[大数据运维]第12讲:Hadoop 分布式资源管理器 Yarn、MR 运行机制剖析
第12讲:Hadoop 分布式资源管理器 Yarn、MR 运行机制剖析
高俊峰(南非蚂蚁)
本课时主要剖析 Hadoop 分布式资源管理器 Yarn 和 MR 运行机制。
Yarn 的整体架构
Yarn 是 Hadoop2.x 版本提出的一种全新的资源管理架构,此架构不仅支持 MapReduce 计算,还方便管理,比如 HBase、Spark、Storm、Tez/Impala 等应用。这种新的架构设计能够使各种类型的计算引擎运行在 Hadoop 上面,并通过 Yarn 从系统层面进行统一的管理。也就是说,通过 Yarn 资源管理器,各种应用就可以互不干扰地运行在同一个 Hadoop 系统中了,来共享整个集群资源。
Yarn 的架构设计基于主从(Master-Slave)模式,主要由 ResourceManager(RM)和NodeManager(NM)两大部分组成。除此之外,还有 ApplicationMaster(AM)、Application Manager、Scheduler 及 Container 等组件辅助实现所有功能。
Yarn 的基本架构如下图所示:

Yarn 中的组件解读
Yarn 中有两大组件,即 ResourceManager(RM)和 NodeManager(NM),其中 ResourceManager 由 ApplicationManager 和 Scheduler 组成。当用户提交 job 或 application 到 Yarn 上时,还会出现一个 ApplicationMaster 组件,此组件是应用程序级别的,用来管理运行在 Yarn 上的应用程序。这些 job 或 application 最终是在一个或多个 Container 中运行,而 Container 的资源则是通过 NodeManager 来分配。
下面分别介绍一下这些组件的功能及应用场景。
1. ResourceManager(RM)
RM 是一个全局的资源管理器,集群里只有一个。它负责整个 Hadoop 系统的资源管理和分配,包括处理客户端请求、启动监控 ApplicationMaster、监控 NodeManager、资源的分配与调度等。它主要由两个组件构成,即调度器(Scheduler)和应用程序管理器 (ApplicationsManager,AsM)。
Scheduler 是一个集群资源调度器,根据集群的容量、队列等限制条件,将集群中的资源分配给各个正在运行的应用程序,以保障整个集群高效、合理地使用资源。
需要注意的是:Scheduler 是一个纯粹的资源调度器,它只负责调度 Containers,不用关心任何与具体应用程序相关的工作。例如,它不会监控或者跟踪应用的执行状态,也不会去重启因程序失败或者其他错误而运行失败的任务。调度器仅根据每个应用程序的资源需求进行合理分配,而资源分配的单位用 Container(容器)表示。Container 是一个动态资源分配单位,它将 CPU 和内存封装起来,从而限定每个任务使用的资源量。
在 Hadoop 中,Yarn 提供了多种直接可用的调度器,常用的 Scheduler 主要有两种,即 Capacity Scheduler 和 Fair Scheduler。第一个是基于容量的资源调度,而第二个是基于公平的资源调度,具体资源调度细节,我将在后面的课时中进行深入介绍。
ApplicationsManager 负责管理整个集群中所有的应用程序,包括应用程序的提交、与调度器协商资源、启动 ApplicationMaster、监控 ApplicationMaster 运行状态并在失败时重新启动它等。它的主要功能总结如下:
-
负责接收用户提交的任务请求,为应用分配第一个 Container,此 Container 用来运行 ApplicationMaster;
-
负责监控 ApplicationMaster 的状态,如果发现 ApplicationMaster 失败,会自动重启 ApplicationMaster 运行的 Container。
从这里可以看出,Container 是最底层的计算单元,所有应用程序都是在 Container 中执行计算任务的。
2. ApplicationMaster
当用户提交一个分析任务时,ApplicationMaster 进程首先启动。接着,它向 ResourceManager 申请资源并和 NodeManager 协同工作来运行此任务;同时,它还会跟踪监视任务的执行状态。当遇到失败的任务时自动重启它;当任务执行完成后,ApplicationMaster 会关闭自己并释放自己的容器。
可以看出,ApplicationMaster 就像一个全职保姆,它负责任务执行的始末,全程保障任务的执行效果。
总体来说,ApplicationMaster 执行过程是按照如下顺序进行的:
(1)ApplicationMaster 切分数据,对任务进行分片;
(2)ApplicationMaster 向 ResourceManager 申请资源,然后把申请下来的资源交给 NodeManager;
(3)监控任务的运行,并对错误任务进行重启;
(4)通过 NodeManager 监视任务的执行和资源使用情况。
3. NodeManager
NodeManager 进程运行在集群中的多个计算节点上,与 HDFS 分布式文件系统中 Datande 的角色类似,每个计算节点都运行一个 NodeManager 服务。
NodeManager 负责每个节点上资源(CPU 和内存)的使用,它主要实现如下功能:
-
接收并处理来自 ApplicationMaster 的 Container 启动、停止等请求;
-
NodeManager 管理着本节点上 Container 的使用(Container 的分配、启动、停止等操作);
-
NodeManager 定时向 ResourceManager 汇报本节点上的资源使用情况以及各个 Container 的运行状态(CPU 和内存等资源)。
需要注意的是:NodeManager 只负责管理自身的 Container,不会去关注 Container 中运行的任务。
4. Container
Container 是 Yarn 资源管理器中最底层的计算单元,是执行计算任务的基本单位,比如 Map task、Reduce task 都在 Container 中执行。
一个节点根据资源的不同,可以运行多个 Container,一个 Container 就是一组分配的系统资源。现阶段 Container 的系统资源只包含 CPU 和内存两种,未来可能会增加磁盘、网络等资源。
在 Yarn 中,ApplicationMaster 会跟 ResourceManager 申请系统资源,而 ResourceManager 只会告诉 ApplicationMaster 哪些 Containers 可以用。若要使用这些资源,ApplicationMaster 还需要去找 NodeManager 请求分配具体的 Container。任何一个 job 或 application 最终都是在一个或多个 Container 中完成分析计算任务的。
Yarn 应用提交过程分析
当用户向 Yarn 提交一个请求时,Yarn 会执行一系列动作来响应用户的请求,那么 Yarn 具体执行了哪些动作呢?如下图所示:
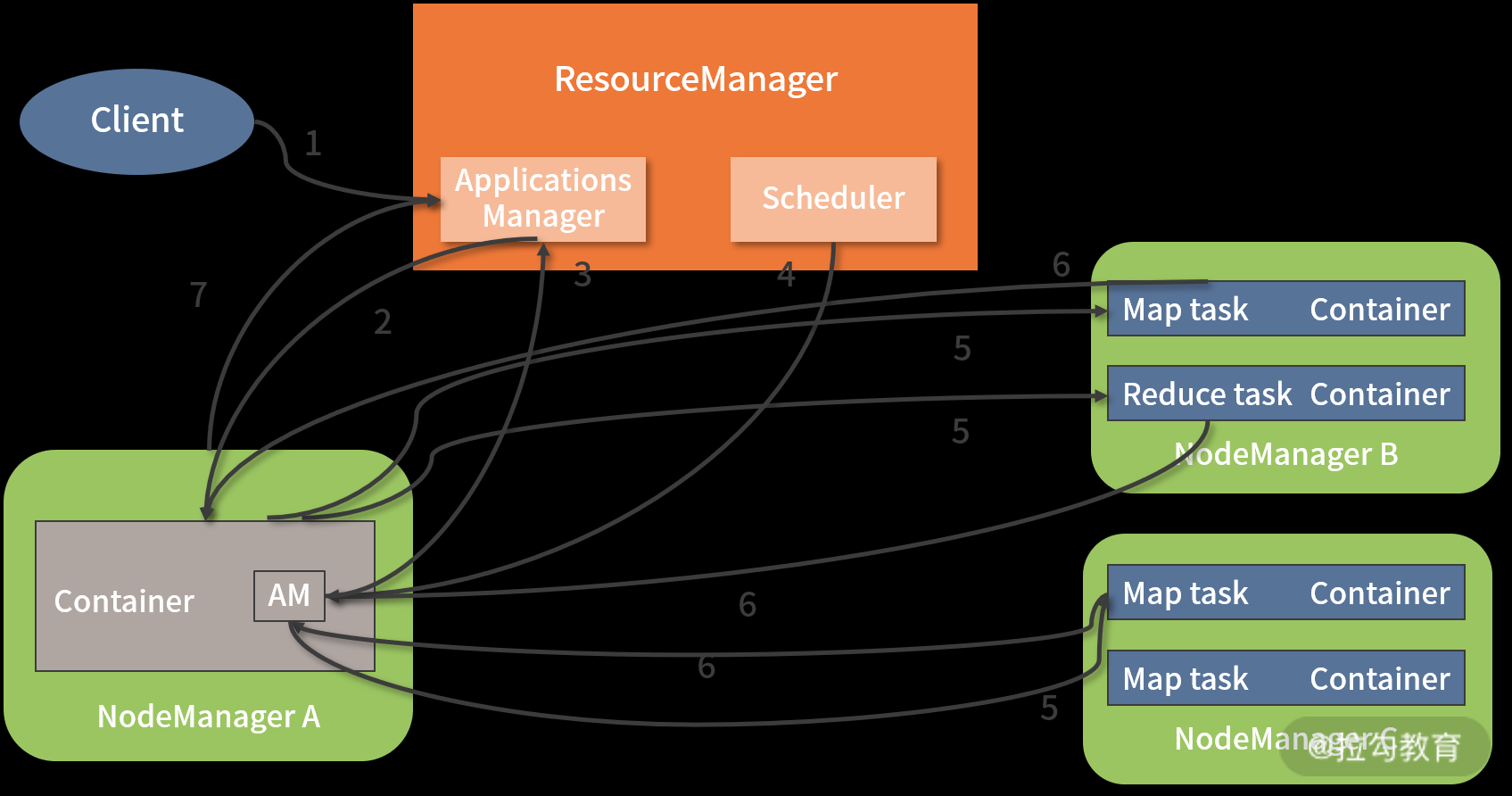
上图展示了用户提交一个应用程序到 Yarn 集群时,ResourceManager、Scheduler、Applicationmanager、ApplicationMaster、NodeManager 和容器如何相互交互的过程。
对上图过程的 7 个步骤分析如下:
(1)Client 向 Yarn 提交一个应用程序,接着 ResourceManager 就会响应用户的请求;
(2)ResourceManager 开启一个 Container,在 Container 中运行一个 ApplicationManager,然后 ApplicationManager 为该应用分配第一个 Container,并选取一个 NodeManager 进行通信,并要求此 NodeManager 在这个 Container 中启动应用程序的 ApplicationMaster;
(3)ApplicationMaster 向 ResourceManager 注册,并向 ResourceManager 申请运行应用程序所需的系统资源;
(4)Scheduler 将资源封装好发送给 ApplicationMaster;
(5)ApplicationMaster 申请到资源后,便与对应的 NodeManager 通信,要求它启动 Container,各个 NodeManager 分配完成资源后,就开始在 Container 中执行 Map task、Reduce task 等具体任务;
(6)各个任务通过 RPC 协议向 ApplicationMaster 汇报自己的状态和进度,以此方式让ApplicationMaster 随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
(7)ApplicationMaster 将任务执行结果返回给 ApplicationManager,并在应用程序运行完成后向 ApplicationManager 注销并关闭自己。
Yarn 中 shell 的使用
Yarn 中 shell 的使用与 HDFS 中的 shell 类似,Yarn 中也提供了一些 shell 命令(注意是 Yarn 命令),通过这些命令可以对 job 或 application 进行管理,还可以查看节点状态、队列状态、分析任务日志、重载刷新 Yarn 配置等。下面依次介绍。
1. Yarn application 管理命令
通过 Yarn application 可以对运行的任务进行状态查看、关闭 application 或启动 application 等操作,看下图这个例子:

由上图可知,目前 Yarn 集群有三个 application 正在运行,application 的类型、名称、ID、用户、队列、状态、进度等都显示的很清楚,要查看某个 application 的状态信息,可执行如下命令:
[hdfs@Yarnserver ~]$ Yarn application -status application_1578297910271_66111
Application-Id : application_1578297910271_66111
Application-Name : Spark shell
Application-Type : SPARK
User : vbs1
Queue : root.vbs
Application Priority : 0
Start-Time : 1589181370705
Finish-Time : 0
Progress : 10%
State : RUNNING
Final-State : UNDEFINED
Tracking-URL : http://Hadoopgateway:4041
RPC Port : 0
AM Host : 172.16.21.8
Aggregate Resource Allocation : 671814190 MB-seconds, 282004 vcore-seconds
Aggregate Resource Preempted : 0 MB-seconds, 0 vcore-seconds
Log Aggregation Status : NOT_START
Diagnostics :
Unmanaged Application : false
Application Node Label Expression : <Not set>
AM container Node Label Expression : <Not set>
TimeoutType : LIFETIME ExpiryTime : UNLIMITED RemainingTime : -1seconds
从这个输出,可以发现,此 application 的所有状态信息,例如,AM 所在节点、应用程序分配的聚合内存量以及分配的聚合 vcores 数。其中,MB-seconds 是应用程序分配的聚合内存量(以兆字节为单位)乘以应用程序运行的秒数得到的结果,而 vcore-seconds 是应用程序分配的聚合 vcores 数乘以应用程序运行的秒数得到的结果。
如果发现某个 application 占用大量集群资源,可以通过命令方式把它 kill 掉,kill 方式如下:
[hdfs@Yarnserver ~]$ Yarn application -kill application_1578297910271_66111
kill 掉这个 application 后,它占用的资源也就释放了。要获取应用程序尝试的列表,可执行如下命令:
[hdfs@Yarnserver ~]$ Yarn applicationattempt -list application_1578297910271_66111
ApplicationAttempt-Id State AM-Container-Id Tracking-URL
appattempt_1578297910271_66111_000001 RUNNING container_e55_1578297910271_66111_01_000001 http://Yarnserver:8088/proxy/application_1578297910271_66111/
从上图可以找到 application 下面的 container,接着看这个 container 的状态,执行如下图所示命令:

从这个输出可以看到 container 的启动时间、运行状态、所在主机及端口等。
2. Yarn node 命令
Yarn node 可以获取集群节点状态,执行如下命令,查看集群活跃节点:
[Hadoop@Yarnserver ~]$ Yarn node -list
2020-05-12 10:12:59,133 INFO client.RMProxy: Connecting to ResourceManager at Yarnserver/172.16.213.41:8032
Total Nodes:3
Node-Id Node-State Node-Http-Address Number-of-Running-Containers
slave003:45117 RUNNING slave003:8042 0
slave001:43761 RUNNING slave001:8042 0
slave002:36604 RUNNING slave002:8042 0
Yarn node 也可以单独查看某个节点状态,执行如下命令:
[Hadoop@Yarnserver ~]$ Yarn node -status slave003:45117
2020-05-12 10:13:39,097 INFO client.RMProxy: Connecting to ResourceManager at Yarnserver/172.16.213.41:8032
2020-05-12 10:13:39,688 INFO conf.Configuration: resource-types.xml not found
2020-05-12 10:13:39,688 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
Node Report :
Node-Id : slave003:45117
Rack : /default-rack
Node-State : RUNNING
Node-Http-Address : slave003:8042
Last-Health-Update : 星期二 12/五月/20 10:12:01:69CST
Health-Report :
Containers : 0
Memory-Used : 0MB
Memory-Capacity : 20480MB
CPU-Used : 0 vcores
CPU-Capacity : 8 vcores
Node-Labels :
Node Attributes :
Resource Utilization by Node : PMem:5587 MB, VMem:7094 MB, VCores:0.0066644456
Resource Utilization by Containers : PMem:0 MB, VMem:0 MB, VCores:0.0
从这个输出可以看出此节点的运行状态、运行的 Containers 数、内存占用、内存总量、CPU 占用、CPU 总量等信息。
3. Yarn queue 命令
通过 Yarn queue 命令可以查看 Yarn 集群中的队列资源信息,看下面操作输出:
[hdfs@Yarnserver ~]$ Yarn queue -status dev
Queue Information :
Queue Name : dev
State : RUNNING
Capacity : 21.5%
Current Capacity : 31.1%
Maximum Capacity : -100.0%
Default Node Label expression : <DEFAULT_PARTITION>
Accessible Node Labels :
这个输出的是 dev 队列的状态。可以看到,dev 队列占用集群总容量的 21.5%,目前已经使用的容量是 31.1%。注意,31.1% 是针对 21.5% 容量来说的,假如集群总容量的 21.5% 是 100GB,那么目前已经使用了 31.1GB。Maximum Capacity 是 Capacity Scheduler 调度策略的参数,在这里无效,此队列我使用的是 Fair Scheduler 调度。
4. Yarn rmadmin 命令
Yarn rmadmin 是 Yarn 中的管理类命令,如果对资源队列做了修改,或者新增了计算节点,或修改了 Yarn 配置文件,那么要在不重启 Yarn 服务的前提下,可以通过 Yarn rmadmin 来刷新配置,使其立刻生效。
此命令常用的参数有如下几个:
-
-refreshQueues,重载队列的 ACL、状态和调度器等属性,ResourceManager 将重新加载 queues 配置文件;
-
-refreshNodes,用来刷新 dfs.hosts 和 dfs.hosts.exclude 配置文件,这种方式无须重启集群服务;
-
-refreshSuperUserGroupsConfiguration,刷新用户组的配置;
-
-refreshUserToGroupsMappings,刷新用户到组的映射配置;
-
-getGroups [username] ,获取指定用户所属的组。
看下面几个例子:
[Hadoop@Yarnserver ~]$ Yarn rmadmin -refreshQueues
[Hadoop@Yarnserver ~]$ Yarn rmadmin -refreshNodes
[Hadoop@Yarnserver ~]$ Yarn rmadmin -getGroups Hadoop
如果你修改了队列配置或者其他配置,可通过执行这些刷新命令,使其立刻生效,而无须重启集群服务。
5. Yarn logs 命令
Yarn logs 命令可以用来查询 application、container 的运行日志,看下面操作实例:
[Yarn@Yarnserver ~]$Yarn logs -applicationId application_1578297910271_66666
上面这个是查看 application_1578297910271_66666 的运行日志。要查看 application 下某个容器的运行日志,可执行如下命令:
[Yarn@Yarnserver ~]$Yarn logs -applicationId application_1578297910271_66666 -containerId container_e55_1578297910271_66666_01_000001
Yarn 下常用的 shell 命令还有很多,记住上面这些基础操作,对运维来说基本足够了,这些 shell 对于我们写监控脚本非常有帮助。例如,要监控队列资源状态,就可以利用 Yarn 下的 shell 写个监控脚本,当队列资源占用异常时进行告警。
总结
本课时主要讲解了分布式资源管理器 Yarn、MR 运行机制,以及 Yarn 相关的 shell 命令,对于 Yarn 资源运行机制的了解有助于对 Hadoop 集群进行调优和故障排查,这部分内容非常重要,要求我们能熟练掌握。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号