[大数据运维]第08讲:通过 Ambari 工具自动化构建 Hadoop 大数据平台和外围应用(下)
第08讲:通过 Ambari 工具自动化构建 Hadoop 大数据平台和外围应用(下)
高俊峰(南非蚂蚁)
3. 通过 Ambari 安装 HBase、Hive 等外围应用
除了一些基础的 Hadoop 应用组件,在企业实际应用中还会集成一些其他生态组件,这些组件可以减少开发工作量,提高工作效率,最常用的就是 Hive 这个外围组件。目前 Hive 已成了很多企业的应用标配。
Hive 发展到现在,为了迎合多种计算引擎,也出现了多种运行模式,最早出现的是 Hive on MapReduce,这种运行模式主要用于离线计算。此外,还有 Hive on Tez、Hive on Spark 两种运行模式。
Tez 是一个构建于 Yarn 之上,且支持复杂的 DAG 任务的数据处理框架,它通过将 MapReduce 的过程进行拆分和组合,减少了 MapReduce 之间的文件存储,从而大幅提升了 MapReduce 作业的性能。因此使用 Hive on Tez 可以大幅提高任务分析性能。
Hive on Spark 是把 Spark 作为 Hive 的一个计算引擎,将 Hive 的查询作为 Spark 的任务提交到 Spark 集群上进行计算。说的通俗点,就是大家已经习惯使用 Hive 了,那么如果让 Hive 也能支持 Spark,这样用户也就很容易接受 Spark 了,所以 Hive on Spark 这种模式就产生了。
要在现有集群中添加外围服务,可在 Ambari 主界面点击左侧导航栏 Services 项,然后再选择“ADD Services”选项,如下图所示:
接着,会显示可以添加哪些服务,如下图所示:
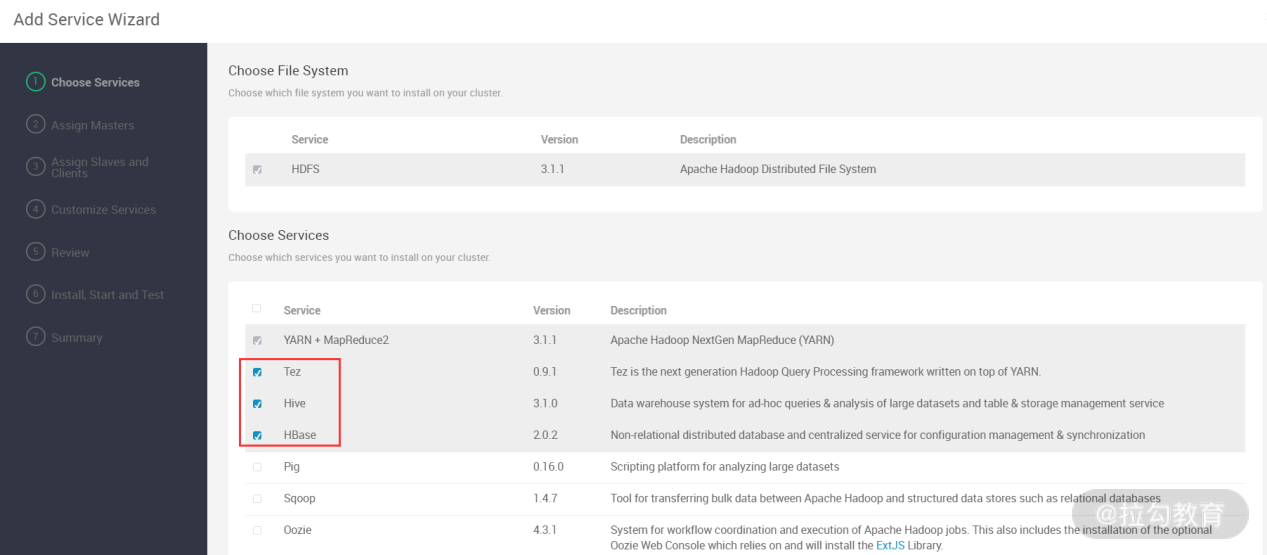
此步骤选择了 Hive、Tez 及 HBase 服务,然后点击“下一步”按钮,如下图所示:
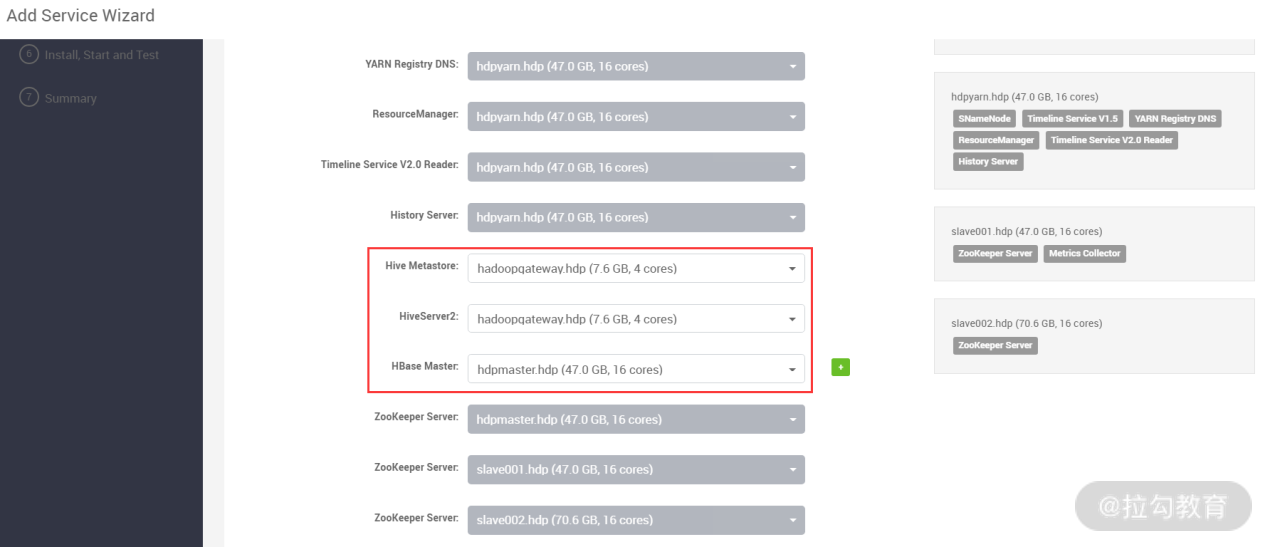
此步骤是选择每个服务安装到哪个主机节点上,一般情况下建议将 Hive 服务(HiveServer2 和 Hive Metastore)安装到外围机上,Hbase Master 服务安装到一个独立的节点,也可以跟其他服务共用一台主机。
配置完成,即可进入下一步,如下图所示:
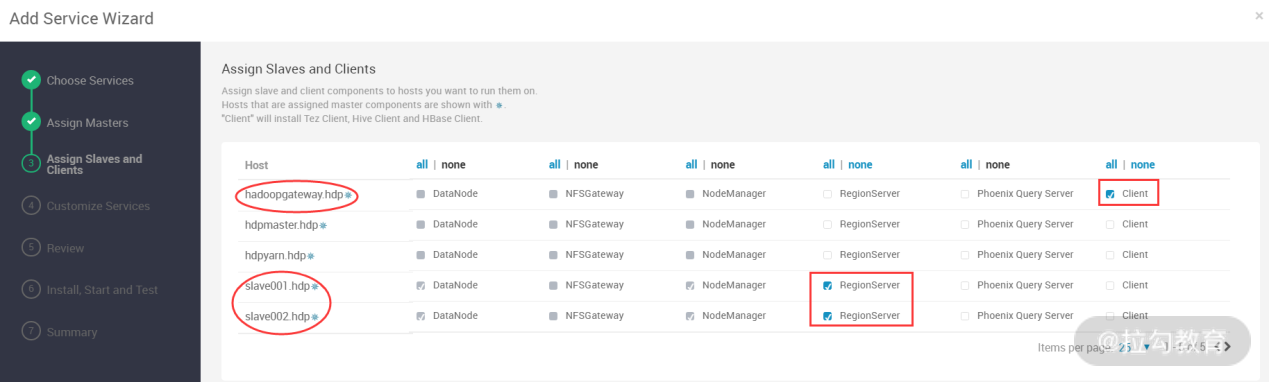
此步骤是配置安装的服务对应 slave 角色。例如,上面选择了 HBase 服务,那么对应的 slave 服务就是 ReginServer,这里选择 slave001 和 slave002 主机提供的 ReginServer 服务。在实际的生产环境中,建议将 ReginServer 服务和 nodemanager 服务分开,如果放在一起,在满负荷状态下,可能出现资源争抢或者资源不足的情况。最后,还需要安装一个 Client 服务到 hadoopgateway.hdp 主机,这个 Client 其实就是 hbase client。
配置完成,即可进入下一步,在这个步骤中,主要是对新安装的服务进行一些参数的配置或修改,大部分保持默认即可,但需要对 Hive 要连接的数据库进行配置,如下图所示:
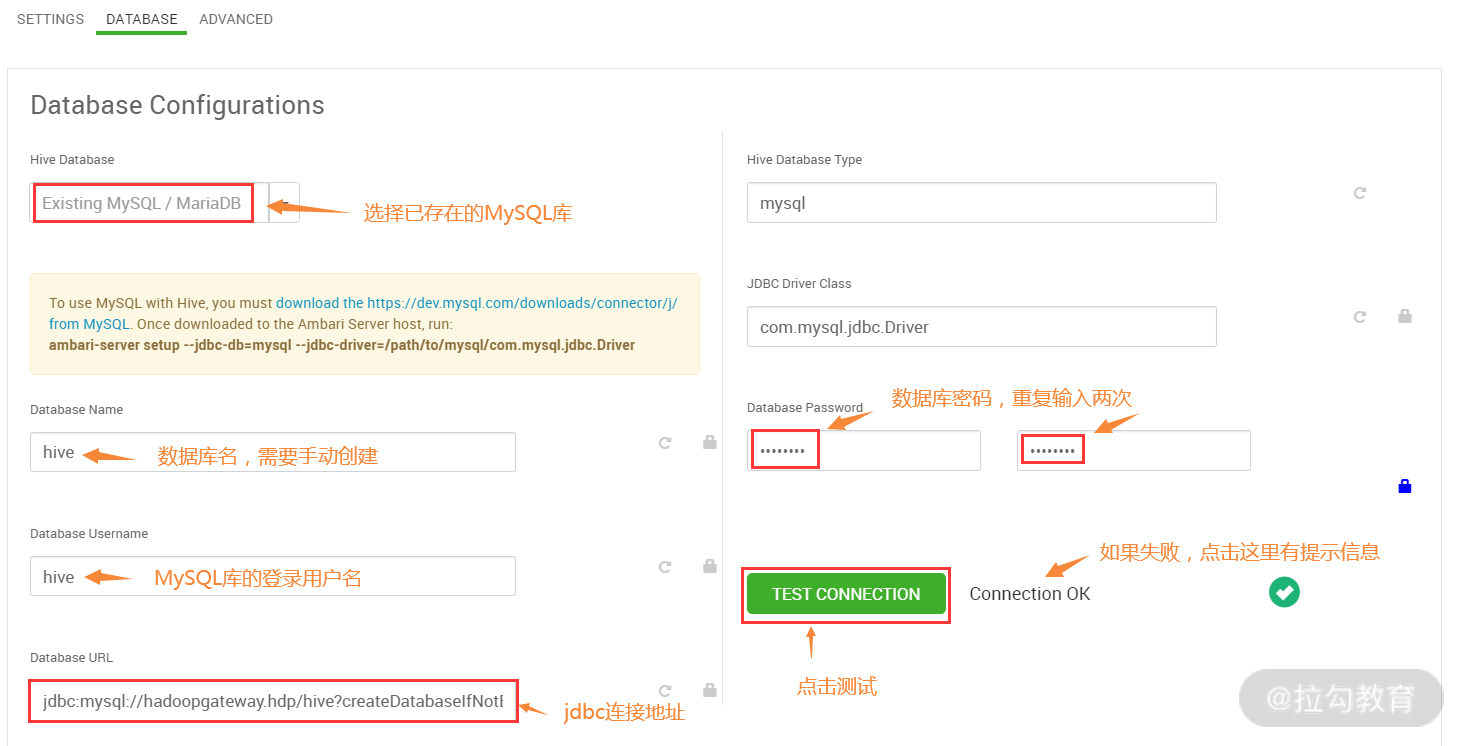
因为 Hive 会将元数据信息存到数据库中,所以需要配置一个数据库,这里我选择了已存在的 MySQL 数据库,版本为 MySQL5.7.29。接着就是配置数据库的库名、连接用户名、连接地址及密码,这些信息需要提前在 MySQL 中配置完成。MySQL 库可以使用 Ambari,也可以在一台独立的主机上安装 MySQL,建议将 MySQL 安装到外围机上。数据库准备好以后,执行如下 SQL 创建 Hive 数据库:
mysql> create database hive character set utf8;
mysql> CREATE USER 'hive'@'172.16.213.%' IDENTIFIED BY ' Hive-321';
mysql> GRANT ALL PRIVILEGES ON hive.* TO 'hive'@'172.16.213.%';
mysql> CREATE USER 'hive'@'localhost' IDENTIFIED BY 'Hive-321';
mysql> GRANT ALL PRIVILEGES ON hive.* TO 'hive'@'localhost';
mysql> FLUSH PRIVILEGES;
数据库配置完成后,可以点击上图的测试连接按钮,检查是否能够连接上 MySQL,如果连接失败,则可以根据失败提示检查失败原因。大部分无法连接 MySQL 的原因是由于 Ambari 没有成功加载 MySQL 的 JDBC 驱动包,若要加载,在 Ambari 主机上执行如下命令:
[root@ambari-server ~]#ambari-server setup --jdbc-db=mysql --jdbc-driver=/usr/share/java/mysql-connector-java.jar
其中,mysql-connector-java.jar 就是这个 JDBC 驱动包,若要找到 jar 包,则需要在系统中安装 mysql-connector-java 这个 rpm 包。
Hive 能够连通 MySQL 后,就可以进入下一步了,在点击“下一步”按钮时,可能会出现如下图所示的警告提示:
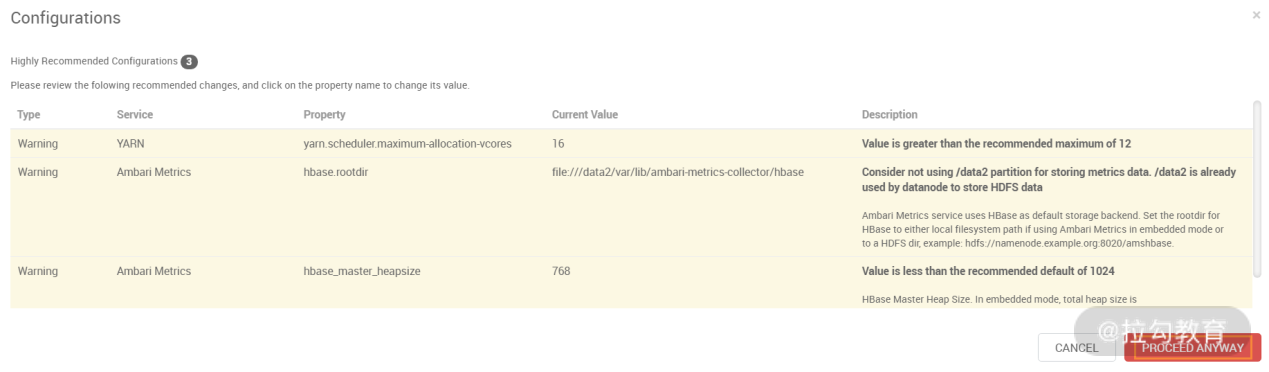
这个警告是因为可能某些参数设置不满足 Ambari 的配置要求,但也有一些情况是误报。比如上图中提示 hbase.rootdir 设置路径不对,而这个路径我已经做过修改了,猜测可能是一个 bug。所以,在这个步骤中如果仅仅是警告提示的话,则可以直接选择“PROCEED ANYWAY”选项跳过即可。
接下来就进入安装阶段了,如下图所示:
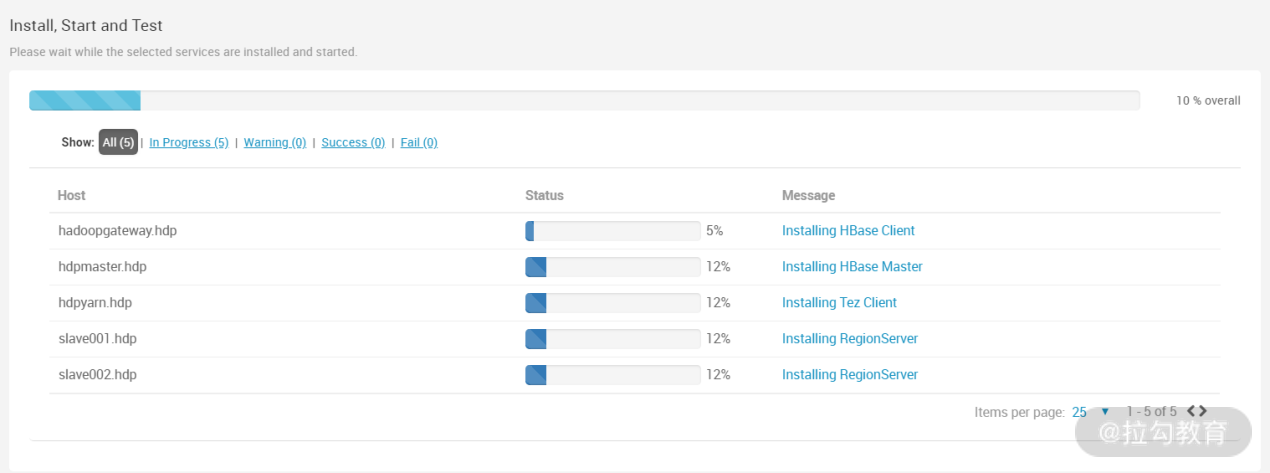
整个安装过程大概需要几分钟就能完成,如果出现错误,根据错误提示排错即可,安装完成后,安装向导会提示重启一些服务,为什么需要重启服务呢?这是因为有新的服务加到集群中,为了使集群其他服务能够识别新的服务,所以需要重启一下之前已安装的服务,如何重启呢?参看下图:
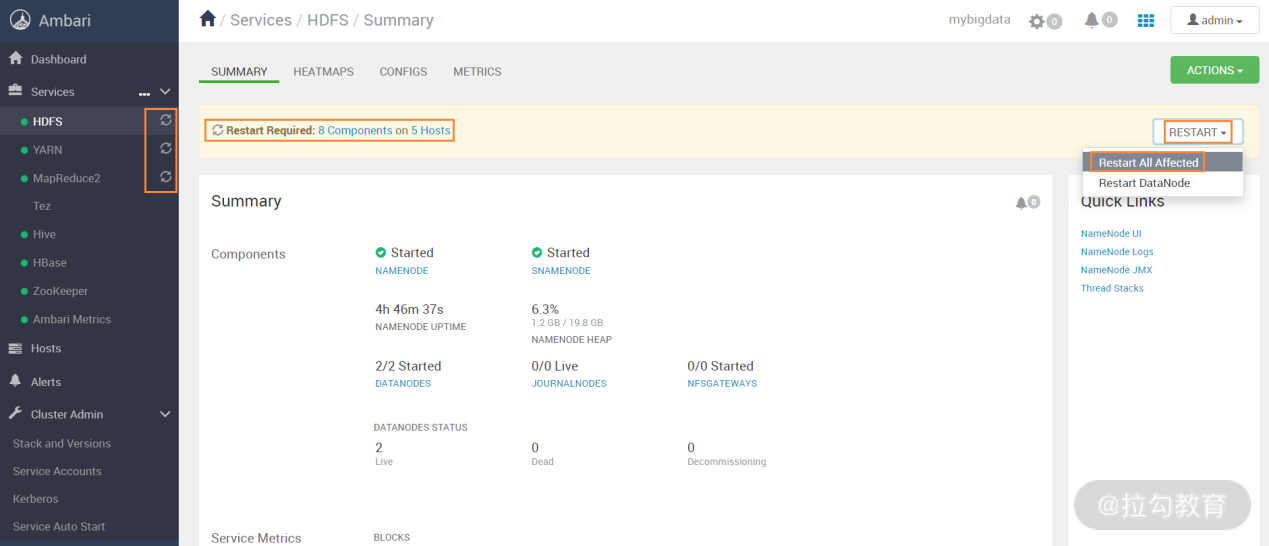
在上图中选择右上角的“Restart All Affected”即可重启所有需要重启的服务。
4. 通过 Ambari 快速构建 Spark on Yarn 集群
在上面,我已经讲述了如何在 Ambari 中添加 Hive、Tez、HBase 等服务,如果要使用 Spark 计算框架,那么将 Spark 添加到 Ambari 的方法与上面服务完全相同,简单介绍如下。
仍然在 Ambari 中选择添加服务,然后进入如下图所示的界面:
此步骤中,选择需要的 Spark2 服务即可,然后进入下一步,如下图所示:
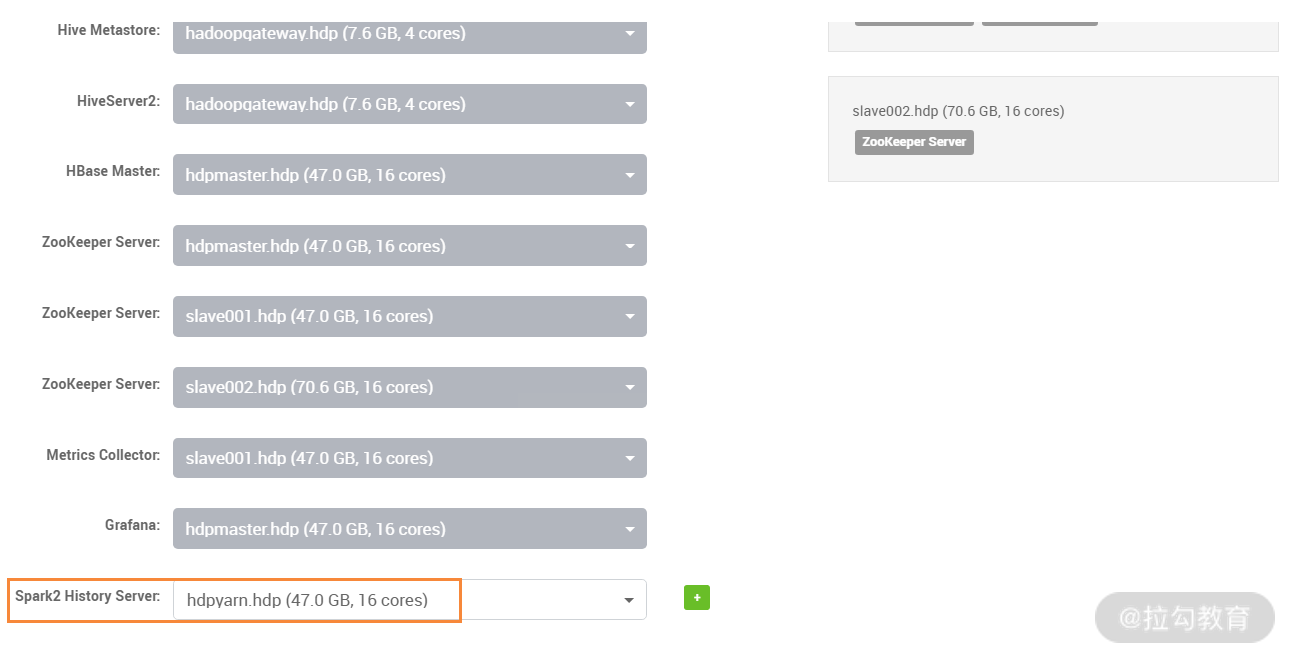
此步骤是设置 Spark2 History Server 服务运行在哪个主机上,这里选择 hdpyarn.hdp 主机,然后进入下一步,如下图所示:
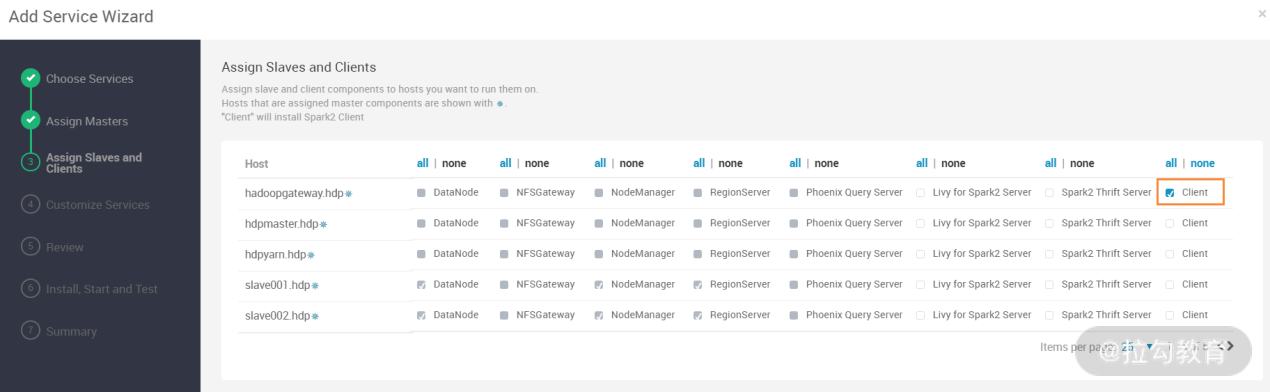
此步骤中,只需要安装一个 Spark Client 到 hadoopgateway.hdp 主机即可,无须选择其他服务,然后进入下一步,如下图所示:
此步骤用来配置 spark 参数,点击上图中的高级,然后找到“Advanced spark2-hive-site-override”项,点开此项的配置参数,修改“metastore.catalog.default”一项内容为 hive,如下图所示:
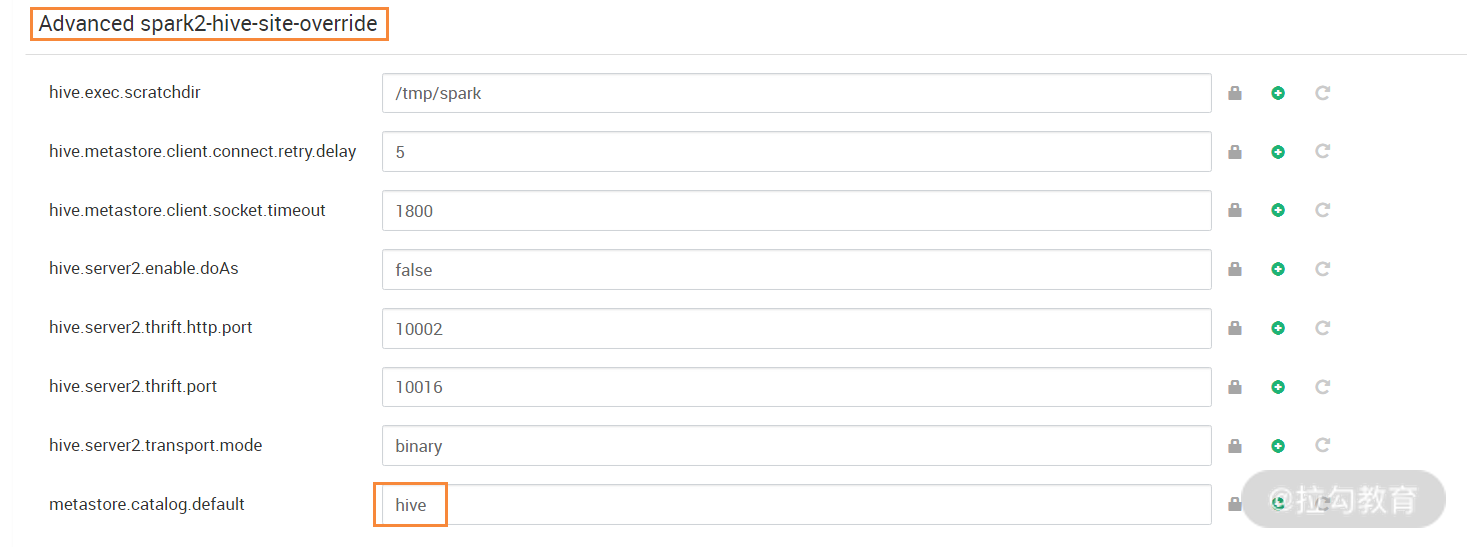
此值默认是 spark,表示读取 SparkSQL 自己的 metastore 库,修改完后,SparkSQL 会去读取 Hive 的 metastore 库,这样就可以实现 SparkSQL 来处理 Hive 的表数据。修改完成后,然后进入下一步,如下图所示:
此步骤是进行 Spark2 服务的安装和配置过程,Spark 服务安装完成后,也需要重新启动之前的某些服务,以让集群识别新部署的 Spark 服务。
利用 Ambari 管理 Hadoop 集群
Ambari 的强大之处除了可以执行自动化安装、部署外,还可以管理 Hadoop 集群上的各个服务,下面来看一下如何管理集群服务。
1. 通过 Ambari 管理 Hadoop 集群中每个服务
在 Ambari 的 Web 页面中,左侧是 Services 列表,选择一个你想要操作的 Service。这里以 HDFS 为例,当点击 HDFS 服务后,就会看到该 Service 的相关信息,如下图所示:
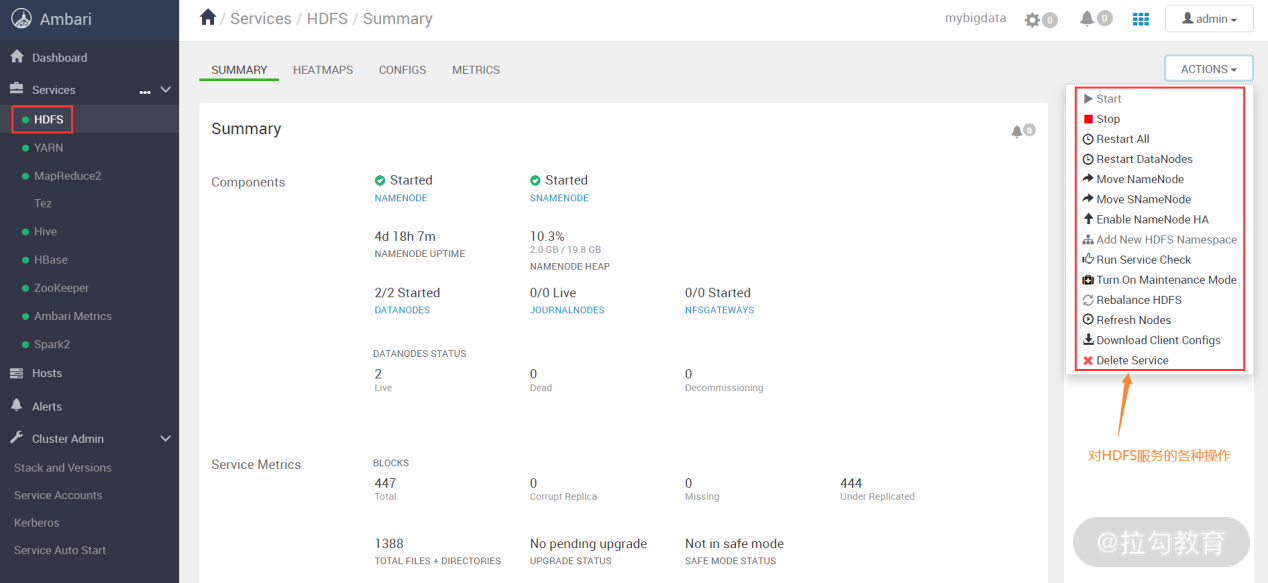
在上图右上角有个“ACTIONS”按钮,点开可以看到很多功能,可以对服务进行重启、关闭、删除等操作,还可以刷新集群节点、给 HDFS 做数据平衡、开启 Namenode HA 等多个功能。
如果要关闭服务,选择上图右上角中的 stop 选项即可,如下图所示:

点开上图“Stop HDFS”的链接,即可查看服务关闭详细日志信息,如下图所示:
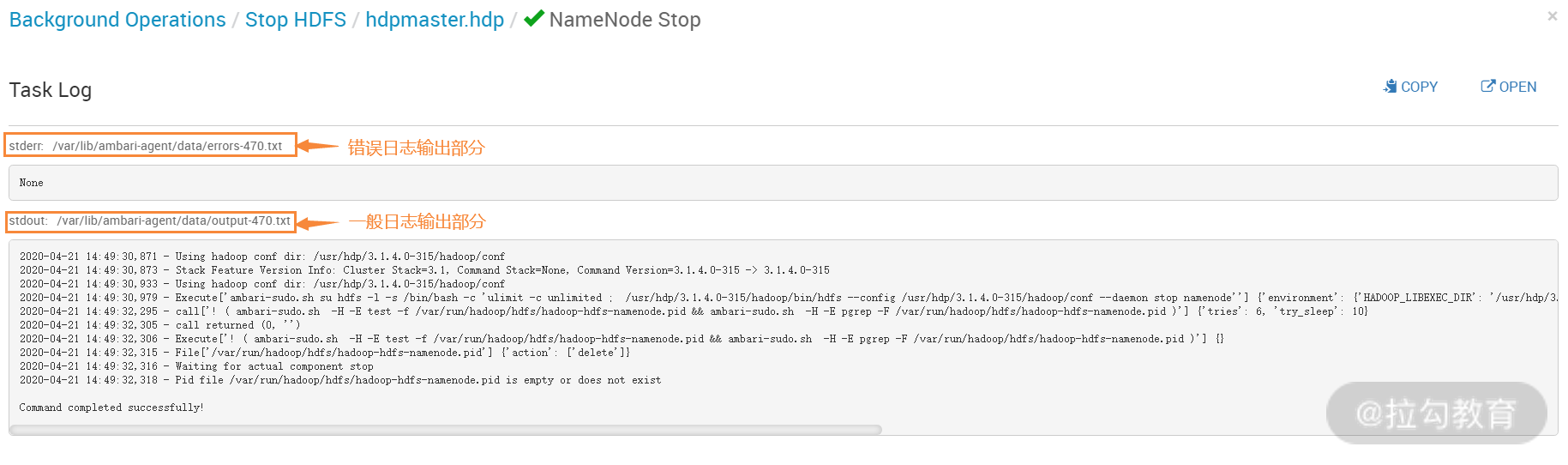
在上图这个输出中,第一部分输出的是错误信息,如果服务无法启动或关闭,则会给出详细的错误信息,我们可根据这个信息进行排错。下面一部分是一般日志输出,主要显示了服务关闭的整个过程。
从对 HDFS 服务启动、关闭中可以看出,Ambari 是对整个集群下该服务进行关闭或者启动的。例如,你要关闭 HDFS 服务,那么 Ambari 关闭的服务有 NameNode、SecondaryNamenode 和 DataNode,所以这里是对一组服务进行维护管理。
如果要对某个节点上某个单独的服务如何管理呢?首先,在 Ambari 的 Web 页面中,点击左侧 Hosts 列表,然后即可打开集群所有主机列表,如下图所示:
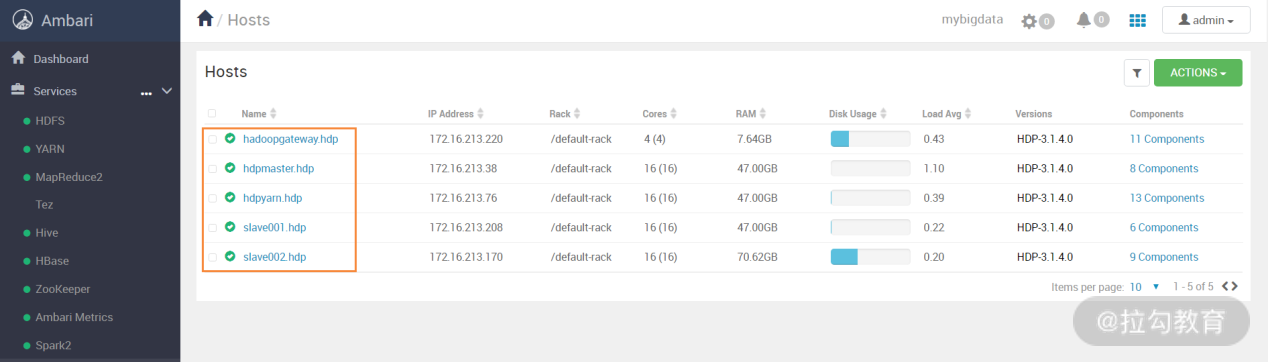
在上图右侧主机列表中,任意选择一个主机打开,出现如下图所示的界面:
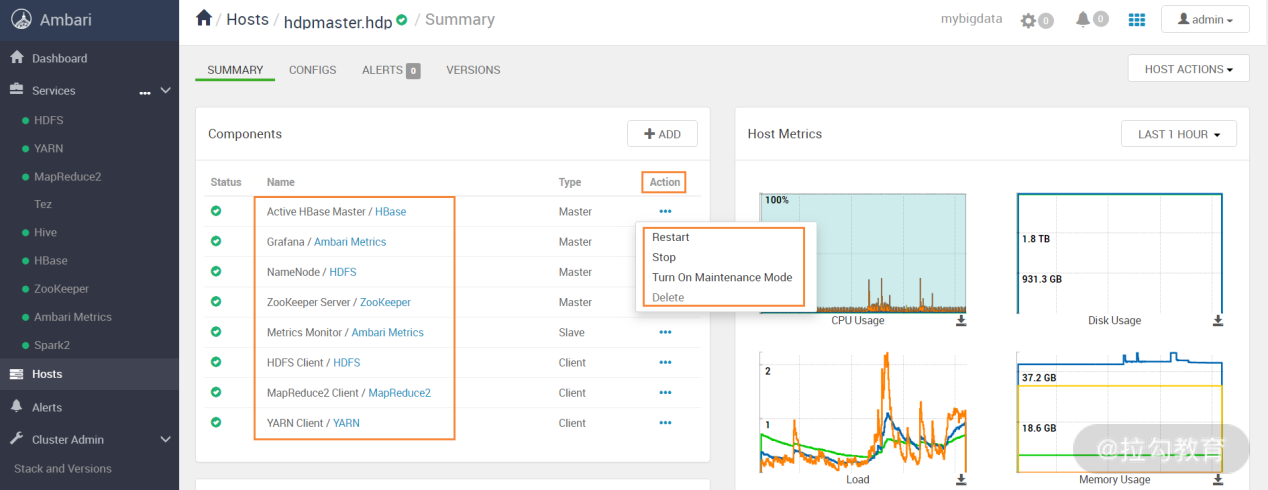
在这个界面中,展示了 hdpmaster.hdp 主机上安装的所有服务,以及服务的状态和类型。如果发现服务状态异常,可以在最后那个“Action”列选择动作,比如重启、关闭、删除等操作。这就实现了对某个主机下某个服务的管理维护操作。
除了可以单独管理主机上的服务,还可以在主机上添加某个服务,在上图页面中点击“ADD”按钮,出现下图界面:
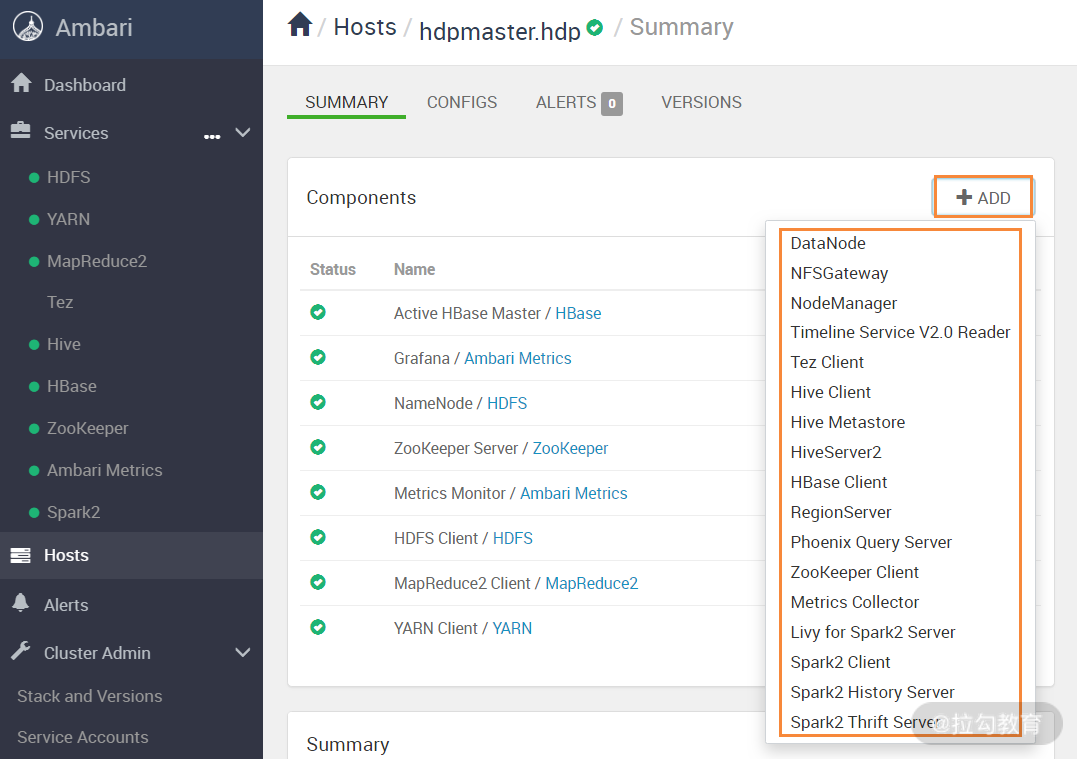
可以看到,可添加的服务有很多,点击需要的服务即可添加到本节点。
到目前为止,基于 HDP 的 Hadoop 集群已经部署成功了,那么如何测试是否部署正常呢,这可以通过 Ambari 提供的一个自动 check 功能。这里以 MapReduce2 为例,选择“Run Service Check”,如下图所示:
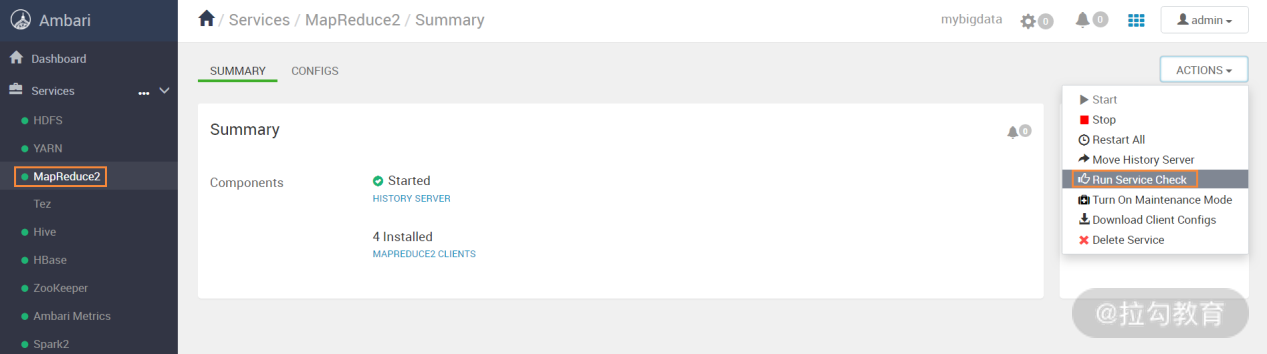
执行这个“Run Service Check”后,Ambari 会在后台运行一个经典的 MapReduce 的 Wordcount 实例,来检查 MapReduce 是不是正常,这从执行日志中可以看出,如下图所示:
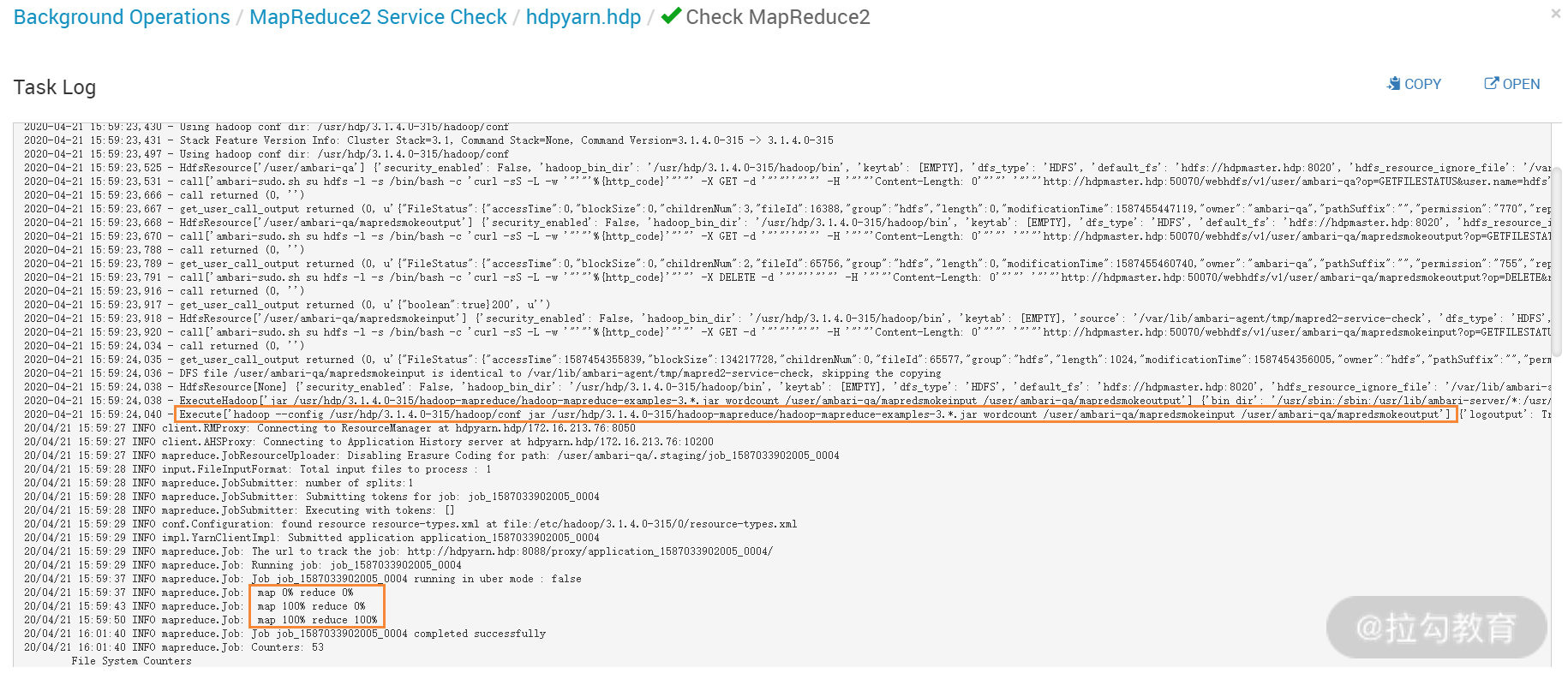
同理,如果要检查 HDFS 服务、Yarn 服务是否正常,都可以通过这种方式实现。
Ambari 实现了自动化运维管理,要对服务进行批量起、停管理时,可在 Ambari 的主机列表页完成,如下图所示:
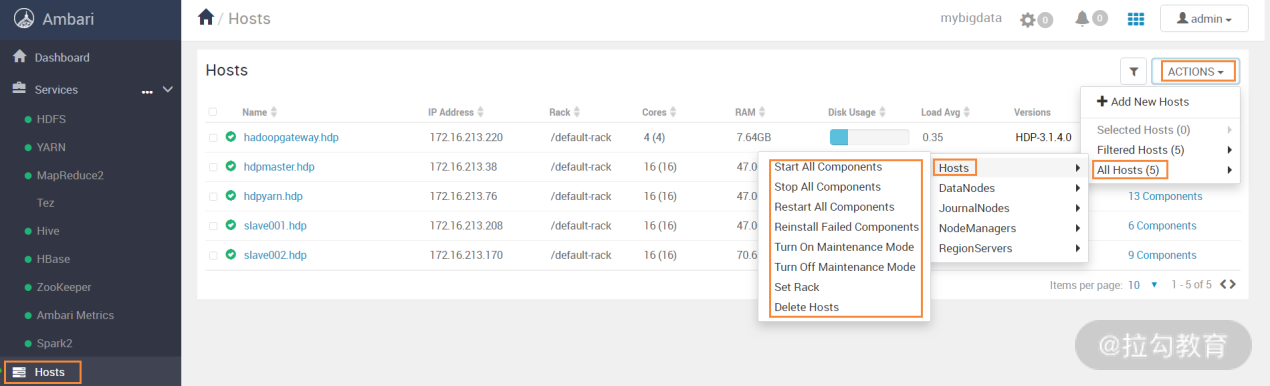
这个界面是对集群所有主机执行所有服务启动、停止、重启等操作,要针对某个服务执行批量管理时,可选择对应的服务名即可,如下图所示:
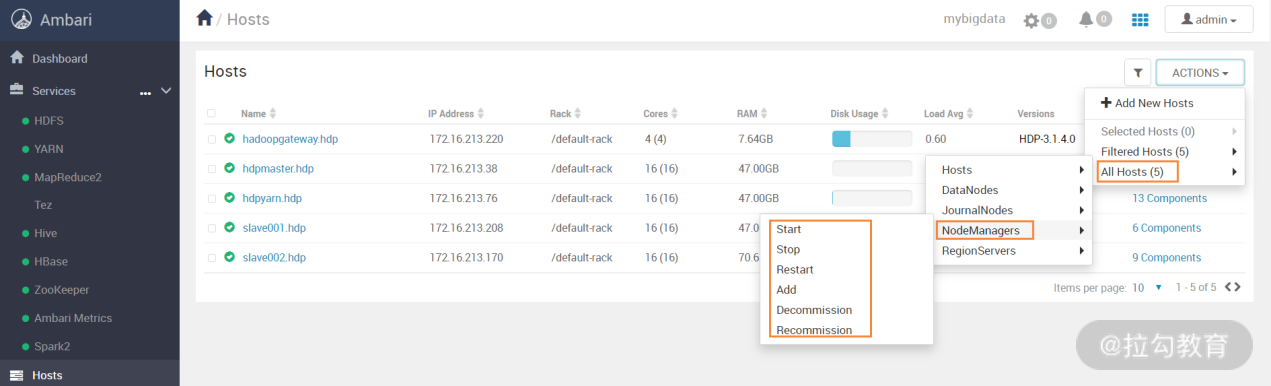
这个界面是对集群下所有节点的 NodeManagers 服务进行批量维护操作,其他服务的维护方法也类似。
2. 在 Ambari 中修改 Hadoop 配置文件及故障告警的实现
在 Hadoop 运维中,对于配置文件的修改是家常便饭,而 Ambari 也提供了批量修改配置文件的功能,它提供了各个组件配置文件修改接口。这里以修改 Yarn 服务的配置为例,打开 Ambari 的 Web 界面,然后选择 Yarn 服务,找到“CONFIGS”一项,如下图所示:
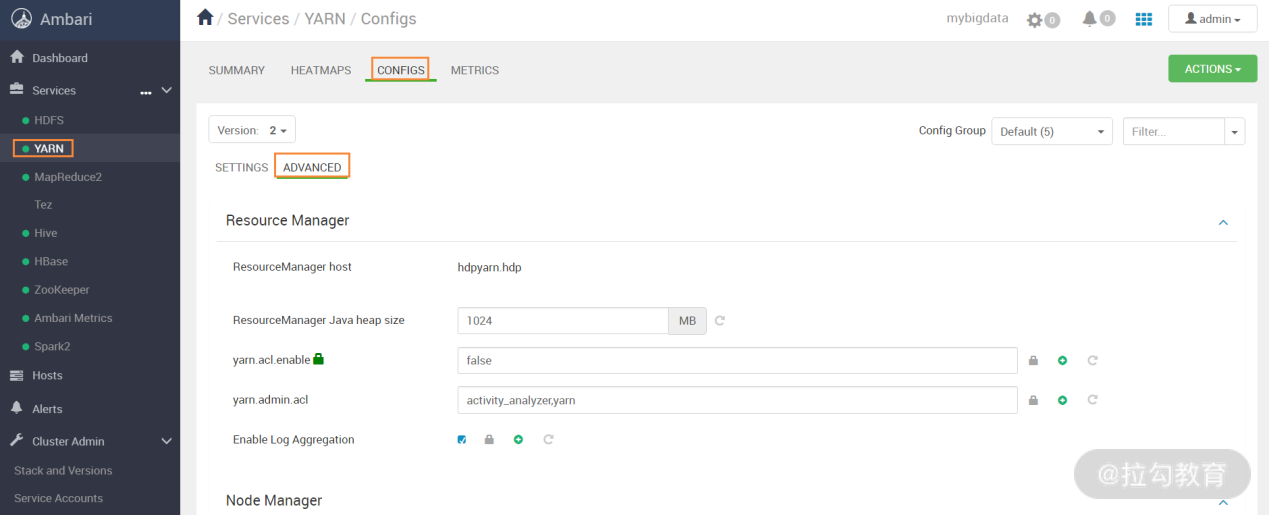
在这个界面中,打开“ADVANCED”一项,就可以修改 Yarn 中的每个配置项了,可以看到,Ambari 将 Yarn 中的不同服务进行了分类配置,每个分类配置中都列出了常见的配置参数,如果没有你需要的配置参数,还可以自己定制需要的配置参数。参数修改完成后,根据提示,还需要重启相应的服务以使配置生效。
Ambari 将修改后的配置参数值存入数据库,然后批量更新配置到每个 Hadoop 节点,始终保证每个节点配置参数的一致性。
Ambari 为了帮助用户实现故障监控以及问题定位,集成了告警(Alert)机制。在 Ambari 中默认定义了很多的告警,用来监测 Hadoop 集群的各个服务模块以及集群节点的状态。
在 Ambari 的 Web 界面中,点击左侧导航中的“Alerts”,即可打开告警配置页面,如下图所示:
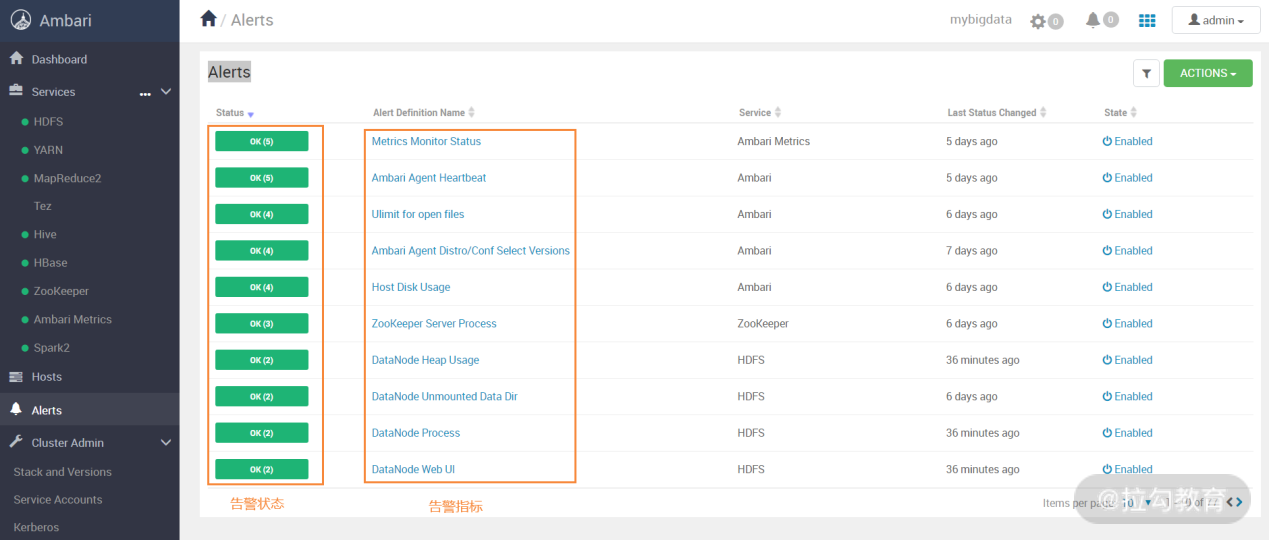
在上图界面中,可以看到每个监控指标的状态,绿色表示正常,如果出现故障,会显示红色。点击右上角“ACTIONS”按键,然后选择下面的“Manage Alert Groups”,即可进入如下图所示的界面:
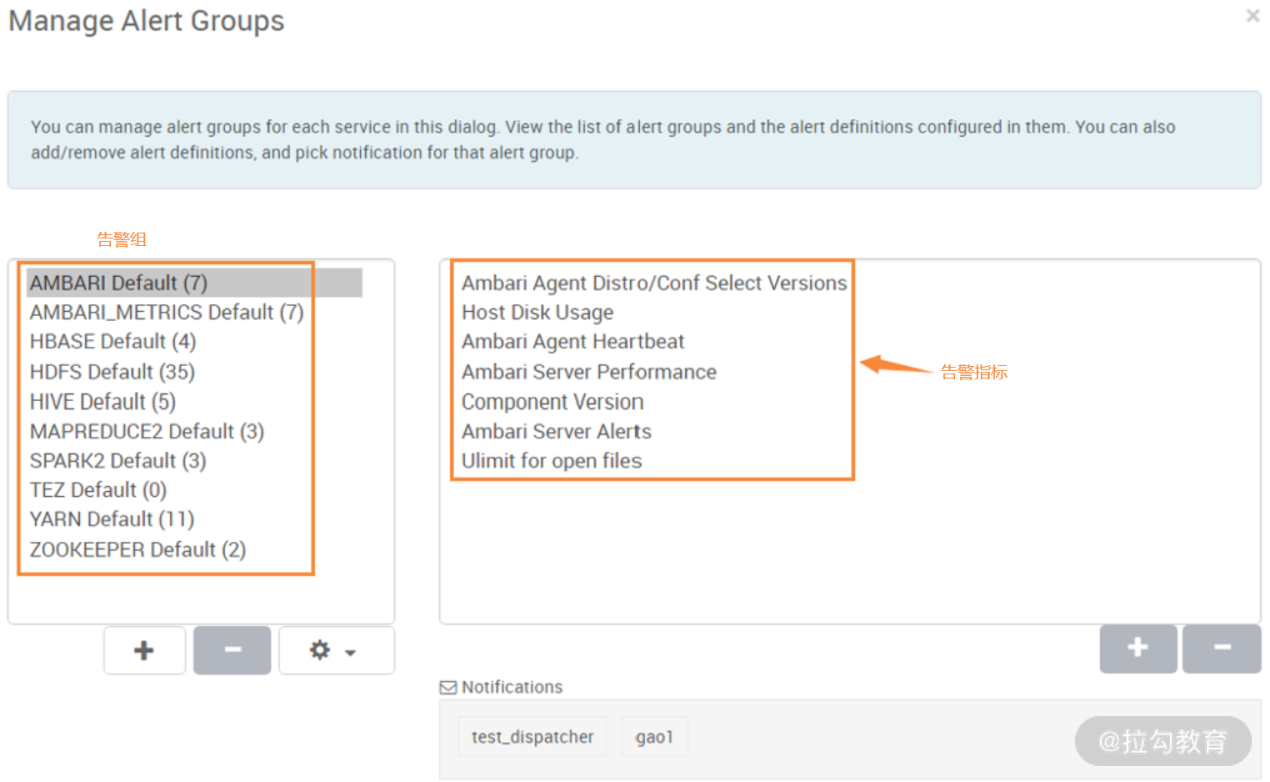
在上图中,左侧是默认定义好的告警组,可以看到,Ambari 告警基本覆盖了所有的模块和服务。选中其中一个告警组,右边会出现此分类下的多个告警指标,每个告警指标都定义了告警的检测时间间隔(Interval)、类型(Type)、阈值(Threshold)等,这些属性是可以修改的,由于定义的告警很多,你可以用过滤器筛选想要查找的告警,如下图所示:
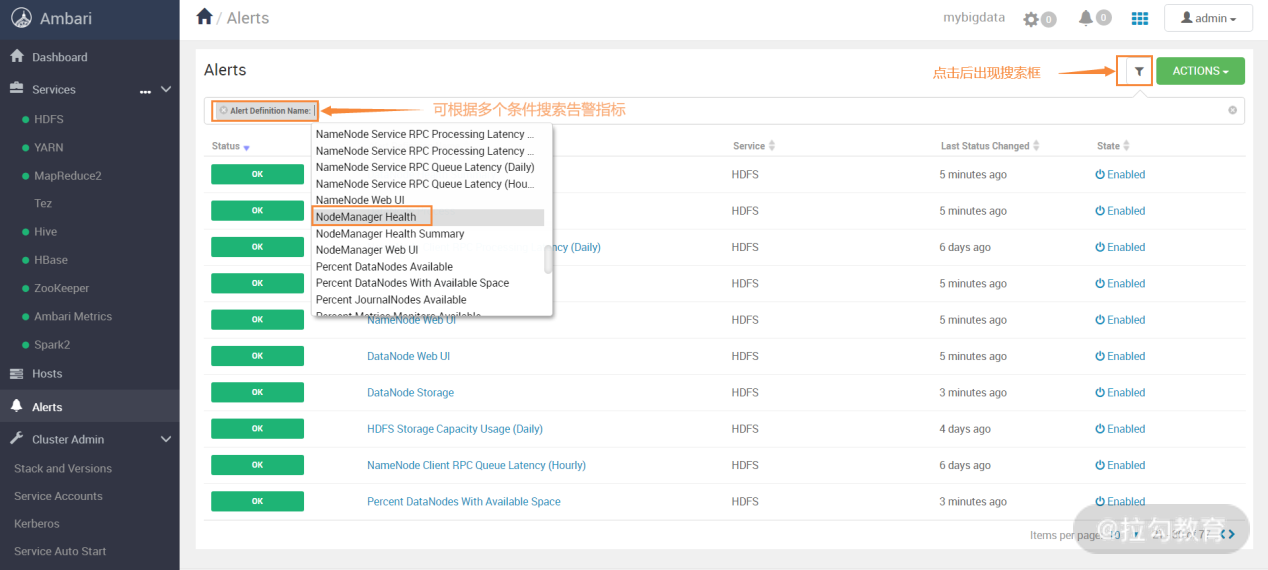
在告警界面下,点开搜索框,可以搜索需要的告警指标,然后对告警指标的属性进行编辑修改,如下图所示:
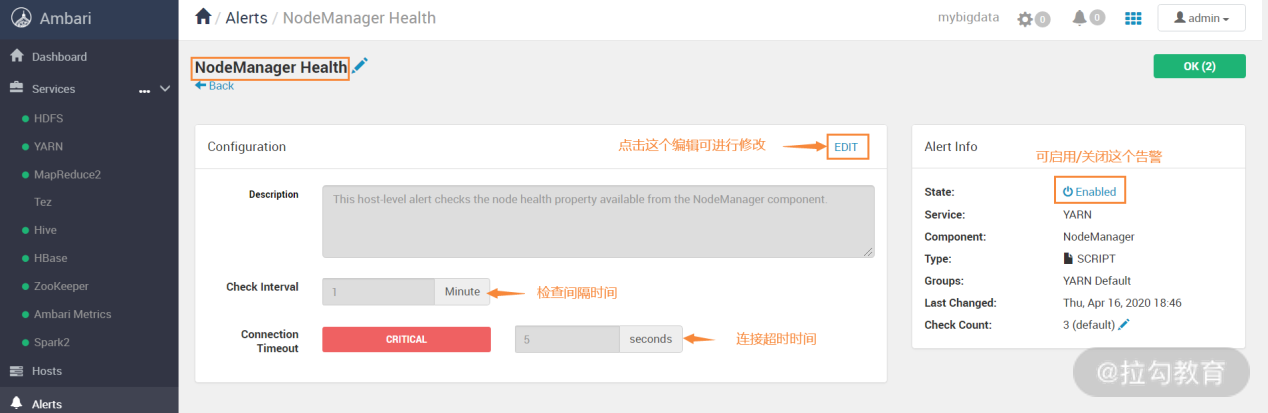
有些告警阀值的配置可能不是很合理,你可以根据实际情况进行调整,调整后自动生效。
告警指标配置好以后,就可以添加通知了,Ambari 默认支持邮件通知和自定义通知,要配置邮件通知。首先在告警页面右上角的“ACTIONS”按键下选择“Manage Alert Notifications”,然后就可以创建一个通知了,如下图所示:
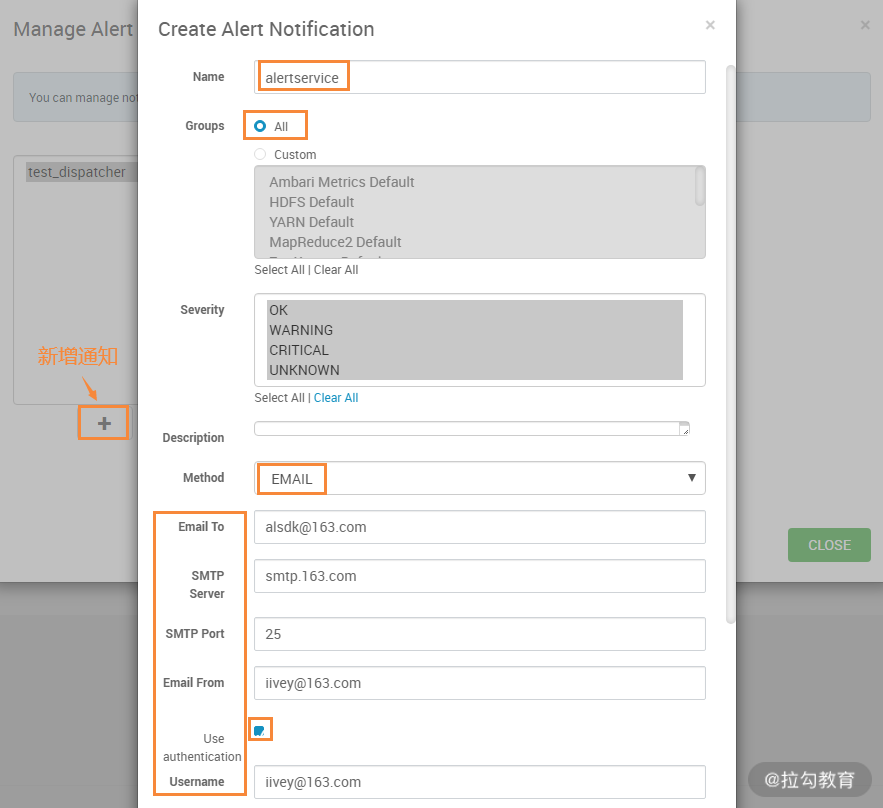
在这个步骤中,需要注意几个配置项。其中:
-
Groups 表示哪些告警组要发送通知,这里选择 all,也可以只选择某个 Group;
-
Severity 表示发送报警的级别,包含 OK、WARNING、CRITICAL 和 UNKNOWN,这里选择所有;
-
Method 表示通知发送方式,包含 Email、SNMP 和自定义,这里选择 Email;
-
Email To 表示收件人,可填写多个,SMTP Server 与你添加的邮箱有关,比如 163 邮箱对应的是 smtp.163.com;
-
SMTP Port 表示发送端口,比如 163 邮箱对应的 SMTP 端口为 25;
-
Emial From 表示发件人邮箱,必须填写真实存在的,Ambari 在发送邮件时会进行校验;
-
Use authentication 表示是否进行用户验证,这里选择验证;
-
Usename 表示发件人邮箱,需要和 Emial From 保持一致;
-
password 和 password confirmation,这两个配置项表示发件人邮箱密码或者授权码,如果你使用的是 163 邮箱,那么就是邮箱的授权码。
邮件通知配置完成后,可以将 Hadoop 集群某个服务关闭,测试一下是否能够正常发送告警邮件,如果不能收到告警邮件,可以查看 /var/log/ambari-server/ambari-server.log 日志以排查问题。
总结
本课时主要讲解了通过 Ambari 工具快速、自动化构建 Hadoop 大数据平台,熟练掌握 Ambari 工具的使用可以提高运维效率,但此工具也屏蔽了很多内部实现的细节,因此,新手入门的话,建议通过 Ambari 进行尝鲜,而要深入理解大数据运维,还是建议通过手工构建的方式掌握各个组件的实现和整合细节。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号