[大数据运维]第22讲:通过 Ganglia 实现对 HDFS、Yarn、Spark 运行状态监控
第22讲:通过 Ganglia 实现对 HDFS、Yarn、Spark 运行状态监控
高俊峰(南非蚂蚁)
Ganglia 概念与架构
1. Ganglia 介绍
说起 Ganglia,可能大家有些陌生,但是如果提起大数据平台监控工具,那么第一个想到的就是 Ganglia。因为 Ganglia 和 Hadoop 属于原生无缝整合,用 Ganglia 来监控 Hadoop 是最简单的大数据监控方案。
Ganglia 可以监控集群中每个节点的状态信息,它由运行在各个节点上的 Gmond 守护进程来采集 CPU、内存、硬盘利用率、I/O 负载、网络流量等方面的数据,然后汇总到 Gmetad 守护进程下,使用 RRDtool(RRD)存储数据,最后将历史数据以曲线方式通过 PHP 页面呈现。
Ganglia 监控系统由三部分组成,分别是 Gmond、Gmetad、Webfrontend,其中:
-
Gmond 是一个客户端守护进程,运行在每一个需要监测的节点上,用于收集本节点的信息并发送到其他节点,同时也接收其他节点发过了的数据,默认的监听端口为 8649;
-
Gmetad 是一个服务端守护进程,运行在一个数据汇聚节点上,定期检查每个监测节点的 gmond 进程并从那里获取数据,然后将数据指标存储在本地 RRD 存储引擎中;
-
Webfrontend 是一个基于 Web 的图形化监控界面,需要和 Gmetad 安装在同一个节点上,它从 Gmetad 中取数据,并且读取 RRD 数据库,通过 RRDtool 生成图表,用于前台展示,界面美观、丰富且功能强大。
2. Ganglia 运行架构
一个简单的 Ganglia 监控系统结构图如下图所示:
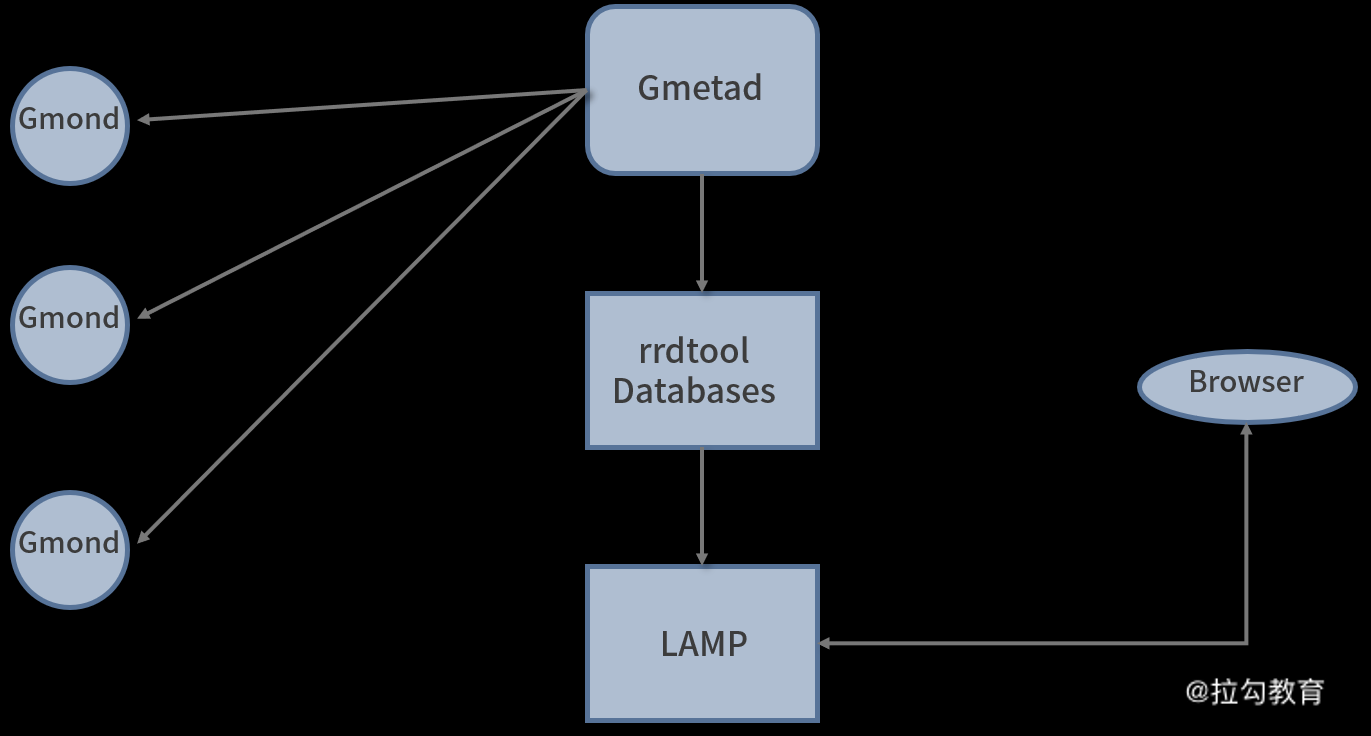
Ganglia 监控系统图
从图中可以看出,一个 Ganglia 监控系统由多个 Gmond 进程和一个主 Gmetad 进程组成,所有 Gmond 进程将收集到的监控数据汇总到 Gmetad 管理端,而 Gmetad 将数据存储到 RRD 数据库中,最后通过 PHP 程序在 Web 界面进行展示。
这是最简单的 Ganglia 运行结构图,在复杂的网络环境下,还有更复杂的 Ganglia 监控架构。下图是 Ganglia 的另一种分布式监控架构图。
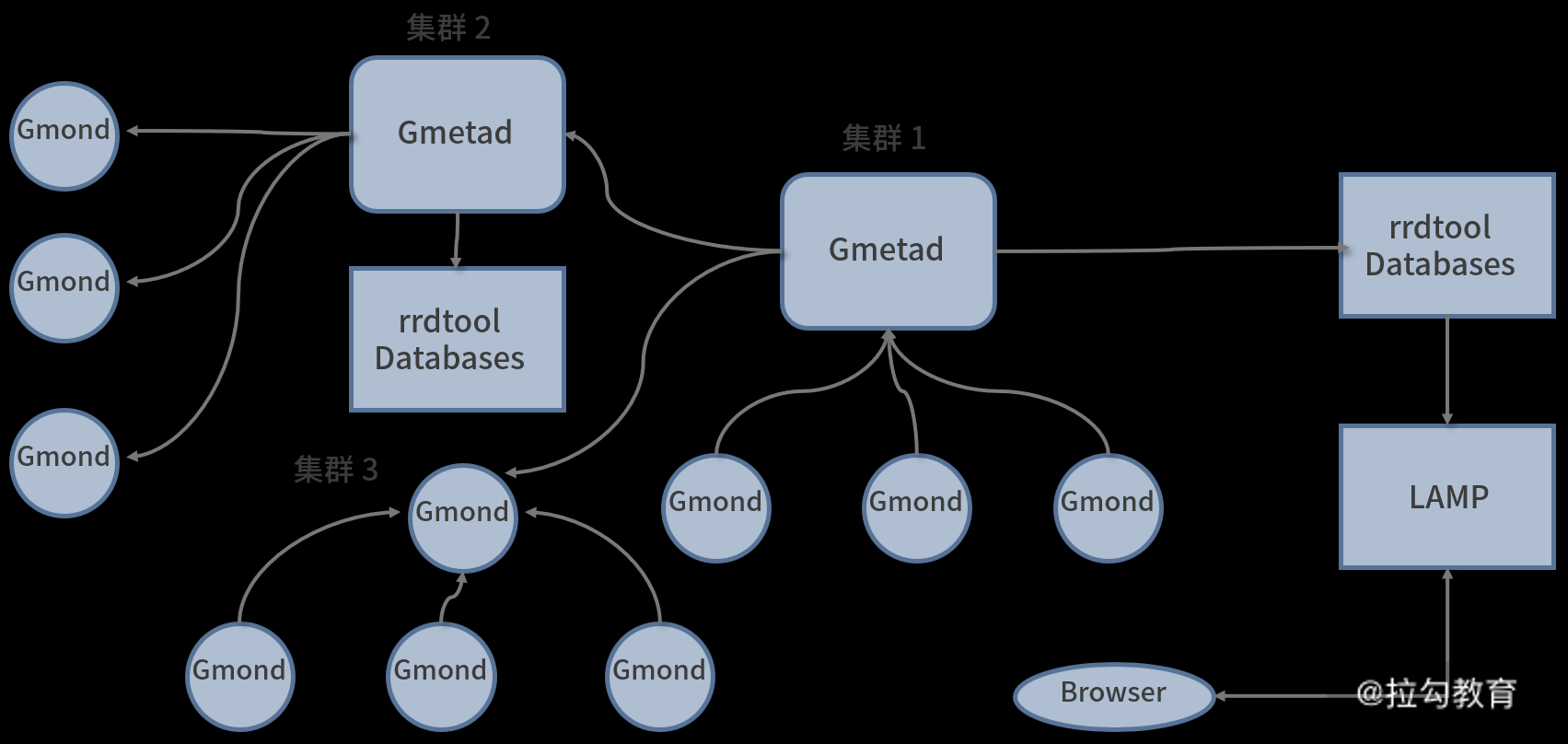
Ganglia 的另一种分布式监控架构图
从这个图中可以看出,Gmond 和 Gmetad 实现了分级架构,二级 Gmond(即图中指向 Gmetad 和一级 Gmond 的 Gmond)可以等待 Gmetad 将监控数据收集走,也可以将监控数据交给一级 Gmond,进而让一级 Gmond 将数据最终交付给 Gmetad。同时,Gmetad 也可以收集其他 Gmetad 的数据,比如,对于上图中的集群 1 和集群 2,集群 2 是一个二级 Gmetad,它将自身收集到的数据又一次地传输给了集群 1 这个一级 Gmetad;而集群 1 将所有集群的数据进行汇总,然后通过 Web 进行统一展现。
在 Ganglia 分布式结构中,经常提到的几个名词有 Node、Cluster 和 Grid,这三部分构成了 Ganglia 分布式监控系统。其中:
-
Node 是 Ganglia 监控系统中的最小单位,即被监控的单台服务器;
-
Cluster 表示一个服务器集群由多台服务器组成,是具有相同监控属性的一组服务器的集合;
-
Grid 表示一个网格,由多个服务器集群组成,即多个 Cluster 组成一个 Grid。
从上面介绍可以看出这三者之间的关系。首先,一个 Grid 对应一个 Gmetad,在 Gmetad 配置文件中可以指定多个 Cluster,然后一个 Node 对应一个 Gmond,Gmond 负责采集其所在机器的数据,同时它还可以接收来自其他 Gmond 的数据,而 Gmetad 定时到每个 gmond上收集监控数据。
Ganglia 的部署与配置
1.下载与安装 Ganglia
在安装 Ganglia 之前,我们对主机、软件、使用角色规划如下表所示:
|
主机 IP/主机名
|
安装软件
|
主机角色
|
|
172.16.213.157(gangliaserver)
|
ganglia-gmetad、ganglia-web lamp
|
Ganglia 服务端、 Ganglia Web 端 监控展示
|
|
172.16.213.120(gangliagmond)
|
ganglia-gmond
|
数据及汇聚主机
|
安装 Ganglia,只需要两台主机即可,一台安装 Ganglia-gmetad,另一台安装 Ganglia-gmond,主机操作系统采用 CentOS 7.7 版本,Ganglia 版本使用 3.7.2。
CentOS 系统中默认的 yum 源并没有包含 Ganglia,所以我们必须安装扩展的 yum 源。首先需要安装一个 EPEL 源,然后才能安装 Ganglia,操作如下:
[root@gangliaserver ~]# yum install epel-release
Ganglia 的安装分为两个部分,分别是 Gmetad 和 Gmond。Gmetad 安装在监控管理端,Gmond 安装在需要监控的客户端主机,对应的 yum 包名分别为 ganglia-gmetad 和 ganglia-gmond。
下面首先在 gangliaserver 主机上安装 ganglia-gmetad,操作如下:
[root@gangliaserver ~]# yum -y install ganglia-gmetad.x86_64
然后,安装 Gmetad 需要 RRDtool 的支持,而通过 yum 方式,会自动查找 Gmetad 依赖的安装包,自动完成安装,这也是 yum 方式安装的优势。
最后在 gangliagmond 主机上安装 Gmond 服务:
[root@gangliagmond ~]# yum -y install ganglia-gmond.x86_64
这样,Ganglia 监控系统就安装完成了。通过 yum 方式安装的 Ganglia 默认配置文件位于 /etc/ganglia 中。
2. 配置 Ganglia
Ganglia 的配置分为三个部分:Ganglia 监控管理端的配置、客户端配置及 Web 端配置,下面依次介绍。
Ganglia 监控管理端配置
监控管理端的配置文件是 gmetad.conf,虽然该配置文件内容比较多,但是需要修改的配置仅有如下几个:
data_source — "bigdata" — 172.16.213.120:8649
gridname — "Server Monitoring"
xml_port — 8651
interactive_port — 8652
rrd_rootdir — "/var/lib/ganglia/rrds"
下面介绍下这几个参数的含义。
-
data_source 参数定义了集群名字,以及集群中的节点。bigdata 就是这个集群的名称,172.16.213.120 指明了从这个节点收集数据,bigdata 后面指定的节点可以有多个,节点名可以是 IP 地址,也可以是主机名。端口可以添加,若不添加的话,默认是 8649。
-
gridname 参数为定义一个网格名称。一个网格有多个服务器集群组成,每个服务器集群由“data_source”选项来定义。
-
xml_port 参数定义了一个收集数据汇总的交互端口,如果不指定,默认是 8651,可以通过 telnet 这个端口得到监控管理端收集到的客户端的所有数据。
-
interactive_port 参数定义了 Web 端获取数据的端口,这个端口在配置 Ganglia 的 Web 监控界面时需要指定,如果不指定,默认是 8652。
-
rrd_rootdir 参数定义了 RRD 数据库的存放目录,Gmetad 在收集到监控数据后会将其更新到该目录下对应的 RRD 数据库中。Gmetad 需要对此文件夹有写权限,默认 Gmetad 是通过 nobody 用户运行的,因此需要授权此目录的权限为 nobody,即 chown -R nobody:nobody "/var/lib/ganglia/rrds" 。
Ganglia 的客户端配置
Ganglia 监控客户端 Gmond 安装完成后,配置文件位于 /etc/ganglia 目录下,名称为 gmond.conf。这个配置文件稍微复杂,需要配置的内容如下所示:
globals {
daemonize = yes
setuid = yes
user = nobody
debug_level = 0
max_udp_msg_len = 1472
mute = no
deaf = no
allow_extra_data = yes
host_dmax = 0
cleanup_threshold = 300
gexec = no
send_metadata_interval = 60
}
cluster {
name = "bigdata"
owner = "unspecified"
latlong = "unspecified"
url = "unspecified"
}
host {
location = "unspecified"
}
udp_send_channel {
mcast_join = 239.2.11.71
port = 8649
ttl = 1
}
udp_recv_channel {
mcast_join = 239.2.11.71
port = 8649
bind = 239.2.11.71
}
tcp_accept_channel {
port = 8649
}
下面介绍下每个配置项的含义。
-
daemonize = yes:是否后台运行,这里表示以后台的方式运行。
-
setuid = yes:是否设置运行用户,在 Windows 中需要设置为 false。
-
user = nobody:设置运行的用户名称,必须是操作系统已经存在的用户,默认是 nobody。
-
debug_level = 0:调试级别,默认是 0,表示不输出任何日志,数字越大表示输出的日志越多。
-
mute = no:是否发送监控数据到其他节点,设置为 yes 表示本节点将不再广播任何自己收集到的数据到网络上。
-
deaf = no:是否接收其他节点发送过来的监控数据,设置为 yes 表示本节点将不再接收任何其他节点广播的数据包。
-
allow_extra_data = yes :当设置为 no 时,该参数可以有效节省带宽。
-
host_dmax = 0:设置是否删除一个节点,0 代表永远不删除,0 之外的整数代表节点的不响应时间,超过这个时间后,Ganglia 就会刷新集群节点信息进而删除此节点。
-
cleanup_threshold = 300:设置 gmond 清理过期数据的时间。
-
gexec = no:当设置为 true 时,gmond 允许节点执行 gexec job,一般选择关闭。
-
send_metadata_interval = 60:用在单播环境中,如果设置为 0,那么当某个节点的 gmond 重启后,gmond 汇聚节点将不再接收这个节点的数据;如果设置大于 0,可以保证在 gmond 节点关闭或重启后,在设定的时间内,gmond 汇聚节点可以重新接收此节点发送过来的信息,单位秒。
-
name = "bigdata":设置集群的名称,是区分此节点属于某个集群的标志,必须和监控管理端 data_source 中的某一项名称匹配。
-
udp_send_channel:设置 udp 包的发送通道。
-
mcast_join = 239.2.11.71:指定发送的多播地址,其中 239.2.11.71 是一个 D 类地址。如果使用单播模式,则要写 host = host1,在网络环境复杂的情况下,推荐使用单播模式。在单播模式下也可以配置多个 udp_send_channel。
-
port = 8649:设置 udp 监听端口,默认 8649。
-
udp_recv_channel:接收 udp 包配置通道。
-
tcp_accept_channel:Tcp 协议通道,通过设置 Tcp 监听的端口,Gmetad 主机可以通过连接 8649 的 Tcp 端口获得监控数据。
注意,在一个集群内,所有客户端的配置是一样的。在完成一个客户端配置后,将配置文件复制到此集群内的所有客户端主机上即可完成客户端主机的配置。
3. Ganglia 的 Web 端配置
Ganglia 的 Web 监控界面是基于 PHP 的,因此需要安装 LAMP 环境,该环境的安装这里不做介绍,你可以点击这里下载 ganglia-web 的最新版本,然后将 ganglia-web 程序放到 Apche Web 的根目录即可。这里我下载的版本是 ganglia-web-3.7.2。
配置 Ganglia 的 Web 界面比较简单,只需要修改几个 php 文件即可。首先是 conf_default.php,可以将其重命名为 conf.php,也可以保持不变;Ganglia 的 Web 默认先找 conf.php,找不到会继续找 conf_default.php,需要修改的内容如下:
$conf['gweb_confdir'] = "/var/www/html/ganglia";
$conf['gmetad_root'] = "/var/lib/ganglia";
$conf['rrds'] = "${conf['gmetad_root']}/rrds";
$conf['dwoo_compiled_dir'] = "${conf['gweb_confdir']}/dwoo/compiled";
$conf['dwoo_cache_dir'] = "${conf['gweb_confdir']}/dwoo/cache";
$conf['rrdtool'] = "/usr/bin/rrdtool";
$conf['ganglia_ip'] = "127.0.0.1";
$conf['ganglia_port'] = 8652;
其中,/var/www/html/ganglia 是 ganglia-web 的根目录,/var/lib/ganglia 为 ganglia 的 RRD 数据目录,/usr/bin/rrdtool 为 RRDtool 命令的默认路径,127.0.0.1 表示 Gmetad 服务所在服务器的地址,8652 表示 Gmetad 服务器交互模式下对应的数据端口。
这里需要说明的是:需要手动建立 compiled 和 cache 目录,并授予 Linux 下 “777” 的权限。另外,RRD 数据库的存储目录 /var/lib/ganglia 一定要保证 RRDtool 可写,因此需要执行授权命令如下:
chown–R nobody:nobody /var/lib/ganglia
这样 RRDtool 才能正常读取 RRD 数据库,进而将数据通过 Web 界面展示出来。
4. 启动与管理 Ganglia 服务
所有配置完成后,就可以在 gangliagmond 服务器上启动 Gmond 服务了,操作如下:
[root@gangliagmond ~]#systemctl start gmond
然后通过查看系统的 /var/log/messages 日志信息,判断 Gmond 是否启动成功,如果出现问题,需要根据日志的提示进行解决。接下来,就可以启动监控管理节点的 Gmetad 服务了,操作如下:
[root@gangliaserver ~]#systemctl start gmetad
Ganglia 服务启动成功后,还需要启动 Apache 服务,然后访问http://172.16.213.157/ganglia,稍等片刻,就可以在 Web 上查看获取的监控数据了,如下图所示:
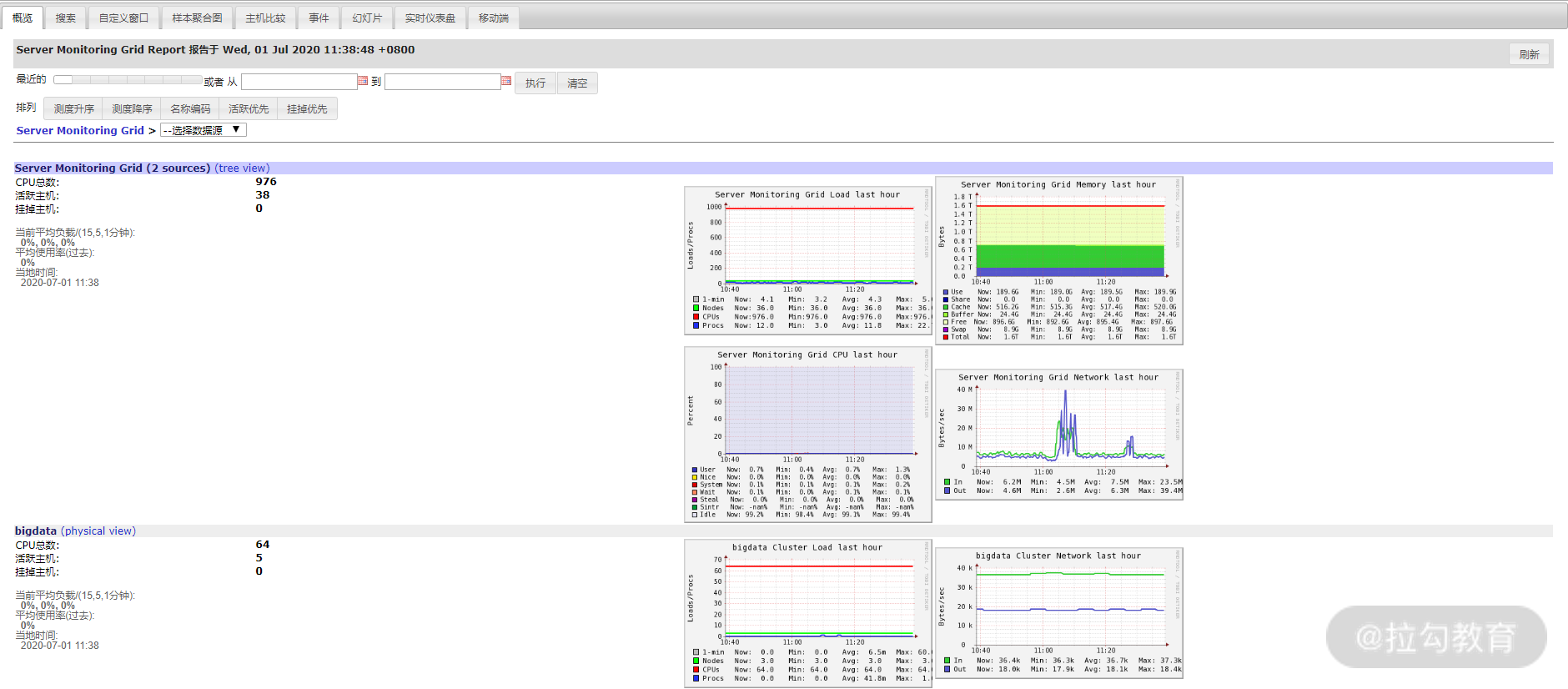
Web 上获取的监控数据图
从这里可以看到,集群 bigdata 已经监控到了 5 台主机,点击这个集群,可以看到 5 台主机的详细信息和各种监控指标。
通过 Ganglia 监控 Hadoop 集群
通过 Ganglia 监控 Hadoop 集群的运行状态非常简单,因为 Hadoop 是原生支持 Ganglia 的,这里我们只需在 Hadoop 集群每个节点的配置文件中找到 hadoop-metrics2.properties 文件,然后做简单地修改配置即可,添加内容如下所示:
*.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
*.sink.ganglia.period=10
*.sink.ganglia.supportsparse=true
namenode.sink.ganglia.servers=172.16.213.120:8649
datanode.sink.ganglia.servers=172.16.213.120:8649
resourcemanager.sink.ganglia.servers=172.16.213.120:8649
nodemanager.sink.ganglia.servers=172.16.213.120:8649
mrappmaster.sink.ganglia.servers=172.16.213.120:8649
jobhistoryserver.sink.ganglia.servers=172.16.213.120:8649
这里我配置了一个 Gmond 汇聚节点,也就是将 Hadoop 所有节点的监控数据都发送到 172.16.213.120 的 8649 端口。最后,Gmetad 再从 172.16.213.120 上去拉取数据,然后在 ganglia-web 上统一进行展示。
注意,每个 Hadoop 节点都要进行配置,并且配置完成后,需要重启 Hadoop 的各个服务(Namenode 服务、Datanode 服务、Resourcemanager 服务、Nodemanager 服务、Jobhistoryserver 服务)。重启服务后,Hadoop 的监控数据会自动发送到指定的 Gmond 节点。
所有 Hadoop 服务器重启完毕后,在 Ganglia 的 Web 界面,就可以看到相关状态图了,如下图所示:
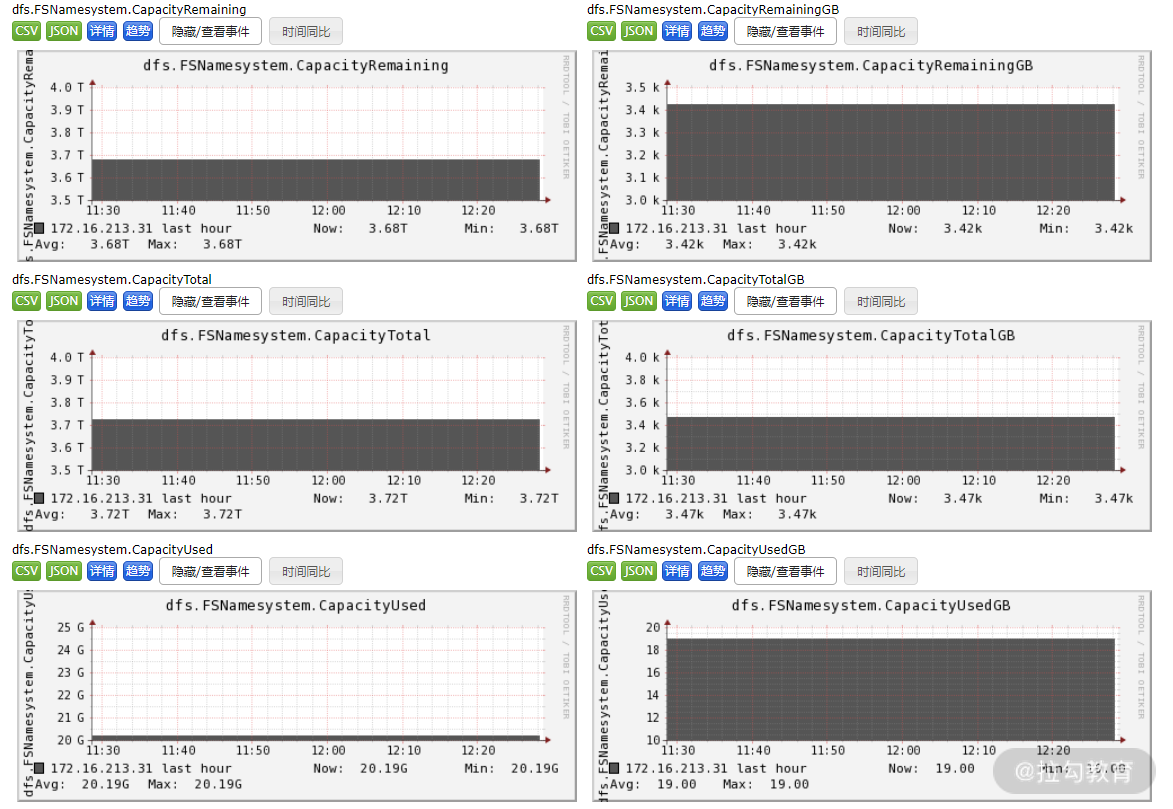
服务器重启后在 Ganglia 的 Web 界面相关状态图
Hadoop 在这个图中,dfs.FSNamesystem.CapacityTotal、dfs.FSNamesystem.CapacityRemaining 及 dfs.FSNamesystem.CapacityRemainingGB 等都是 Ganglia 对 Hadoop 的监控指标,我们可以通过程序获取这些指标的具体值,然后实现告警等操作。
获取 Ganglia 监控数据并实现告警
当 Ganglia 收集到 Hadoop 数据后,我们可以将需要监控的项目对应的值抽取出来,然后将采集到的数据与指定的报警阈值进行比较。如果发现采集到的数据大于或小于指定的报警阈值,那么就通过监控告警系统(如 Nagios/Zabbix/Centreon)设置的报警方式进行故障通知。在这个过程中,我们只关注如何抽取 Ganglia 监控到的数据,其他的操作,比如采集数据时间间隔、报警阈值设置、报警方式设置、报警联系人设置等都在监控告警系统中进行设置。
下面给出一个抽取 Ganglia 监控数据的脚本,内容如下:
#!/usr/bin/env python
import sys
import getopt
import socket
import xml.parsers.expat
class GParser:
def __init__(self, host, metric):
self.inhost =0
self.inmetric = 0
self.value = None
self.host = host
self.metric = metric
def parse(self, file):
p = xml.parsers.expat.ParserCreate()
p.StartElementHandler = parser.start_element
p.EndElementHandler = parser.end_element
p.ParseFile(file)
if self.value == None:
raise Exception('Host/value not found')
return float(self.value)
def start_element(self, name, attrs):
if name == "HOST":
if attrs["NAME"]==self.host:
self.inhost=1
elif self.inhost==1 and name == "METRIC" and attrs["NAME"]==self.metric:
self.value=attrs["VAL"]
def end_element(self, name):
if name == "HOST" and self.inhost==1:
self.inhost=0
def usage():
print """Usage: check_ganglia_metric \
-h|--host= -m|--metric= -w|--warning= \
-c|--critical= """
sys.exit(3)
if __name__ == "__main__":
##############################################################
ganglia_host = '127.0.0.1'
ganglia_port = 8651
host = None
metric = None
warning = None
critical = None
try:
options, args = getopt.getopt(sys.argv[1:],
"h:m:w:c:s:p:",
["host=", "metric=", "warning=", "critical=", "server=", "port="],
)
except getopt.GetoptError, err:
print "check_gmond:", str(err)
usage()
sys.exit(3)
for o, a in options:
if o in ("-h", "--host"):
host = a
elif o in ("-m", "--metric"):
metric = a
elif o in ("-w", "--warning"):
warning = float(a)
elif o in ("-c", "--critical"):
critical = float(a)
elif o in ("-p", "--port"):
ganglia_port = int(a)
elif o in ("-s", "--server"):
ganglia_host = a
if critical == None or warning == None or metric == None or host == None:
usage()
sys.exit(3)
try:
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((ganglia_host,ganglia_port))
parser = GParser(host, metric)
value = parser.parse(s.makefile("r"))
s.close()
except Exception, err:
print "CHECKGANGLIA UNKNOWN: Error while getting value \"%s\"" % (err)
sys.exit(3)
if critical > warning:
if value >= critical:
print "CHECKGANGLIA CRITICAL: %s is %.2f" % (metric, value)
sys.exit(2)
elif value >= warning:
print "CHECKGANGLIA WARNING: %s is %.2f" % (metric, value)
sys.exit(1)
else:
print "CHECKGANGLIA OK: %s is %.2f" % (metric, value)
sys.exit(0)
else:
if critical >= value:
print "CHECKGANGLIA CRITICAL: %s is %.2f" % (metric, value)
sys.exit(2)
elif warning >= value:
print "CHECKGANGLIA WARNING: %s is %.2f" % (metric, value)
sys.exit(1)
else:
print "CHECKGANGLIA OK: %s is %.2f" % (metric, value)
sys.exit(0)
在这个脚本中,需要修改的地方有两个,即 ganglia_host 和 ganglia_port。ganglia_host 表示 Gmetad 服务所在服务器的 IP 地址,这里我将脚本放在了 Gmetad 所在的服务器上,因此这个值就是 “127.0.0.1”。ganglia_port 表示 Gmetad 收集数据汇总的交互端口,默认是 8651。
将此脚本命名为 check_ganglia_metric.py,然后放到 Gmetad 所在的服务器上,并授予可执行权限。在命令行中直接执行 check_ganglia_metric.py 脚本,即可获得使用帮助:
[root@centreonserver plugins]# python check_ganglia_metric.py
Usage: check_ganglia_metric -h|--host= -m|--metric= -w|--warning= -c|--critical=
下面分别介绍其中各个参数的意义。
-
-h 表示从哪个主机上提取数据,后跟主机名或 IP 地址。这里需要注意的是,Ganglia 默认将收集到的数据存放在 gmetad 配置文件中“rrd_rootdir”参数指定的目录下。如果被监控的主机没有主机名或主机名没有进行 DNS 解析,那么 Ganglia 就会用此主机的 IP 地址作为目录名来存储收集到的数据;反之,就会以主机名作为存储数据的目录名称。因此,这里的“-h”参数就要以 Ganglia 存储 RRD 数据的目录名称为准。
-
-m 表示要收集的指标值,比如 cpu_num、disk_free、cpu_user、disk_total、load_one、part_max_used 等,这些指标值可以在 Ganglia 存储 RRD数据的目录中找到,也可以在 Ganglia 的 Web 界面中查找到。
-
-w 表示警告的阈值,当此脚本收集到的指标值低于或者高于指定的警告阈值时,此脚本就会发出告警通知,同时此脚本返回状态值 1。
-
-c 表示故障阈值,当此脚本收集到的指标值低于或者高于指定的故障阈值时,此脚本就会发出故障通知,同时此脚本返回状态值 2。
下面演示一下此脚本的用法,这里以检测 172.16.213.31 主机(Namenode 节点)的 HDFS 存储空间为例,其他指标值以此类推:
[root@centreonserver plugins]# ./check_ganglia_metric.py -h 172.16.213.31 -m dfs.FSNamesystem.CapacityRemainingGB -w 100 -c 50
CHECKGANGLIA OK: dfs.FSNamesystem.CapacityRemainingGB is 3424.00
这个例子是检测 Hadoop 可用的 HDFS 存储空间情况,指标 dfs.FSNamesystem.CapacityRemainingGB 表示可用的 HDFS 存储空间;-w 表示 HDFS 剩余可用空间小于 100 GB 时进行警告;-c 表示 HDFS 剩余可用空间小于 50 GB 时进行故障告警。从输出结果可知,HDFS 剩余空间目前有 3.4T 左右,远远高于指定的告警阈值。
通过此脚本,可以将 Ganglia 的监控指标对应的值提取出来,然后在监控告警平台进行触发告警,这个功能的实现将在下一课时讲解。
总结
本课时主要讲解了 Ganglia 监控系统的使用,首先对 Ganglia 的概念和架构进行了简单的介绍;然后讲解了 Ganglia 系统的安装和部署,以及如何通过 Ganglia 监控 Hadoop 集群的各个指标;最后讲解了通过一个脚本将 Ganglia 监控指标提取出来的方法,这是本课时的一个重点。通过 Ganglia 监控 Hadoop 非常简单,在大数据运维中,Ganglia 是监控的首选平台。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号