[大数据运维]第16讲:轻量级日志收集工具 Filebeat 应用案例
第16讲:轻量级日志收集工具 Filebeat 应用案例
高俊峰(南非蚂蚁)
Filebeat 简介
Filebeat 是一个开源的文本日志收集器,Elastic 公司 Beats 数据采集产品的一个子产品,采用 Go 语言开发。一般安装在业务服务器上作为代理来监测日志目录或特定的日志文件,并把它们发送到 Logstash、Elasticsearch、Redis 或 Kafka 等。点击官方地址下载各个版本的 Filebeat。
Filebeat 架构与运行原理
Filebeat 是一个轻量级的日志监测、传输工具,它最大的特点是性能稳定、配置简单、占用系统资源很少,这也是强烈推荐 Filebeat 的原因。下图是官方给出的 Filebeat 架构图:
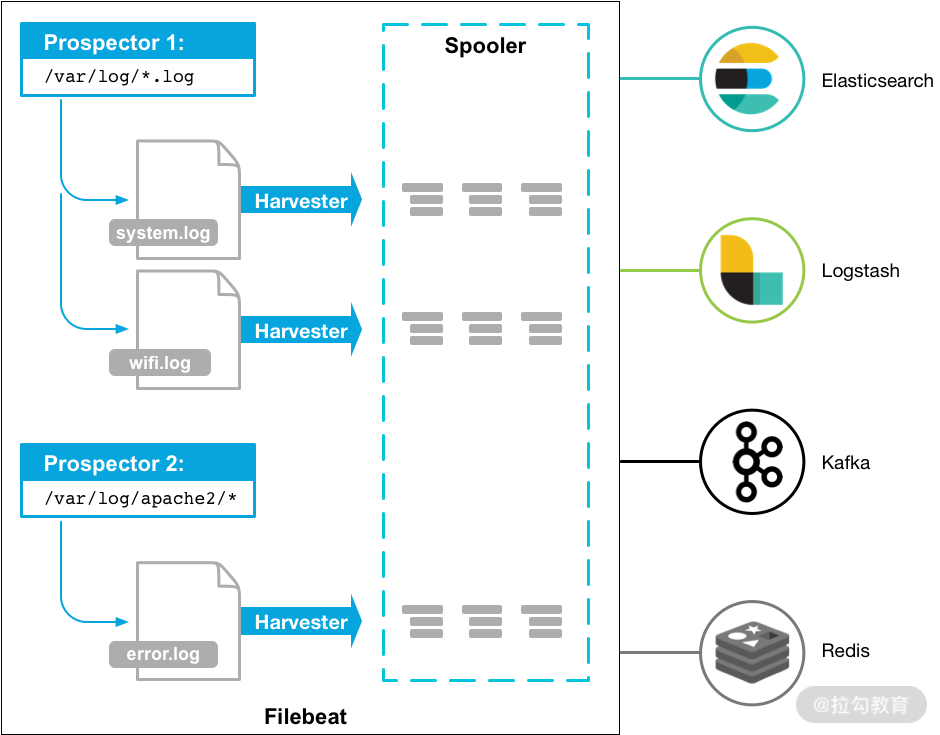
从图中可以看出,Filebeat 主要由两个组件构成:Prospector(探测器)和 Harvester(收集器),这两类组件一起协作完成 Filebeat 的工作。
其中,收集器负责进行单个文件的内容收集,在运行过程中,每一个收集器会对一个文件逐行进行内容读取,并且把读写到的内容发送到配置的 output 中。当收集器开始进行文件的读取后,将会负责这个文件的打开和关闭操作,因此,在收集器运行过程中,文件都处于打开状态。如果在收集过程中,删除了这个文件或者是对文件进行了重命名,Filebeat 依然会继续对这个文件进行读取,这时候将会一直占用着文件所对应的磁盘空间,直到收集器关闭。
探测器负责管理收集器,它会找到所有需要进行读取的数据源,然后交给收集器进行内容收集,如果 input type 配置的是 log 类型,探测器将会去配置路径下查找所有能匹配上的文件,然后为每一个文件创建一个收集器。
因此,filebeat 的工作流程为:当开启 filebeat 程序的时候,它会启动一个或多个探测器去检测指定的日志目录或文件,对于探测器找出的每一个日志文件,filebeat 会启动收集进程,每一个收集进程读取一个日志文件的内容,然后将这些日志数据发送到后台处理程序(spooler),后台处理程序会集合这些事件,最后发送集合的数据到 output 指定的目的地。
安装并配置 Filebeat
1. 为什么要使用 Filebeat
Logstash 功能虽然强大,但是它依赖 Java,在数据量大的时候,Logstash 进程会消耗过多的系统资源,这将严重影响业务系统的性能。而 Filebeat 就是一个完美的替代者,它也是 Beat 成员之一,基于 Go 语言,没有任何依赖,配置文件简单、格式明了,同时,Filebeat 比 Logstash 更加轻量级,所以占用系统资源极少,非常适合安装在生产机器上。这也是推荐使用 Filebeat 来作为日志收集软件的原因。
2. 下载与安装 Filebeat
你可以从 Elastic 官网获取 Filebeat 安装包,这里下载的版本是 filebeat-7.7.1-linux-x86_64.tar.gz,将下载下来的安装包直接解压到一个路径下即可完成安装。这里我将 Filebeat 安装到 filebeatserver 主机(172.16.213.156)上,设定将 Filebeat 安装到 /usr/local 目录下,基本操作过程如下:
[root@filebeatserver ~]# tar -zxvf filebeat-7.7.1-linux-x86_64.tar.gz -C /usr/local
[root@filebeatserver ~]# mv /usr/local/filebeat-7.7.1-linux-x86_64 /usr/local/filebeat
3. 配置 Filebeat
由上一步可知,Filebeat 的配置文件目录为 /usr/local/filebeat/filebeat.yml。Filebeat 的配置非常简单,这里仅列出常用的配置项,内容如下:
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/secure
fields:
log_topic: osmessages
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
name: "172.16.213.156"
setup.kibana:
output.kafka:
enabled: true
hosts: ["172.16.213.51:9092", "172.16.213.75:9092", "172.16.213.109:9092"]
version: "0.10"
topic: '%{[fields][log_topic]}'
partition.round_robin:
reachable_only: true
worker: 2
required_acks: 1
compression: gzip
max_message_bytes: 10000000
logging.level: debug
每个配置项的含义介绍如下:



注意,这个配置是将 filbeat 输出到 Kafka 中,因此你需要先配置好 Kafka 集群,并且将 Kafka 中的 topic 设置为可自动创建。
Filebeat 会将收集到的日志自动转成 json 格式输出,因此我们在 Kafka 中看到的日志应该是 json 格式的,该格式会占用部分空间,但是有助于后期对日志的过滤处理。如果你想将 Filebeat 获取到的日志原样输出到 Kafka 中,也是可以的,只需对 output 部分做如下修改:
output.kafka:
enabled: true
hosts: ["172.16.213.51:9092", "172.16.213.75:9092", "172.16.213.109:9092"]
version: "0.10"
topic: '%{[fields][log_topic]}'
codec.format.string: '%{[message]}'
partition.round_robin:
reachable_only: true
worker: 2
required_acks: 1
compression: gzip
max_message_bytes: 10000000
其实就是在 output 部分添加了 codec.format 这个配置,此配置表示指定写入 Kafka 集群的消息格式,后面只添加了 message 列,表示仅输出 json 中 message 字段的数据,而 message 字段就是最原始的日志内容,所以这个配置就是将原始的日志内容原样输出到 Kafka 中。
4. 启动 Filebeat 收集日志
所有配置完成之后,就可以启动 Filebeat,开启收集日志进程了,启动方式如下:
[root@filebeatserver ~]# cd /usr/local/filebeat
[root@filebeatserver filebeat]# nohup ./filebeat -e -c filebeat.yml &
这样,就把 Filebeat 进程放到后台运行起来了。启动后,在当前目录下会生成一个 nohup.out 文件,可以查看 Filebeat 启动日志和运行状态。
5. Filebeat 输出信息格式解读
这里以操作系统中 /var/log/secure 文件的日志格式为例,选取一个 SSH 登录系统失败的日志,内容如下:
Jun 11 16:17:43 localhost sshd[8160]: Failed password for root from 172.16.213.229 port 43860 ssh2
Filebeat 接收到 /var/log/secure 日志后,会将上面日志发送到 Kafka 集群,在 Kafka 任意一个节点上,消费输出日志内容如下:
{"@timestamp": "2020-06-11T08:17:47.848Z",
"@metadata": {
"beat": "filebeat",
"type": "_doc",
"version": "7.7.1"
},
"ecs": {
"version": "1.5.0"
},
"host": {
"name": "172.16.213.156"
},
"agent": {
"ephemeral_id": "a7e4d4f8-6508-40af-97a1-00504522c059",
"hostname": "filebeatserver",
"id": "958ac24b-c552-44e6-9a4a-1636f15ae0b6",
"version": "7.7.1",
"name": "172.16.213.156",
"type": "filebeat"
},
"log": {
"offset": 41480,
"file": {
"path": "/var/log/secure"
}
},
"message": "Jun 11 16:17:43 localhost sshd[8160]: Failed password for root from 172.16.213.229 port 43860 ssh2",
"input": {
"type": "log"
},
"fields": {
"log_topic": "osmessages"
}
}
从这个输出可以看到,输出日志被修改成了 JSON 格式,日志总共分为八个大字段,分别是 @timestamp、ecs、host、agent、log、message、input 和 fileds 字段,每个字段含义如下:
-
@timestamp,时间字段,表示读取到该行内容的时间;
-
ecs:ecs 版本字段,这是 Filebeat7 版本新增的一个字段,通过 ECS 可让用户对不同的数据源执行统一的搜索、可视化和分析;
-
host,主机名字段,输出主机名,如果没主机名,输出主机对应的 IP;
-
agent,表示 agent 所在主机的事件信息,比如主机名、IP 等;
-
log,表示读取的日志文件信息及偏移量信息;
-
message,表示真正的日志内容;
-
input,日志输入的类型,可以有多种输入类型,如 Log、Stdin、redis、Docker、TCP/UDP 等;
-
fields,topic 对应的消息字段或自定义增加的字段。
通过 Filebeat 接收到的内容,默认增加了不少字段,但是有些字段对数据分析来说没有太大用处,所以有时候需要删除这些没用的字段。在 Filebeat 配置文件中添加如下配置,即可删除不需要的字段:
processors:
- drop_fields:
fields: ["input", "host", "agent.type", "agent.ephemeral_id", "agent.id", "agent.version", "ecs"]
这个设置表示删除 input、host、agent.type、agent.ephemeral_id 等指定字段,其中,@timestamp 和 @metadata 字段是不能删除的。
注意这里使用了 processors,Filebeat 对于收集的每行日志都封装成 event,event 发送到 output 之前,可在配置文件中定义 processors 去处理 event。processor 主要用来减少输出的字段、添加其他的 metadata 等操作,每个 processor 会接收一个 event,并将一些定义好的规则应用到 event,然后发送到 output。
这里配置的 drop_fields 就是删除一些不必要的字段,具体删除哪些字段,要根据应用需求而定。如果将 Filebeat 的所有字段都输出到 Kafka,不但影响性能,而且还占用空间。
做完这个设置后,再次查看 Kafka 中的输出日志,已经不再输出这四个字段信息了。
Filebeat 输出到 Redis 的配置Filebeat 除了可以发送日志数据到 Kafka,还可以发送数据到 Redis。如果你需要发送数据给 Redis,可以按照如下配置文件进行配置:
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/messages
- /var/log/secure
name: "172.16.213.156"
output.redis:
hosts: ["172.16.213.227"]
db: "0"
key: "filebeat-log"
timeout: 5
logging.level: debug
在这个例子中,我监控了两个日志文件 /var/log/messages 和 /var/log/secure,并将这两个文件的内容实时输出到 Redis 中,重点看 output.redis 这部分的配置。Hosts 指定 Redis 服务器的地址,默认端口是 6379,db 指定将日志写到那个库中,key 指定 key 名称,timeout 是连接超时时间。
配置完成,启动 filebeat 服务,然后尝试 ssh 登录 172.16.213.156 主机,让 /var/log/secure 文件产生日志,接着登录 Redis 服务器,查看是否有数据写入,如下图所示:
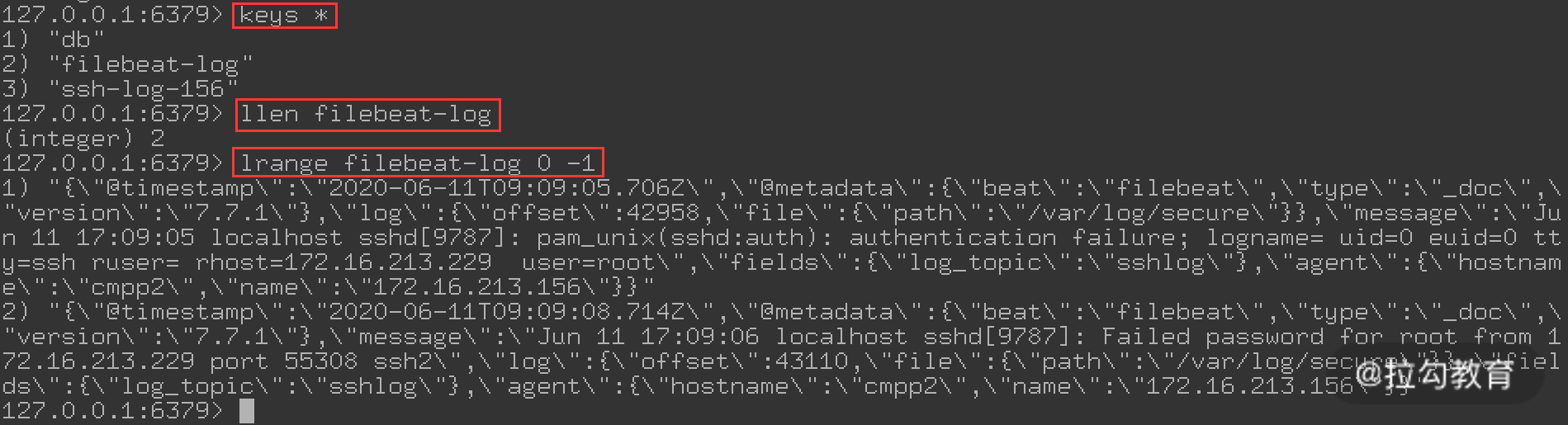
可以看到,Filebeat 已经将收集到的数据传到了 Redis 服务器上。
总结
本课时主要讲解了 Filebeat 的安装、配置及如何使用。在经典的 EFK 架构中,Filebeat 经常作为前端收集日志,然后将日志传给 Kafka,然后 Logstash 再从 Kafka 消费日志中将数据发送到 Elasticsearch 中,最后在 Kibana 中进行可视化展示。在后面的课时内容中我将陆续介绍这些架构的实现细节。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号