[大数据运维]第23讲:Namenode、Datanode、Nodemanager 等服务状态监控策略
第23讲:Namenode、Datanode、Nodemanager 等服务状态监控策略
高俊峰(南非蚂蚁)
Centreon 介绍与安装
Centreon 是一款功能强大的分布式 IT 监控系统,通过第三方组件可以实现对网络、操作系统和应用程序的监控:
-
首先,它是开源的,你可以免费使用它;
-
其次,它的底层采用 centreon-engine(类似 Nagios 的引擎)作为监控软件,同时通过 cbd 模块将监控到的数据定时写入数据库中,而 Centreon 实时从数据库读取该数据并通过 Web 界面展现监控数据;
-
最后,Centreon 就是 Nagios 的一个管理配置工具,通过 Centreon 提供的 Web 配置界面,可以轻松完成各种烦琐的监控配置。
Centreon 的安装非常简单,有 ISO 镜像安装、VM 虚拟机安装、源码编译安装和 yum 源安装四种方式。其中,源码编译安装较复杂,出错概率也较高,我比较推荐采用 ISO 镜像安装方式或者虚拟机镜像方式进行安装。
你可以从 Centreon 官网下载到需要的版本,如下图所示:
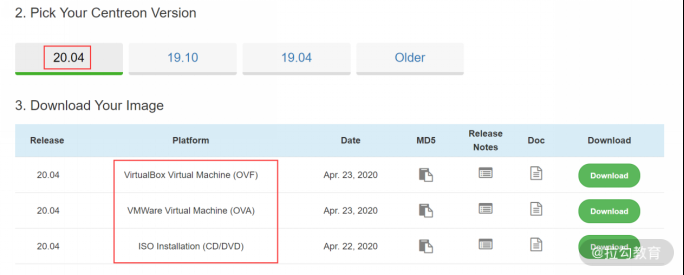
我下载的是 VirtualBox Virtual Machine,其实就是一个打包好的虚拟机。下载后,将文件导入 VirtualBox 虚拟机,然后直接启动系统即可完成安装,非常简单。登录系统,默认的用户名是 root,密码为 centreon。
虚拟机启动完成后,直接访问虚拟机的 IP 地址,即可打开 Centreon 登录界面,默认情况下 Centreon Web 登录的用户名为 admin,密码为 centreon。
Centreon 配置与使用
配置 Centreon 并不复杂,所有操作都能在 Web 管理界面完成,如果对 Nagios 的配置过程比较了解,那么配置 Centreon 就变得非常简单。
下面先来熟悉一下 Centreon 中配置文件之间的关系。
在 Centreon 的配置过程中涉及几个定义:主机、主机组、主机模板,服务、服务组、服务模板、联系人、联系人组、监控时间和监控命令等。从这些定义可以看出,Centreon 的各个配置文件之间是互相关联,彼此引用的关系。
成功配置一台 Centreon 监控系统,必须要弄清楚每个配置文件之间依赖与被依赖的关系,其中,最重要的有四点:
-
要定义监控哪些主机、主机组、服务和服务组;
-
要定义这个监控需通过什么命令实现;
-
要定义监控的时间段;
-
定义主机或服务出现问题时要通知的联系人和联系人组。
1. 配置主机模板
登录 Centreon Web,在左侧导航中,选择 Configuration → Hosts →Templates,然后编辑 generic — active — host — custom 模板,如下图所示:
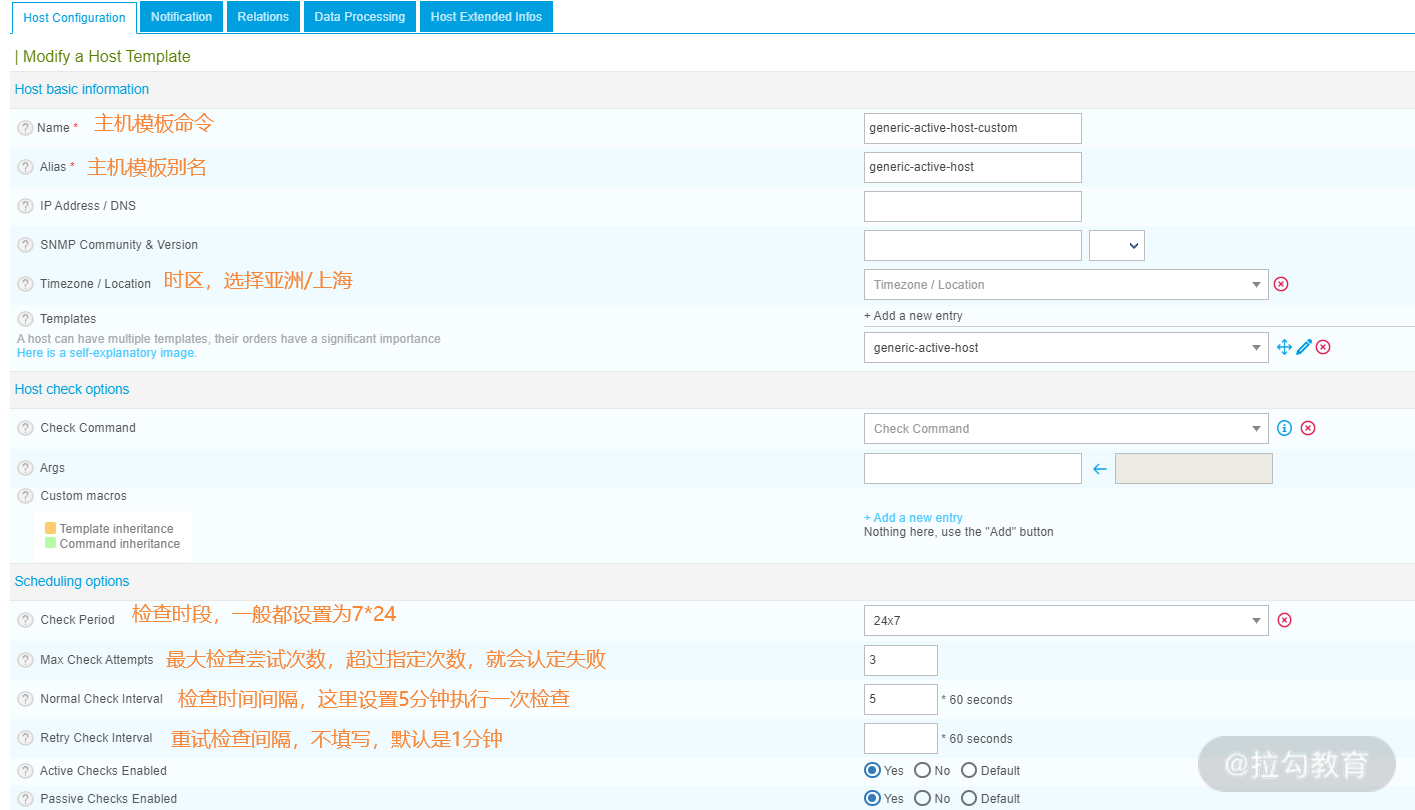
主机模板,是对主机默认属性或通用属性的设置。 只有主机引用了这个模板,那么此模板的设置值就继承到主机里面了。一些基础的主机监控,比如主机检查属性、报警通知属性、自定义宏属性等都可以在主机模板中进行设置,当然也可以在定义主机监控的时候设置这些属性。
主机模板的一个最大特点是继承性,如果一个主机引用了这个模板,那么此主机模板下的所有监控属性都被自动继承过来了。
例如,要对 1000 台主机做 ping 连通性检查,首先可以创建一个 check_ping 命令,然后将这个命令引用到主机模板中,最后在创建主机的时候,这 1000 台主机都引用这个主机模板即可。
引用主机模板的好处是,如果监控属性发生了变化,只需修改主机模板的配置即可,而无须一个主机一个主机地修改,方便快捷。
有时候可能会发现一个监控属性既在主机模板中设置了,也在主机定义中设置了,此时就有一个优先级的问题,在这种情况下,监控属性的生效值以主机中的设置为准。
点击下图中的“Notification”标签,用来设置告警通知属性模板,如下图所示:
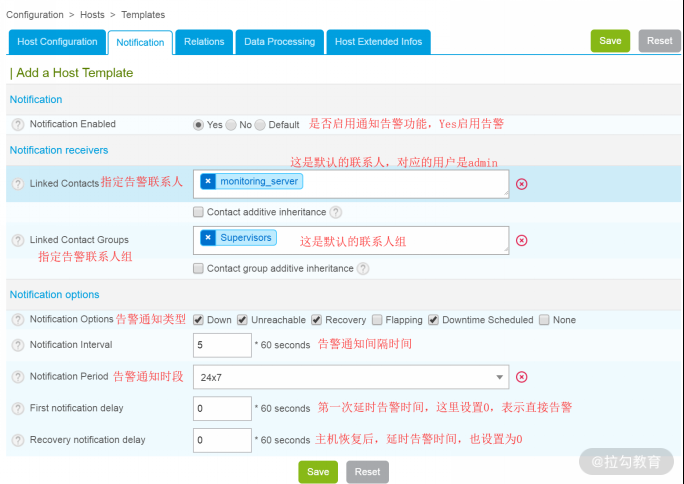
告警通知属性主要对是否启用告警、告警联系人、告警周期、告警类型等进行设置,上图已经很清楚地描述了每个选项的含义,这里不再多说。
2. 添加主机监控
选择 Configuration → Hosts → Hosts,点击 Add 按钮添加一个主机,如下图所示:
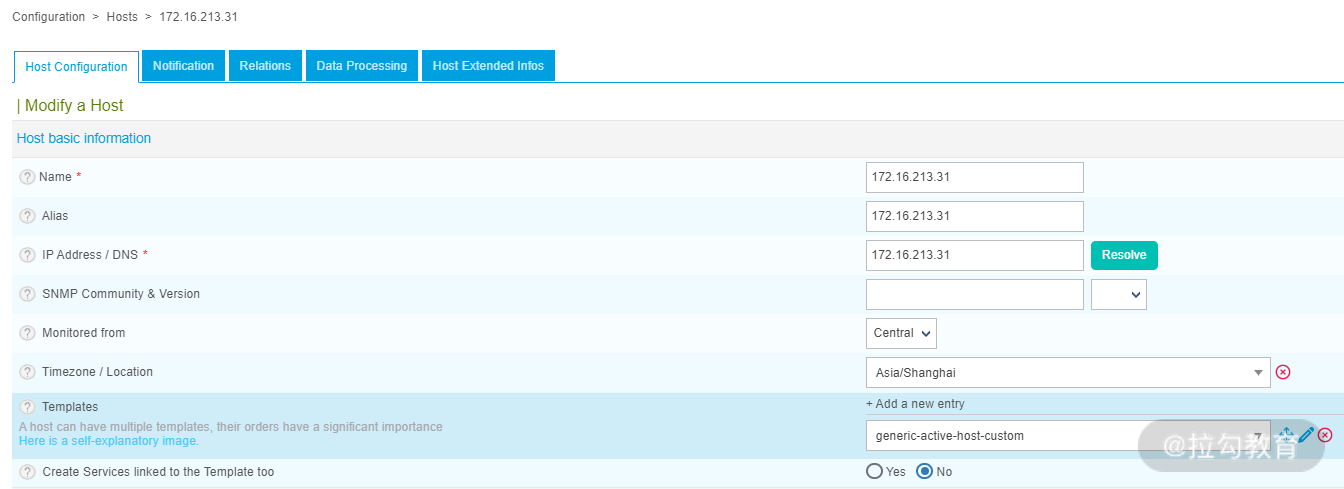
首先添加一个 172.16.213.31 主机,此主机无须设置更多的属性,只需要引用模板即可,模板就选择之前我们创建的“generic-active-host-custom”。这样,此主机的所有属性就配置完成了,因为更多的主机属性都通过指定的主机模板继承进去了。
要添加更多的主机,方法与上面完全相同。下面依次添加多台主机,如下图所示:
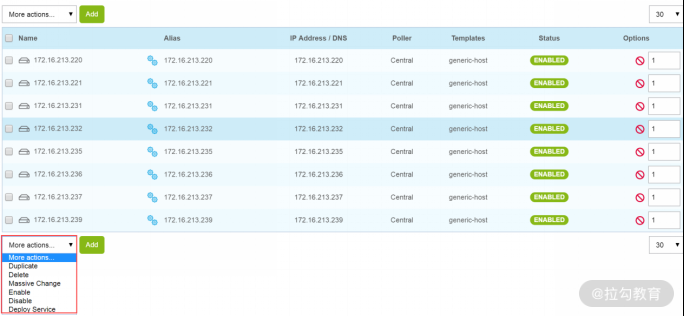
在这个界面上,有很多操作属性,可以用于对主机进行复制、删除、修改、启用和禁用等,由此可见,通过 Centreon 管理主机非常方便、简单。
3. 监控引擎管理
在完成主机和主机组添加后,这些主机信息并不会马上生效,还需要将这些信息生成 Centreon 配置文件进行保存,然后重新启动监控引擎,这就是 Centreon 的监控引擎管理功能。在任何配置添加或修改完成后,都需要重启监控引擎才能使这些配置生效。
选择 Configuration → Pollers → Pollers,如下图所示:

在此图中选择“Export configuration”,如下图所示:
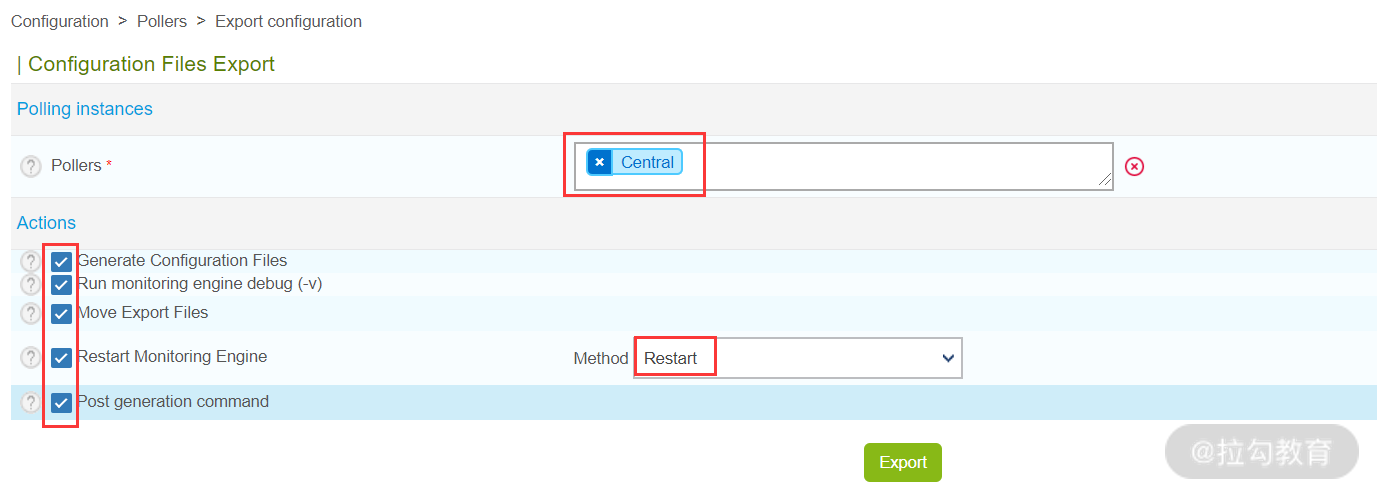
上图主要用于将创建好的配置导出,首先选择 pollers 为 central,然后勾选左边所有动作,最后选择执行方式,可选的有两个,即 Restart 和 Reload。
-
Restart 用于重新启动监控引擎服务,比如新增加了一台主机,就可以使用 Restart 这个动作。
-
Reload 是重新加载配置,比如修改了某个主机的配置参数,使用 Reload 重新加载即可。
4. 添加服务
在完成主机添加后,下面开始添加需要监控的服务。
(1)修改服务模板
这里的服务模板与之前介绍的主机模板类似,它们具有相同的作用,选择 Configuration→Services→Templates,找到“generic-active-service”这个自带的模板,如下图所示:
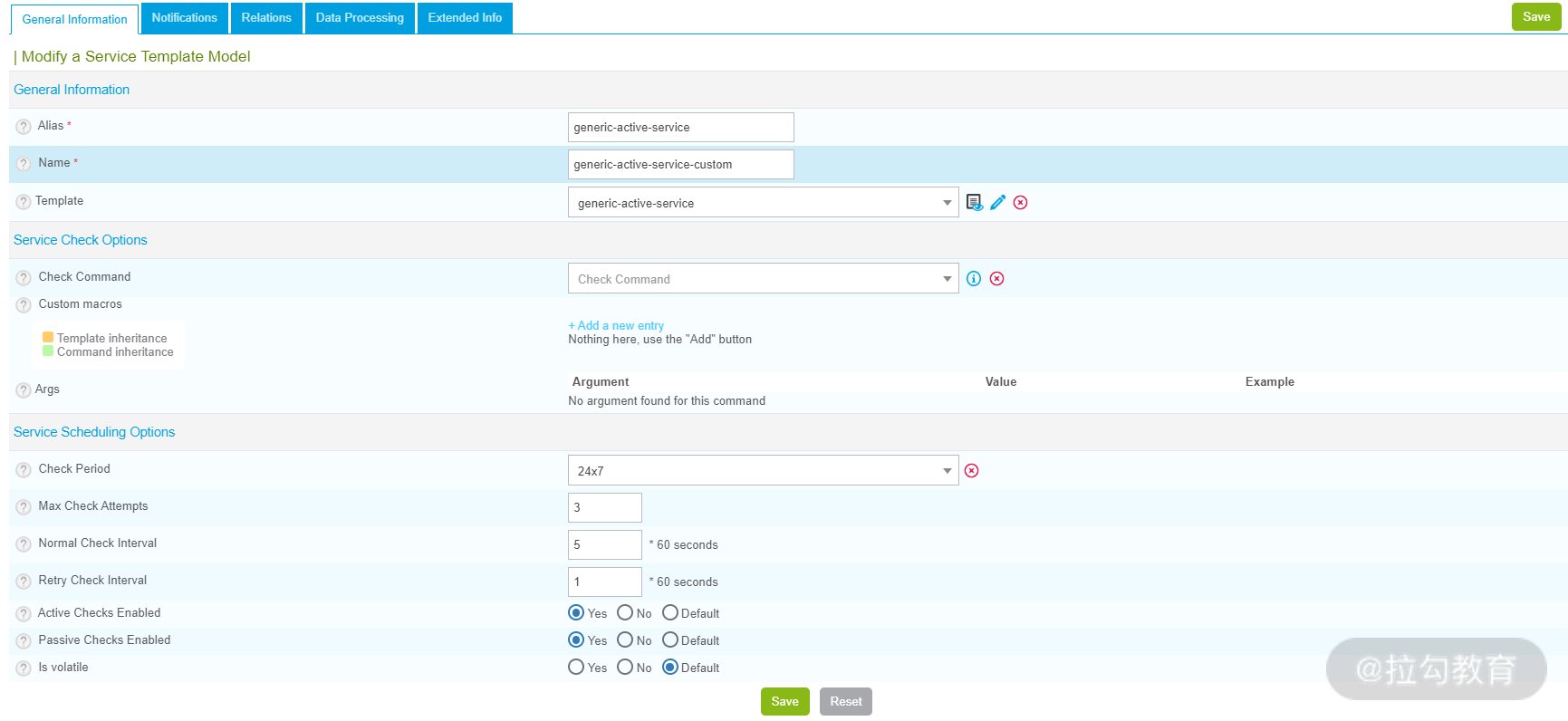
此界面中主要用来设置服务模板的一些属性值,点击上图中的“Notification”选项,可以用来设置通知属性,如下图所示:
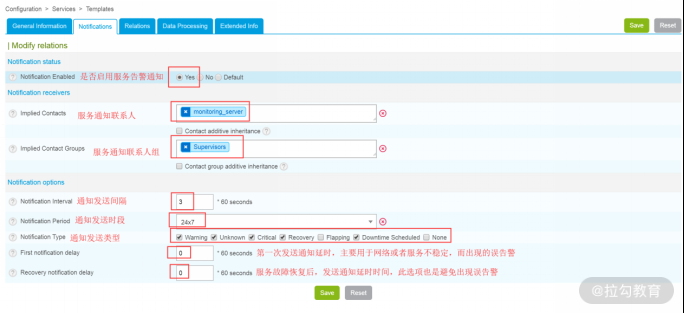
在此界面中,对每个选项的含义都做了详细的描述,这里不再多说。generic-active-service 服务模板中设置的属性值都是通用的或公用的,主要用于在创建服务的时候进行引用。
(2)创建监控命令
选择 Configuration→Commands→Checks,点击 add 创建一个命令,如下图所示:
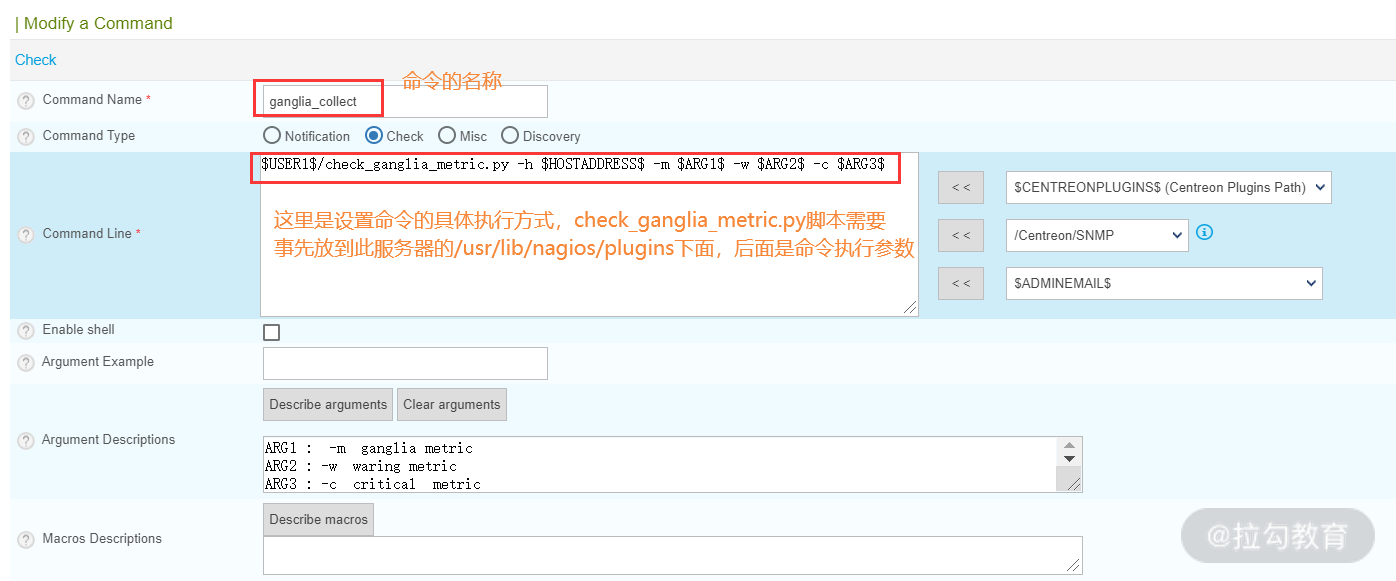
这里创建了一个“ganglia_collect”命令,此命令用来收集 Ganglia 上面的监控指标,可以看到,此命令最终应用的监控命令是 check_ganglia_metric.py,这个脚本我们在上个课时中介绍过。
(3)添加监控服务
添加监控服务的方法与添加主机基本一样,选择 Configuration→Services→Services by host,点击 Add 按钮添加一个服务。这里添加了一个“check_hadoop_block”的服务,在“Service Template”中引用了服务模板 generic-active-service,如下图所示:
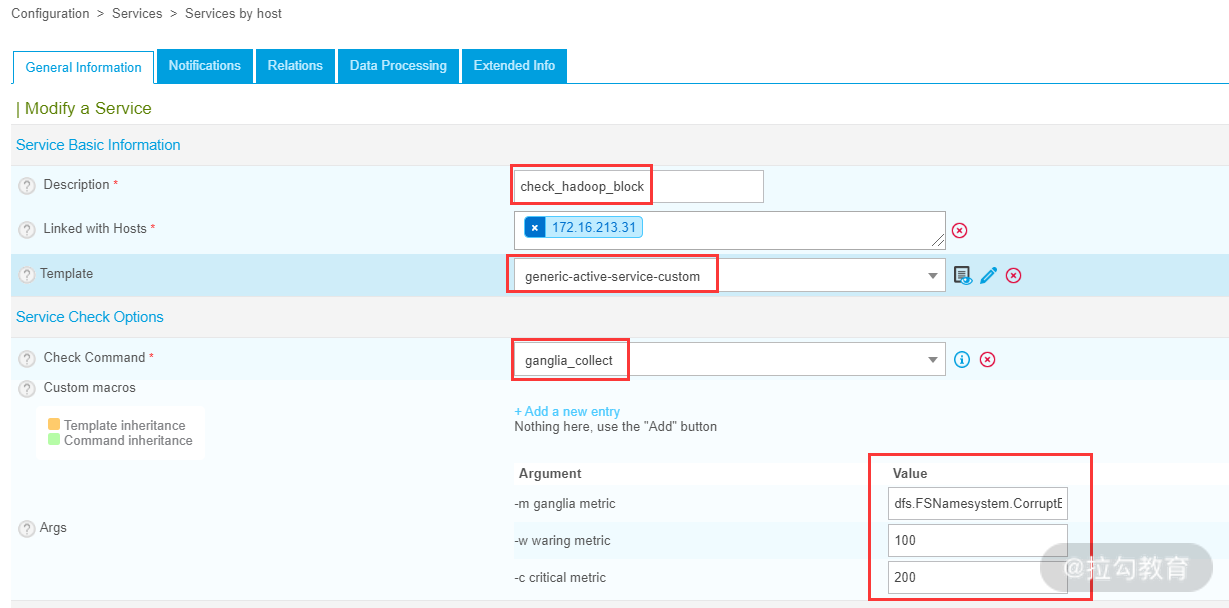
在添加监控服务过程中,只要引用了之前创建好的基础服务模板,那么大部分的属性基本都不用配置了,因为已经在服务模板配置过了。
这里重点关注“check_hadoop_block”服务中引用的命令 ganglia_collect 中三个参数的配置,分别是监控指标、警告阈值和故障阈值。其中,监控项 dfs.FSNamesystem.CorruptBlocks 表示已损坏的 block 数量。这样一个监控服务就添加完成了,如下图所示:

在上图的服务监控列表中,可以对每个服务进行复制、删除、启用、禁用等操作,这些功能对以后的监控系统运维是非常重要的。
5. 监控报警配置
监控报警配置是 Centreon 中一个非常重要的组成部分,在前面介绍了主机和服务的添加,并且在主机和服务中都引用了各自的模板。而我们在模板中已经开启了报警通知功能,下面就重点讲下主机和服务的报警通知功能。
(1)开启主机报警通知
开启主机报警通知功能有两种方法。
第一种方法是在定义主机时进行开启,选择 Configuration→Hosts→Hosts,编辑已经创建好的主机 172.16.213.31,这里重点看通知(Notification)选项,如下图所示:
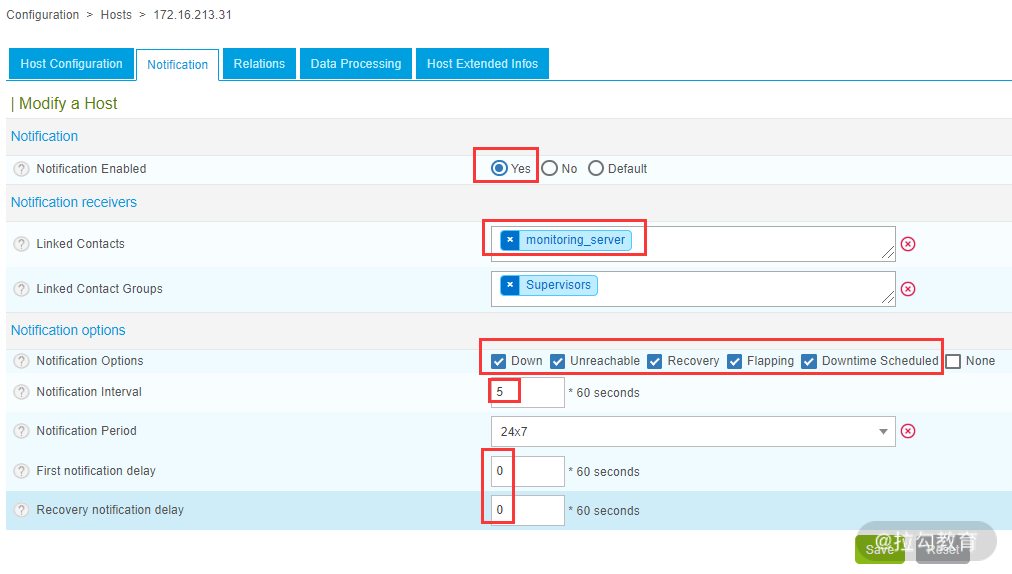
在默认情况下,通知选项处于“Default”状态,该状态表示一个继承关系,这里选择“monitoring_server”作为通知联系人,monitoring_server 就是 admin 用户的全名,“选择Supervisor”作为联系人组。这里可以根据监控需要任意添加。
接着还可以选择通知间隔、通知周期、通知类型、是否延时发送通知等选项。对于比较重要的主机可以选择短一点的通知时间间隔,可以选择通知周期为 7×24,另外还可以选择工作日(Workhours)、非工作日(Nonworkhours)两个选项,可以选择通知类型为宕机(Down)、不可到达(Unreachable)、恢复(Recovery)等。最后一个选项是设定第一次发送通知的延时时间,如果设置为 0,则表示主机故障后立刻发送通知。
第二种方法是配置主机模板中的设置。在前面介绍的主机添加过程中,都引用了主机模板,而在主机模板配置中也可以开启报警通知功能,开启方法很简单。
那就是编辑主机模板,找到通知选项,设置方法与上图完全一样,当开启了通知功能后,对应的这个主机就继承了模板的设置,自动开启了主机通知功能。
(2)报警方式和联系人配置
在开启了主机和服务的报警通知功能后,还需要设置报警方式和报警联系人。Centreon 支持多种报警方式,可以选择邮件报警、短信报警、微信报警、钉钉报警等方式,而邮件报警是默认方式,可以无须添加插件直接使用。
选择 Configuration→Users→Contacts/Users,然后编辑 admin 用户,如下图所示:
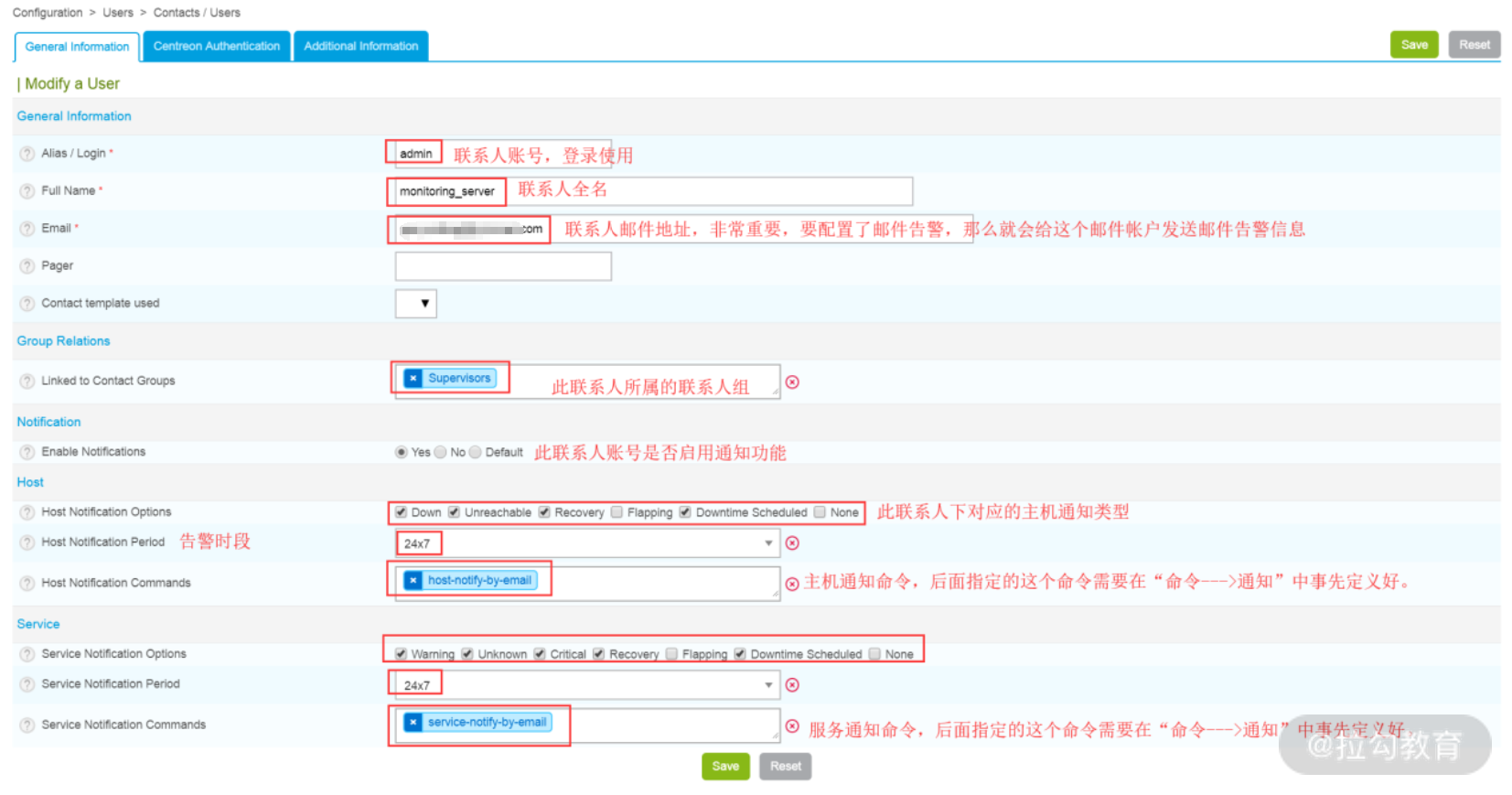
上图总共分成了两个部分,第一部分是用户设置,每个选项的含义在图中都进行了标注;第二部分是通知告警,主要是配置报警通知命令,这里重点关注一下主机通知和服务通知命令。如果是邮件报警,在主机通知命令中,可以选择 host—notify—by—email,而在服务通知命令中可以选择 service—notify—by—email。关于这两个命令,要根据实际情况进行修改,修改方法很简单:选择 Configuration→Commands→Notifications 选项,编辑对应的命令即可。
这里推荐一个利用命令行发邮件的工具“sendEmail”,这个命令行发邮件的工具功能非常强大,使用也非常简单,强烈推荐。
点击这里下载 sendEmail,解压即可使用。可以将解压出来的 sendEmail 可执行文件复制到 /usr/local/bin 下,直接运行 sendEmail 就会显示详细的用法,这里介绍几个重要的使用参数。
-
-f,表示发送者的邮箱。
-
-t,表示接收者的邮箱。
-
-s,表示 SMTP 服务器的域名或者 IP 地址。
-
-u,表示邮件的主题。
-
-xu,表示 SMTP 验证的用户名。
-
-xp,表示 SMTP 验证的密码。
-
-m,表示邮件的内容。
下面是一个定义好的 host - notify - by-email 命令的内容:
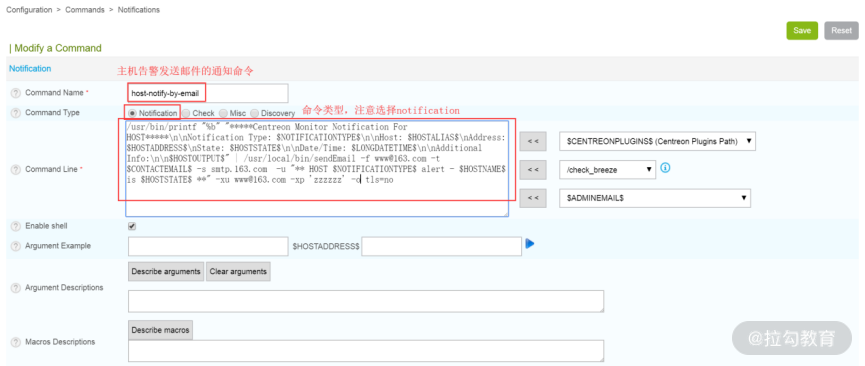
/usr/bin/printf "%b" "*Centreon Monitor Notification For HOST*\n\nNotification Type: $NOTIFICATIONTYPE$\n\nHost: $HOSTALIAS$\nAddress: $HOSTADDRESS$\nState: $HOSTSTATE$\n\nDate/Time: $LONGDATETIME$\n\nAdditional Info:\n\n$HOSTOUTPUT$" | /usr/local/bin/sendEmail -f www@163.com -t $CONTACTEMAIL$ -s smtp.163.com -u "** HOST $NOTIFICATIONTYPE$ alert - $HOSTNAME$ is $HOSTSTATE$ **" -xu www@163.com -xp 'zzzzzz' -o tls=no
在 Configuration→Commands→Notifications 中,编辑“host-notify-by-email”内容如下图所示:
下面是一个定义好的 service-notify-by-email 命令的内容:
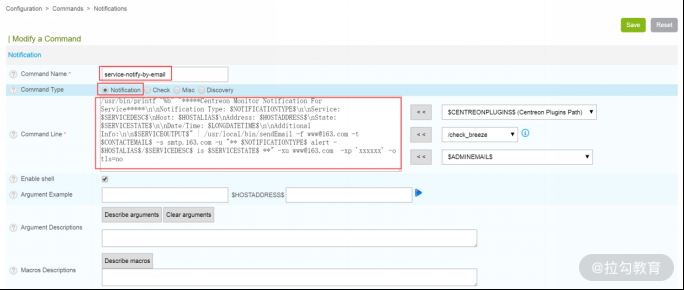
/usr/bin/printf "%b" "*Centreon Monitor Notification For Service*\n\nNotification Type: $NOTIFICATIONTYPE$\n\nService: $SERVICEDESC$\nHost: $HOSTALIAS$\nAddress: $HOSTADDRESS$\nState: $SERVICESTATE$\n\nDate/Time: $LONGDATETIME$\n\nAdditional Info:\n\n$SERVICEOUTPUT$" | /usr/local/bin/sendEmail -f www@163.com -t $CONTACTEMAIL$ -s smtp.163.com -u "** $NOTIFICATIONTYPE$ alert - $HOSTALIAS$/$SERVICEDESC$ is $SERVICESTATE$ **" -xu www@163.com -xp 'xxxxxx' -o tls=no
在 Configuration→Commands→Notifications 中,编辑“service-notify-by-email”内容如下图所示:
告警通知配置完毕后,重启 Centreon 监控引擎,以使告警配置生效,到这里为止,关于 Centreon 邮件报警方式的配置已介绍完毕。
通过 Centreon 实现对 Hadoop 的监控
上个课时我介绍了 Ganglia 的使用,以及如何从 Ganglia 监控指标中获取监控数据。下面我将介绍通过监控系统来实现对 Ganglia 监控数据的告警配置。
Centreon 对 Hadoop 的监控,主要是通过编写脚本的形式去访问 HDFS 的 50070 端口,以及 yarn 的 8080 端口,来实现对 NameNode、Datanode 以及 Resourcemanager 和 Nodemanager 的监控。
这里假定 Hadoop 集群中主 Namenode 的 IP 为 172.16.213.31,备 Namenode 的 IP 为172.16.213.41,Resourcemanager 节点的 IP 为 172.16.213.41,这些 IP 会在下面的配置中用到。
下面我会分享几个监控 Hadoop 的脚本,以及如何将脚本集成到 Centreon 中进行故障告警和通知。
1. 监控 Namenode 运行状态
首先,在监控服务器的 Centreon Web 界面选择 Configuration→Commands→Checks,然后点击 Add 按钮新建一个 Command,如下图所示。
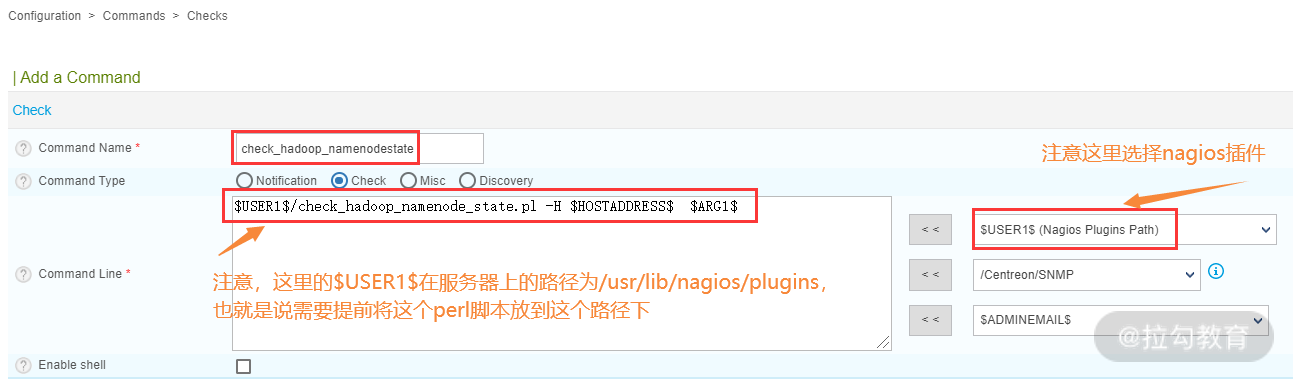
在创建 check_hadoop_namenodestate 命令过程中,需要使用一个 perl 脚本 check_hadoop_namenode_state.pl(本课时所有脚本都可点击这里下载,将下载下来的文件和目录都放到 Centreon 服务器的 /usr/lib/nagios/plugins 目录下),此脚本其中的“-H”表示主机地址,后面的参数 $ARG1$ 表示 namenode 的状态,有两种状态,即 active 和 standby。此脚本用来检测高可用 Namenode 的主、备是否发生切换,如果主、备发生切换,则意味着 Namenode 可能出现问题,所以要做好主备的状态监控。
接着,开始添加 check_hanamenode_active 服务,如下图所示:
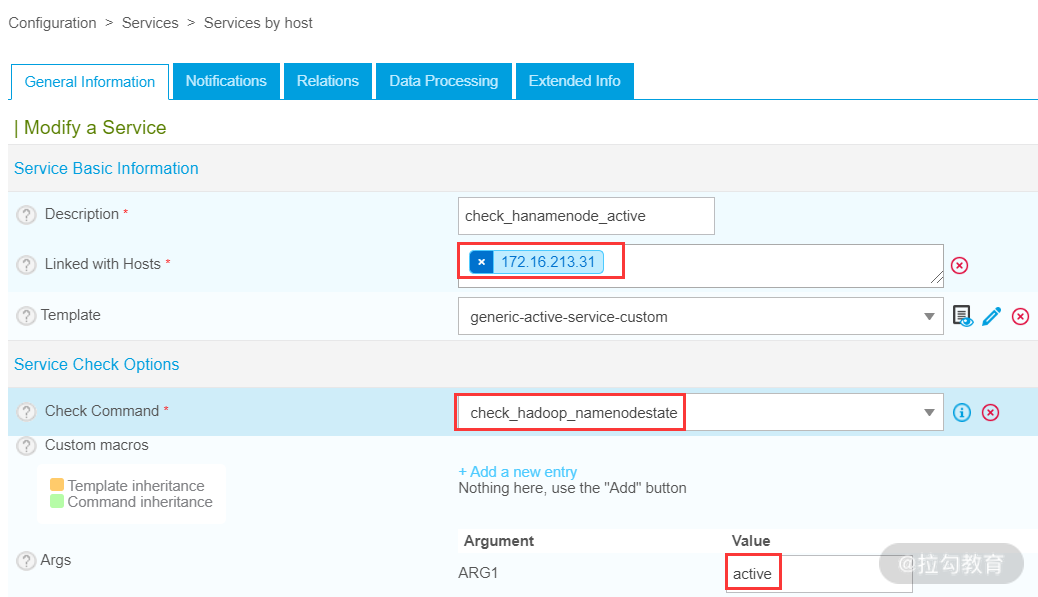
注意,这里添加的服务对应的主机是 172.16.213.31,此主机是 Namenode 的主节点,因此它的状态应该是 active,注意此服务在检查命令配置项中,添加刚刚配置好的那个命令即可。
然后,继续添加第二个服务 check_hanamenode_standby,此服务用来检查 Namenode 备机运行状态,如下图所示:
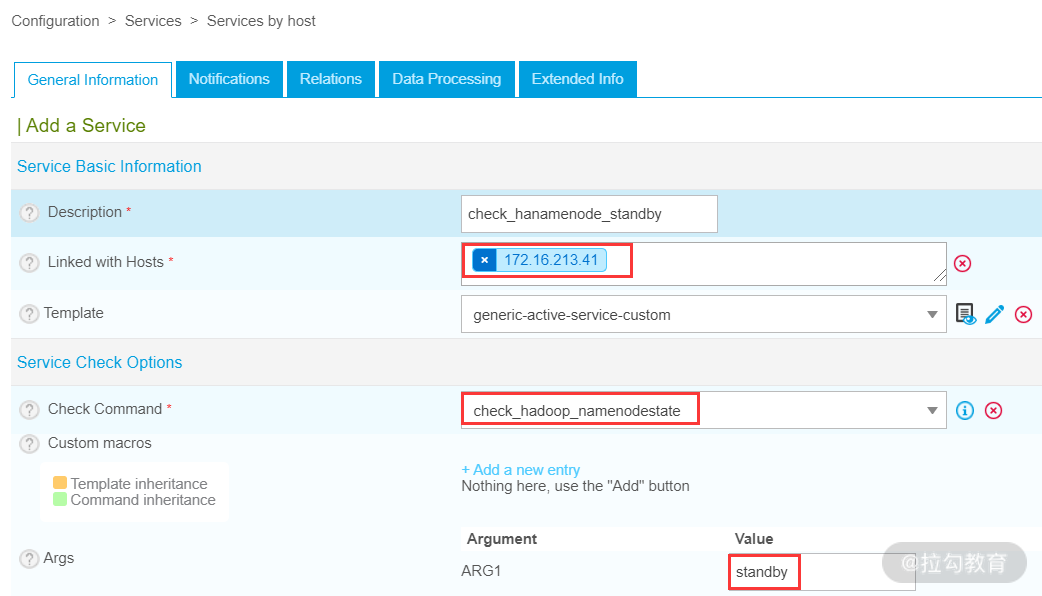
配置完毕后,对 Namenode 主、备运行状态已经配置完成。对 Namenode 监控,还需要及时了解 HDFS 数据块状态(是否丢失块、出现坏块、未复制的块等),这个功能需要通过另一个脚本实现,该脚本为 check_hadoop_replication.pl。
要使用这个脚本,仍然是先创建一个监控命令,在 Centreon Web 界面选择 Configuration→Commands→Checks,然后点击 Add 按钮新建一个 Command,如下图所示。
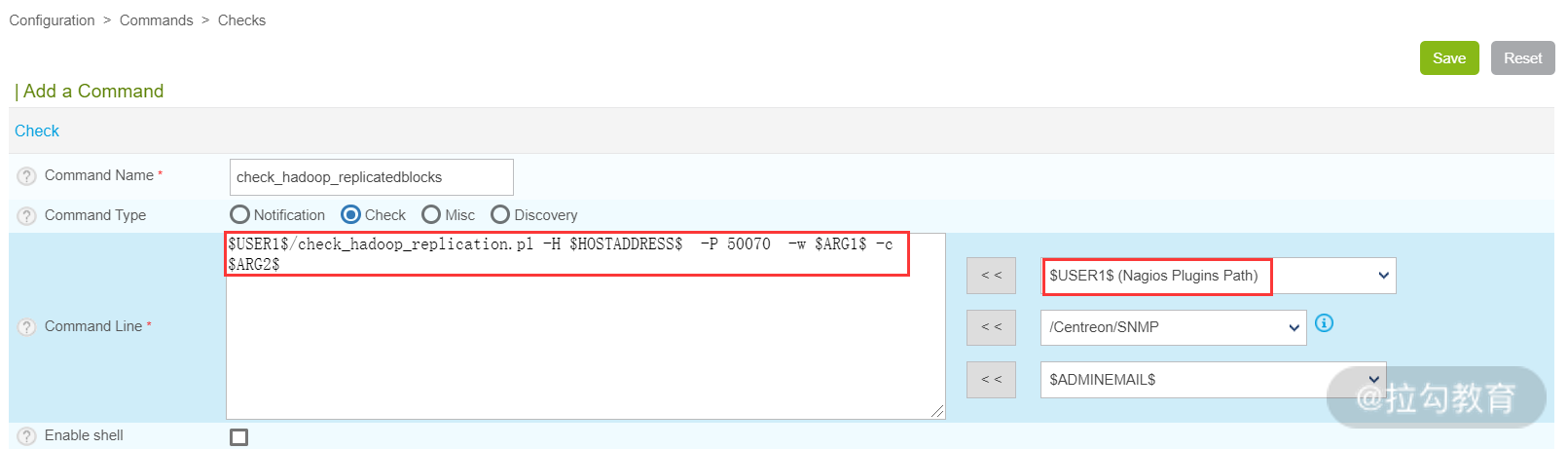
在这个界面,我们调用了刚上传到服务器上的那个脚本,此脚本中 -H 是指定 Namenode 服务器的 IP,-P 是指定 Namenode 的 Web 端口,默认是 50070,-w 是 HDFS 数据块故障状态的警告值,-c 是 HDFS 数据块故障状态的故障值。
接着,开始创建服务,这里创建了一个 check_hadoop_namenode_replicatedblocks 服务,如下图所示:
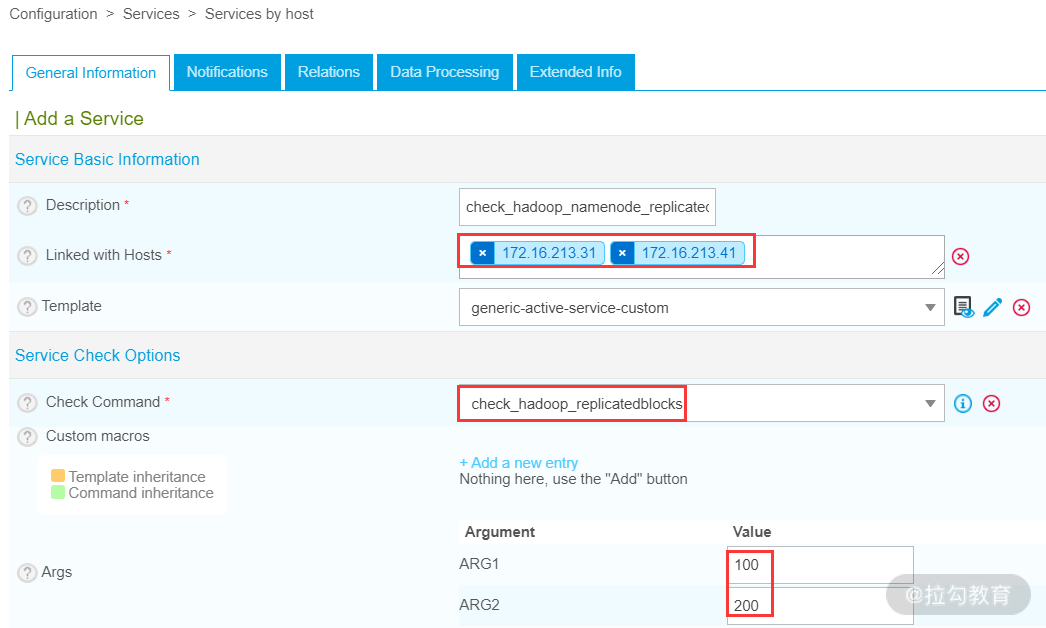
此服务中,连接了两个主机,也就是对这两个主机的 HDFS 数据块状态进行定期监控和检查。
2. 监控 Datanode 运行状态
对 Datanode 的监控主要监控节点服务是否宕机,如果发现 Datanode 服务宕机,那么需要马上处理,所以对 Datanode 的监控至关重要。要监控 Datanode,需借助一个脚本 check_hadoop_datanodes.pl,此脚本已包含在上面那个下载地址中。
接着,在 Centreon Web 界面选择 Configuration→Commands→Checks,然后点击 Add 按钮新建一个 Command,如下图所示。
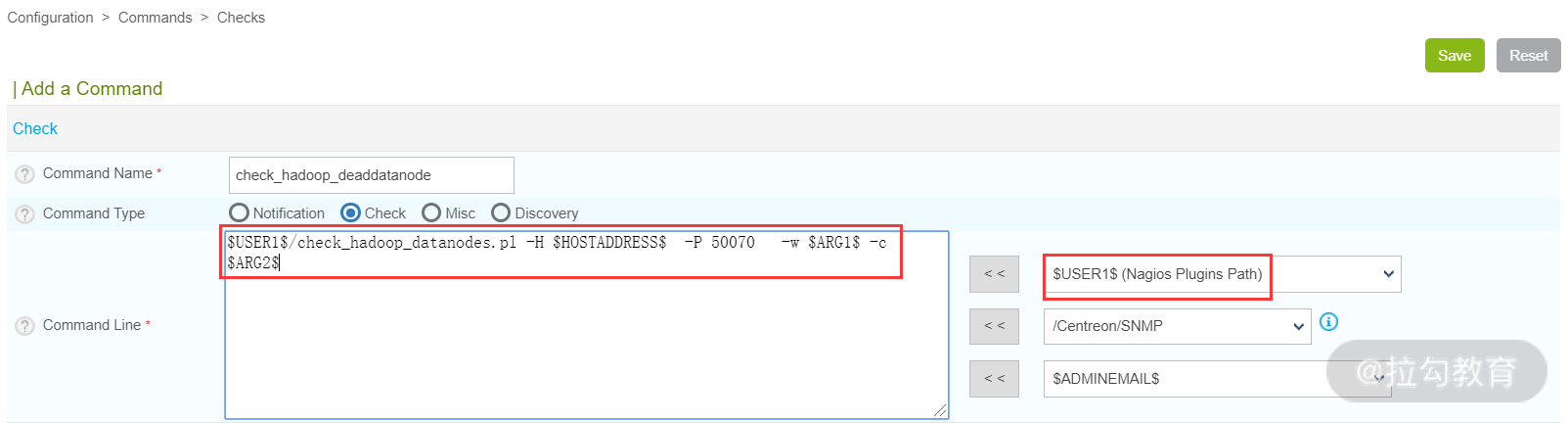
这里创建了一个命令 check_hadoop_deaddatanode,然后将上面脚本引用进来即可,参数含义不再介绍。
命令创建完成,接着,开始创建监控服务,这里我创建的服务名称是 check_hadoop_datanode_dead,将此服务连接到 172.16.213.31 主机上,如下图所示:
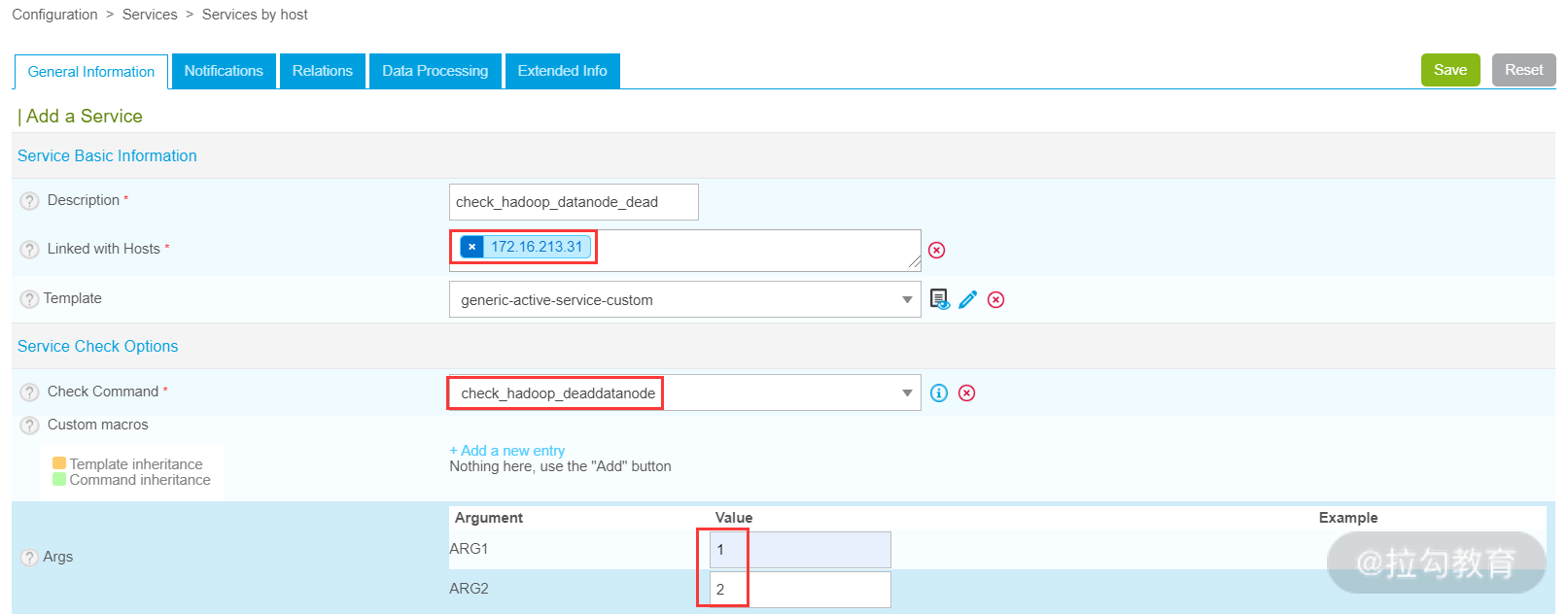
注意,在上图中,ARG1 代表警告阈值,ARG2 代表故障阈值,这个可根据实际情况进行修改。配置完毕后,对 Datanode 的监控就添加完成了。
3. 监控 resourcemanager、nodemanager 状态
对于 Hadoop 的分布式计算,必须监控的服务有两个,即 resourcemanager 和 nodemanager。这里首先介绍如何监控 resourcemanager 服务,对该服务的监控,主要是监控 resourcemanager 对 JVM 内存资源的使用状态,当 JVM 使用资源过大时,需要考虑计算资源是否充足,是否存在异常任务等。
因此这里我主要监控 resourcemanager 的 JVM 使用状态,要监控 resourcemanager 的 JVM 内存资源状态,需借助一个脚本 check_hadoop_yarn_resource_manager_heap.pl,此脚本已包含在上面那个下载地址中。
接着,在 Centreon Web 界面选择 Configuration→Commands→Checks,然后点击 Add 按钮新建一个 Command,如下图所示:
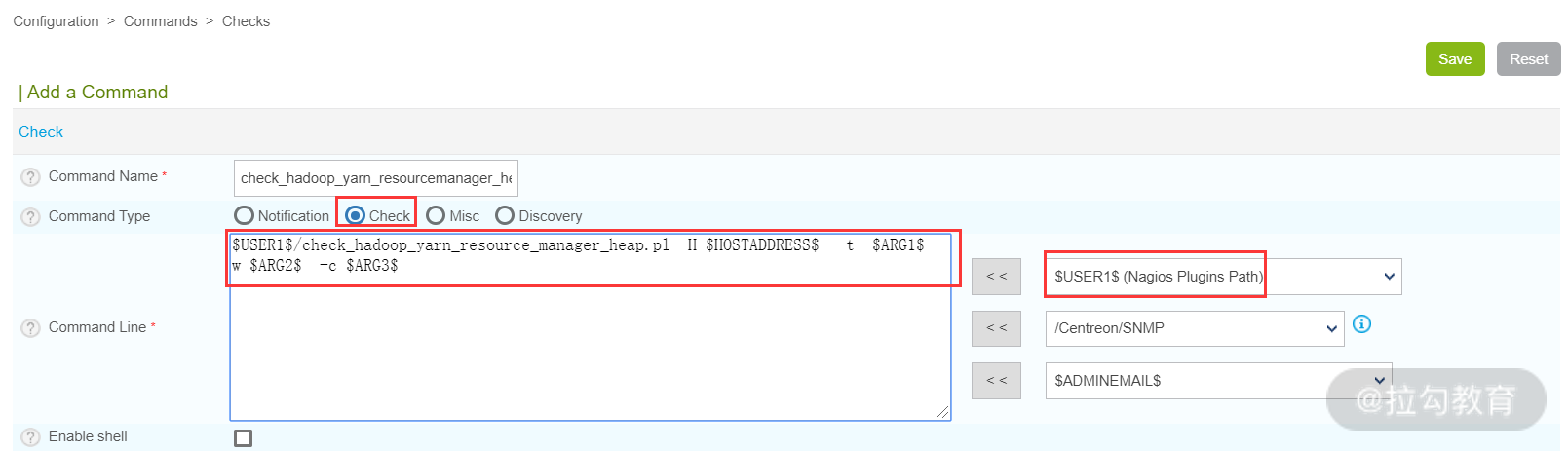
在上图中,通过创建一个命令将 check_hadoop_yarn_resource_manager_heap.pl 脚本引用进来了,其中 -t 参数表示超时时间。
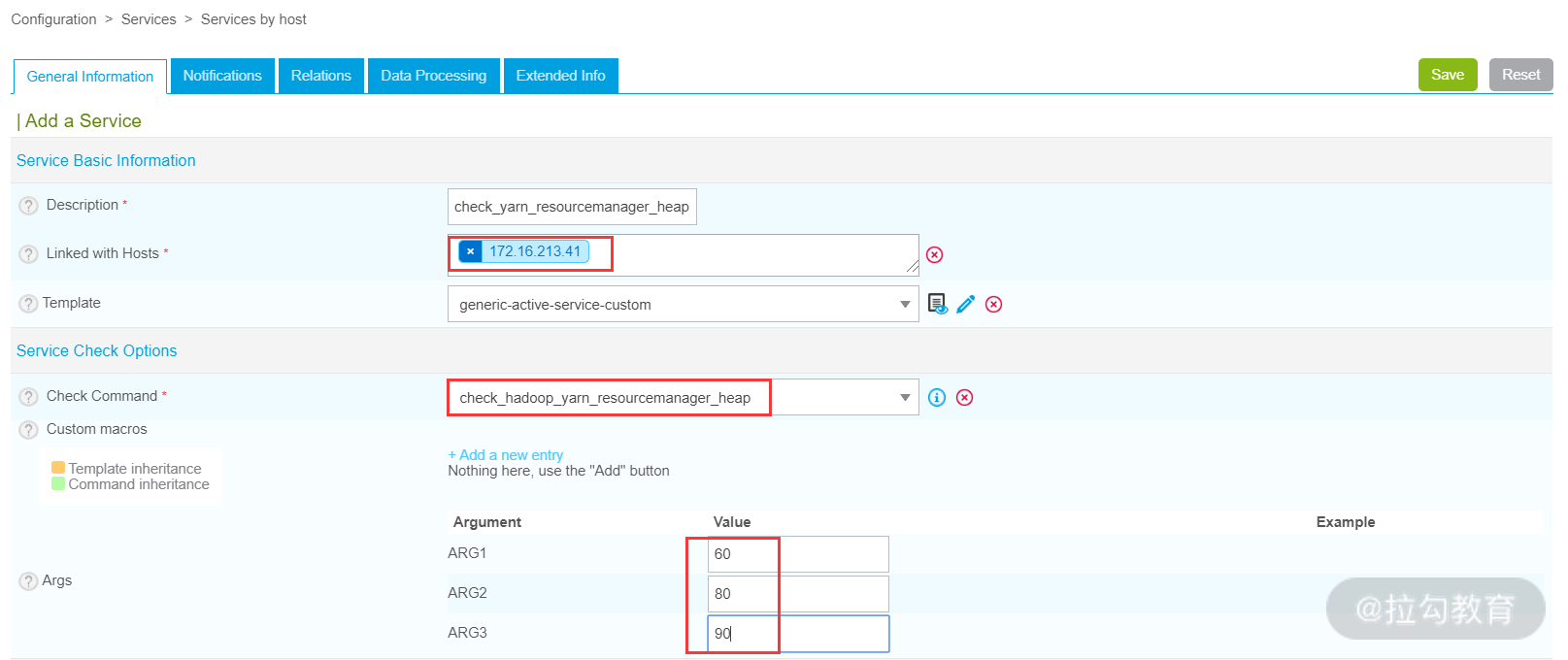
然后,开始创建监控 resourcemanager 的 JVM 内存状态的服务,这里我创建的服务名称是 check_yarn_resourcemanager_heap,将此服务连接到 172.16.213.41 主机上,如下图所示:
-
ARG1 参数代表的含义是超时时间,单位是秒;
-
ARG2 参数代表的含义是警告阈值,这个值是百分比;
-
ARG3 参数代表的含义是故障阈值,对应的值也是百分比。
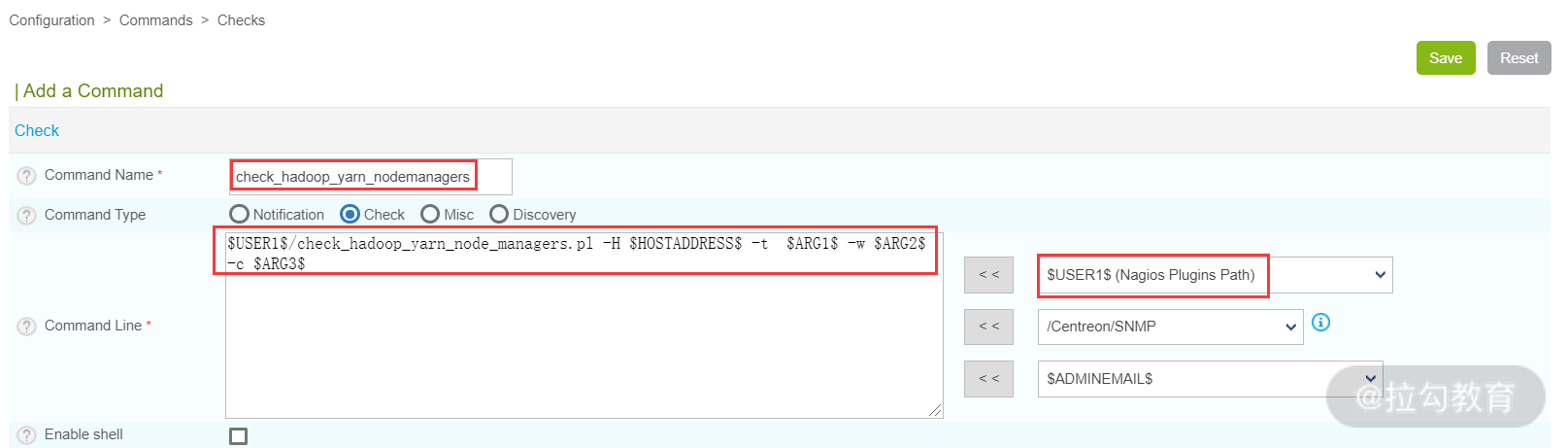
最后,再来看看如何监控 Nodemanager,在实际运行中,也会出现各种问题,比如 Nodemanager 所在的节点可能出现磁盘只读,此时该节点就会自动进入黑名单,或者出现内存溢出,Nodemanager 服务就会自动退出。针对这些情况,运维需要及时发现、及时处理,所以对 Nodemanager 的监控至关重要,同样,需要借助一个脚本 check_hadoop_yarn_node_managers.pl,此脚本已包含在上面那个下载地址中。
然后,在 Centreon Web 界面选择 Configuration→Commands→Checks,点击 Add 新建一个 Command,如下图所示。
命令创建完毕后,接下来开始创建服务,引入此命令,这里创建一个 check_yarn_lostnodemanager 服务,如下图所示:
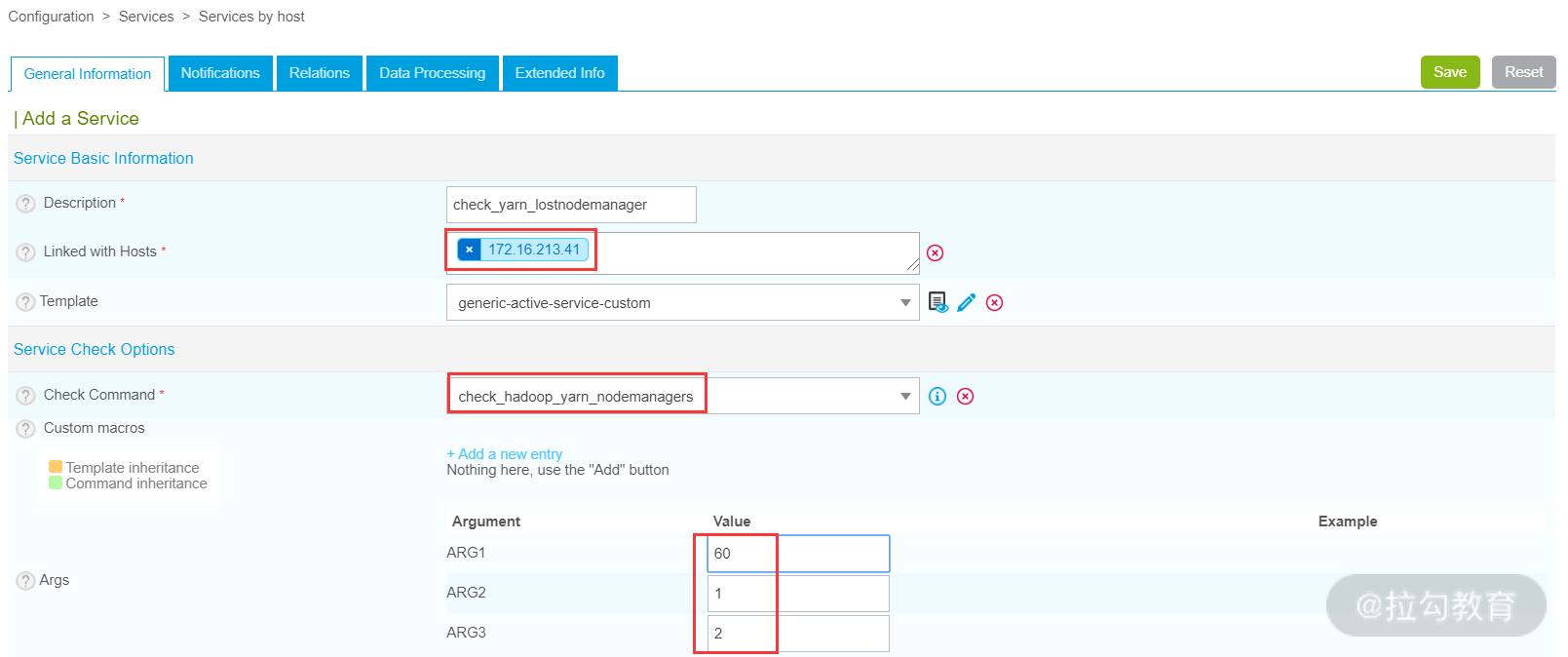
注意,check_hadoop_yarn_node_managers.pl 脚本的实现是对 Nodemanager 的监控,借助了 Yarn 的 8080 端口,因此,这里监控连接主机是 172.16.213.41,而 ARG1、ARG2 和 ARG3 的含义依次是超时时间、警告阈值和故障阈值。
总结
本课时主要讲解了监控系统 Centreon 的使用,以及如何在 Centreon 上监控 Hadoop 的 NameNode、Datanode、resourcemanager 及 nodemanager 服务,通过 Ganglia 获取 Hadoop 集群数据,然后结合 Centreon,就可以实现将监控指标进行实时告警,Ganglia+Centreon 的组合是大数据运维监控环境下最常用的开源监控方案。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号