[大数据运维]第07讲:通过 Ambari 工具自动化构建 Hadoop 大数据平台和外围应用(上)
第07讲:通过 Ambari 工具自动化构建 Hadoop 大数据平台和外围应用(上)
高俊峰(南非蚂蚁)
本课时主要讲“通过 Ambari 工具自动化构建大数据运维平台”的内容。
大数据运维工具 Ambari
当学完前面的内容,是否发现分布式 Hadoop 集群部署很麻烦,而且管理维护也不简单,那么在实际的企业运维中,是否有更简单的部署、维护、监控的办法呢?答案是肯定的,本课时我们就将介绍这些大数据平台集中运维工具。
1. Hadoop 集群的多种部署方式
在前面的课时中,详细介绍了 Hadoop 的手工部署过程,其实手工部署还是比较复杂的,对于操作系统的配置、Hadoop 的安装及配置都需要手工去完成,虽然采用了自动化运维的方式,但仍然有很多工作要做,这就是手工部署的缺点,也是优点,为什么呢?因为手工部署的好处是可以了解每个软件的配置细节和运作原理,这对大数据运维来说,至关重要。
除了手工部署方式外,Hadoop 还可以通过一些 Web 工具实现自动化部署和管理,比较知名的有 Ambari、Cloudera Manager(CM)等。Ambari 是 Apache 官方的产品,而 CM 是 Cloudera 公司开发的一款大数据集群安装部署利器。这两个产品实现的功能基本相同,但 CM 为收费产品,某些高级功能需要付费才能使用,而 Ambari 是纯开源产品,可自由免费使用。本课时我们将重点介绍 Ambari 的使用。
Hadoop 有两种部署方式,如何来做选择呢?如果你是一个初学者,那么推荐使用 Ambari 这样的工具来实现快速部署;如果你是专业的大数据运维工程师,那么建议采用手工方式进行部署。因为 Ambari 工具隐藏了很多部署和实现的细节,会导致只知其然,而不知其所以然,而大数据运维不仅要知其然,还要知其所以然。
2. Ambari 是什么
Apache Ambari 是大数据平台集成运维管理工具,它支持 Apache Hadoop 集群的部署、管理和监控。目前,Ambari 已支持大多数 Hadoop 生态圈的组件,如 HDFS、MapReduce、 HBase、Spark、Storm、Kafka、Druid、ZooKeeper、Hive、Pig、Sqoop、Oozie 等。
我们知道,Hadoop 集群通过手动方式进行安装,相当麻烦,而采用 Ambari 后,所有组件和服务都可以通过 Web 界面提供的安装向导,一步一步快速完成安装。同时,通过 Ambari 还可以对集群服务进行批量的重启、关闭等维护操作。此外,Ambari 内部还集成了系统数据采集功能、并支持故障告警,所有节点的负载、IO、磁盘等状态都可以通过图表方式实时展示,如果某个指标出现故障,可以用邮件或自定义方式告警。
Ambari 跟 Hadoop 等开源软件一样,也是 Apache 中的一个顶级项目,通过 Ambari 可以实现部署、管理、监视 Hadoop 集群,对大数据运维工程师来说,通过此工具,可以大大提高工作效率。
3. Ambari 的架构与工作原理
Ambari 是一个分布式架构的应用工具,主要由三部分组成,即 Ambari Server、Ambari Agent、Ambari Web 和 Metrics Collector。基本运行原理是用户通过 Ambari Server 通知 Ambari Agent 安装指定的软件,Ambari Agent 定时发送各个机器上每个软件模块的运行状态给 Ambari Server;同时 Metrics Collector 用来提供监控信息查询接口,供 Ambari Server 进行查询,而 Ambari Server 会把所有状态信息汇总,最终呈现在 Ambari 的 Web 页面上,以便了解集群的各种状态数据,并进行相应的管理和维护。
下图是 Ambari 整体架构图:
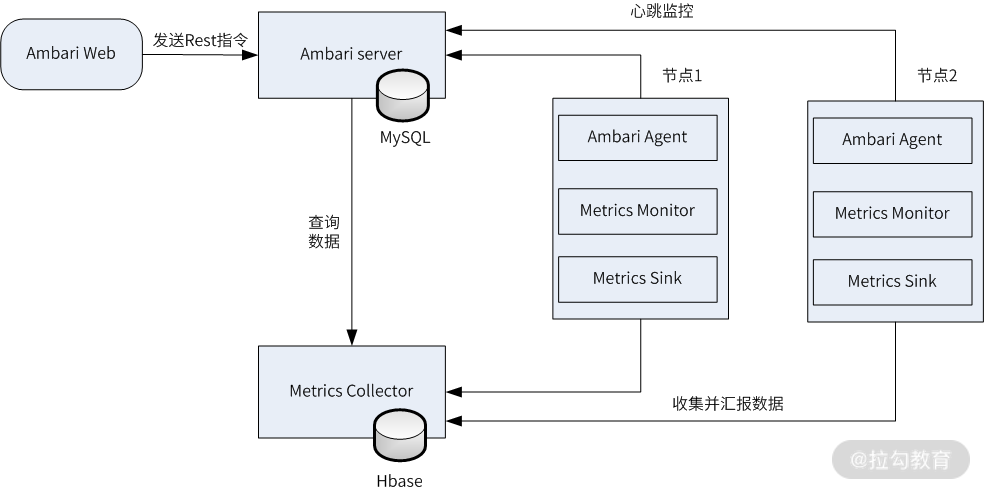
从图中可以看出,Ambari 主要分为四个部分,每个部分实现功能如下所示。
-
Ambari Web:前端展示界面,Web 前端通过 HTTP 发送 Rest 指令和 Ambari Server 进行交互。
-
Ambari Server:Ambari 的核心部分,主要用来和 Ambari Web、Ambari Web 进行交互。此外,Ambari Server 的数据默认存储在 PostgresSQL 中,也可以使用 MySQL 进行存储。
-
Metrics Collector:监控数据收集器,由 Metrics Collector、Metrics Monitor、Metrics Sink 三个部分组成,Metrics Monitor 主要负责收集并汇报操作系统相关的指标,比如主机的 CPU、内存、磁盘、网络等信息;Metrics Sink 负责收集并汇报 Hadoop 组件的相关指标,比如 HDFS 的 CPU 使用率、内存占用情况等。而 Metrics Collector 用来接收 Metrics Monitor 和 Metrics Sink 汇报上来的监控信息,并将数据存储到 HBase 中,最后,Metrics Collector 还提供监控数据查询接口,以供 Ambari Server 进行查询。
-
Ambari Agent:部署在集群节点上监控程序,主要功能有两个,第一个是采集所在节点的信息并且汇总,然后发送心跳汇报给 Ambari Server;第二个是用于接收 Ambari Server 发送过来的操作指令,然后交给执行器调用 puppet 或 Python 脚本等模块执行任务。在实际应用中,每个大数据节点都要安装 Ambari Agent 服务和 Metrics Monitor 服务。
总体来说,Ambari 完成的功能分为两大部分,分别是集群的统一部署、管理和基本的监控(组件存活状态监控),这部分功能由 Ambari Web、Ambari Server 和 Ambari Agent 完成:Ambari Web 提供可视化界面,发送操作指令;Ambari Server 维护着整个集群的状态;Ambari Agent 执行具体的指令去操作服务和组件,同时会通过心跳汇报主机和服务的状态信息。
另一部分是集群的状态监控,通过 Metrics Collector、Metrics Monitor、Metrics Sink 完成集群节点状态数据的收集和存储,并提供给 Ambari Server 进行实时查询。
安装与部署 Ambari
对于 Ambari 的安装,目前有两个可选发行版本:Apache 的 Ambari、Hortonworks 的 Ambari。这两个发行版本区别不大,但 Apache 的 Ambari 需要编译才能使用,而 Hortonworks 的 Ambari 提供了 rpm 包版本,因此安装更加简单。这里就使用 Hortonworks 的 Ambari 来进行安装。
1. 部署前准备工作
安装之前需要先规划好主机及角色,这里以 5 台主机为例作为安装环境,采用 Centos7.7 版本系统,各主机 IP、功能分配如下表所示:
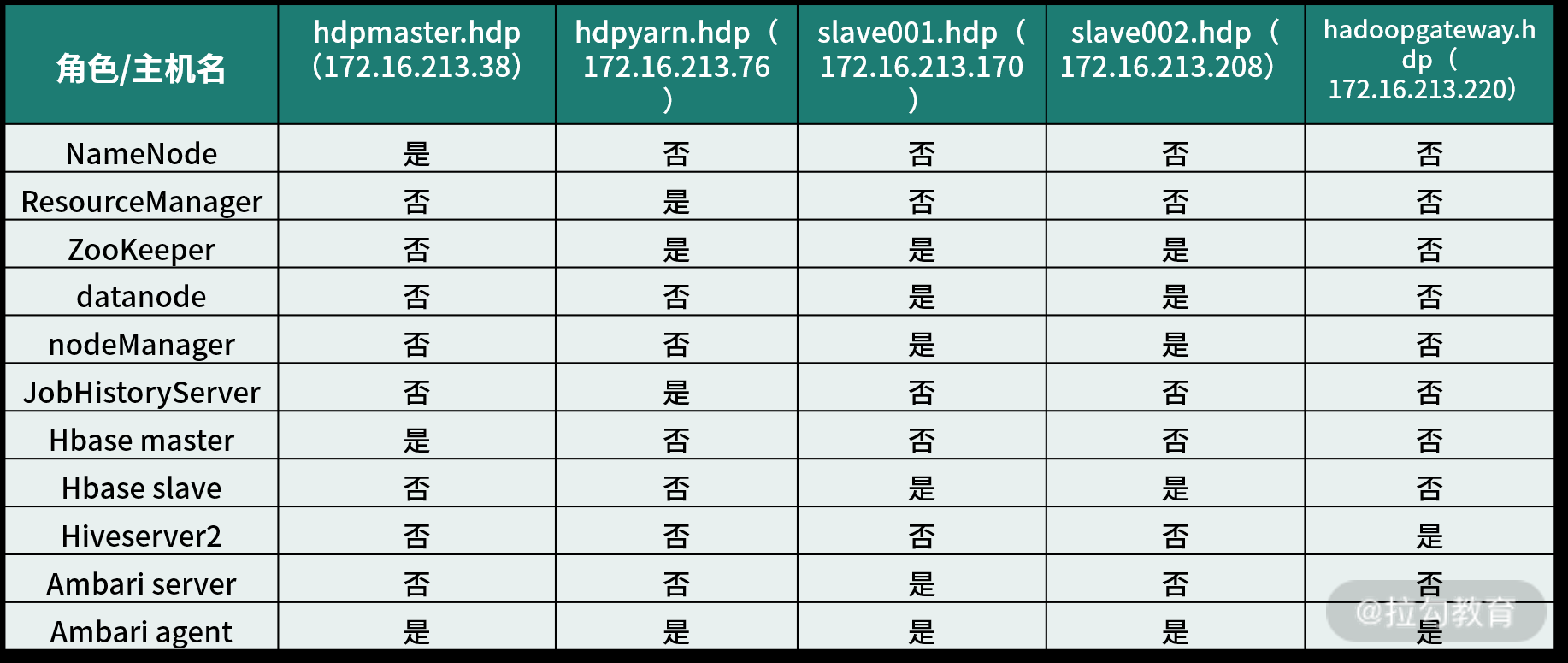
在这个主机规划中,增加了一台 gateway.hdp 主机,此主机是提交分析任务到 Hadoop 集群的一个接口,开发或测试人员可通过登录这台机器,将自己的数据分析任务提交到 Hadoop 上运行,所以此主机也称为网关机。
接着,还需要做如下准备工作。
(1)配置 Ambari 主机到 Agent 的无密码登录
由于 Ambari Server 主机会通过 ssh 登录到每个 Agent 主机上执行一些命令,所以需要配置从 Ambari server 主机到 Agent 主机的无密码登录。在我们这个环境中,要配置从 Ambari server 到其他 4 台主机的无密码登录。
(2)构建 yum 仓库
Ambari 的安装包可以到 Hortonworks 官网下载,也可以直接使用 Hortonworks 提供的 yum 源,但是这种方式安装 Ambari 太慢了。所以最好的方式是在本地构建一个 yum 仓库,从官网下载 Ambari 安装包,然后导入本地仓库,这样会比较顺利一些,包括后面的 HDP 安装,也采用这种方式。
(3)系统基础环境配置
跟前面手动安装 Hadoop 一样,对操作系统基础环境也需要进行配置,例如关闭 selinux 和 firewalld、添加本机解析文件 hosts、配置用户资源 ulimit、添加时间同步时钟、安装配置 JDK 等,这些工作可通过 ansible 自动完成,这里不再赘述。
2. 搭建 Yum 仓库
Yum 仓库可以在任意一台服务器上部署,这个服务跟 Hadoop 集群没有任何关系,它只是在安装集群服务的时候用来提供安装源。
(1)搭建 Yum 仓库的 http 服务
以 nginx 作为 http server 为例,需要安装 nginx server,这里在 172.16.213.239 主机上安装 nginx,操作如下:
[root@server239 soft]#yum install nginx
默认安装的 nginx 主程序目录在 /usr/share/nginx/html 下,因此,yum 仓库文件放在这个目录下即可。接着,修改 nginx 配置文件 nginx.conf,添加如下加粗内容到默认 server 部分。
server {
autoindex on;
autoindex_exact_size on;
autoindex_localtime on;
listen 80 default_server;
listen [::]:80 default_server;
server_name _;
root /usr/share/nginx/html;
location / {
}
error_page 404 /404.html;
location = /40x.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}
最后,重启 nginx 服务器即可:
[root@server239 soft]# systemctl start nginx
(2)添加 rpm 文件到 yum 仓库
在 /usr/share/nginx/html 目录下创建一个用于存储仓库文件的目录,也可不创建。这里创建一个 soft 目录,可直接把 rpm 文件放在 soft 目录下,也可在 soft 目录下创建子目录分类存储。这里在 soft 目录下创建一个 Ambari 目录,然后把下载好的 Ambari 包放到这个目录下。
要获取 Ambari 的所有 rpm 包,可在 hortonworks 网站进行下载。
此软件包大小在 1.9G 左右,下载可能要一段时间,注意,此软件包是针对 Centos7 版本的。将下载的压缩包解压到 /usr/share/nginx/html/soft/ambari 目录下,保持解压后的目录结构。
(3)安装 createrepo,创建索引库
下载的软件包默认已经自带了索引库,所以针对 Ambari 无需再创建索引库,不过如果是自建仓库,还需要创建索引库。下面简单介绍下如何创建索引库。
假定已经指定了 yum 仓库的根目录为 /usr/share/nginx/html/soft,为了让 yum 能识别这些目录,需要创建 yum 索引库,创建索引库需要一个命令 createrepo。因此要先安装这个命令,然后再创建索引库,操作过程如下:
[root@server239 ~]# yum install createrepo -y
[root@server239 ~]# createrepo /usr/share/nginx/html/soft
createrepo 命令执行完毕后,会在 soft 目录下产生一个 repodata 目录,这就是索引库。
(4)测试本地 yum 仓库
在另一台客户端机器上,创建一个 yum 源文件 local.repo,内容如下:
#VERSION_NUMBER=2.7.4.0-118
[ambari-2.7.4.0]
#json.url = http://public-repo-1.hortonworks.com/HDP/hdp_urlinfo.json
name=ambari Version - ambari-2.7.4.0
baseurl=http://172.16.213.239/ambari/centos7/2.7.4.0-118
gpgcheck=1
gpgkey=http://172.16.213.239/ambari/centos7/2.7.4.0-118/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins
enabled=1
priority=1
将这个文件放到客户端主机的 /etc/yum.repos.d 路径下,然后执行如下命令:
[root@server239 ~]# yum clean all
[root@server239 ~]# yum makecache
[root@server239 ~]# yum repolist
最后,执行一个在线安装测试:
[root@server239 ~]# yum install ambari
如果能顺利安装,表明 yum 仓库搭建成功。
3. 安装 MySQL 库并初始化数据
Ambari 使用的默认数据库是 PostgreSQL,不过它也支持 MySQL。下面以 MySQL 数据库为例,简单介绍下其安装、初始化库的创建及授权。
点击这里下载 MySQL 的 yum 源,然后安装 rpm 文件,执行如下操作:
[root@ambariserver ~]# rpm -ivh mysql80-community-release-el7-3.noarch.rpm
此 yum 源安装后,会在 /etc/yum.repos.d/ 下生成一个 mysql-community.repo 文件,此仓库包含了 MySQL 的各个版本,默认开启的是 8.0 版本,可选择开启需要的版本,我这里开启的是 5.7 版本。接着,就可以通过 yum 安装 MySQL 了,操作如下:
[root@ambariserver ~]# yum install -y mysql-server mysql
安装完成后,执行启动 MySQL 服务:
[root@ambariserver ~]# systemctl start mysqld
启动后,会生成 root 临时密码,可在 /var/log/mysqld.log 找到临时密码,然后登录 mysql,执行如下操作:
mysql> alter user 'root'@'localhost' identified by '新密码';
mysql> ALTER USER 'root'@'localhost' PASSWORD EXPIRE NEVER;
mysql> flush privileges;
上面修改了 root 用户的密码,然后就可以进行创建 Ambari 库的操作了:
mysql> create database ambari character set utf8 ;
mysql> CREATE USER 'ambari'@'172.16.213.%'IDENTIFIED BY '密码';
mysql> GRANT ALL PRIVILEGES ON *.* TO 'ambari'@'172.16.213.%';
mysql> FLUSH PRIVILEGES;
上面的 SQL 操作,首先创建了一个 ambari 库,接着创建了一个 ambari 用户,并进行授权,该授权允许 172.16.213.0/24 这个段的 IP 进行连接,最后刷新权限使其生效。
4. 通过 yum 安装 Ambari 并进行配置
准备了这么多,下面开始安装 Ambari。在这之前,先安装 ambari 的依赖包,执行如下命令:
[root@ambariserver ~]# yum install openssh wget vim openssh-clients openssl gcc* openssh-server mysql-connector-odbc mysql-connector-java python-devel*
这里面比较重要的是安装 mysql-connector-java 这个软件包,这是 Java 连接 MySQL 的一个驱动包,此软件包安装后,会生成一个 /usr/share/java/mysql-connector-java.jar 文件,此文件在安装 ambari 的时候会用到。
然后安装 Ambari,执行如下命令:
[root@ambariserver ~]# yum install -y ambari-server
ambari-server 安装会自动下载 postgresql 包,先不用管它,后面我会指定使用 MySQL 数据库。
最后对 Ambari 进行配置,执行如下命令进入交互模式:
[root@ambariserver ~]# ambari-server setup
[root@ambariserver java]# ambari-server setup
Using python /usr/bin/python
Setup ambari-server
Checking SELinux...
SELinux status is 'disabled'
Customize user account for ambari-server daemon [y/n] (n)? y
Enter user account for ambari-server daemon (root):ambari
Adjusting ambari-server permissions and ownership...
Checking firewall status...
Checking JDK...
[1] Oracle JDK 1.8 + Java Cryptography Extension (JCE) Policy Files 8
[2] Custom JDK
==============================================================================
Enter choice (1): 2
WARNING: JDK must be installed on all hosts and JAVA_HOME must be valid on all hosts.
WARNING: JCE Policy files are required for configuring Kerberos security. If you plan to use Kerberos,please make sure JCE Unlimited Strength Jurisdiction Policy Files are valid on all hosts.
Path to JAVA_HOME: /usr/java/jdk1.8.0_162
Validating JDK on Ambari Server...done.
Check JDK version for Ambari Server...
JDK version found: 8
Minimum JDK version is 8 for Ambari. Skipping to setup different JDK for Ambari Server.
Checking GPL software agreement...
GPL License for LZO: https://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html
Enable Ambari Server to download and install GPL Licensed LZO packages [y/n] (n)? y
Completing setup...
Configuring database...
Enter advanced database configuration [y/n] (n)? y
Configuring database...
==============================================================================
Choose one of the following options:
[1] - PostgreSQL (Embedded)
[2] - Oracle
[3] - MySQL / MariaDB
[4] - PostgreSQL
[5] - Microsoft SQL Server (Tech Preview)
[6] - SQL Anywhere
[7] - BDB
==============================================================================
Enter choice (1): 3
Hostname (localhost):
Port (3306):
Database name (ambari):
Username (ambari):
Enter Database Password (bigdata):
Re-enter password:
Configuring ambari database...
Should ambari use existing default jdbc /usr/share/java/mysql-connector-java.jar [y/n] (y)? y
Configuring remote database connection properties...
WARNING: Before starting Ambari Server, you must run the following DDL directly from the database shell to create the schema: /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql
Proceed with configuring remote database connection properties [y/n] (y)? y
Extracting system views...
ambari-admin-2.7.4.0.118.jar
....
Ambari repo file contains latest json url http://public-repo-1.hortonworks.com/HDP/hdp_urlinfo.json, updating stacks repoinfos with it...
Adjusting ambari-server permissions and ownership...
Ambari Server 'setup' completed successfully.
在交互模式中,需要填写的内容,可按照上面我填写的来。
首先是 JDK 路径,我们进行了手工指定,数据库选了 MySQL,接着需要给出 MySQL 库的地址、端口、库名、用户名和密码,这些信息在上面初始化数据库的时候已经进行了创建。然后,ambari 会询问 jdbc 对应的 jar 包驱动,直接输入 y 即可。最后,有个警告信息,这个非常重要,该信息告诉我们,在启动 ambari server 之前,需要先对数据库执行一个 SQL 文件导入,其实就是导入 ambari server 的一些基础数据,导入方法如下所示:
mysql> use ambari
mysql> source /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql;
ambari 基础数据导入完成后,就可以启动 ambari server 服务了,执行如下命令:
[root@ambariserver ~]# ambari-server start
Ambari Web 默认会启动一个 8080 端口,可通过http://ambariserver:8080 访问 Web 界面,用户名和密码默认 admin。
通过 Ambari 部署一个 Hadoop3.x 集群
安装 Ambari 后,就可以通过该工具进行 Hadoop 的自动化安装部署和集中维护等工作了。下面我将带领你亲身体验 Ambari 的用武之地,以及给运维带来哪些便捷之处。
1. 从零开始部署一套 Hadoop3.x 集群
当你成功登录 Ambari Web 之后,会看到如下默认界面:
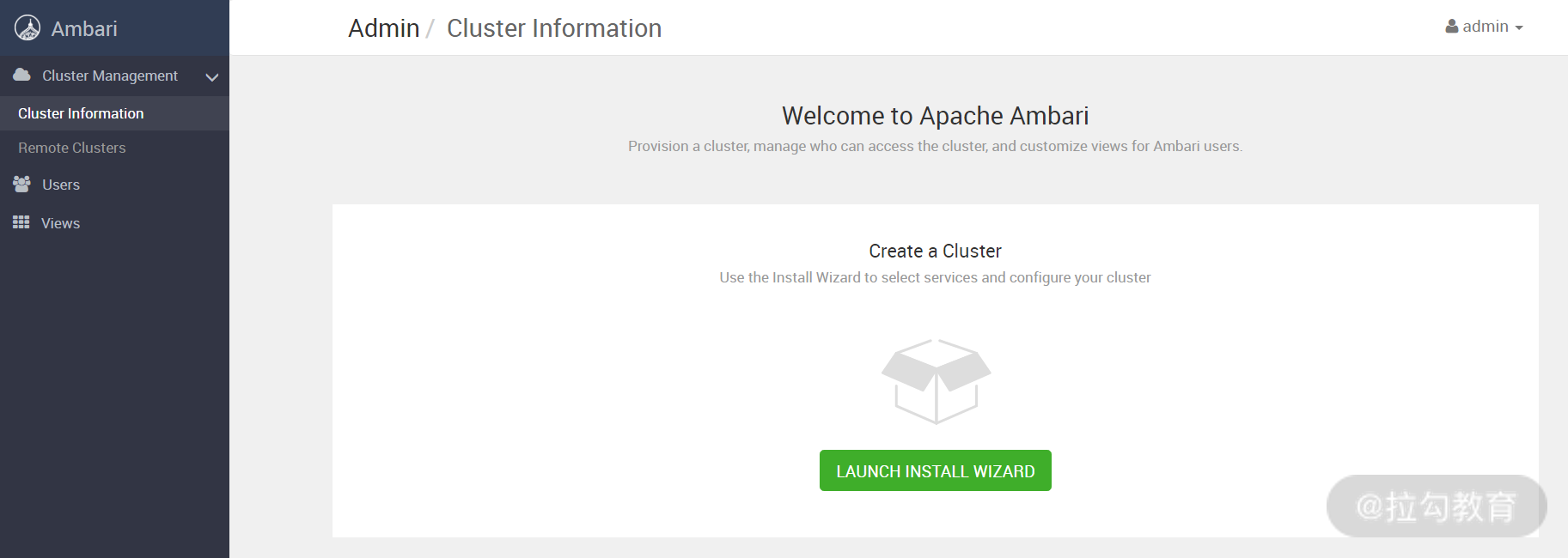
点击上图的“LAUNCH INSTALL WIZARD”,就可以开始创建一个大数据集群了,如下图所示:
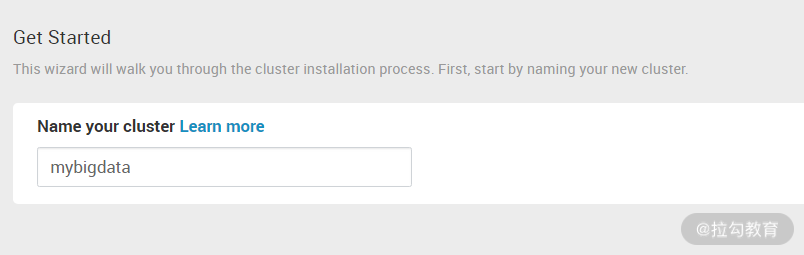
需要定义一个集群的名字,这里我命名为 mybigdata,接着进入下图界面:
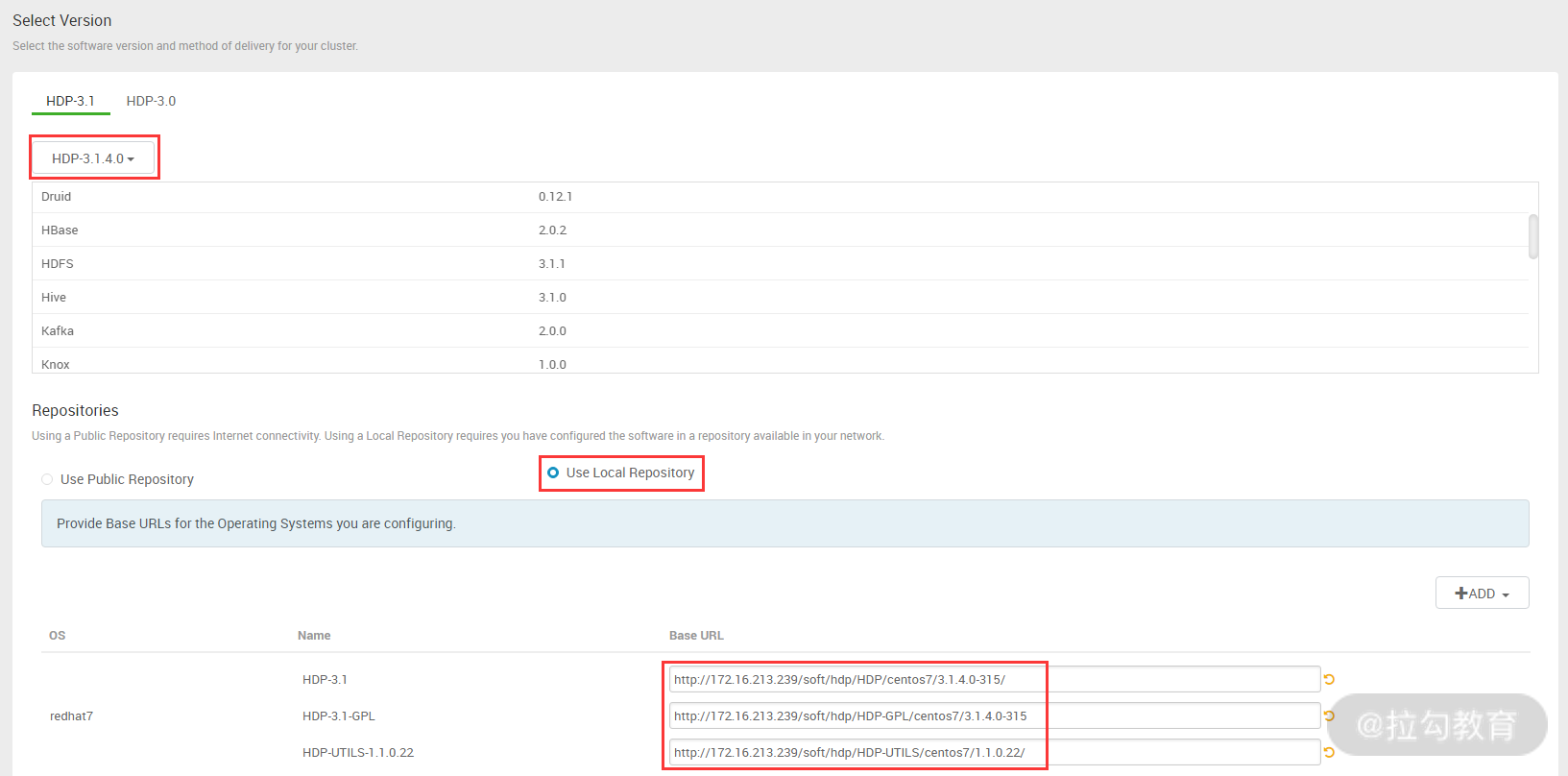
图中需选择要安装的 HDP 版本,以及安装 HDP 的 yum 仓库地址,HDP 版本选择目前最新的 3.1.4 版,而 HDP 仓库可以选择官方的 yum 地址,也可以用本地的 yum 源地址。由于安装 HDP 需要下载的软件很多,而官方 yum 地址下载速度很慢,因此建议搭建本地仓库,可以点击如下 HDP 的三个压缩包下载,然后解压放入本地仓库即可:
-
HDP
-
HDP-UTILS
-
HDP-GPL
这里,本地仓库是 172.16.213.239,其三个 URL 地址分别是:
-
http://172.16.213.239/soft/hdp/HDP/centos7/3.1.4.0-315/
-
http://172.16.213.239/soft/hdp/HDP-GPL/centos7/3.1.4.0-315/
-
http://172.16.213.239/soft/hdp/HDP-UTILS/centos7/1.1.0.22/
上图配置完成后,点击“下一步”按钮,进入下图界面:
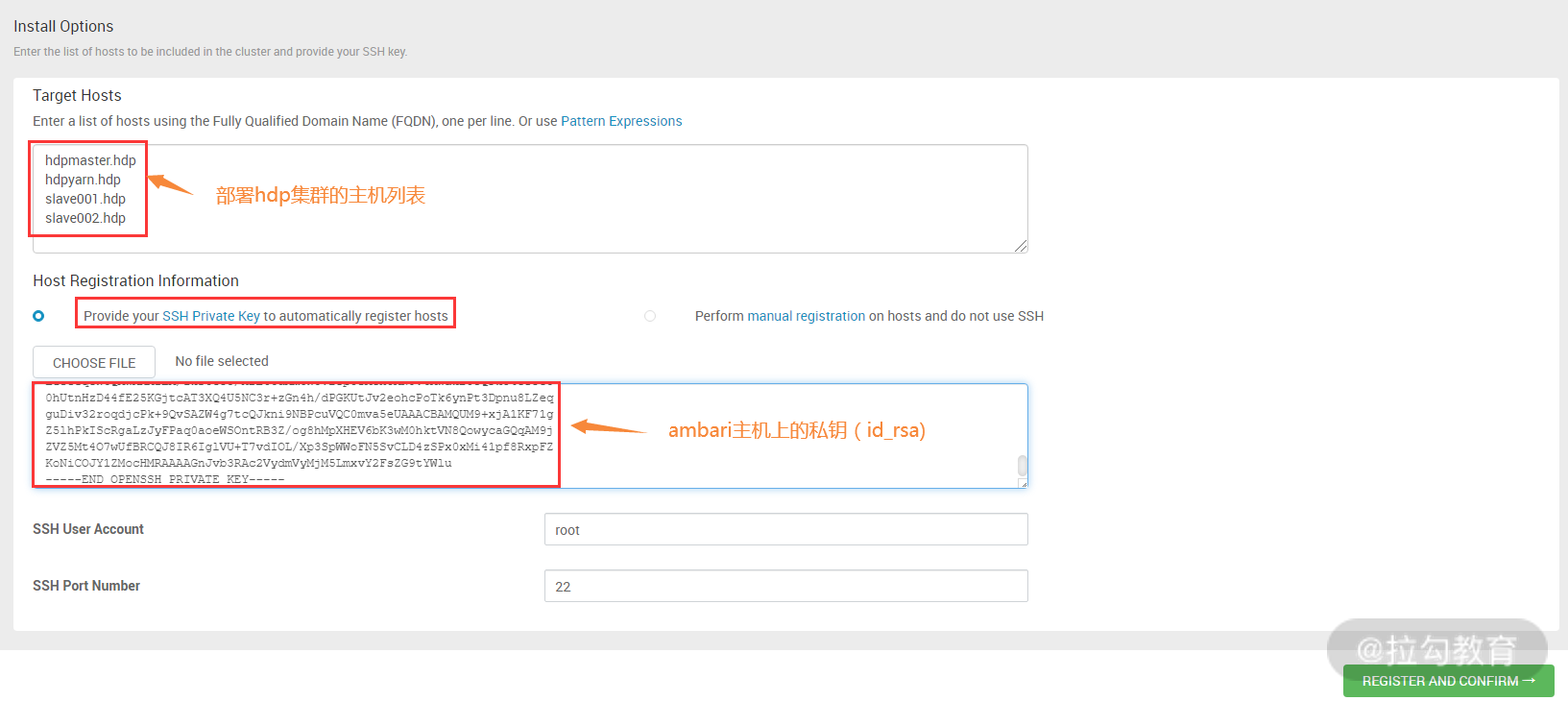
此步骤需要配置的有两个,第一个是安装 hdp 集群的主机列表,这里我通过主机名进行定义,一行一个主机名,当然这些主机名是可以解析到 IP 地址的。第二个是指定 ambari server 主机的私钥,可以通过上传私钥文件或者贴出私钥文件的内容这两种方式,最后一部分是配置 ambari server 主机登录到 agent 主机的用户和端口,保持默认即可。
配置完成,点击“下一步”按钮,进入下图所示界面:
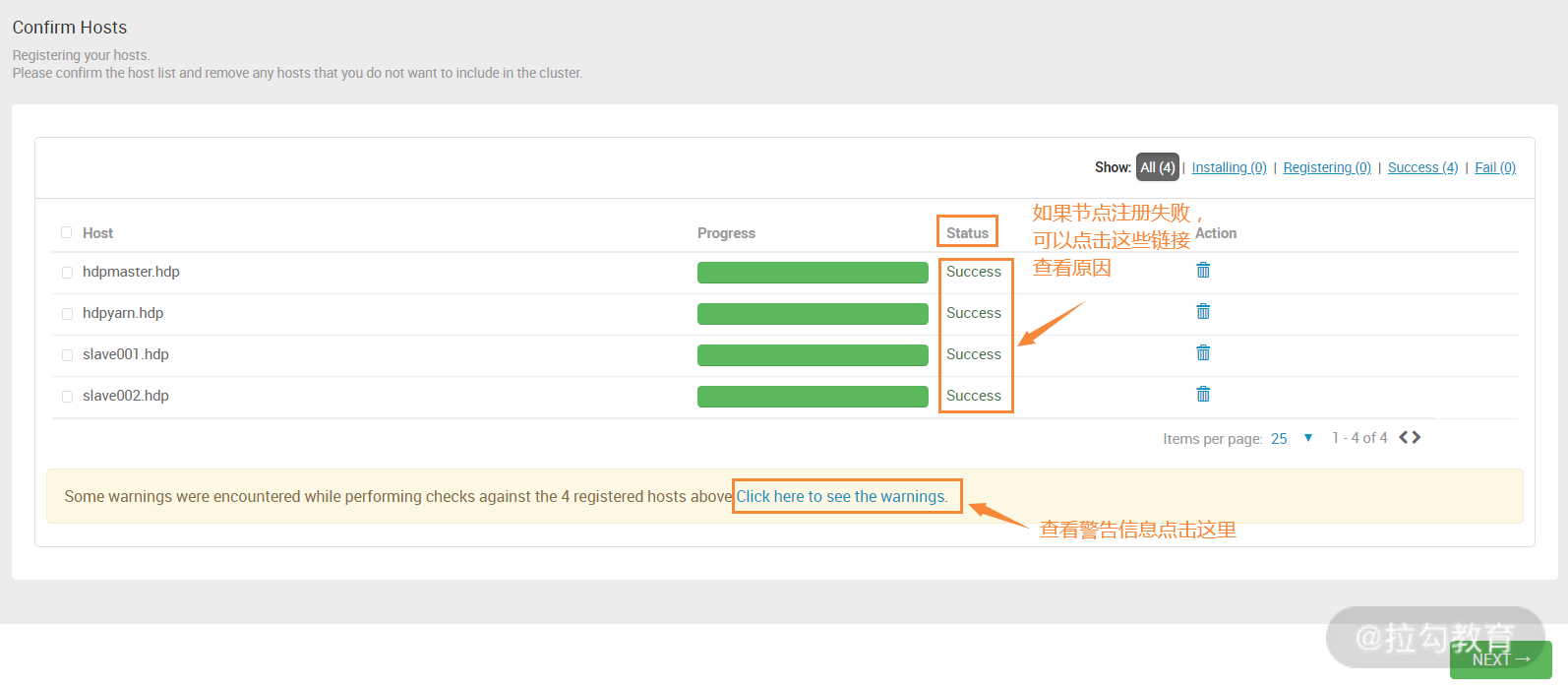
这个步骤最容易出错,因为此步骤首先进行无密码登录验证,也就是从 ambari server 主机登录到所有 hdp 集群节点。如果能够登录到 hdp 节点,那么将进行一系列注册操作,主要包括从 ambari server 拷贝多个 Python 脚本、创建 ambari 源、安装 ambari agent 等任务。
如果出现错误,会有状态提示,点击“status”列下面的链接会显示详细的错误日志,然后根据错误信息进行问题排查。如果操作系统配置方面有问题,可能会出现警告,点击最下面那个警告链接查看详细信息。
配置完成后,点击“下一步”按钮,来到下图所示界面:
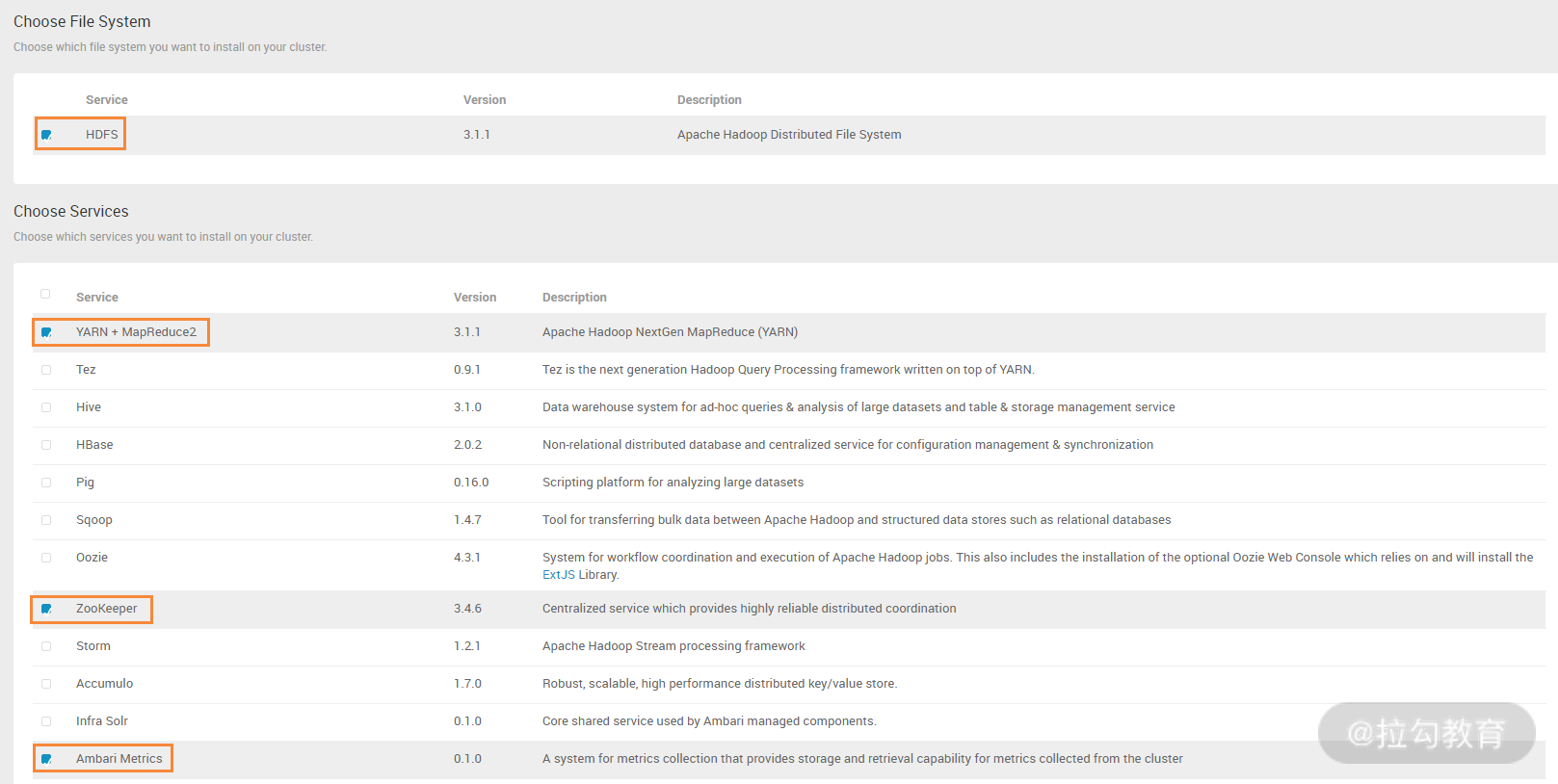
这个步骤是选择要安装的集群服务,其中,HDFS 是必选项,然后在选择服务中看到有非常多的可选服务,要根据实际环境中需要的服务,选择安装即可。这些服务之间有依赖性,比如你选择了 YARN+MapReduce2,那么必须要选择 ZooKeeper 服务,安装向导会检测这种依赖性并提示你进行安装,当然,有很多服务是没有必要安装的,如 Atlas、Ranger、SmartSense 等,如果没有安装这些服务,那么安装向导有如下提示:
这里选择 PROCEED ANYWAY 即可,这样就跳过安装了,但有些服务像“流氓”一样,必须强制安装,如 SmartSense,没关系,先安装上,所有安装完成后,再卸载了它即可。
本例中我选择了 HDFS、YARN+Mapreduce2、ZooKeeper、Ambari Metrics 这些基础服务,其他服务暂时不选,等基础服务安装完成后,再单独安装其他外围服务。要安装的服务选择完毕后,就进入了下图界面中:
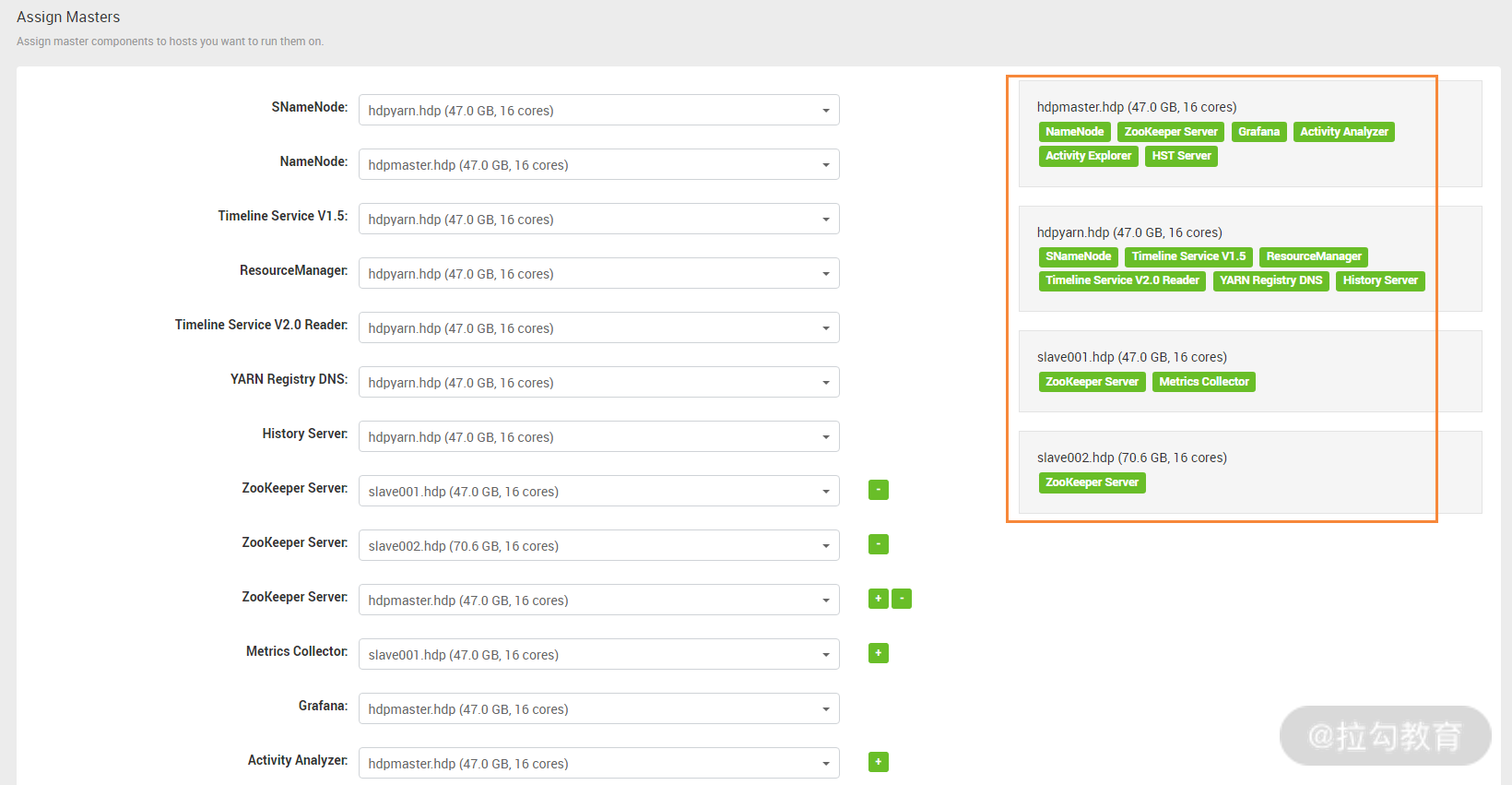
此步骤是建立 hdp 服务和主机的对应关系,也就是这些服务分别安装在哪些主机上,这其实就是我之前介绍的主机角色规划,根据之前的功能规划,将不同服务选择安装到对应的主机上即可。一个基本的分配原则是分布式存储和分布式计算功能分开,这里可以看到,出现了一个 SNameNode 服务,此服务可以为 NameNode 提供冷备功能。要和 NameNode 服务部署在不同的主机上,另外,还需要为 ZooKeeper Server 选择三台独立的主机,而 Grafana 是一个美观、强大的可视化监控指标展示工具,放在一个负载不高的节点即可。最后,剩余的其他服务都跟 resourcemanager 有关,因此统一放到一个主机上即可。
接着,就进入了如下界面:
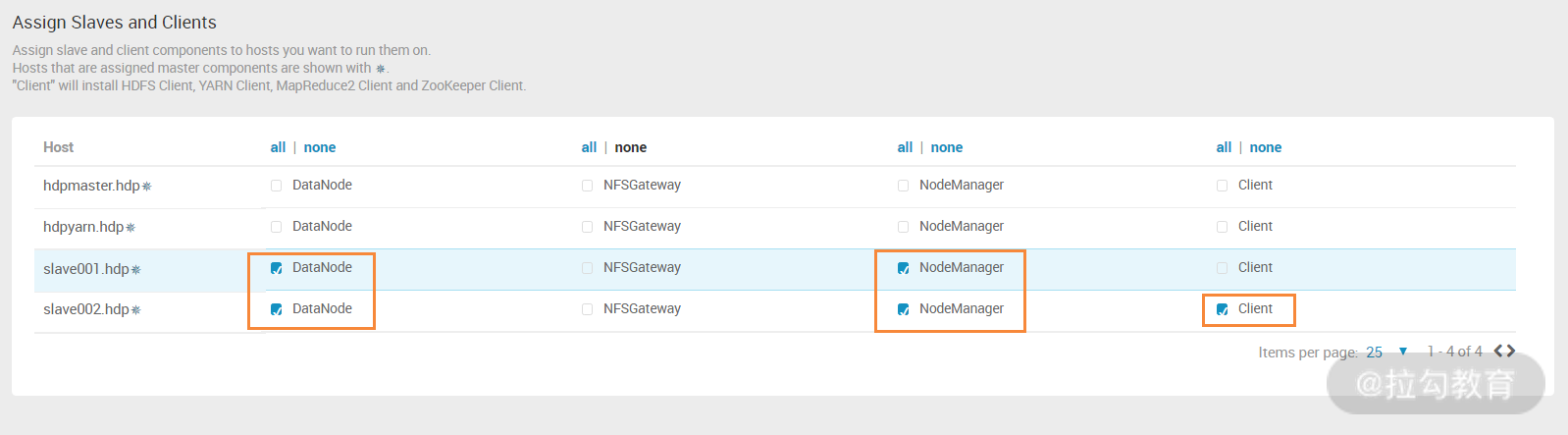
此步骤是分配集群的 slave 节点和 client 节点,slave 节点主要对应 Datanode 和 Nodemanager 服务,可以将这两个服务同时部署到一台主机上。而 client 节点就是上面介绍过的外围机功能,为必选项,这里选择 slave002.hdp 主机作为 hdp 集群的外围主机。
接着,安装向导就来到了如下界面:
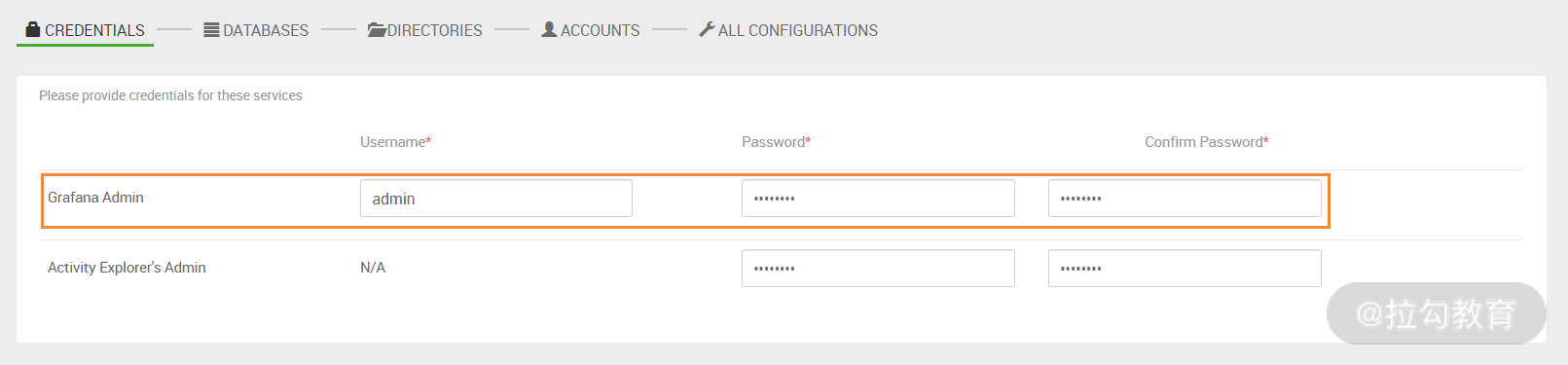
此步骤是设置 Grafana 登录的密码,统一设置一个密码即可,然后进入下一步,如下图所示:
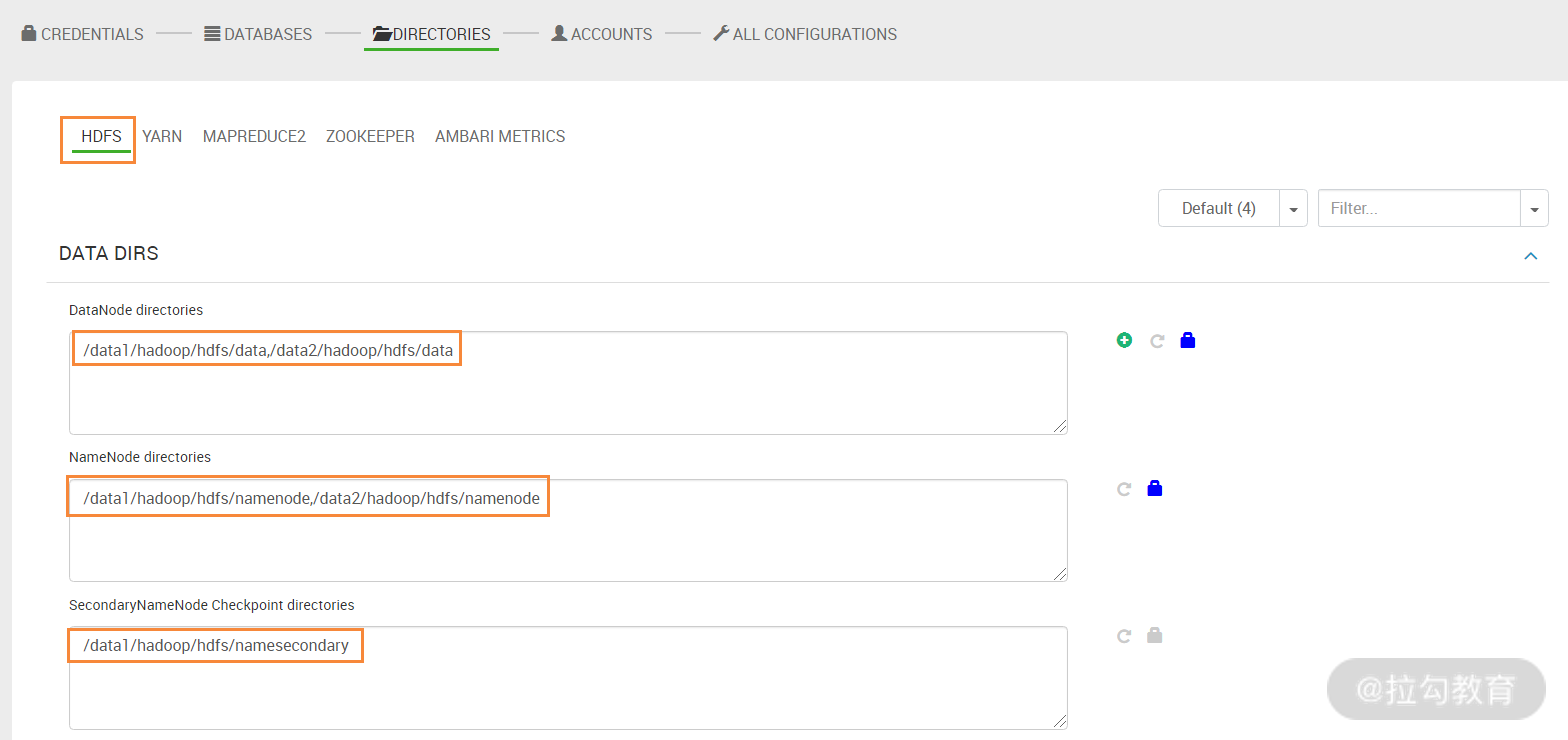
此步骤是设置 HDFS、Yarn、MapReduce2、ZooKeeper 等应用的数据存储路径和日志存储路径,这些存储路径需要提前规划好,这里我将 HDFS 数据块存储在每个 datanode 节点的 /data1 和 /data2 目录了,这两个路径对应的是两个独立的磁盘。同时将 HDFS 元数据存储在 Namenode 主机的 /data1 和 /data2 目录下,这两个目录对应的是两组独立的 RAID1 磁盘组,最大限度保证元数据的安全。其他日志路径保持默认即可。
同理,还需要设置 Yarn 的几个路径信息,如下图所示:
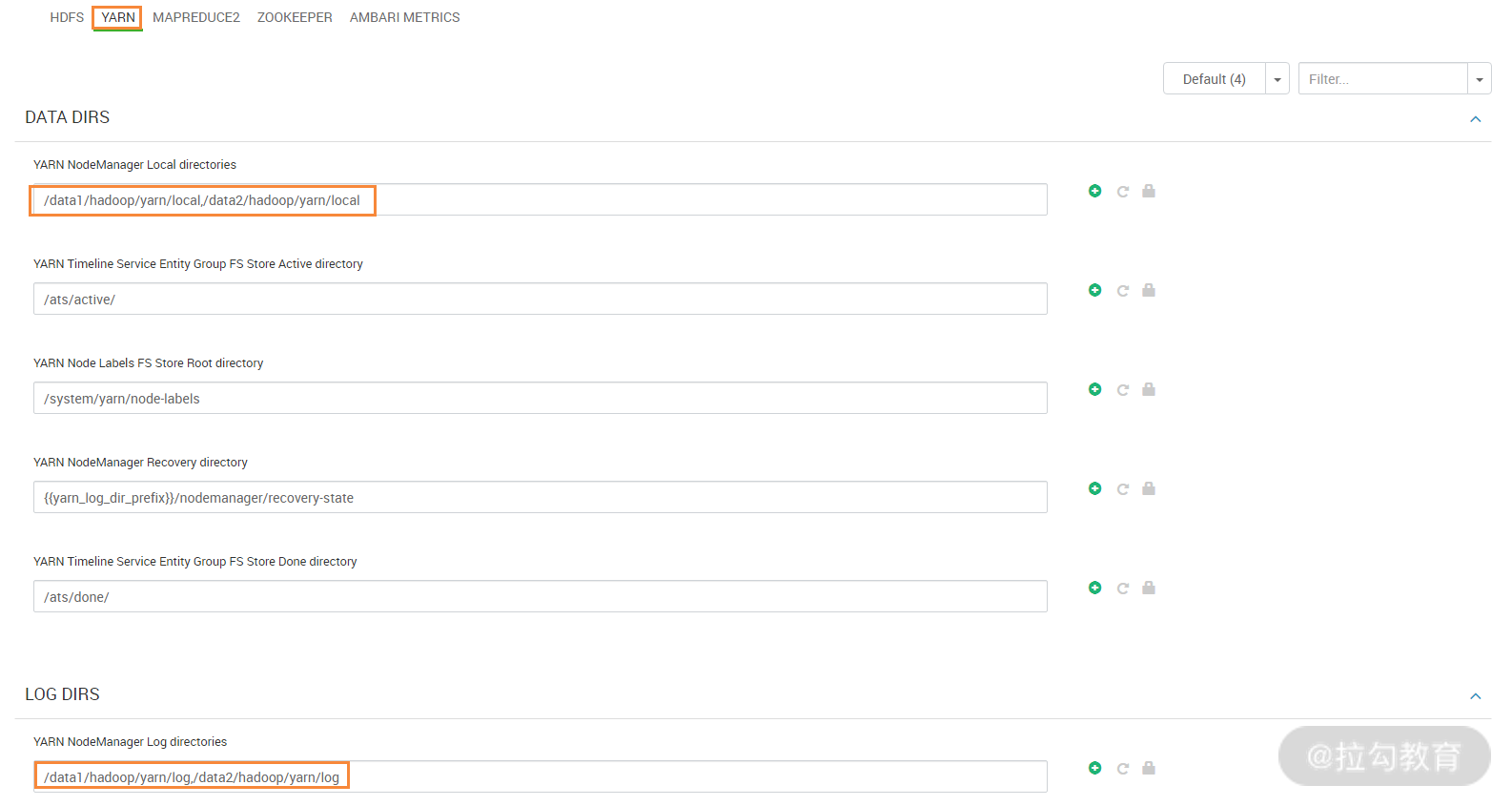
重点设置的是 Yarn 中 nodemanager 的 local directories、log directories 的路径,其中,local directories 用来设置 application 在分布式计算过程中的中间数据存储路径,建议分为多个磁盘来存储;而 log directories 是配置 nodemanager 上 container 运行的本地日志存储路径,这两个路径都是本地文件系统上的路径。
接着,还要简单设置下 ZooKeeper 的数据存储路径,如下图所示:
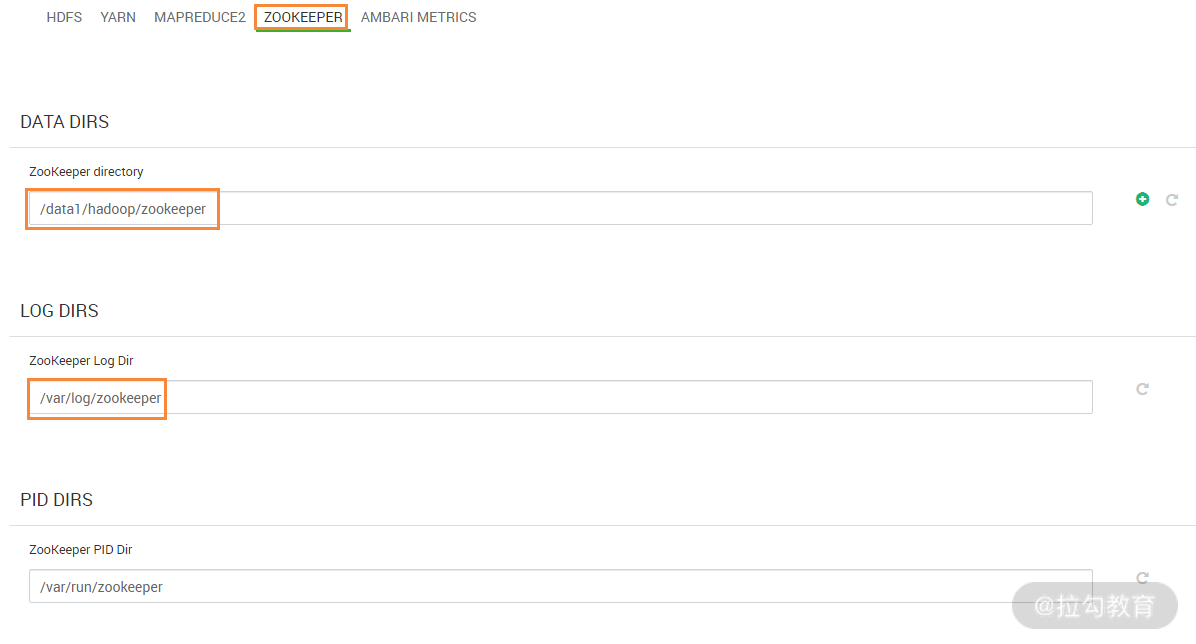
此步骤配置 ZooKeeper 的数据存储目录以及日志存储目录,配置完成,进入下一步操作,如下图所示:
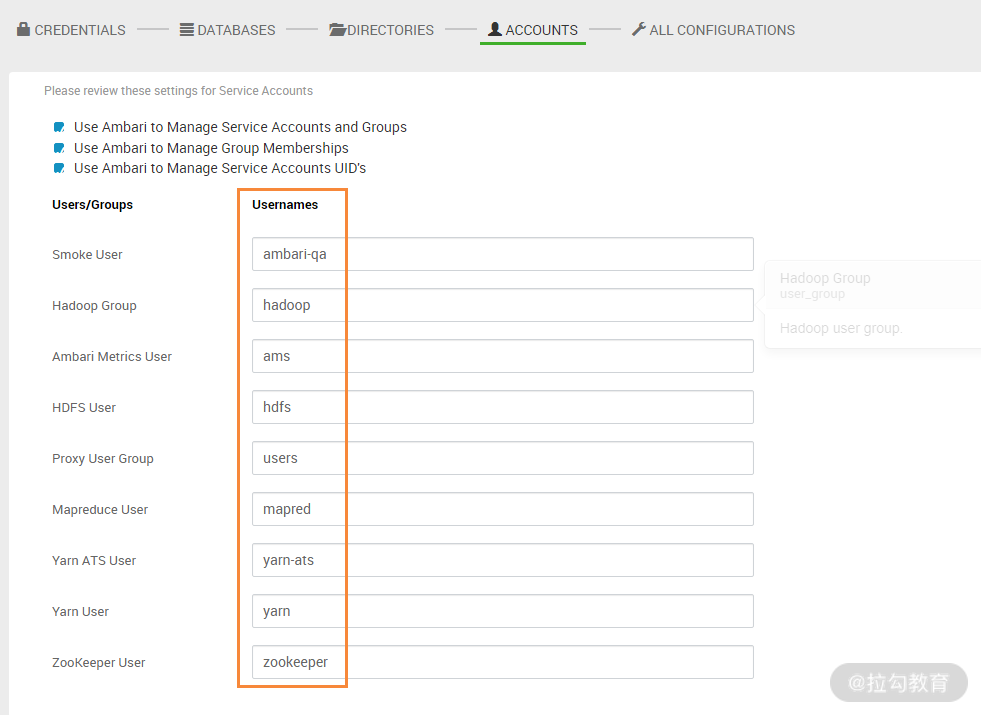
此步骤是配置用 ambari 管理 hdp 集群服务的账号和组,即针对不同的服务,分别有不同的用户和组进行服务的启动管理工作。保持默认即可。
点击“下一步”按钮,进入下图界面:
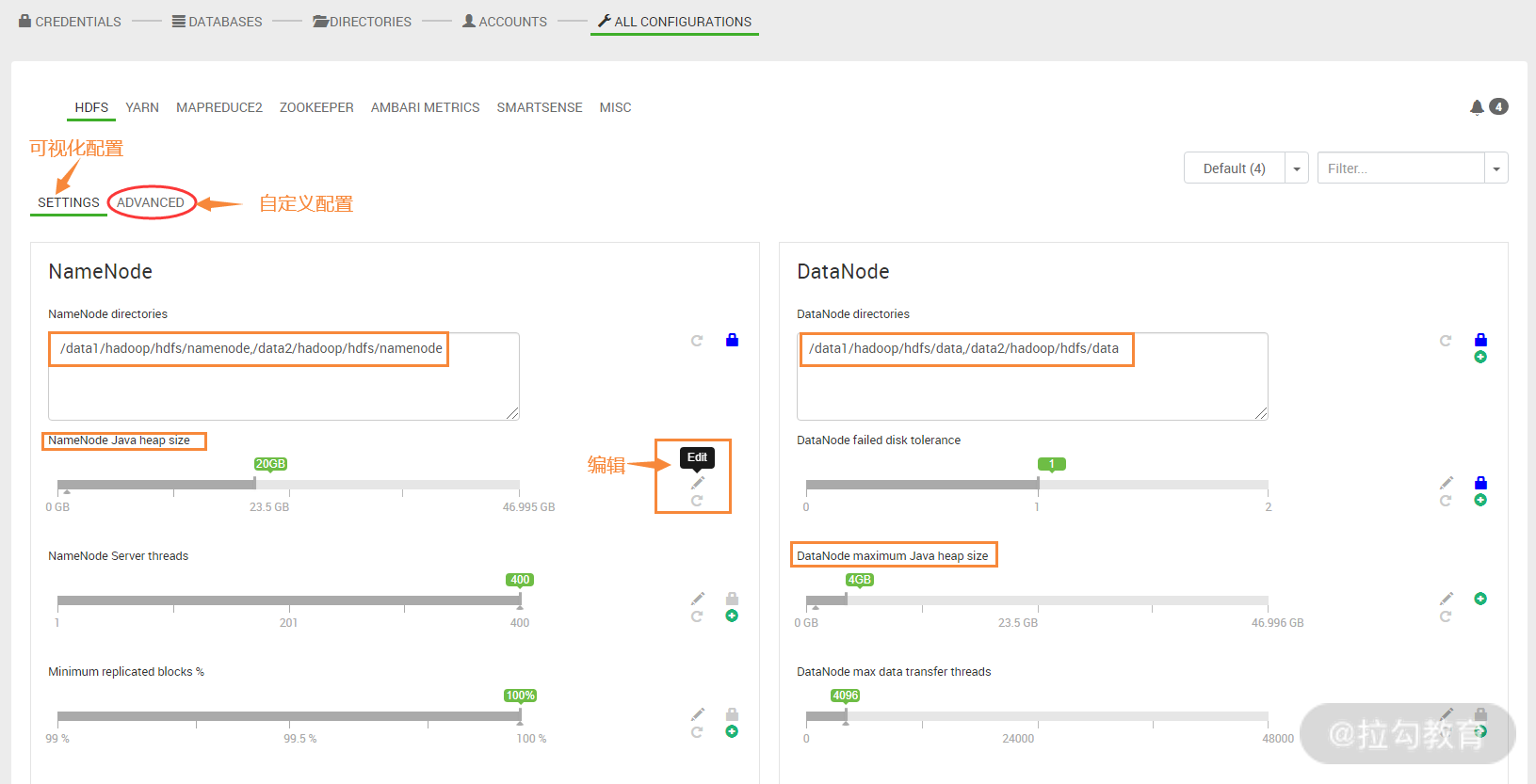
此步骤非常重要,主要用来配置 HDFS、Yarn、MapReduce2、ZooKeeper 等一些 JVM 内存参数和优化参数,可以在这个界面进行基础参数设置,如何自定义配置参数,可点击上面的“ADVANCED”进入高级配置部分。这里我就配置几个基础参数,主要是 NameNode java head size 和 datanode maximum java head size,一般 NameNode java head size 要足够大,这里我设置为 20G,datanode maximum java head size 设置 4GB 基本可满足一般需求。
接着,还需要对 yarn 进行内存和 CPU 的资源配置,如下图所示:
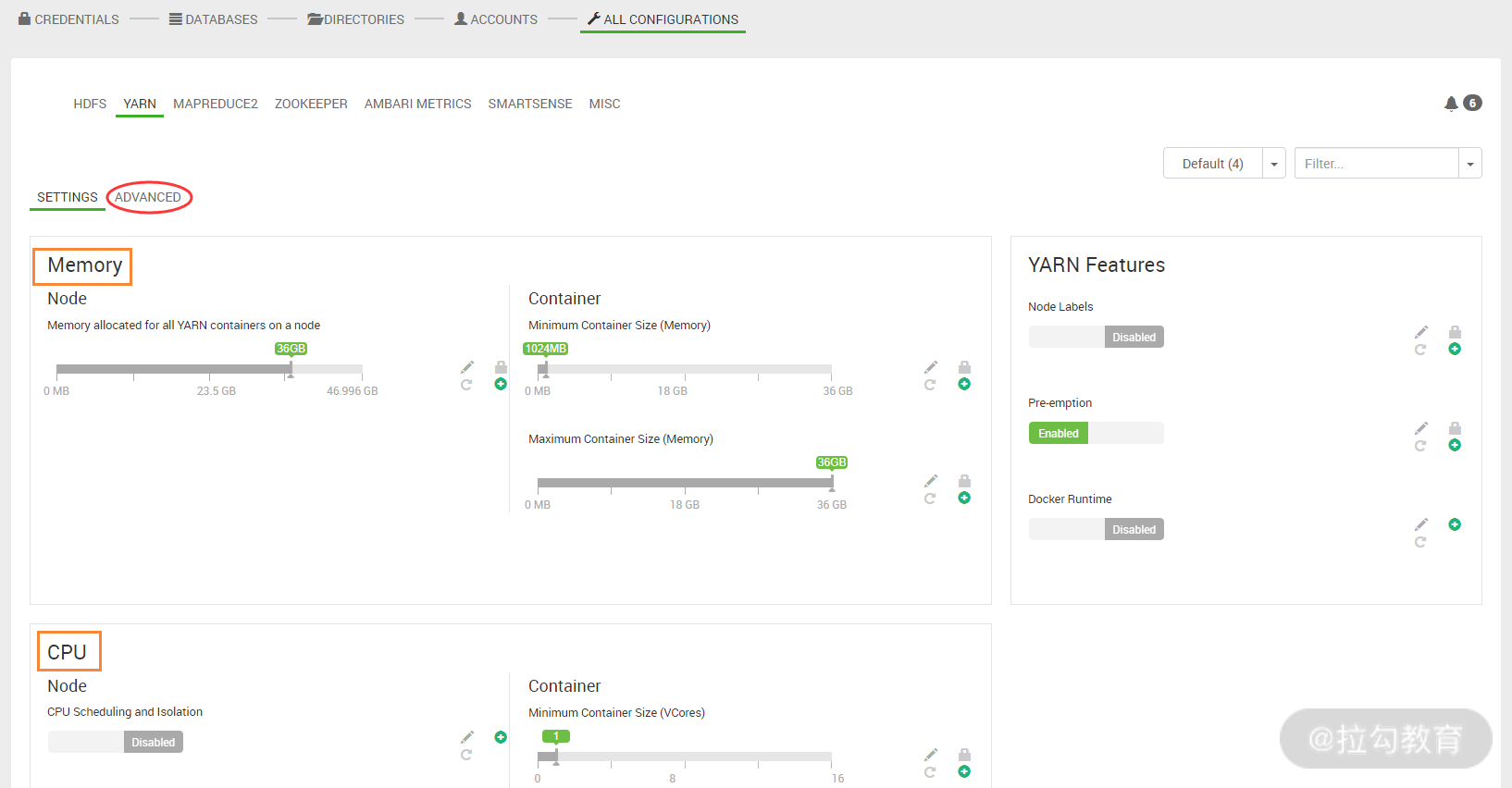
此界面中,有两个配置需要特别注意,第一个是 Memory 项,它主要设置每个 nodemanager 节点可最大使用的内存量,对应的参数是 yarn.nodemanager.resource.memory-mb;另一个是 CPU 项,它主要配置每个 nodemanager 节点可最大使用的虚拟 CPU 核数,对应的参数为 yarn.nodemanager.resource.cpu-vcores。
所有相关参数配置完成后,点击“下一步”按钮,进入下图界面:

此步骤是一个安装预览界面,直接点击“下一步”按钮,如下图所示:
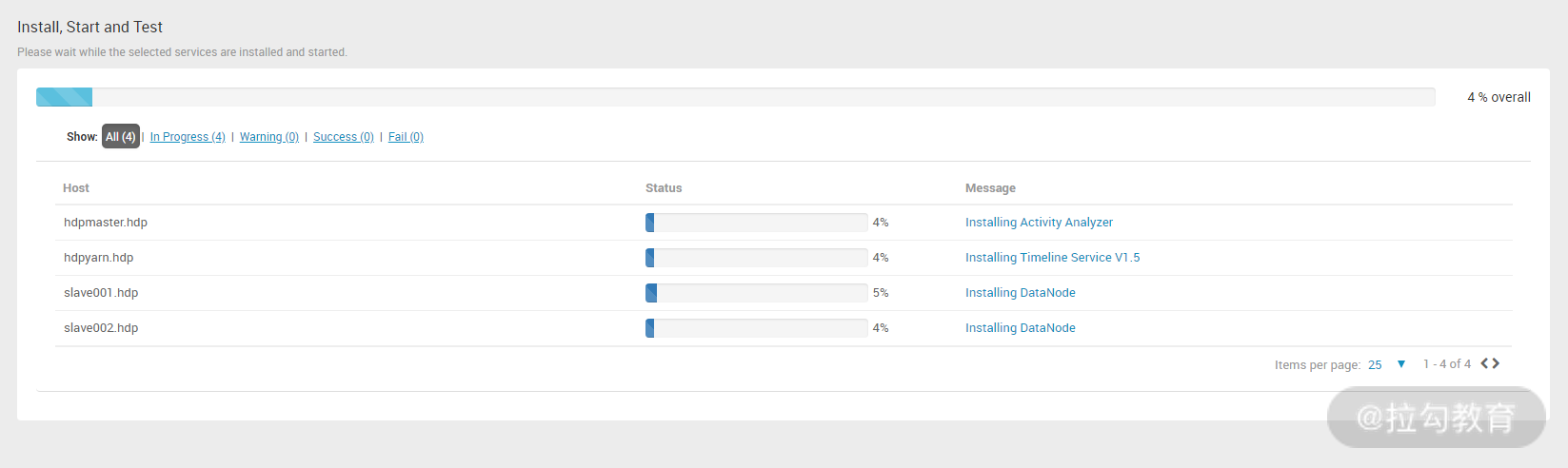
从此步骤开始,正式进入了 hdp 集群安装过程,安装过程可能会出现问题,如果出现错误,可点击 Message 列下面的链接来查看具体出错信息。我在安装过程中,在 hdpyarn.hdp 主机上出现了错误,点击主机对应的 Message 列链接,发现了错误的具体信息,如下图所示:
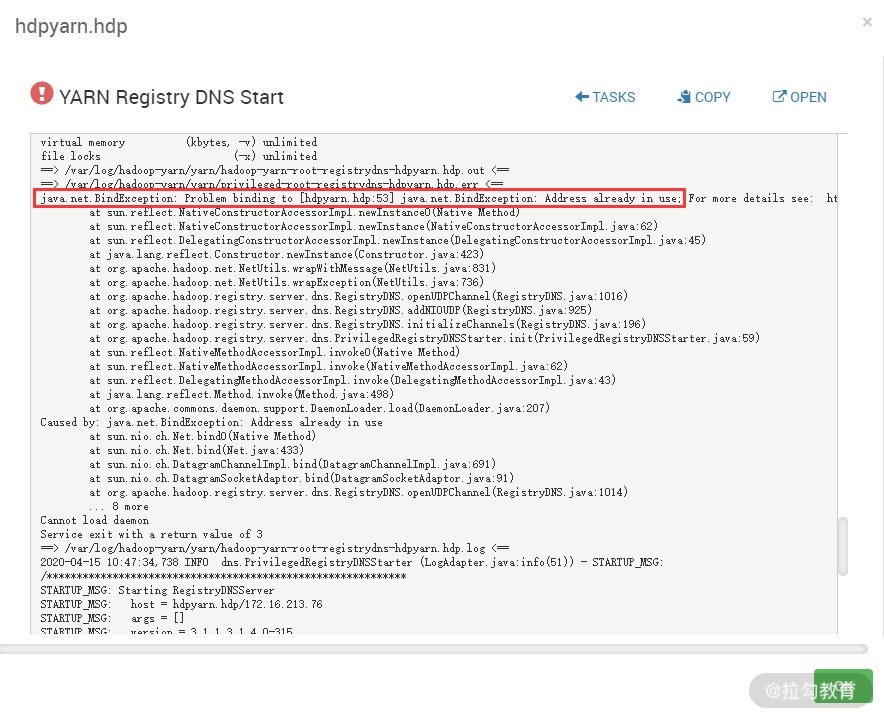
这个错误提示此主机上 53 端口被占用,导致 YARN Registry DNS 服务无法启动,于是登录此主机检查 53 端口,发现被 dnsmasq 服务占用了,于是关闭 dnsmasq 服务,重启 YARN Registry DNS 服务就恢复正常了。
这是解决问题的一个例子,很多情况下在部署中出现的错误,都会有详细的日志信息,结合日志,可以很快排查出问题。
由于我这里使用的是本地 yum 源,因此安装过程应该很快,如果没有任何报错信息,那么hdp集群就安装成功了。下图是安装完成后的一个界面图:
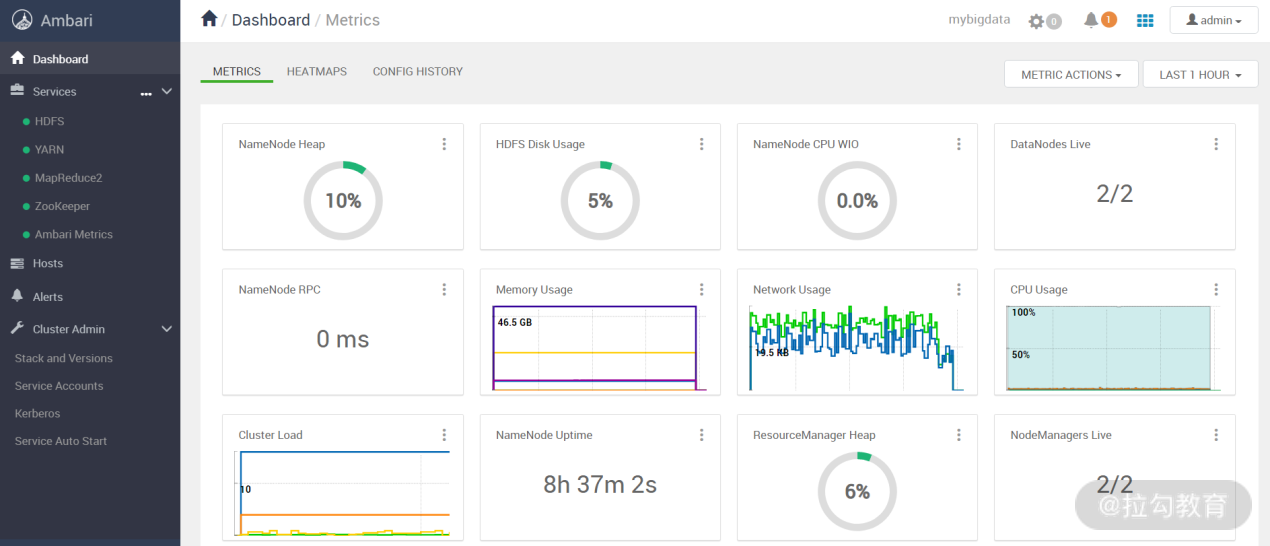
接下来,我们就可以在这个平台上对 hdp 集群进行配置与管理了。
2. 利用 Ambari 扩容集群节点
如果出现 HDFS 存储空间不足或者计算能力不够了,那么就需要扩容 HDP 集群。通过 Ambari 扩容集群非常简单,只需要轻点几下鼠标即可完成。
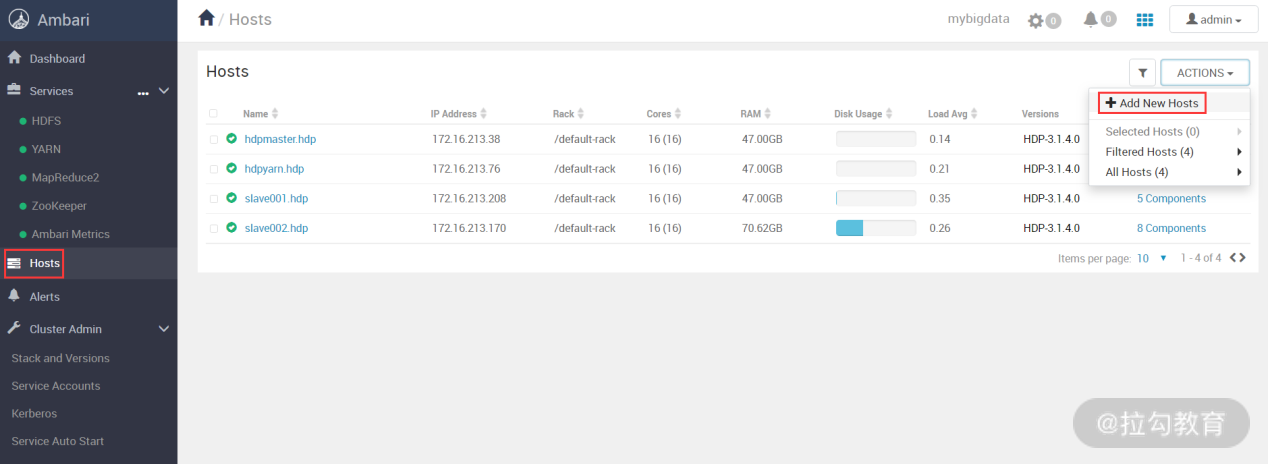
首先,在 Ambari 主界面点击左侧导航栏 Hosts 项,然后在右上角的“ACTIONS”按钮选择“Add New Hosts”,如下图所示:
接着,就会出现如下图所示的界面:
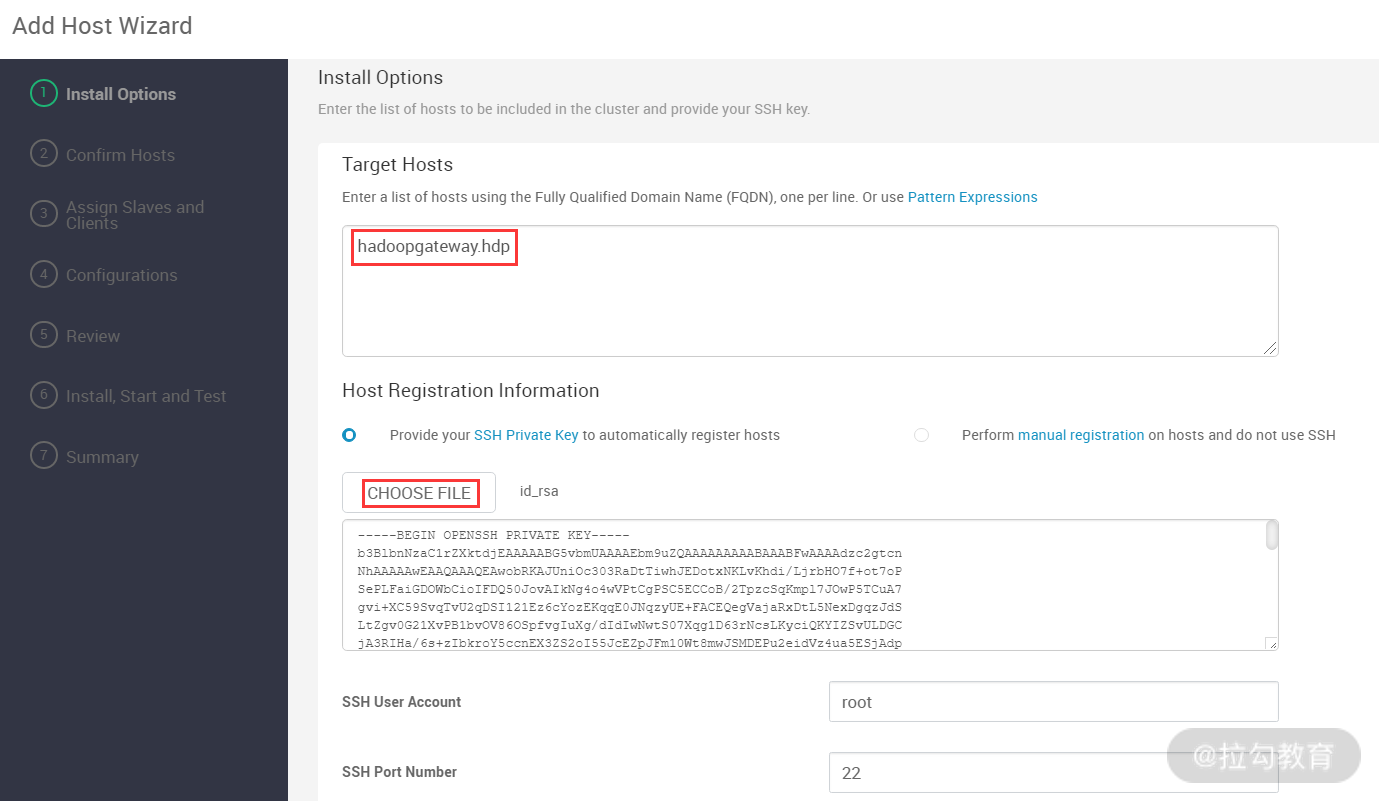
这个界面似曾熟悉,其实就是配置要扩容的主机地址,以及如何无密码登录到此主机,在加入此主机前,要配置好 Ambari 主机到 hadoopgateway.hdp 主机的密钥登录认证,配置完毕后,点击“下一步”按钮即可进入下图所示的界面中:

此步骤开始自动注册此主机,所谓注册,就是拷贝一些 Python 脚本到这个主机,并安装 Ambari Agent 服务,还有就是对此主机的环境检测,如果环境检测发现问题,还给出警告提示。我这里就检测出了几个问题,如下图所示:
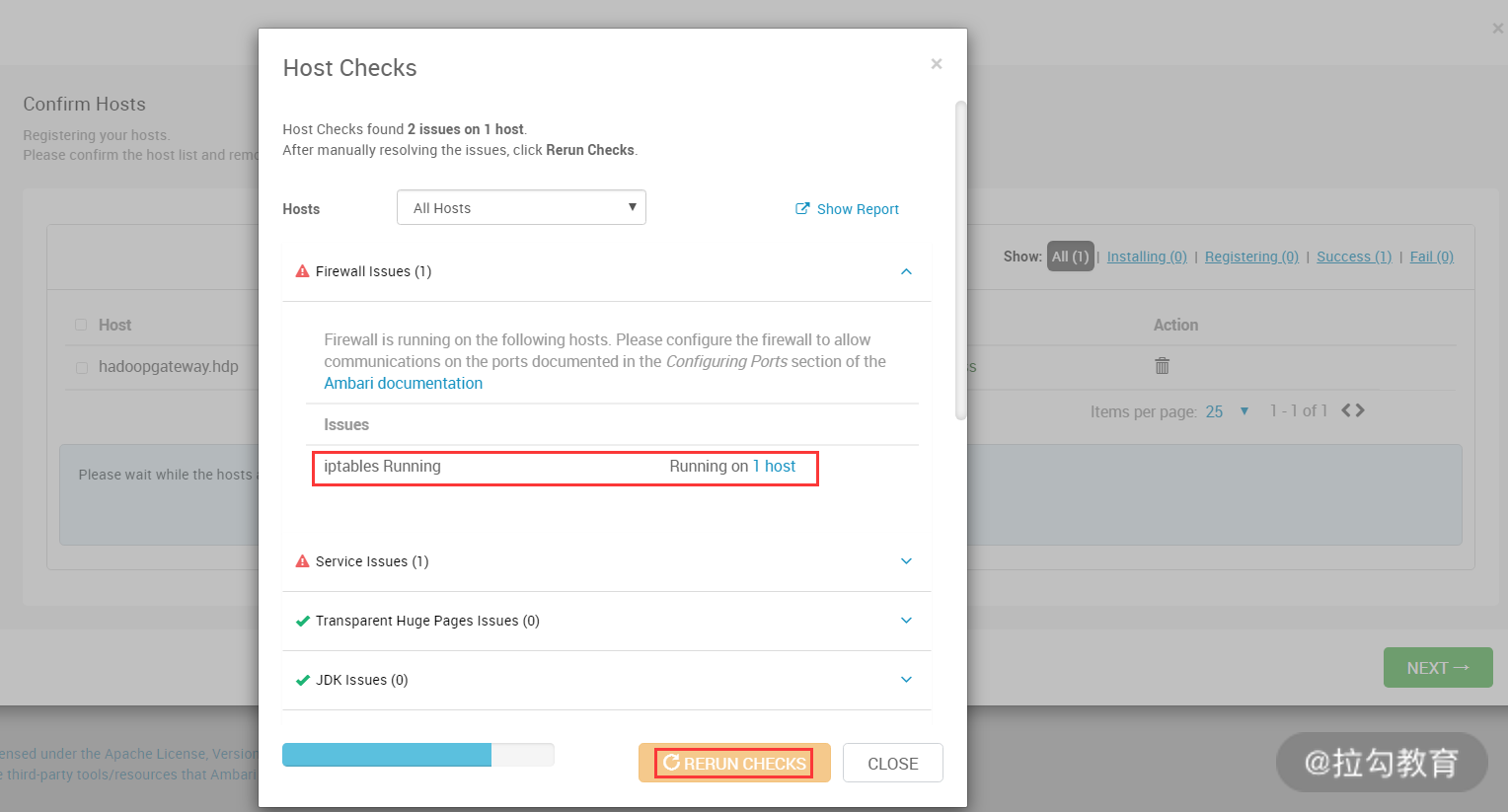
这个错误提示此主机 iptables 没有关闭,根据提示关闭防火墙即可,然后单击“RERUN CHECK”按钮重新检查。主机注册成功后,点击“下一步”按钮进入下图所示的界面:
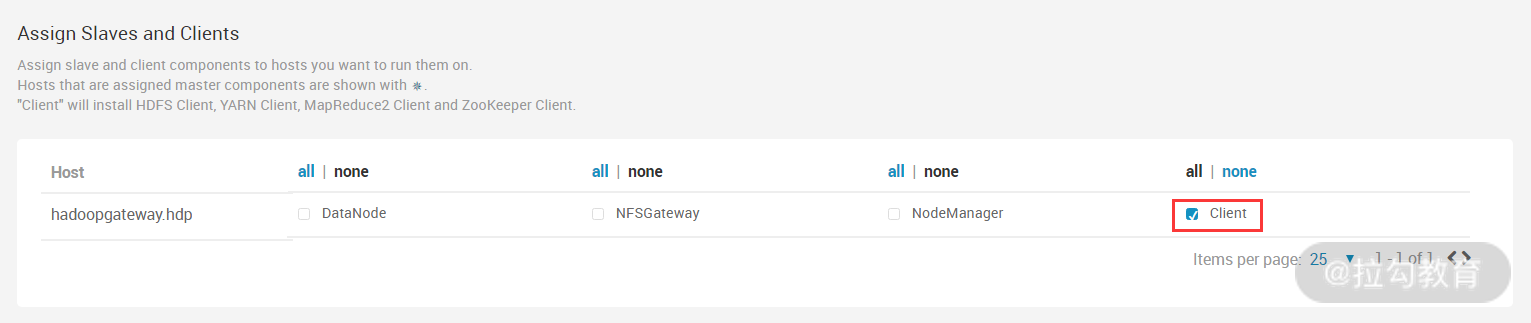
此步骤是选择主机的角色,因为这个主机是作为 Hadoop 外围机使用的,也就是开发、测试人员都通过此主机提交任务到 Hadoop 集群。所以这里选择 Client 即可。继续点击“下一步”按钮,进入下图所示的界面:
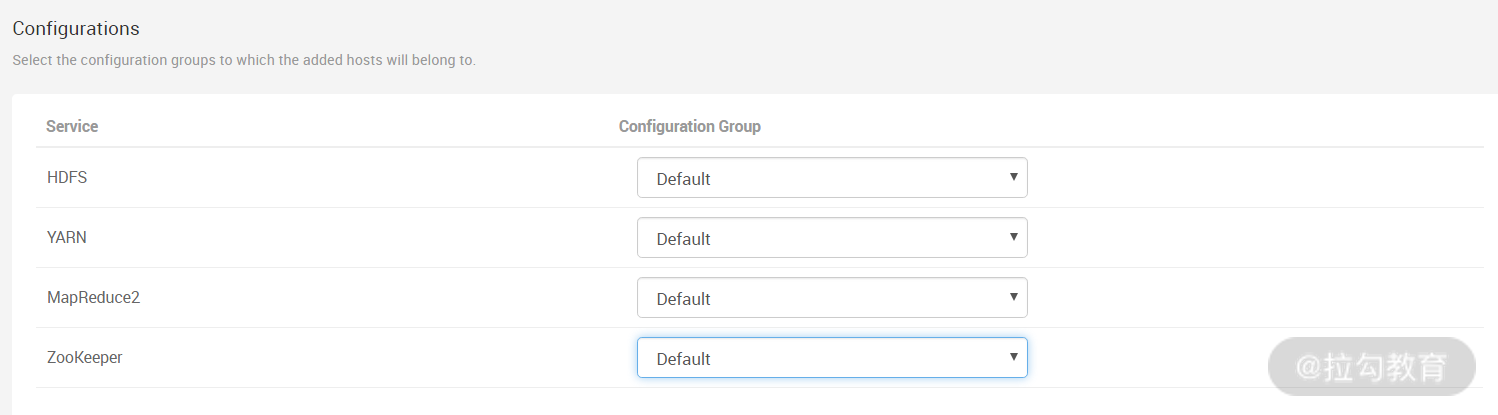
此步骤是配置将新增主机加入那个配置组中,保持默认即可,点击“下一步”按钮,进入安装预览界面,继续点击“下一步”按钮,开始进行安装,如下图所示的界面:
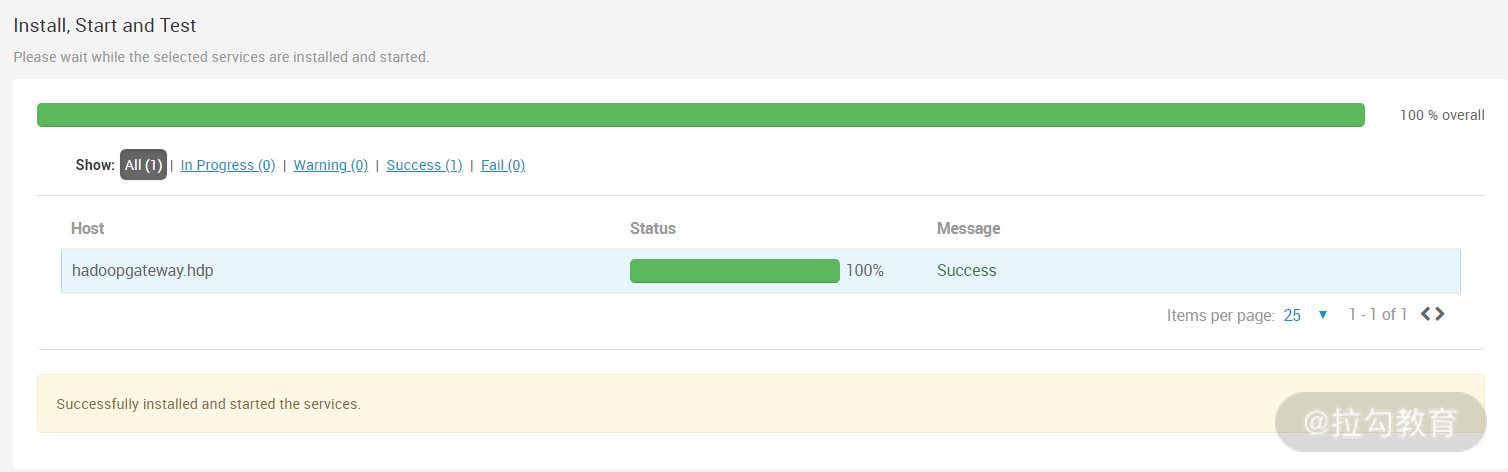
这样,一个新增主机就添加到集群中了,可以根据这个方法,添加多个 datanode 节点或 nodemanager 节点到集群中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号