间中创建以下 NetworkPolicy 来阻止所有入站和出站流量。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-all
spec:
podSelector: {}
policyTypes:
- Ingress
- Egress
此策略可以确保即使没有被其他任何 NetworkPolicy 选择的 Pod 也不会被允许入站或出站流量。
SCTP 支持
FEATURE STATE: Kubernetes v1.20 [stable]
作为一个稳定特性,SCTP 支持默认是被启用的。要在集群层面禁用 SCTP,你(或你的集群管理员)需要为 API 服务器指定 --feature-gates=SCTPSupport=false,... 来禁用 SCTPSupport 特性门控。启用该特性门控后,用户可以将 NetworkPolicy 的 protocol 字段设置为 SCTP。
说明:
你必须使用支持 SCTP 协议网络策略的 CNI 插件。
针对某个端口范围
FEATURE STATE: Kubernetes v1.22 [beta]
在编写 NetworkPolicy 时,你可以针对一个端口范围而不是某个固定端口。
这一目的可以通过使用 endPort 字段来实现,如下例所示:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: multi-port-egress
namespace: default
spec:
podSelector:
matchLabels:
role: db
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 32000
endPort: 32768
上面的规则允许名字空间 default 中所有带有标签 db 的 Pod 使用 TCP 协议与 10.0.0.0/24 范围内的 IP 通信,只要目标端口介于 32000 和 32768 之间就可以。
使用此字段时存在以下限制:
- 作为一种 Beta 阶段的特性,端口范围设定默认是被启用的。要在整个集群范围内禁止使用 endPort 字段,你(或者你的集群管理员)需要为 API 服务器设置 -feature-gates=NetworkPolicyEndPort=false,... 以禁用 NetworkPolicyEndPort 特性门控。
- endPort 字段必须等于或者大于 port 字段的值。
- 两个字段的设置值都只能是数字。
说明:
你的集群所使用的 CNI 插件必须支持在 NetworkPolicy 规约中使用 endPort 字段。如果你的网络插件不支持 endPort 字段,而你指定了一个包含 endPort 字段的 NetworkPolicy,策略只对单个 port 字段生效。
基于名字指向某名字空间
FEATURE STATE: Kubernetes 1.21 [beta]
只要 NamespaceDefaultLabelName 特性门控被启用,Kubernetes 控制面会在所有名字空间上设置一个不可变更的标签 kubernetes.io/metadata.name。该标签的值是名字空间的名称。
如果 NetworkPolicy 无法在某些对象字段中指向某名字空间,你可以使用标准的标签方式来指向特定名字空间。
通过网络策略(至少目前还)无法完成的工作
到 Kubernetes 1.23 为止,NetworkPolicy API 还不支持以下功能,不过你可能可以使用操作系统组件(如 SELinux、OpenVSwitch、IPTables 等等)或者第七层技术(Ingress 控制器、服务网格实现)或准入控制器来实现一些替代方案。如果你对 Kubernetes 中的网络安全性还不太了解,了解使用 NetworkPolicy API 还无法实现下面的用户场景是很值得的。
- 强制集群内部流量经过某公用网关(这种场景最好通过服务网格或其他代理来实现);
- 与 TLS 相关的场景(考虑使用服务网格或者 Ingress 控制器);
- 特定于节点的策略(你可以使用 CIDR 来表达这一需求不过你无法使用节点在 Kubernetes 中的其他标识信息来辩识目标节点);
- 基于名字来选择服务(不过,你可以使用标签来选择目标 Pod 或名字空间,这也通常是一种可靠的替代方案);
- 创建或管理由第三方来实际完成的“策略请求”;
- 实现适用于所有名字空间或 Pods 的默认策略(某些第三方 Kubernetes 发行版本或项目可以做到这点);
- 高级的策略查询或者可达性相关工具;
- 生成网络安全事件日志的能力(例如,被阻塞或接收的连接请求);
- 显式地拒绝策略的能力(目前,NetworkPolicy 的模型默认采用拒绝操作,其唯一的能力是添加允许策略);
- 禁止本地回路或指向宿主的网络流量(Pod 目前无法阻塞 localhost 访问,它们也无法禁止来自所在节点的访问请求)。
IPv4/IPv6 双协议栈
FEATURE STATE: Kubernetes v1.21 [beta]
IPv4/IPv6 双协议栈网络能够将 IPv4 和 IPv6 地址分配给 Pod 和 Service。
从 1.21 版本开始,Kubernetes 集群默认启用 IPv4/IPv6 双协议栈网络,以支持同时分配 IPv4 和 IPv6 地址。
支持的功能
Kubernetes 集群的 IPv4/IPv6 双协议栈可提供下面的功能:
- 双协议栈 pod 网络(每个 pod 分配一个 IPv4 和 IPv6 地址)
- IPv4 和 IPv6 启用的服务
- Pod 的集群外出口通过 IPv4 和 IPv6 路由
先决条件
为了使用 IPv4/IPv6 双栈的 Kubernetes 集群,需要满足以下先决条件:
- Kubernetes 1.20 版本或更高版本,有关更早 Kubernetes 版本的使用双栈服务的信息,请参考对应版本的 Kubernetes 文档。
- 提供商支持双协议栈网络(云提供商或其他提供商必须能够为 Kubernetes 节点提供可路由的 IPv4/IPv6 网络接口)
- 支持双协议栈的网络插件(如 Kubenet 或 Calico)
配置 IPv4/IPv6 双协议栈
要使用 IPv4/IPv6 双协议栈,确保为集群的相关组件启用 IPv6DualStack 特性门控,(从 1.21 版本开始,IPv4/IPv6 双协议栈默认是被启用的)。
- kube-apiserver:
--service-cluster-ip-range=<IPv4 CIDR>,<IPv6 CIDR>
- kube-controller-manager:
--cluster-cidr=<IPv4 CIDR>,<IPv6 CIDR>--service-cluster-ip-range=<IPv4 CIDR>,<IPv6 CIDR>- --node-cidr-mask-size-ipv4|--node-cidr-mask-size-ipv6 对于 IPv4 默认为 /24,对于 IPv6 默认为 /64
- kube-proxy:
--cluster-cidr=<IPv4 CIDR>,<IPv6 CIDR>
说明:
IPv4 CIDR 的一个例子:10.244.0.0/16(尽管你会提供你自己的地址范围)。
IPv6 CIDR 的一个例子:fdXY:IJKL:MNOP:15::/64 (这里演示的是格式而非有效地址 - 请看 RFC 4193)。
从 1.21 开始 IPv4/IPv6 双协议栈默认为启用状态。你可以在必要的时候通过为 kube-apiserver、kube-controller-manager、kubelet 和 kube-proxy 命令行设置 --feature-gates="IPv6DualStack=false" 来禁用此特性。
服务
你可以使用 IPv4 或 IPv6 地址来创建 Service。服务的地址族默认为第一个服务集群 IP 范围的地址族(通过 kube-apiserver 的 --service-cluster-ip-range 参数配置)。当你定义服务时,可以选择将其配置为双栈。若要指定所需的行为,你可以设置 .spec.ipFamilyPolicy 字段为以下值之一:
- SingleStack:单栈服务。控制面使用第一个配置的服务集群 IP 范围为服务分配集群 IP。
- PreferDualStack:
- 为服务分配 IPv4 和 IPv6 集群 IP 地址。(如果集群设置了 --feature-gates="IPv6DualStack=false",则此设置的行为与 SingleStack 设置相同。)
- RequireDualStack:从 IPv4 和 IPv6 的地址范围分配服务的 .spec.ClusterIPs
- 从基于在 .spec.ipFamilies 数组中第一个元素的地址族的 .spec.ClusterIPs 列表中选择 .spec.ClusterIP
如果你想要定义哪个 IP 族用于单栈或定义双栈 IP 族的顺序,可以通过设置服务上的可选字段 .spec.ipFamilies 来选择地址族。
说明:
.spec.ipFamilies 字段是不可变的,因为系统无法为已经存在的服务重新分配 .spec.ClusterIP 如果你想改变 .spec.ipFamilies,则需要删除并重新创建服务。
你可以设置 .spec.ipFamily 为以下任何数组值:
- ["IPv4"]
- ["IPv6"]
- ["IPv4","IPv6"] (双栈)
- ["IPv6","IPv4"] (双栈)
你所列出的第一个地址族用于原来的 .spec.ClusterIP 字段。
双栈服务配置场景
以下示例演示多种双栈服务配置场景下的行为。
新服务的双栈选项
- 此服务规约中没有显式设定 .spec.ipFamilyPolicy。当你创建此服务时,Kubernetes 从所配置的第一个 service-cluster-ip-range 种为服务分配一个集群IP,并设置 .spec.ipFamilyPolicy 为 SingleStack。(无选择算符的服务和无头服务的行为方式与此相同。)
apiVersion: v1
kind: Service
metadata:
name: my-service
labels:
app: MyApp
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
-
此服务规约显式地将 .spec.ipFamilyPolicy 设置为 PreferDualStack。当你在双栈集群上创建此服务时,Kubernetes 会为该服务分配 IPv4 和 IPv6 地址。控制平面更新服务的 .spec 以记录 IP 地址分配。字段 .spec.ClusterIPs 是主要字段,包含两个分配的 IP 地址;.spec.ClusterIP 是次要字段,其取值从 .spec.ClusterIPs 计算而来。
- 对于 .spec.ClusterIP 字段,控制面记录来自第一个服务集群 IP 范围对应的地址族的 IP 地址。
- 对于单协议栈的集群,.spec.ClusterIPs 和 .spec.ClusterIP 字段都仅仅列出一个地址。
- 对于启用了双协议栈的集群,将 .spec.ipFamilyPolicy 设置为 RequireDualStack 时,其行为与 PreferDualStack 相同。
apiVersion: v1
kind: Service
metadata:
name: my-service
labels:
app: MyApp
spec:
ipFamilyPolicy: PreferDualStack
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
- 下面的服务规约显式地在 .spec.ipFamilies 中指定 IPv6 和 IPv4,并将 .spec.ipFamilyPolicy 设定为 PreferDualStack。当 Kubernetes 为 .spec.ClusterIPs 分配一个 IPv6 和一个 IPv4 地址时,.spec.ClusterIP 被设置成 IPv6 地址,因为它是 .spec.ClusterIPs 数组中的第一个元素,覆盖其默认值。
apiVersion: v1
kind: Service
metadata:
name: my-service
labels:
app: MyApp
spec:
ipFamilyPolicy: PreferDualStack
ipFamilies:
- IPv6
- IPv4
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
现有服务的双栈默认值
下面示例演示了在服务已经存在的集群上新启用双栈时的默认行为。(将现有集群升级到 1.21 会启用双协议栈支持,除非设置了 --feature-gates="IPv6DualStack=false")
- 在集群上启用双栈时,控制面会将现有服务(无论是 IPv4 还是 IPv6)配置 .spec.ipFamilyPolicy 为 SingleStack 并设置 .spec.ipFamilies 为服务的当前地址族。
apiVersion: v1
kind: Service
metadata:
name: my-service
labels:
app: MyApp
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
你可以通过使用 kubectl 检查现有服务来验证此行为。
kubectl get svc my-service -o yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: MyApp
name: my-service
spec:
clusterIP: 10.0.197.123
clusterIPs:
- 10.0.197.123
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: MyApp
type: ClusterIP
status:
loadBalancer: {}
- 在集群上启用双栈时,带有选择算符的现有无头服务由控制面设置 .spec.ipFamilyPolicy 为 SingleStack 并设置 .spec.ipFamilies 为第一个服务集群 IP 范围的地址族(通过配置 kube-apiserver 的 --service-cluster-ip-range 参数),即使 .spec.ClusterIP 的设置值为 None 也如此。
apiVersion: v1
kind: Service
metadata:
name: my-service
labels:
app: MyApp
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
你可以通过使用 kubectl 检查带有选择算符的现有无头服务来验证此行为。
kubectl get svc my-service -o yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: MyApp
name: my-service
spec:
clusterIP: None
clusterIPs:
- None
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: MyApp
在单栈和双栈之间切换服务
服务可以从单栈更改为双栈,也可以从双栈更改为单栈。
- 要将服务从单栈更改为双栈,根据需要将 .spec.ipFamilyPolicy 从 SingleStack 改为 PreferDualStack 或 RequireDualStack。当你将此服务从单栈更改为双栈时,Kubernetes 将分配缺失的地址族,以便现在该服务具有 IPv4 和 IPv6 地址。编辑服务规约将 .spec.ipFamilyPolicy 从 SingleStack 改为 PreferDualStack。
之前:
spec:
ipFamilyPolicy: SingleStack
之后:
spec:
ipFamilyPolicy: PreferDualStack
要将服务从双栈更改为单栈,请将 .spec.ipFamilyPolicy 从 PreferDualStack 或 RequireDualStack 改为 SingleStack。当你将此服务从双栈更改为单栈时,Kubernetes 只保留 .spec.ClusterIPs 数组中的第一个元素,并设置 .spec.ClusterIP 为那个 IP 地址,并设置 .spec.ipFamilies 为 .spec.ClusterIPs 地址族。
无选择算符的无头服务
对于不带选择算符的无头服务,若没有显式设置 .spec.ipFamilyPolicy,则 .spec.ipFamilyPolicy 字段默认设置为 RequireDualStack。
LoadBalancer 类型服务
要为你的服务提供双栈负载均衡器:
- 将 .spec.type 字段设置为 LoadBalancer
- 将 .spec.ipFamilyPolicy 字段设置为 PreferDualStack 或者 RequireDualStack
说明:
为了使用双栈的负载均衡器类型服务,你的云驱动必须支持 IPv4 和 IPv6 的负载均衡器。
出站流量
如果你要启用出站流量,以便使用非公开路由 IPv6 地址的 Pod 到达集群外地址(例如公网),则需要通过透明代理或 IP 伪装等机制使 Pod 使用公共路由的 IPv6 地址。ip-masq-agent项目支持在双栈集群上进行 IP 伪装。
说明:
确认你的 CNI 驱动支持 IPv6。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号