[大数据运维]第21讲:Filebeat+Kafka+Logstash+Elasticsearch 构建可视化日志分析系统
第21讲:Filebeat+Kafka+Logstash+Elasticsearch 构建可视化日志分析系统
高俊峰(南非蚂蚁)
典型 ELK 应用架构
下图是本课时即将要介绍的一个线上真实案例的架构图:
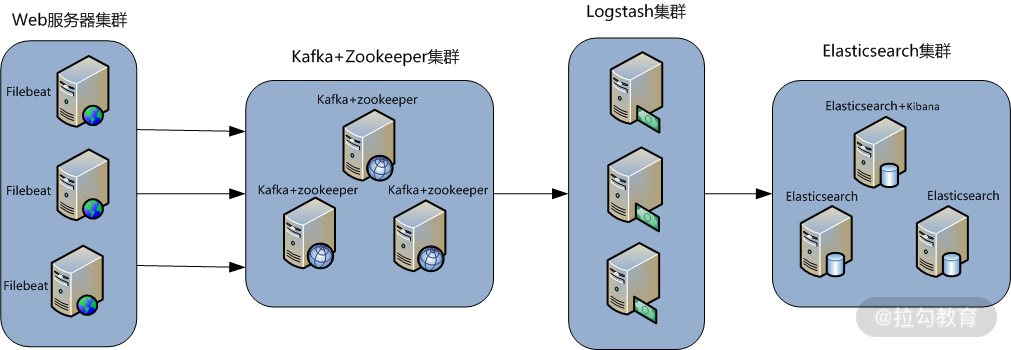
某个线上案例图
此架构稍微有些复杂,这里解读一下架构图,该图从左到右,总共分为 5 层,每层实现的功能和含义介绍如下。
第一层,数据采集层:数据采集层位于最左边的业务服务器集群上,在每个业务服务器上面安装了 Filebeat 做日志收集,然后把采集到的原始日志发送到 Kafka+ZooKeeper 集群上。
第二层,消息队列层:原始日志发送到 Kafka+ZooKeeper 集群上后,会进行集中存储,此时,Filbeat 是消息的生产者,存储的消息可以随时被消费。
第三层,数据分析层:Logstash 作为消费者,会去 Kafka+ZooKeeper 集群节点实时拉取原始日志,然后将获取到的原始日志根据规则进行分析、清洗、过滤,最后将清洗好的日志转发至 Elasticsearch 集群中。
第四层,数据持久化存储:Elasticsearch 集群在接收到 Logstash 发送过来的数据后,执行写磁盘、建索引库等操作,最后将结构化的数据存储到 Elasticsearch 集群上。
第五层,数据查询、展示层:Kibana 是一个可视化的数据展示平台,当有数据检索请求时,它从 Elasticsearch 集群上读取数据,然后进行可视化出图和多维度分析。
部署环境与角色说明
1. 服务器环境与角色
操作系统统一采用 Centos 7.7 版本,各个服务器角色如下表所示:
| IP 地址 | 主机名 | 角色 | 用途 |
|---|---|---|---|
| 172.16.213.156 | filebeatserver | 业务服务器 + filebeat | 业务服务器集群 |
| 172.16.213.31 | kafkazk1 | Kafka + ZooKeeper | Kafka Broker 集群 |
| 172.16.213.41 | kafkazk2 | Kafka + ZooKeeper | |
| 172.16.213.70 | kafkazk3 | Kafka + ZooKeeper | |
| 172.16.213.151 | logstashserver | Logstash | 数据转发 |
| 172.16.213.152 | server1 | ES Master、ES NataNode | Elasticsearch 集群 |
| 172.16.213.138 | server2 | ES Master、Kibana | |
| 172.16.213.80 | server3 | ES Master、ES NataNode |
基本架构图如下:
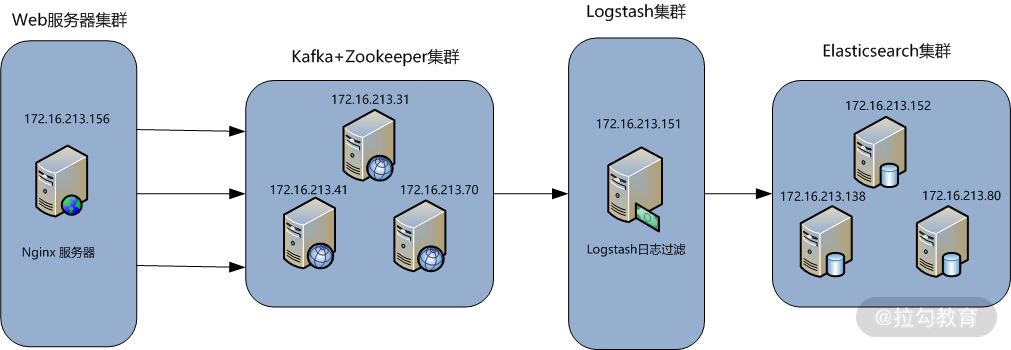
此架构需要 8 台服务器完成,每台服务器的作用和对应的 IP 信息都已经在图上进行了标注。最前面的一台是 Nginx 服务器,用于产生日志,然后由 Filebeat 来收集 Nginx 产生的日志,Filebeat 将收集到的日志推送(push)到 Kafka 集群中,完成日志的收集工作。接着,Logstash 去 Kafka 集群中拉取(pull)日志并进行日志过滤、分析,之后将日志发送到 Elasticsearch 集群中进行索引和存储,最后由 Kibana 完成日志的可视化查询。
在下面的介绍中,我们设定 Kafka 集群和 Elasticsearch 集群已经部署完成,在此基础上介绍如何通过 Filebeat 和 Logstash 收集与处理 Nginx 日志。
2. 软件环境与版本
下表详细说明了本课时安装软件对应的名称和版本号,其中,ELK 三款软件推荐选择一样的版本,这里选择的是 7.7.1 版本。
|
软件名称
|
版本
|
说明
|
|
JDK
|
JDK 1.8.0_171
|
Java 环境解析器
|
|
filebeat
|
filebeat-7.7.1-linux-x86_64
|
前端日志收集器
|
|
Logstash
|
logstash-7.7.1
|
日志收集、过滤、转发
|
|
zookeeper
|
zookeeper-3.5.8
|
资源调度、协作
|
|
Kafka
|
kafka_2.11-2.4.1
|
消息通信中间件
|
|
elasticsearch
|
elasticsearch-7.7.1
|
日志存储与检索
|
|
kibana
|
kibana-7.7.1-linux-x86_64
|
日志展示、分析
|
注意,Elasticsearch 新版本中已经自带了 JDK,因此无需用我们指定的 JDK,除此之外,Kafka、ZooKeeper 及 Logstash 都需要 JDK 环境。
EFLK 收集 Nginx 访问日志案例
1. Nginx 日志内容与格式分析
下面是一个业务系统输出的日志格式,由于业务系统输出的日志格式无法更改,因此需要我们通过 Logstash 的 Filter 过滤功能以及 grok 插件来获取需要的数据格式。此业务系统输出的日志内容以及原始格式如下:
2020-06-29T00:00:06+08:00|~|183.61.6.82|~|Mozilla/5.0 (iPhone; CPU iPhone OS 12_3_1 like Mac OS X)AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148|~|http://m.sina.cn/cm/ads_ck_wap.html|~|1460709836200|~|DF0184266887D0E
可以看出,这段日志都是以“|~|”为区间进行分隔的,那么刚好我们就以“|~|”为区间分隔符,将这段日志内容分割为 6 个字段。这里通过 grok 插件进行正则匹配组合就能完成这个功能。
完整的 grok 正则匹配组合语句如下:
%{TIMESTAMP_ISO8601:localtime}\|\~\|%{IPORHOST:clientip}\|\~\|(%{GREEDYDATA:http_user_agent})\|\~\|(%{DATA:http_referer})\|\~\|%{GREEDYDATA:media_id}\|\~\|%{GREEDYDATA:nginx_id}
这里用到了四种匹配模式,即 TIMESTAMP_ISO8601、IPORHOST、GREEDYDATA 和 DATA,都是 Logstash 默认的,可以在 Logstash 安装目录下找到。具体含义可自行查阅,这里不再介绍。
编写 grok 正则匹配组合语句有一定难度,需要根据具体的日志格式和 Logstash 提供的匹配模式配合实现,不我们可以借助于 grok 调试平台,在这个平台上,可以很方便地调试 grok 正则表达式。
有了上面这个 grok 匹配规则之后,就可以将此规则写入 Logstash 配置文件中,稍后我们来看看如何在 Logstash 中配置日志字段分割。
2. 配置 Filebeat
Filebeat 是安装在 Nginx 服务器上的,关于 Filebeat 的安装与基础应用,在前面已经详细介绍过了,这里不再说明,仅给出配置好的 filebeat.yml 文件的内容:
filebeat.inputs:
- type: log
enabled: true
paths:
- /data/nginx/openresty/logs/nginxlogs_*.log
fields:
log_topic: nginxlogs
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
name: "172.16.213.156"
setup.kibana:
output.kafka:
enabled: true
hosts: ["172.16.213.31:9092", "172.16.213.41:9092", "172.16.213.70:9092"]
version: "0.10"
topic: '%{[fields][log_topic]}'
codec.format.string: '%{[message]}'
partition.round_robin:
reachable_only: true
worker: 2
required_acks: 1
compression: gzip
max_message_bytes: 10000000
processors:
- drop_fields:
fields: ["input", "host", "agent.type", "agent.ephemeral_id", "agent.id", "agent.version", "ecs"]
logging.level: info
在这个配置文件中,是将 Nginx 的访问日志 /data/nginx/openresty/logs/nginxlogs_*.log 内容实时地发送到 Kafka 集群 Topic 为 nginxlogs 中。需要注意的是 Filebeat 输出日志到 Kafka 中配置文件的写法。这里用了 codec.format.string 配置项,也就是将日志保持原样输出到 Kafka 中,这种方式对后面的日志过滤减轻了很多工作量。
配置完成后,启动 Filebeat 即可:
[root@filebeatserver ~]# cd /usr/local/filebeat
[root@filebeatserver filebeat]# nohup ./filebeat -e -c filebeat.yml &
启动完成后,可查看 Filebeat 的启动日志,观察启动是否正常。注意,通过 nohup 这种方式启动 Filebeat 后,若要退出 SecureCRT 的话,则需要输入 exit 命令正常退出,不然 Filebeat 进程会自动关闭。
3. 配置 Logstash
上面我已经对 Nginx 的日志格式进行了分析,并做好了匹配规则,下面直接给出 Logstash 事件配置文件 kafka_nginx_into_es.conf 的内容:
input {
kafka {
bootstrap_servers => "172.16.213.31:9092,172.16.213.41:9092,172.16.213.70:9092"
topics => ["nginxlogs"]
add_field => { "[@metadata][myid]" => "nginxlogs" }
}
}
filter {
if [@metadata][myid] == "nginxlogs" {
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:localtime}\|\~\|%{IPORHOST:clientip}\|\~\|(%{GREEDYDATA:http_user_agent})\|\~\|(%{DATA:http_referer})\|\~\|%{GREEDYDATA:media_id}\|\~\|%{GREEDYDATA:nginx_id}" }
}
date {
match => ["localtime", "yyyy-MM-dd'T'HH:mm:ssZZ"]
target => "@timestamp"
}
mutate {
remove_field => "@version"
remove_field => "message"
remove_field => "localtime"
}
}
}
output {
if [@metadata][myid] == "nginxlogs" {
elasticsearch {
hosts => ["172.16.213.152:9200","172.16.213.138:9200","172.16.213.80:9200"]
index => "nginxlogs-%{+YYYY.MM.dd}"
}
}
}
这个配置文件完成实现的功能有如下几个方面:
-
从 Kafka 接收输入数据(消费数据)
-
将输入日志内容分为 6 个字段
-
将输入日志的时间字段信息转存到 @timestamp 字段里
-
删除 @version 字段、message 字段和 localtime 字段
-
将过滤分割后的内容输出到 Elasticsearch 中
在此配置文件中,input 中的 topics 用来指定从 Kafka 中需要从哪个 Topic 中读取数据,add_field 用来增加一个字段,用于标识和判断,在 output 输出中会用到。
接着,需要注意一下 date 插件中 match 的写法,其中,localtime 是输入日志中的时间字段,"yyyy-MM-dd'T'HH:mm:ssZZ" 用来匹配输入日志字段的格式,在匹配成功后,会将 localtime 字段的内容转存到 @timestamp 字段里,target 默认指的就是 @timestamp。所以 “target => "@timestamp"” 表示用 localtime 字段的时间更新 @timestamp 字段的时间。
在最后的 output 配置段中,使用了 Elasticsearch 插件,其中,hosts 是一个数组类型的值,后面跟的值是 Elasticsearch 节点的地址与端口,默认端口是 9200,可添加多个地址。index 指定 Nginx 日志在 Elasticsearch 中索引的名称,该名称会在 Kibana 中用到。这个索引名 nginxlogs 可以使用变量,Logstash 提供了 %{+YYYY.MM.dd} 这种写法。在语法解析的时候,看到以 + 开头的,就会自动认为后面是时间格式,尝试用时间格式来解析后续字符串。
这种以天为单位分割的写法,可以很容易删除老的数据或者搜索指定时间范围内的数据。此外,注意索引名中不能有大写字母。这里的索引名称我定义以 nginxlogs 开头,后面跟上时间,这样会每天生成一个索引。
所有配置完成后,就可以启动 logstash 了,执行如下命令:
[root@logstashserver ~]# cd /usr/local/logstash
[root@logstashserver logstash]# nohup bin/logstash -f kafka_nginx_into_es.conf &
logstash 启动后,可以通过查看 logstash 日志来观察是否启动正常,如果启动失败,则会在日志中有启动失败的提示。
4. 安装与配置 Kibana
前面课时中我陆续介绍了 Filebeat、Logstash、Elasticsearch 的安装、配置与使用,而在经典的 EFLK 架构(Elasticsearch、Filebeat、Logstash、Kibana)中,还有一个软件——Kibana,此软件负责数据的展示与多维度查询。下面我就介绍下这个软件的使用。
(1)下载与安装 Kibana
Kibana 使用 JavaScript 语言编写,安装部署十分简单,即下即用,你可以从 Elastic 官网下载所需的版本,需要注意的是 Kibana 与 Elasticsearch 的版本必须一致。另外,在安装 Kibana 时,要确保 Elasticsearch、Logstash 和 Kafka 已经安装完毕。
这里安装的版本是 kibana-7.7.1-linux-x86_64.tar.gz。将下载下来的安装包直接解压到一个路径下即可完成 Kibana 的安装,这里将其安装到 server1 主机(172.16.213.152)上,然后统一将 Kibana 安装到 /usr/local 目录下,基本操作过程如下:
[root@server1 ~]# tar -zxvf kibana-7.7.1-linux-x86_64.tar.gz -C /usr/local
[root@server1 ~]# mv /usr/local/kibana-7.7.1-linux-x86_64 /usr/local/kibana
这里我们将 Kibana 安装到了 /usr/local 目录下。
(2)配置 Kibana
由于将 Kibana 安装到了 /usr/local 目录下,因此,Kibana 的配置文件为 /usr/local/kibana/config/kibana.yml,其配置非常简单,这里仅列出常用的配置项,内容如下:
server.port: 5601
server.host: "172.16.213.152"
elasticsearch.url: "http://172.16.213.138:9200"
kibana.index: ".kibana"
其中,每个配置项的含义介绍如下:
-
server.port,Kibana 绑定的监听端口,默认是 5601;
-
-
server.host,Kibana 绑定的 IP 地址,如果内网访问,设置为内网地址即可;
-
-
elasticsearch.url,Kibana 访问 Elasticsearch 的地址,如果是 Elasticsearch 集群,添加任一集群节点 IP 即可,官方推荐设置为 Elasticsearch 集群中 client node 角色的节点 IP;
-
-
kibana.index,用于存储 Kibana 数据信息的索引,这个可以在 Kibana Web 界面中看到。
注意,这里我配置了 Kibana 从 172.16.213.138 节点上获取 Elasticsearch 数据,因此需要在此节点的 Elasticsearch 配置文件中添加如下内容:
http.cors.enabled: true
http.cors.allow-origin: "*"
其中,http.cors.enabled 用来设置是否支持跨域,默认为 false,这里设置为 true。当设置为允许跨域时,http.cors.allow-origin 设置才能生效,此配置默认值为 *,表示支持所有域名;如果只允许某些域名能访问,那么可以使用正则表达式匹配相关域名即可。
(3)启动 Kibana 服务
所有配置完成后,就可以启动 Kibana 了,启动的命令在 /usr/local/kibana/bin 目录下,具体如下:
[root@server1 ~]# cd /usr/local/kibana/
[root@server1 kibana]# nohup bin/kibana --allow-root &
[root@server1 kibana]# ps -ef|grep node
root 6407 1 0 Jan15 ? 00:59:11 bin/../node/bin/node --no-warnings bin/../src/cli
root 7732 32678 0 15:13 pts/0 00:00:00 grep --color=auto node
这样,Kibana 对应的 Node 服务就启动起来了。
(4)配置 Kibana 展示 Elasticsearch 数据
继续接着 EFLK 架构进行介绍,Filebeat 从 Nginx 上收集数据到 Kafka,然后 Logstash 从 Kafka 中拉取数据。如果数据能够正确发送到 Elasticsearch,我们就可以在 Kibana 中配置索引了。
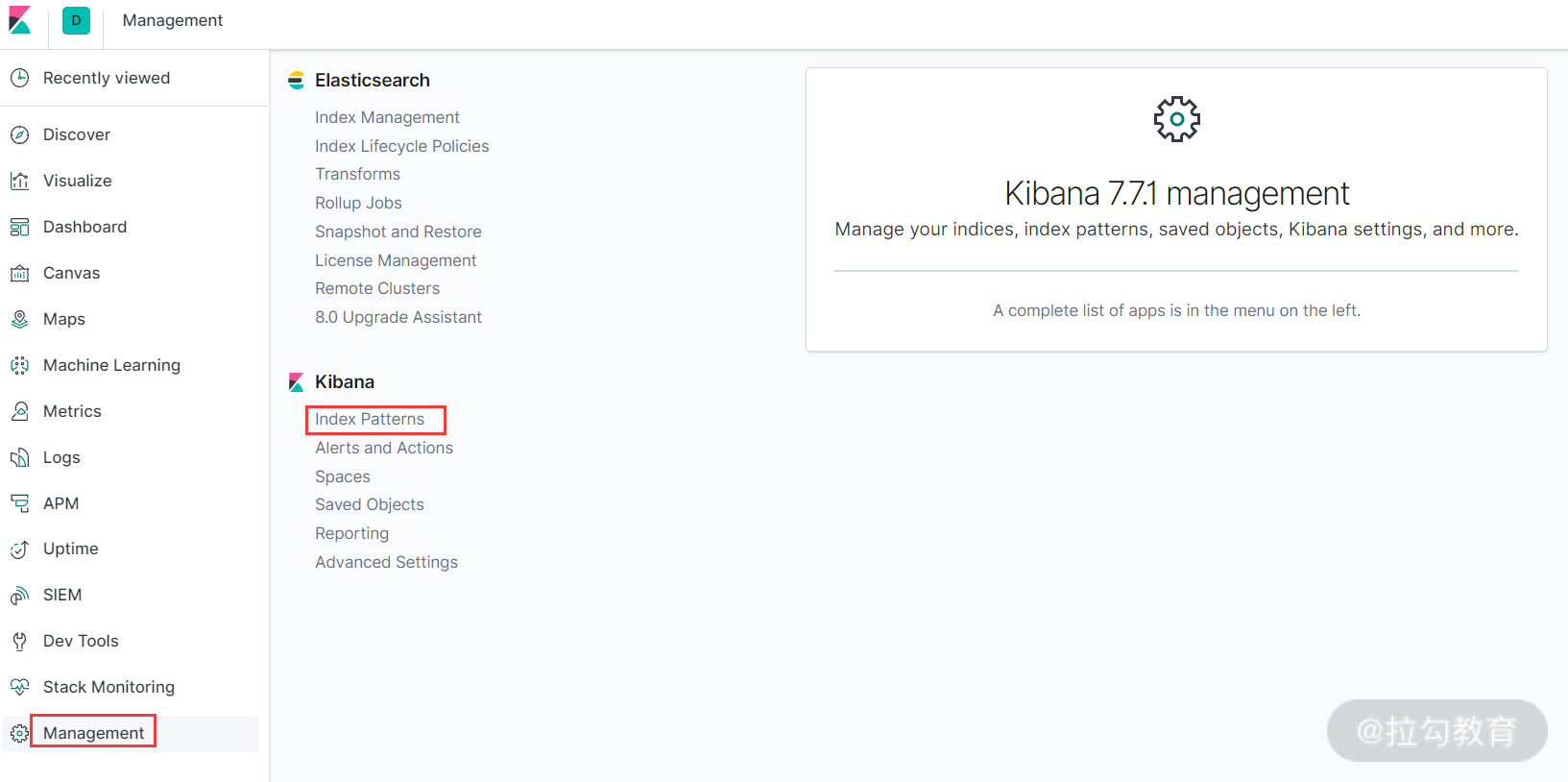
登录 Kibana,打开浏览器访问 http://172.16.213.152:5601 ,会自动打开 Kibana 的 Web 界面。在登录 Kibana 后,第一步要做的是配置 index_pattern,点击 Kibana 左侧导航中的 Management 菜单,然后选择右侧的 Index Patterns 按钮,如下图所示:
接着,点击 Index Patterns 按钮,开始创建一个 index pattern,如下图所示:
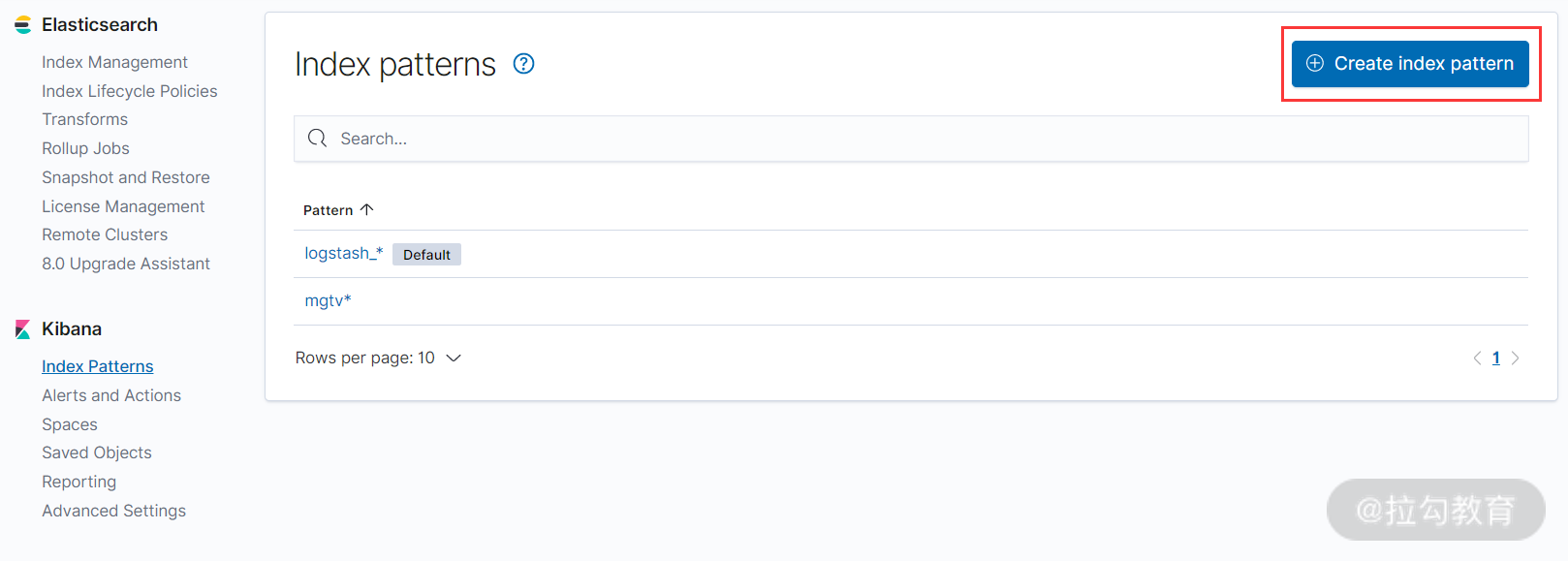
点击上图右上角的 Create index pattern 按钮,创建 index pattern 的界面如下所示:
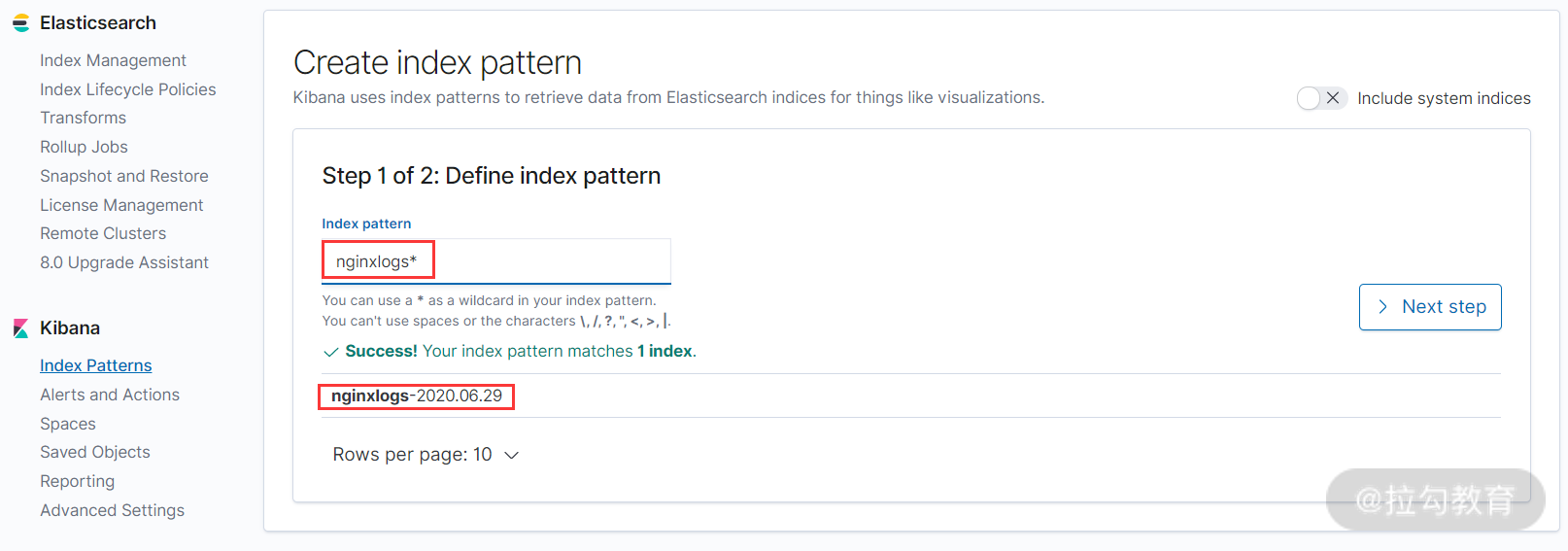
这里需要填写一个 Index pattern 名称,这个 Index pattern,其实我已经在 Logstash 中定义好了,名为 nginxlogs-%{+YYYY.MM.dd},而这里只需填入 nginxlogs-* 即可。如果已经有对应的数据写入 Elasticsearch,那么 Kibana 会自动检测到并抓取映射文件,此时就可以创建 Index pattern 了,如上图所示。如果你填入索引名称后,右边的 “Next step” 按钮仍然是不可点击状态的,则说明 Kibana 还没有抓取到输入索引对应的映射文件,此时可以让 Filebeat 再生成一点数据,只要数据正常传到 Elasticsearch 中,那么 Kibana 就能马上检测到。
接着,选择日志按照时间字段 “@timestamp” 进行排序,如下图所示:
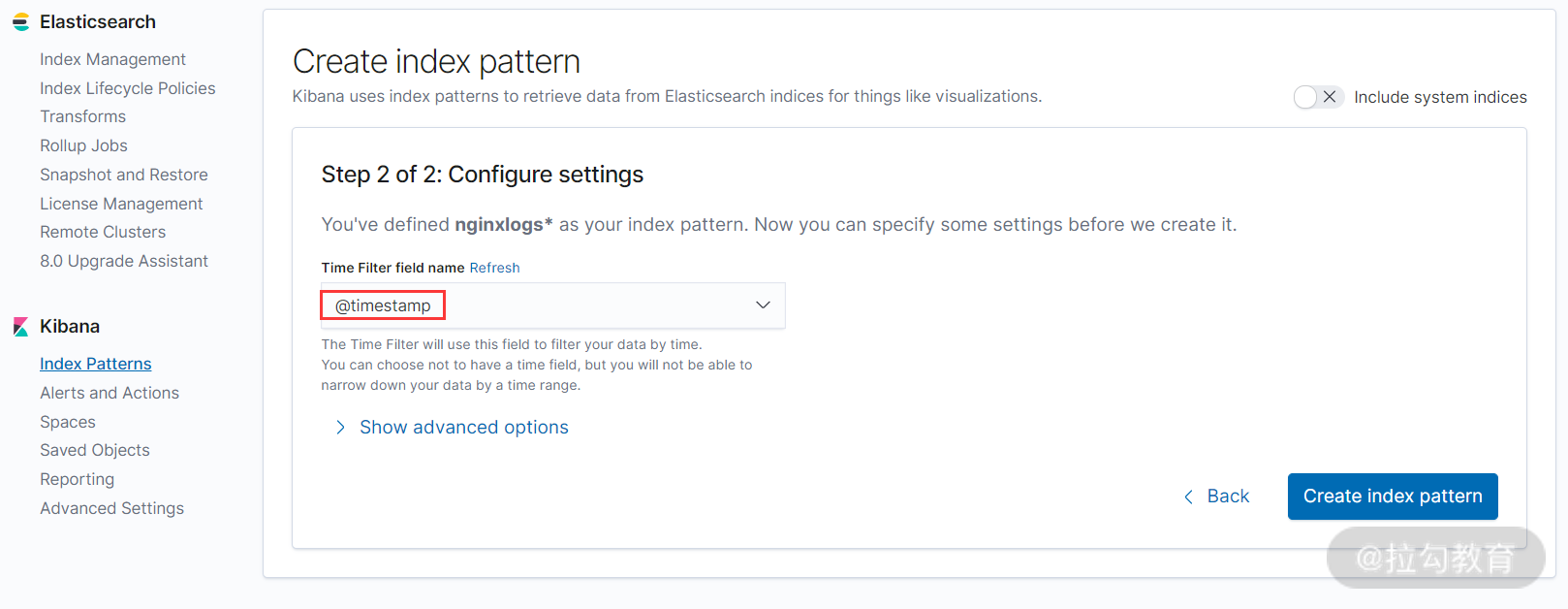
最后,点击 “Create index pattern” 按钮,完成 Index pattern 的创建,如下图所示:
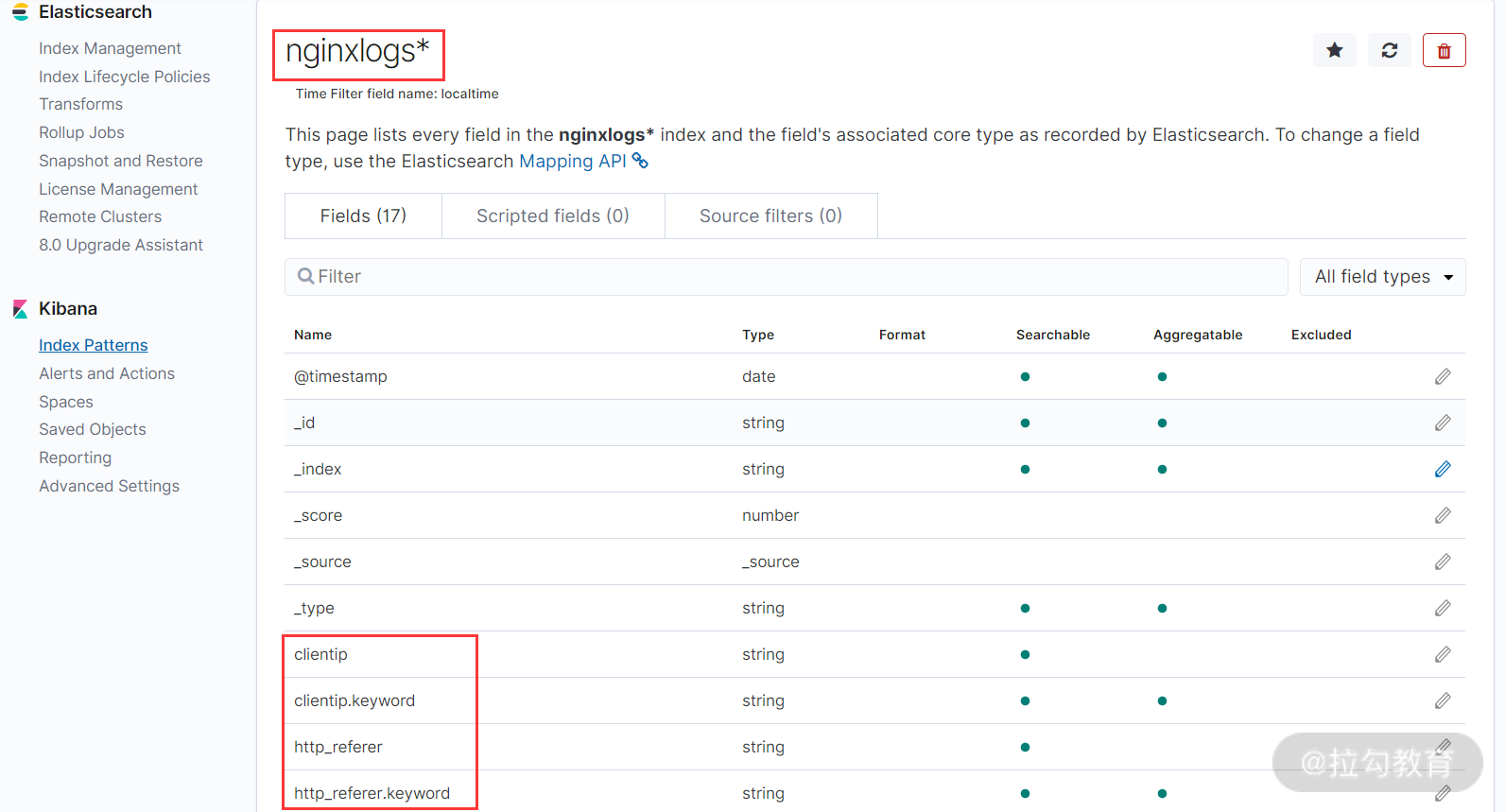
创建完成 Index pattern 后,点击 kibana 左侧导航中的 Discover 导航栏,即可展示已经收集到的日志信息,如下图所示:
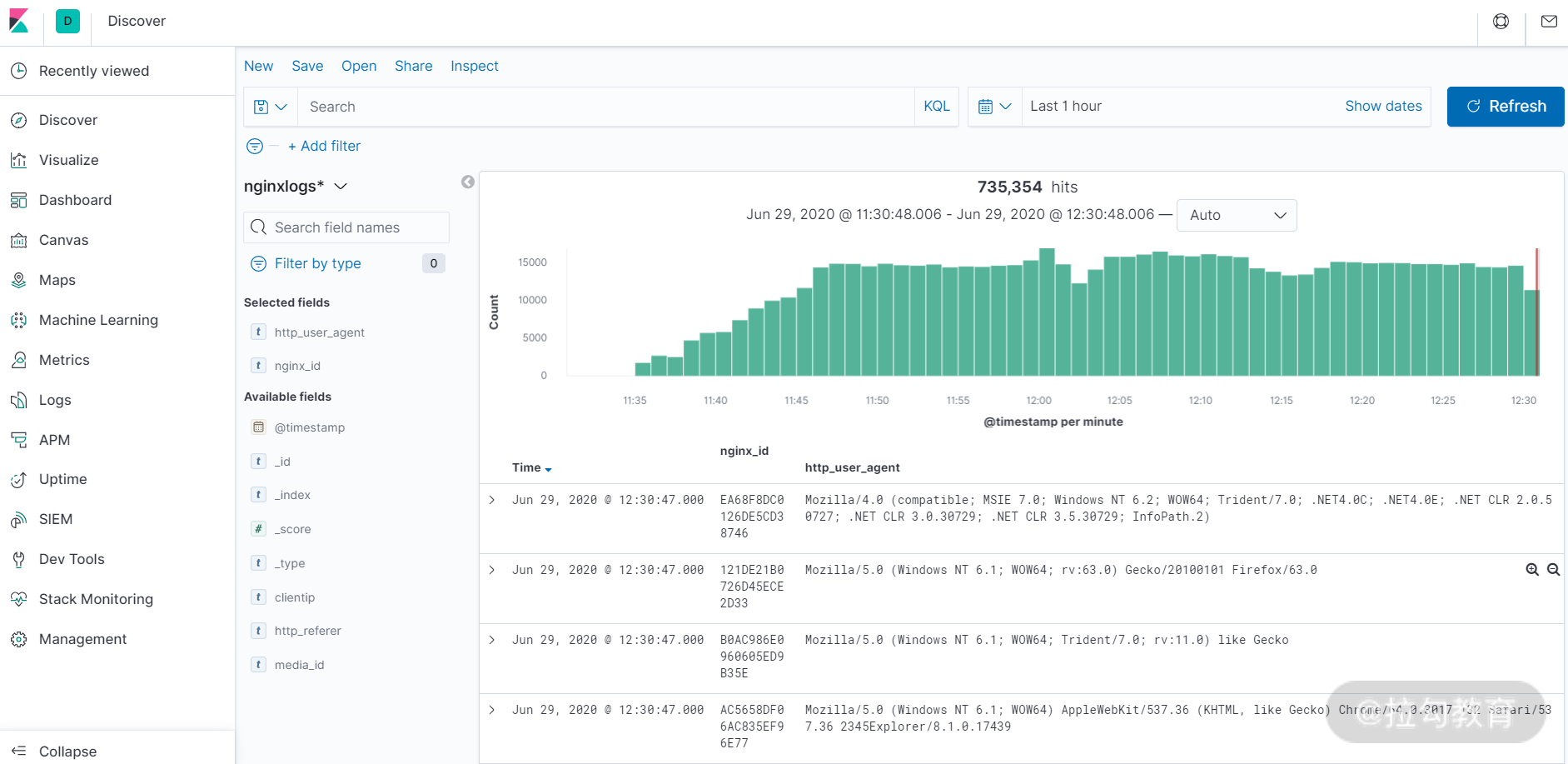
Kibana 的 Web 界面操作和使用比较简单,这里仅仅介绍下左侧导航栏中几个常用导航的含义及功能,更细节的功能可自行操作几遍就基本掌握了。
-
Discover:主要用来进行日志检索、查询数据,这个功能使用最多。
-
Visualize:数据可视化,可以在这里创建各种维度的可视化视图,如面积图、折线图、饼图、热力图、标签云等,通过创建可视化视图,日志数据浏览会变得非常直观。
-
Dashboard:仪表盘功能,仪表盘其实是可视化视图的组合,通过将各种可视化视图组合到一个页面,就可以从整体上了解数据和日志的各种状态。
-
Dev Tools:这是一个调试工具控制台,Kibana 提供了一个 UI 来与 Elasticsearch 的 REST API 进行交互。 控制台主要有两个方面,即 Editor(编辑器)与 Response(响应),Editor 用来编写对 Elasticsearch 的请求,Response 显示对请求的响应。
-
Management:这是管理界面,可以在这里创建索引模式,调整 Kibana 设置等操作。
至此,ELK 收集 Nginx 日志的配置工作完成。
总结
本课时主要介绍了生产环境下的 EFLK 应用架构收集 Nginx 日志的应用案例。首先讲解了 Nginx 日志如何进行字段分割,然后介绍了如何通过 Filebeat 收集 Nginx 日志并传送到 Kafka 集群中,接着介绍了如何通过 Logstash 从 Kafka 中消费日志,并将日志进行字段分割,同时传送到 Elasticsearch 中进行存储和查询,最后介绍了如何在 Kibana 中展示日志和查询日志。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号