[大数据运维]第25讲:Yarn 资源调度 Fair Schedule 与 Capacity Scheduler 配置选型
第25讲:Yarn 资源调度 Fair Schedule 与 Capacity Scheduler 配置选型
高俊峰(南非蚂蚁)
在大数据平台运维中,会经常遇到集群资源争抢的问题。因为在公司内部,Hadoop Yarn 集群一般会被多个业务、多个用户同时使用,共享 Yarn 资源。此时,如果不对集群资源做规划和管理的话,那么就会出现 Yarn 的资源被某一个用户提交的 Application(App)占满,而其他用户只能等待;或者也可能会出现集群还有很多剩余资源,但 App 就是无法使用的情况。
如何解决这个问题呢?此时就需要用到 Hadoop 中提供的资源调度器。
Yarn 多用户资源管理策略
Yarn 提供了可插拔的资源调度算法,用于解决 App 之间资源竞争的问题。在 Yarn 中有三种资源调度器可供选择,即 FIFO Scheduler、Capacity Scheduler、Fair Scheduler,目前使用比较多的是 Fair Scheduler 和 Capacity Scheduler。下面对这三种资源调度器分别进行介绍。
1. FIFO Scheduler
在 Hadoop 1.x 系列版本中,默认使用的调度器是 FIFO,它采用队列方式将每个任务按照时间先后顺序进行服务。比如排在最前面的任务需要若干 Map Task 和 Reduce Task,当发现有空闲的服务器节点时就分配给这个任务,直到任务执行完毕。
2. Capacity Scheduler
在 Hadoop 2.x/3.x 系列版本中,默认使用的调度器是 Capacity Scheduler(容量调度器),这是一种多用户、多队列的资源调度器。每个队列可以配置资源量,可限制每个用户、每个队列的并发运行作业量,也可限制每个作业使用的内存量;每个用户的作业有优先级,在单个队列中,作业按照先来先服务(实际上是先按照优先级,优先级相同的再按照作业提交时间)的原则进行调度。
容量资源调度器,支持多队列,但默认情况下只有 root.default 这一个队列。
当不同用户提交任务时,任务都会在这个队列里按照先进先出策略执行调度,很明显,单个队列会大大降低多用户的资源使用率。
因此,要使用容量资源调度,一定要配置多个队列,每个队列可配置一定比率的资源量(CPU、内存);同时为了防止同一个用户的任务独占队列的所有资源,调度器会对同一个用户提交的任务所占资源量进行限定。
举个简单的例子,下图是容量调度器中配置好的一个队列树:
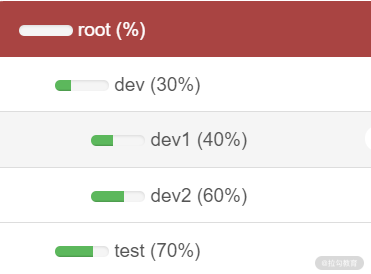
上图通过队列树方式对 Yarn 集群资源做了一个划分,可以看到,在 root 队列下面定义了两个子队列 dev 和 test,分别占 30% 和 70% 的 Yarn 集群资源;而 dev 队列又被分成了 dev1 和 dev2 两个子队列,分别占用 dev 队列 30% 中的 40% 和 60% 的 Yarn 集群资源。
容量调度除了可以配置队列及其容量外,还可以配置一个用户或任务可以分配的最大资源数量、同时可以配置运行应用的数量、队列的 ACL 认证等。
如何让任务运行在指定的队列呢?
有两种方式,一种是直接指定队列名,另一种是通过用户名、用户组和队列名进行对应。注意:对于容量调度器,我们的队列名必须是队列树中的最后一部分,如果使用队列树则不会被识别。例如,在上面配置中,可直接使用 dev1 和 dev2 作为队列名,但如果用 root.dev.dev1 或者 dev.dev2 则都是无效的。
3. Fair Scheduler
Fair Scheduler(公平调度器)支持多用户、多分组管理,每个分组可以配置资源量,也可限制每个用户和每个分组中并发运行的作业数量;每个用户的作业有优先级,优先级越高分配的资源就越多。公平调度器的主要目标是实现 Yarn 上运行的任务能公平的分配到资源。
Fair Scheduler 将整个 Yarn 的可用资源划分成多个队列资源池,每个队列中可以配置最小和最大的可用资源(内存和 CPU)、最大可同时运行 Application 数量、权重,以及可以提交和管理 Application 的用户等。
资源池以及用户的对应关系如下图所示:
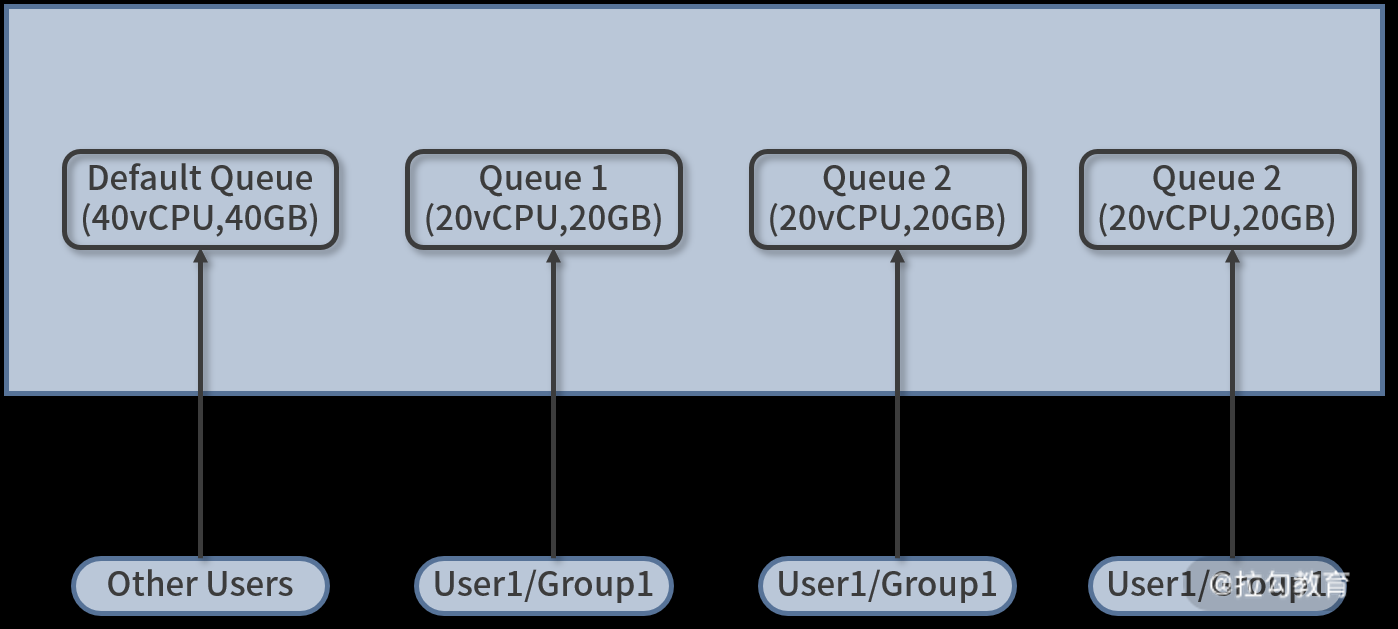
在上图中,假设整个 Yarn 集群可用的 CPU 资源为 100vCPU,可用的内存资源为 100GB。现在为三个业务线各自划分一个队列,分别是 Queue1、Queue2 和 Queue3,每个队列可用的资源均为 20vCPU 和 20GB 内存,最后还规划了一个 default 队列,用于运行其他用户和业务提交的任务。可用资源为 40vCPU 和 40GB 内存,这样,四个队列将整个 Yarn 集群资源刚好分配完毕。
在执行任务的时候,可以显性地指定任务运行的队列,但更多情况下不指定队列,而是通过用户名作为队列名称来提交任务,即用户 user1 提交的任务被分配到队列 Queue1 中,用户 user2 提交的任务被分配到资源池 Queue2 中。注意,这里的 user1 和 user2 是配置的固定用户,除了这些用户外,其他未指定的用户提交的任务将会被分配到 default 队列中。这里的用户名,就是提交 App 所使用的 Linux/Unix 的系统用户名。
除了可以通过用户名作为队列名,在用户比较多的时候,还可以使用用户组,将同一类用户放到一个用户组下,然后将这个用户组配置到资源调度策略中。
接下来,向你介绍 Fair Scheduler 调度的配置。
Fair Scheduler 调度的配置
要启用公平调度器,首先需要配置 yarn-site.xml 文件,添加如下设置:
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
公平调度器的配置文件路径位于 HADOOP_CONF_DIR下 的 fair-scheduler.xml 文件中,这个路径可以通过配置 yarn-site.xml 文件,添加如下内容来实现:
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>/etc/hadoop/conf/fair-scheduler.xml</value>
</property>
若没有这个配置文件,调度器会在用户提交第一个应用时为其自动创建一个队列,队列的名字就是用户名,所有的任务都会被分配到 default 队列中。
接下来重点看看 fair-scheduler.xml 文件如何编写,此文件中定义队列的层次是通过嵌套元素实现的。所有的队列都是 root 队列的孩子,下面是一个定义好的公平调度策略:
<?xml version="1.0"?>
<allocations>
<!-- users max running apps -->
<userMaxAppsDefault>10</userMaxAppsDefault>
<queue name="root">
<aclSubmitApps> </aclSubmitApps>
<aclAdministerApps> </aclAdministerApps>
<queue name="default">
<minResources>12000mb,5vcores</minResources>
<maxResources>100000mb,50vcores</maxResources>
<maxRunningApps>22</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>1</weight>
<aclSubmitApps>*</aclSubmitApps>
</queue>
<queue name="dev_group">
<minResources>115000mb,50vcores</minResources>
<maxResources>500000mb,150vcores</maxResources>
<maxRunningApps>181</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>5</weight>
<aclSubmitApps> dev_group</aclSubmitApps>
<aclAdministerApps>hadoop dev_group</aclAdministerApps>
</queue>
<queue name="test_group">
<minResources>23000mb,10vcores</minResources>
<maxResources>300000mb,100vcores</maxResources>
<maxRunningApps>22</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>4</weight>
<aclSubmitApps> test_group</aclSubmitApps>
<aclAdministerApps>hadoop test_group</aclAdministerApps>
</queue>
</queue>
<queuePlacementPolicy>
<rule name="user" create="false" />
<rule name="primaryGroup" create="false" />
<rule name="secondaryGroupExistingQueue" create="false" />
<rule name="default" queue="default" />
</queuePlacementPolicy>
</allocations>
下面介绍这个配置中的几个配置项的含义:
|
配置项
|
含义
|
|
userMaxAppsDefault
|
默认的用户最多可同时运行多少个应用程序
|
|
minResources
|
设置最少资源保证量,设置格式为“X mb, Y vcores”,当一个队列的最少资源保证量未满足时,它将优先于其他同级队列获得资源
|
|
maxResources
|
设置最多可以使用的资源量,fair scheduler 会保证每个队列使用的资源量不会超过该队列的最多可使用资源量
|
|
maxRunningApps
|
设置最多同时运行的应用程序数
|
|
schedulingMode
|
设置队列采用的调度模式,可以是 fifo、fair 或者 drf
|
|
weight
|
设置队列的权重,权重越高,可获取的资源就越多
|
|
aclSubmitApps
|
表示可向队列中提交应用程序的用户和组列表,默认情况下为“*”,表示任何用户和组均可以向该队列提交应用程序
|
再来看一下队列执行规则列表(Queue Placement Policy),Fair 调度器采用了一套基于规则的配置来确定应用应该放到哪个队列中。在上面的例子中,我定义了一个规则列表,总共有四个规则,其中的每个规则会被逐个尝试,直到匹配成功。
例如,第一个规则是 user,表示将提交任务的用户名作为队列名,然后将任务放到这个队列中执行;第二个规则 primaryGroup,表示将提交任务的用户所属的主组作为队列名;第三个规则 secondaryGroupExistingQueue 表示将提交任务的用户所属的附属组作为队列名;最后一个规则 default,表示当前面所有规则都不满足时,用户提交的任务会放到 default 队列中。
除了上面的规则之外,还可以在 yarn-site.xml 文件添加如下配置:
<property>
<name>yarn.scheduler.fair.user-as-default-queue</name>
<value>true</value>
<description>default is True</description>
</property>
此配置值默认为 true,表示当任务中未指定队列名时,将以用户名作为队列名,这个配置就实现了根据用户名自动分配队列;如果设置为 false,那么所有任务会被放入 default 队列,而不是放到基于用户名的队列中。
另外,我们还可以在 yarn-site.xml 文件添加如下配置:
<property>
<name>yarn.scheduler.fair.allow-undeclared-pools</name>
<value>false</value>
<description>default is True</description>
</property>
此配置表示是否允许创建未定义的队列,默认值为 true,表示 Yarn 将会自动创建任务中指定的未定义过的队列名。设置成 false 后,用户就无法创建队列了,该任务会被分配到 default 队列中。
最后,再来说下资源抢占,当一个任务提交到一个繁忙集群中的空队列时,任务并不会马上执行,而是暂时阻塞,直到正在运行的任务释放系统资源,才开始执行。为了使提交的任务执行时间更具预测性(可以设置等待的超时时间),Fair 调度器支持抢占。
抢占就是允许调度器杀掉占用超过其应占资源份额队列的 containers,这些 containers 资源释放后可,被分配到应该享有这些份额资源的队列中。需要注意,抢占会降低集群的执行效率,因为被终止的 containers 需要被重新执行。
要启用抢占模式,可以在 yarn-site.xml 文件中添加如下配置:
<property>
<name>yarn.scheduler.fair.preemption</name>
<value>true</value>
</property>
可以设置此参数为 true 来启用抢占功能。此外,还需要在 fair-scheduler.xml 文件中添加一个参数用来控制抢占的过期时间,参数设置如下:
<fairSharePreemptionTimeout>60</fairSharePreemptionTimeout>
此参数用来设置某个队列的超时时间,如果队列在指定的时间内未获得最小的资源保障,调度器就会抢占 container。
还可以在 fair-scheduler.xml 文件中添加全局配置参数,内容如下:
<defaultFairSharePreemptionTimeout>60</defaultFairSharePreemptionTimeout>
此参数用来配置所有队列的超时时间。
这里需要注意,在 fair-scheduler.xml 配置中,添加了用户和用户组,这里的用户和用户组的对应关系,需要维护在 ResourceManager 上,ResourceManager 在分配资源池时候,是从 ResourceManager 所在的操作系统上读取用户和用户组的对应关系的,否则就会被分配到default 队列中。而客户端机器上的用户对应的用户组无关紧要。
在 fair-scheduler.xml 第一次添加、配置完成后,需要重启 Yarn 集群才能生效,而后面再对 fair-scheduler.xml 进行修改用户或者调整资源池配额后,无须重启 yarn 集群,只需执行下面的命令刷新即可生效:
[hadoop@yarnserver ~]$ yarn rmadmin -refreshQueues
[hadoop@yarnserver ~]$ yarn rmadmin -refreshUserToGroupsMappings
动态更新只支持修改资源池配额,如果是新增或减少资源池,则还需要重启 Yarn 集群。
容量调度与公平调度对比与选型
1. 相同
容量调度和公平调度实现的功能基本一致,例如,它们都支持多用户、多队列,即都适用于多用户共享集群的应用环境。同时,单个队列均支持优先级和 FIFO 调度方式,还支持资源共享,即某个队列中的资源有剩余时,可共享给其他缺资源的队列。
2. 不同
-
核心调度策略不同
容量调度器的调度策略是,先选择资源利用率低的队列,然后在队列中同时考虑 FIFO 和内存因素;而公平调度器仅考虑公平,而公平是通过任务缺额体现的,调度器每次选择缺额最大的任务(队列的资源量,任务的优先级等仅用于计算任务缺额)。
-
对特殊任务的处理不同
容量调度器调度任务时会考虑作业的内存限制,为了满足某些特殊任务的特殊内存需求,可能会为该任务分配多个 slot;而公平调度器对这种特殊的任务无能为力,只能杀掉这种任务。
因此,具体选用哪种调度算法,可根据实际应用需求而定。一个基本的经验是,小型 Yarn 集群(100 个节点以内),可考虑使用公平调度器,而大型 Yarn 集群(超过 100 个节点)可采用容量调度器效果会更好。
总结
本课时主要介绍了 Yarn 集群中常用的两个资源调度器:容量调度和公平调度。通过该课时的学习,我们了解到,在多个用户同时使用 Yarn 集群的时候,合理地设置调度器可以有效利用集群资源,并减少资源争抢,使集群资源利用率达到最大化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号