[汇编]《汇编语言》第11章 标志寄存器
王爽《汇编语言》第四版 超级笔记
第11章 标志寄存器
CPU内部的寄存器中,有一种特殊的寄存器(对于不同的处理机,个数和结构都可能不同)具有以下3种作用。
(1)用来存储相关指令的某些执行结果;
(2)用来为CPU执行相关指令提供行为依据;
(3)用来控制CPU的相关工作方式。
这种特殊的寄存器在8086CPU中,被称为标志寄存器。8086CPU的标志寄存器有16位,其中存储的信息通常被称为程序状态字(PSW)。
我们己经使用过8086CPU的ax、bx、cx、dx、si、di、bp、sp、IP、cs、ss、ds、es等13个寄存器了,本章中的标志寄存器(以下简称为flag)是我们要学习的最后一个寄存器。
flag和其他寄存器不一样,其他寄存器是用来存放数据的,都是整个寄存器具有一个含义。
而flag寄存器是按位起作用的,也就是说,它的每一位都有专门的含义,记录特定的信息。
8086CPU的flag寄存器的结构如图11.1所示。
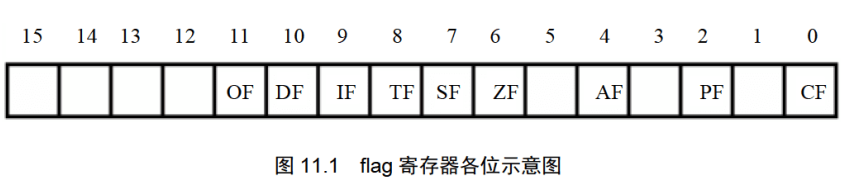
flag的1、3、5、12、13、14、15位在8086CPU中没有使用,不具有任何含义。而0、2、4、6、7、8、9、10、11位都具有特殊的含义。
在这一章中,我们学习标志寄存器中的CF、PF、ZF、SF、OF、DF标志位,以及一些与其相关的典型指令。
11.1 ZF标志、PF标志、SF标志
flag的第6位是ZF,零标志位。它记录相关指令执行后,其结果是否为0。如果结果为0,那么zf=1;如果结果不为0,那么zf=0。
比如,指令:
mov ax,1
sub ax,1
执行后,结果为0,则zf=1。
mov ax,2
sub ax,1
执行后,结果不为0,则zf=0。
对于zf的值,我们可以这样来看,zf标记相关指令的计算结果是否为0,如果为0,则zf要记录下“是0”这样的肯定信息。
在计算机中1表示逻辑真,表示肯定,所以当结果为0的时候zf=1,表示“结果是0”。如果结果不为0,则zf要记录下“不是0”这样的否定信息。
在计算机中0表示逻辑假,表示否定,所以当结果不为0的时候zf=0,表示“结果不是0”。
比如,指令:
mov ax,1
and ax,0
执行后,结果为0,则zf=1,表示“结果是0”。
mov ax,1
or ax,0
执行后,结果不为0,则zf=0,表示“结果非0”。
注意,在8086CPU的指令集中,有的指令的执行是影响标志寄存器的,比如,add、sub、mul、div、inc、or、and等,它们大都是运算指令(进行逻辑或算术运算);
有的指令的执行对标志寄存器没有影响,比如,mov、push、pop等,它们大都是传送指令。在使用一条指令的时候,要注意这条指令的全部功能,其中包括,执行结果对标志寄存器的哪些标志位造成影响。
flag的第2位是PF,奇偶标志位。它记录相关指令执行后,其结果的所有bit位中1的个数是否为偶数。如果1的个数为偶数,pf=1,如果为奇数,那么pf=0。
比如,指令:
mov al,1
add al,10
执行后,结果为00001011B,其中有3(奇数)个1,则pf=0;
mov al,1
or al,2
执行后,结果为00000011B,其中有2(偶数)个1,则pf=1;
sub al,al
执行后,结果为00000000B,其中有0(偶数)个1,则pf=1。
flag的第7位是SF,符号标志位。它记录相关指令执行后,其结果是否为负。如果结果为负,sf=1;如果非负,sf=0。
计算机中通常用补码来表示有符号数据。计算机中的一个数据可以看作是有符号数, 也可以看成是无符号数。比如:
- 00000001B,可以看作为无符号数1,或有符号数+1;
- 10000001B,可以看作为无符号数129,也可以看作有符号数-127。
这也就是说,对于同一个二进制数据,计算机可以将它当作无符号数据来运算,也可以当作有符号数据来运算。比如:
mov al,10000001B
add al,1
结果:(al)=10000010B。
可以将add指令进行的运算当作无符号数的运算,那么add指令相当于计算129+1,结果为130(10000010B);也可以将add指令进行的运算当作有符号数的运算,那么add指令相当于计算-127+1,结果为-126(10000010B)。
不管我们如何看待,CPU在执行add等指令的时候,就己经包含了两种含义,也将得到用同一种信息来记录的两种结果。关键在于我们的程序需要哪一种结果。
SF标志,就是CPU对有符号数运算结果的一种记录,它记录数据的正负。在我们将数据当作有符号数来运算的时候,可以通过它来得知结果的正负。如果我们将数据当作无符号数来运算,SF的值则没有意义,虽然相关的指令影响了它的值。
这也就是说,CPU在执行add等指令时,是必然要影响到SF标志位的值的。至于我们需不需要这种影响,那就看我们如何看待指令所进行的运算了。
比如:
mov al,10000001B
add al,1
执行后,结果为10000010B,sf=1,表示:如果指令进行的是有符号数运算,那么结果为负;
mov al,10000001B
add al,01111111B
执行后,结果为0,sf=0,表示:如果指令进行的是有符号数运算,那么结果为非负。
某些指令将影响标志寄存器中的多个标记位,这些被影响的标记位比较全面地记录了指令的执行结果,为相关的处理提供了所需的依据。
比如指令sub al,al执行后,ZF、PF、SF等标志位都要受到影响,它们分别为:1、1、0。
11.2 CF标志、OF标志
flag的第0位是CF,进位标志位。一般情况下,在进行无符号数运算的时候,它记录了运算结果的最高有效位向更高位的进位值,或从更高位的借位值。
对于位数为N的无符号数来说,其对应的二进制信息的最高位,即第N-1位,就是它的最高有效位,而假想存在的第N位,就是相对于最高有效位的更高位,如图11.2 所示。
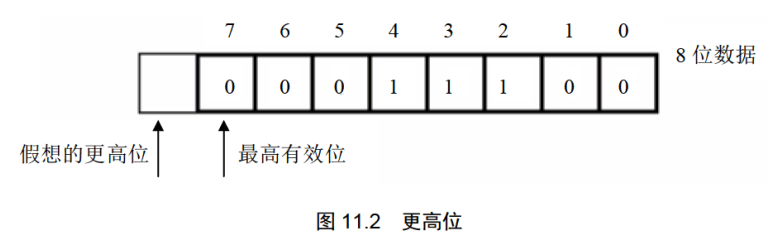
我们知道,当两个数据相加的时候,有可能产生从最高有效位向更高位的进位。比如,两个8位数据:98H+98H,将产生进位。由于这个进位值在8位数中无法保存,我们在前面的课程中,就只是简单地说这个进位值丢失了。
其实CPU在运算的时候,并不丢弃这个进位值,而是记录在一个特殊的寄存器的某一位上。
8086CPU就用flag的CF位来记录这个进位值。比如,下面的指令:
mov al,98H
add al,al ;执行后:(al)=30H, CF=1, CF记录了从最高有效位向更高位的进位值
add al,al ;执行后:(al)=60H, CF=0, CF记录了从最高有效位向更高位的进位值
而当两个数据做减法的时候,有可能向更高位借位。比如,两个8位数据:97H-98H,将产生借位,借位后,相当于计算197H-98H。而flag的CF位也可以用来记录这个借位值。比如,下面的指令:
mov al,97H
sub al,98H ;执行后:(al)=FFH, CF=1, CF记录了向更高位的借位值
sub al,al ;执行后:(al)=0, CF=0, CF记录了向更高位的借位值
我们先来谈谈溢出的问题。在进行有符号数运算的时候,如结果超过了机器所能表示的范围称为溢出。
那么,什么是机器所能表示的范围呢?
比如说,指令运算的结果用8位寄存器或内存单元来存放,比如,add al,3,那么对于8位的有符号数据,机器所能表示的范围就是-128127。同理,对于16位有符号数据,机器所能表示的范围是-3276832767。
如果运算结果超出了机器所能表达的范围,将产生溢出。
注意,这里所讲的溢出,只是对有符号数运算而言。下面我们看两个溢出的例子。
mov al,98
add al,99
执行后将产生溢出。因为add al,99进行的有符号数运算是:
(al)=(al)+99=98+99=197。
而结果197超出了机器所能表示的8位有符号数的范围:-128~127。
mov al,0F0H ;F0H,为有符号数-16的补码
add al,088H ;88H,为有符号数-120的补码
执行后,将产生溢出。因为add al,088H进行的有符号数运算是:
(al)=(al)+(-l 20)=(-16)+(-120)=-136
而结果-136超出了机器所能表示的8位有符号数的范围:-128~127。
如果在进行有符号数运算时发生溢出,那么运算的结果将不正确。就上面的两个例子来说:
mov al,98
add al,99
add指令运算的结果是(al)=0C5H,因为进行的是有符号数运算,所以al中存储的是有符号数,而C5H是有符号数-59的补码。
如果我们用add指令进行的是有符号数运算,则98+99=-59这样的结果让人无法接受。造成这种情况的原因,就是实际的结果197,作为一个有符号数,在8位寄存器al中存放不下。
同样,对于:
mov al,0F0H ;F0H,为有符号数-16的补码
add al,088H ;88H,为有符号数-120的补码
add指令运算的结果是(al)=78H,因为进行的是有符号数运算,所以al中存储的是有符号数,而78H表示有符号数120。如果我们用add指令进行的是有符号数运算,则-16-120=120这样的结果显然不正确。造成这种情况的原因,就是实际的结果-136,作为一个有符号数,在8位寄存器al中存放不下。
由于在进行有符号数运算时,可能发生溢出而造成结果的错误。则CPU需要对指令执行后是否产生溢出进行记录。
flag的第11位是OF,溢出标志位。一般情况下,OF记录了有符号数运算的结果是否发生了溢出。如果发生溢出,OF=1;如果没有,OF=0。
一定要注意CF和OF的区别:CF是对无符号数运算有意义的标志位,而OF是对有符号数运算有意义的标志位。 比如:
mov al,98
add al,99
add指令执行后:CF=0,OF=1。前面我们讲过,CPU在执行add等指令的时候,就包含了两种含义:无符号数运算和有符号数运算。
对于无符号数运算,CPU用CF位来记录是否产生了进位;对于有符号数运算,CPU用OF位来记录是否产生了溢出,当然,还要用SF位来记录结果的符号。
对于无符号数运算,98+99没有进位,CF=0;对于有符数运算,98+99发生溢出,OF=1。
mov al,0F0H
add al,88H
add指令执行后:CF=1,OF=1。对于无符号数运算,0F0H+88H有进位,CF=1;对于有符号数运算,0F0H+88H发生溢岀,OF=1。
mov al,0F0H
add al,78H
add指令执行后:CF=1,OF=0。对于无符号运算,0F0H+78H有进位,CF=1;对于有符号数运算,0F0H+78H不发生溢出,OF=0。
我们可以看出,CF和OF所表示的进位和溢出,是分别对无符号数和有符号数运算而言的,它们之间没有任何关系。
11.3 adc指令、sbb指令、cmp指令
adc是带进位加法指令,它利用了CF位上记录的进位值。
指令格式:adc 操作对象1,操作对象2
功能:操作对象1=操作对象1+操作对象2+CF
比如指令adc ax,bx实现的功能是:(ax)=(ax)+(bx)+CF
例:
mov ax,2
mov bx,1
sub bx,ax
adc ax,1
执行后,(ax)=4。adc执行时,相当于计算:(ax)+1+CF=2+1+1=4。
mov ax,1
add ax,ax
adc ax,3
执行后,(ax)=5。adc执行时,相当于计算:(ax)+3+CF=2+3+0=5。
mov al,98H
add al,al
adc al,3
执行后,(al)=34H。adc执行时,相当于计算:(al)+3+CF=30H+3+1=34H。
可以看出,adc指令比add指令多加了一个CF位的值。
为什么要加上CF的值呢?CPU为什么要提供这样一条指令呢?
先来看一下CF的值的含义。在执行adc指令的时候加上的CF的值的含义,是由adc指令前面的指令决定的,也就是说,关键在于所加上的CF值是被什么指令设置的。
显然,如果CF的值是被sub指令设置的,那么它的含义就是借位值;如果是被add指令设置的,那么它的含义就是进位值。我们来看一下两个数据:0198H和0183H如何相加的:
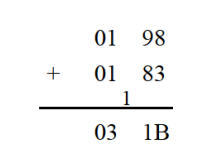
可以看出,加法可以分两步来进行:
①低位相加;
②高位相加再加上低位相加产生的进位值。
下面的指令和add ax,bx具有相同的结果:
add al,bl
adc ah,bh
看来CPU提供adc指令的目的,就是来进行加法的第二步运算的。adc指令和add指令相配合就可以对更大的数据进行加法运算。我们来看一个例子:
编程,计算1EF000H+201000H,结果放在ax(高16位)和bx(低16位)中。
因为两个数据的位数都大于16,用add指令无法进行计算。我们将计算分两步进行,先将低16位相加,然后将高16位和进位值相加。程序如下。
mov ax,001EH
mov bx,0F000H
add bx,1000H
adc ax,0020H
adc指令执行后,也可能产生进位值,所以也会对CF位进行设置。由于有这样的功能,我们就可以对任意大的数据进行加法运算。看一个例子:
编程,计算1EF0001000H+2010001EF0H,结果放在ax(最高16位),bx(次高16位),cx(低16位)中。
计算分3步进行:
(1)先将低16位相加,完成后,CF中记录本次相加的进位值;
(2)再将次高16位和CF(来自低16位的进位值)相加,完成后,CF中记录本次相加的进位值;
(3)最后高16位和CF(来自次高16位的进位值)相加,完成后,CF中记录本次相加的进位值。
程序如下。
mov ax,001EH
mov bx,0F000H
mov cx,1000H
add cx,1EF0H
adc bx,1000H
adc ax,0020H
下面编写一个子程序,对两个128位数据进行相加。
名称:addl28
功能:两个128位数据进行相加。
参数:ds:si指向存储第一个数的内存空间,因数据为128位,所以需要8个字单元,由低地址单元到高地址单元依次存放128位数据由低到高的各个字。运算结果存储在第一个数的存储空间中。
ds:di指向存储第二个数的内存空间。
程序如下。
addl28: push ax
push cx
push si
push di
sub ax,ax ;将CF设置为0
mov cx,8
s:mov ax,[si]
adc ax,[di]
mov [si],ax
inc si
inc si
inc di
inc di
loop s
pop di
pop si
pop cx
pop ax
ret
inc和loop指令不影响CF位。
sbb是带借位减法指令,它利用了CF位上记录的借位值。
指令格式:sbb操作对象1,操作对象2
功能:操作对象1=操作对象1-操作对象2-CF
比如指令sbb ax,bx实现的功能是:(ax)=(ax)-(bx)-CF
sbb指令执行后,将对CF进行设置。利用sbb指令可以对任意大的数据进行减法运算。比如,计算003E1000H-00202000H,结果放在ax,bx中,程序如下:
mov bx,1000H
mov ax,003EH
sub bx,2000H
sbb ax,0020H
sbb和adc是基于同样的思想设计的两条指令,在应用思路上和adc类似。
在这里,我们就不再进行过多的讨论。通过学习这两条指令,我们可以进一步领会一下标志寄存器CF位的作用和意义。
cmp是比较指令,cmp的功能相当于减法指令,只是不保存结果。
cmp指令执行后,将对标志寄存器产生影响。其他相关指令通过识别这些被影响的标志寄存器位来得知比较结果。
cmp指令格式:cmp操作对象1,操作对象2
功能:计算操作对象1-操作对象2但并不保存结果,仅仅根据计算结果对标志寄存器进行设置。
比如,指令cmp ax,ax,做(ax)-(ax)的运算,结果为0,但并不在ax中保存,仅影响flag的相关各位。指令执行后:zf=1,pf=1,sf=0,cf=0,of=0。
下面的指令:
mov ax,8
mov bx,3
cmp ax,bx
执行后:(ax)=8,zf=0,pf=1,sf=0,cf=0,of=0。
其实,我们通过cmp指令执行后,相关标志位的值就可以看岀比较的结果。
cmp ax,bx
- 如果(ax)=(bx) 则(ax)-(bx)=0,所以:zf=1;
- 如果(ax)不等于(bx) 则(ax)-(bx)不等于0,所以:zf=0;
- 如果(ax)<(bx) 则(ax)-(bx)将产生借位,所以:cf=1;
- 如果(ax)>=(bx) 则(ax)-(bx)不必借位,所以:cf=0;
- 如果(ax)>(bx ) 则(ax)-(bx)既不必借位,结果又不为0,所以:cf=0并且zf=0;
- 如果(ax)<=(bx) 则(ax)-(bx)既可能借位,结果可能为0,所以:cf=1或zf=1。
现在我们可以看出比较指令的设计思路,即:通过做减法运算,影响标志寄存器,标志寄存器的相关位记录了比较的结果。反过来看上面的例子。
指令cmp ax,bx的逻辑含义是比较ax和bx中的值,如果执行后:
- zf=1,说明(ax)=(bx)
- zf=0,说明(ax)不等于(bx)
- cf=1,说明(ax)<(bx)
- cf=0,说明(ax)>=(bx)
- cf=0并且zf=0,说明(ax)>(bx)
- cf=1或zf=1,说明(ax)<=(bx)
同add、sub指令一样,CPU在执行cmp指令的时候,也包含两种含义:进行无符号数运算和进行有符号数运算。
所以利用cmp指令可以对无符号数进行比较,也可以对有符号数进行比较。上面所讲的是用cmp进行无符号数比较时,相关标志位对比较结果的记录。下面我们再来看一下如果用cmp来进行有符号数比较时,CPU用哪些标志位对比较结果进行记录。
我们以cmp ah,bh为例进行说明。
cmp ah,bh
- 如果(ah)=(bh) 则(ah)-(bh)=0,所以:zf=1;
- 如果(ah)不等于(bh) 则(ah)-(bh)不等于0,所以:zf=0;
所以,根据cmp指令执行后zf的值,就可以知道两个数据是否相等。
我们继续看,如果(ah)<(bh)则可能发生什么情况呢?
对于有符号数运算,在(ah)<(bh)情况下,(ah)-(bh)显然可能引起sf=1,即结果为负。
比如:
- (ah)=1,(bh)=2;则(ah)-(bh)=0FFH,0FFH为-1的补码,因为结果为负,所以 sf=1。
- (ah)=0FEH,(bh)=0FFH;则(ah)-(bh)=-2-(-1)=0FFH,因为结果为负,所以 sf=1。
通过上面的例子,我们是不是可以得到这样的结论:“cmp 操作对象1,操作对象2”指令执行后,sf=1,就说明操作对象1<操作对象2?
当然不是。
我们再看两个例子。
(ah)=22H,(bh)=0A0H;则(ah)-(bh)=34-(-96)=82H,82H是-126的补码
所以sf=1
这里虽然sf=1,但是并不能说明(ah)<(bh)因为显然34>-96。
两个有符号数A和B相减,得到的是负数,那么可以肯定A<B,这个思路没有错误,关键在于我们根据什么来断定得到的是一个负数。
CPU将cmp指令得到的结果记录在flag的相关标志位中。我们可以根据指令执行后,相关标志位的值来判断比较的结果。单纯地考查sf的值不可能知道结果的正负。因为sf记录的只是可以在计算机中存放的相应位数的结果的正负。
比如add ah,al执行后,sf记录的是ah中的8位二进制信息所表示的数据的正负。cmp ah,bh执行后,sf记录的是(ah)-(bh)所得到的8位结果数据的正负,虽然这个结果没有在我们能够使用的寄存器或内存单元中保存,但是在指令执行的过程中,它暂存在CPU内部的暂存器中。
所得到的相应结果的正负,并不能说明,运算所应该得到的结果的正负。这是因为在运算的过程中可能发生溢出。如果有这样的情况发生,那么,sf的值就不能说明任何问题。比如:
mov ah,22H
mov bh,0A0H
sub ah,bh
结果sf=1,运算实际得到的结果是(ah)=82H,但是在逻辑上,运算所应该得到的结果是:34-(-96)=130。就是因为130这个结果作为一个有符号数超岀了-128~127这个范围,在ah中不能表示,而ah中的结果被CPU当作有符号数解释为-126。而sf被用来记录这个实际结果的正负,所以sf=1。但sf=1不能说明在逻辑上,运算所得的正确结果的正负。
我们考虑一下,两种结果之间的关系,实际结果的正负,和逻辑上真正结果的正负,它们之间有多大的距离呢?
从上面的分析中,我们知道,实际结果的正负,之所以不能说明逻辑上真正结果的正负,关键的原因在于发生了溢岀。如果没有溢出发生的话,实际结果的正负和逻辑上真正结果的正负就一致了。
所以,我们应该在考查sf(得知实际结果的正负)的同时考查(得知有没有溢出),就可以得知逻辑上真正结果的正负,同时就可以知道比较的结果。
下面,我们以cmp ah,bh为例,总结一下CPU执行cmp指令后,sf和of的值是如何来说明比较的结果的。
(1)如果sf=1,而of=0
of=0,说明没有溢出,逻辑上真正结果的正负=实际结果的正负;
因sf=1,实际结果为负,所以逻辑上真正的结果为负,所以(ah)<(bh)。
(2)如果sf=1,而of=1
of=1,说明有溢出,逻辑上真正结果的正负不等于实际结果的正负;
因sf=1,实际结果为负。
实际结果为负,而又有溢出,这说明是由于溢出导致了实际结果为负,简单分析一下,就可以看岀,如果因为溢出导致了实际结果为负,那么逻辑上真正的结果必然为正。
这样,sf=1,of=1,说明了(ah)>(bh)。
(3)如果sf=0,而of=1
of=1,说明有溢出,逻辑上真正结果的正负不等于实际结果的正负;
因sf=0,实际结果非负。而of=1说明有溢岀,则结果非0,所以,实际结果为正。
实际结果为正,而又有溢出,这说明是由于溢出导致了实际结果非负,简单分析一下,就可以看岀,如果因为溢出导致了实际结果为正,那么逻辑上真正的结果必然为负。
这样,sf=0,of=1,说明了(ah)<(bh)。
(4)如果sf=0,而of=0
of=0,说明没有溢出,逻辑上真正结果的正负=实际结果的正负;
因sf=0,实际结果非负,所以逻辑上真正的结果非负,所以(ah)>=(bh)。
我们深入讨论了cmp指令在进行有符号数和无符号数比较时,对flag相关标志位的影响和CPU如何通过相关的标志位来表示比较的结果。
在学习中,要注意领会8086CPU这种工作机制的设计思想。实际上,这种设计思想对于各种处理机来说是普遍的。
下面的内容中我们将学习一些根据cmp指令的比较结果(即cmp指令执行后,相关标志位的值)进行工作的指令。
11.4 检测比较结果的条件转移指令、DF标志和串传送指令
“转移”指的是它能够修改IP,而“条件”指的是它可以根据某种条件,决定是否修改IP。
比如,jcxz就是一个条件转移指令,它可以检测cx中的数值,如果(cx)=0,就修改IP,否则什么也不做。所有条件转移指令的转移位移都是[-128,127]。
除了jcxz之外,CPU还提供了其他条件转移指令,大多数条件转移指令都检测标志寄存器的相关标志位,根据检测的结果来决定是否修改IP。
它们检测的是哪些标志位呢?
就是被cmp指令影响的那些,表示比较结果的标志位。这些条件转移指令通常都和cmp相配合使用,就好像call和ret指令通常相配合使用一样。
因为cmp指令可以同时进行两种比较,无符号数比较和有符号数比较,所以根据cmp指令的比较结果进行转移的指令也分为两种,即根据无符号数的比较结果进行转移的条件转移指令(它们检测zf、cf的值)和根据有符号数的比较结果进行转移的条件转移指令(它们检测sf、of和zf的值)。
下面是常用的根据无符号数的比较结果进行转移的条件转移指令。

这些指令比较常用,它们都很好记忆,它们的第一个字母都是j,表示jump;后面的字母表示意义如下。
e:表不 equal
ne:表示 not equal
b:表示 below
nb:表不 not below
a:表不 above
na:表示 not above
注意观察一下它们所检测的标志位,都是cmp指令进行无符号数比较的时候,记录比较结果的标志位。
比如je,检测zf位,当zf=1的时候进行转移,如果在je前面使用了cmp指令,那么je对zf的检测,实际上就是间接地检测cmp的比较结果是否为两数相等。下面看一个例子。
编程实现如下功能:
如果(ah)=(bh)则(ah)=(ah)+(ah),否则(ah)=(ah)+(bh)。
cmp ah,bh
je s
add ah, bh
jmp short ok
s:add ah,ah
ok: ...
上面的程序执行时,如果(ah)=(bh),则cmp ah,bh使zf=1,而je检测zf是否为1,如果为1,将转移到标号s处执行指令add ah,ah。这也可以说,cmp比较ah、bh后所得到的相等的结果使得je指令进行转移。从而很好地体现了je指令的逻辑含义,相等则转移。
虽然je的逻辑含义是“相等则转移”,但它进行的操作是zf=1时则转移。“相等则转移”这种逻辑含义,是通过和cmp指令配合使用来体现的,因为是cmp指令为“zf=1”赋予了“两数相等”的含义。
至于究竟在je之前使不使用cmp指令,在于我们的安排。je检测的是zf位置,不管je前面是什么指令,只要CPU执行je指令时,zf=1,那么就会发生转移,比如:
mov ax,0
add ax,0
je s
inc ax
s: inc ax
执行后,(ax)=1。add ax,0使得zf=1,所以je指令将进行转移。可在这个时候发生的转移的确不带有“相等则转移”的含义。
因为此处的je指令检测到的zf=1,不是由cmp等比较指令设置的,而是由add指令设置的,并不具有“两数相等”的含义。但无论“zf=1”的含义如何,是什么指令设置的,只要是zf=1,就可以使得je指令发生转移。
对于jne、jb、jnb、ja、jna等指令和cmp指令配合使用的思想和je相同,可以自己分析一下。
虽然我们分别讨论了cmp指令和与其比较结果相关的有条件转移指令,但是它们经常在一起配合使用。
所以我们在联合应用它们的时候,不必再考虑cmp指令对相关标志位的影响和je等指令对相关标志位的检测。因为相关的标志位,只是为cmp和je等指令传递比较结果。
我们可以直接考虑cmp和je等指令配合使用时,表现出来的逻辑含义。它们在联合使用的时候表现出来的功能有些像高级语言中的IF语句。
我们来看下面的一组程序。
data段中的8个字节如下:
data segment
db 8,11,8,1,8,5,63,38
data ends
(1)编程,统计data段中数值为8的字节的个数,用ax保存统计结果。
编程思路:初始设置(ax)=0,然后用循环依次比较每个字节的值,找到一个和8相等的数就将ax的值加1。程序如下。
mov ax,data
mov ds,ax
mov bx,0 ;ds:bx指向第一个字节
mov ax,0 ;初始化累加器
mov cx,8
s: cmp byte ptr [bx],8 ;和8进行比较
jne next ;如果不相等转到next,继续循环
inc ax ;如果相等就将计数值加1
next: inc bx
loop s ;程序执行后:(ax)=3
这个程序也可以写成这样:
mov ax,data
mov ds,ax
mov bx,0 ;ds:bx指向第一个字节
mov ax,0 ;初始化累加器
mov cx,8
s: cmp byte ptr [bx],8 ;和8进行比较
je ok ;如果相等转到ok
jmp short next ;如果不相等转到next,继续循环
inc ax ;如果相等就将计数值加1
ok: inc ax
next: inc bx
loop s ;程序执行后:(ax)=3
比起第一个程序,它直接地遵循了“等于8则计数值加1”的原则,用je指令检测等于8的情况,但是没有第一个程序精简。第一个程序用jne检测不等于8的情况,从而间接地检测等于8的情况。要注意在使用cmp和条件转移指令时的这种编程思想。
(2)编程,统计data段中数值大于8的字节的个数,用ax保存统计结果。
编程思路:初始设置(ax)=0,然后用循环依次比较每个字节的值,找到一个大于8的就将ax的值加1。
程序如下。
mov ax,data
mov ds,ax
mov ax,0 ;初始化累加器
mov bx,0 ;ds:bx指向第一个字节
mov cx,8
s: cmp byte ptr [bx],8 ;和8进行比较
jna next ;如果不大于8转到next,继续循环
inc ax ;如果大于8就将计数值加1
next: inc bx
loop s ;程序执行后:(ax)=3
程序执行后:(ax)=3
(3)编程,统计data段中数值小于8的字节的个数,用ax保存统计结果。
编程思路:初始设置(ax)=0,然后用循环依次比较每个字节的值,找到一个小于8的就将ax的值加1。程序如下。
mov ax,data
mov ds,ax
mov ax,0 ;初始化累加器
mov bx,0 ;ds:bx指向第一个字节
mov cx,8
s: cmp byte ptr [bx],8 ;和8进行比较
jnb next ;如果不小于8转到next,继续循环
inc ax ;如果小于8就将计数值加1
next: inc bx
loop s
程序执行后:(ax)=2
上面讲解了根据无符号数的比较结果进行转移的条件转移指令。根据有符号数的比较结果进行转移的条件转移指令的工作原理和无符号的相同,只是检测了不同的标志位。
我们在这里主要探讨的是cmp、标志寄存器的相关位、条件转移指令三者配合应用的原理,这个原理具有普遍性,而不是逐条讲解条件转移指令。对这些指令感兴趣的读者可以查看相关的指令手册。
flag的第10位是DF,方向标志位。在串处理指令中,控制每次操作后si、di的增减。
- df=0 每次操作后si、di递增;
- df=1 每次操作后si、di递减。
我们来看下面的一个串传送指令。
格式:movsb
功能:执行movsb指令相当于进行下面几步操作。
(1)((es)x16+(di))=((ds)x16+(si))
(2)如果df=0 则:
(si)=(si)+1
(di)=(di)+1
如果df=1 则:
(si)=(si)-1
(di)=(di)-1
用汇编语法描述movsb的功能如下。
mov es:[di],byte ptr ds:[si] ;8086并不支持这样的指令,这里只是个描述
如果df=0:
inc si
inc di
如果df=1:
dec si
dec di
可以看出,movsb的功能是将ds:si指向的内存单元中的字节送入es:di中,然后根据标志寄存器df位的值,将si和di递增或递减。
当然,也可以传送一个字,指令如下。
格式:movsw
movsw的功能是将ds:si指向的内存字单元中的字送入cs:di中,然后根据标志寄存器df位的值,将si和di递增2或递减2。
用汇编语法描述movsw的功能如下。
mov es:[di],word ptr ds:[si] ;8086并不支持这样的指令,这里只是个描述
如果df=0:
add si,2
add di,2
如果df=1:
sub si,2
sub di,2
movsb和movsw进行的是串传送操作中的一个步骤,一般来说,movsb和movsw都和rep配合使用,格式如下:
rep movsb
用汇编语法来描述rep movsb的功能就是:
s: movsb
loop s
可见,rep的作用是根据cx的值,重复执行后面的串传送指令。由于每执行一次movsb指令si和di都会递增或递减指向后一个单元或前一个单元,则rep movsb就可以循环实现(cx)个字符的传送。
同理,也可以使用这样的指令:rep movsw。
相当于:
s: movsw
loop s
由于flag的df位决定着串传送指令执行后,si和di改变的方向,所以CPU应该提供相应的指令来对df位进行设置,从而使程序员能够决定传送的方向。
8086CPU提供下面两条指令对df位进行设置。
- cld指令:将标志寄存器的df位置0
- std指令:将标志寄存器的df位置1
我们来看下面的两个程序。
(1)编程,用串传送指令,将data段中的第一个字符串复制到它后面的空间中。
data segment
db 'Welcome to masm!'
db 16 dup (0)
data ends
我们分析一下,使用串传送指令进行数据的传送,需要给它提供一些必要的信息,它们是:
- 传送的原始位置:ds:si;
- 传送的目的位置:es:di;
- 传送的长度:cx;
- 传送的方向:df。
在这个问题中,这些信息如下。
- 传送的原始位置:data:0;
- 传送的目的位置:data:0010;
- 传送的长度:16;
- 传送的方向:因为正向传送(每次串传送指令执行后,si和di递增)比较方便,所以设置df=0。
好了,明确了这些信息之后,我们来编写程序:
mov ax,data
mov ds,ax
mov si,0 ;ds:si 指向 data:0
mov es,ax
mov di,16 ;es:di 指向 data:0010
mov cx,16 ;(cx)=16, rep 循环16次
cld ;设置df=0,正向传送
rep movsb
(2)编程,用串传送指令,将F000H段中的最后16个字符复制到data段中。
data segment
db 16 dup (0)
data ends
我们还是先来看一下应该为串传送指令提供什么样的信息。
要传送的字符串位于F000H段的最后16个单元中,那么它的最后一个字符的位置:F000:FFFF,是显而易见的。可以将ds:si指向F000H段的最后一个单元,将es:di指向data段中的最后一个单元,然后逆向(即从高地址向低地址)传送16个字节即可。
- 传送的原始位置:F000:FFFF;
- 传送的目的位置:data:000F;
- 传送的长度:16;
- 传送的方向:因为逆向传送(每次串传送指令执行后,si和di递减)比较方便,所 以设置df=1。
程序如下。
mov ax,0f000h
mov ds,ax
mov si,0ffffh ;ds:si 指向 f000:ffff
mov ax,data
mov es,ax
mov di,15 ;es:di 指向data:000F
mov cx,16 ;(cx)=16, rep 循环16次
std ;设置df=1,逆向传送
rep movsb
11.5 pushf和popf、标志寄存器在Debug中的表示
pushf的功能是将标志寄存器的值压栈,而popf是从栈中弹出数据,送入标志寄存器中。
pushf和popf,为直接访问标志寄存器提供了一种方法。
在Debug中,标志寄存器是按照有意义的各个标志位单独表示的。在Debug中,我们可以看到下面的信息。

下面列出Debug对我们已知的标志位的表示。


