[K8s]Kubernetes-扩展
扩展 Kubernetes
改变你的 Kubernetes 集群的行为的若干方法。
Kubernetes 是高度可配置且可扩展的。因此,大多数情况下,你不需要派生自己的 Kubernetes 副本或者向项目代码提交补丁。
本指南描述定制 Kubernetes 的可选方式。主要针对的读者是希望了解如何针对自身工作环境需要来调整 Kubernetes 的集群管理者。对于那些充当平台开发人员的开发人员或 Kubernetes 项目的贡献者而言,他们也会在本指南中找到有用的介绍信息,了解系统中存在哪些扩展点和扩展模式,以及它们所附带的各种权衡和约束等等。
概述
定制化的方法主要可分为配置(Configuration)和扩展(Extensions)两种。前者主要涉及改变参数标志、本地配置文件或者 API 资源;后者则需要额外运行一些程序或服务。本文主要关注扩展。
Configuration
配置文件和参数标志的说明位于在线文档的参考章节,按可执行文件组织:
- kubelet
- kube-apiserver
- kube-controller-manager
- kube-scheduler
在托管的 Kubernetes 服务中或者受控安装的发行版本中,参数标志和配置文件不总是可以修改的。即使它们是可修改的,通常其修改权限也仅限于集群管理员。此外,这些内容在将来的 Kubernetes 版本中很可能发生变化,设置新参数或配置文件可能需要重启进程。有鉴于此,通常应该在没有其他替代方案时才应考虑更改参数标志和配置文件。
内置的策略 API,例如 ResourceQuota、PodSecurityPolicies、NetworkPolicy 和基于角色的访问控制(RBAC)等等都是内置的 Kubernetes API。API 通常用于托管的 Kubernetes 服务和受控的 Kubernetes 安装环境中。这些 API 是声明式的,与 Pod 这类其他 Kubernetes 资源遵从相同的约定,所以新的集群配置是可复用的,并且可以当作应用程序来管理。此外,对于稳定版本的 API 而言,它们与其他 Kubernetes API 一样,采纳的是一种预定义的支持策略。出于以上原因,在条件允许的情况下,基于 API 的方案应该优先于配置文件和参数标志。
扩展
扩展(Extensions)是一些扩充 Kubernetes 能力并与之深度集成的软件组件。它们调整 Kubernetes 的工作方式使之支持新的类型和新的硬件种类。
大多数集群管理员会使用一种托管的 Kubernetes 服务或者其某种发行版本。因此,大多数 Kubernetes 用户不需要安装扩展,至于需要自己编写新的扩展的情况就更少了。
扩展模式
Kubernetes 从设计上即支持通过编写客户端程序来将其操作自动化。任何能够对 Kubernetes API 发出读写指令的程序都可以提供有用的自动化能力。自动化组件可以运行在集群上,也可以运行在集群之外。通过遵从本文中的指南,你可以编写高度可用的、运行稳定的自动化组件。自动化组件通常可以用于所有 Kubernetes 集群,包括托管的集群和受控的安装环境。
编写客户端程序有一种特殊的 Controller(控制器) 模式,能够与 Kubernetes 很好地协同工作。控制器通常会读取某个对象的 .spec,或许还会执行一些操作,之后更新对象的 .status。Controller(控制器) 是 Kubernetes 的客户端。
当 Kubernetes 充当客户端,调用某远程服务时,对应的远程组件称作 Webhook。远程服务称作Webhook 后端。与控制器模式相似,Webhook 也会在整个架构中引入新的失效点(Point of Failure)。
在 Webhook 模式中,Kubernetes 向远程服务发起网络请求。在可执行文件插件(Binary Plugin)模式中,Kubernetes 执行某个可执行文件(程序)。可执行文件插件在 kubelet(例如,FlexVolume 插件和网络插件)和 kubectl 中使用。
下面的示意图中展示了这些扩展点如何与 Kubernetes 控制面交互。
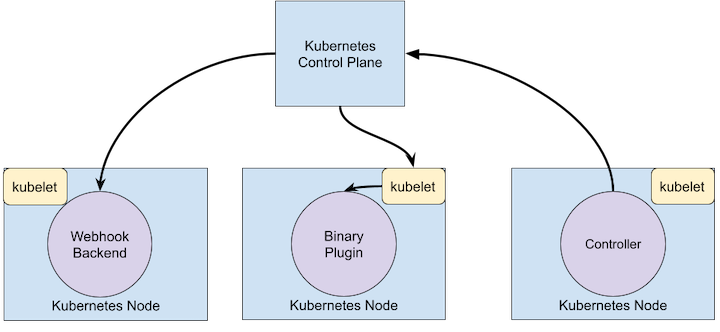
扩展点
此示意图显示的是 Kubernetes 系统中的扩展点。
-
用户通常使用 kubectl 与 Kubernetes API 交互。kubectl 插件能够扩展 kubectl 程序的行为。这些插件只会影响到每个用户的本地环境,因此无法用来强制实施整个站点范围的策略。
-
API 服务器处理所有请求。API 服务器中的几种扩展点能够使用户对请求执行身份认证、基于其内容阻止请求、编辑请求内容、处理删除操作等等。这些扩展点在 API 访问扩展节详述。
-
API 服务器向外提供不同类型的资源(resources)。内置的资源类型,如 pods,是由 Kubernetes 项目所定义的,无法改变。你也可以添加自己定义的或者其他项目所定义的称作自定义资源(Custom Resources)的资源,正如自定义资源节所描述的那样。自定义资源通常与 API 访问扩展点结合使用。
-
Kubernetes 调度器负责决定 Pod 要放置到哪些节点上执行。有几种方式来扩展调度行为。这些方法将在调度器扩展节中展开。
-
Kubernetes 中的很多行为都是通过称为控制器(Controllers)的程序来实现的,这些程序也都是 API 服务器的客户端。控制器常常与自定义资源结合使用。
-
组件 kubelet 运行在各个节点上,帮助 Pod 展现为虚拟的服务器并在集群网络中拥有自己的 IP。网络插件使得 Kubernetes 能够采用不同实现技术来连接 Pod 网络。
-
组件 kubelet 也会为容器增加或解除存储卷的挂载。通过存储插件,可以支持新的存储类型。
如果你无法确定从何处入手,下面的流程图可能对你有些帮助。注意,某些方案可能需要同时采用几种类型的扩展。
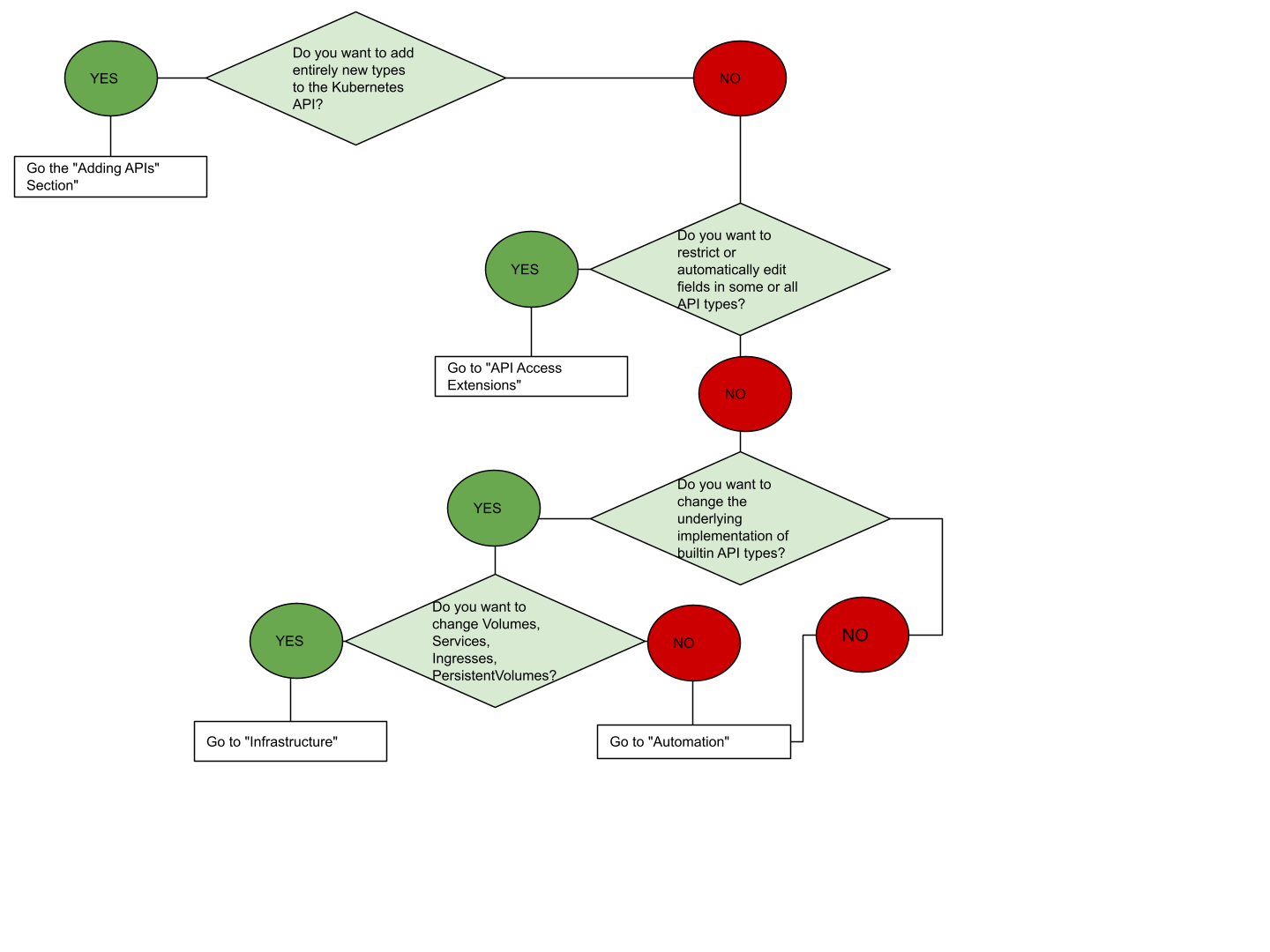
API 扩展
用户定义的类型
如果你想要定义新的控制器、应用配置对象或者其他声明式 API,并且使用 Kubernetes 工具(如 kubectl)来管理它们,可以考虑向 Kubernetes 添加自定义资源。
不要使用自定义资源来充当应用、用户或者监控数据的数据存储。
结合使用新 API 与自动化组件
自定义资源 API 与控制回路的组合称作 Operator 模式。Operator 模式用来管理特定的、通常是有状态的应用。这些自定义 API 和控制回路也可用来控制其他资源,如存储或策略。
更改内置资源
当你通过添加自定义资源来扩展 Kubernetes 时,所添加的资源通常会被放在一个新的 API 组中。你不可以替换或更改现有的 API 组。添加新的 API 不会直接让你影响现有 API(如 Pods)的行为,不过 API 访问扩展能够实现这点。
API 访问扩展
当请求到达 Kubernetes API 服务器时,首先要经过身份认证,之后是鉴权操作,再之后要经过若干类型的准入控制器的检查。
这些步骤中都存在扩展点。
Kubernetes 提供若干内置的身份认证方法。它也可以运行在某中身份认证代理的后面,并且可以将来自鉴权头部的令牌发送到某个远程服务(Webhook)来执行验证操作。所有这些方法都在身份认证文档中有详细论述。
身份认证
身份认证负责将所有请求中的头部或证书映射到发出该请求的客户端的用户名。
Kubernetes 提供若干种内置的认证方法,以及认证 Webhook 方法以备内置方法无法满足你的要求。
鉴权
鉴权操作负责确定特定的用户是否可以读、写 API 资源或对其执行其他操作。此操作仅在整个资源集合的层面进行。换言之,它不会基于对象的特定字段作出不同的判决。如果内置的鉴权选项无法满足你的需要,你可以使用鉴权 Webhook 来调用用户提供的代码,执行定制的鉴权操作。
动态准入控制
请求的鉴权操作结束之后,如果请求的是写操作,还会经过准入控制处理步骤。除了内置的处理步骤,还存在一些扩展点:
- Image Policy webhook 能够限制容器中可以运行哪些镜像。
- 为了执行任意的准入控制,可以使用一种通用的 Admission webhook 机制。这类 Webhook 可以拒绝对象创建或更新请求。
基础设施扩展
存储插件
FlexVolumes 卷可以让用户挂载无需内建支持的卷类型,kubelet 会调用可执行文件插件来挂载对应的存储卷。
设备插件
使用设备插件,节点能够发现新的节点资源(除了内置的类似 CPU 和内存这类资源)。
网络插件
通过节点层面的网络插件,可以支持不同的网络设施。
调度器扩展
调度器是一种特殊的控制器,负责监视 Pod 变化并将 Pod 分派给节点。默认的调度器可以被整体替换掉,同时继续使用其他 Kubernetes 组件。或者也可以在同一时刻使用多个调度器。
这是一项非同小可的任务,几乎绝大多数 Kubernetes 用户都会发现其实他们不需要修改调度器。
调度器也支持一种 Webhook,允许使用某种 Webhook 后端(调度器扩展)来为 Pod 可选的节点执行过滤和优先排序操作。
1 - 扩展 Kubernetes API
1.1 - 定制资源
定制资源(Custom Resource)是对 Kubernetes API 的扩展。本页讨论何时向 Kubernetes 集群添加定制资源,何时使用独立的服务。本页描述添加定制资源的两种方法以及怎样在二者之间做出抉择。
定制资源
资源(Resource)是 Kubernetes API 中的一个端点,其中存储的是某个类别的 API 对象的一个集合。例如内置的 pods 资源包含一组 Pod 对象。
定制资源(Custom Resource)是对 Kubernetes API 的扩展,不一定在默认的 Kubernetes 安装中就可用。定制资源所代表的是对特定 Kubernetes 安装的一种定制。不过,很多 Kubernetes 核心功能现在都用定制资源来实现,这使得 Kubernetes 更加模块化。
定制资源可以通过动态注册的方式在运行中的集群内或出现或消失,集群管理员可以独立于集群更新定制资源。一旦某定制资源被安装,用户可以使用 kubectl 来创建和访问其中的对象,就像他们为 pods 这种内置资源所做的一样。
定制控制器
就定制资源本身而言,它只能用来存取结构化的数据。当你将定制资源与定制控制器(Custom Controller)相结合时,定制资源就能够提供真正的声明式 API(Declarative API)。
使用声明式 API,你可以声明或者设定你的资源的期望状态,并尝试让 Kubernetes 对象的当前状态同步到其期望状态。控制器负责将结构化的数据解释为用户所期望状态的记录,并持续地维护该状态。
你可以在一个运行中的集群上部署和更新定制控制器,这类操作与集群的生命周期无关。定制控制器可以用于任何类别的资源,不过它们与定制资源结合起来时最为有效。Operator 模式就是将定制资源与定制控制器相结合的。你可以使用定制控制器来将特定于某应用的领域知识组织起来,以编码的形式构造对 Kubernetes API 的扩展。
我是否应该向我的 Kubernetes 集群添加定制资源?
在创建新的 API 时,请考虑是将你的 API 与 Kubernetes 集群 API 聚合起来还是让你的 API 独立运行。
|
考虑 API 聚合的情况
|
优选独立 API 的情况
|
|
你的 API 是声明式的。
|
你的 API 不符合声明式模型。
|
|
你希望可以是使用 kubectl 来读写你的新资源类别。
|
不要求 kubectl 支持。
|
|
你希望在 Kubernetes UI (如仪表板)中和其他内置类别一起查看你的新资源类别。
|
不需要 Kubernetes UI 支持。
|
|
你在开发新的 API。
|
你已经有一个提供 API 服务的程序并且工作良好。
|
|
你有意愿取接受 Kubernetes 对 REST 资源路径所作的格式限制,例如 API 组和名字空间。(参阅 API 概述)
|
你需要使用一些特殊的 REST 路径以便与已经定义的 REST API 保持兼容。
|
|
你的资源可以自然地界定为集群作用域或集群中某个名字空间作用域。
|
集群作用域或名字空间作用域这种二分法很不合适;你需要对资源路径的细节进行控制。
|
|
你希望复用 Kubernetes API 支持特性。
|
你不需要这类特性。
|
声明式 APIs
典型地,在声明式 API 中:
- 你的 API 包含相对而言为数不多的、尺寸较小的对象(资源)。
- 对象定义了应用或者基础设施的配置信息。
- 对象更新操作频率较低。
- 通常需要人来读取或写入对象。
- 对象的主要操作是 CRUD 风格的(创建、读取、更新和删除)。
- 不需要跨对象的事务支持:API 对象代表的是期望状态而非确切实际状态。
命令式 API(Imperative API)与声明式有所不同。以下迹象表明你的 API 可能不是声明式的:
- 客户端发出“做这个操作”的指令,之后在该操作结束时获得同步响应。
- 客户端发出“做这个操作”的指令,并获得一个操作 ID,之后需要检查一个 Operation(操作)对象来判断请求是否成功完成。
- 你会将你的 API 类比为远程过程调用(Remote Procedure Call,RPCs)。
- 直接存储大量数据;例如每个对象几 kB,或者存储上千个对象。
- 需要较高的访问带宽(长期保持每秒数十个请求)。
- 存储有应用来处理的最终用户数据(如图片、个人标识信息(PII)等)或者其他大规模数据。
- 在对象上执行的常规操作并非 CRUD 风格。
- API 不太容易用对象来建模。
- 你决定使用操作 ID 或者操作对象来表现悬决的操作。
我应该使用一个 ConfigMap 还是一个定制资源?
如果满足以下条件之一,应该使用 ConfigMap:
- 存在一个已有的、文档完备的配置文件格式约定,例如 mysql.cnf 或 pom.xml。
- 你希望将整个配置文件放到某 configMap 中的一个主键下面。
- 配置文件的主要用途是针对运行在集群中 Pod 内的程序,供后者依据文件数据配置自身行为。
- 文件的使用者期望以 Pod 内文件或者 Pod 内环境变量的形式来使用文件数据,而不是通过 Kubernetes API。
- 你希望当文件被更新时通过类似 Deployment 之类的资源完成滚动更新操作。
说明: 请使用 Secret 来保存敏感数据。Secret 类似于 configMap,但更为安全。
如果以下条件中大多数都被满足,你应该使用定制资源(CRD 或者聚合 API):
- 你希望使用 Kubernetes 客户端库和 CLI 来创建和更改新的资源。
- 你希望 kubectl 能够直接支持你的资源;例如,kubectl get my-object object-name。
- 你希望构造新的自动化机制,监测新对象上的更新事件,并对其他对象执行 CRUD 操作,或者监测后者更新前者。
- 你希望编写自动化组件来处理对对象的更新。
- 你希望使用 Kubernetes API 对诸如 .spec、.status 和 .metadata 等字段的约定。
- 你希望对象是对一组受控资源的抽象,或者对其他资源的归纳提炼。
添加定制资源
Kubernetes 提供了两种方式供你向集群中添加定制资源:
- CRD 相对简单,创建 CRD 可以不必编程。
- API 聚合 需要编程,但支持对 API 行为进行更多的控制,例如数据如何存储以及在不同 API 版本间如何转换等。
Kubernetes 提供这两种选项以满足不同用户的需求,这样就既不会牺牲易用性也不会牺牲灵活性。
聚合 API 指的是一些下位的 API 服务器,运行在主 API 服务器后面;主 API 服务器以代理的方式工作。这种组织形式称作 API 聚合(API Aggregation,AA)。对用户而言,看起来仅仅是 Kubernetes API 被扩展了。
CRD 允许用户创建新的资源类别同时又不必添加新的 API 服务器。使用 CRD 时,你并不需要理解 API 聚合。
无论以哪种方式安装定制资源,新的资源都会被当做定制资源,以便与内置的 Kubernetes 资源(如 Pods)相区分。
CustomResourceDefinitions
CustomResourceDefinition API 资源允许你定义定制资源。定义 CRD 对象的操作会使用你所设定的名字和模式定义(Schema)创建一个新的定制资源,Kubernetes API 负责为你的定制资源提供存储和访问服务。CRD 对象的名称必须是合法的 DNS 子域名。
CRD 使得你不必编写自己的 API 服务器来处理定制资源,不过其背后实现的通用性也意味着你所获得的灵活性要比 API 服务器聚合少很多。
关于如何注册新的定制资源、使用新资源类别的实例以及如何使用控制器来处理事件,相关的例子可参见定制控制器示例。
API 服务器聚合
通常,Kubernetes API 中的每个都需要处理 REST 请求和管理对象持久性存储的代码。Kubernetes API 主服务器能够处理诸如 pods 和 services 这些内置资源,也可以按通用的方式通过 CRD 来处理定制资源。
聚合层(Aggregation Layer)使得你可以通过编写和部署你自己的 API 服务器来为定制资源提供特殊的实现。主 API 服务器将针对你要处理的定制资源的请求全部委托给你自己的 API 服务器来处理,同时将这些资源提供给其所有客户端。
选择添加定制资源的方法
CRD 更为易用;聚合 API 则更为灵活。请选择最符合你的需要的方法。
通常,如何存在以下情况,CRD 可能更合适:
- 定制资源的字段不多;
- 你在组织内部使用该资源或者在一个小规模的开源项目中使用该资源,而不是在商业产品中使用。
比较易用性
CRD 比聚合 API 更容易创建
|
CRDs
|
聚合 API
|
|
无需编程。用户可选择任何语言来实现 CRD 控制器。
|
需要使用 Go 来编程,并构建可执行文件和镜像。
|
|
无需额外运行服务;CRD 由 API 服务器处理。
|
需要额外创建服务,且该服务可能失效。
|
|
一旦 CRD 被创建,不需要持续提供支持。Kubernetes 主控节点升级过程中自动会带入缺陷修复。
|
可能需要周期性地从上游提取缺陷修复并更新聚合 API 服务器。
|
|
无需处理 API 的多个版本;例如,当你控制资源的客户端时,你可以更新它使之与 API 同步。
|
你需要处理 API 的多个版本;例如,在开发打算与很多人共享的扩展时。
|
高级特性与灵活性
聚合 API 可提供更多的高级 API 特性,也可对其他特性实行定制;例如,对存储层进行定制。
|
特性
|
描述
|
CRDs
|
聚合 API
|
|
合法性检查
|
帮助用户避免错误,允许你独立于客户端版本演化 API。这些特性对于由很多无法同时更新的客户端的场合。
|
可以。大多数验证可以使用 OpenAPI v3.0 合法性检查 来设定。其他合法性检查操作可以通过添加合法性检查 Webhook 来实现。
|
可以,可执行任何合法性检查。
|
|
默认值设置
|
同上
|
可以。可通过 OpenAPI v3.0 合法性检查的 default 关键词(自 1.17 正式发布)或更改性(Mutating)Webhook来实现(不过从 etcd 中读取老的对象时不会执行这些 Webhook)。
|
可以。
|
|
多版本支持
|
允许通过两个 API 版本同时提供同一对象。可帮助简化类似字段更名这类 API 操作。如果你能控制客户端版本,这一特性将不再重要。
|
可以。
|
可以。
|
|
定制存储
|
支持使用具有不同性能模式的存储(例如,要使用时间序列数据库而不是键值存储),或者因安全性原因对存储进行隔离(例如对敏感信息执行加密)。
|
不可以。
|
可以。
|
|
定制业务逻辑
|
在创建、读取、更新或删除对象时,执行任意的检查或操作。
|
可以。要使用 Webhook。
|
可以。
|
|
支持 scale 子资源
|
允许 HorizontalPodAutoscaler 和 PodDisruptionBudget 这类子系统与你的新资源交互。
|
可以。
|
可以。
|
|
支持 status 子资源
|
允许在用户写入 spec 部分而控制器写入 status 部分时执行细粒度的访问控制。允许在对定制资源的数据进行更改时增加对象的代际(Generation);这需要资源对 spec 和 status 部分有明确划分。
|
可以。
|
可以。
|
|
其他子资源
|
添加 CRUD 之外的操作,例如 "logs" 或 "exec"。
|
不可以。
|
可以。
|
|
strategic-merge-patch
|
新的端点要支持标记了 Content-Type: application/strategic-merge-patch+json 的 PATCH 操作。对于更新既可在本地更改也可在服务器端更改的对象而言是有用的。要了解更多信息,可参见使用 kubectl patch 来更新 API 对象。
|
不可以。
|
可以。
|
|
支持协议缓冲区
|
新的资源要支持想要使用协议缓冲区(Protocol Buffer)的客户端。
|
不可以。
|
可以。
|
|
OpenAPI Schema
|
是否存在新资源类别的 OpenAPI(Swagger)Schema 可供动态从服务器上读取?是否存在机制确保只能设置被允许的字段以避免用户犯字段拼写错误?是否实施了字段类型检查(换言之,不允许在 string 字段设置 int 值)?
|
可以,依据 OpenAPI v3.0 合法性检查 模式(1.16 中进入正式发布状态)。
|
可以。
|
公共特性
与在 Kubernetes 平台之外实现定制资源相比,无论是通过 CRD 还是通过聚合 API 来创建定制资源,你都会获得很多 API 特性:
|
功能特性
|
具体含义
|
|
CRUD
|
新的端点支持通过 HTTP 和 kubectl 发起的 CRUD 基本操作
|
|
监测(Watch)
|
新的端点支持通过 HTTP 发起的 Kubernetes Watch 操作
|
|
发现(Discovery)
|
类似 kubectl 和仪表盘(Dashboard)这类客户端能够自动提供列举、显示、在字段级编辑你的资源的操作
|
|
json-patch
|
新的端点支持带 Content-Type: application/json-patch+json 的 PATCH 操作
|
|
merge-patch
|
新的端点支持带 Content-Type: application/merge-patch+json 的 PATCH 操作
|
|
HTTPS
|
新的端点使用 HTTPS
|
|
内置身份认证
|
对扩展的访问会使用核心 API 服务器(聚合层)来执行身份认证操作
|
|
内置鉴权授权
|
对扩展的访问可以复用核心 API 服务器所使用的鉴权授权机制;例如,RBAC
|
|
Finalizers
|
在外部清除工作结束之前阻止扩展资源被删除
|
|
准入 Webhooks
|
在创建、更新和删除操作中对扩展资源设置默认值和执行合法性检查
|
|
UI/CLI 展示
|
kubectl 和仪表盘(Dashboard)可以显示扩展资源
|
|
区分未设置值和空值
|
客户端能够区分哪些字段是未设置的,哪些字段的值是被显式设置为零值的。
|
|
生成客户端库
|
Kubernetes 提供通用的客户端库,以及用来生成特定类别客户端库的工具
|
|
标签和注解
|
提供涵盖所有对象的公共元数据结构,且工具知晓如何编辑核心资源和定制资源的这些元数据
|
准备安装定制资源
在向你的集群添加定制资源之前,有些事情需要搞清楚。
第三方代码和新的失效点的问题
尽管添加新的 CRD 不会自动带来新的失效点(Point of Failure),例如导致第三方代码被在 API 服务器上运行,类似 Helm Charts 这种软件包或者其他安装包通常在提供 CRD 的同时还包含带有第三方代码的 Deployment,负责实现新的定制资源的业务逻辑。
安装聚合 API 服务器时,也总会牵涉到运行一个新的 Deployment。
存储
定制资源和 ConfigMap 一样也会消耗存储空间。创建过多的定制资源可能会导致 API 服务器上的存储空间超载。
聚合 API 服务器可以使用主 API 服务器的同一存储。如果是这样,你也要注意此警告。
身份认证、鉴权授权以及审计
CRD 通常与 API 服务器上的内置资源一样使用相同的身份认证、鉴权授权和审计日志机制。
如果你使用 RBAC 来执行鉴权授权,大多数 RBAC 角色都会授权对新资源的访问(除了 cluster-admin 角色以及使用通配符规则创建的其他角色)。你要显式地为新资源的访问授权。CRD 和聚合 API 通常在交付时会包含针对所添加的类别的新的角色定义。
聚合 API 服务器可能会使用主 API 服务器相同的身份认证、鉴权授权和审计机制,也可能不会。
访问定制资源
Kubernetes 客户端库可用来访问定制资源。并非所有客户端库都支持定制资源。Go 和 Python 客户端库是支持的。
当你添加了新的定制资源后,可以用如下方式之一访问它们:
- kubectl
- Kubernetes 动态客户端
- 你所编写的 REST 客户端
- 使用 Kubernetes 客户端生成工具所生成的客户端。生成客户端的工作有些难度,不过某些项目可能会随着 CRD 或聚合 API 一起提供一个客户端
1.2 - 通过聚合层扩展 Kubernetes API
使用聚合层(Aggregation Layer),用户可以通过额外的 API 扩展 Kubernetes,而不局限于 Kubernetes 核心 API 提供的功能。
这里的附加 API 可以是现成的解决方案比如 metrics server,或者你自己开发的 API。
聚合层不同于定制资源(Custom Resources)。后者的目的是让 kube-apiserver 能够认识新的对象类别(Kind)。
聚合层
聚合层在 kube-apiserver 进程内运行。在扩展资源注册之前,聚合层不做任何事情。要注册 API,用户必须添加一个 APIService 对象,用它来“申领” Kubernetes API 中的 URL 路径。自此以后,聚合层将会把发给该 API 路径的所有内容(例如 /apis/myextension.mycompany.io/v1/…)转发到已注册的 APIService。
APIService 的最常见实现方式是在集群中某 Pod 内运行扩展 API 服务器。如果你在使用扩展 API 服务器来管理集群中的资源,该扩展 API 服务器(也被写成“extension-apiserver”)一般需要和一个或多个控制器一起使用。apiserver-builder 库同时提供构造扩展 API 服务器和控制器框架代码。
反应延迟
扩展 API 服务器与 kube-apiserver 之间需要存在低延迟的网络连接。发现请求需要在五秒钟或更短的时间内完成到 kube-apiserver 的往返。
如果你的扩展 API 服务器无法满足这一延迟要求,应考虑如何更改配置以满足需要。
2 - Operator 模式
Operator 是 Kubernetes 的扩展软件,它利用定制资源管理应用及其组件。Operator 遵循 Kubernetes 的理念,特别是在控制器方面。
初衷
Operator 模式旨在捕获(正在管理一个或一组服务的)运维人员的关键目标。负责特定应用和 service 的运维人员,在系统应该如何运行、如何部署以及出现问题时如何处理等方面有深入的了解。
在 Kubernetes 上运行工作负载的人们都喜欢通过自动化来处理重复的任务。Operator 模式会封装你编写的(Kubernetes 本身提供功能以外的)任务自动化代码。
Kubernetes 上的 Operator
Kubernetes 为自动化而生。无需任何修改,你即可以从 Kubernetes 核心中获得许多内置的自动化功能。你可以使用 Kubernetes 自动化部署和运行工作负载,甚至可以自动化 Kubernetes 自身。
Kubernetes 的 Operator 模式概念使你无需修改 Kubernetes 自身的代码,通过把定制控制器关联到一个以上的定制资源上,即可以扩展集群的行为。Operator 是 Kubernetes API 的客户端,充当定制资源的控制器。
Operator 示例
使用 Operator 可以自动化的事情包括:
- 按需部署应用
- 获取/还原应用状态的备份
- 处理应用代码的升级以及相关改动。例如,数据库 schema 或额外的配置设置
- 发布一个 service,要求不支持 Kubernetes API 的应用也能发现它
- 模拟整个或部分集群中的故障以测试其稳定性
- 在没有内部成员选举程序的情况下,为分布式应用选择首领角色
想要更详细的了解 Operator?下面是一个示例:
- 有一个名为 SampleDB 的自定义资源,你可以将其配置到集群中。
- 一个包含 Operator 控制器部分的 Deployment,用来确保 Pod 处于运行状态。
- Operator 代码的容器镜像。
- 控制器代码,负责查询控制平面以找出已配置的 SampleDB 资源。
- Operator 的核心是告诉 API 服务器,如何使现实与代码里配置的资源匹配。
- 如果添加新的 SampleDB,Operator 将设置 PersistentVolumeClaims 以提供持久化的数据库存储,设置 StatefulSet 以运行 SampleDB,并设置 Job 来处理初始配置。
- 如果你删除它,Operator 将建立快照,然后确保 StatefulSet 和 Volume 已被删除。
- Operator 也可以管理常规数据库的备份。对于每个 SampleDB 资源,Operator 会确定何时创建(可以连接到数据库并进行备份的)Pod。这些 Pod 将依赖于 ConfigMap 和/或具有数据库连接详细信息和凭据的 Secret。
- 由于 Operator 旨在为其管理的资源提供强大的自动化功能,因此它还需要一些额外的支持性代码。在这个示例中,代码将检查数据库是否正运行在旧版本上,如果是,则创建 Job 对象为你升级数据库。
部署 Operator
部署 Operator 最常见的方法是将自定义资源及其关联的控制器添加到你的集群中。跟运行容器化应用一样,控制器通常会运行在控制平面之外。例如,你可以在集群中将控制器作为 Deployment 运行。
使用 Operator
部署 Operator 后,你可以对 Operator 所使用的资源执行添加、修改或删除操作。按照上面的示例,你将为 Operator 本身建立一个 Deployment,然后:
kubectl get SampleDB # 查找所配置的数据库
kubectl edit SampleDB/example-database # 手动修改某些配置
可以了!Operator 会负责应用所作的更改并保持现有服务处于良好的状态。
编写你自己的 Operator
如果生态系统中没可以实现你目标的 Operator,你可以自己编写代码。
你还可以使用任何支持 Kubernetes API 客户端的语言或运行时来实现 Operator(即控制器)。
以下是一些库和工具,你可用于编写自己的云原生 Operator。
说明: 本部分链接到提供 Kubernetes 所需功能的第三方项目。Kubernetes 项目作者不负责这些项目。此页面遵循 CNCF 网站指南,按字母顺序列出项目。要将项目添加到此列表中,请在提交更改之前阅读内容指南。
- Charmed Operator Framework
- kubebuilder
- KubeOps (dotnet operator SDK)
- KUDO (Kubernetes 通用声明式 Operator)
- Metacontroller,可与 Webhooks 结合使用,以实现自己的功能。
- Operator Framework
- shell-operator
3 - 计算、存储和网络扩展
3.1 - 网络插件
Kubernetes 中的网络插件有几种类型:
- CNI 插件:遵守容器网络接口(Container Network Interface,CNI)规范,其设计上偏重互操作性。
- Kubernetes 遵从 CNI 规范的 v0.4.0 版本。
- Kubenet 插件:使用 bridge 和 host-local CNI 插件实现了基本的 cbr0。
安装
kubelet 有一个单独的默认网络插件,以及一个对整个集群通用的默认网络。它在启动时探测插件,记住找到的内容,并在 Pod 生命周期的适当时间执行所选插件(这仅适用于 Docker,因为 CRI 管理自己的 CNI 插件)。在使用插件时,需要记住两个 kubelet 命令行参数:
- cni-bin-dir:kubelet 在启动时探测这个目录中的插件
- network-plugin:要使用的网络插件来自 cni-bin-dir。它必须与从插件目录探测到的插件报告的名称匹配。对于 CNI 插件,其值为 "cni"。
网络插件要求
除了提供 NetworkPlugin 接口来配置和清理 Pod 网络之外,该插件还可能需要对 kube-proxy 的特定支持。iptables 代理显然依赖于 iptables,插件可能需要确保 iptables 能够监控容器的网络通信。例如,如果插件将容器连接到 Linux 网桥,插件必须将 net/bridge/bridge-nf-call-iptables 系统参数设置为1,以确保 iptables 代理正常工作。如果插件不使用 Linux 网桥(而是类似于 Open vSwitch 或者其它一些机制),它应该确保为代理对容器通信执行正确的路由。
默认情况下,如果未指定 kubelet 网络插件,则使用 noop 插件,该插件设置 net/bridge/bridge-nf-call-iptables=1,以确保简单的配置(如带网桥的 Docker )与 iptables 代理正常工作。
CNI
通过给 Kubelet 传递 --network-plugin=cni 命令行选项可以选择 CNI 插件。Kubelet 从 --cni-conf-dir(默认是 /etc/cni/net.d)读取文件并使用该文件中的 CNI 配置来设置各个 Pod 的网络。CNI 配置文件必须与 CNI 规约匹配,并且配置所引用的所有所需的 CNI 插件都应存在于 --cni-bin-dir(默认是 /opt/cni/bin)下。
如果这个目录中有多个 CNI 配置文件,kubelet 将会使用按文件名的字典顺序排列的第一个作为配置文件。
除了配置文件指定的 CNI 插件外,Kubernetes 还需要标准的 CNI lo 插件,最低版本是0.2.0。
支持 hostPort
CNI 网络插件支持 hostPort。你可以使用官方 portmap 插件,它由 CNI 插件团队提供,或者使用你自己的带有 portMapping 功能的插件。
如果你想要启动 hostPort 支持,则必须在 cni-conf-dir 指定 portMappings capability。例如:
{
"name": "k8s-pod-network",
"cniVersion": "0.3.0",
"plugins": [
{
"type": "calico",
"log_level": "info",
"datastore_type": "kubernetes",
"nodename": "127.0.0.1",
"ipam": {
"type": "host-local",
"subnet": "usePodCidr"
},
"policy": {
"type": "k8s"
},
"kubernetes": {
"kubeconfig": "/etc/cni/net.d/calico-kubeconfig"
}
},
{
"type": "portmap",
"capabilities": {"portMappings": true}
}
]
}
支持流量整形
实验功能
CNI 网络插件还支持 pod 入口和出口流量整形。你可以使用 CNI 插件团队提供的 bandwidth 插件,也可以使用你自己的具有带宽控制功能的插件。
如果你想要启用流量整形支持,你必须将 bandwidth 插件添加到 CNI 配置文件(默认是 /etc/cni/net.d)并保证该可执行文件包含在你的 CNI 的 bin 文件夹内 (默认为 /opt/cni/bin)。
{
"name": "k8s-pod-network",
"cniVersion": "0.3.0",
"plugins": [
{
"type": "calico",
"log_level": "info",
"datastore_type": "kubernetes",
"nodename": "127.0.0.1",
"ipam": {
"type": "host-local",
"subnet": "usePodCidr"
},
"policy": {
"type": "k8s"
},
"kubernetes": {
"kubeconfig": "/etc/cni/net.d/calico-kubeconfig"
}
},
{
"type": "bandwidth",
"capabilities": {"bandwidth": true}
}
]
}
现在,你可以将 kubernetes.io/ingress-bandwidth 和 kubernetes.io/egress-bandwidth 注解添加到 pod 中。例如:
apiVersion: v1
kind: Pod
metadata:
annotations:
kubernetes.io/ingress-bandwidth: 1M
kubernetes.io/egress-bandwidth: 1M
...
kubenet
Kubenet 是一个非常基本的、简单的网络插件,仅适用于 Linux。它本身并不实现更高级的功能,如跨节点网络或网络策略。它通常与云驱动一起使用,云驱动为节点间或单节点环境中的通信设置路由规则。
Kubenet 创建名为 cbr0 的网桥,并为每个 pod 创建了一个 veth 对,每个 Pod 的主机端都连接到 cbr0。这个 veth 对的 Pod 端会被分配一个 IP 地址,该 IP 地址隶属于节点所被分配的 IP 地址范围内。节点的 IP 地址范围则通过配置或控制器管理器来设置。cbr0 被分配一个 MTU,该 MTU 匹配主机上已启用的正常接口的最小 MTU。
使用此插件还需要一些其他条件:
- 需要标准的 CNI bridge、lo 以及 host-local 插件,最低版本是0.2.0。kubenet 首先在 /opt/cni/bin 中搜索它们。指定 cni-bin-dir 以提供其它搜索路径。首次找到的匹配将生效。
- Kubelet 必须和 --network-plugin=kubenet 参数一起运行,才能启用该插件。
- Kubelet 还应该和 --non-masquerade-cidr=< clusterCidr > 参数一起运行,以确保超出此范围的 IP 流量将使用 IP 伪装。
- 节点必须被分配一个 IP 子网,通过kubelet 命令行的 --pod-cidr 选项或控制器管理器的命令行选项 --allocate-node-cidrs=true --cluster-cidr=< cidr > 来设置。
自定义 MTU(使用 kubenet)
要获得最佳的网络性能,必须确保 MTU 的取值配置正确。网络插件通常会尝试推断出一个合理的 MTU,但有时候这个逻辑不会产生一个最优的 MTU。例如,如果 Docker 网桥或其他接口有一个小的 MTU,kubenet 当前将选择该 MTU。或者如果你正在使用 IPSEC 封装,则必须减少 MTU,并且这种计算超出了大多数网络插件的能力范围。
如果需要,你可以使用 network-plugin-mtu kubelet 选项显式的指定 MTU。例如:在 AWS 上 eth0 MTU 通常是 9001,因此你可以指定 --network-plugin-mtu=9001。如果你正在使用 IPSEC,你可以减少它以允许封装开销,例如 --network-plugin-mtu=8873。
此选项会传递给网络插件;当前仅 kubenet 支持 network-plugin-mtu。
用法总结
- --network-plugin=cni 用来表明我们要使用 cni 网络插件,实际的 CNI 插件可执行文件位于 --cni-bin-dir(默认是 /opt/cni/bin)下,CNI 插件配置位于 --cni-conf-dir(默认是 /etc/cni/net.d)下。
- --network-plugin=kubenet 用来表明我们要使用 kubenet 网络插件,CNI bridge,lo 和 host-local 插件位于 /opt/cni/bin 或 cni-bin-dir 中。
- --network-plugin-mtu=9001 指定了我们使用的 MTU,当前仅被 kubenet 网络插件使用。
3.2 - 设备插件
FEATURE STATE: Kubernetes v1.10 [beta]
Kubernetes 提供了一个设备插件框架,你可以用它来将系统硬件资源发布到 Kubelet。
供应商可以实现设备插件,由你手动部署或作为 DaemonSet 来部署,而不必定制 Kubernetes 本身的代码。目标设备包括 GPU、高性能 NIC、FPGA、InfiniBand 适配器以及其他类似的、可能需要特定于供应商的初始化和设置的计算资源。
注册设备插件
kubelet 提供了一个 Registration 的 gRPC 服务:
service Registration {
rpc Register(RegisterRequest) returns (Empty) {}
}
设备插件可以通过此 gRPC 服务在 kubelet 进行注册。在注册期间,设备插件需要发送下面几样内容:
- 设备插件的 Unix 套接字。
- 设备插件的 API 版本。
- ResourceName 是需要公布的。这里 ResourceName 需要遵循扩展资源命名方案,类似于 vendor-domain/resourcetype。(比如 NVIDIA GPU 就被公布为 nvidia.com/gpu。)
成功注册后,设备插件就向 kubelet 发送它所管理的设备列表,然后 kubelet 负责将这些资源发布到 API 服务器,作为 kubelet 节点状态更新的一部分。
比如,设备插件在 kubelet 中注册了 hardware-vendor.example/foo 并报告了节点上的两个运行状况良好的设备后,节点状态将更新以通告该节点已安装 2 个 "Foo" 设备并且是可用的。
然后用户需要请求其他类型的资源的时候,就可以在 Container 规范请求这类设备,但是有以下的限制:
- 扩展资源仅可作为整数资源使用,并且不能被过量使用
- 设备不能在容器之间共享
假设 Kubernetes 集群正在运行一个设备插件,该插件在一些节点上公布的资源为 hardware-vendor.example/foo。下面就是一个 Pod 示例,请求此资源以运行某演示负载:
---
apiVersion: v1
kind: Pod
metadata:
name: demo-pod
spec:
containers:
- name: demo-container-1
image: k8s.gcr.io/pause:2.0
resources:
limits:
hardware-vendor.example/foo: 2
#
# 这个 pod 需要两个 hardware-vendor.example/foo 设备
# 而且只能够调度到满足需求的节点上
#
# 如果该节点中有 2 个以上的设备可用,其余的可供其他 Pod 使用
设备插件的实现
设备插件的常规工作流程包括以下几个步骤:
-
初始化。在这个阶段,设备插件将执行供应商特定的初始化和设置,以确保设备处于就绪状态。
-
插件使用主机路径 /var/lib/kubelet/device-plugins/ 下的 Unix 套接字启动一个 gRPC 服务,该服务实现以下接口:
service DevicePlugin { // ListAndWatch 返回 Device 列表构成的数据流。 // 当 Device 状态发生变化或者 Device 消失时,ListAndWatch // 会返回新的列表。 rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {} // Allocate 在容器创建期间调用,这样设备插件可以运行一些特定于设备的操作, // 并告诉 kubelet 如何令 Device 可在容器中访问的所需执行的具体步骤 rpc Allocate(AllocateRequest) returns (AllocateResponse) {} // GetPreferredAllocation 从一组可用的设备中返回一些优选的设备用来分配, // 所返回的优选分配结果不一定会是设备管理器的最终分配方案。 // 此接口的设计仅是为了让设备管理器能够在可能的情况下做出更有意义的决定。 rpc GetPreferredAllocation(PreferredAllocationRequest) returns (PreferredAllocationResponse) {} // PreStartContainer 在设备插件注册阶段根据需要被调用,调用发生在容器启动之前。 // 在将设备提供给容器使用之前,设备插件可以运行一些诸如重置设备之类的特定于 // 具体设备的操作, rpc PreStartContainer(PreStartContainerRequest) returns (PreStartContainerResponse) {} }
说明:
插件并非必须为 GetPreferredAllocation() 或 PreStartContainer() 提供有用的实现逻辑,调用 GetDevicePluginOptions() 时所返回的 DevicePluginOptions 消息中应该设置这些调用是否可用。kubelet 在真正调用这些函数之前,总会调用 GetDevicePluginOptions()来查看是否存在这些可选的函数。
-
插件通过 Unix socket 在主机路径 /var/lib/kubelet/device-plugins/kubelet.sock 处向 kubelet 注册自身。
-
成功注册自身后,设备插件将以服务模式运行,在此期间,它将持续监控设备运行状况,并在设备状态发生任何变化时向 kubelet 报告。它还负责响应 Allocate gRPC 请求。在 Allocate 期间,设备插件可能还会做一些设备特定的准备;例如 GPU 清理或 QRNG 初始化。如果操作成功,则设备插件将返回 AllocateResponse,其中包含用于访问被分配的设备容器运行时的配置。kubelet 将此信息传递到容器运行时。
处理 kubelet 重启
设备插件应能监测到 kubelet 重启,并且向新的 kubelet 实例来重新注册自己。在当前实现中,当 kubelet 重启的时候,新的 kubelet 实例会删除 /var/lib/kubelet/device-plugins 下所有已经存在的 Unix 套接字。设备插件需要能够监控到它的 Unix 套接字被删除,并且当发生此类事件时重新注册自己。
设备插件部署
你可以将你的设备插件作为节点操作系统的软件包来部署、作为 DaemonSet 来部署或者手动部署。
规范目录 /var/lib/kubelet/device-plugins 是需要特权访问的,所以设备插件必须要在被授权的安全的上下文中运行。如果你将设备插件部署为 DaemonSet,/var/lib/kubelet/device-plugins 目录必须要在插件的 PodSpec 中声明作为卷(Volume)被挂载到插件中。
如果你选择 DaemonSet 方法,你可以通过 Kubernetes 进行以下操作:将设备插件的 Pod 放置在节点上,在出现故障后重新启动守护进程 Pod,来进行自动升级。
API 兼容性
Kubernetes 设备插件支持还处于 beta 版本。所以在稳定版本出来之前 API 会以不兼容的方式进行更改。作为一个项目,Kubernetes 建议设备插件开发者:
- 注意未来版本的更改
- 支持多个版本的设备插件 API,以实现向后/向前兼容性。
如果你启用 DevicePlugins 功能,并在需要升级到 Kubernetes 版本来获得较新的设备插件 API 版本的节点上运行设备插件,请在升级这些节点之前先升级设备插件以支持这两个版本。采用该方法将确保升级期间设备分配的连续运行。
监控设备插件资源
FEATURE STATE: Kubernetes v1.15 [beta]
为了监控设备插件提供的资源,监控代理程序需要能够发现节点上正在使用的设备,并获取元数据来描述哪个指标与容器相关联。设备监控代理暴露给 Prometheus 的指标应该遵循 Kubernetes Instrumentation Guidelines,使用 pod、namespace 和 container 标签来标识容器。
kubelet 提供了 gRPC 服务来使得正在使用中的设备被发现,并且还未这些设备提供了元数据:
// PodResourcesLister 是一个由 kubelet 提供的服务,用来提供供节点上
// Pods 和容器使用的节点资源的信息
service PodResourcesLister {
rpc List(ListPodResourcesRequest) returns (ListPodResourcesResponse) {}
rpc GetAllocatableResources(AllocatableResourcesRequest) returns (AllocatableResourcesResponse) {}
}
这一 List 端点提供运行中 Pods 的资源信息,包括类似独占式分配的 CPU ID、设备插件所报告的设备 ID 以及这些设备分配所处的 NUMA 节点 ID。此外,对于基于 NUMA 的机器,它还会包含为容器保留的内存和大页的信息。
// ListPodResourcesResponse 是 List 函数的响应
message ListPodResourcesResponse {
repeated PodResources pod_resources = 1;
}
// PodResources 包含关于分配给 Pod 的节点资源的信息
message PodResources {
string name = 1;
string namespace = 2;
repeated ContainerResources containers = 3;
}
// ContainerResources 包含分配给容器的资源的信息
message ContainerResources {
string name = 1;
repeated ContainerDevices devices = 2;
repeated int64 cpu_ids = 3;
repeated ContainerMemory memory = 4;
}
// ContainerMemory 包含分配给容器的内存和大页信息
message ContainerMemory {
string memory_type = 1;
uint64 size = 2;
TopologyInfo topology = 3;
}
// Topology 描述资源的硬件拓扑结构
message TopologyInfo {
repeated NUMANode nodes = 1;
}
// NUMA 代表的是 NUMA 节点
message NUMANode {
int64 ID = 1;
}
// ContainerDevices 包含分配给容器的设备信息
message ContainerDevices {
string resource_name = 1;
repeated string device_ids = 2;
TopologyInfo topology = 3;
}
端点 GetAllocatableResources 提供最初在工作节点上可用的资源的信息。此端点所提供的信息比导出给 API 服务器的信息更丰富。
// AllocatableResourcesResponses 包含 kubelet 所了解到的所有设备的信息
message AllocatableResourcesResponse {
repeated ContainerDevices devices = 1;
repeated int64 cpu_ids = 2;
repeated ContainerMemory memory = 3;
}
ContainerDevices 会向外提供各个设备所隶属的 NUMA 单元这类拓扑信息。NUMA 单元通过一个整数 ID 来标识,其取值与设备插件所报告的一致。设备插件注册到 kubelet 时会报告这类信息。
gRPC 服务通过 /var/lib/kubelet/pod-resources/kubelet.sock 的 UNIX 套接字来提供服务。设备插件资源的监控代理程序可以部署为守护进程或者 DaemonSet。规范的路径 /var/lib/kubelet/pod-resources 需要特权来进入,所以监控代理程序必须要在获得授权的安全的上下文中运行。如果设备监控代理以 DaemonSet 形式运行,必须要在插件的 PodSpec 中声明将 /var/lib/kubelet/pod-resources 目录以卷的形式被挂载到设备监控代理中。
对“PodResourcesLister 服务”的支持要求启用 KubeletPodResources 特性门控。从 Kubernetes 1.15 开始默认启用,自从 Kubernetes 1.20 开始为 v1。
设备插件与拓扑管理器的集成
FEATURE STATE: Kubernetes v1.18 [beta]
拓扑管理器是 Kubelet 的一个组件,它允许以拓扑对齐方式来调度资源。为了做到这一点,设备插件 API 进行了扩展来包括一个 TopologyInfo 结构体。
message TopologyInfo {
repeated NUMANode nodes = 1;
}
message NUMANode {
int64 ID = 1;
}
设备插件希望拓扑管理器可以将填充的 TopologyInfo 结构体作为设备注册的一部分以及设备 ID 和设备的运行状况发送回去。然后设备管理器将使用此信息来咨询拓扑管理器并做出资源分配决策。
TopologyInfo 支持定义 nodes 字段,允许为 nil(默认)或者是一个 NUMA 节点的列表。这样就可以使设备插件可以跨越 NUMA 节点去发布。
下面是一个由设备插件为设备填充 TopologyInfo 结构体的示例:
pluginapi.Device{ID: "25102017", Health: pluginapi.Healthy, Topology:&pluginapi.TopologyInfo{Nodes: []*pluginapi.NUMANode{&pluginapi.NUMANode{ID: 0,},}}}
设备插件示例
下面是一些设备插件实现的示例:
- AMD GPU 设备插件
- Intel 设备插件 支持 Intel GPU、FPGA 和 QuickAssist 设备
- KubeVirt 设备插件用于硬件辅助的虚拟化
- The NVIDIA GPU 设备插件
- 需要 nvidia-docker 2.0,以允许运行 Docker 容器的时候启用 GPU。
- 为 Container-Optimized OS 所提供的 NVIDIA GPU 设备插件
- RDMA 设备插件
- Solarflare 设备插件
- SR-IOV 网络设备插件
- Xilinx FPGA 设备插件
4 - 服务目录
服务目录(Service Catalog)是服务目录是一种扩展 API,它能让 Kubernetes 集群中运行的应用易于使用外部托管的的软件服务,例如云供应商提供的数据仓库服务。
服务目录可以检索、供应、和绑定由服务代理人(Service Brokers)提供的外部托管服务(Managed Services),而无需知道那些服务具体是怎样创建和托管的。
服务代理(Service Broker)是由 Open Service Broker API 规范定义的一组托管服务的端点,这些服务由第三方提供并维护,其中的第三方可以是 AWS、GCP 或 Azure 等云服务提供商。托管服务的一些示例是 Microsoft Azure Cloud Queue、Amazon Simple Queue Service 和 Google Cloud Pub/Sub,但它们可以是应用程序能够使用的任何软件交付物。
使用服务目录,集群操作员可以浏览某服务代理所提供的托管服务列表,供应托管服务实例并与之绑定,以使其可以被 Kubernetes 集群中的应用程序使用。
示例用例
应用开发人员,希望使用消息队列,作为其在 Kubernetes 集群中运行的应用程序的一部分。但是,他们不想承受构造这种服务的开销,也不想自行管理。幸运的是,有一家云服务提供商通过其服务代理以托管服务的形式提供消息队列服务。
集群操作员可以设置服务目录并使用它与云服务提供商的服务代理通信,进而部署消息队列服务的实例并使其对 Kubernetes 中的应用程序可用。应用开发者于是可以不关心消息队列的实现细节,也不用对其进行管理。他们的应用程序可以简单的将其作为服务使用。
架构
服务目录使用 Open Service Broker API 与服务代理进行通信,并作为 Kubernetes API 服务器的中介,以便协商启动部署和获取应用程序使用托管服务时必须的凭据。
服务目录实现为一个扩展 API 服务器和一个控制器,使用 Etcd 提供存储。它还使用了 Kubernetes 1.7 之后版本中提供的聚合层来呈现其 API。
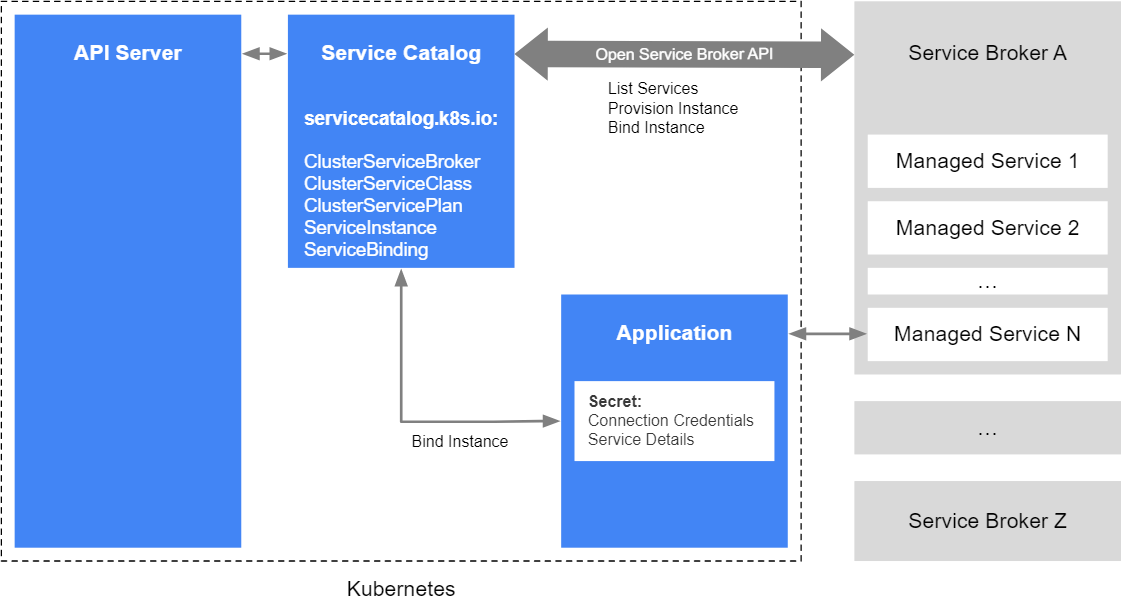
API 资源
服务目录安装 servicecatalog.k8s.io API 并提供以下 Kubernetes 资源:
- ClusterServiceBroker:服务目录的集群内表现形式,封装了其服务连接细节。集群运维人员创建和管理这些资源,并希望使用该代理服务在集群中提供新类型的托管服务。
- ClusterServiceClass:由特定服务代理提供的托管服务。当新的 ClusterServiceBroker 资源被添加到集群时,服务目录控制器将连接到服务代理以获取可用的托管服务列表。然后为每个托管服务创建对应的新 ClusterServiceClass 资源。
- ClusterServicePlan:托管服务的特定产品。例如托管服务可能有不同的计划可用,如免费版本和付费版本,或者可能有不同的配置选项,例如使用 SSD 存储或拥有更多资源。与 ClusterServiceClass 类似,当一个新的 ClusterServiceBroker 被添加到集群时,服务目录会为每个托管服务的每个可用服务计划创建对应的新 ClusterServicePlan 资源。
- ServiceInstance:ClusterServiceClass 提供的示例。由集群运维人员创建,以使托管服务的特定实例可供一个或多个集群内应用程序使用。当创建一个新的 ServiceInstance 资源时,服务目录控制器将连接到相应的服务代理并指示它调配服务实例。
- ServiceBinding:ServiceInstance 的访问凭据。由希望其应用程序使用服务 ServiceInstance 的集群运维人员创建。创建之后,服务目录控制器将创建一个 Kubernetes Secret,其中包含服务实例的连接细节和凭据,可以挂载到 Pod 中。
认证
服务目录支持这些认证方法:
- 基本认证(用户名/密码)
- OAuth 2.0 不记名令牌
使用方式
集群运维人员可以使用服务目录 API 资源来供应托管服务并使其在 Kubernetes 集群内可用。涉及的步骤有:
- 列出服务代理提供的托管服务和服务计划。
- 配置托管服务的新实例。
- 绑定到托管服务,它将返回连接凭证。
- 将连接凭证映射到应用程序中。
列出托管服务和服务计划
首先,集群运维人员在 servicecatalog.k8s.io 组内创建一个 ClusterServiceBroker 资源。此资源包含访问服务代理终结点所需的 URL 和连接详细信息。
这是一个 ClusterServiceBroker 资源的例子:
apiVersion: servicecatalog.k8s.io/v1beta1
kind: ClusterServiceBroker
metadata:
name: cloud-broker
spec:
# 指向服务代理的末端。(这里的 URL 是无法使用的。)
url: https://servicebroker.somecloudprovider.com/v1alpha1/projects/service-catalog/brokers/default
#####
# 这里可以添加额外的用来与服务代理通信的属性值,
# 例如持有者令牌信息或者 TLS 的 CA 包。
#####
下面的时序图展示了从服务代理列出可用托管服务和计划所涉及的各个步骤:
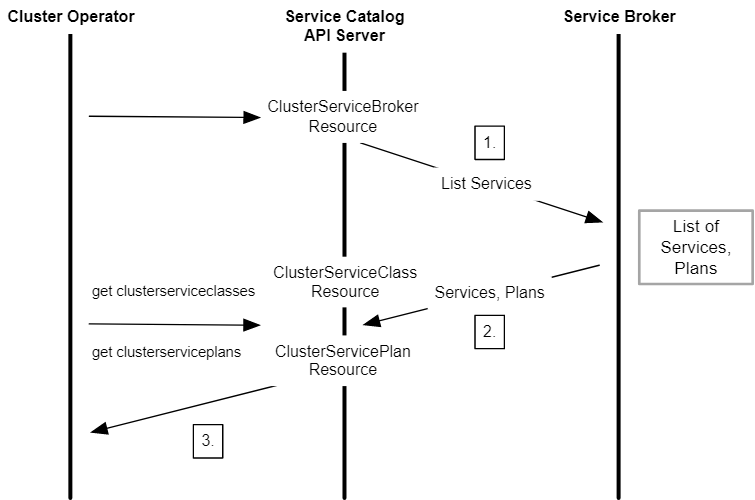
- 一旦 ClusterServiceBroker 资源被添加到了服务目录之后,将会触发一个到外部服务代理的调用,以列举所有可用服务;
- 服务代理返回可用的托管服务和服务计划列表,这些列表将本地缓存在 ClusterServiceClass 和 ClusterServicePlan 资源中。
- 集群运维人员接下来可以使用以下命令获取可用托管服务的列表:
kubectl get clusterserviceclasses \
-o=custom-columns=SERVICE\ NAME:.metadata.name,EXTERNAL\ NAME:.spec.externalName
它应该输出一个和以下格式类似的服务名称列表:
SERVICE NAME EXTERNAL NAME
4f6e6cf6-ffdd-425f-a2c7-3c9258ad2468 cloud-provider-service
... ...
他们还可以使用以下命令查看可用的服务计划:
kubectl get clusterserviceplans \
-o=custom-columns=PLAN\ NAME:.metadata.name,EXTERNAL\ NAME:.spec.externalName
它应该输出一个和以下格式类似的服务计划列表:
PLAN NAME EXTERNAL NAME
86064792-7ea2-467b-af93-ac9694d96d52 service-plan-name
... ...
供应一个新实例
集群运维人员可以通过创建一个 ServiceInstance 资源来启动一个新实例的配置。
下面是一个 ServiceInstance 资源的例子:
apiVersion: servicecatalog.k8s.io/v1beta1
kind: ServiceInstance
metadata:
name: cloud-queue-instance
namespace: cloud-apps
spec:
# 引用之前返回的服务之一
clusterServiceClassExternalName: cloud-provider-service
clusterServicePlanExternalName: service-plan-name
#####
# 这里可添加额外的参数,供服务代理使用
#####
以下时序图展示了配置托管服务新实例所涉及的步骤:
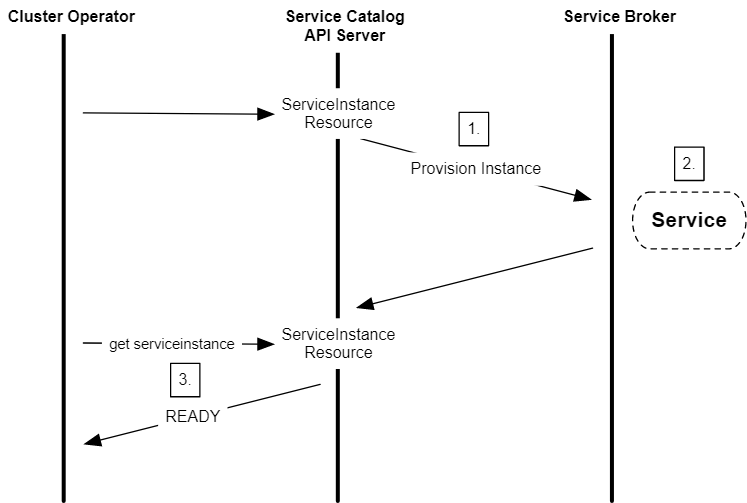
- 创建 ServiceInstance 资源时,服务目录将启动一个到外部服务代理的调用,请求供应一个实例。
- 服务代理创建一个托管服务的新实例并返回 HTTP 响应。
- 接下来,集群运维人员可以检查实例的状态是否就绪。
绑定到托管服务
在设置新实例之后,集群运维人员必须绑定到托管服务才能获取应用程序使用服务所需的连接凭据和服务账户的详细信息。该操作通过创建一个 ServiceBinding 资源完成。
以下是 ServiceBinding 资源的示例:
apiVersion: servicecatalog.k8s.io/v1beta1
kind: ServiceBinding
metadata:
name: cloud-queue-binding
namespace: cloud-apps
spec:
instanceRef:
name: cloud-queue-instance
#####
# 这里可以添加供服务代理使用的额外信息,例如 Secret 名称或者服务账号参数,
#####
以下顺序图展示了绑定到托管服务实例的步骤:
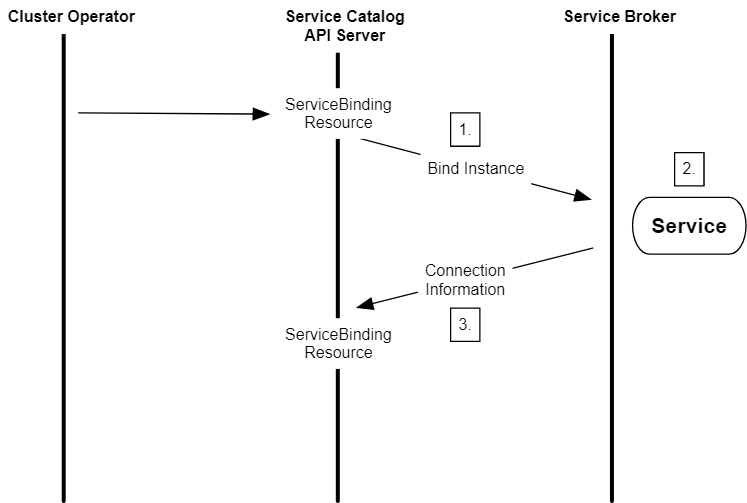
- 在创建 ServiceBinding 之后,服务目录调用外部服务代理,请求绑定服务实例所需的信息。
- 服务代理为相应服务账户启用应用权限/角色。
- 服务代理返回连接和访问托管服务示例所需的信息。这是由提供商和服务特定的,故返回的信息可能因服务提供商和其托管服务而有所不同。
映射连接凭据
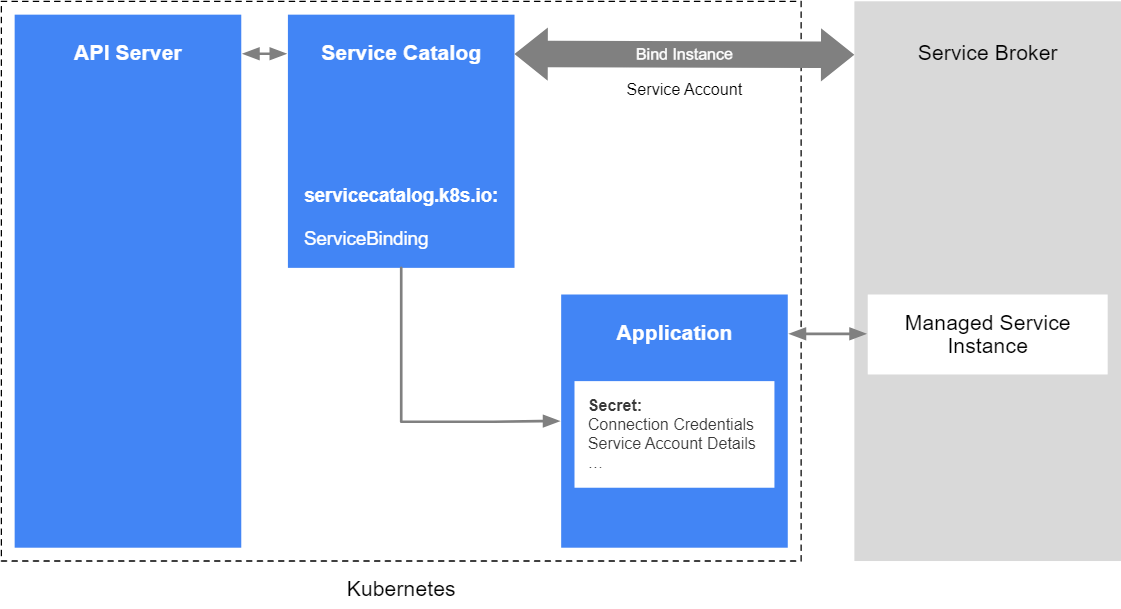
完成绑定之后的最后一步就是将连接凭据和服务特定的信息映射到应用程序中。这些信息存储在 secret 中,集群中的应用程序可以访问并使用它们直接与托管服务进行连接。
Pod 配置文件
执行此映射的一种方法是使用声明式 Pod 配置。
以下示例描述了如何将服务账户凭据映射到应用程序中。名为 sa-key 的密钥保存在一个名为 provider-cloud-key 的卷中,应用程序会将该卷挂载在 /var/secrets/provider/key.json 路径下。环境变量 PROVIDER_APPLICATION_CREDENTIALS 将映射为挂载文件的路径。
...
spec:
volumes:
- name: provider-cloud-key
secret:
secretName: sa-key
containers:
...
volumeMounts:
- name: provider-cloud-key
mountPath: /var/secrets/provider
env:
- name: PROVIDER_APPLICATION_CREDENTIALS
value: "/var/secrets/provider/key.json"
以下示例描述了如何将 Secret 值映射为应用程序的环境变量。在这个示例中,消息队列的主题名从 Secret provider-queue-credentials 中名为 topic 的主键映射到环境变量 TOPIC 中。
...
env:
- name: "TOPIC"
valueFrom:
secretKeyRef:
name: provider-queue-credentials
key: topic

 浙公网安备 33010602011771号
浙公网安备 33010602011771号