[大数据运维]第29讲:大数据平台的硬件规划、网络调优、架构设计、节点规划
第29讲:大数据平台的硬件规划、网络调优、架构设计、节点规划
高俊峰(南非蚂蚁)
这一课时,我将向你介绍 Hadoop 大数据平台的硬件选型、网络方面的架构设计和存储规划等内容。
大数据平台硬件选型
要对 Hadoop 大数据平台进行硬件选型,首先需要了解 Hadoop 的运行架构以及每个角色的功能。在一个典型的 Hadoop 架构中,通常有 5 个角色,分别是 NameNode、Standby NameNode、ResourceManager、NodeManager、DataNode 以及外围机。
其中 NameNode 负责协调集群上的数据存储,Standby NameNode 属于 NameNode 的热备份,ResourceManager 负责协调计算分析,这三者属于管理角色,一般部署在独立的服务器上。
而 NodeManager 和 DataNode 角色主要用于计算和存储,为了获得更好的性能,通常将 NodeManager 和 DataNode 部署在一起。
1.对 NameNode、ResourceManager 及其 Standby NameNode 节点硬件配置
由于角色的不同,以及部署位置的差别,对硬件的需求也不相同,推荐对 NameNode、ResourceManager 及其 Standby NameNode 节点选择统一的硬件配置,基础配置推荐如下表所示:
|
硬件
|
配置
|
|
CPU
|
推荐 2 路 8 核、2 路 10 核或 2 路 12 核等,主频至少 2~2.5GHz
|
|
内存
|
推荐 64~256GB
|
|
磁盘
|
分为 2 组,即系统盘和数据盘,系统盘 2T*2,做 raid1;数据盘 2-4T 左右,数据盘的数量取决于你想冗余备份元数据的份数
|
|
网卡
|
万兆网卡(光纤卡)
|
|
电源
|
均配置冗余电源
|
对于 CPU,可根据资金预算,选择 8 核、10 核或者 12 核。
对于内存,常用的计算公式是集群中 100 万个块(HDFS blocks)对应 NameNode 需要 1GB 内存,如果你的集群规模在 100 台以内,NameNode 服务器的内存配置一般选择 128GB 即可。
由于 NameNode 以及 Standby NameNode 两个节点需要存储 HDFS 的元数据,所以需要配置数据盘,数据盘建议至少配置 4 块,每两块做 raid1,做两组 raid1;然后将元数据分别镜像存储到这两个 raid1 磁盘组中。而对于 ResourceManager,由于不需要存储重要数据,因而,数据盘可不配置。
网络方面,为了不让网络传输成为瓶颈,建议配备光纤接口网卡,节点之间带宽要保证在 10GB左右。
最后,主机电源推荐都是用双电源,虽然有一些费电,但可保证这些重要节点的稳定性,不至于出现电源故障直接宕机的情况。
2.对 NodeManager、DataNode 节点服务器硬件配置
下面再说下企业通用和主流的 NodeManager、DataNode 节点服务器硬件配置,如下表所示:
|
硬件
|
配置
|
|
CPU
|
推荐 2 路 10 核、2 路 12 核或 2 路 14 核等,主频至少 2~2.5GHz
|
|
内存
|
推荐 64~512GB
|
|
磁盘
|
分为 2 组,系统盘和数据盘,系统盘 2T*2,做 raid1;数据盘 4~8T 左右,数据盘单盘使用,无须做 raid
|
|
网卡
|
万兆网卡(光纤卡),存储越多,网络吞吐就要求越高
|
|
电源
|
最好配置冗余电源,如预算不足,也可使用单电源
|
由于 NodeManager、DataNode 主要用于计算和存储,所以对 CPU 性能要求会比较高,推荐 2 路 14 核。
内存方面,如果分布式计算中涉及 Spark、HBase 组件,那么建议配置大内存,每个节点 256GB 内存是个不错的配置。
磁盘方面,DataNode 节点主要用来存储数据,所以需要配置大量磁盘,磁盘单盘使用,无须做 raid,磁盘大小推荐每块 8T。不建议使用更大的单盘,当然如果有条件,也可采购 SSD 磁盘,但是 SSD 磁盘成本太高,需要根据预算来定。
每个 DataNode 建议配置 8 ~ 10 块硬盘,具体数量,需要根据总共需要的存储空间而定。例如,假设总共需要存储 800TB 的数据,HDFS 的块副本数为 3,如果每个 DataNode 配置 10 块 8T 的硬盘,那么,采购 30 台 DataNode 服务器即可。NodeManager 节点也会存储一些分析任务的中间结果以及日志等临时数据,建议这些数据的存储路径和 HDFS 的数据存储路径分开,单独规划 3~5 块 4~8T 磁盘来存储这些临时数据即可,同理,这些磁盘也无须做 raid,单盘使用即可。
在网络方面,也建议 NodeManager 和 DataNode 采购光纤接口网卡,所有 NodeManager、DataNode 节点连接到光纤交换机,保证节点之间 10GB 高速网络传输。
最后,在电源方面,可根据预算,决定是否采购双电源,在集群模式下,NodeManager 或 DataNode 某个节点故障对 Hadoop 影响不大,所以使用单电源也是可行的。
大数据平台网络架构设计
1.Hadoop 基础网络架构
普通的 Hadoop 网络一般由两层结构组成:接入交换机和汇聚交换机(或者核心交换机),在具体布线上采用 TOR 方式,在一个 42U 的标准服务器机柜的最上面安装接入交换机,每个服务器的光纤网口都接入到机柜上部的光交换机上,这个接入交换机再通过光纤,接入到网络机柜的汇聚或核心交换机上。
基本架构如下图所示:
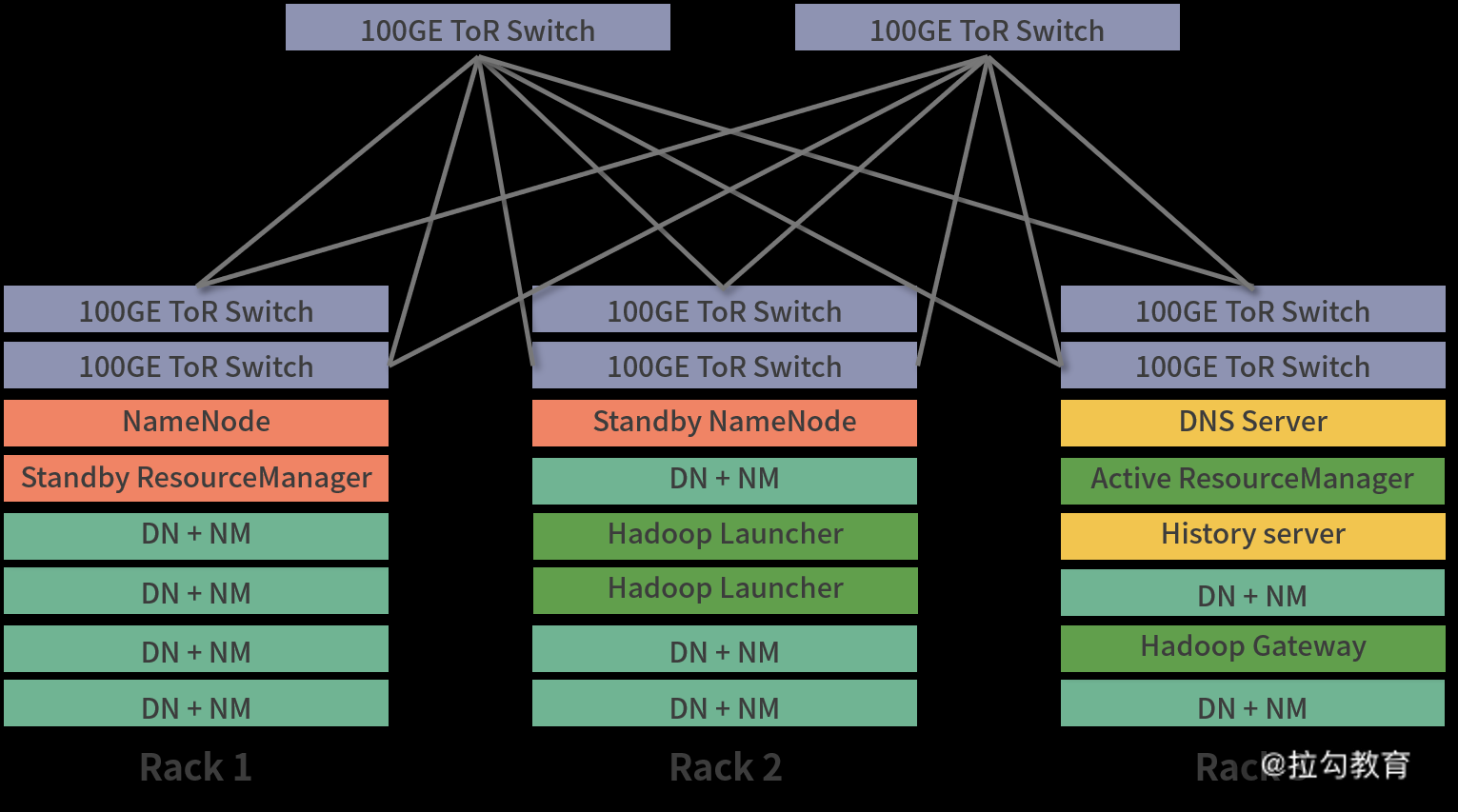
在上图中,列出了三个机柜,在每个机柜上有两个 10GE 的 TOR 交换机,这两个交换机为主、备模式,然后这些主、被交换机在通过光纤接入到上层的 100GE 汇聚交换机上。这种部署默认可以最大限度地保证网络的传输质量和稳定性。
在每个机柜中都可部署相应的 Hadoop 服务,可以看出,机柜 1 和 2 分别部署了 NameNode 的主、被节点,这两个主、备节点分开部署到不同的机柜,可以最大限度保证 NameNode 的可靠性,不建议将主、备节点部署到同一个机柜中,因为如果某个机柜发生故障(电源故障、网络故障),那么主、备将失去存在的意义。
同理,ResourceManager 节点也部署了主、备的 HA 功能,这两个节点也不能在一个机柜中,这是一个基本常识。此外,在每个机柜中,都分布着 NodeManager 和 DataNode 节点,并且这两个服务是部署在一起的。
此外,在三个机柜中,还有 Hadoop gateway 节点,这些节点相当于用户与 Hadoop 的交互接口,通过这些节点提交任务到 Hadoop 集群中,通常这些节点也可以有多个,建议分布在多个机柜中。
2.Hadoop 机架感知机制
所谓机架感知就是自动了解 Hadoop 集群中每个机器节点所属的机架,某个 Datanode 节点是属于哪个机柜并非智能感知的,而是需要 Hadoop 的管理者人为地告知 Hadoop 哪台机器属于哪个机柜。
这样在 Hadoop 的 Namenode 启动初始化时,会将这些机器与机柜的对应信息保存在内存中,用来作为 HDFS 写数据块操作分配 Datanode 列表时(比如 3 个 block 对应三台 Datanode)选择 DataNode 的策略。
比如,要写三个数据块到对应的三台 Datanode,那么通过机架感知策略,可以尽量将三个副本分布到不同的机柜上。
默认情况下,Hadoop 的机架感知功能没有启用。所以,通常情况下,Hadoop 集群的 HDFS 在选机器时,是随机选择的,这在某些情况下会影响 HDFS 读写性能,进而影响作业的性能以至于整个集群的服务。
而在开启了机架感知后,不同节点之间的通信能够尽量发生在同一个机架之内,而不是跨机架,同时,为了提高容错能力,Namenode 节点会尽可能把数据块的副本放到多个机架上,进而提升数据的安全性。
要查看当前集群机架配置情况,可执行如下命令:
[hadoop@namenodemaster conf]$ hdfs dfsadmin -printTopology
Rack: /default-rack
172.16.213.103:9866 (slave002)
172.16.213.169:9866 (slave003)
172.16.213.70:9866 (slave001)
可以看到默认所有节点都是一个机架 default-rack,此时没有配置机架感知。要配置机架感知,首先需要自定义机器机架位置,编写机架配置文件 rack.data,内容如下:
172.16.213.103 slave002 /switch1/rack2
172.16.213.70 slave001 /switch1/rack1
172.16.213.169 slave003 /switch1/rack3
这里将三个节点分别放到三个不同的机柜中。
然后还需要配置一个机架感知脚本,假定脚本名称为 rack.sh,内容如下:
#!/bin/bash
HADOOP_CONF=/etc/hadoop/conf/
while [ $# -gt 0 ] ;
do
nodeArg=$1
exec<${HADOOP_CONF}/rack.data
result=""
while read line
do
ar=( $line )
if [ "${ar[0]}" = "$nodeArg" ]||[ "${ar[1]}" = "$nodeArg" ]
then
result="${ar[2]}"
fi
done
shift
if [ -z "$result" ]
then
echo -n "/default-rack"
else
echo -n "$result"
fi
done
将此脚本放大 Hadoop 配置文件目录下即可,并授予可执行权限。
最后一步,还需要修改 core-site.xml 文件,添加机架感知脚本,添加如下内容:
<property>
<name>net.topology.script.file.name</name>
<value>/etc/hadoop/conf/rack.sh</value>
</property>
配置完成后,需要重启 NameNode 服务,配置才能生效。
重启服务后,要验证机架感知配置是否生效,可执行如下命令:
[hadoop@namenodemaster conf]$ hdfs dfsadmin -printTopology
Rack: /switch1/rack1
172.16.213.70:9866 (slave001)
Rack: /switch1/rack2
172.16.213.103:9866 (slave002)
Rack: /switch1/rack3
172.16.213.169:9866 (slave003)
可以看出,HDFS 的机架感知配置已经成功。
3.大数据平台架构设计要点
在构建大数据平台之前,首先要考虑需要的存储容量、计算能力、是否有实时分析的需求、数据的存储周期等因素,然后再根据这些需求进行平台的架构设计。
同时,还要考虑平台的健壮性,例如,任意一个节点宕机都不会影响平台的正常使用,任何一个磁盘的损坏都不会导致数据丢失等。
针对 Hadoop 大数据平台的基础架构,最基本的要求是保证 NameNode、ResourceManager 这些管理节点的高可用性,因此这些节点必须要做 HA。
此外,为了保障 HDFS 数据的安全性,对 Hadoop 块存储一定要设置合适的副本数。例如,设置 3 个副本,那么集群中任意 2 个 datanode 节点故障宕机,都不会丢失数据。
在网络方面,建议每个节点的服务器采用双网卡绑定,网络设置为冗余模式,并和交换机做冗余绑定,做到单个网卡故障或者单个交换机故障,都能保证此节点网络正常运行。
下面是一个典型的 Hadoop 大数据平台部署拓扑,如下图所示:
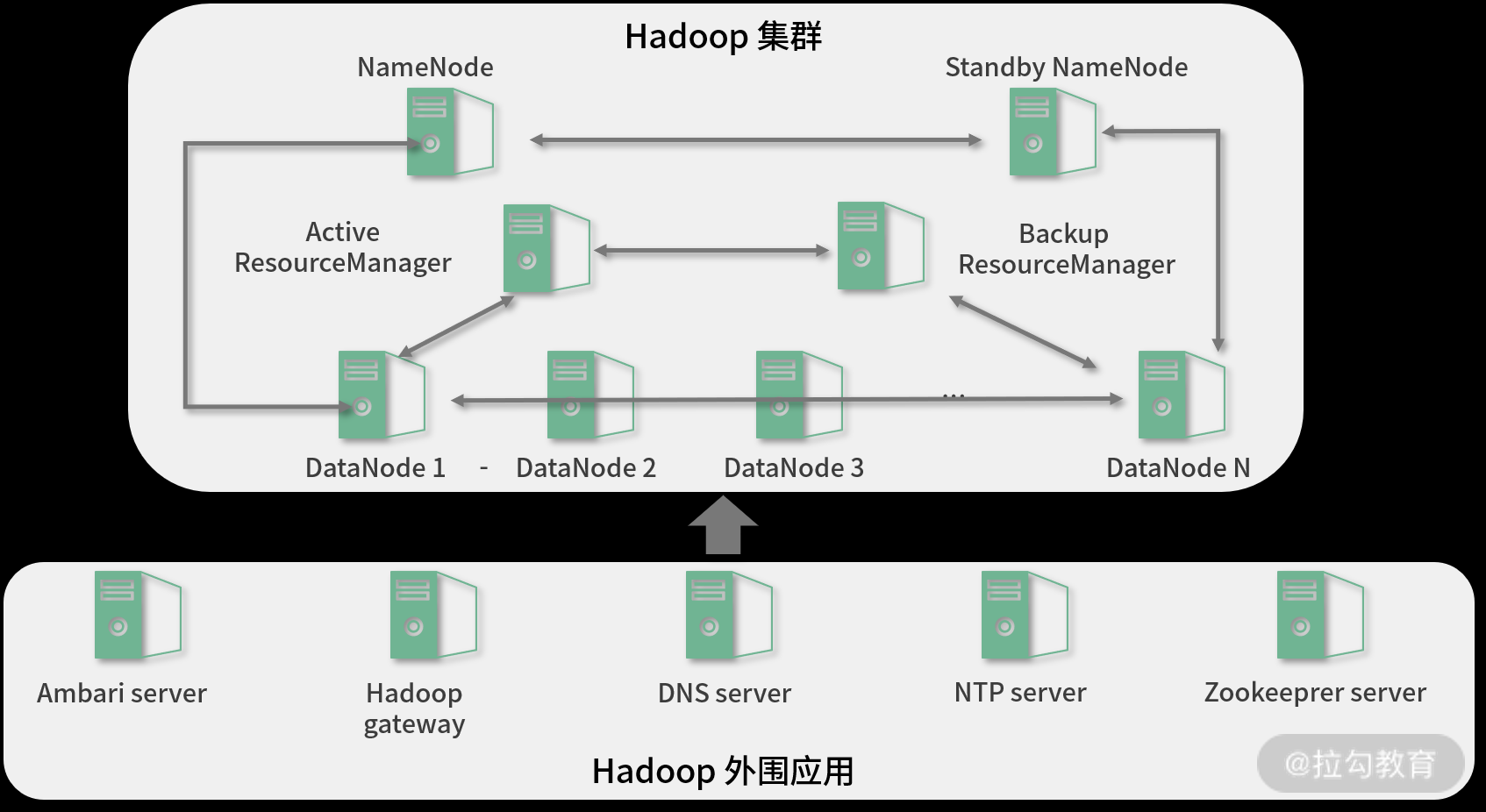
从图中可以看出,NameNode、ResourceManager 节点都部署了高可用功能,任何一个节点故障都不会影响集群的存储和计算。此外,DataNode 节点可根据存储周期、存储容量、计算任务数进行扩容和缩容,并且扩容、缩容可在线直接进行,不影响集群运行。
此外,在 Hadoop 集群之外,还要跟 Hadoop 配合的一些外围应用,例如 ambari,用来自动化运维、监控 Hadoop 集群,Hadoop gateway 用于和 Hadoop 集群的交互接口,而 DNS server 和 NTP server 主要用于 Hadoop 集群内部的主机名解析与时间同步。Zookeeper Server 用于 Hadoop 集群中的仲裁和协调调度。
大数据平台存储、计算节点规划
对大数据平台存储和计算资源的规划,需要根据实际应用需求判断,例如,现有的和日增长的数据量、数据的存储周期、每天计算任务的中间结果数据量,以及数据冗余空间,比如保持几个副本等实际应用需求。
我以一个实际案例举例说明:目前有数据量 500TB,每天数据量增长 2T 左右,数据块副本为 3,所有数据存储周期为 2 年,根据这个需求,就可以算出需要的存储节点数。
-
2 年数据量需要的存储空间:(2*3)*(365*2)=4380TB
-
总共需要的存储空间:4380TB+(500*3)TB=5880TB
如果以一个存储节点 12 块 4T 硬盘来计算,则需要约(5880TB/48TB=147)123 个存储节点;而如果采用一个存储节点 10 块 8T 硬盘来计算,需要约(5880TB/80TB=147)74 个存储节点即可。
那么此时如何选择每个节点硬盘的大小呢?这就要看大数据平台需要的计算资源有多少了,很显然,按照 4T 硬盘 12 块来规划的话,可获得更多的计算资源(CPU、内存),但此方案需要采购 123 台服务器,成本较高;反之,如果采用 10块 8T 硬盘来规划的话,那么只需要 74 台服务器即可,此时可计算 74 台服务器是否能满足计算资源的要求,如果能满足,那么这个磁盘规划就是最合适的。
对于计算资源规划,要看都运行哪些应用,如果是 Spark、HBase、ElasticSearch 这类吃内存的大数据组件,那么建议计算节点所选的服务器的内存一定要大,最好 64GB 起,能有 128GB 更好。由于前期对计算资源需求很难评估,所以可根据上面这个原则去配置 CPU 和内存即可,如果遇到计算性能瓶颈,可以在后期进行水平扩展,非常方便。
大数据平台对硬件的规划原则: 如果能够确切地知道存储和计算的资源需要,那么就按照这个需求来配置即可;但如果无法准确地评估出存储和计算资源需求量,那么一定要留下可扩展的余地,比如留下足够的机柜位置、网络接口、磁盘接口等。在实际应用中,存储容量一般很好预估,但计算资源很难预估,因此留下足够的扩展接口,是必须要考虑的一个问题。
总结
本课时主要介绍了 Hadoop 大数据平台的硬件选项、网络方面的架构设计和存储规划等内容。其中如何对大数据平台做好存储、计算等资源的规划,至关重要,它也是运维大数据平台的第一步,如果前期规划不当,到后期发现架构不合理,那么需要修改或者扩展将非常困难,所以这部分内容需要你反复练习揣摩。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号