[大数据运维]第10讲:如何通过 Hive/tez 与 Hadoop 的整合快速实现大数据开发(下)
第10讲:如何通过 Hive/tez 与 Hadoop 的整合快速实现大数据开发(下)
高俊峰(南非蚂蚁)
(3)启动 Hiveserver2 服务
如果有程序通过 JDBC/ODBC 接口连接 Hive 的话,就需要启动 Hiveserver2 服务,否则不需要启动。启动后会开启 10000 和 10002 两个端口,10000 端口用于 JDBC、ODBC 远程连接,10002 是 Hive 的 Web UI 界面,可以查看 Hive 执行的 SQL 以及任务运行状态。在 HiveDB 主机上启动 Hiveserver2 服务方式如下:
[hadoop@hivedb ~]$ hive --service hiveserver2
Hiveserver2 服务默认也是启动在前台,并且启动过程中可以通过 hiveconf 设置相应的自定义参数和值。要让 Hiveserver2 服务启动到后台,可执行如下命令:
[hadoop@hivedb ~]$ nohup hiveserver2 --hiveconf hive.server2.thrift.prot=10000 1>/opt/bigdata/hive/current/hiveserver.log 2> /opt/bigdata/hive/current/hiveserver.err &
通过这个方式,可以指定要启动的端口,并将标准日志和错误日志输出到了不同的文件中。注意,在启动 Hiveserver2 服务之前,Metastore 服务是必须要启动的。
5. Hive 常用 SQL 操作
Hive 服务启动后,就可以在 Hive 的各个客户端执行查询分析操作了。这里以 Hive CLI 为例,介绍下 Hive 中常见的一些 SQL 操作。
(1)创建表、修改表、显示表
要创建一个表,可以执行如下 SQL 命令:
hive> CREATE TABLE A (a INT, b STRING);
还可以创建一个带索引字段 ds 的表:
hive> CREATE TABLE A (a INT, b STRING) PARTITIONED BY (dt STRING);
还可以创建一个分区表:
hive> create table test_table (id string, ip string,pt string) partitioned by (dt string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
要显示所有表,可以执行如下 SQL 命令:
hive> SHOW TABLES;
要更改表名,可以执行如下 SQL 命令:
hive> ALTER TABLE A RENAME TO B
(2)映射数据到表中
Hive 表创建后,可以将本地数据或 HDFS 上的数据加载到 Hive 表中,常见的 load 数据方式有如下几个。
要加载本地文件数据,将本地文件导入 Hive 表中,可执行如下 SQL 命令:
hive> LOAD DATA LOCAL INPATH '/examples/files/kv1.txt' OVERWRITE INTO TABLE A;
其中,/examples/files/kv1.txt 是本地操作系统下的路径。
要加载本地文件数据,将本地文件导入 Hive 表中,同时给定分区信息,可执行如下 SQL 命令:
hive> LOAD DATA LOCAL INPATH '/examples/files/kv2.txt' OVERWRITE INTO TABLE A PARTITION (dt='2020-05-04');
要加载 HDFS 上的数据,将 HDFS 上的文件导入 Hive 表,同时给定分区信息,可执行如下 SQL 命令:
hive> LOAD DATA INPATH '/user/mydata/kv3.txt' OVERWRITE INTO TABLE A PARTITION (dt='2020-05-04');
通过上面执行的 SQL 可知,如果有 local 这个关键字,则这个路径为本地文件系统路径;如果省略掉 local 关键字,那么这个路径是分布式文件系统 HDFS 中的路径。
注意,Hive 中默认的字段分隔符为 ASCII 码的控制符 \001,若在建表的时候没有指明分隔符,那么 load 文件的时候文件的分隔符需要是 '\001';若文件分隔符不是 '001',程序不会报错,但表查询的结果会全部为 'null';如果要造数据测试的话,用 Vi 打开文件,按键 Ctrl+V,然后再 按键 Ctrl+A, 可以输入这个控制符 \001。
要将 Hive 表数据导入到本地 A_table 目录中,可执行如下 SQL 命令:
hive> insert overwrite local directory '/home/hadoop/A_table' row format delimited fields terminated by '\t' select * from A;
(3)添加、删除、清空分区
要给 Hive 表添加分区,可执行如下 SQL 命令:
hive> alter table test_table add if not exists partition(dt='2020-05-04') ;
要删除 Hive 表分区,可执行如下 SQL 命令:
hive> alter table test_table drop if exists partition(dt='2020-05-04') ;
要清空 Hive 表分区数据,可执行如下 SQL 命令:
hive> truncate table test_table partition(dt='2020-05-04') ;
对 Hive SQL 我先介绍这么多,作为大数据平台的运维工程师,不需要对 Hive SQL 有多么高深的了解,只需要掌握一些基础的操作就可以了,这些操作可以帮助我们排查问题。
6. Beeline 的使用
启动了 Hiveserver2 服务后,就可以使用 Beeline 工具来连接 Hiveserver2 服务。这里我们将 HiveDB 上的 Hive 安装目录复制到 Hiveclient 主机,然后将 Hiveclient 作为运行 hive 命令的客户端。
Beeline 的使用很简单,一般只需要两个参数即可。
-
-n:连接时使用的用户名,这个用户是允许代理的用户,需要经过授权才能连接。
-
-u:用于 JDBC URL 连接的字串。
下面是通过 beeline 连接 hive 的一个例子:
[hadoop@hiveclient ~]$ beeline -u jdbc:hive2://yarnserver:10000 -n gaojf
上面命令运行成功后,就会进入 beeline 命令行下,如下图所示:
在这个命令中,我使用了 gaojf 这个用户,这是一个操作系统下的用户,如果不指定 -n 参数,那么 beeline 会默认使用 anonymous 这个用户。由于这里没有开启 beeline 的安全认证机制,所以不需要指定用户的密码。在这个步骤中,可能会出现如下问题:
20/05/02 17:56:07 [main]: WARN jdbc.HiveConnection: Failed to connect to yarnserver:10000
Error: Could not open client transport with JDBC Uri: jdbc:hive2://yarnserver:10000: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.security.AccessControlException: Permission denied: user=gaojf, access=EXECUTE, inode="/tmp":hadoop:supergroup:drwxrwx---
这个错误的意思是 beeline 要在 HDFS 上的 /tmp/hive 目录下以 gaojf 用户身份创建一个 gaojf 目录,但 /tmp 这个目录下只有 hadoop 用户和 supergroup 组的读写执行权限,没有其他用户或组的权限,这是 HDFS 上典型的权限问题。HDFS 文件系统的权限跟 Linux 下文件系统的权限实现机制是一样的,要解决这个问题,最简单的方式是将 HDFS 上 /tmp 目录权限修改为 777 即可,也就是执行如下命令:
[hadoop@yarnserver conf]$ hadoop fs -chmod 777 /tmp
授权成功后,再次执行 beeline 进入命令行就不会出现此错误了。
还有一种方式,就是在 namenode 上创建 gaojf 这个用户,然后将此用户加入到 supergroup 这个组中,这样,只需要保证 HDFS 上的 /tmp 目录权限是 775 就可以了。由此可知,HDFS 上的权限认证默认走的是 Linux 下的权限认证方法。
此外,Hive 中每个用户在执行分析任务时,还需要用到另一个 HDFS 目录,那就是 /user,每个用户都会在执行分析任务时把相关依赖包放到“/user/用户名”这个路径下。因此,也需要将 /user 目录权限设置为 775,然后将每个用户加到 supergroup 中。
接着, 我们在 beeline 命令行执行一个简单的 SQL 查询,看看是否正常,操作如下图所示:
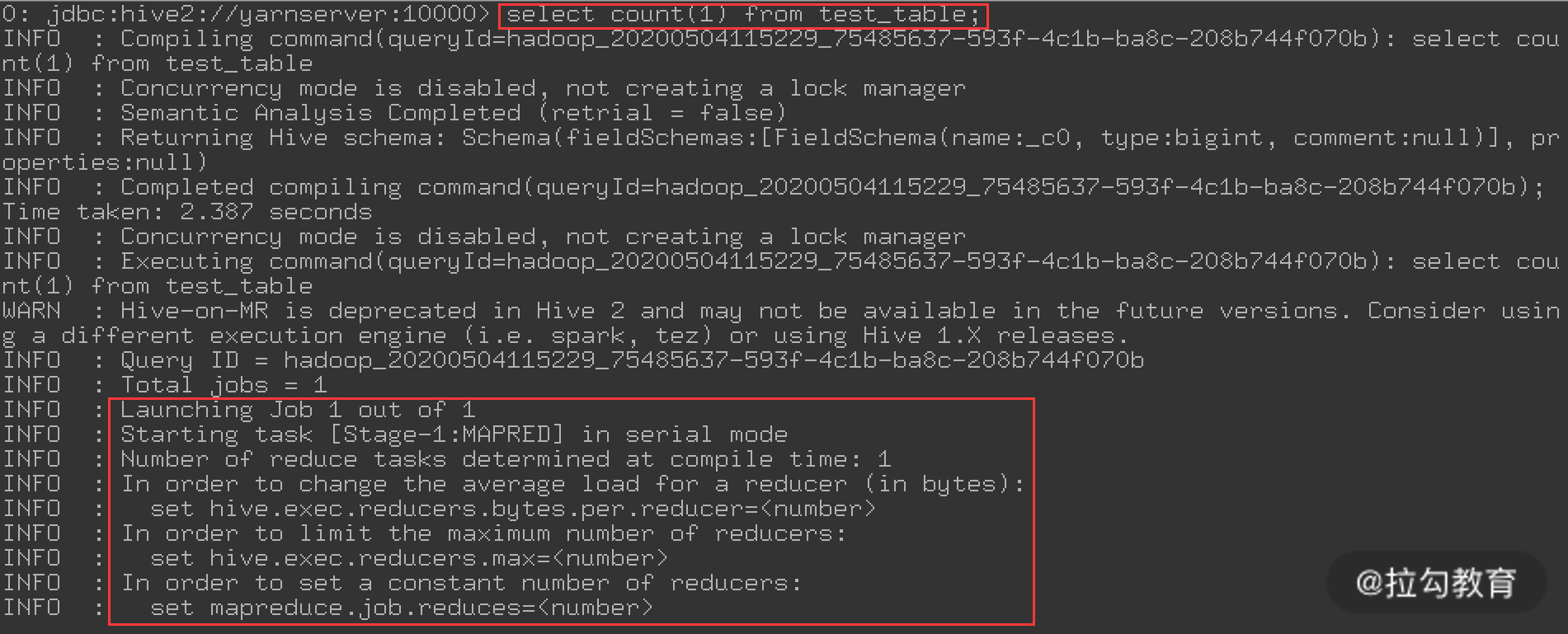
这是执行一个 select count 操作,统计 test_table 这张表有多少行数据,执行 select count(1) 查询的话,就会走 mapreduce;而如果执行 select * from test_table 的话,是不会走 mapreduce 的,这点需要注意。
上面执行的这个 select 操作,等了好久都没有执行结果,看来应该有问题,于是查看 hive 的日志文件 hive.log(默认路径在 /tmp/hadoop/hive.log),发现了如下异常:
org.apache.hadoop.security.authorize.AuthorizationException: User: hadoop is not allowed to impersonate gaojf
这个错误其实还是一个权限问题,这就要说下 Hadoop 中的 ProxyUser 机制,Hadoop2.0 版本开始支持 ProxyUser,所谓 ProxyUser 就是使用 User A 的用户认证信息,以 User B 的名义去访问 Hadoop 集群,对应 Hadoop 集群来说它认为是 User B 在访问集群,而对集群访问请求的权限验证(如 HDFS 文件系统权限、Yarn 队列权限)也是以 User B 用户的角色实现的,这里的 User A 被认为是 SuperUser,而 User B 就是 ProxyUser。
要实现 ProxyUser 机制,需要在 NameNode 和 ResourceManager 的 core-site.xml 中添加代理权限相关配置,注意添加的配置有如下内容:
<property>
<name>hadoop.proxyuser.userA.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.userA.users</name>
<value>user1,user2</value>
</property>
<property>
<name>hadoop.proxyuser.userA. groups</name>
<value>group1,group2</value>
</property>
其中:
-
hadoop.proxyuser.userA.hosts 表示配置 userA 允许通过代理访问的主机节点;
-
hadoop.proxyuser.userA.users 表示配置 userA 允许代理的用户;
-
hadoop.proxyuser.userA. groups 表示配置 userA 允许代理的用户所属组。
这里的 userA 可以理解为上面所说的 SuperUser,而这段配置的含义是允许用户 userA 在任意主机节点,代理用户 user1 和 user2、代理用户组 group1 和 group2,进而实现对集群的访问。
对于 ProxyUser 机制来说,hadoop.proxyuser.userA.hosts 是必须要配置的,hadoop.proxyuser.userA.users 和 hadoop.proxyuser.userA. groups 至少需要配置一个。这几个配置项的值都可以使用“*”来表示允许所有的主机、用户或用户组。
结合上面的报错提示,我们添加如下内容到 NameNode 和 ResourceManager 的 core-site.xml 中。
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop. groups</name>
<value>hadoop</value>
</property>
这段配置的含义是允许 hadoop 用户在任意主机节点,代理用户组 hadoop 访问集群。这个配置修改后,并不会马上生效,可以执行以下命令,分别将信息更新到 namenode 和 resourcemananger 上。
[hadoop@namenodemaster ~]$ hdfs dfsadmin –refreshSuperUserGroupsConfiguration
[hadoop@yarnserver conf]$ yarn rmadmin –refreshSuperUserGroupsConfiguration
最后,还需要做一个操作,那就是将 gaojf 用户加到 Hadoop 这个组中,此操作必须在 Hadoop 集群的 yarnserver 主机上执行,因为 yarn 的权限认证是在 resourcemananger 节点上,执行操作如下:
[root@yarnserver ~]# useradd gaojf
[root@yarnserver ~]# usermod -G hadoop gaojf
[root@yarnserver ~]# id gaojf
uid=1002(gaojf) gid=1002(gaojf) 组=1002(gaojf),1001(hadoop)
现在,我们再来执行刚才的那个 select 查询 SQL,如下图所示:
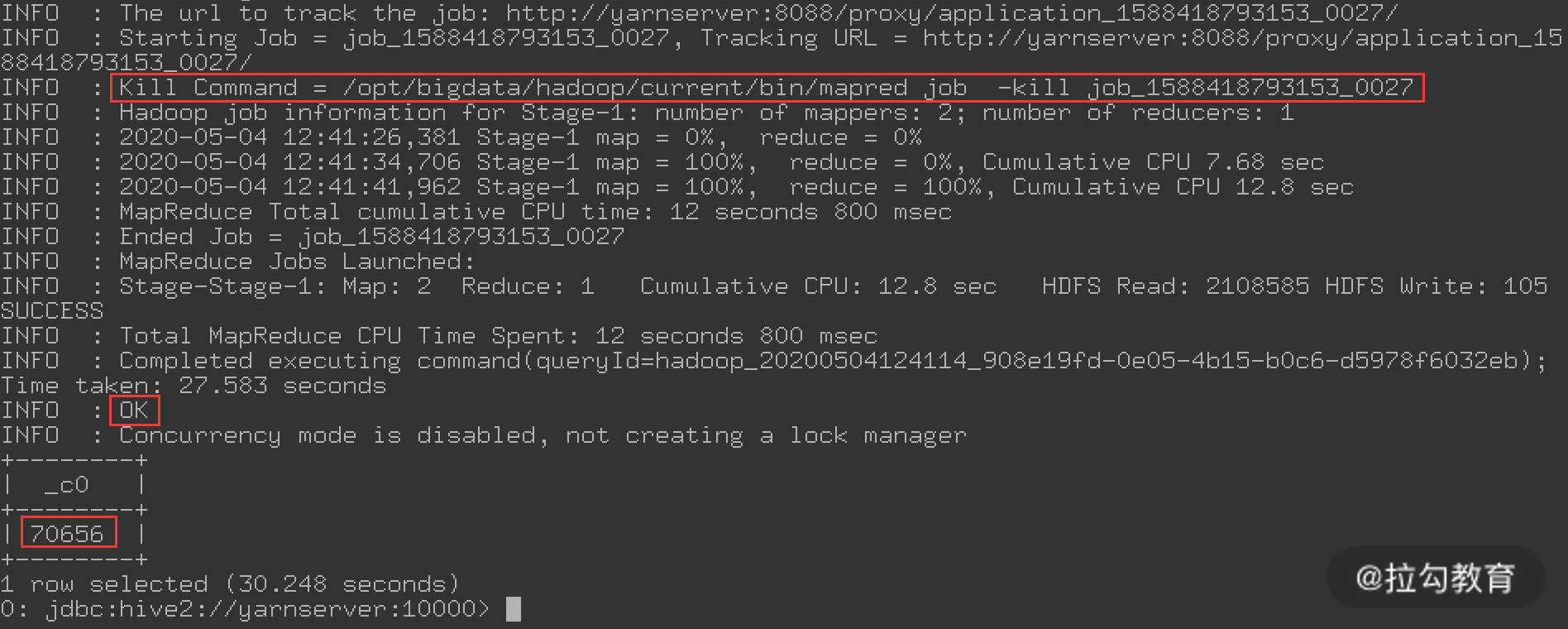
可以看到,很快就得到了查询结果,因为这个查询是走了 MapReduce,还可以在 Yarn 的 8088 端口查看执行状态,如下图所示:
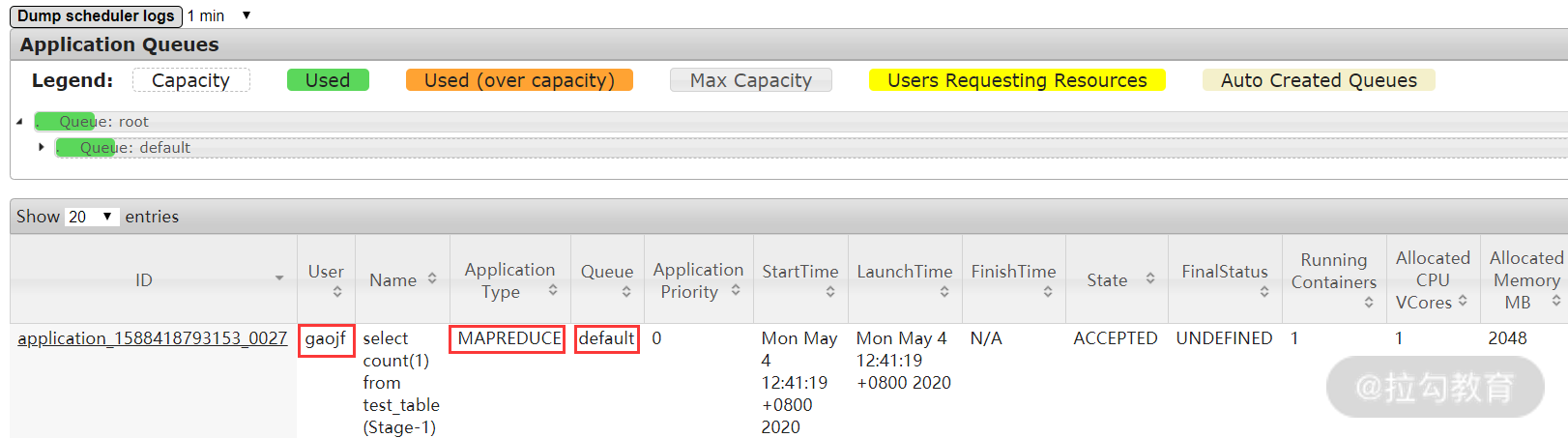
从上图中,可以看出这个任务执行的用户是 gaojf,任务类型是 MapReduce,提交在 default 队列中。
Hive 运行引擎 MR、Tez 配置
Tez 是一个构建在 Hive 之上的支持复杂 DAG 任务(有向无环图)的数据处理引擎,它把 MapReduce 的执行过程拆分成若干个子过程。同时可以把多个有依赖的 MapReduce 任务组合成一个较大的 DAG 任务,这种逻辑减少了 MapReduce 中间数据频繁写入 HDFS 上的性能问题,同时,通过合理组合其子过程,进而大幅提升了 MapReduce 作业的性能。
Hive 支持多个计算引擎,常见的有 Hive On MapReduce、Hive On Tez 及 Hive On Spark。Hive On MapReduce 是默认的运行引擎,主要处理离线数据,Hive On Tez 是支持 DAG 作业(有向无环图)的计算引擎,而 Hive On Spark 主要是基于内存计算的引擎。现在 Hive On MapReduce 由于运行效率低下,很少使用了,Hive On Tez 是目前的主流。
Tez 在执行小任务时,速度是 Hive On MapReduce 模式的 2~3 倍,而在执行大型分析任务时,速度是 Hive On MapReduce 的 8~10 倍左右。
1. 源码编译安装 Tez
目前 Tez 发布的最新版本是 0.9.2,此版本是基于 Hadoop 2.7.2 的,而我们这里的环境是 Hadoop 3.2.1 及 Hive 3.1.2。所以 Tez 官方发布的二进制版本无法使用,需要通过源码重新编译,经过测试,0.9.x 版本无法兼容 Hadoop3.2.1,主要是 Google Guava 版本冲突,Tez0.9.x 默认的 Guava 11.0.2 版本,而 Hadoop3.2.1 自带的 Guava 版本为 27.0,所以不能兼容。要解决这个问题,需要点击这里下载最新的 Tez 0.10.1 版本,此版本兼容 Hadoop3.2.1,将 Tez 源码下载后,执行下面步骤进行安装:
[hadoop@ hivedb ~]$unzip tez-master.zip
[hadoop@hivedb ~]$cd tez-master
[hadoop@hivedb tez-master]$/usr/local/maven/bin/mvn install -Dhadoop.version=3.2.1 -DskipTests -Dmaven.javadoc.skip=true
上面的 -Dhadoop.version 是指定 Hadoop 的版本,根据你的环境来指定即可。Tez 下默认的依赖软件版本可通过查看源码目录下的 pom.xml 文件。
要编译 Tez,需要 maven 工具,并且编译安装 Tez 时间会比较长,编译安装完成后,会在源码目录下的 tez-dist/target/ 中找到编译好的 Tez,其中,有两个版本,即 tez-0.10.1-SNAPSHOT-minimal.tar.gz 和 tez-0.10.1-SNAPSHOT.tar.gz,这两个就是我们需要的 Tez 程序。
2. 配置 Tez 与 Hive 整合
Tez 与 Hive 的整合需要三个步骤,分别是上传 Tez 的 jar 包到 HDFS、配置 Hive 及 Hive 中 Tez 包的引入,下面依次说明。
首先,将上面编译好的 tez-0.10.1-SNAPSHOT.tar.gz 包进行解压,然后将解压后的文件放到一个目录下,最后上传到 HDFS 上,操作如下:
[hadoop@hivedb target]$mkdir tez-0.10.1
[hadoop@ hivedb target]$ tar zxvf tez-0.10.1-SNAPSHOT.tar.gz -C tez-0.10.1
[hadoop@ hivedb target]$ hadoop fs -mkdir /tez
[hadoop@ hivedb target]$hadoop fs -put tez-0.10.1 /tez
接着,在 Hive 配置目录 /opt/bigdata/hive/current/conf 中添加一个 tez-site.xml 文件,内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/tez/tez-0.10.1,${fs.defaultFS}/tez/tez-0.10.1/lib</value>
</property>
<property>
<name>tez.lib.uris.classpath</name>
<value>${fs.defaultFS}/tez/tez-0.10.1,${fs.defaultFS}/tez/tez-0.10.1/lib</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
<property>
<name>tez.am.resource.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>tez.am.resource.cpu.vcores</name>
<value>2</value>
</property>
</configuration>
在这个配置中,有三个参数需要特别注意,其中,tez.lib.uris 用来指定 Hive 运行依赖的 tez 包,这个路径是 HDFS 上的路径、tez.lib.uris.classpath 用来指定 Hadoop 依赖的相关包,tez.use.cluster.hadoop-libs 表示是否使用 Hadoop 自身的 lib 包,这里设置为 true。
另外,还需要修改 hive-site.xml 文件,添加如下内容:
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>
这个配置是设置 Hive 的默认引擎为 tez,设置完成后,Hive 配置就结束了,最后,还需要在 HiveDB 上部署 Tez 本地程序。将上面源码编译好的 tez-0.10.1-SNAPSHOT-minimal.tar.gz 包解压到 /opt/bigdata/tez 目录下即可,操作如下:
[hadoop@hivedb bigdata]$ mkdir -p /opt/bigdata/tez/tez-0.10.1
[hadoop@hivedb bigdata]$tar zxvf tez-0.10.1-SNAPSHOT-minimal.tar.gz -C /opt/bigdata/tez/tez-0.10.1
[hadoop@hivedb bigdata]$cd /opt/bigdata/tez
[hadoop@hivedb tez]$ ln -s tez-0.10.1 current
Tez 包部署完成后,找到 /opt/bigdata/hive/current/conf/hive-env.sh 文件,添加以下内容,将本地 tez 包引入 hive,内容如下:
export HIVE_HOME=/opt/bigdata/hive/current
export TEZ_HOME=/opt/bigdata/tez/current
export TEZ_JARS=""
for jar in `ls $TEZ_HOME |grep jar`; do
export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/$jar
done
for jar in `ls $TEZ_HOME/lib`; do
export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/lib/$jar
done
export HADOOP_CLASSPATH=${TEZ_JARS}/*:${TEZ_JARS}/lib/*
到此为止,Tez 整合到 Hive 配置完成了。
3. 测试 Tez 功能
这里我在 Hiveclient 主机上进行Tez 功能测试,由于在 Hive 基础上进行了 Tez 整合,所以还需要将 HiveDB 主机上的 Hive 安装目录以及 Tez 安装目录都复制到 Hiveclient 主机上,然后做如下功能测试。操作如下:
[hadoop@hiveclient conf]$ beeline -u jdbc:hive2://yarnserver:10000 -n gaojf
0: jdbc:hive2://yarnserver:10000> create table ad1 (id string, ip string,pt string) partitioned by (dt string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
0: jdbc:hive2://yarnserver:10000> LOAD DATA LOCAL INPATH '/home/hadoop/demo100.txt' OVERWRITE INTO TABLE ad1 PARTITION (dt='2020-05-06');
0: jdbc:hive2://yarnserver:10000> select count(1) from ad1;
这个步骤中通过 Beeline 链接 Hiveserver2,被代理的用户是 gaojf,也可以是任意一个用户;然后创建了一个表 ad1,通过 load 方法将本地文件导入到 ad1 表中;最后执行 select 查询 SQL 获取此表记录数,select 查询过程如下图所示:
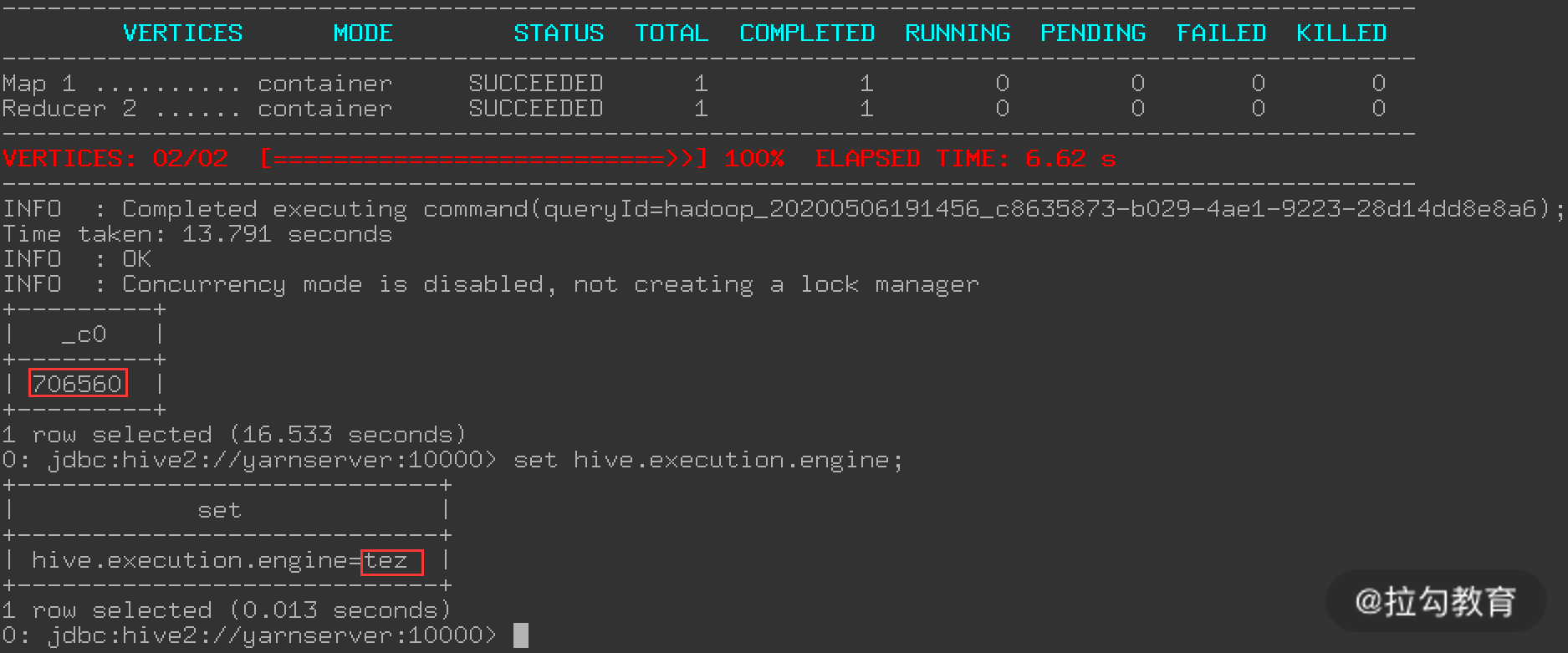
上图就是 Tez 的执行过程,可以看到执行这个查询花费了 16.533 秒,而目前的计算引擎是 Tez。可以通过“set hive.execution.engine=mr;”切换计算引擎为 MR,然后再次执行 select 查询,结果如下图所示:
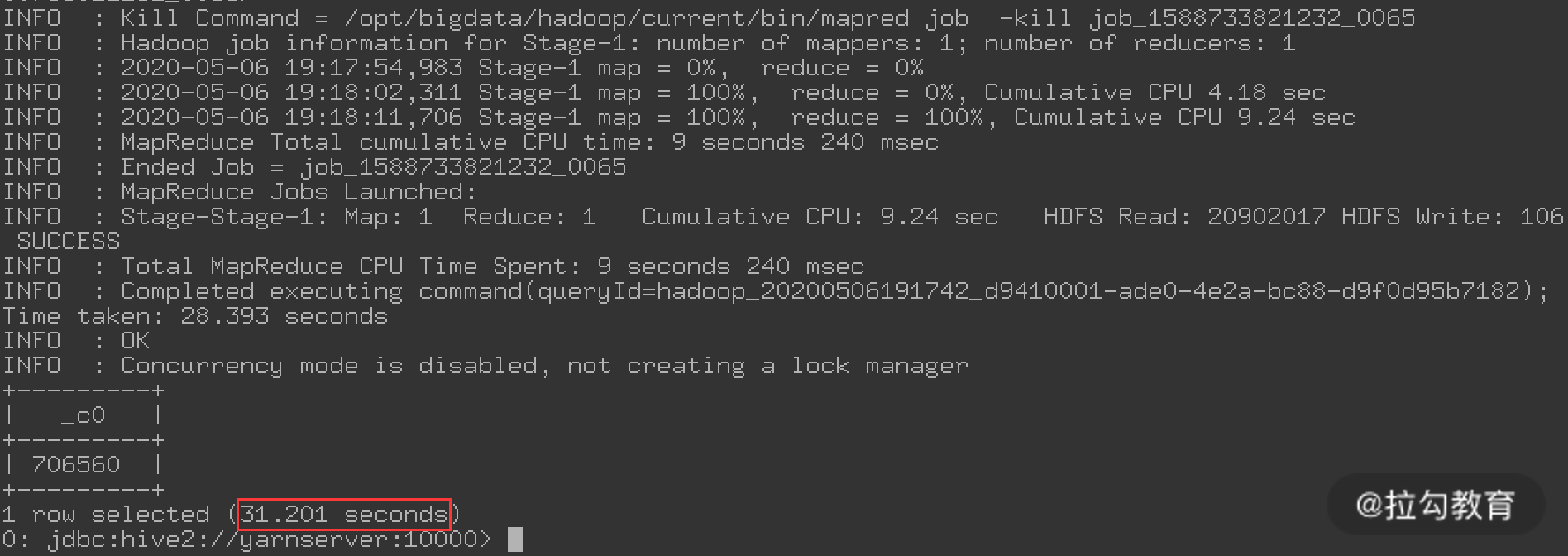
可以看到,通过 MR 引擎执行这个查询花费了 31.201 秒,比 Tez 慢了近一倍,这就是 Tez 的优势。
要查看任务的详细运行状态信息,可查看 yarnserver 的 8088 端口,如下图所示:
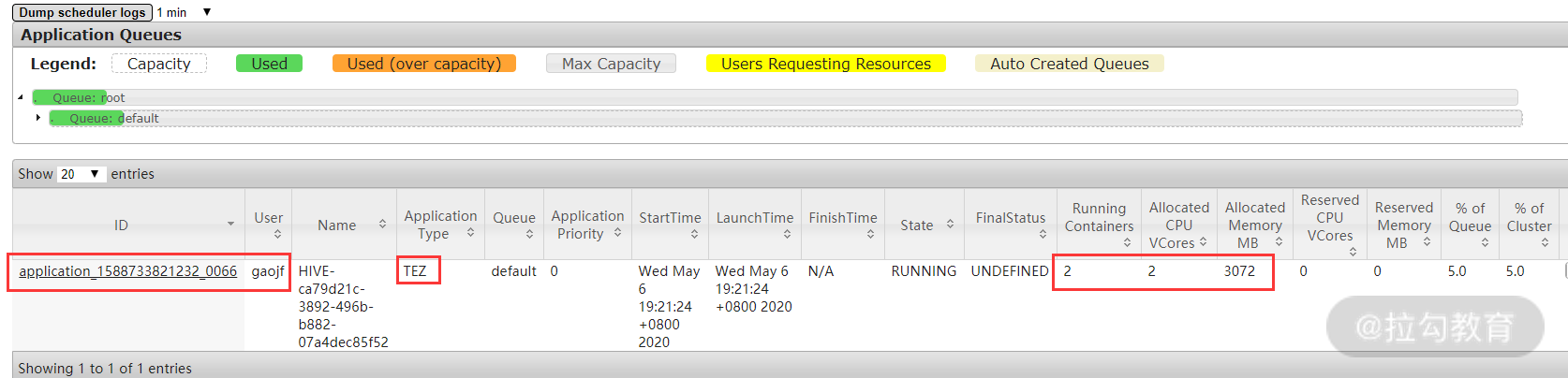
从上图可以看出,任务 application_1588733821232_0066 使用的是 Tez 引擎,还有此任务使用的队列、CPU、内存等资源信息。
总结
本课时注意讲解了 Hive 与 Hadoop 的整合,以及如何将 Tez、Beeline 整合到 Hive 中。重点是 Hive 与其他组件的整合实现快速开发,作为大数据运维工程师,Hive 的部署与整合是必须要掌握的内容。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号