[大数据运维]第14讲:HBase 与 Hadoop 的整合应用实践
第14讲:HBase 与 Hadoop 的整合应用实践
高俊峰(南非蚂蚁)
Spark 与 Yarn 的整合过程
Spark 独立模式下集群资源配置比较灵活,但是当用户较多时,资源调度无法控制,则会出现资源争抢的情况。此时可以考虑使用 Yarn 的资源调度,也就是将 Spark 整合到 Yarn 资源管理器中,然后通过 Yarn 的资源调度策略来实现 Spark 集群资源的调度。下面我们就来讲解它们在整合时的步骤。
1.安装 Spark 客户端
在 Yarn 中集成 Spark,不需要在每个 Hadoop 节点中部署 Spark 程序。因为在 Yarn 中,Spark 是作为一个客户端存在的,也就是说,只需要选择一个 Hadoop 节点来安装 Spark 程序即可。这个节点就是 Spark 客户端,后面 Spark 任务的提交都在这个节点完成。
这里我的 Hadoop 集群版本为 Hadoop3.2.1,总共有五个 Hadoop 节点,Hadoop 集群环境如下表所示:
| 角色/主机名 | nnmaster.cloud(172.16.213.151) | yarnserver.cloud(172.16.213.152) | slave001.cloud(172.16.213.138) | slave002.cloud(172.16.213.80) | hadoopgateway.cloud(172.16.213.226) |
|---|---|---|---|---|---|
| NameNode | 是 | 是 | 否 | 否 | 否 |
| DataNode | 否 | 否 | 是 | 是 | 否 |
| JournalNode | 否 | 否 | 是 | 是 | 是 |
| ZooKeeper | 否 | 否 | 是 | 是 | 是 |
| ZKFC | 是 | 是 | 否 | 否 | 否 |
| ResourceManager | 否 | 是 | 否 | 否 | 否 |
| NodeManager | 否 | 否 | 是 | 是 | 否 |
| Spark | 否 | 否 | 否 | 否 | 是 |
这里将 Spark 软件安装到 Hadoopgateway.cloud 节点上,Spark 的版本这里仍然选择 Spark-3.0.0,登录 Spark 官网,下载二进制安装包 spark-3.0.0-preview2-bin-hadoop3.2.tgz,然后将 Spark 解压到 /opt/bigdata 目录下,安装过程与 Spark 独立集群模式完全一样,这里不再介绍。
2. 在 Yarn 中配置 Spark
这里以上面介绍的 Hadoop 集群环境为准,默认情况 Yarn 下只能运行 MR 任务。要让 Spark 也运行在 Yarn 下,则需要在 Yarn 配置文件中添加几个配置参数,第一个修改的配置文件是 yarn-site.xml,在此文件中添加如下内容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle,spark_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
其中,yarn.nodemanager.aux-services 表示 NodeManager 上运行的附属服务。添加 mapreduce_shuffle,才可运行 MapReduce 程序,这里新增了 spark_shuffle,表示可以运行 spark 任务。
最后两个参数分别表示运行 mapreduce、spark 需要加载的 Java 类文件,按照上面的内容添加进去即可。
由于指定了 spark_shuffle,还需要将 Spark 对应的 jar 包放到 Hadoop 的库文件中,这就进入了第二步。在 Spark 程序目录下找到 yarn 子目录,里面有一个 jar 文件,文件名类似 Spark-3.0.0-preview2-yarn-shuffle.jar,将此 jar 文件复制到 Hadoop 对应的 lib 目录下,我这里的路径为 /opt/bigdata/hadoop/current/share/hadoop/yarn/lib。Hadoop 集群中每个 NodeManager 节点都有执行此复制的操作,如果你忘记复制此 jar 文件,那么 NodeManager 服务就无法启动。
所有 NodeManager 节点 jar 包复制完成后,重启 yarn 服务和所有 NodeManager 服务,以使配置生效。
3. 开启 Spark 日志记录功能
配置 Spark 的历史日志服务,可以查看每个 Spark 任务的执行情况,以便于故障排查。若要开启 Spark 的 HistoryServer 功能,则需要执行三个步骤的操作,具体如下。
第一步,修改 Spark 配置文件目录下的 spark-env.sh 文件,添加如下内容:
export JAVA_HOME=/opt/bigdata/jdk
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/opt/bigdata/hadoop/current/lib/native
export SPARK_LIBRARY_PATH=$SPARK_LIBRARY_PATH
export SPARK_CLASSPATH=$SPARK_CLASSPATH
export HADOOP_HOME=/opt/hadoop/current
export HADOOP_CONF_DIR=/etc/hadoop/conf
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=30 -Dspark.history.fs.logDirectory=hdfs://bigdata/spark-job-log"
其中,主要是 SPARK_HISTORY_OPTS 选项,此选项有三个参数,每个参数含义如下:
-
spark.history.ui.port 用来指定 HistoryServer 的端口为 18080;
-
spark.history.retainedApplications 用来设置在内存中缓存任务信息详情的个数,不建议设置的太大,30 ~ 50 个即可;
-
spark.history.fs.logDirectory 用来指定存储 Spark 任务日志的 HDFS 路径,此路径在启动 HistoryServer 服务之前必须创建好。
第二步,在 Spark 的 spark-default.conf 文件中添加如下内容:
spark.shuffle.service.enabled true
spark.eventLog.enabled true
spark.yarn.historyServer.address=hadoopgateway.cloud:18080
spark.history.ui.port=18080
spark.eventLog.dir hdfs://bigdata/spark-job-log
spark.yarn.archive hdfs://bigdata/libs/sparkjars.zip
每个参数的含义如下所示。
-
spark.shuffle.service.enabled:shuffle Service 是长期存在于 NodeManager 进程中的一个辅助服务,该服务来抓取 shuffle 数据。通过设置此参数为 true,可以减少 Executor 的压力,在 Executor GC 的时候也不会影响其他 Executor 的任务运行。
-
spark.eventLog.enabled:是否开启 spark 日志服务功能,true 表示开启。
-
spark.yarn.historyServer.address:指定在哪个节点启动 Spark 的 HistoryServer 服务,后面跟上主机名加端口。
-
spark.history.ui.port:指定 HistoryServer 端口号,18080 是 HistoryServer 的默认端口。
-
spark.eventLog.dir:指定 Spark 读取任务日志的 HDFS 路径。
-
spark.yarn.archive:在运行 Spark 任务时,Spark 会从安装目录中读取依赖的 jar 文件到 HDFS。如果依赖的 jar 文件过多,那么此过程将非常耗时,此时,可以将 Spark 依赖的 jar 文件(Spark 安装程序对应的 jars 目录)事先上传到 HDFS 的某个路径下,然后通过 spark.yarn.archive 或者 spark.yarn.jars 参数去引用这个路径,这样可以大大减少任务的启动时间。
上传 jar 文件到 HDFS 有两种方法,一种是将所有 jar 文件打包成一个压缩文件,然后上传到 HDFS,此时可以通过 spark.yarn.archive 参数来引用这个路径;另一种是将所有 jar 文件一个个上传到 HDFS 上,然后通过 spark.yarn.jars 来引用。具体配置方式如下:
spark.yarn.jars hdfs://bigdata/libs/spark-yarn-jars/*.jar
spark.yarn.archive hdfs://bigdata/libs/sparkjars.zip
这两个参数,任选其一即可。
第三步,就是启动 HistoryServer 服务,在 Spark 客户端节点 hadoopgateway.cloud 启动 HistoryServer 服务,执行如下命令:
[hadoop@hadoopgateway conf]$ cd /opt/bigdata/spark/current/sbin
[hadoop@hadoopgateway sbin]$ ./start-history-server.sh
此时,打开 Hadoopgateway.cloud 的 18080 端口,如下图所示:
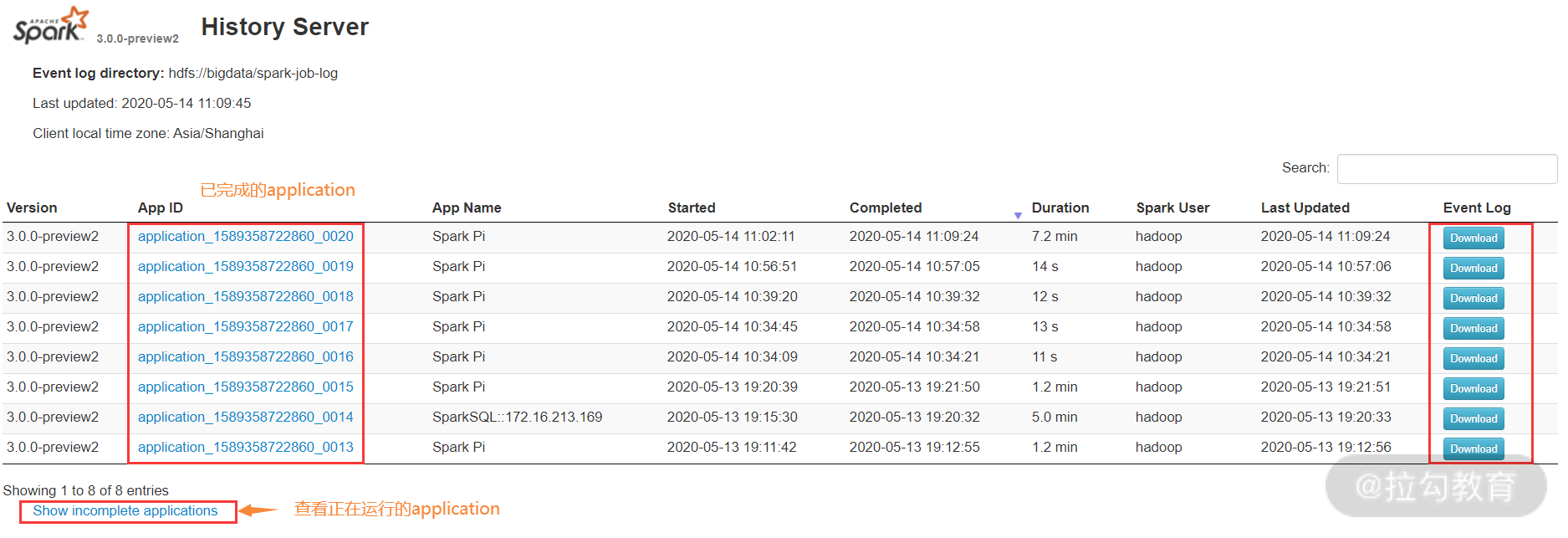
上图是执行 Spark 任务后的状态截图,默认此页面为空,当执行过 Spark 任务后,查看 HDFS 上的 spark-job-log 目录,应该也有数据了。
4. 测试 Yarn 下的 Spark 任务执行
将 Spark 集成到 Yarn 下后,就可以执行 Spark 任务了,在 Yarn 下执行 Spark 任务也有三种模式,即 spark-shell、spark-sql 和 spark-submit。这里以 spark-submit 为例,介绍 Yarn 下如何提交 Spark 任务到 Yarn 集群中。
-
yarn client 模式提交
可使用 spark-submit --master yarn 或者 spark-submit --master yarn --deploy-mode client,提交 Spark 任务到 Yarn 集群,例如:
[hadoop@hadoopgateway ~]$ spark-submit --class org.apache.spark.examples.SparkPi --master yarn /opt/bigdata/spark/current/examples/jars/spark-examples_2.12-3.0.0-preview2.jar
Pi is roughly 3.140115700578503
可以看到,yarn client 模式的结果输出到了屏幕上,在任务执行过程中,查看 yarn 的 8080 页面状态,如下图所示:

从此图中可以看出,Spark 任务成功提交到了 Yarn 集群,并且获取了集群资源。
-
yarn cluster 模式提交
可以使用 spark-submit --master yarn --deploy-mode cluster 提交 spark 任务到 yarn 集群,例如:
[hadoop@hadoopgateway ~]$ spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster /opt/bigdata/spark/current/examples/jars/spark-examples_2.12-3.0.0-preview2.jar
此模式下,任务执行完成后,并不会输出结果到屏幕,而是输出到某个节点上了,在任务执行过程中,查看 yarn 的 8080 页面状态,如下图所示:

从此图中可以看出 yarn cluster 模式与 yarn client 模式的区别,要查看任务执行结果,点击 application_1591072251901_0006 链接,会得到如下图所示结果:

5. yarn client 模式与 yarn cluster 模式流程解析
从上面的测试中可以发现,yarn client 模式与 yarn cluster 模式是有一些细微区别的,实际上,它们在执行流程上还是有很多不同的。下面对它们的执行流程做简单分析。
-
yarn client 模式流程解析
下图展示了 yarn client 模式的执行流程:
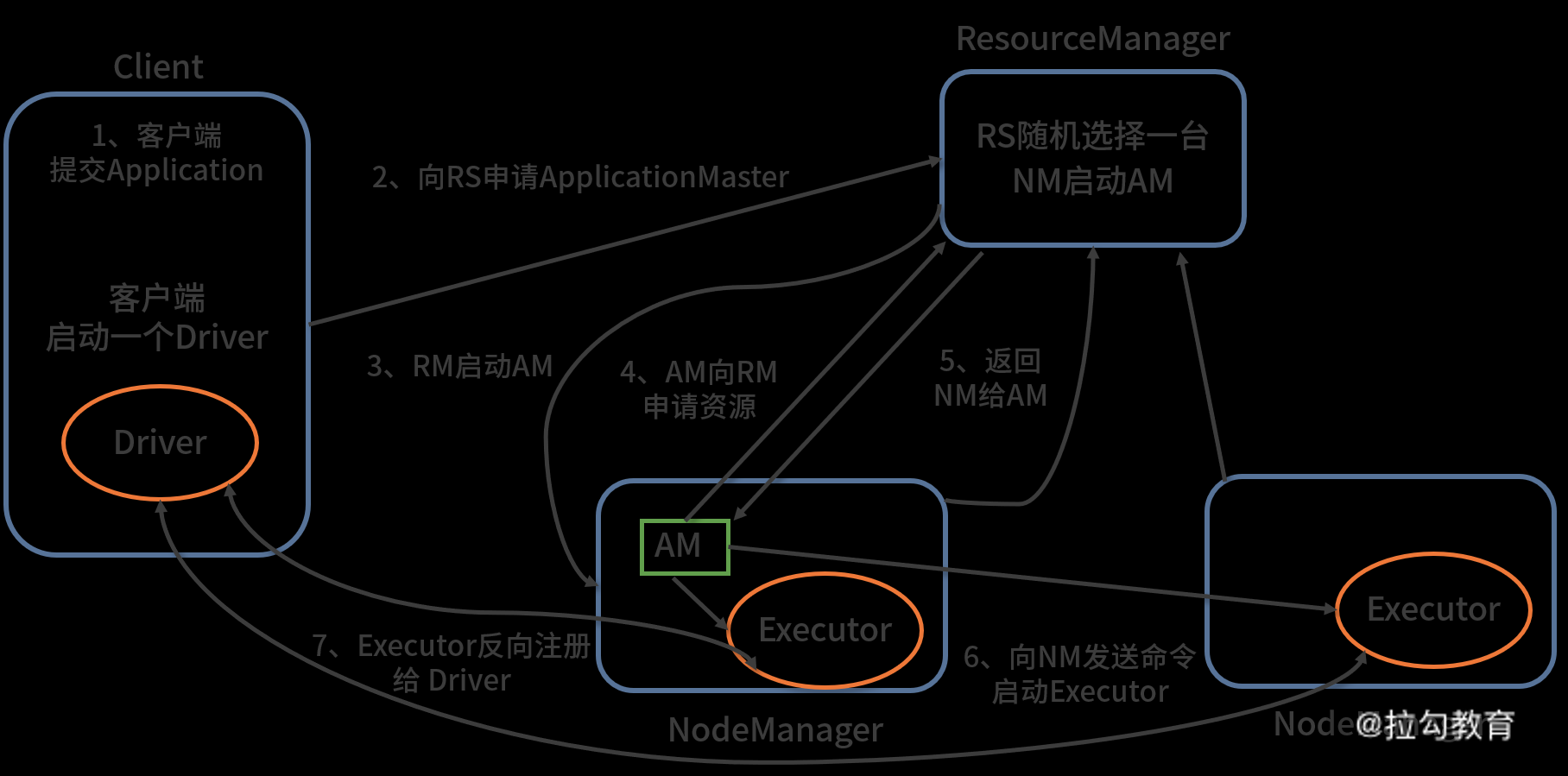
从图中可以看出,yarn client 模式的执行流程大致如下:
-
在客户端提交一个 Application,并启动一个 Driver 进程;
-
Driver 进程会向 RS(ResourceManager)发送请求,启动 AM(ApplicationMaster)的资源;
-
RS 收到请求,随机选择一台 NM(NodeManager)启动 AM,这里的 NM 相当于 Spark 独立集群模式中的 Worker 节点;
-
AM 启动后,会向 RS 请求一批 container 资源,用于启动 Executor;
-
RS 会找到一批 NM 返回给 AM,用于启动 Executor;
-
AM 会向 NM 发送命令启动 Executor;
-
Executor 启动后,会反向注册给 Driver,Driver 发送 task 到 Executor,执行情况和结果返回给 Driver 端。
-
yarn cluster 模式流程解析
如下图所示,展示了 yarn cluster 模式的执行流程:
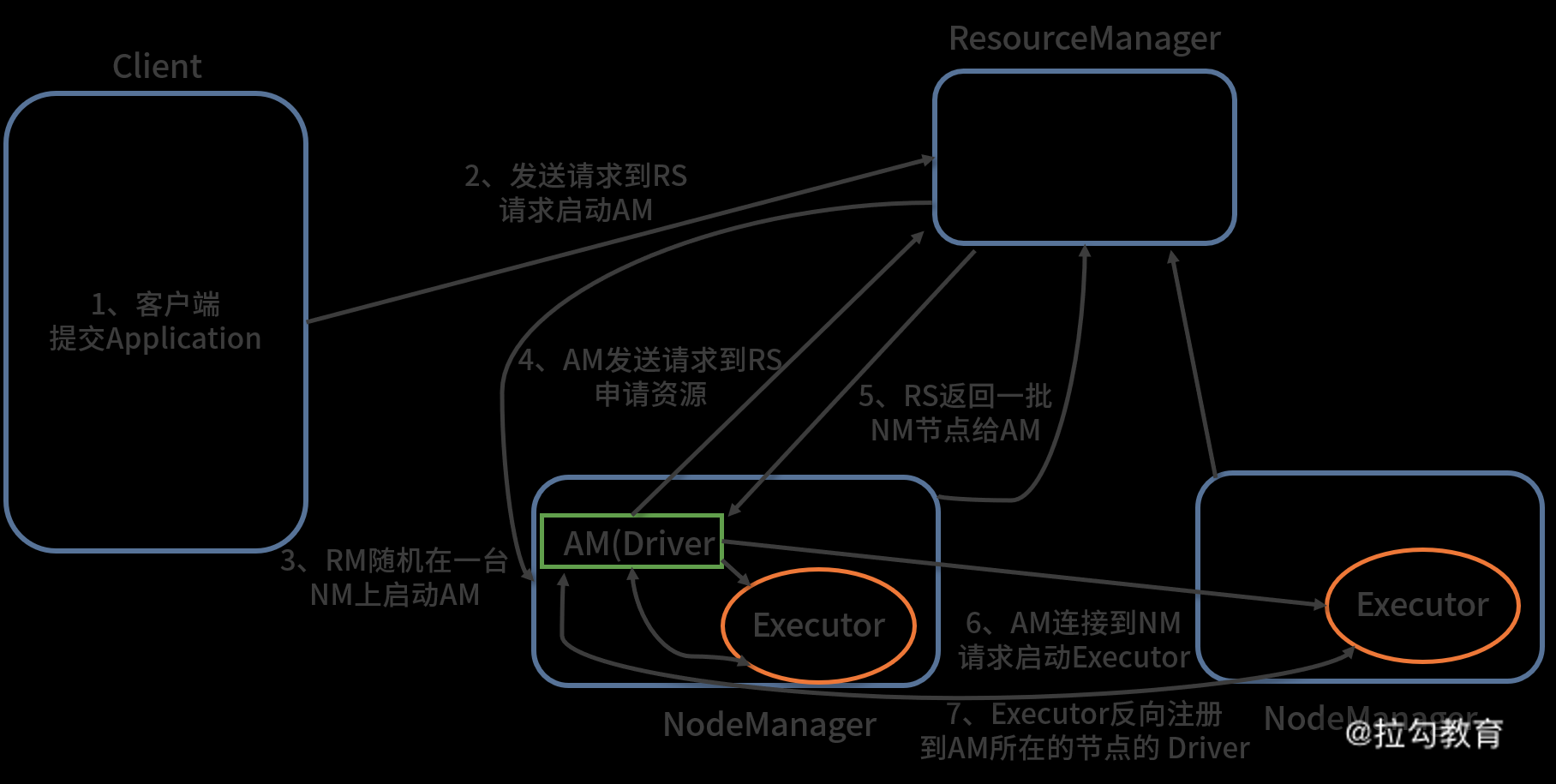
从图中可以看出,yarn cluster 模式的执行流程大致如下:
-
客户机提交 Application 应用程序;
-
发送请求到 RS(ResourceManager),请求启动 AM(ApplicationMaster);
-
RS 收到请求后随机在一台 NM(NodeManager)上启动 AM(相当于 Driver 端);
-
AM 启动,AM 发送请求到 RS,请求一批 container 用于启动 Executor;
-
RS 返回一批 NM 节点给 AM;
-
AM 连接到 NM,发送请求到 NM 并启动 Executor;
-
Executor 反向注册到 AM 所在节点的 Driver,Driver 发送 task 到 Executor。
HBase 与 Hadoop 集群的整合
HBase 的架构也是基于 master、slave 这种主、从模式的,在主节点运行 HMaster 服务,而在从节点运行 HRegionServer 服务。HMaster 作为一个管理节点,主要实现对 RegionServer 的监控、处理 RegionServer 故障转移、处理元数据的变更、处理 region 的分配或转移、在空闲时间进行数据的负载均衡、通过 ZooKeeper 发布自己的位置给客户端等功能。而 HRegionServer 负责 table 数据的实际读写,管理 Region。在 HBase 分布式集群中,HRegionServer 一般跟 DataNode 在同一个节点上,目的是实现数据的本地性,提高读写效率。
HBase 依赖于 HDFS 用于存储数据,所以在部署 HBase 时,需要 Hadoop 环境。下面就介绍下如何将 HBase 整合到 Hadoop 集群中。
1. HBase 和 Hadoop 版本的选择
安装 HBase 时,要考虑选择正确的 Hadoop 版本,否则可能出现不兼容的情况,一般情况下需要根据 Hadoop 版本来决定要使用的 HBase 版本,具体版本匹配信息可点击 HBase 官网链接查看。从左侧的 Basic Prerequisites 中可找到 HBase 与 JDK、Hadoop 的匹配关系,如下图所示:
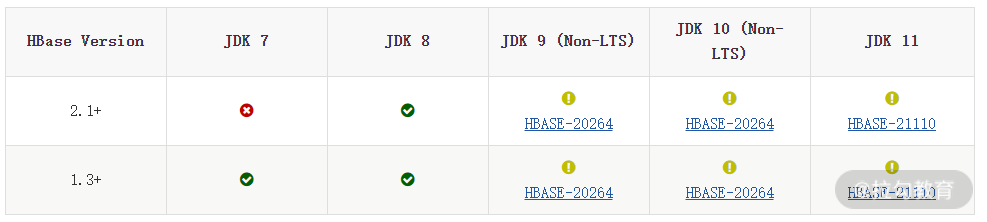
其中,图标为 x 这个符号表示不支持;图标为叹号表示未测试;绿色的对钩表示支持。从图中可以看出,HBase1.3 以后的版本支持 JDK7 和 JDK8,而 HBase2.1 以后的版本仅支持 JDK8,而 JDK9、10、11 目前还没有进行测试,所以这里我们选择 JDK8 版本。
下面再看一下 Hadoop 和 HBase 的对应关系,如下图所示:

从图中可以看出,Hadoop-3.1.1 以后的版本可以支持 HBase-2.1.x、HBase-2.2.x 和 HBase-2.3.x。这里我们仍然采用 Hadoop3.2.1 版本,而 HBase 采用 HBase-2.2.5,这两个版本之间是兼容的。
2. HBase 安装环境介绍
HBase 的安装需要依赖 Hadoop 环境(主要是 HDFS 分布式文件系统),这点跟 Spark 类似。因此,需要先安装好 Hadoop 集群,可以将 HDFS 和 HBase 集群部署在一起,也可以分开部署,考虑到性能问题,一般建议将 HDFS 和 HBase 集群服务部署在一起,而 nodemanager 服务不建议和 HBase 的 RegionServer 服务放在一起,因为这两个服务可能出现争抢资源的问题。下表是 Hadoop 集群节点环境以及安装 HBase 集群服务的规划:
| 角色/主机名 | nnmaster.cloud(172.16.213.151) | yarnserver.cloud(172.16.213.152) | slave001.cloud(172.16.213.138) | slave002.cloud(172.16.213.80) | hadoopgateway.cloud(172.16.213.226) |
|---|---|---|---|---|---|
| NameNode | 是 | 是 | 否 | 否 | 否 |
| DataNode | 否 | 否 | 是 | 是 | 否 |
| JournalNode | 否 | 否 | 是 | 是 | 是 |
| ZooKeeper | 否 | 否 | 是 | 是 | 是 |
| ZKFC | 是 | 是 | 否 | 否 | 否 |
| ResourceManager | 否 | 是 | 否 | 否 | 否 |
| NodeManager | 否 | 否 | 是 | 是 | 否 |
| HBase master | 是 | 是 | 否 | 否 | 否 |
| RegionServer | 否 | 是 | 是 | 是 | 否 |
| HBase client | 否 | 否 | 否 | 否 | 是 |
由于这里是演示环境,所以将 nodemanager 服务和 HBase 的 RegionServer 服务放在了一起。在生产环境下,建议将这两个服务分开。
3. HBase 的下载与安装
你可以点击 HBase 官网下载 HBase 程序,HBase 也提供了源码包和二进制包两种形式。这里我下载的是二进制包,HBase 版本为 HBase-2.2.5。
HBase 下载完成后,直接解压就完成安装了。
根据前面的规划,需要在 Hadoop 的所有节点安装 HBase 程序,这里我先在 nnmaster.cloud 主机上安装好 HBase,然后进行配置,配置完成后,打包统一复制到其他节点。这个过程可以采用 Ansible 的方法批量自动化完成。
这里我仍然将 HBase 安装到系统的简单的 /opt/bigdata 目录下,安装过程如下:
[root@nnmaster opt]# mkdir -p /opt/bigdata/hbase
[root@nnmaster opt]# tar zxvf hbase-2.2.5-bin.tar.gz -C /opt/ bigdata/hbase/
[root@nnmaster opt]# cd /opt/bigdata/hbase/
[root@nnmaster hbase]# ln -s hbase-2.2.5 current
安装完成后,还需要进行配置,下面进入 HBase 配置阶段。
4. 完全分布式 HBase 部署过程
HBase 的部署过程,也需要对系统进程基础优化、安装 JDK、ZooKeeper、关闭防火墙等基础操作。由于这个过程我已经在 Hadoop 集群配置完成,因此这里略去,直接进入 HBase 的配置过程。
-
在每个集群节点添加 HBase 环境变量
在 HBase 集群的每个节点上修改 Hadoop 用户下的 .bash_profile 文件,添加 HBase 环境变量,内容如下:
export HBASE_HOME=/opt/bigdata/hbase/current
export HBASE_CONF_DIR=/etc/hbase/conf
export PATH=$PATH:$HBASE_HOME/bin
注意,此文件中之前的 Hadoop 环境变量信息一定要保留,因为 HBase 也会去读取 Hadoop 的环境变量内容。这里我将 HBase 的配置文件路径设置为 /etc/hbase/conf,一会我要创建这个路径。
最后,执行 source 命令使其生效:
[root@nnmaster conf]#source /home/hadoop/.bash_profile
-
配置 HBase 集群
HBase 可以运行在单机模式下,也可以运行在集群模式下。单机模式主要用来进行功能测试,不能用于生产环境,因此,这里我们部署的是 HBase 集群模式。
HBase 的配置文件默认位于 HBase 安装目录下的 conf 子目录中,将这个 conf 目录复制一份到 /etc/hbase 目录中,当然要事先创建好 /etc/hbase 目录。接着,需要修改三个配置文件,分别是 hbase-env.sh、hbase-site.xml 及 regionservers 文件,同时还要新增 2 个文件,即 HDFS 的 hdfs-site.xml 及 backup-masters 文件。
首先修改 hbase-env.sh 文件,此文件用来设置 HBase 的一些 Java 环境变量信息,以及 JVM 内存信息,在此文件中添加如下内容:
export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -Xmx10g -XX:ReservedCodeCacheSize=256m"
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -Xmx20g -Xms20g -Xmn256m -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:ReservedCodeCacheSize=256m"
HBASE_MANAGES_ZK=false
第一个是配置 HBase master 的 JVM 内存大小,这个根据服务器物理内存大小和应用场景来定,我这里配置 10GB。
第二个是设置每个 RegionServer 进程的 JVM 内存大小,该内存尽量要设置大一些,如果是单独运行 RegionServer 的服务器,可设置物理内存的 80% 左右。
第三个是设置跟 ZooKeeper 相关的配置,如果 HBASE_MANAGES_ZK 为 true,则表示由 HBase 自己管理 ZooKeeper,不需要单独部署 ZooKeeper。如果为 false,则表示不使用 HBase 自带的 ZooKeeper,而使用独立部署的 ZooKeeper。这里设置为 false,也就是独立部署 ZooKeeper 集群,该 ZooKeeper 集群仍然使用之前 Hadoop 集群使用的那个 ZooKeeper 即可。
接着,修改 hbase-site.xml 文件,要添加的参数如下:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://bigdata/hbase</value>
<description>The directory shared by RegionServers.
</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>slave001.cloud,slave002.cloud,hadoopgateway.cloud</value>
</property>
<property>
<name>hbase.client.scanner.caching</name>
<value>100</value>
</property>
<property>
<name>hbase.regionserver.global.memstore.upperLimit</name>
<value>0.3</value>
</property>
<property>
<name>hbase.regionserver.global.memstore.lowerLimit</name>
<value>0.25</value>
</property>
<property>
<name>hfile.block.cache.size</name>
<value>0.5</value>
</property>
<property>
<name>hbase.master.maxclockskew</name>
<value>180000</value>
<description>Time difference of regionserver from master</description>
</property>
<property>
<name>hbase.client.scanner.timeout.period</name>
<value>300000</value>
<description>default is 60s</description>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>1800000</value>
<description>default is 90s</description>
</property>
<property>
<name>hbase.rpc.timeout</name>
<value>300000</value>
<description>default is 60s</description>
</property>
<property>
<name>hbase.hregion.memstore.flush.size</name>
<value>268435456</value>
<description>default is 128M</description>
</property>
<property>
<name>hbase.hregion.max.filesize</name>
<value>6442450944</value>
</property>
<property>
<name>hbase.regionserver.handler.count</name>
<value>100</value>
<description>default is 30</description>
</property>
</configuration>
对其中每个参数含义介绍如下。
-
hbase.rootdir:指定 RegionServer 的共享目录,用来持久化 HBase,这个 URL 是 HDFS 上的一个路径。需特别注意的是,hbase.rootdir 里面的 HDFS 地址是要跟 Hadoop 的 core-site.xml 里面的 fs.defaultFS 参数设置 HDFS 的 IP 地址或者域名、端口必须一致。
-
hbase.cluster.distributed:用来设置 HBase 的运行模式,值为 false 表示单机模式,为 true 表示分布式模式。
-
hbase.unsafe.stream.capability.enforce:此参数是为了解决文件系统不支持 hsync 报错而造成启动失败的问题,究其原因,是因为二进制版本的 HBase 编译环境是 Hadoop2.x,而 Hadoop2.x 版本不支持 hsync。
-
hbase.zookeeper.quorum:设置 ZooKeeper 独立集群的地址列表,用逗号分隔每个 ZooKeeper 节点,必须是奇数个。
-
hbase.client.scanner.caching:这是个优化参数,表示当调用 Scanner 的 next 方法,而 当值又不在缓存里的时候,从服务端一次获取的行数。越大的值意味着 Scanner 会快一些,但是会占用更多的内存。
-
hbase.regionserver.global.memstore.upperLimit:设置单个 region server 的全部 memtores 最大值。超过这个值,一个新的 update 操作会被挂起,强制执行 flush 操作。
-
hbase.regionserver.global.memstore.lowerLimit:此参数跟上面这个参数相关联,表示强制执行 flush 操作的时候,当低于这里设置的值时,flush 就会停止,默认是堆大小的 35%。如果这个值和 hbase.regionserver.global.memstore.upperLimit 相同,则意味着当 update 操作因为内存限制被挂起时,会尽量少的执行 flush 操作。
-
hfile.block.cache.size:表示分配给 HFile/StoreFile 的 block cache 占最大堆(-Xmx setting)的比例,默认是 20%,设置为 0 就是不分配。
-
hbase.master.maxclockskew:HBase 集群各个节点可能出现和 HBase master 节点时间不一致,这会导致 RegionServer 退出,通过设置此参数,可以增大各节点的时间容忍度,默认是 30s,此值不要太大,毕竟时间不一致是不正常现象,可将所有节点和内网时间服务器做同步,也可以和外网时间服务器进行同步。
-
hbase.client.scanner.timeout.period:该参数表示 HBase 客户端发起一次 scan 操作的 RPC 调用至得到响应之间总的超时时间。
-
zookeeper.session.timeout:设置 HBase 和 ZooKeeper 的会话超时时间。HBase 把这个值传给 ZooKeeper 集群,单位是毫秒。
-
hbase.rpc.timeout:设置 RPC 的超时时间,默认 60s。
-
hbase.hregion.memstore.flush.size:设置 memstore 的大小,当 memstore 的大小超过这个值的时候,会 flush 到磁盘。
-
hbase.regionserver.handler.count:此参数表示 RegionServers 受理的 RPC Server 实例数量。对于 Master 来说,这个属性是 Master 受理的 handler 数量,然后修改第三个文件 regionservers,将 regionservers 节点的主机名添加到此文件即可,一行一个主机名,根据之前规划,内容如下:
yarnserver.cloud
slave001.cloud
slave002.cloud
配置 HBase 要修改的文件就这三个,接下来,还需要将 Hadoop 集群中 HDFS 的配置文件 hdfs-site.xml 软连接或者复制到 /etc/hbase/conf 目录下,因为 HBase 会读取 HDFS 配置信息。
最后,还需要新增一个配置文件 backup-masters,用来实现 HBase 集群的高可用,为了保证 HBase 集群的高可靠性,HBase 支持多 Backup Master 设置,当 Active Master 故障宕机后,Backup Master 可以自动接管整个 HBase 的集群。要实现这个功能,只需要在 HBase 配置文件目录下新增一个文件 backup-masters 即可,在此文件中添加要用做 Backup Master 的节点主机名,可以添加多个,一行一个。
这里我将 yarnserver.cloud 主机作为 HBase master 的备用节点,因此,backup-masters 文件的内容为:
yarnserver.cloud
至此,HBase 集群配置完毕。
5. 启动与维护 HBase 集群
所有配置完成后,将配置文件复制到 HBase 集群的所有节点上,然后就可以起到 HBase 集群服务了。下面我来为你讲解它的具体步骤。
-
启动 HMaster 服务
执行如下命令启动 HMaster 服务:
[hadoop@nnmaster conf]$/opt/bigdata/hbase/current/bin/hbase-daemon.sh start master
[hadoop@nnmaster conf]$ jps
12993 NameNode
19124 HMaster
19304 Jps
13198 DFSZKFailoverController
由于配置了 HMaster 的高可用服务,因此需要在 nnmaster.cloud 节点和 yarnserver.cloud 节点都启动 HMaster 服务。服务启动后,可以看到有个 HMaster 进程,表示 HMaster 服务启动成功。
-
启动 HRegionServer 服务
按照上面的规划,需要在 yarnserver.cloud、slave001.cloud 和 slave002.cloud 节点启动 regionserver 服务。执行如下命令启动 HRegionServer 服务:
[hadoop@slave001 conf]$ /opt/bigdata/hbase/current/bin/hbase-daemon.sh start regionserver
[hadoop@slave001 conf]$ jps
32435 QuorumPeerMain
3444 HRegionServer
6389 Jps
614 DataNode
3930 NodeManager
32702 JournalNode
服务启动后,会看到有个 HRegionServer 进程,表示 regionserver 服务器的成功。
所有服务启动完成后,可以查看 HBase 的 Web 页面,访问 [http://nnmaster.cloud : 16010](http://nnmaster.cloud : 16010),其中,16010 是 HMaster 的默认 Web 端口,如下图所示:
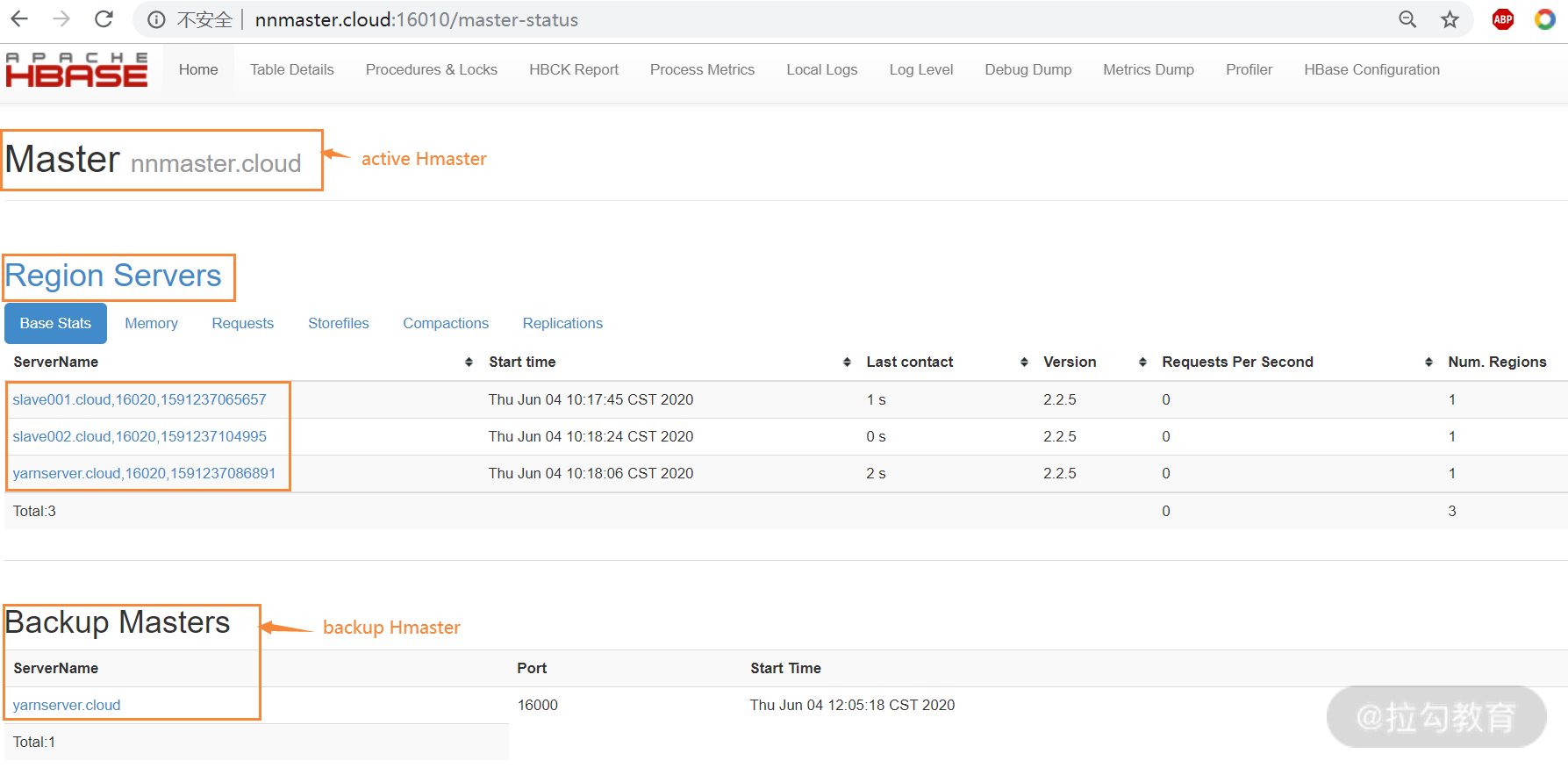
从图中可以看出,活跃的 HMaster 和备用的 HMaster,以及 regionserver 节点的状态信息。
6. 测试 HBase 的基础功能与 HA 功能
HBase 集群服务启动后,我们可以在 HBase client 主机上(hadoopgateway.cloud)进入 HBase 命令行,执行如下命令:
[hadoop@hadoopgateway ~]$ hbase shell
进入 HBase 命令行后,即可执行创建表等操作,如下图所示:
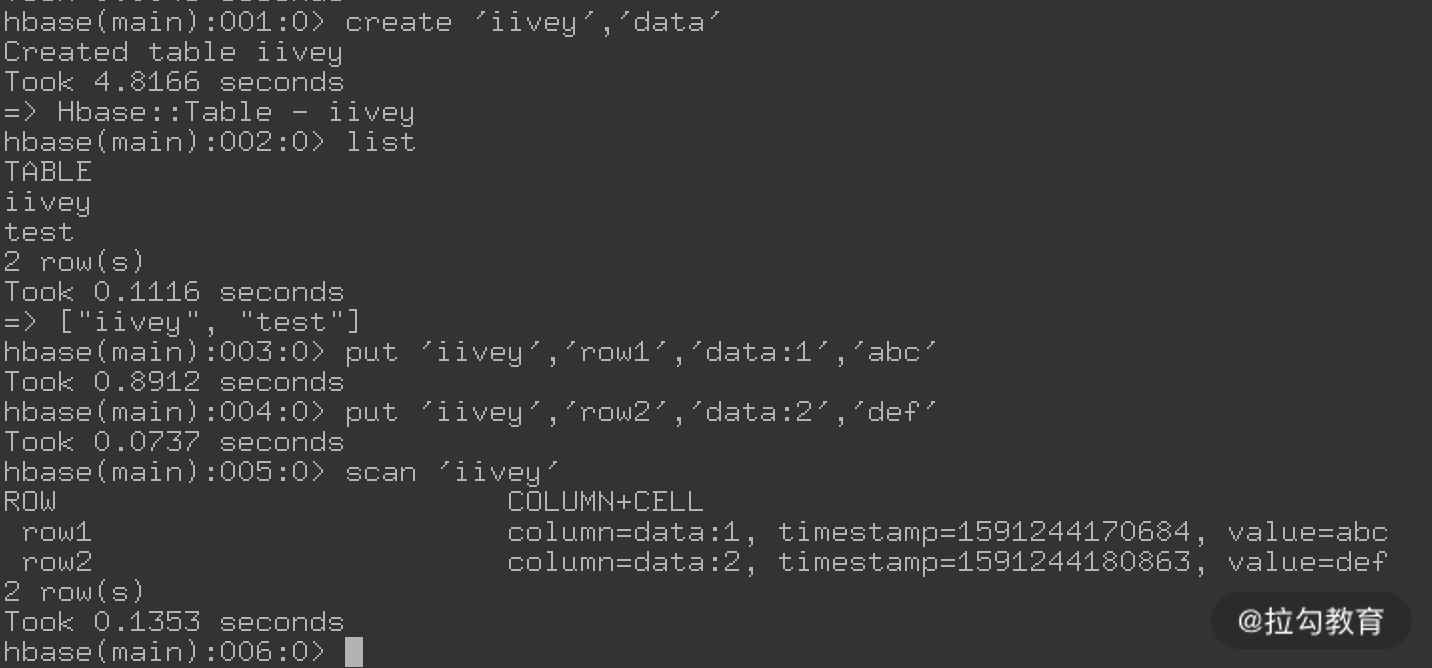
创建的表默认会存储在 HDFS 的 /hbase 路径下,可以查看是否生成相关目录和文件。
上面我们配置了 HMaster 的 HA,要测试是否实现了 HA 功能,只需要停止目前处于 active 状态的 HMaster 服务,然后通过 HMaster 的 16010 端口页面观察是否自动实现了主、备切换。如下图所示:
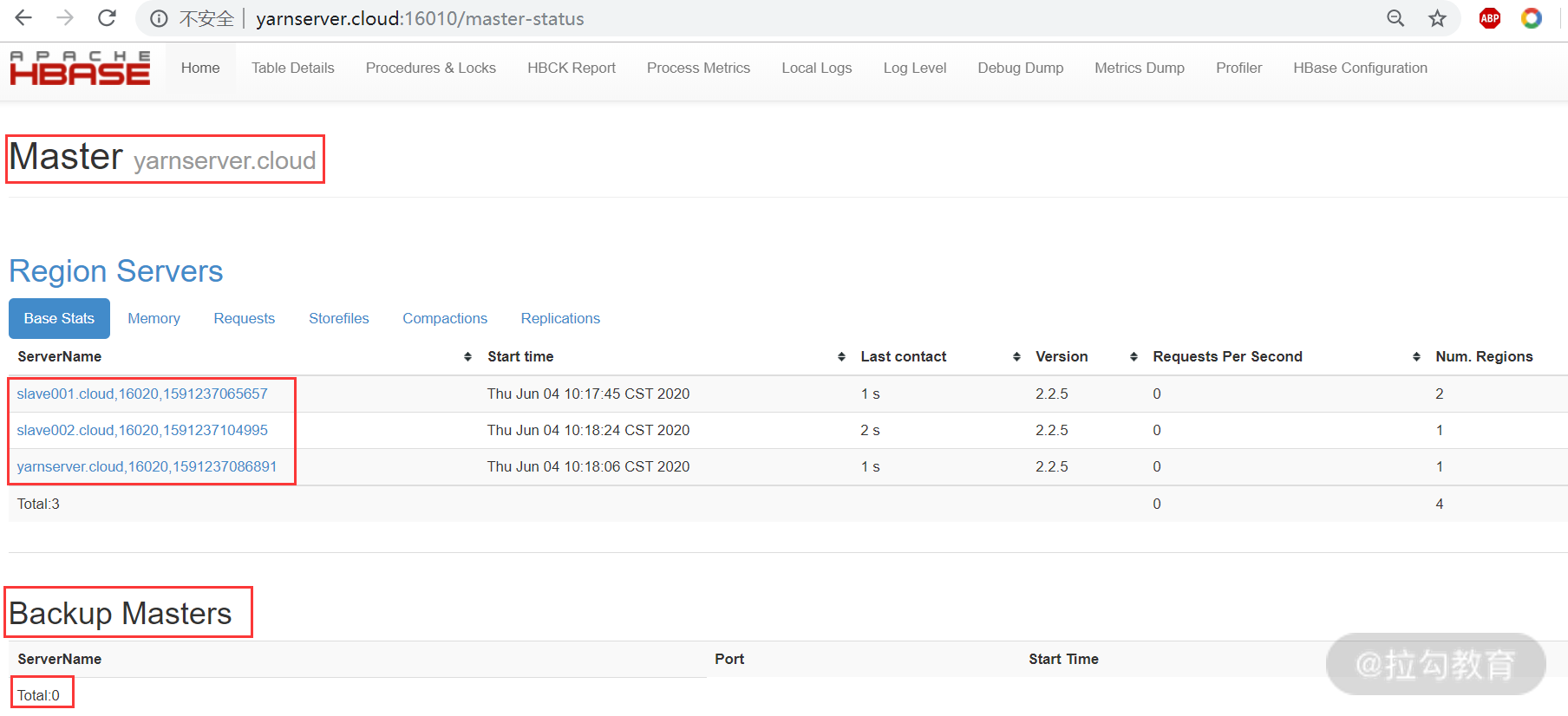
从图中可以看出,yarnserver.cloud 节点自动变成了主 HMaster,而没有 Backup Masters 节点了。当重新启动 nnmaster.cloud 节点的 HMaster 服务,此节点将变成 Backup Masters 节点。
总结
本课时主要讲解了 Spark 与 Yarn 的整合,以及 HBase 与 Hadoop 集群的整合应用,作为 Hadoop 集群的外围组件,Spark、HBase 在企业的使用非常广泛。作为运维要熟练掌握这些外围组件和 Hadoop 的整合应用,并能够熟练处理整合过程中出现的各种问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号